메모리 관리의 배경
멀티태스킹 시스템에서는 여러 프로세스가 동시에 메모리에 존재한다. 메모리는 현대 컴퓨터 시스템의 핵심 자원이며, 이를 효율적으로 관리하는 것이 운영체제의 중요한 역할이다.
메모리는 각각 고유한 주소(Address) 를 가진 바이트 배열로 구성된다. 메모리 장치는 주소의 연속적인 흐름만을 다루며, 주소가 어떻게 생성되었는지는 관여하지 않는다.
기본 하드웨어
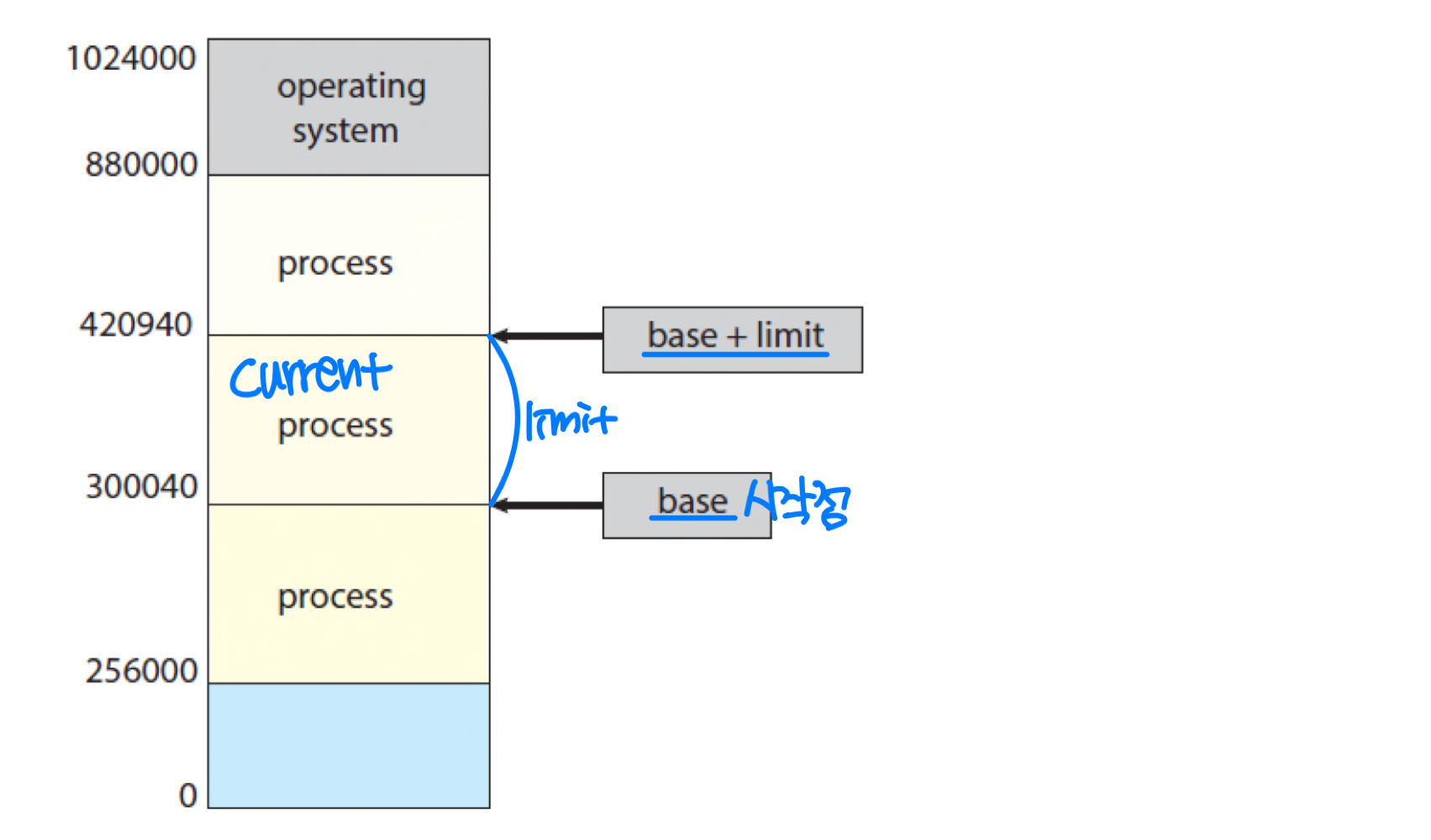
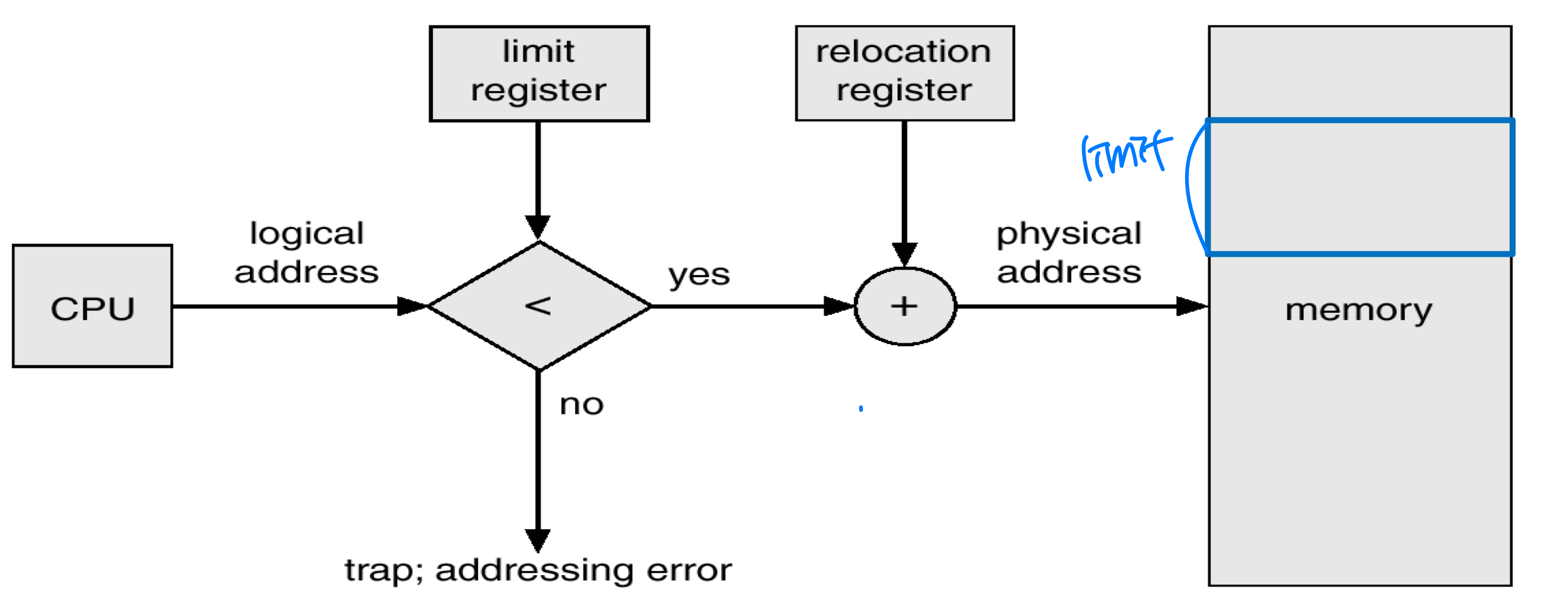
각 프로세스는 독립된 메모리 공간을 가져야 하며, 다른 프로세스의 메모리 영역을 침범해서는 안 된다. 이를 위해 베이스 레지스터(Base Register) 와 리밋 레지스터(Limit Register) 를 사용한다.
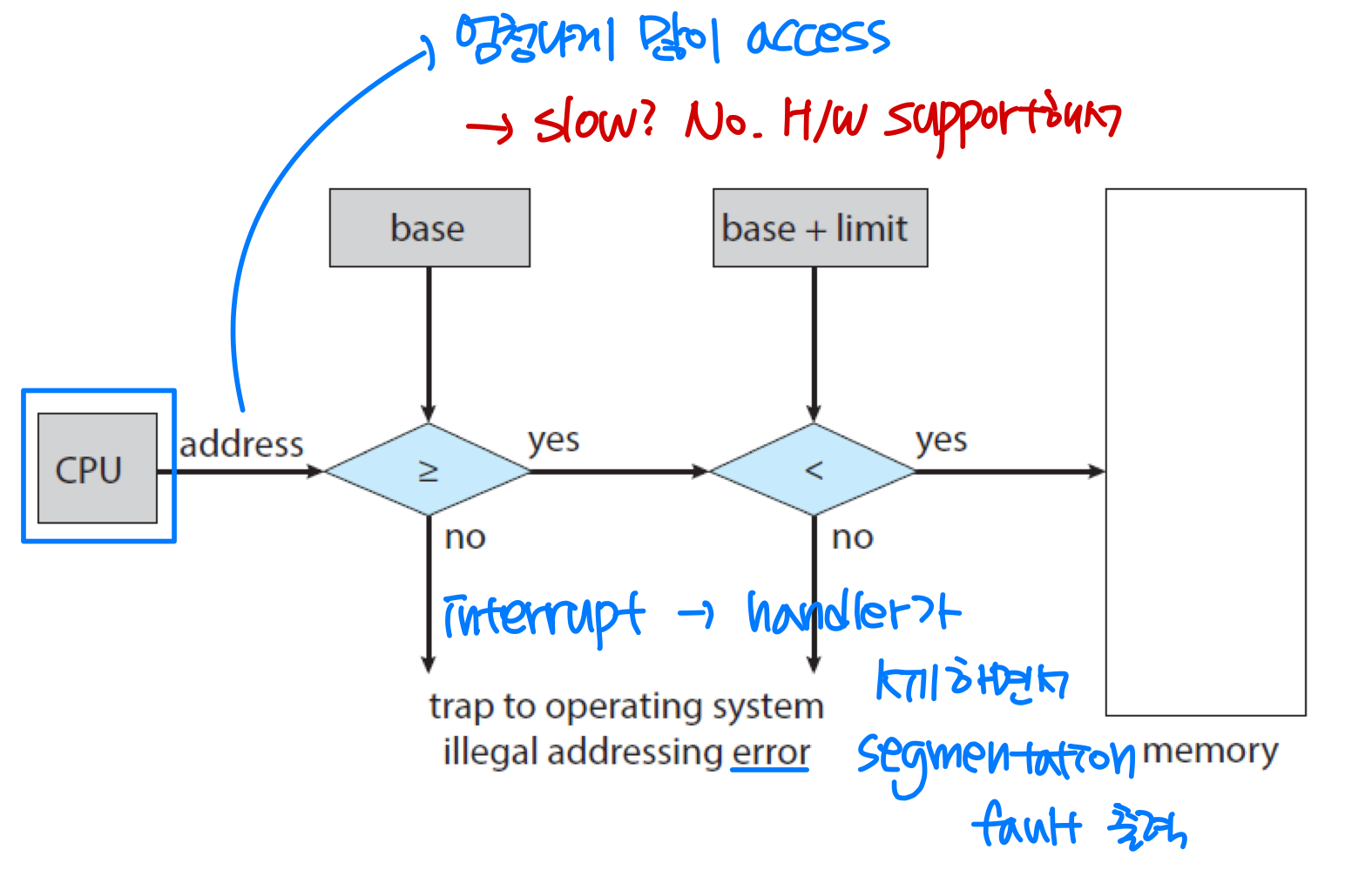
베이스 레지스터는 프로세스가 사용할 수 있는 메모리의 시작 주소를, 리밋 레지스터는 그 범위의 크기를 저장한다. CPU 하드웨어가 생성된 모든 주소를 이 두 레지스터와 비교하여, 범위를 벗어나면 트랩을 발생시킨다.
왜 메모리가 아닌 레지스터를 사용할까? 레지스터는 CPU 내부에 있어 참조 속도가 빠르기 때문이다. 메모리에 두면 매번 참조하는 데 오래 걸린다.
이 레지스터들은 특권 명령(Privileged Instruction) 으로만 로드할 수 있어, 일반 사용자 프로세스가 임의로 변경할 수 없다.
주소 바인딩(Address Binding)
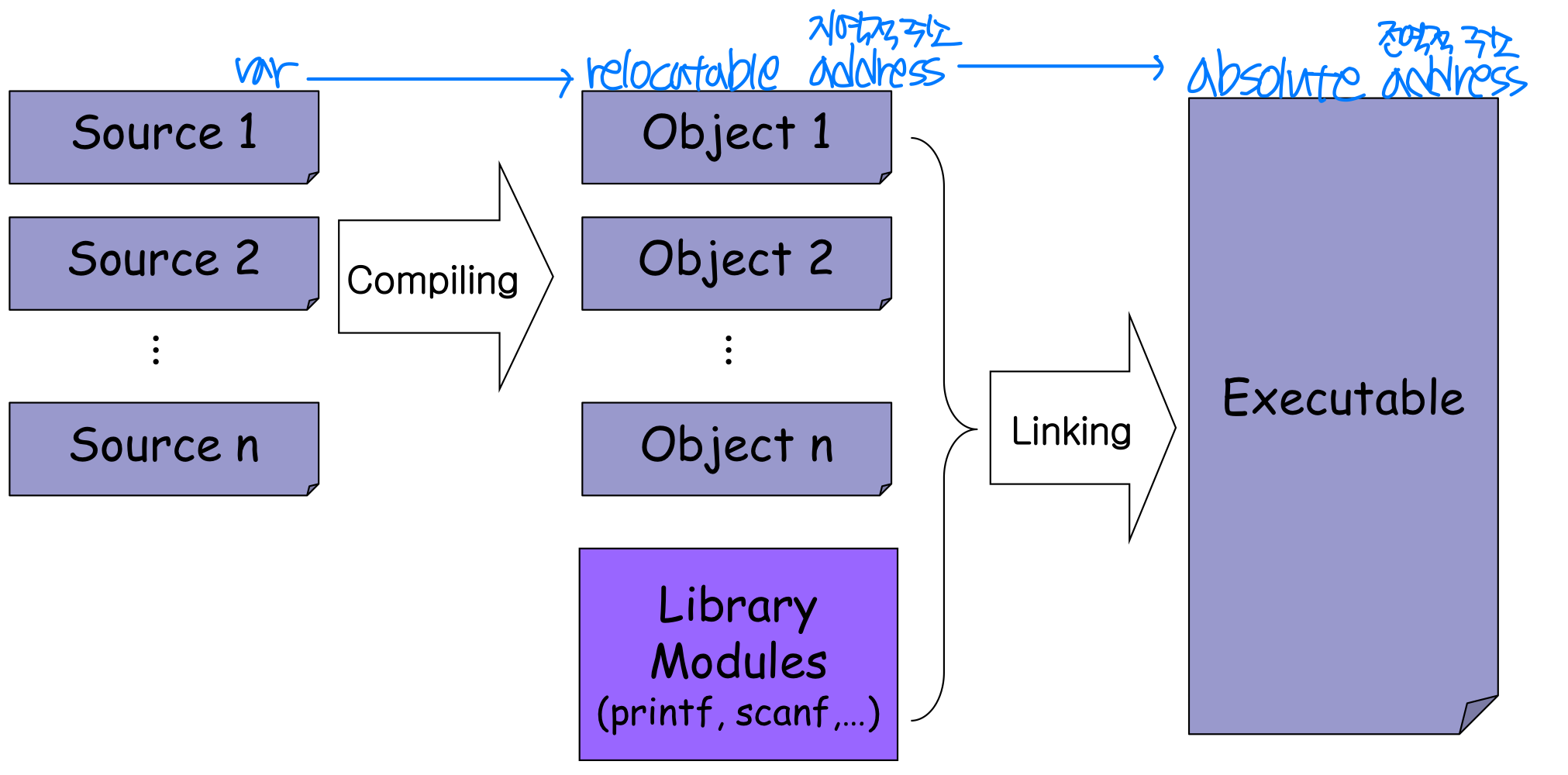
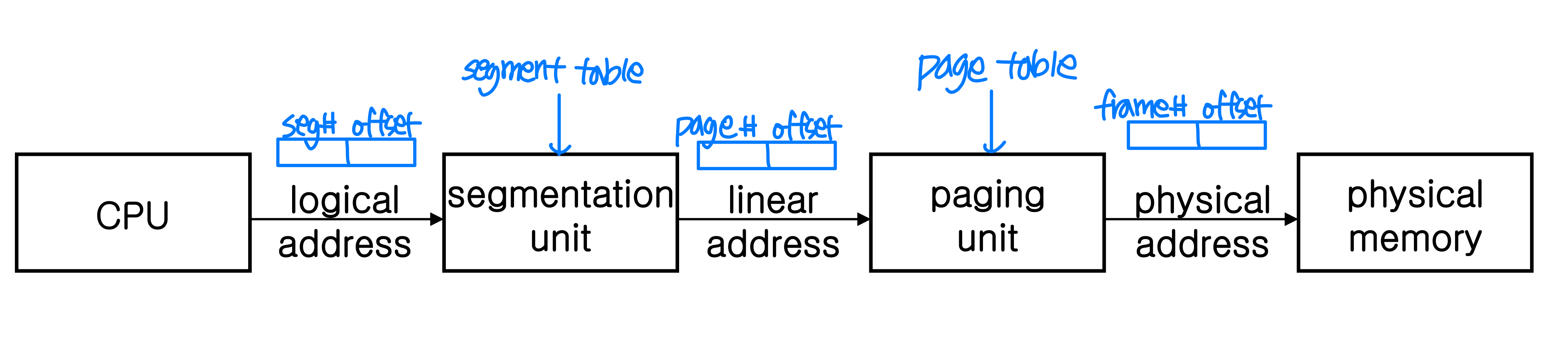
대부분의 시스템은 사용자 프로세스가 물리 메모리의 어느 위치에든 적재될 수 있도록 허용한다. 프로그램이 작성되어 실행되기까지, 주소는 여러 단계에 걸쳐 변환된다.
주소 표현의 변환 과정:
- 소스 프로그램: 심볼릭 주소(Symbolic Address) 를 사용한다. 예를 들어 변수명
count나 함수명이 이에 해당한다. - 컴파일러: 심볼을 재배치 가능 주소(Relocatable Address) 로 바인딩한다. "모듈 시작으로부터 14바이트" 같은 지역적 주소다.
- 링커 또는 로더: 재배치 가능 주소를 절대 주소(Absolute Address) 로 바인딩한다.
0x74014같은 전역적, 절대적 주소다.
주소 바인딩(Address Binding) 이란 이처럼 하나의 주소 공간을 다른 주소 공간으로 매핑하는 과정이며, 여기서는 최종 바인딩을 의미한다.
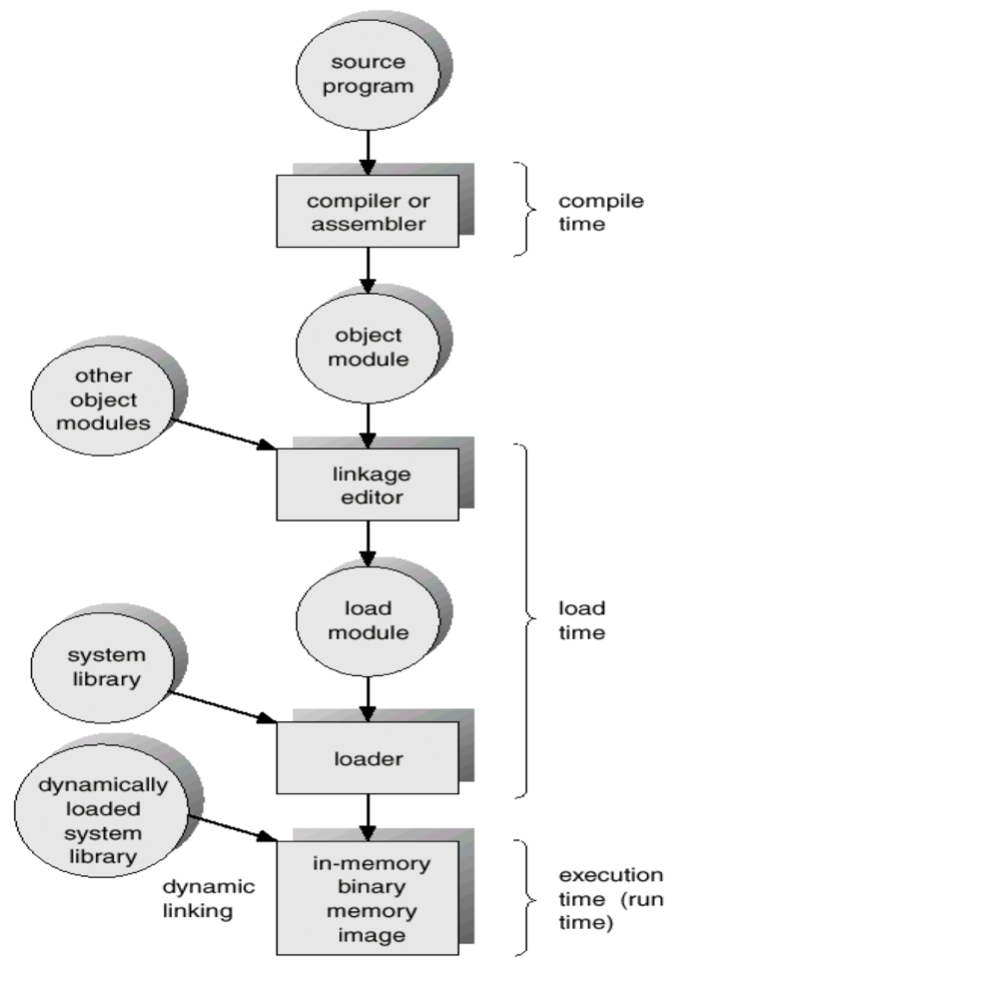
프로그램은 컴파일(Compile) -> 링킹(Linking) -> 로딩(Loading) -> 실행(Execution) 단계를 거친다. OS에 따라 링킹과 로딩을 하나의 단계로 보기도 한다.
주소 바인딩 시점에 따라 세 가지로 나뉜다.
- 컴파일 타임(Compile Time): 절대 코드(Absolute Code) 를 생성한다. 시작 위치가 바뀌면 프로그램을 다시 컴파일해야 한다. MS-DOS의
.com파일이 대표적인 예다. - 로드 타임(Load Time): 재배치 가능 코드를 생성한다. 시작 위치가 바뀌면 다시 로드해야 한다.
- 실행 타임(Execution Time): 대부분의 범용 OS가 사용하는 방식으로, 논리 주소 지정을 지원하는 시스템에서 사용된다. 주소 매핑을 위한 하드웨어 지원이 필요하다.
논리 주소와 물리 주소
- 논리 주소(Logical Address): CPU가 생성하는 주소로, 프로세스 내부에서 사용된다.
- 물리 주소(Physical Address): 메모리 장치가 실제로 인식하는 전역적 주소다.
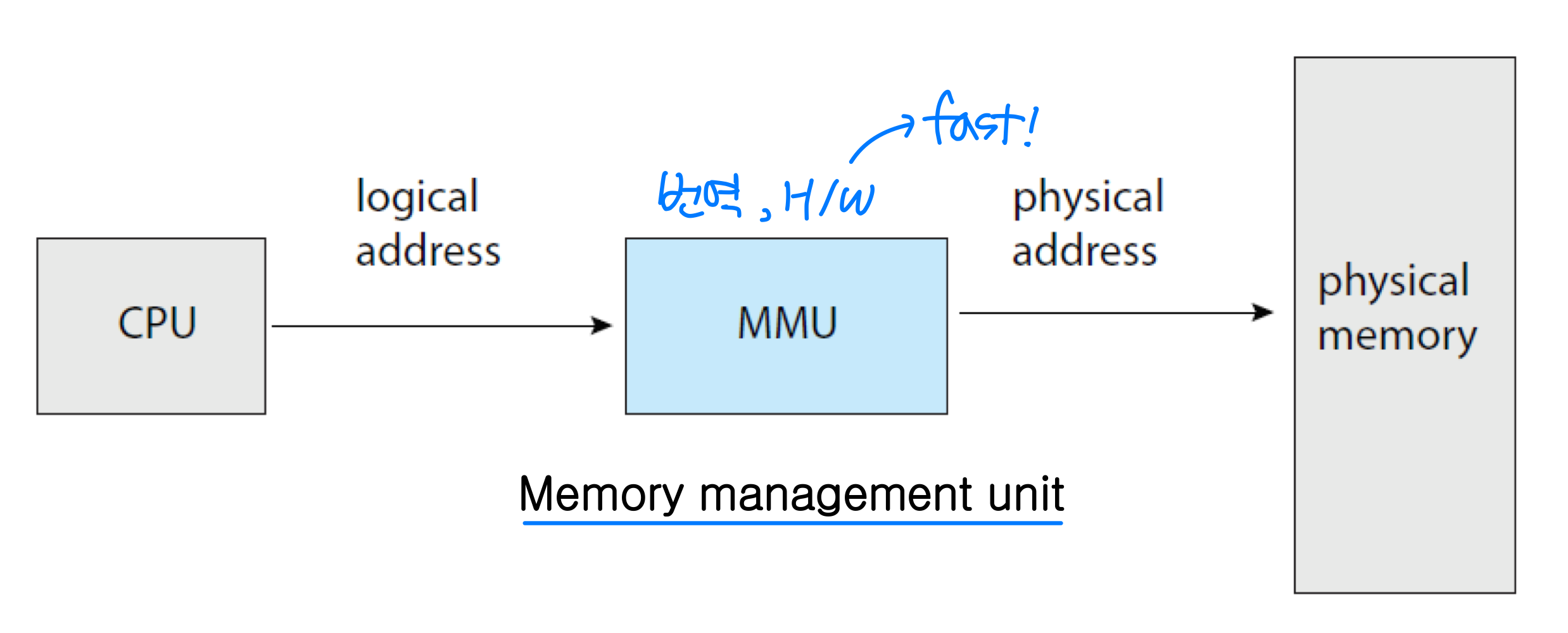
바인딩 시점에 따라 두 주소의 관계가 달라진다.
- 컴파일 타임/로드 타임 바인딩: 논리 주소 = 물리 주소
- 실행 타임 바인딩: 논리(가상) 주소 물리 주소
관련 용어를 정리하면 다음과 같다.
- 논리 주소 공간(Logical Address Space): 프로그램이 생성하는 모든 논리 주소의 집합
- 물리 주소 공간(Physical Address Space): 논리 주소에 대응하는 모든 물리 주소의 집합
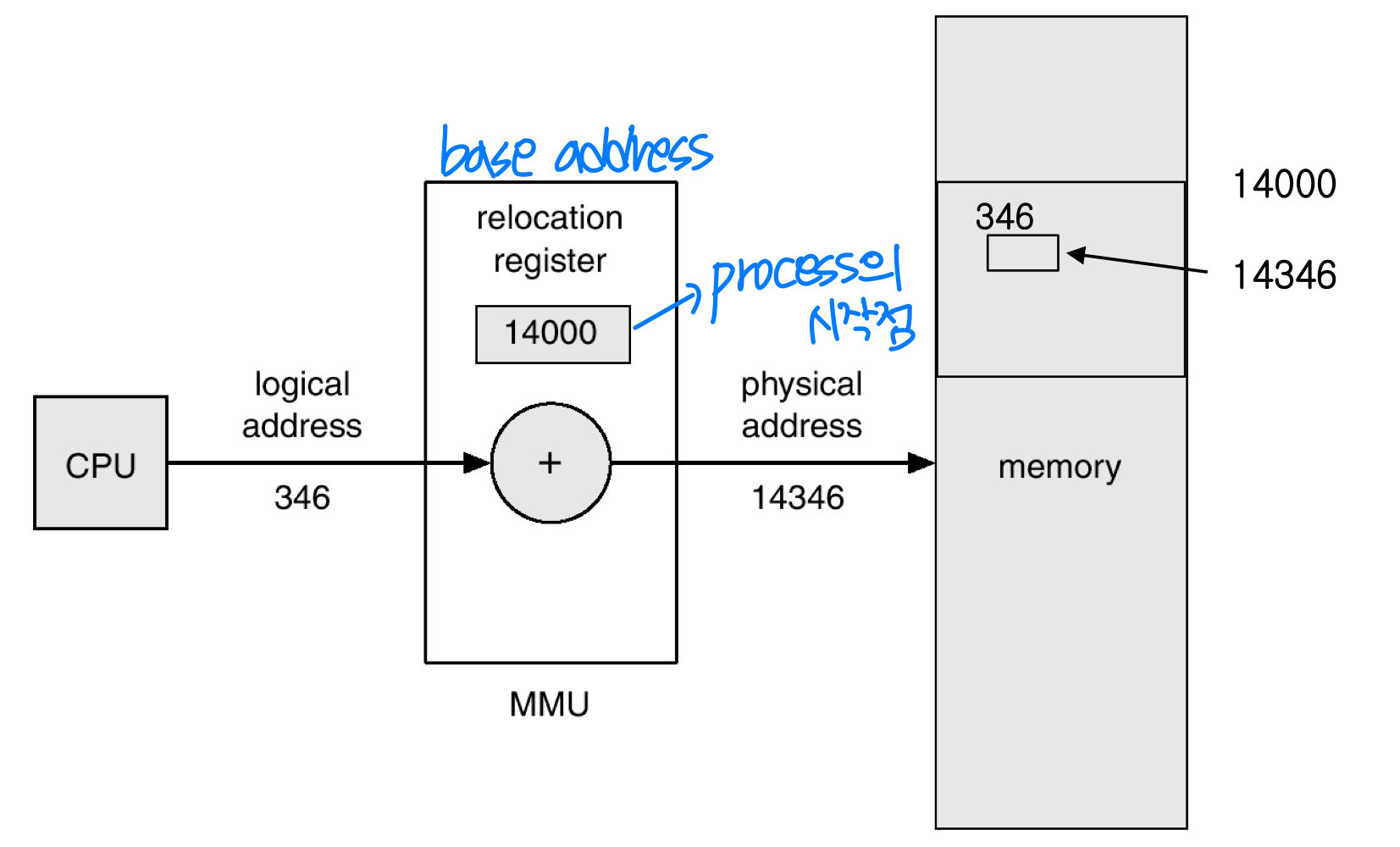
실행 시간의 주소 매핑은 MMU(Memory-Management Unit) 가 담당한다. 가장 단순한 방법은 재배치 레지스터(Relocation Register, = Base Register) 를 사용하는 것이다. 사용자 프로그램은 물리 주소를 직접 볼 수 없다. 프로세스별로 메모리 영역이 다르고 독립적이기 때문이다.
동적 링킹과 공유 라이브러리
정적 링킹(Static Linking) 은 모든 오브젝트 모듈을 하나의 바이너리 프로그램 이미지로 결합하는 방식이다. 반면 동적 링킹(Dynamic Linking) 은 링킹을 실행 시점까지 연기하여, 불필요한 중복을 방지하고 효율성을 높인다. 시스템 라이브러리가 대표적인 예다.
동적 링킹에서는 스텁(Stub) 이라는 작은 코드 조각을 사용한다. 스텁은 실제 라이브러리 루틴의 본체 대신 링크되어 있다가, 필요할 때 라이브러리를 로드하고 링크한다. 구체적으로 스텁은 다음 역할을 한다.
- 적절한 라이브러리 루틴의 위치를 찾는 방법
- 라이브러리가 준비되지 않았을 때 로드하는 방법
라이브러리 루틴이 동적으로 링크되면, 스텁은 자신을 해당 루틴의 주소로 대체하고 그 루틴을 직접 실행한다.
동적 링킹의 장점:
- 라이브러리 코드를 프로세스 간에 공유할 수 있다. 여러 버전의 라이브러리가 공존할 수도 있다.
- 라이브러리를 업데이트해도 다시 링킹할 필요가 없다.
동적 링킹은 공유 라이브러리를 사용하므로, 다시 로드되지 않고 공유된다는 점에 주의해야 한다. 또한 동적 링킹은 OS의 도움이 필요하다.
스와핑(Swapping)
프로세스가 실행되려면 메모리에 적재되어야 한다. 하지만 메모리가 부족할 때는 프로세스를 일시적으로 보조 저장장치(Backing Store) 로 내보내고, 다시 메모리로 불러올 수 있다. 이를 스와핑(Swapping) 이라 한다.
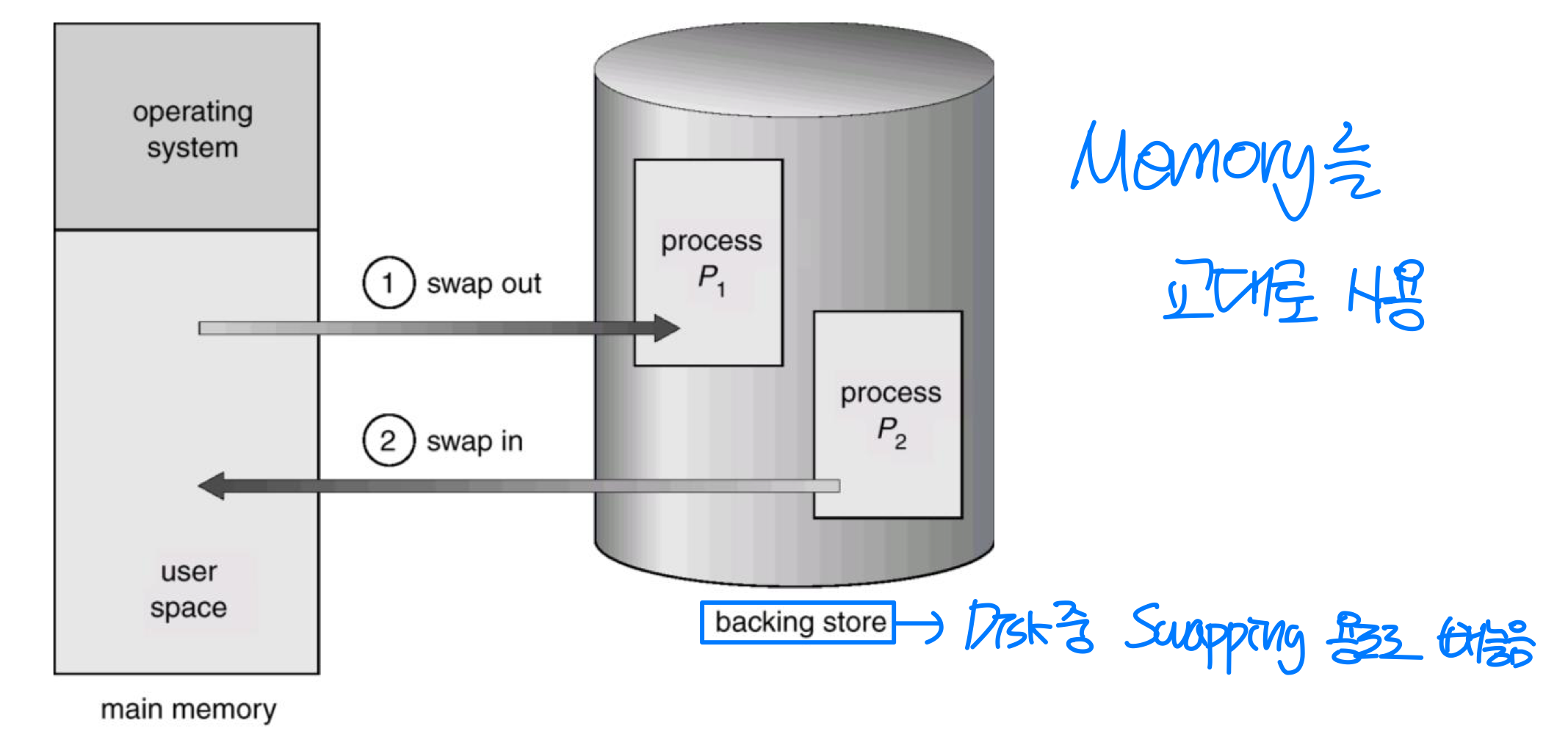
스왑 아웃된 프로세스는 기본적으로 이전에 점유했던 동일한 메모리 공간에 다시 스왑 인된다. 단, 실행 타임 바인딩을 사용하는 경우에는 MMU의 재배치 레지스터만 바꿔주면 되므로 다른 위치에 적재될 수 있다.
보조 저장장치(Backing Store) 는 빠른 디스크로, 보통 파일 시스템과는 별도의 파티션에 위치한다. 모든 사용자의 메모리 이미지 사본을 수용할 만큼 충분히 커야 하며, 메모리 이미지에 대한 직접 접근을 제공해야 한다.
디스패칭(Dispatching) 과정에서는 컨텍스트 스위칭 시 다음과 같은 일이 일어난다. 먼저 스케줄러가 선택한 프로세스가 메모리에 있는지 확인한다. 메모리에 없다면, 기존 프로세스를 스왑 아웃하고 원하는 프로세스를 스왑 인한다.
스와핑 시스템의 컨텍스트 스위치 시간
프로세스 크기가 100 MB이고, 디스크 전송률이 50 MB/s, 평균 지연이 8 ms인 경우를 생각해보자.
스와핑 시간 = (100 MB / 50 MB/s + 8 ms) x 2 (스왑 아웃 + 스왑 인) = 4,016 ms
일반적으로 SSD는 HDD보다 10~30배 빠르지만, 그래도 상당한 시간이 걸린다. 스와핑 시간은 실제 사용 중인 메모리 양에 비례하므로, 프로세스 전체가 아닌 실제 사용 부분만 스왑하면 시간을 줄일 수 있다.
중요한 점은 타임 슬라이스(Time Slice)가 스왑 시간보다 충분히 길어야 한다는 것이다. 스왑 시간이 타임 슬라이스보다 길면 CPU는 놀고 디스크만 계속 돌게 된다.
대부분의 시스템은 수정된 형태의 스와핑을 사용한다. 메모리 사용량이 특정 임계값을 초과했을 때에만 스와핑을 활성화하는 방식이다.
연속 메모리 할당(Contiguous Memory Allocation)
연속 메모리 할당에서는 각 프로세스에게 하나의 연속된 메모리 블록을 할당한다.
메모리는 보통 두 영역으로 나뉜다.
- 상주 OS 영역: 인터럽트 벡터와 함께 높은(혹은 낮은) 주소에 위치
- 사용자 프로세스 영역: 나머지 메모리
여러 사용자 프로세스가 동시에 메모리에 존재할 수 있다. 그렇다면 입력 큐에서 대기 중인 프로세스들에게 메모리를 어떻게 할당할 것인가?
메모리 매핑과 보호
메모리 매핑과 보호는 재배치 레지스터(Relocation Register) 와 리밋 레지스터(Limit Register) 가 제공한다. 메모리 접근 시 MMU가 논리 주소를 동적으로 매핑하며, 컨텍스트 스위칭 때 디스패처가 이 레지스터들을 올바르게 로드한다.
메모리 할당 정책
가변 분할 방식(Variable Partition Scheme, MVT) 은 대표적인 메모리 할당 정책이다. MVT는 Multiprogramming with a Variable number of Tasks의 약자다.
동작 방식은 다음과 같다.
- 처음에는 모든 가용 메모리가 하나의 큰 빈 블록(홀, Hole)을 형성한다.
- 프로세스가 도착하면, 그 프로세스를 수용할 수 있는 충분히 큰 홀을 찾는다.
- 프로세스가 종료되면 메모리를 반환하며, 인접한 홀끼리 병합할 수 있다.
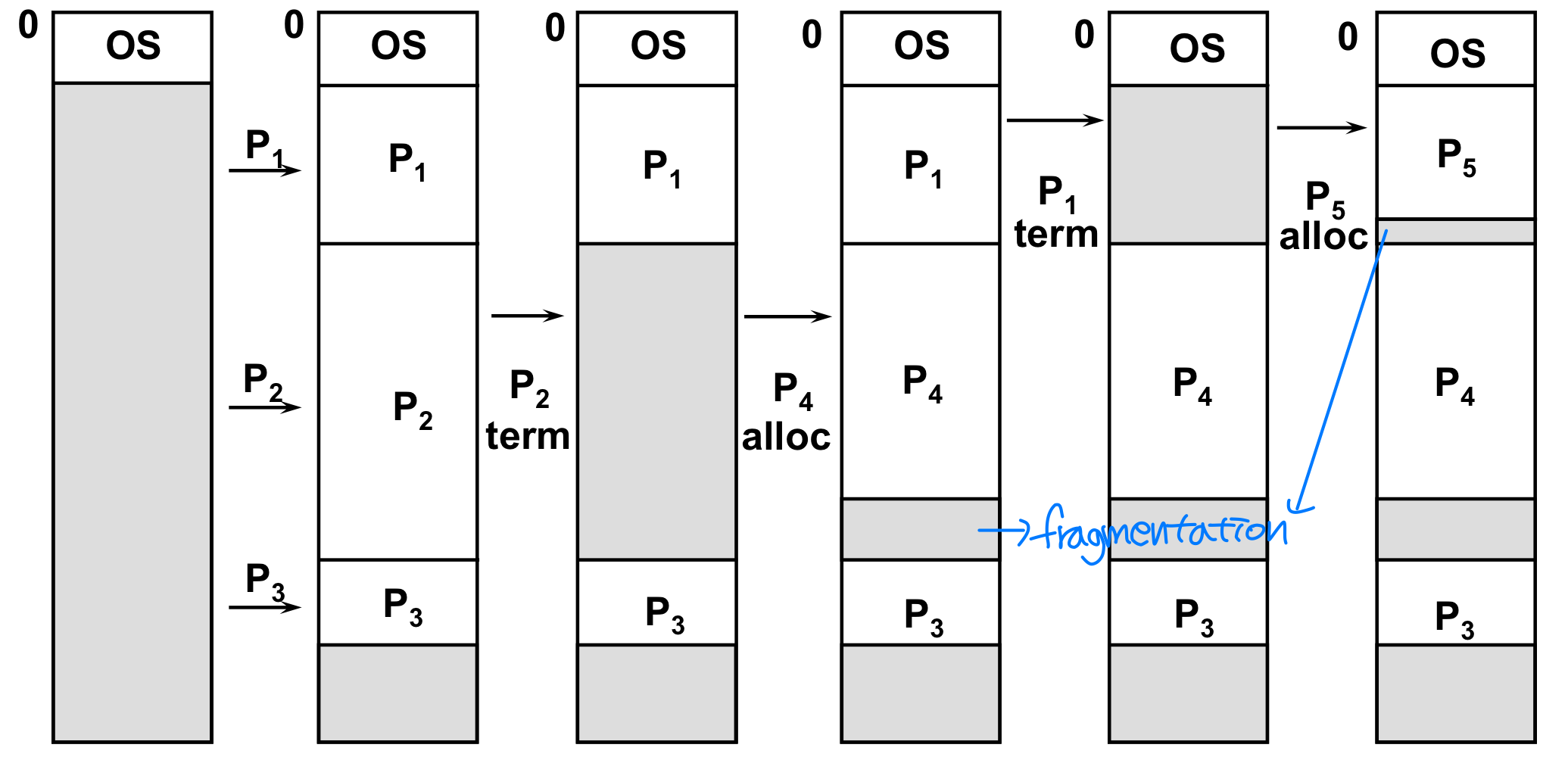
단편화(Fragmentation)
연속 메모리 할당에서 가장 큰 문제는 단편화(Fragmentation) 다.
외부 단편화(External Fragmentation)
빈 메모리 공간이 작은 조각들로 흩어져 있는 현상이다. 전체 빈 메모리 크기는 충분하더라도, 연속된 큰 블록을 할당하지 못하는 경우가 발생한다. 프로세스 메모리 바깥에서 발생하는 단편화다.
50% 규칙(50-Percent Rule): First Fit 분석에 따르면, N개의 할당된 블록이 있으면 약 0.5N개의 블록이 단편화로 손실된다. 전체 메모리의 약 1/3이 사용 불가할 수 있다는 의미다. 메인 메모리의 단편화는 보조 저장장치에도 영향을 미친다.
내부 단편화(Internal Fragmentation)
할당된 메모리와 실제 요청한 메모리의 차이다. 예를 들어 18,464바이트 크기의 홀에서 18,462바이트를 요구하는 프로세스에 할당하면, 남은 2바이트가 내부 단편화가 된다. 이처럼 작은 홀을 관리하는 오버헤드를 줄이기 위해, 물리 메모리를 고정 크기 블록으로 나누는 것이 일반적이다.
단편화의 해결
압축(Compaction) 은 외부 단편화의 해결 방법이다. 사용 중인 메모리를 한쪽으로 모아 큰 빈 블록을 만드는 방식이지만, 실행 타임에 동적 재배치가 가능한 경우에만 사용할 수 있고 비용이 비싸다.
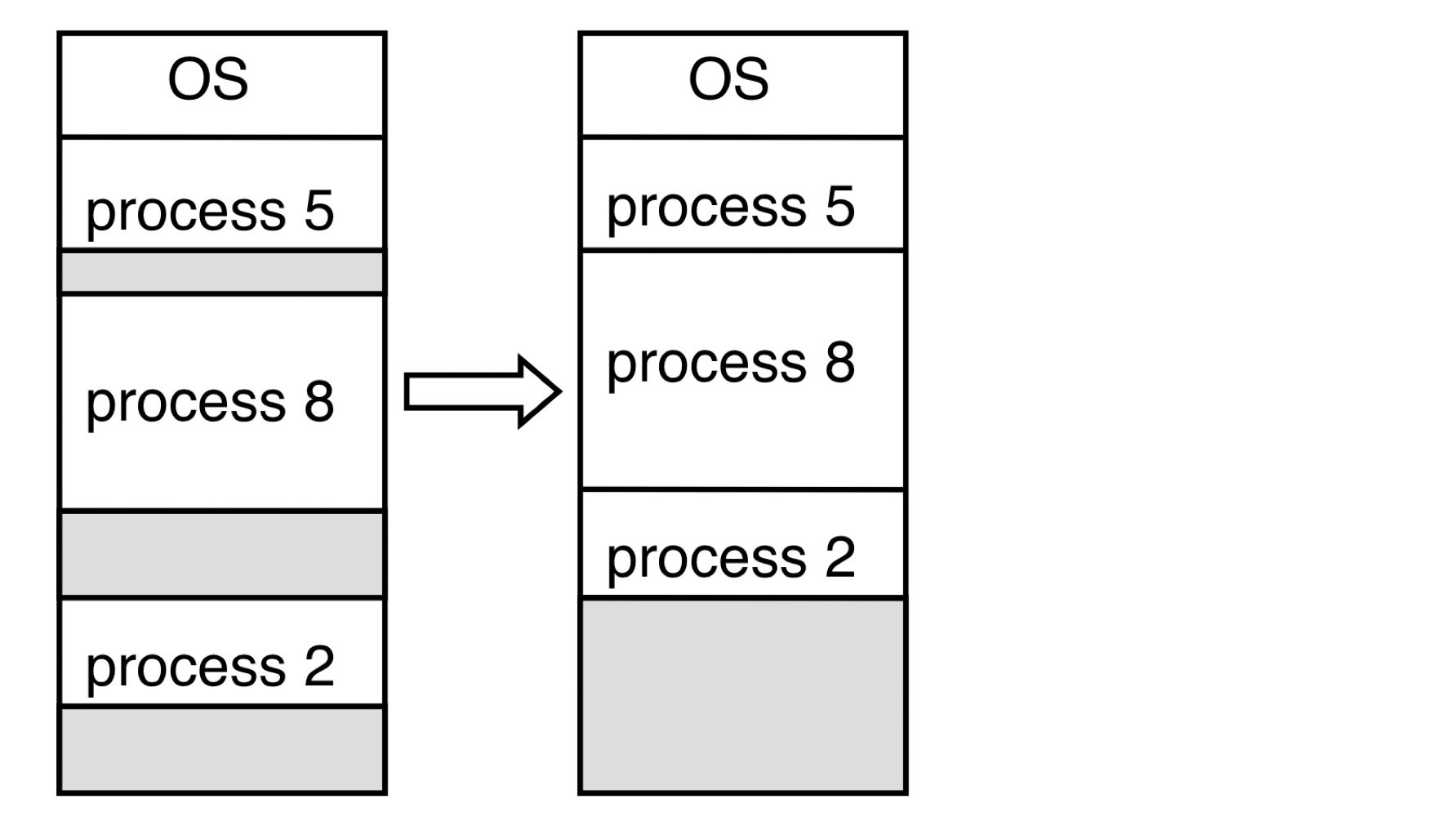
더 나은 대안은 논리 주소 공간을 비연속적으로 허용하는 것이다.
- 페이징(Paging): 메모리를 일정한 단위로 쪼갠다. 외부 단편화를 해결하지만, 내부 단편화가 발생한다.
- 세그멘테이션(Segmentation): 가변 크기 단위로 분할한다.
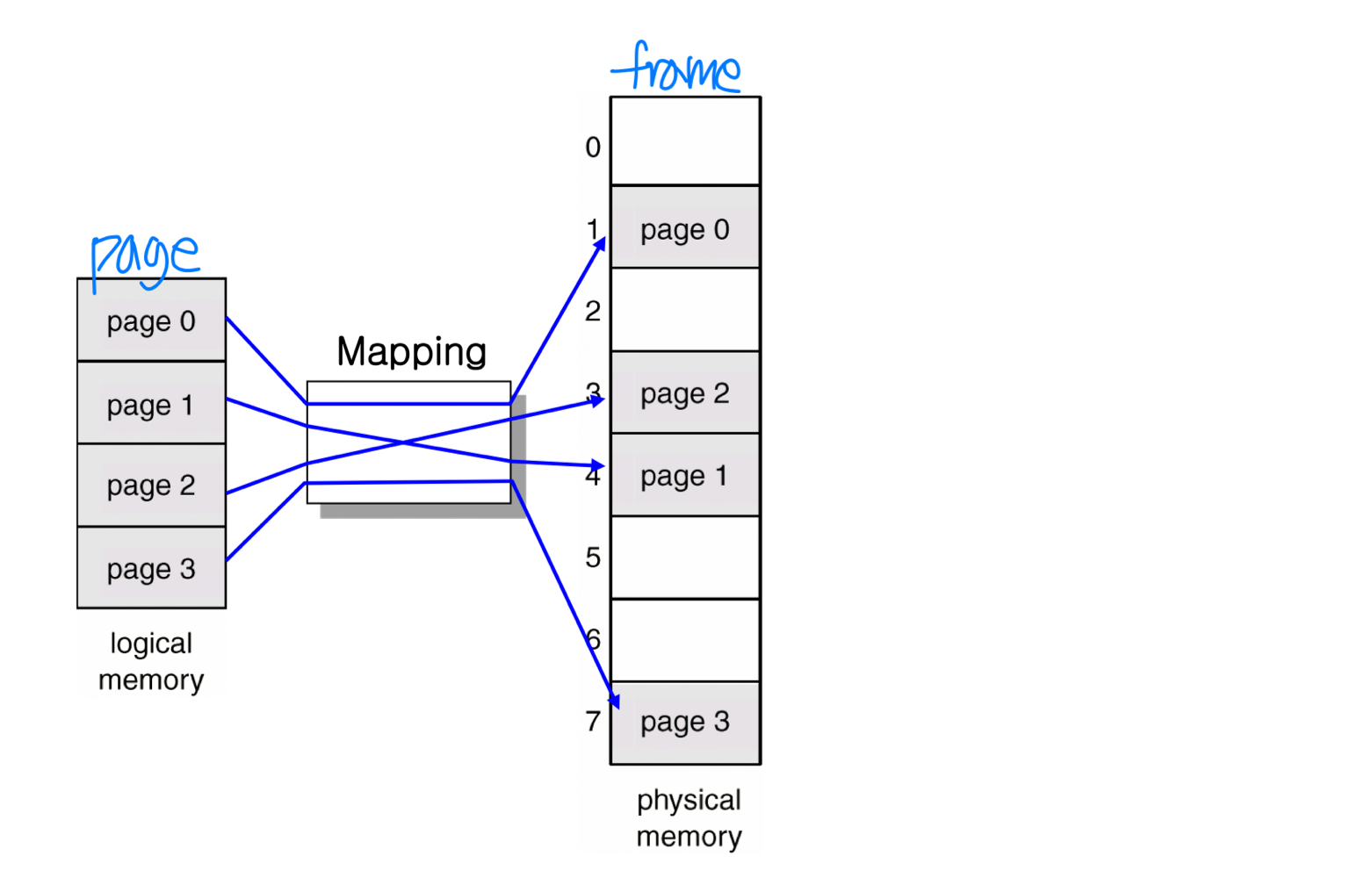
페이징(Paging)
페이징은 프로세스의 물리 주소 공간이 비연속적(Noncontiguous) 일 수 있도록 하는 메모리 관리 기법이다.
핵심 개념은 다음과 같다.
- 물리 메모리: 프레임(Frame) 이라는 고정 크기 블록으로 구성된다. 물리적 위치를 나타낸다.
- 논리 메모리: 페이지(Page) 라는 고정 크기 블록으로 구성된다. 메모리 내용을 담는다.
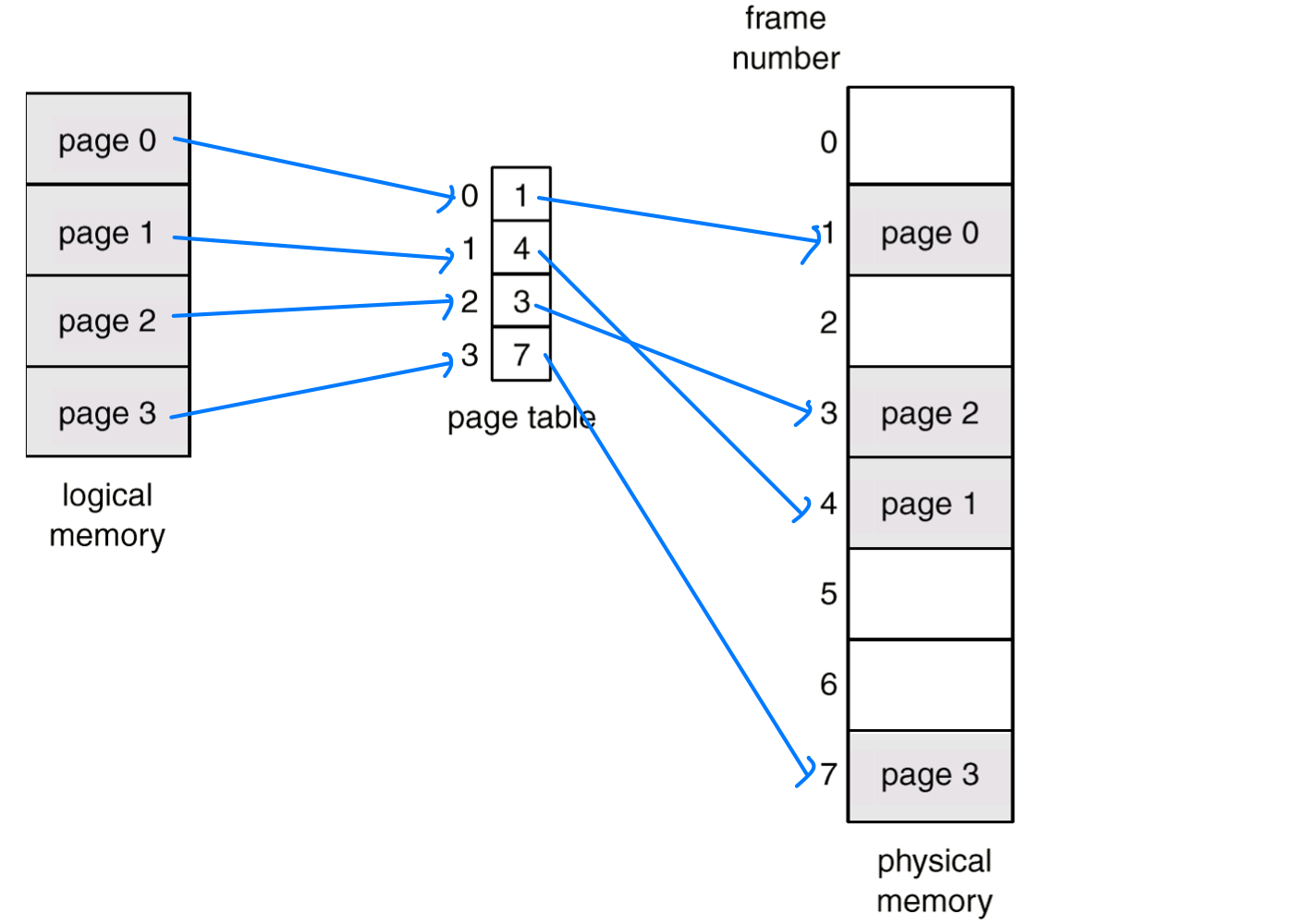
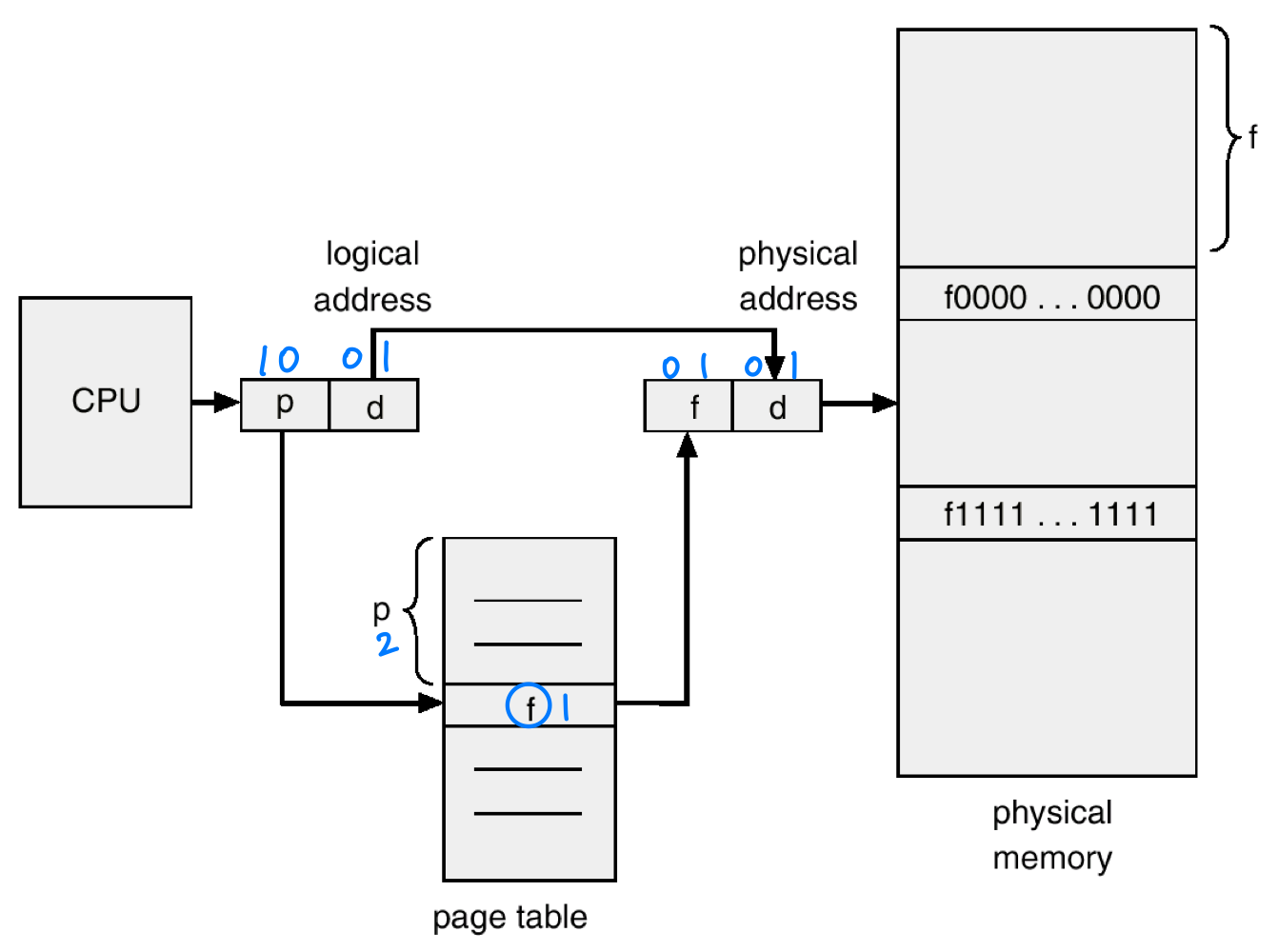
- 페이지와 프레임의 매핑은 페이지 테이블(Page Table) 을 통해 이루어진다.
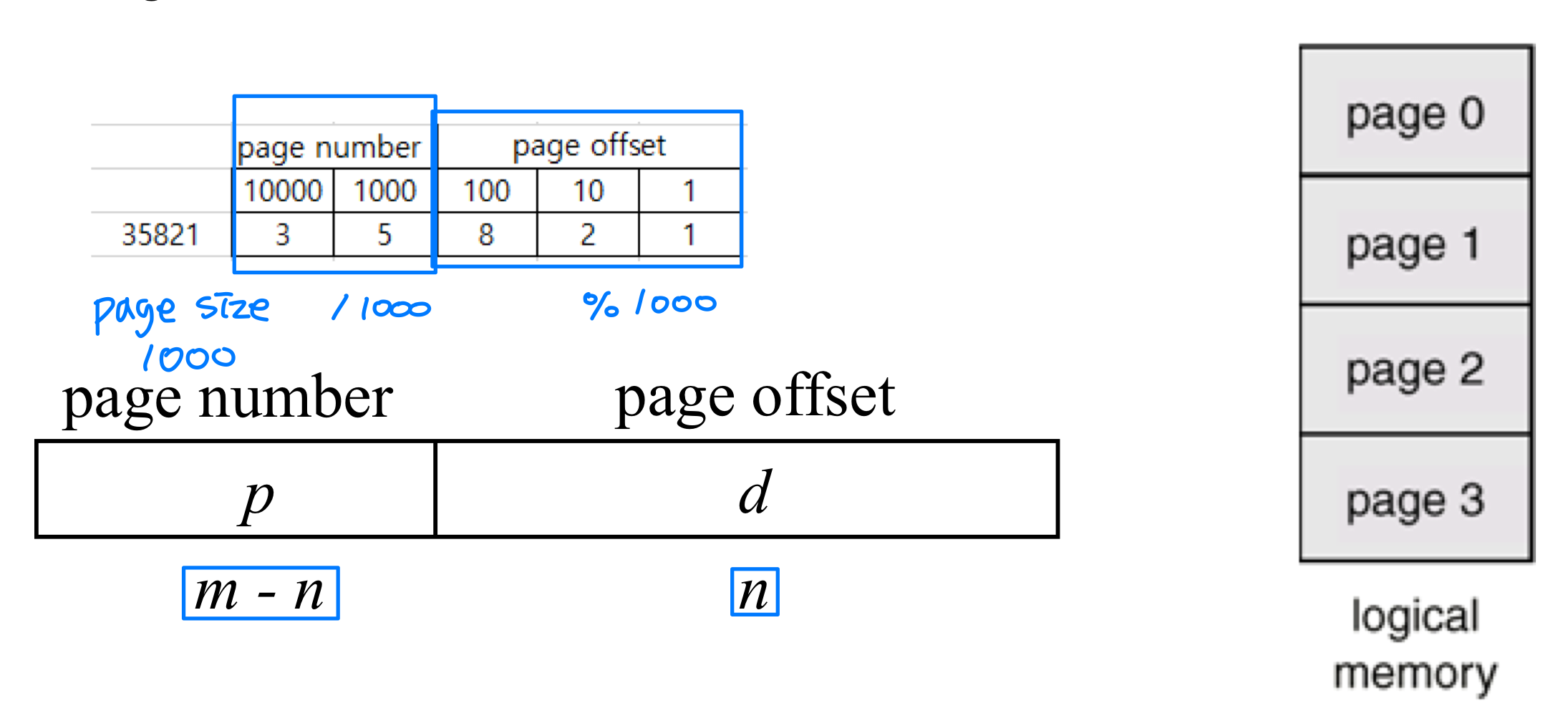
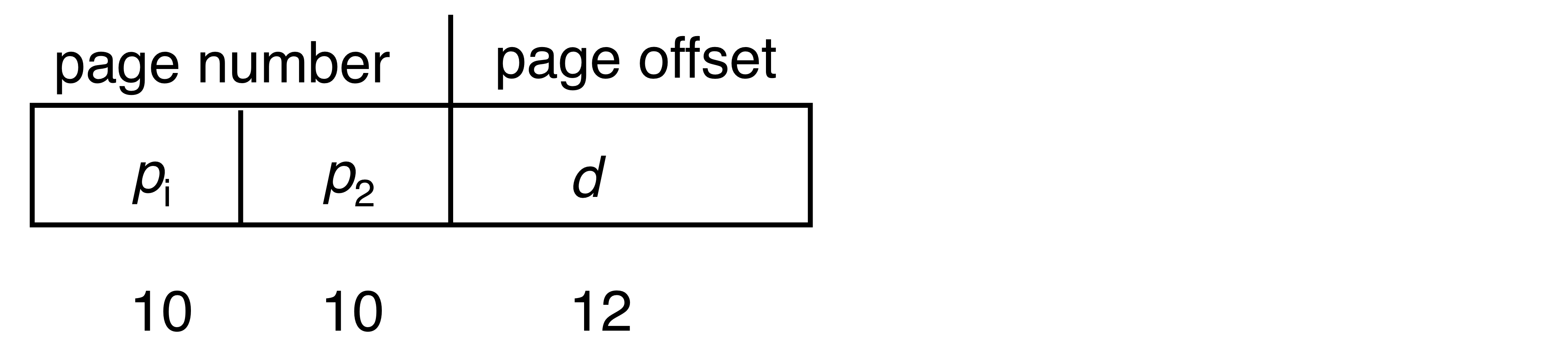
논리 주소의 구조
논리 주소는 페이지 번호(Page Number) 와 페이지 오프셋(Page Offset) 으로 구성된다. 오프셋은 페이지 내에서의 상대적 위치를 나타낸다.
- 논리 주소 공간의 크기:
- 페이지 크기: (예: 256바이트이면 오프셋은 8비트)
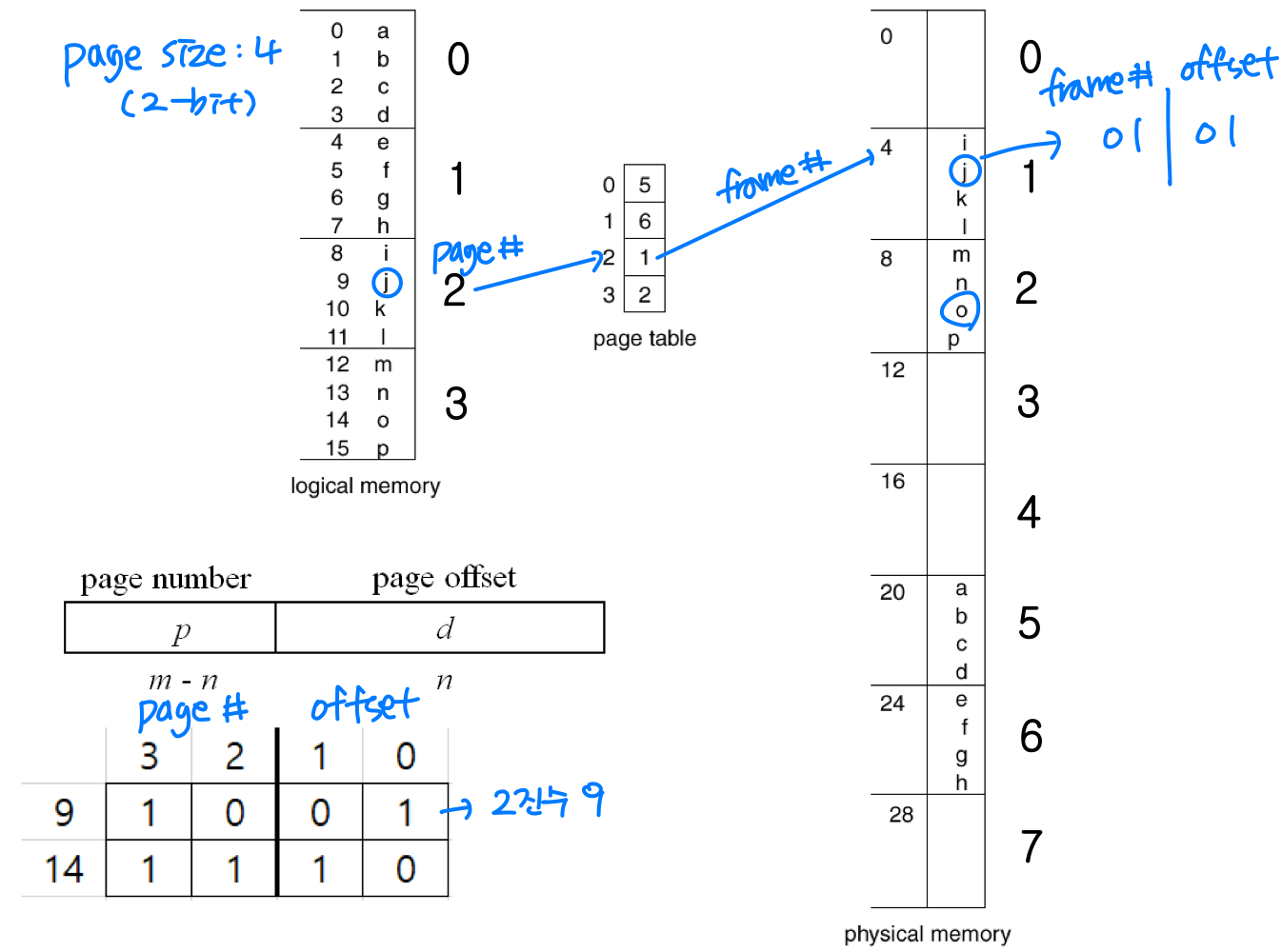
페이징의 오버헤드
페이징에는 두 가지 오버헤드가 존재한다.
- 페이지 테이블 접근: 페이지 테이블은 메모리에 있고 크기가 상당히 크기 때문에, 물리 메모리에 접근하기 전에 테이블을 먼저 조회해야 한다. 결과적으로 메모리 접근이 2번 필요하다.
- 내부 단편화: 평균적으로 프로세스당 반 페이지의 내부 단편화가 발생한다. 하지만 페이징에는 외부 단편화가 없으므로, 내부 단편화가 발생하더라도 더 나은 선택이다.
실제 시스템에서의 페이지 크기와 테이블 규모를 살펴보자.
- 페이지 크기: 보통 4 KB ~ 4 MB
- 4 KB = 바이트 -> 오프셋 12비트, 페이지 번호 20비트 -> 페이지 테이블 엔트리 약 = 1,000,000개
- 4 MB = 바이트 -> 오프셋 22비트, 페이지 번호 10비트 -> 페이지 테이블 엔트리 = 1,024개
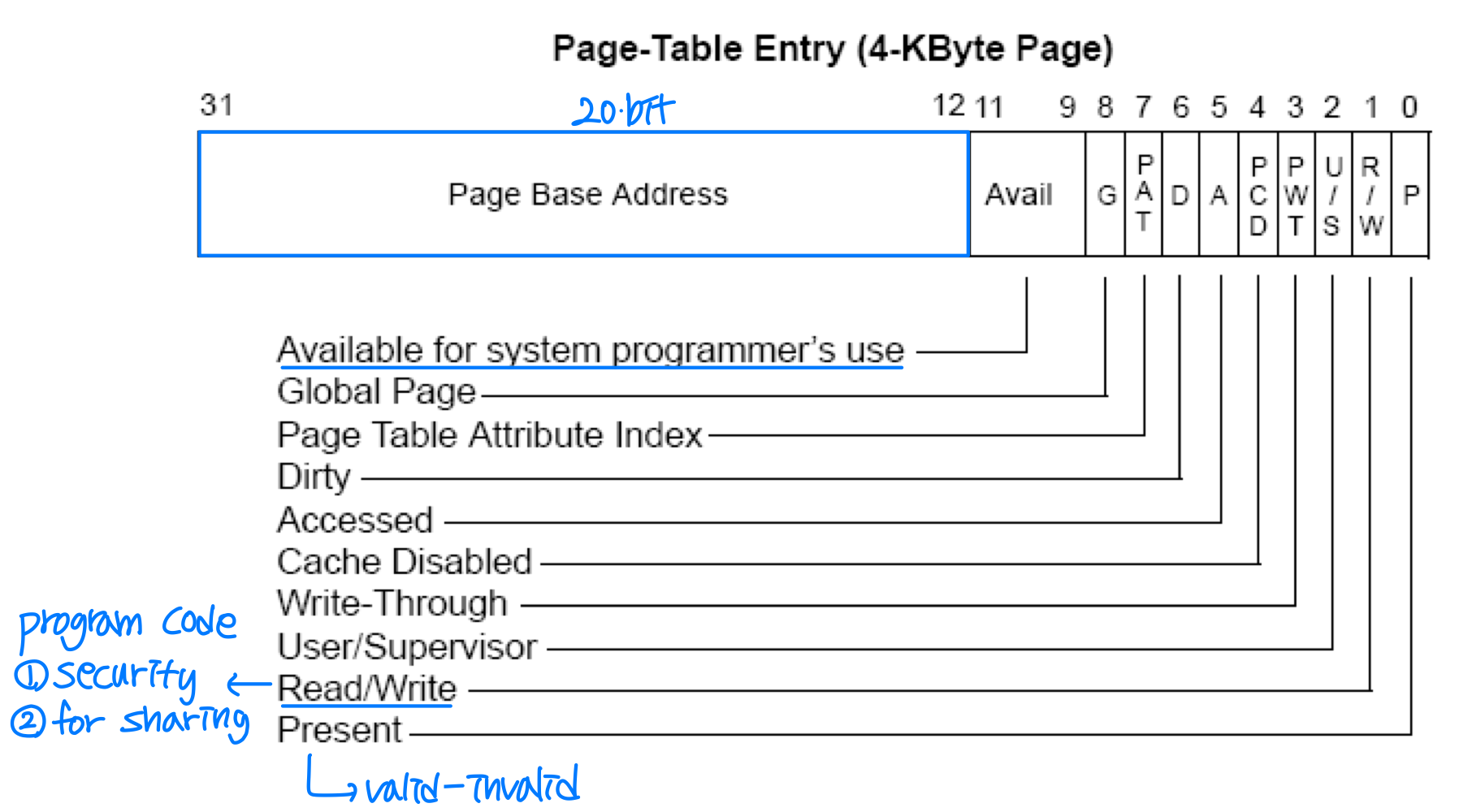
- 페이지 테이블 엔트리 크기: 4바이트(32비트) -> 20비트(프레임 번호) + 12비트(속성 플래그)
x86 페이지 테이블 엔트리
프레임 테이블(Frame Table)
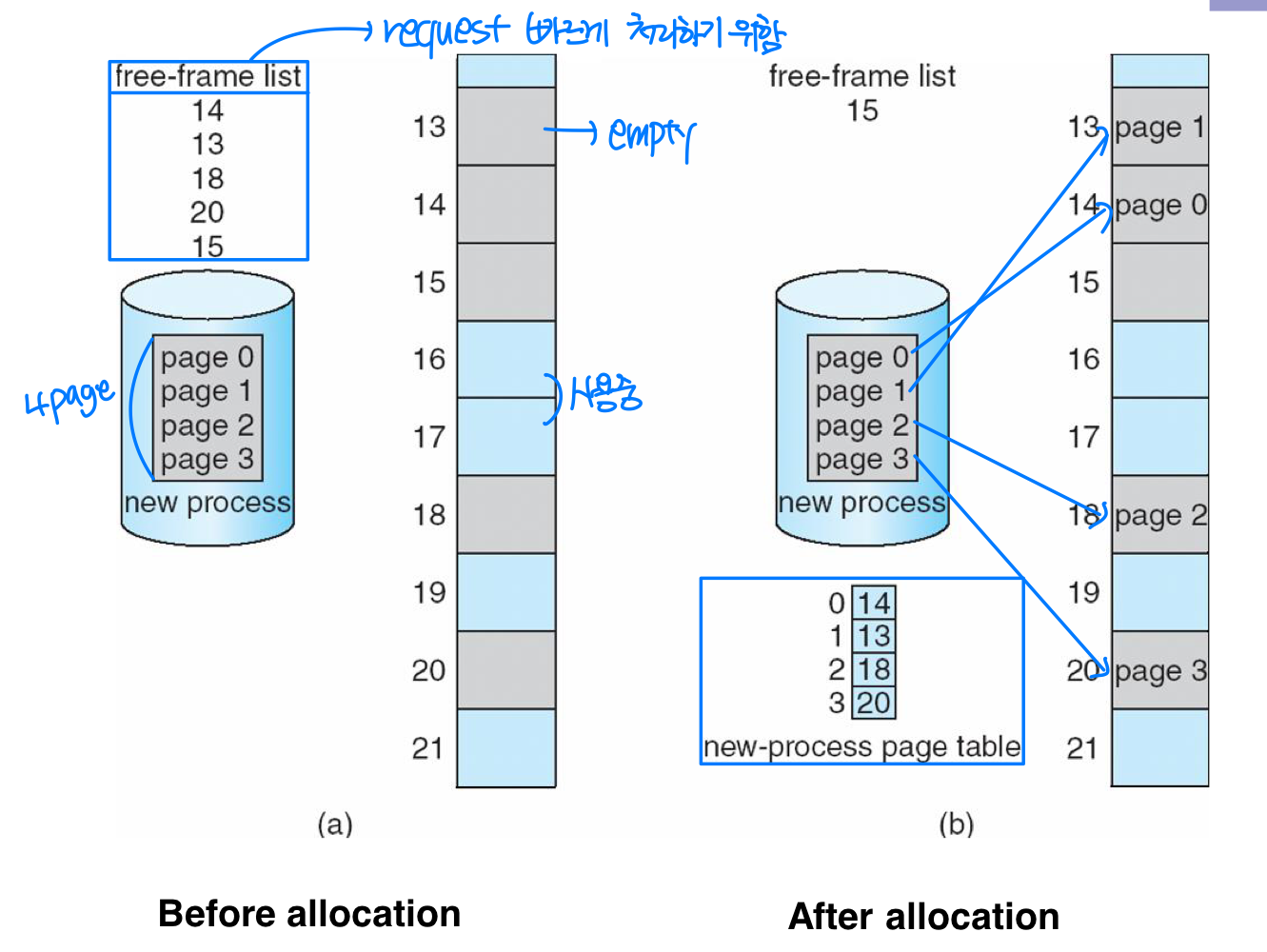
OS는 프레임 테이블(Frame Table) 에 프레임 정보를 관리한다.
- 전체 프레임 수
- 어떤 프레임이 할당되었는지
- 어떤 프레임이 가용한지
OS는 빈 프레임 목록(Free Frame List) 도 함께 유지한다.
하드웨어 지원
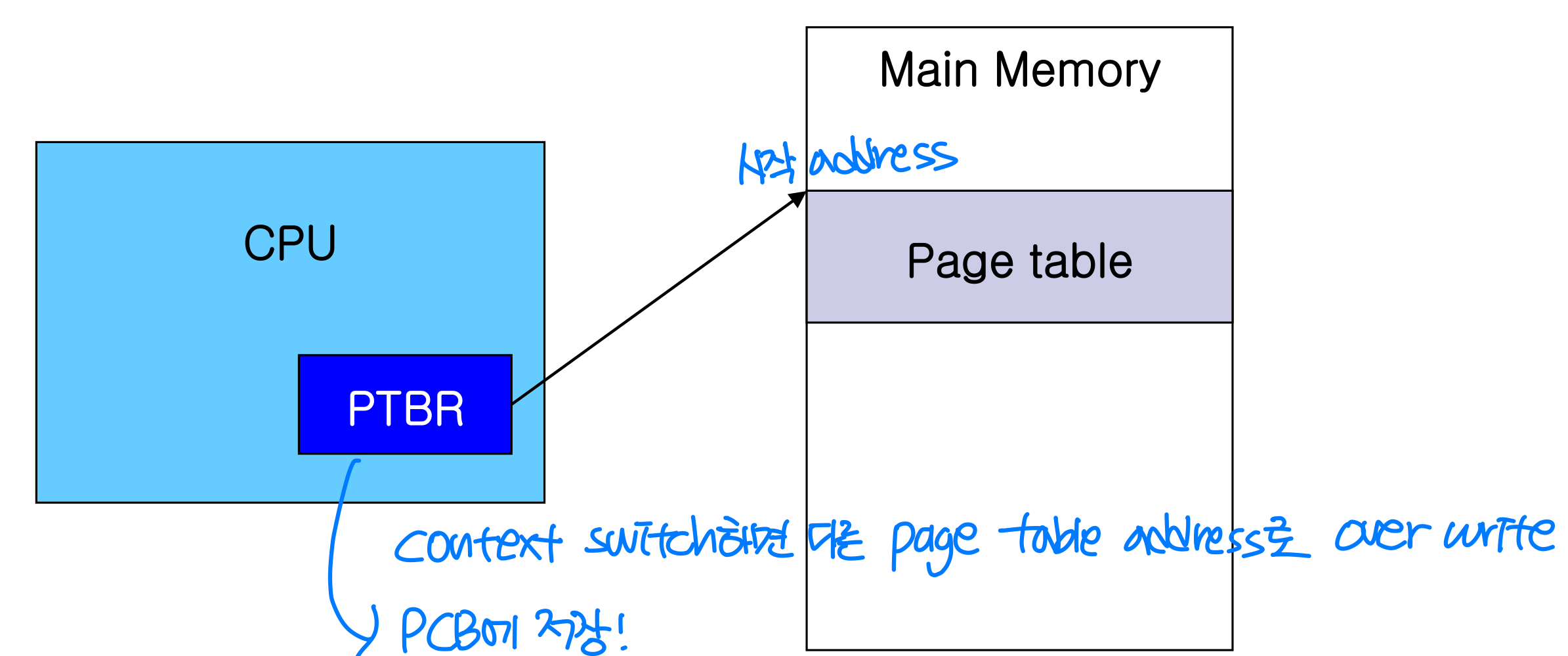
대부분의 OS는 각 프로세스에 페이지 테이블을 할당한다. 페이지 테이블에 대한 포인터는 PTBR(Page-Table Base Register) 값과 함께 PCB(Process Control Block) 에 저장된다. 컨텍스트 스위칭 시 디스패처가 올바른 하드웨어 페이지 테이블도 함께 로드한다.
하드웨어로 페이지 테이블을 구현하는 가장 단순한 방법은 전용 레지스터 집합을 사용하는 것이다. 예를 들어 DEC PDP-11은 8개의 엔트리를 빠른 레지스터에 보관했다. 하지만 페이지 테이블이 크면 이 방법은 현실적이지 않다.
PTBR(Page-Table Base Register) 방식에서는 페이지 테이블을 메인 메모리에 저장하고, PTBR이 그 시작 주소를 가리킨다. x86에서는 CR3 레지스터가 이 역할을 한다. 문제는 하나의 바이트에 접근하기 위해 메모리 접근이 2번 필요하다는 것이다.
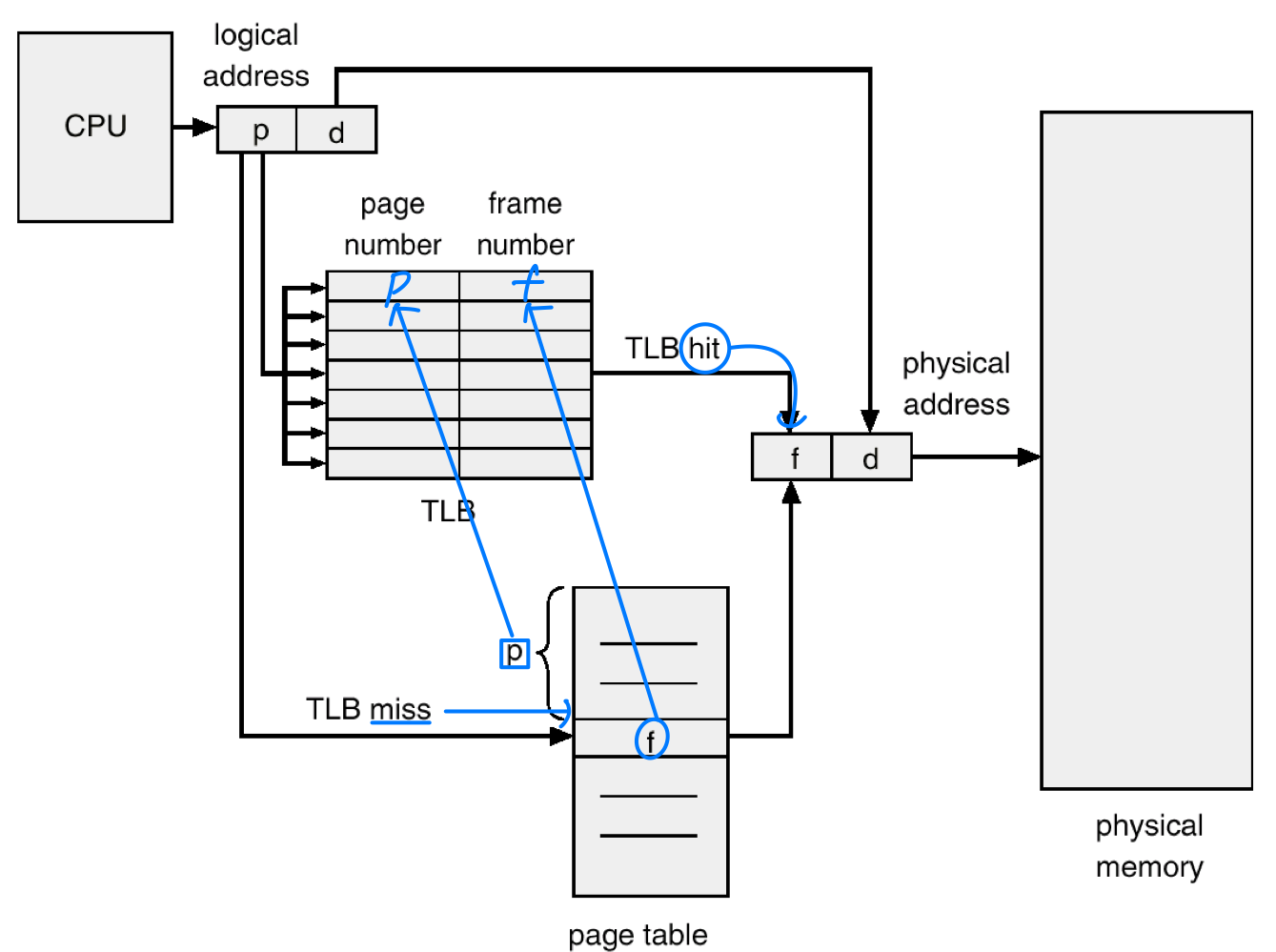
TLB (Translation Look-aside Buffer)
메모리 2번 접근 문제를 해결하기 위해 TLB(Translation Look-aside Buffer) 를 사용한다. TLB는 주소 변환을 위한 소형 고속 하드웨어 캐시다.
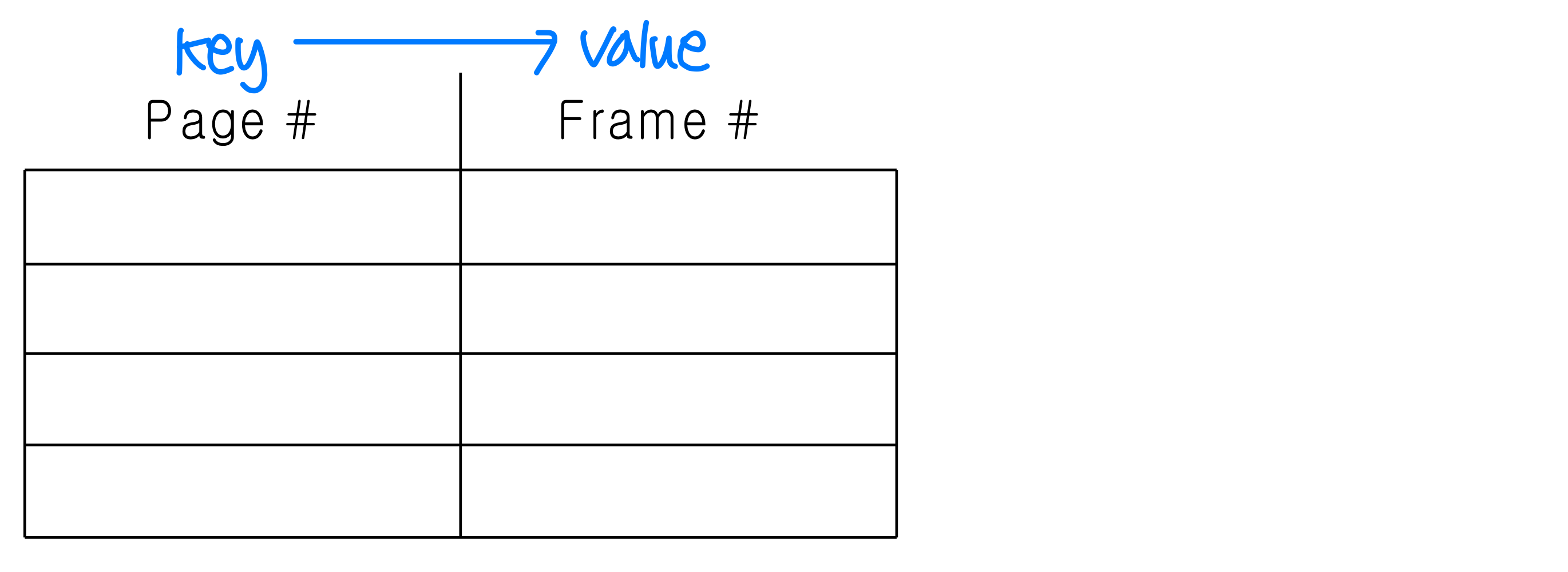
TLB는 연관 메모리(Associative Memory) 로, (key: 페이지 번호, value: 프레임 번호) 쌍으로 구성된다.
- TLB 히트: 논리 주소의 페이지 번호가 TLB에 있으면, 매핑되지 않은 메모리 접근 대비 10% 이하의 지연만 발생한다.
- TLB 미스: TLB에 없으면 메인 메모리의 페이지 테이블에서 조회한 뒤, 해당
(페이지 번호, 프레임 번호)쌍을 TLB에 삽입한다. TLB가 가득 차면 OS가 교체 대상을 선정한다.
일부 TLB는 각 엔트리에 ASID(Address-Space Identifier) 를 저장한다 (예: MIPS). 컨텍스트 스위치 시 페이지 테이블이 교체되면 TLB 내용도 의미가 없어지는데, ASID를 사용하면 프로세스를 구분할 수 있으므로 TLB를 비우지 않아도 된다. 엔트리는 페이지 번호 + 프레임 번호 + ASID로 구성된다. ASID가 없는 프로세서(예: x86)는 프로세스 전환 시 TLB 전체를 플러시한다.
연관 메모리(Associative Memory)
연관 메모리는 해시처럼 동작하며, 하드웨어 수준에서 병렬 탐색을 수행한다. 소프트웨어 탐색이 아닌 하드웨어 탐색이라는 점이 핵심이다.
주소 변환 (p, d)에서 p가 연관 레지스터에 있으면 바로 프레임 번호를 얻고, 없으면 메모리의 페이지 테이블에서 프레임 번호를 가져온다.
보호(Protection)
각 프레임에는 보호 비트(Protection Bits) 가 있다.
- 읽기-쓰기(Read-Write) 또는 읽기 전용(Read-Only) 설정이 가능하다.
- 읽기 전용 페이지에 쓰기를 시도하면 하드웨어 트랩이 발생한다.
- 확장하면 읽기 전용, 읽기-쓰기, 실행 전용 등의 조합이 가능하다.
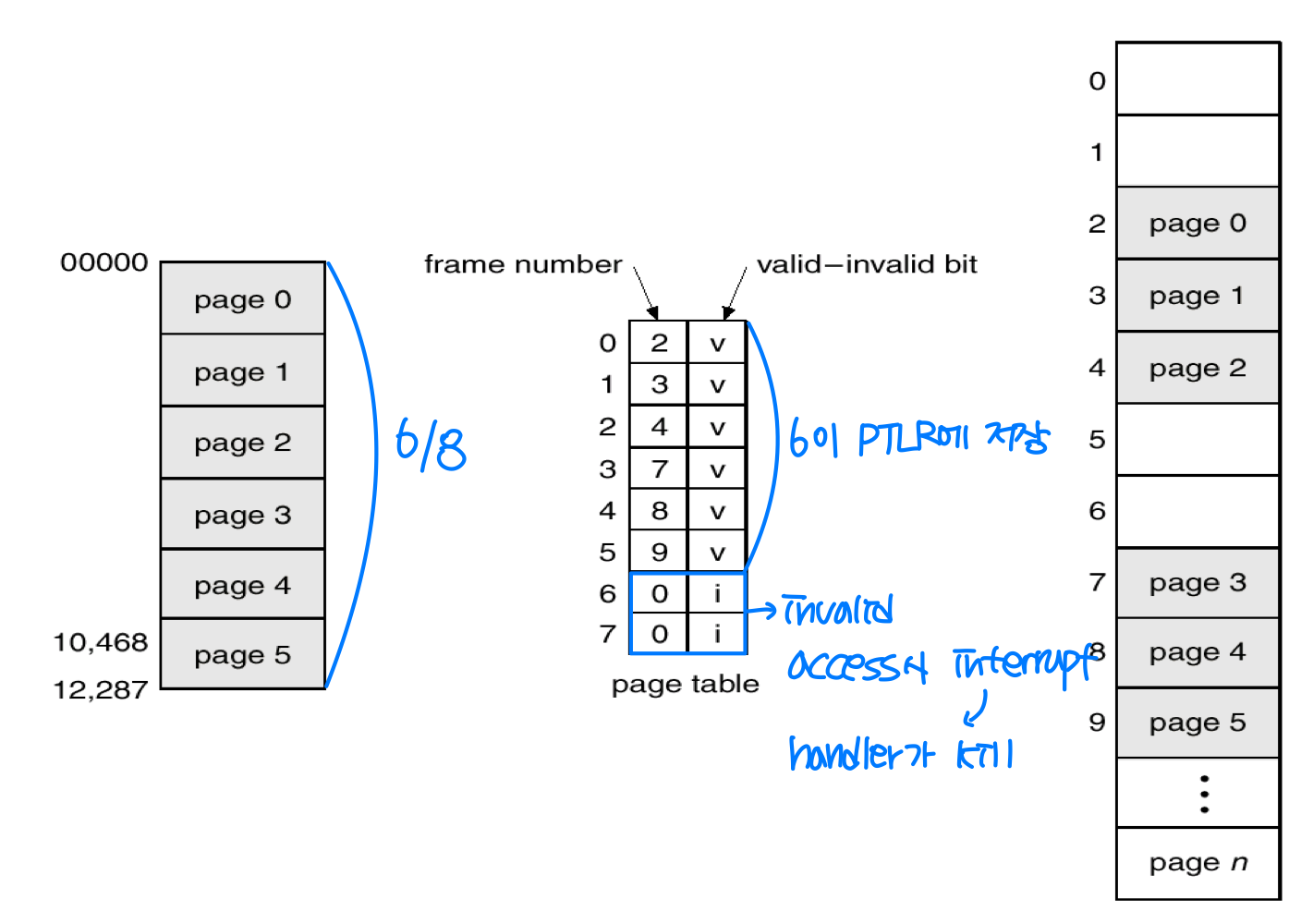
또한 페이지 테이블의 각 엔트리에는 유효-무효 비트(Valid-Invalid Bit) 가 있다. 무효(Invalid)로 설정된 페이지에는 OS가 접근을 허용하지 않는다.
대부분의 프로세스는 자신의 전체 주소 범위를 사용하지 않으므로, 페이지 테이블이 메모리를 낭비할 수 있다. 이를 위해 일부 시스템은 PTLR(Page-Table Length Register) 을 제공하여 유효한 테이블 길이만 저장한다.
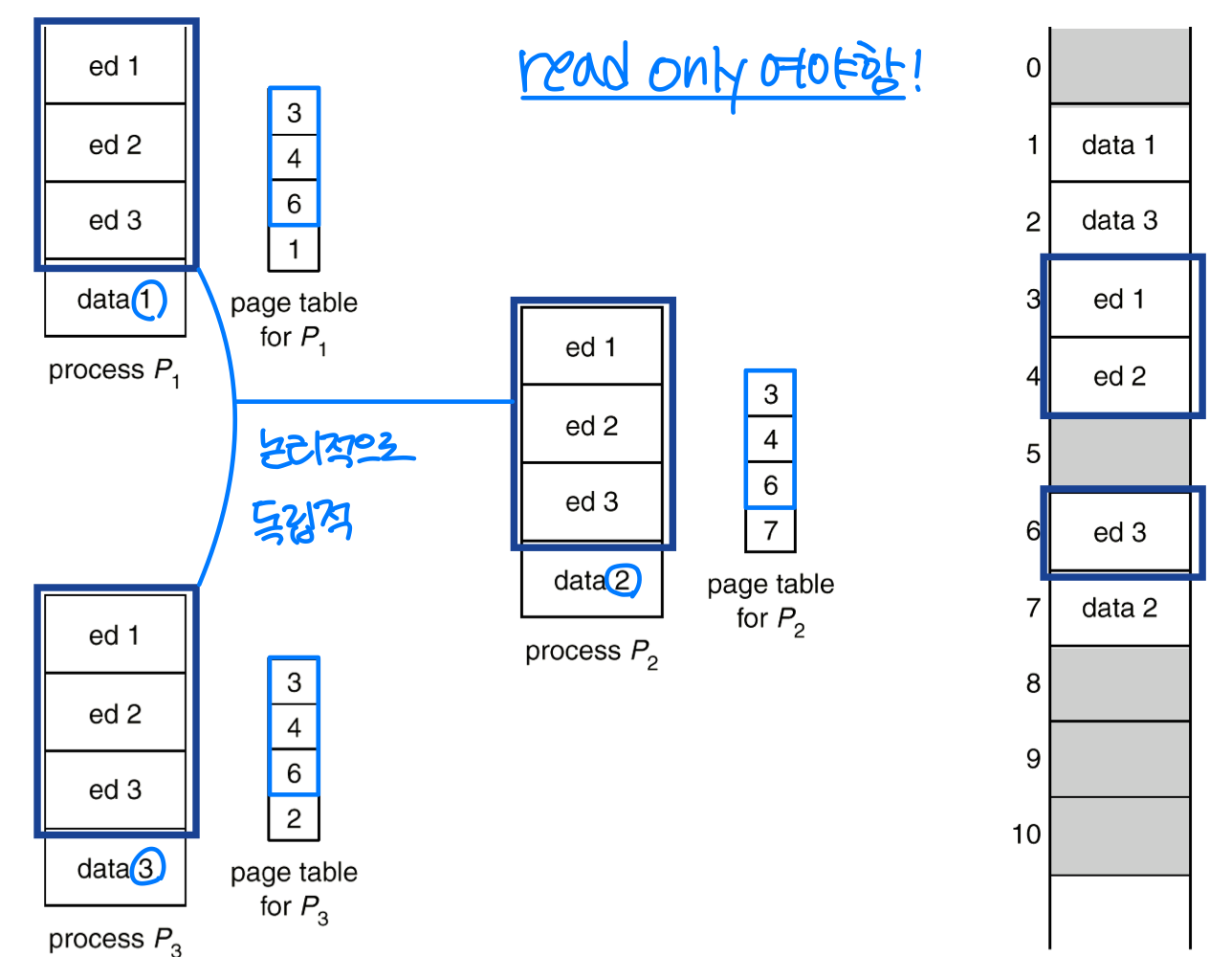
공유 페이지(Shared Pages)
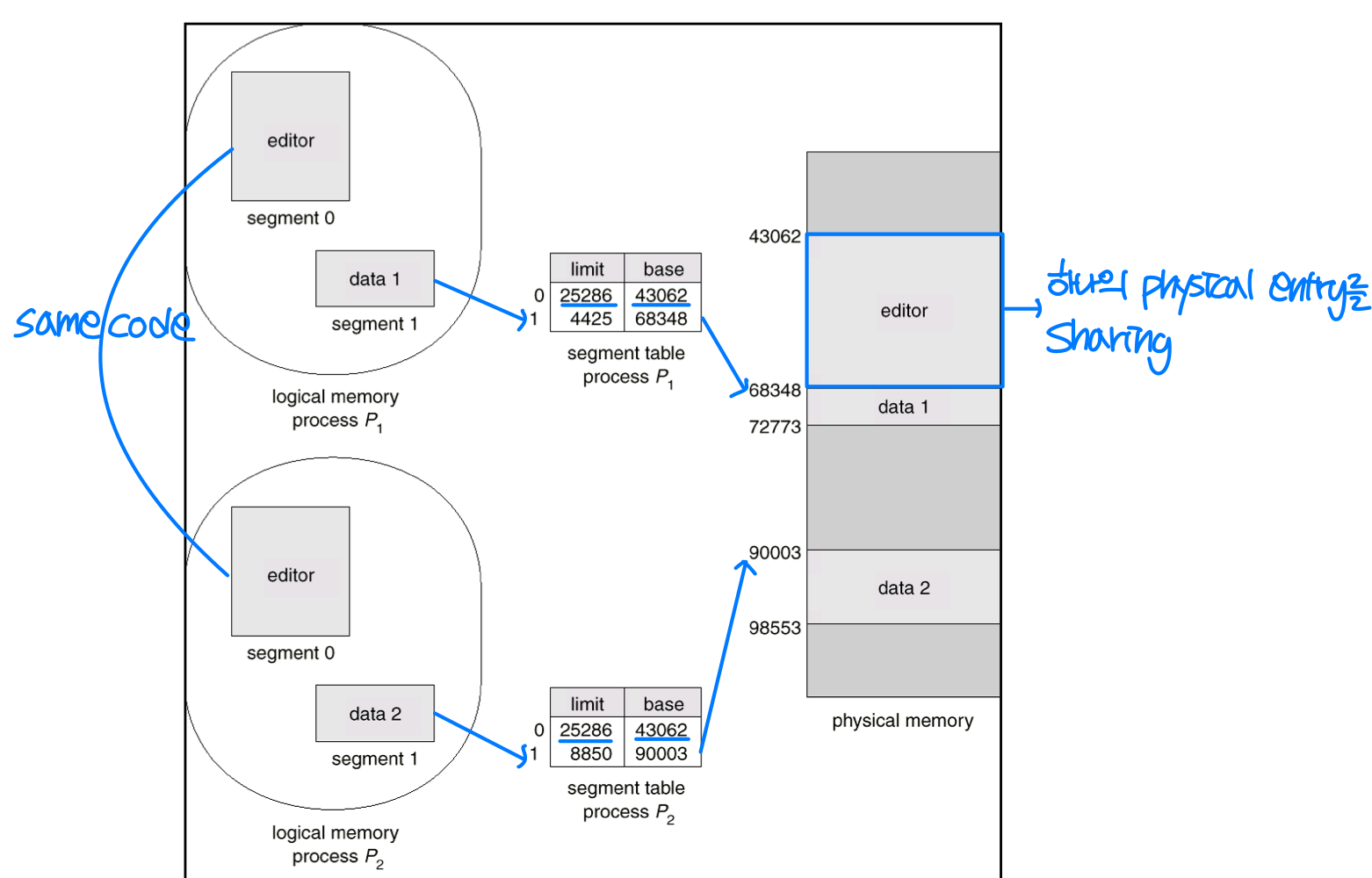
페이징은 공통 코드를 공유할 수 있는 가능성을 제공한다. 예를 들어 프로세스 P1, P2, P3가 동일한 텍스트 에디터를 서로 다른 데이터로 실행하는 경우, 에디터 코드는 공유하고 데이터만 각각 다른 프레임에 매핑하면 된다. 단, 공유되는 코드는 자기 수정이 불가능한 코드(Non-Self-Modifying Code) 여야 한다.
페이지 테이블의 구조
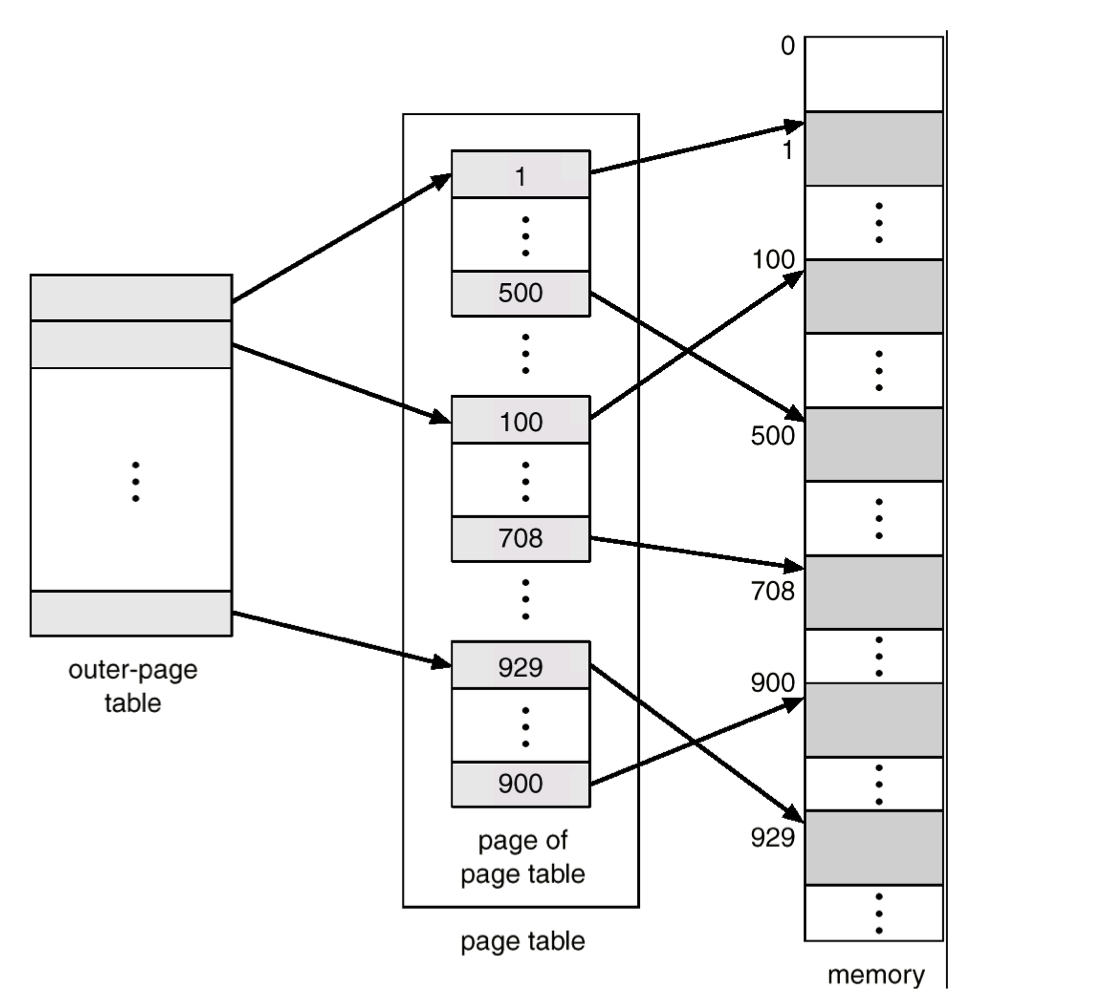
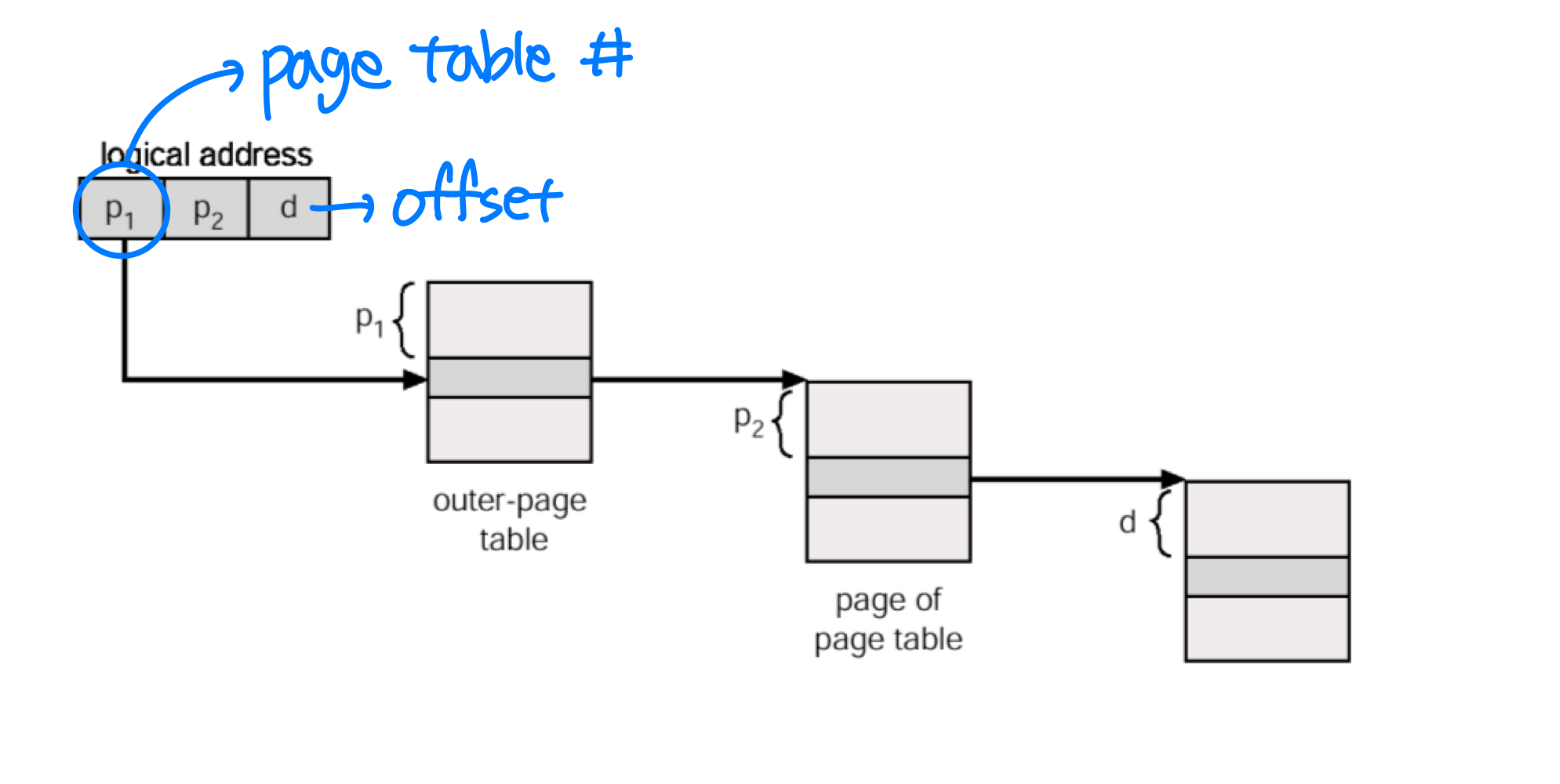
계층적 페이징(Hierarchical Paging)
시스템이 큰 논리 주소 공간을 지원하면, 페이지 테이블 자체가 상당한 오버헤드가 된다.
예를 들어 32비트 주소 공간에 페이지 크기가 4 KB()이면, 페이지 테이블 엔트리는 = 100만 개를 넘는다. 이 테이블은 연속적인 메모리 공간에 있어야 하는데, 이렇게 큰 연속 메모리를 할당하기는 어렵다.
해결책은 계층적 페이징이다. 페이지 테이블 자체를 다시 페이징하는 방식이다.
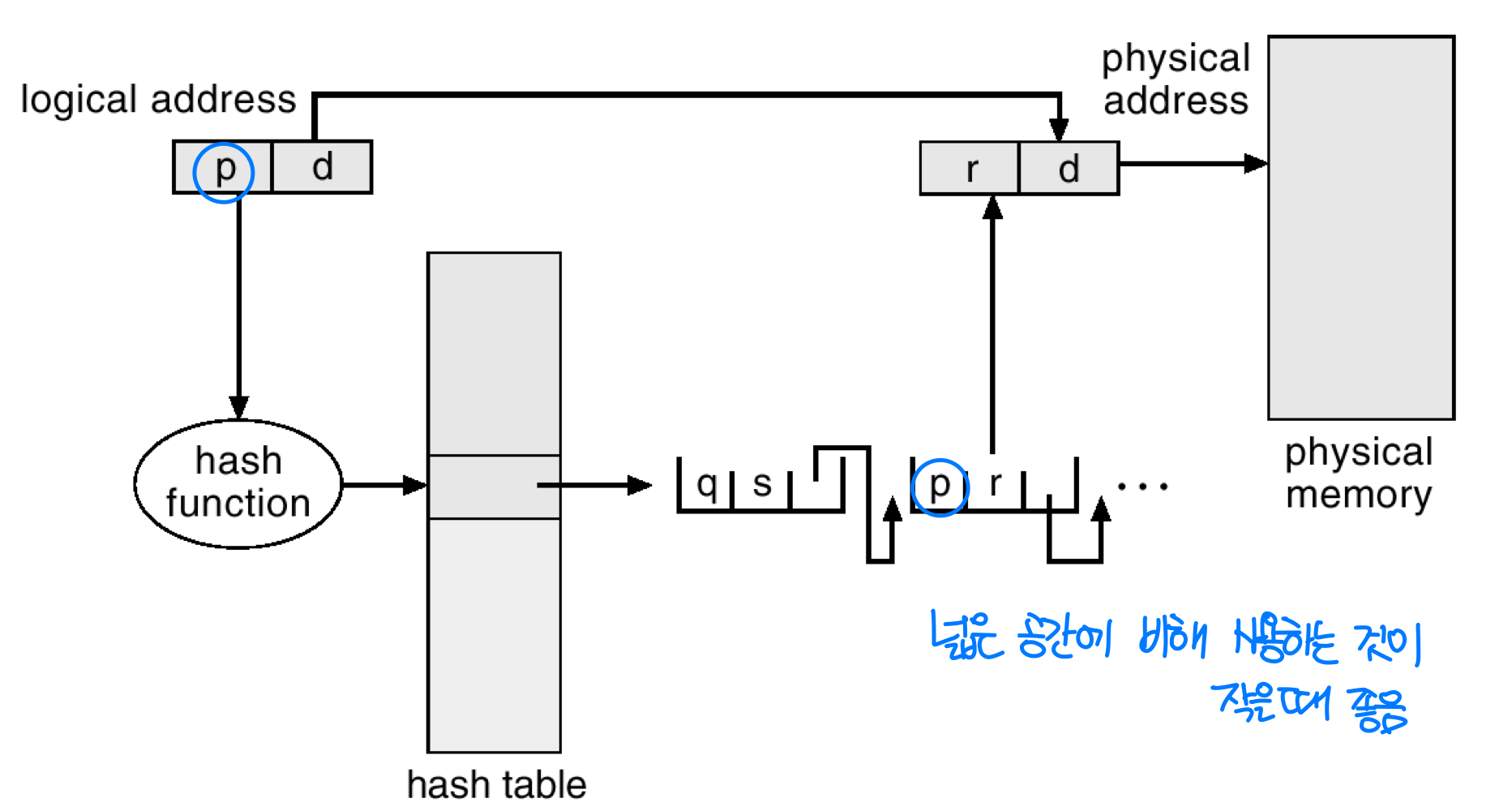
해시 페이지 테이블(Hashed Page Table)
해시를 이용한 페이지 테이블로, 32비트를 초과하는 큰 주소 공간에서 주로 사용된다. 주소 공간이 너무 크면 계층적 페이징으로도 테이블 크기를 감당하기 어렵기 때문이다.
해시 테이블의 각 위치는 페이지 테이블 엔트리의 연결 리스트(Linked List) 로 구성된다.
세그멘테이션(Segmentation)
사용자 관점에서 메모리는 하나의 선형 배열이 아니라, 스택, 수학 라이브러리, 메인 프로그램 등 가변 크기 세그먼트의 집합이다. 이 세그먼트들 사이에 반드시 순서가 있는 것은 아니다.
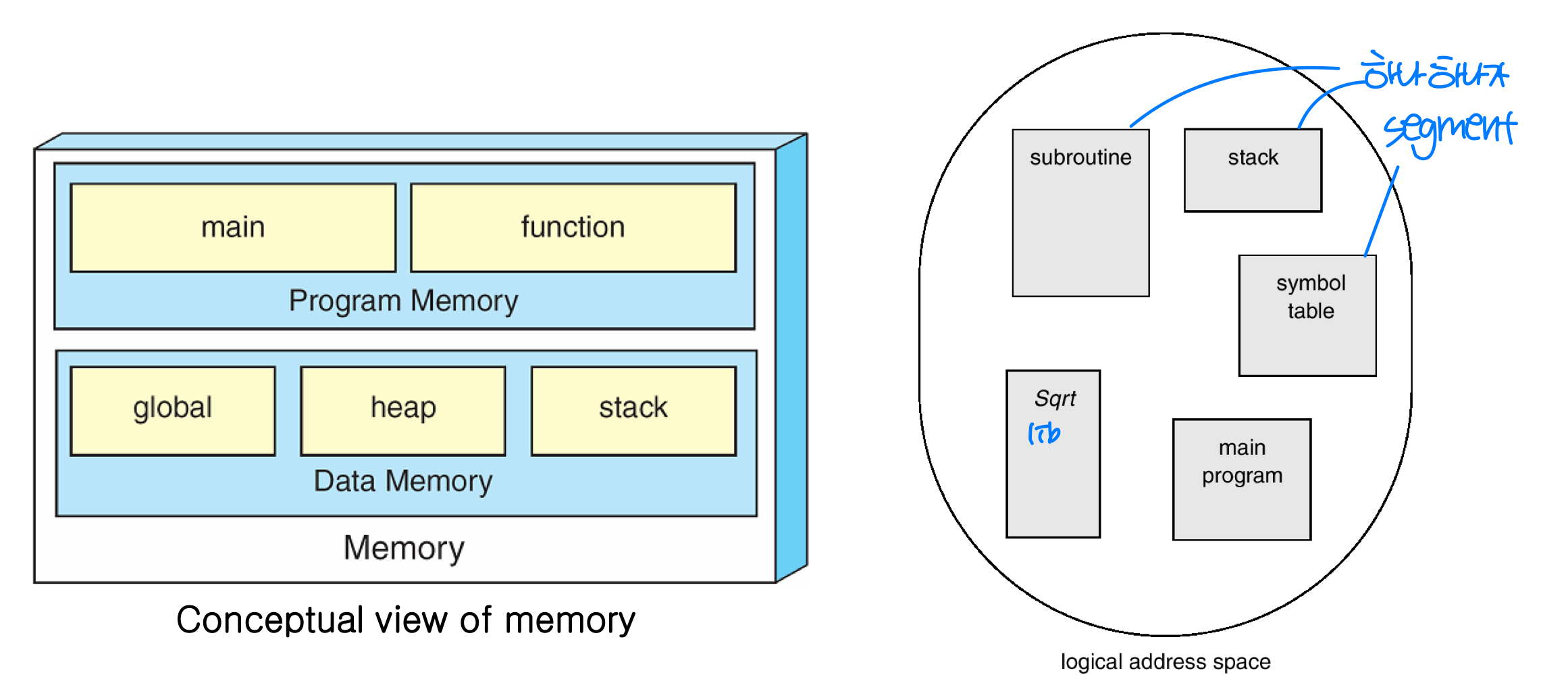
세그멘테이션(Segmentation) 은 이러한 사용자 관점을 지원하는 메모리 관리 기법이다.
- 논리 주소 공간은 세그먼트의 집합이다.
- 각 세그먼트는 이름(번호) 과 길이를 가진다.
- 논리 주소 =
<세그먼트 번호, 오프셋> - 예를 들어 C 컴파일러는 코드, 전역 변수, 힙, 스택, 표준 C 라이브러리 등의 세그먼트를 생성할 수 있다.
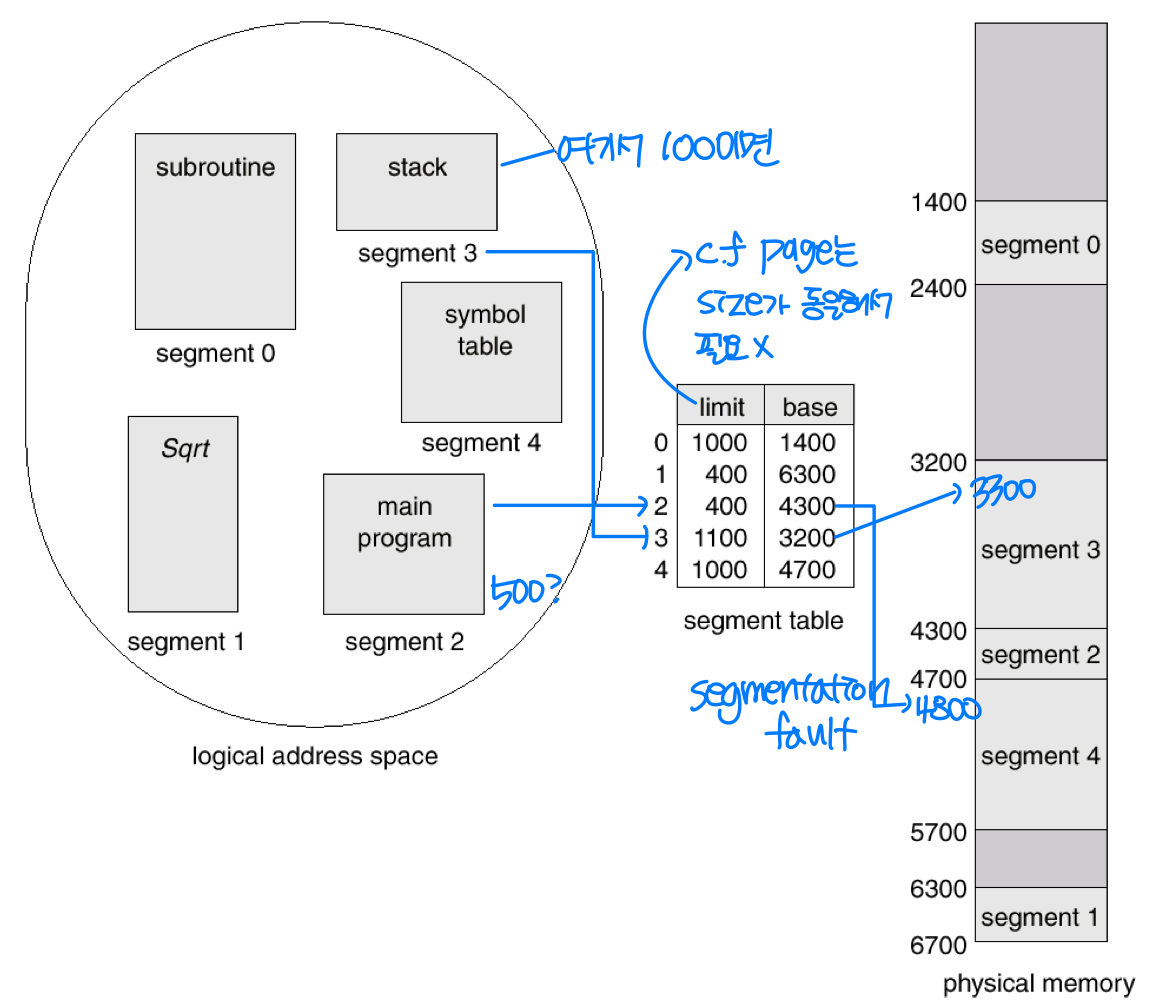
세그멘테이션 하드웨어
2차원 주소(세그먼트 번호, 오프셋)를 1차원 바이트 시퀀스로 매핑해야 한다. 이를 위해 세그먼트 테이블(Segment Table) 을 사용하며, 각 엔트리는 세그먼트 베이스(Base) 와 세그먼트 리밋(Limit) 으로 구성된다. 즉, 각 세그먼트의 시작 주소와 크기를 저장하여 메모리 매핑을 세그먼트 단위로 수행한다.
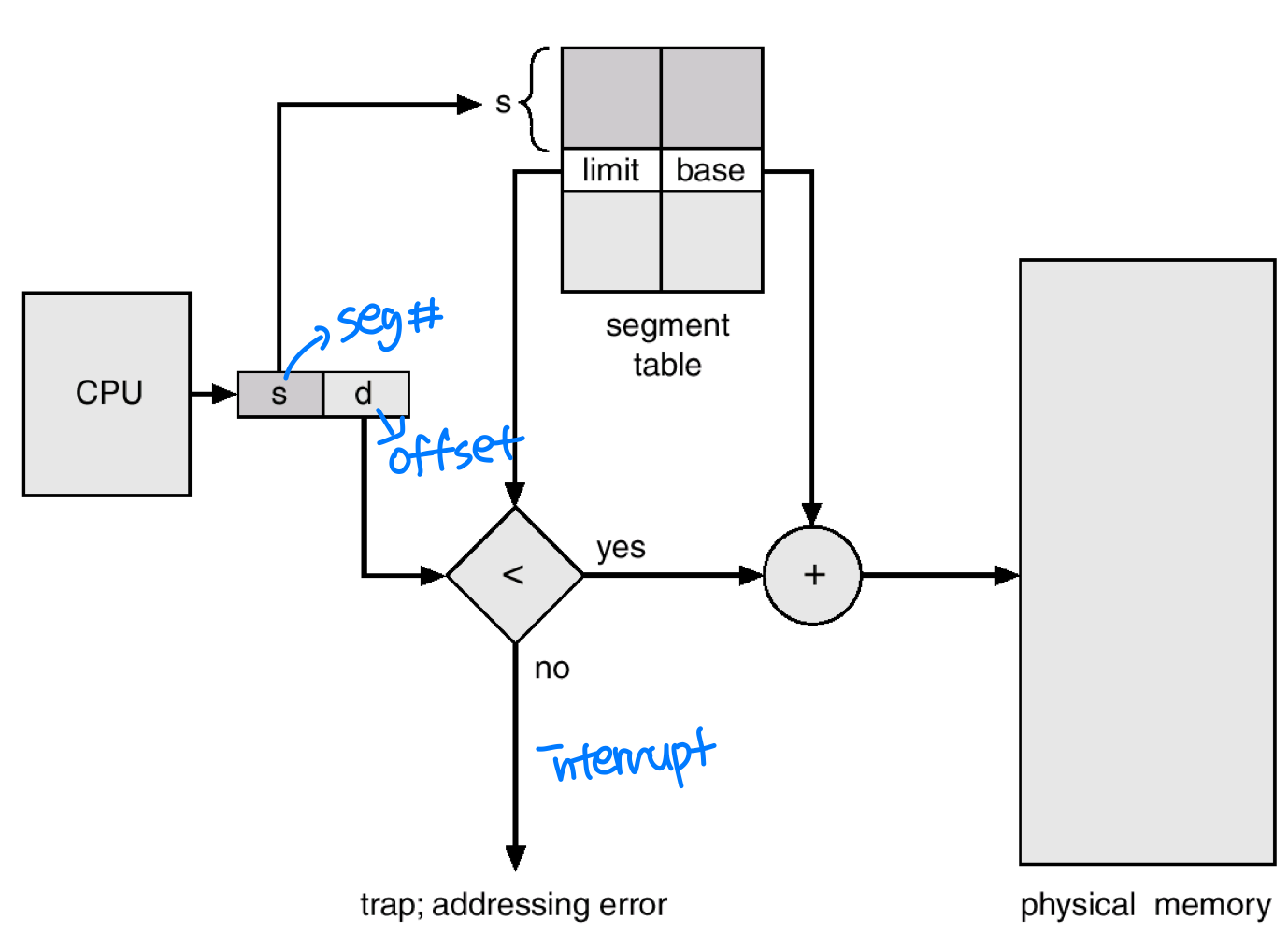
세그멘테이션 아키텍처
세그먼트 테이블은 2차원 논리 주소를 물리 주소로 매핑하며, 각 엔트리는 다음으로 구성된다.
- base: 세그먼트가 물리 메모리에서 시작하는 주소
- limit: 세그먼트의 길이
관련 레지스터로는 다음 두 가지가 있다.
- STBR(Segment-Table Base Register): 세그먼트 테이블의 메모리 내 위치를 가리킨다.
- STLR(Segment-Table Length Register): 프로그램이 사용하는 세그먼트 수를 나타낸다. 세그먼트 번호
s가 합법적이려면s가 STLR보다 작아야 한다.
세그멘테이션에서도 페이징처럼 보호(Protection) 와 공유(Sharing) 가 가능하다.
사례: Intel Pentium
일부 아키텍처는 페이징과 세그멘테이션을 모두 지원한다. Intel x86이 대표적인 예로, 순수 세그멘테이션과 세그멘테이션 + 페이징 방식을 지원한다.
Pentium 세그멘테이션
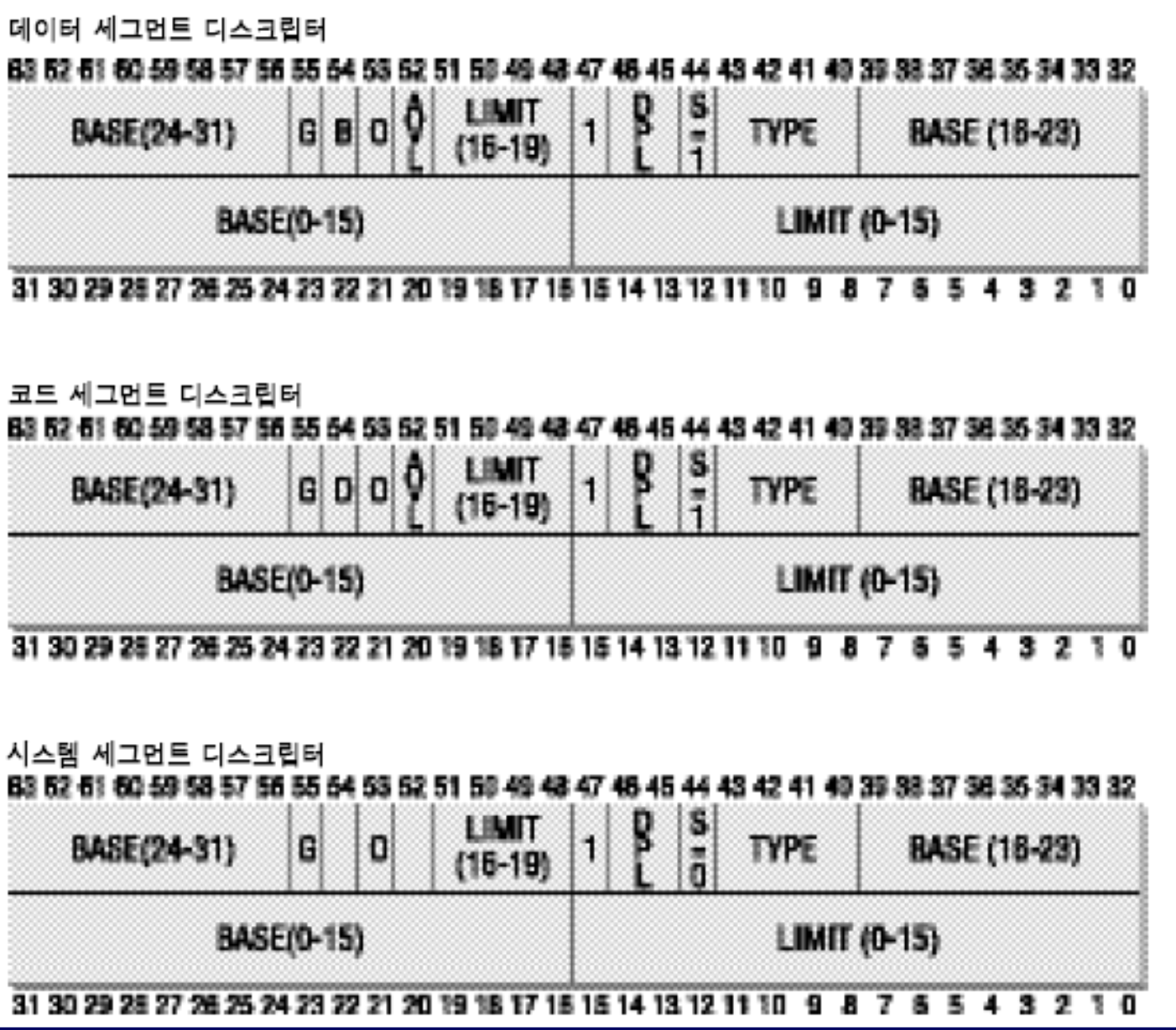
- 세그먼트 최대 크기: 4 GB (32비트 머신의 최대 주소 = 4G)
- 세그먼트 최대 개수: 16K (= 16,384)개
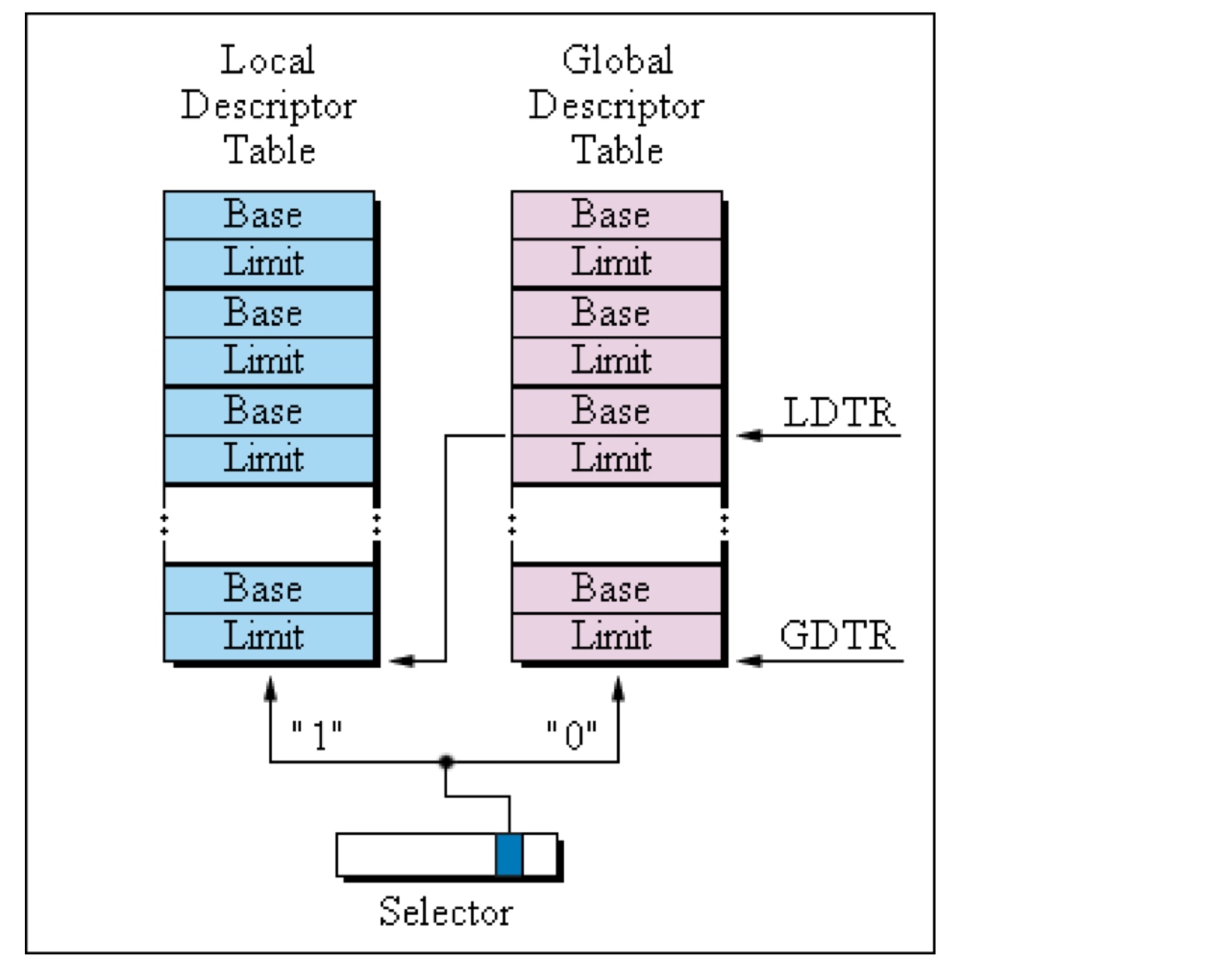
- 1번째 파티션: 프로세스 전용 세그먼트 8K개 -> LDT(Local Descriptor Table) 에 보관. 프로세스마다 별도의 8K 세그먼트 테이블을 가진다.
- 2번째 파티션: 공유 세그먼트 8K개 -> GDT(Global Descriptor Table) 에 보관
Pentium은 다음 레지스터를 가진다.
- 6개의 세그먼트 레지스터: CS(Code), SS(Stack), DS(Data), ES(Extra), FS, GS -> 세그먼트 번호를 저장하며, 오프셋은 포인터가 담당
- 6개의 8바이트 마이크로프로그램 레지스터: LDT 또는 GDT의 디스크립터를 보관 -> 세그먼트 테이블 엔트리의 캐시 역할
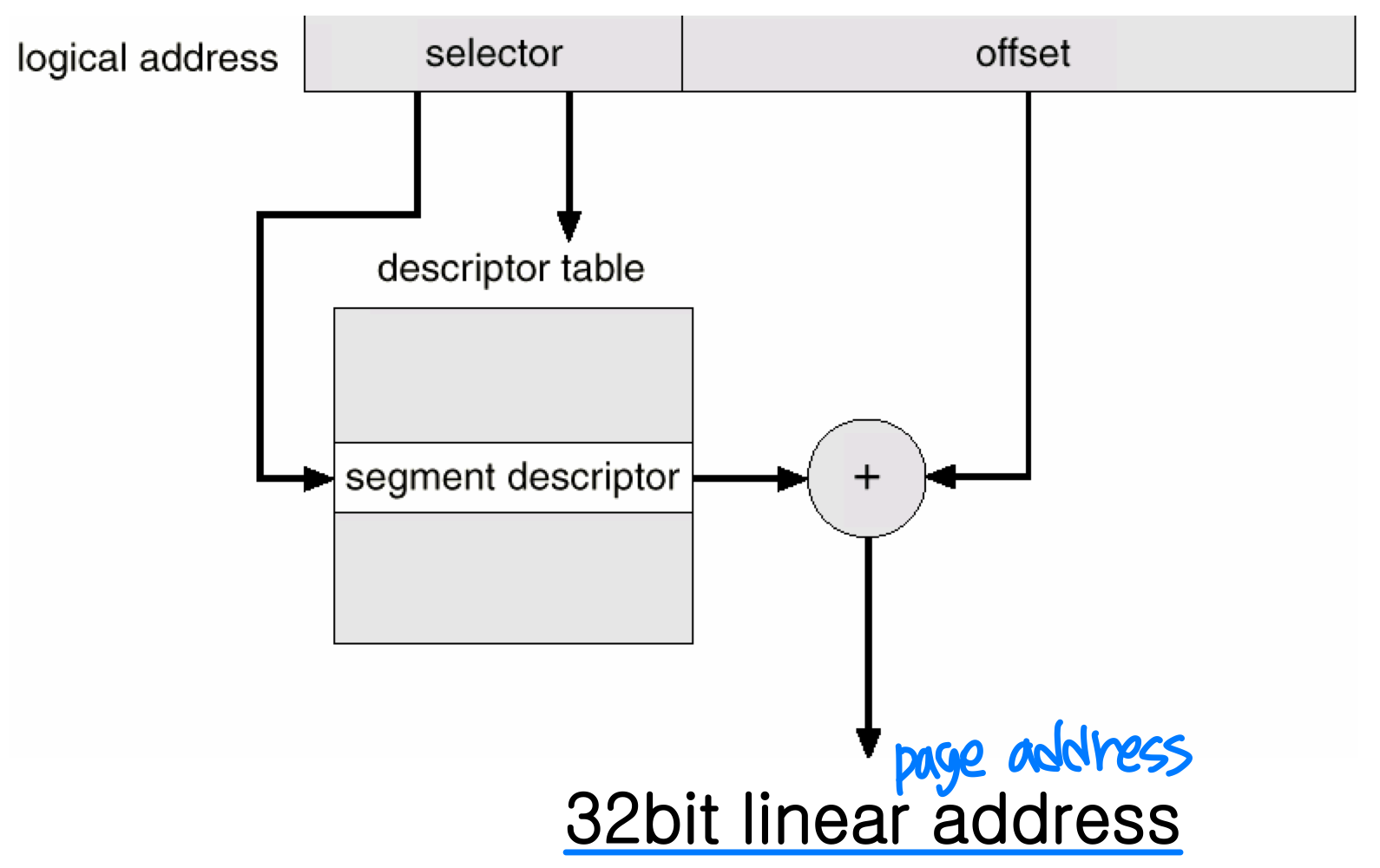
세그먼트 디스크립터(Segment Descriptor) 는 64비트 정보로, 세그먼트의 속성을 기술한다.
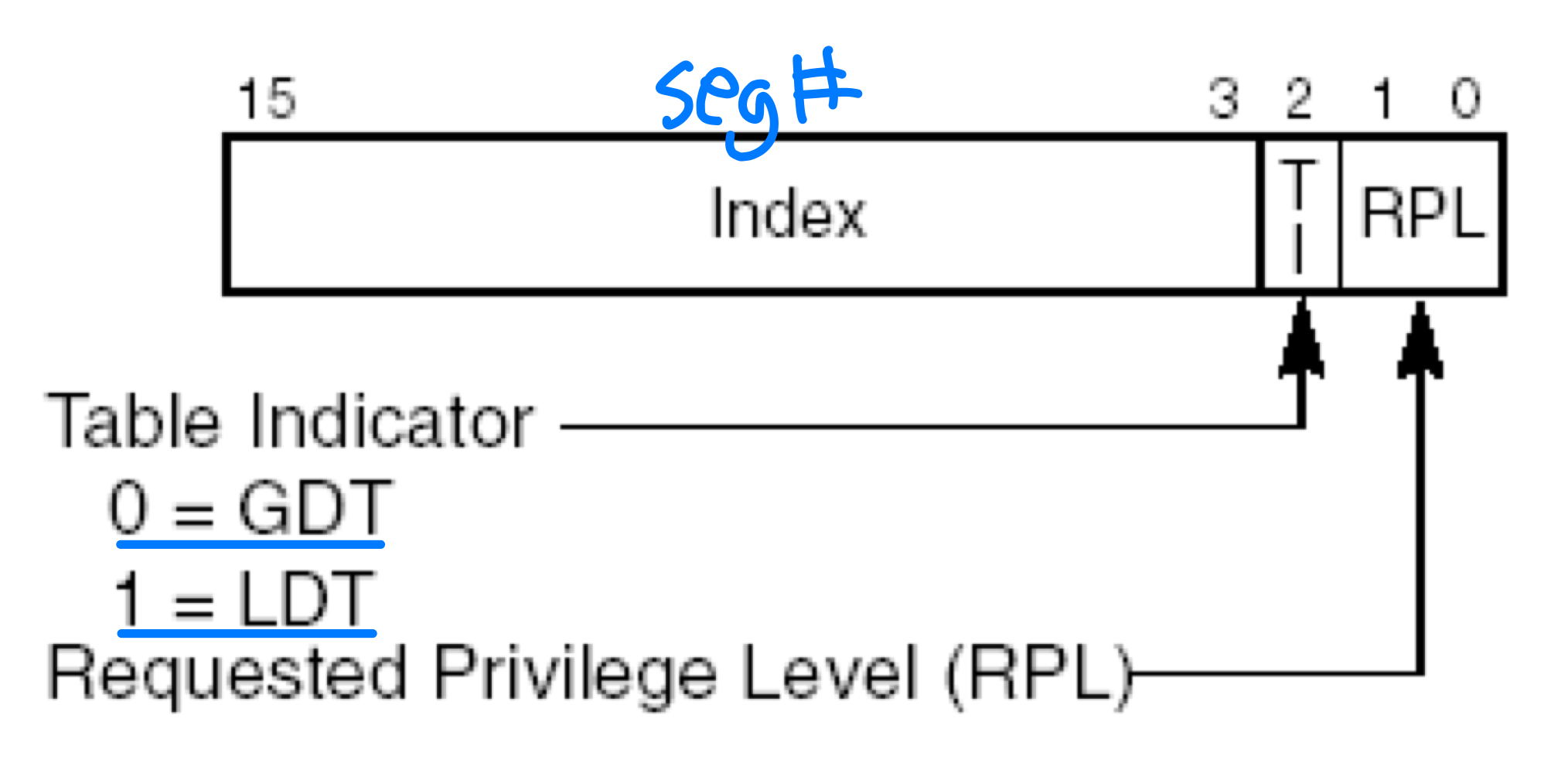
논리 주소는 (셀렉터, 오프셋) 쌍으로 구성된다.
셀렉터(Selector) 는 16비트 숫자로, 다음과 같이 구성된다.
- 세그먼트 번호: 13비트 (= 8K)
- GDT 또는 LDT 선택: 1비트
- 보호 수준: 2비트
오프셋(Offset) 은 32비트 숫자다.
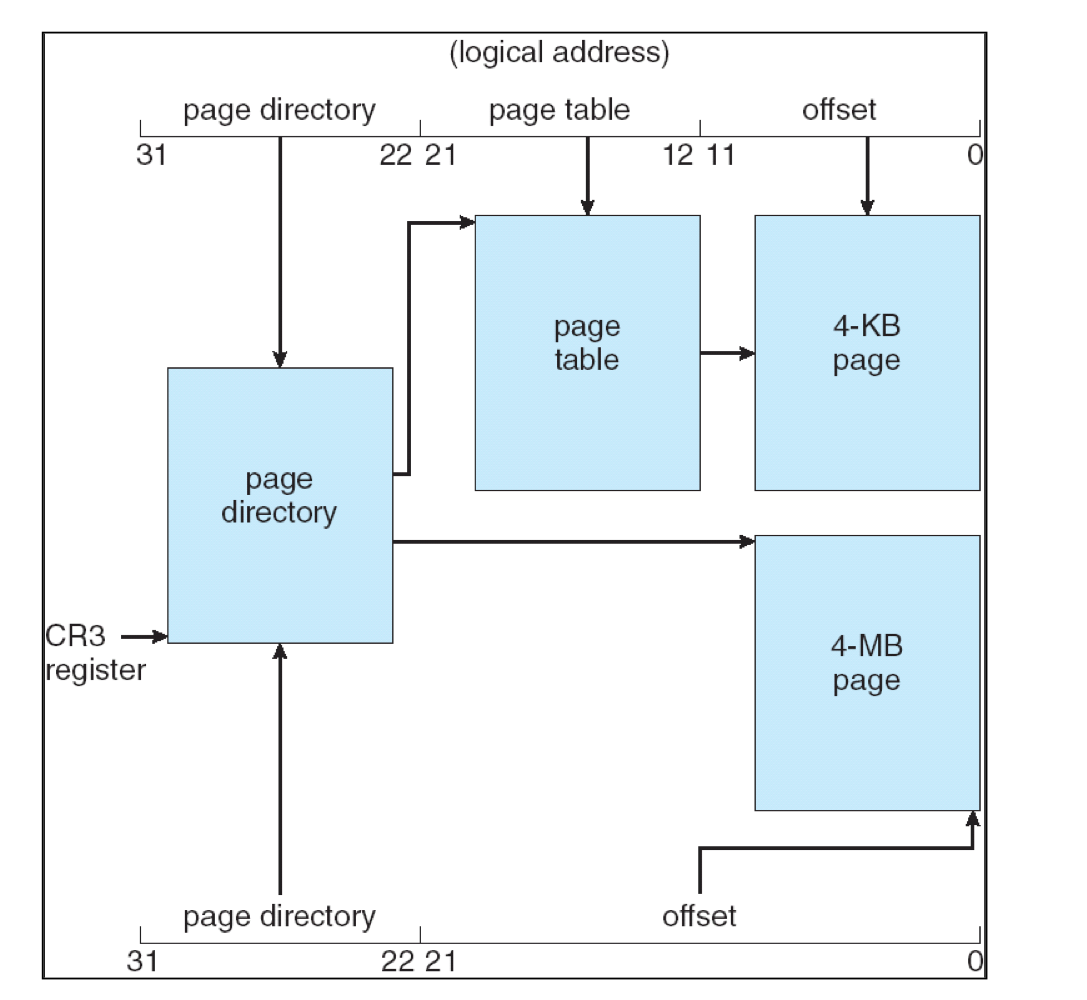
Pentium 페이징
Pentium은 4 KB 또는 4 MB 페이지 크기를 지원한다. 페이지 디렉터리 엔트리의 페이지 크기 플래그(Page Size Flag) 로 구분한다.
4 KB 페이지(페이지 크기 플래그 = 0)
2단계 페이징을 사용한다. CR4 레지스터의 PSE 비트로 제어한다.

4 MB 페이지(페이지 크기 플래그 = 1)

HGU 전산전자공학부 김인중 교수님의 23-1 운영체제 수업을 듣고 작성한 포스트이며, 첨부한 모든 사진은 교수님 수업 PPT의 사진 원본에 필기를 한 수정본입니다.