스레드란?
하나의 프로그램 안에서 여러 작업을 동시에 처리하고 싶다면 어떻게 해야 할까? 프로세스를 여러 개 만드는 방법도 있지만, 이는 비용이 크다. 이때 등장하는 것이 스레드(Thread) 다.
프로세스(Process) 는 실행 중인 프로그램으로, 각 프로세스는 독립적인 자원을 점유하며 서로 자원을 공유하지 않는다. 반면 스레드는 프로세스보다 작은 실행 단위로, 같은 프로세스 내의 스레드들은 자원을 공유한다.
스레드를 사용하면 코드를 단순화하고 효율성을 높일 수 있다. 실제로 대부분의 커널(Kernel) 자체도 멀티스레드로 구현되어 있다.
스레드의 구성 요소
스레드는 다음 요소로 구성된다.
- Thread ID
- 프로그램 카운터(Program Counter)
- 레지스터 세트(Register Set)
- 스택(Stack) - 지역 변수, 함수 호출 정보
이 중 스택은 스레드마다 독립적으로 가지며, 나머지 코드/데이터/파일 등의 자원은 같은 프로세스 내 스레드끼리 공유한다.
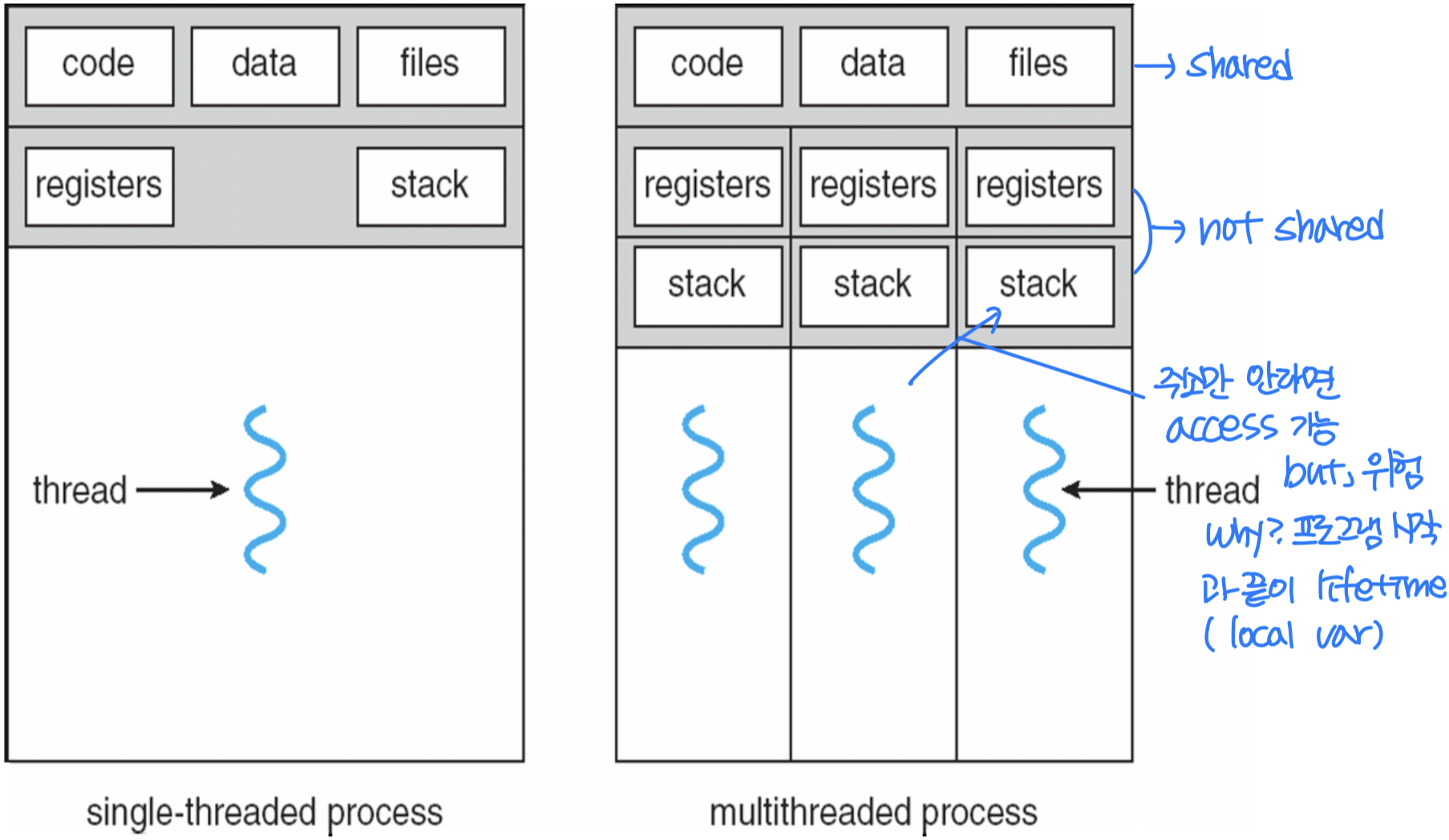
프로세스 vs. 스레드
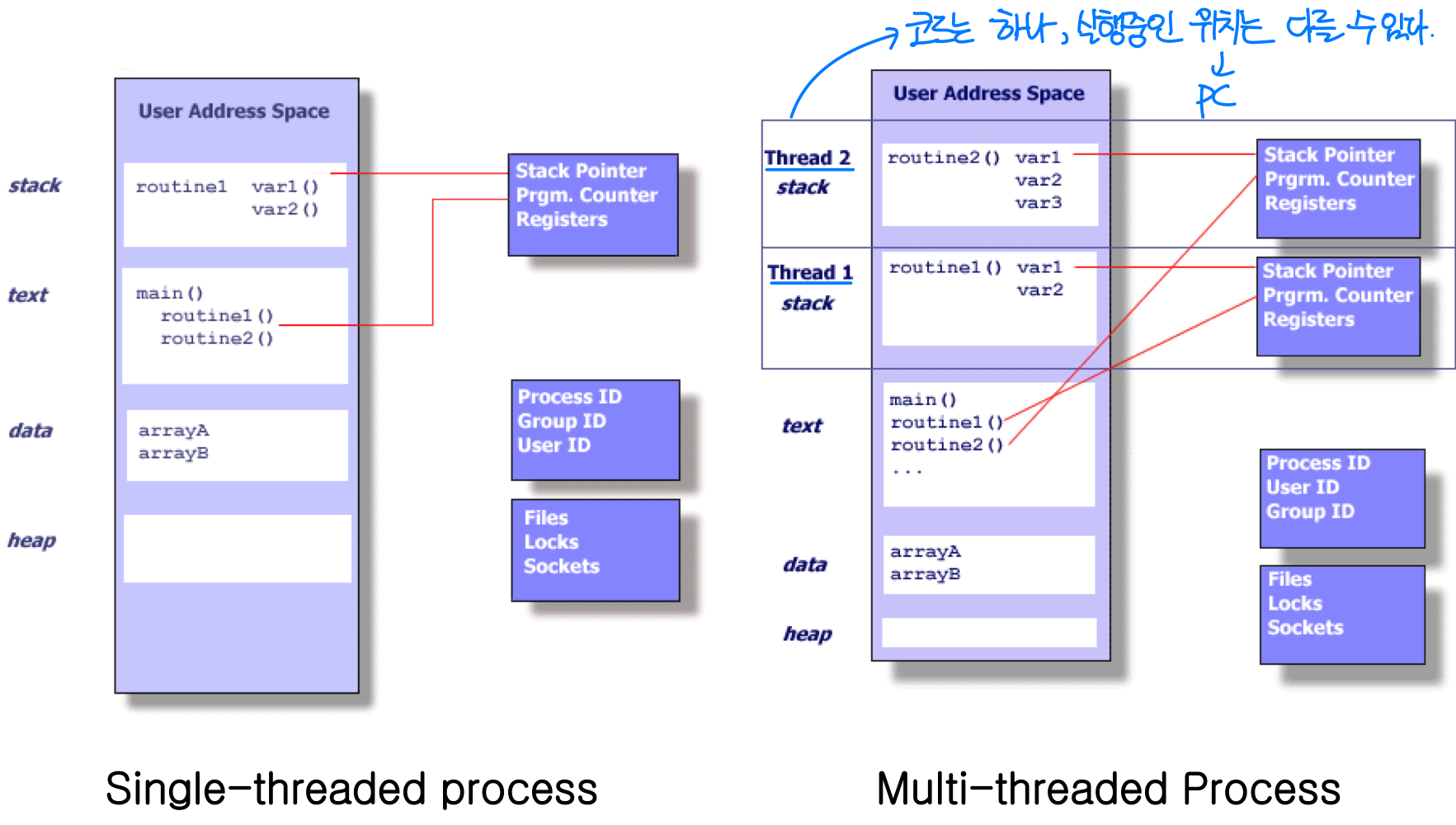
스레드 제어 블록 (TCB)
TCB(Thread Control Block) 는 운영체제 커널 내에서 스레드를 관리하기 위한 데이터 구조다. PCB가 프로세스 정보를 담듯이, TCB는 스레드 고유 정보를 담는다.
TCB에 포함되는 정보는 다음과 같다.
- Thread ID
- 스레드 상태 (running, ready, waiting, start, done)
- 스택 포인터(Stack Pointer) - 스레드마다 스택이 독립적이므로 별도로 관리한다
- 프로그램 카운터(Program Counter)
- 레지스터 값
- PCB 포인터 - 스레드가 속한 프로세스의 PCB를 가리킨다
왜 스레드를 사용하는가?
프로세스 생성은 시간과 자원 면에서 비용이 크다. 예를 들어 웹 서버가 수천 개의 요청을 처리해야 하는 상황을 생각해 보자. 요청마다 새로운 프로세스를 만든다면 엄청난 오버헤드가 발생한다.
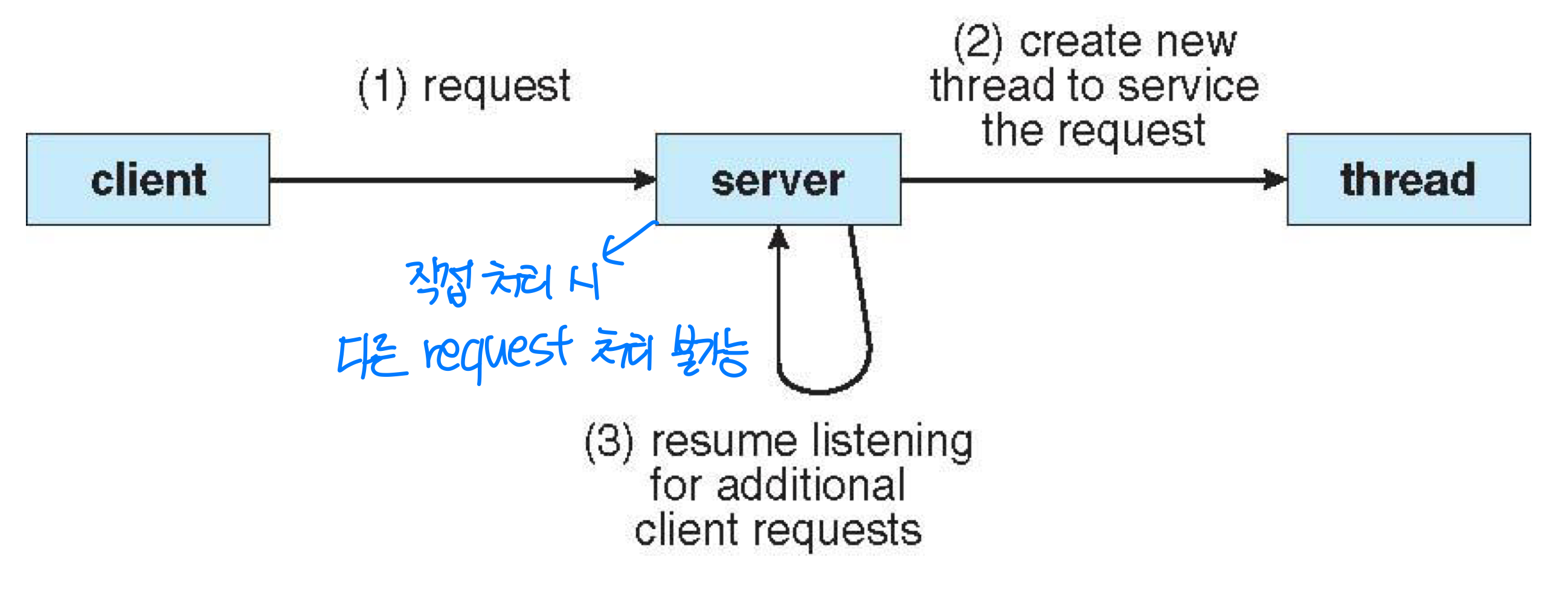
단일 스레드 프로세스와 비교했을 때의 장점:
- 확장성(Scalability): 멀티프로세서 구조를 효과적으로 활용할 수 있다
- 반응성(Responsiveness): GUI 스레드처럼, 한 작업이 블록되어도 다른 작업이 계속 실행된다
다중 프로세스와 비교했을 때의 장점:
- 자원 공유(Resource Sharing): 전역 변수만으로도 간단하게 데이터를 공유할 수 있다. 공유가 빈번한 경우 스레드가 훨씬 유리하다
- 경제성(Economy): 프로세스 생성은 스레드 생성보다 약 30배 느리다
멀티코어 프로그래밍
멀티코어 또는 멀티프로세서 시스템에서 프로그래밍할 때는 다음과 같은 도전 과제가 있다.
- 작업 분배(Dividing Activities): 작업을 어떻게 나눌 것인가
- 균형(Balance): 각 코어에 비슷한 양의 작업을 분배해야 한다
- 데이터 분할(Data Splitting)
- 데이터 의존성(Data Dependency): 작업 간 데이터가 의존 관계에 있으면 순서를 지켜야 한다
- 테스트와 디버깅: 멀티스레드 환경의 디버깅은 어렵고 복잡하다. 로그 파일(파일에 출력)을 활용하는 방법이 대표적이다
동시성(Concurrency) vs. 병렬성(Parallelism)
이 두 개념은 자주 혼동되지만 명확히 다르다.
동시성(Concurrency) 은 여러 작업이 진행 중인 상태를 의미한다. 싱글 코어 환경에서도 스케줄러가 타임 셰어링을 통해 동시성을 제공할 수 있다. 실제로 동시에 실행되는 것이 아니라 빠르게 번갈아 실행하는 것이다.

병렬성(Parallelism) 은 여러 작업이 실제로 동시에 실행되는 것을 의미한다. 이를 위해서는 멀티코어 시스템이 필요하다.
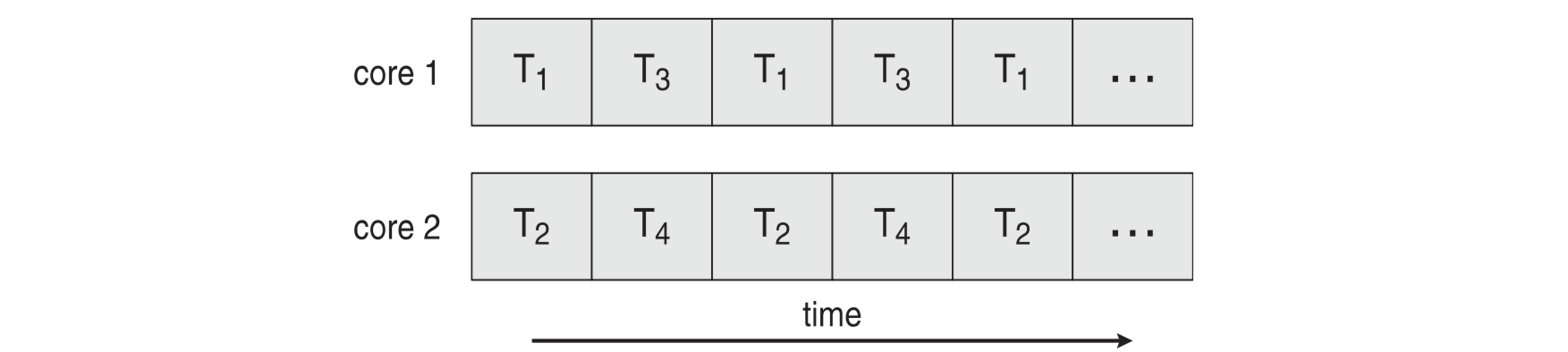
병렬성의 종류
- 데이터 병렬성(Data Parallelism): 동일한 데이터의 부분 집합을 여러 코어에 분배하고, 각 스레드가 같은 연산을 수행한다. 예를 들어 TA 4명이 100명의 과제를 각 25명씩 채점하는 것과 같다.
- 태스크 병렬성(Task Parallelism): 각 스레드가 서로 다른 연산을 수행한다. 태스크 간 의존성이 없을 때 병렬 처리의 속도 향상이 극대화된다.
스레드 수가 증가할수록 하드웨어 차원의 스레딩 지원도 함께 발전한다. 예를 들어 Oracle SPARC T4 프로세서는 8개의 코어에 코어당 8개의 하드웨어 스레드를 지원한다.
암달의 법칙 (Amdahl's Law)
병렬 처리를 통해 얻을 수 있는 성능 향상에는 한계가 있다. 암달의 법칙은 이 한계를 수학적으로 표현한다.
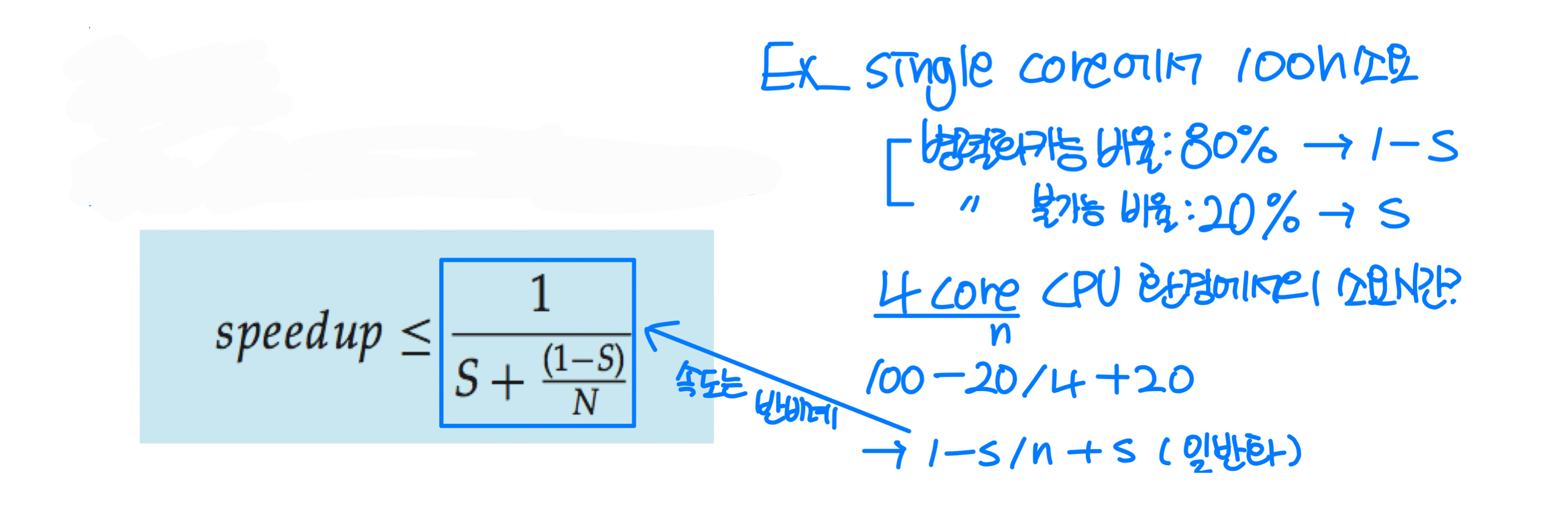
여기서 S는 직렬 실행 비율, N은 프로세싱 코어 수다.
예를 들어 애플리케이션이 75% 병렬 / 25% 직렬이라면, 코어를 1개에서 2개로 늘렸을 때 속도 향상은 1.6배에 불과하다.
- N이 무한대에 가까워져도, 속도 향상은 1/S에 수렴한다
- 즉, 직렬 부분의 비율이 전체 성능 향상에 불균형적으로 큰 영향을 미친다
멀티스레딩 모델
스레드는 구현 위치에 따라 두 종류로 나뉜다.
사용자 스레드(User Thread)
- 사용자 수준의 스레드 라이브러리가 지원하는 스레드다
- 라이브러리 함수 호출로 생성된다 (시스템 콜이 아님)
- 커널이 사용자 스레드의 존재를 알지 못한다
- 커널 스레드보다 전환이 빠르고 가볍다
커널 스레드(Kernel Thread)
- 커널이 직접 생성하고 관리하는 스레드다
- 커널의 스케줄러에 의해 스케줄링된다
- 프로세스보다는 가볍지만, 사용자 스레드보다는 비용이 크다 (프로세스 > 커널 스레드 > 사용자 스레드)
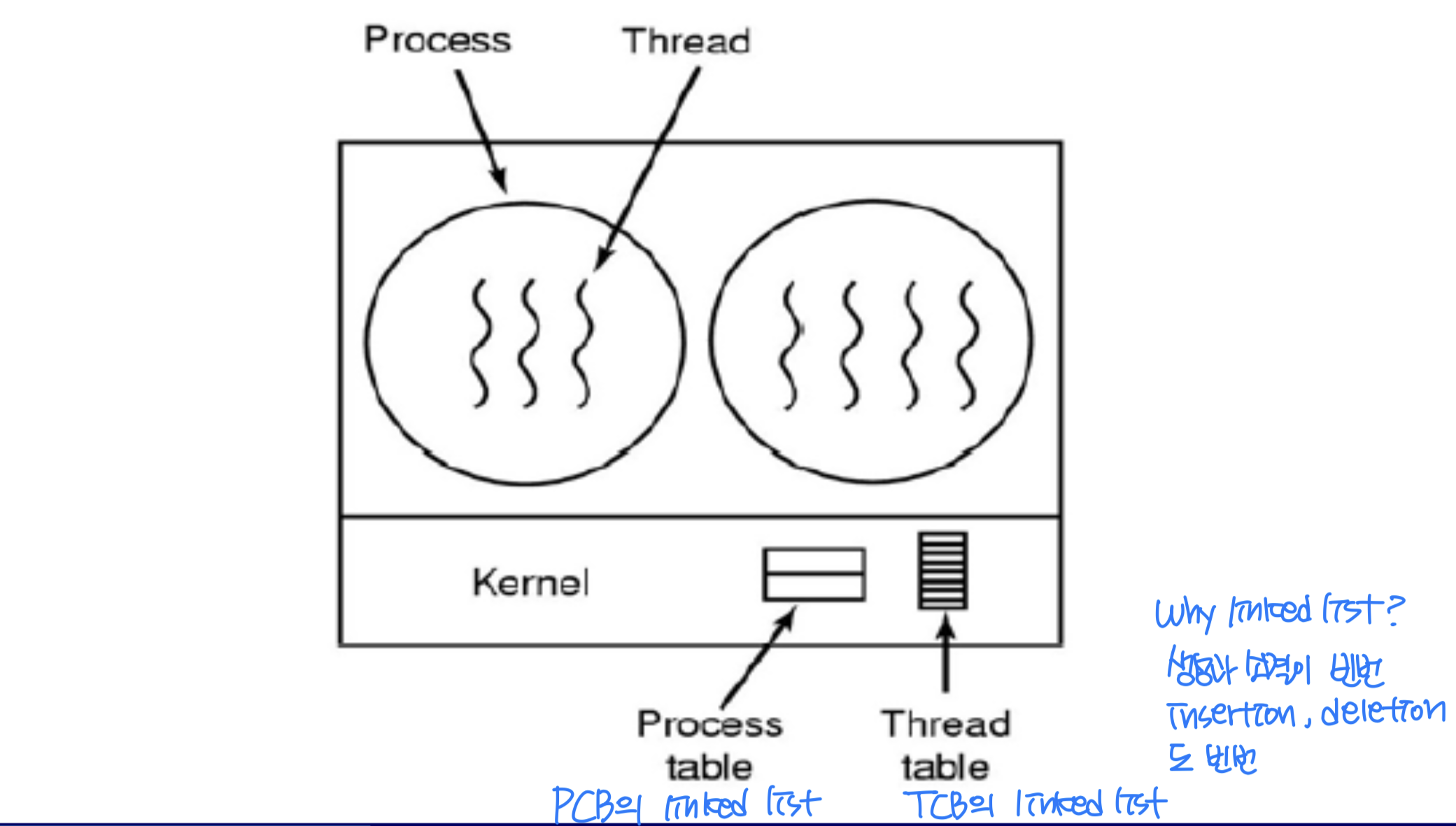
핵심 이슈는 사용자 스레드와 커널 스레드 간의 대응 관계를 어떻게 설정하느냐다.
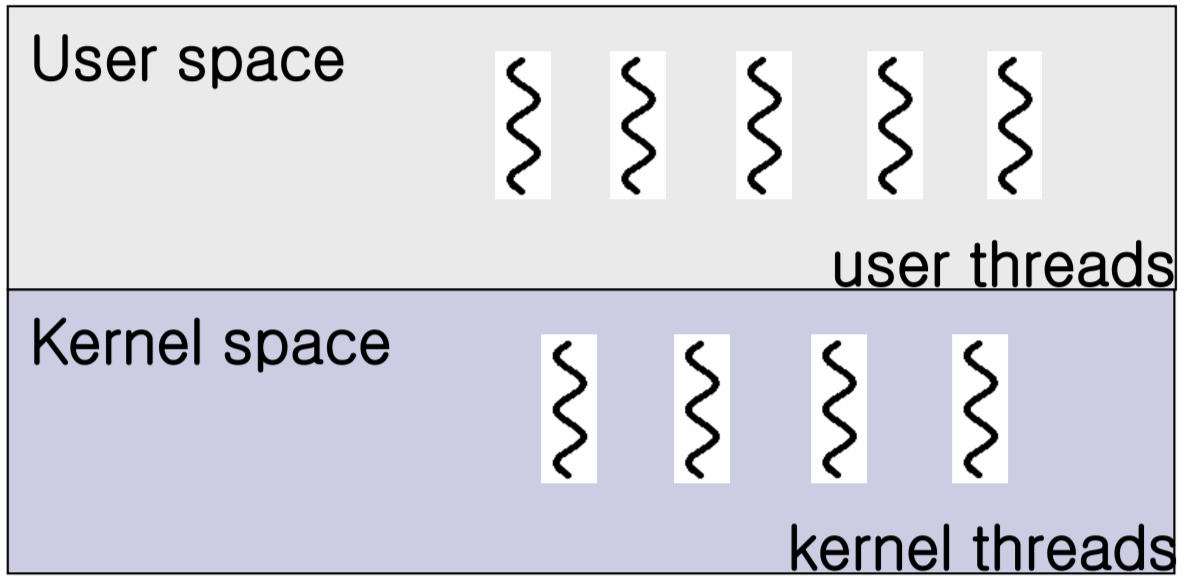
다대일 모델 (Many-to-One)
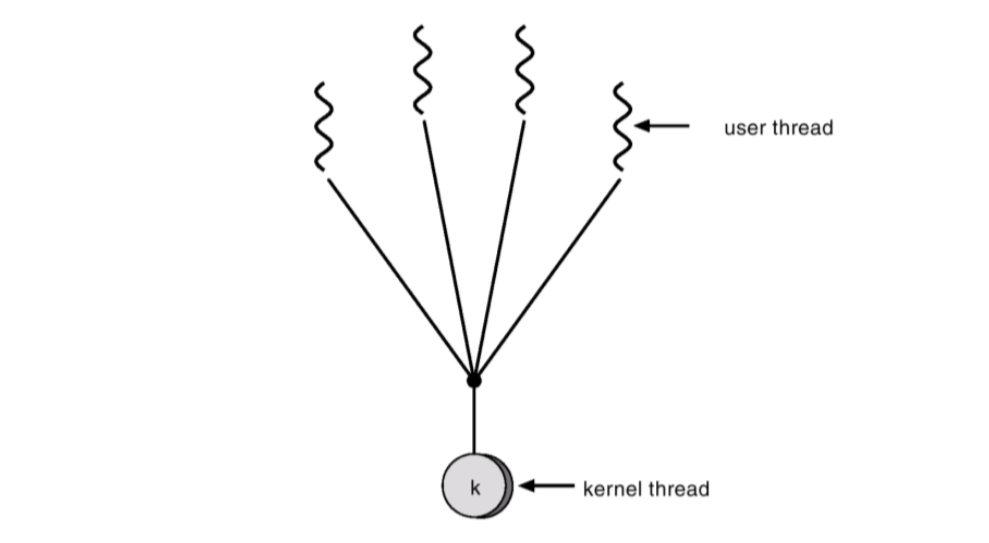
여러 사용자 스레드가 하나의 커널 스레드에 매핑되는 구조다. 스레드 관리는 사용자 수준 스레드 라이브러리가 담당한다.
예시: Green threads, GNU Portable Threads
일대일 모델 (One-to-One)
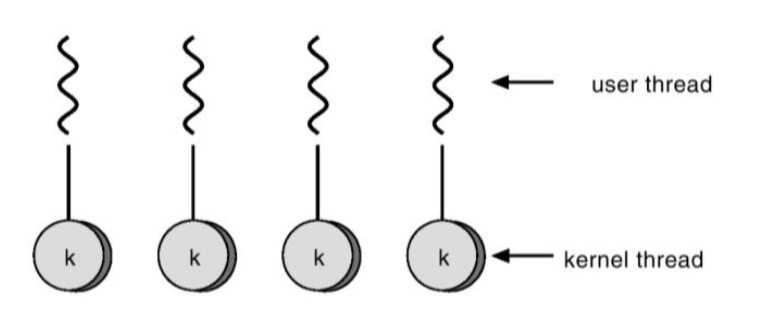
각 사용자 스레드가 하나의 커널 스레드에 매핑된다. 더 높은 동시성을 제공하지만, 스레드 생성 시 오버헤드가 발생한다. 스레드 관리는 커널이 담당한다.
예시: Linux, Windows, Solaris
다대다 모델 (Many-to-Many)
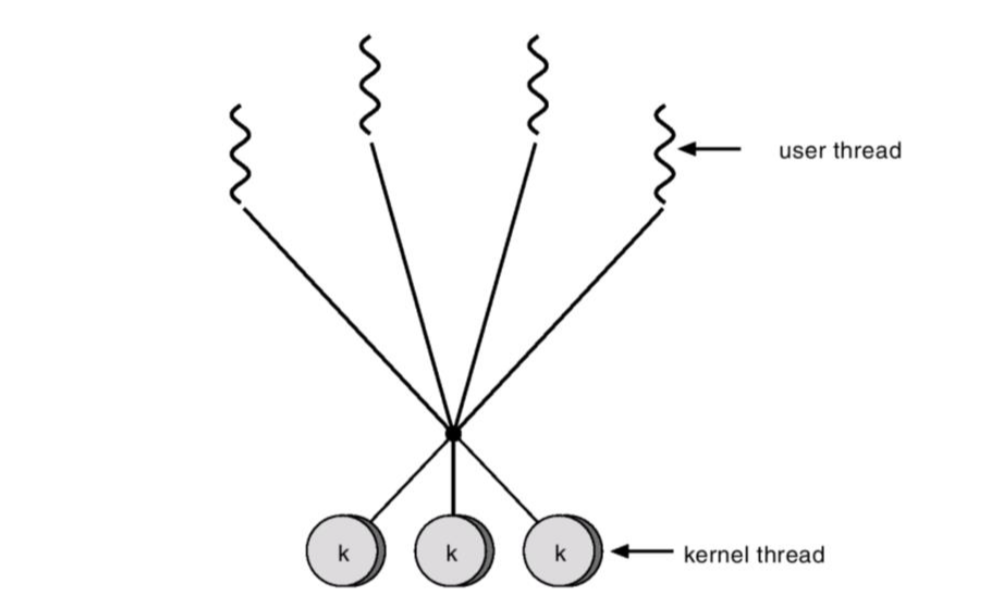
여러 사용자 스레드가 같거나 더 적은 수의 커널 스레드에 매핑된다. 다대일 모델과 일대일 모델의 절충안(Compromise) 이다.
두 수준 모델 (Two-level Model)
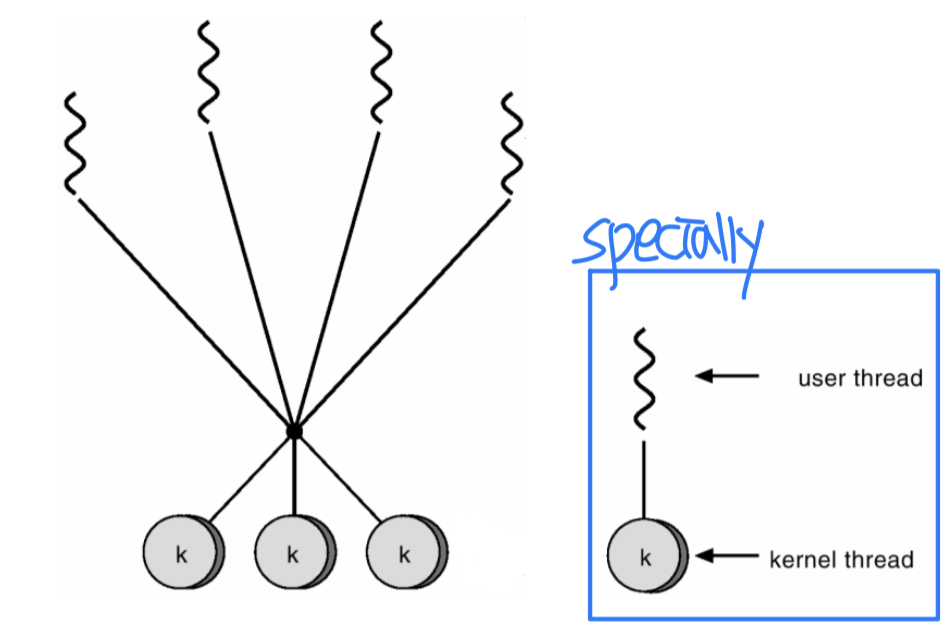
기본적으로 N:M 모델의 변형이다. 다대다 매핑을 기본으로 하되, 특정 사용자 스레드를 커널 스레드에 직접 바인딩할 수도 있다.
예시: IRIX, HP-UX, Tru64, Solaris (8 이하)
스케줄러 활성화와 LWP
다대다 모델과 두 수준 모델에서는 커널과 스레드 라이브러리 간의 통신이 필요하다. 스케줄러 활성화(Scheduler Activation) 는 이 통신을 위한 메커니즘 중 하나다.
이 모델들에서 사용자 스레드와 커널 스레드는 LWP(Lightweight Process) 를 통해 연결된다.
LWP는 사용자 스레드와 커널 스레드를 연결하는 데이터 구조로, 일종의 주문서와 같은 역할을 한다. 기본적으로 하나의 LWP가 하나의 커널 스레드에 대응하며(예외도 존재), 사용자 수준 스레드 라이브러리 입장에서 LWP는 가상 프로세서(Virtual Processor) 처럼 보인다.
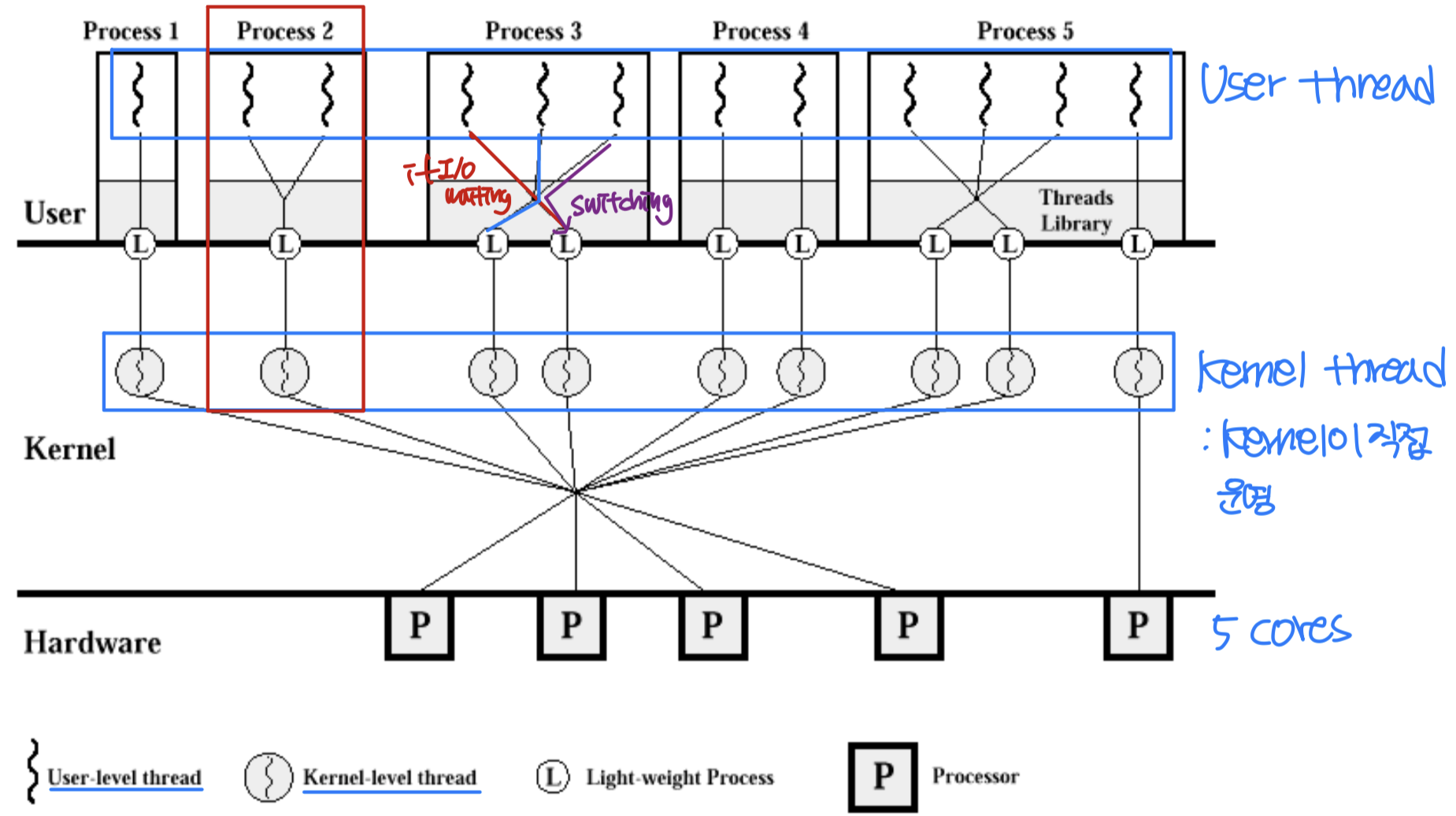
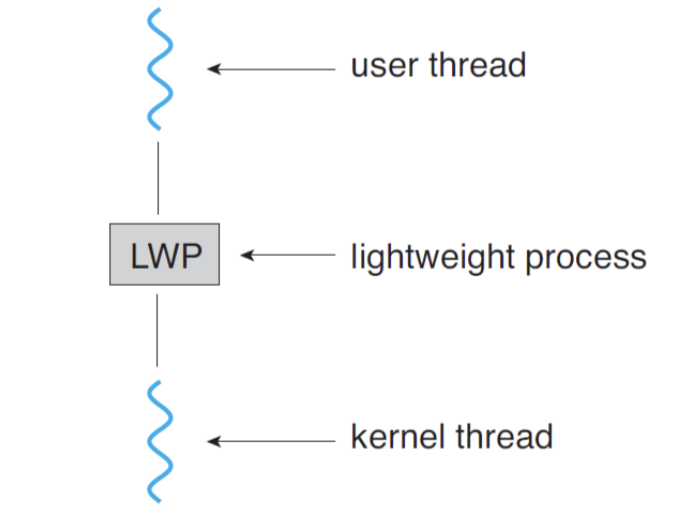
동작 방식은 다음과 같다.
- 커널이 가상 프로세서(LWP) 집합을 제공한다
- 사용자 수준 스레드 라이브러리가 사용자 스레드를 가상 프로세서에 스케줄링한다
- 커널 스레드가 블록되거나 언블록되면, 커널이 스레드 라이브러리에 이를 알린다. 이를 업콜(Upcall) 이라 한다
- Upcall 핸들러가 적절히 스케줄링한다
- 커널 스레드가 블록되면: 해당 LWP를 다른 스레드에 할당
- 커널 스레드가 언블록되면: LWP를 다시 할당
스레드 라이브러리
스레드 라이브러리(Thread Library) 는 스레드를 생성하고 관리하기 위한 API 집합이다. 구현 방식에 따라 두 가지로 나뉜다.
- 사용자 수준 라이브러리: 커널 지원 없이 사용자 공간에서 동작
- 커널 수준 라이브러리: 커널의 스케줄러 자체가 역할을 수행
주요 스레드 라이브러리는 다음과 같다.
- POSIX Pthreads: 가장 널리 사용되는 스레드 표준
- 과거: LinuxThreads
- 현재: NPTL (Native POSIX Thread Library)
- GNU Portable Threads
- Open source Pthreads for Win32
- Win32 threads
- Java threads
POSIX Pthreads



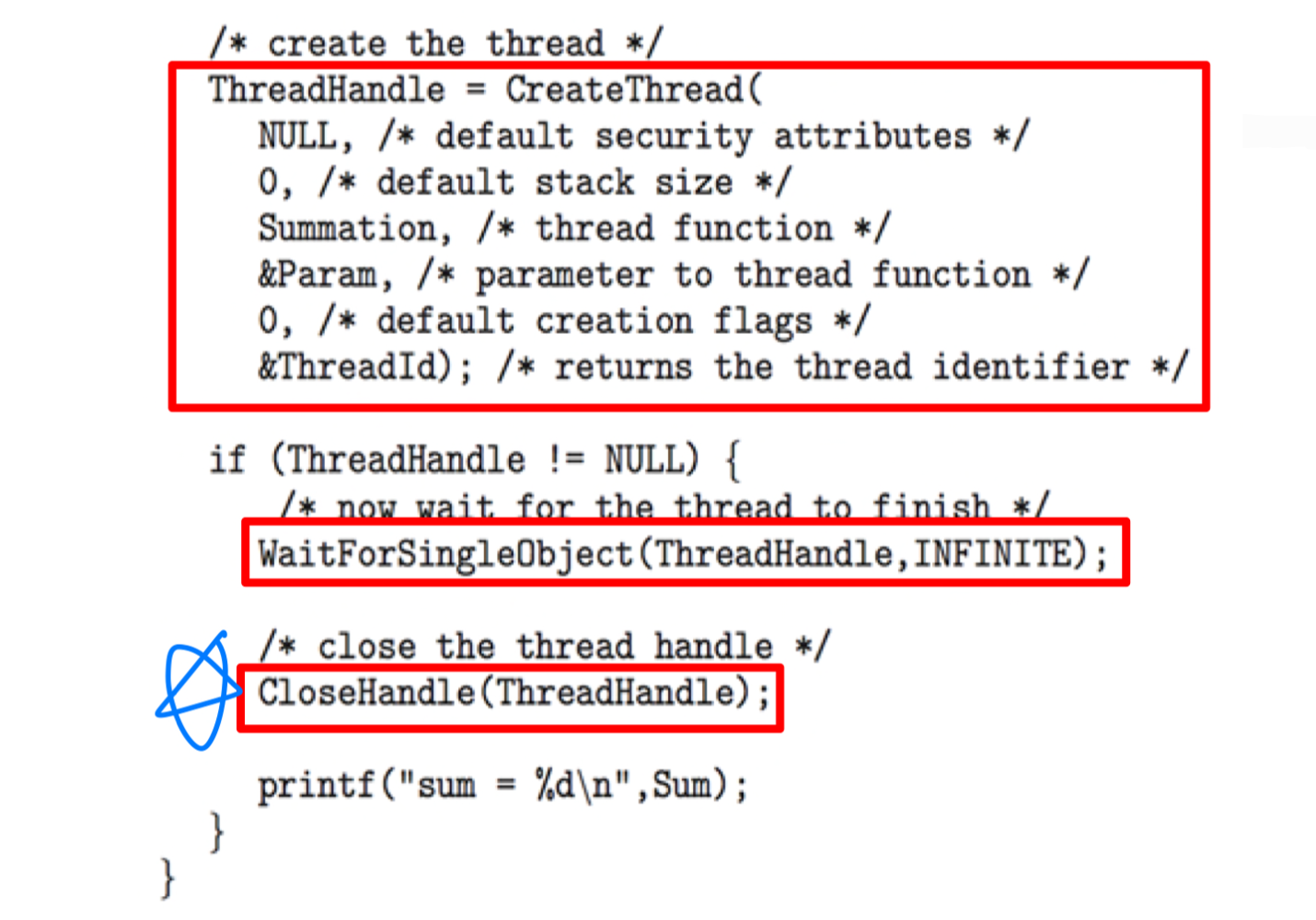
Windows Threads


Java Threads
Java 스레드는 JVM(Java Virtual Machine) 이 관리한다. 일반적으로 하위 OS가 제공하는 스레드 모델을 기반으로 구현된다.
Java에서 스레드를 생성하는 방법은 두 가지다.
- Thread 클래스를 확장(extends) 하는 방법
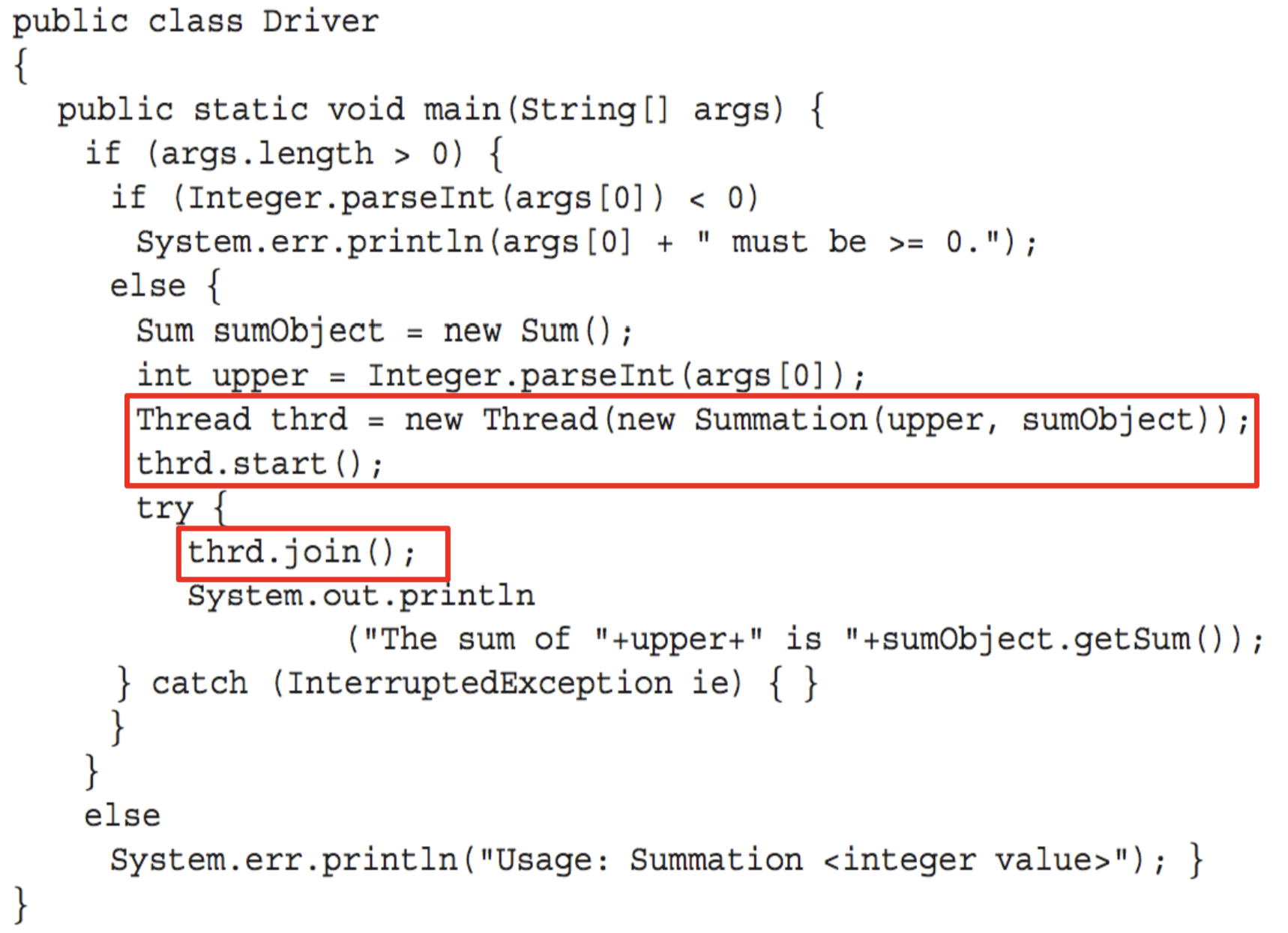
- Runnable 인터페이스를 구현(implements) 하는 방법 - 다중 인터페이스 구현이 가능하므로 더 유연하다
Thread 클래스 사용

Runnable 인터페이스 사용

실행 예제

암묵적 스레딩 (Implicit Threading)
암묵적 스레딩은 스레드의 생성과 관리를 프로그래머가 아닌 컴파일러와 런타임 라이브러리가 담당하는 방식이다. 대표적인 방법 세 가지가 있다.
- Thread Pools
- OpenMP
- Grand Central Dispatch
이외에도 Microsoft Threading Building Blocks(TBB), java.util.concurrent 패키지 등이 있다.
스레드 풀 (Thread Pool)
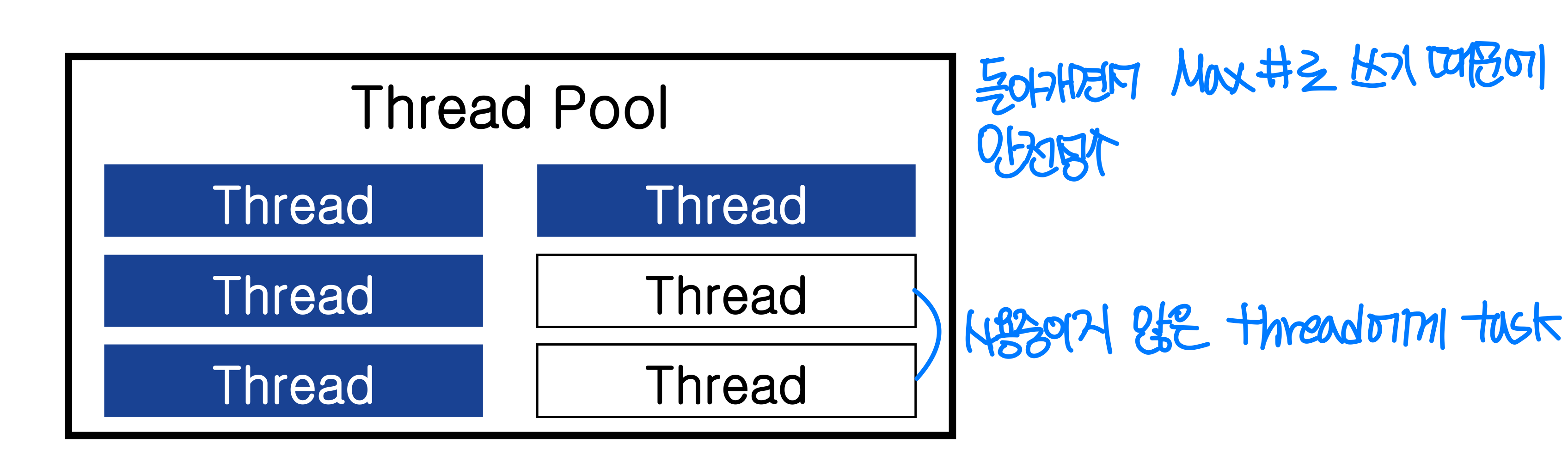
스레드 풀은 미리 일정 수의 스레드를 생성해 두고, 작업이 들어오면 대기 중인 스레드에 할당하는 방식이다.
장점:
- 새 스레드를 생성하는 것보다 기존 스레드를 재사용하는 것이 약간 더 빠르다
- 스레드 수를 풀의 크기로 제한할 수 있어 자원 관리가 용이하다
- 태스크 실행과 스레드 생성 메커니즘을 분리하여 다양한 실행 전략을 적용할 수 있다
- 예를 들어 태스크를 주기적으로 실행하도록 스케줄링할 수 있다
OpenMP
OpenMP는 공유 메모리 환경에서의 병렬 프로그래밍을 지원하는 도구다. C, C++, FORTRAN용 컴파일러 지시어(Directive)와 API를 제공하며, 병렬 실행 가능한 코드 블록(병렬 영역, Parallel Region) 을 식별하여 자동으로 병렬화한다.
컴파일 명령: gcc -fopenmp main.c

위 예제에서 볼 수 있는 루프 언롤링(Loop Unrolling) 은 루프를 작은 반복으로 분해하고 다른 코어에서 동시에 실행하여 성능을 향상시키는 기법이다.
스레드 관련 이슈
fork()와 exec()
멀티스레드 프로세스에서 fork()를 호출하면 어떻게 될까?
- 프로세스의 모든 스레드를 복제하는가?
fork()를 호출한 해당 스레드만 복제하는가?
UNIX는 두 가지 버전의 fork를 지원한다.
fork(): 프로세스 내 모든 스레드를 복사한다fork1():fork()를 호출한 현재 스레드만 복사한다
예를 들어 3개의 스레드를 가진 프로세스에서 fork()를 호출하면 3개의 스레드가 모두 복사된다.
반면 exec()는 전체 프로세스를 새 프로그램으로 대체하므로 모든 스레드가 사라진다.
스레드 취소 (Thread Cancellation)
스레드 취소란 스레드가 완료되기 전에 강제로 종료하는 것이다.
pthread_cancel(tid) 함수를 사용하며, 이 호출은 즉시 스레드를 죽이는 명령이 아니라 취소 요청을 보내는 것이다.
스레드 취소의 문제점은 스레드가 다른 스레드와 자원을 공유한다는 점이다. 프로세스는 자체 자원을 보유하므로 종료해도 비교적 안전하지만, 스레드는 공유 데이터를 갱신하는 도중에 취소될 수 있어 프로세스보다 더 주의가 필요하다.
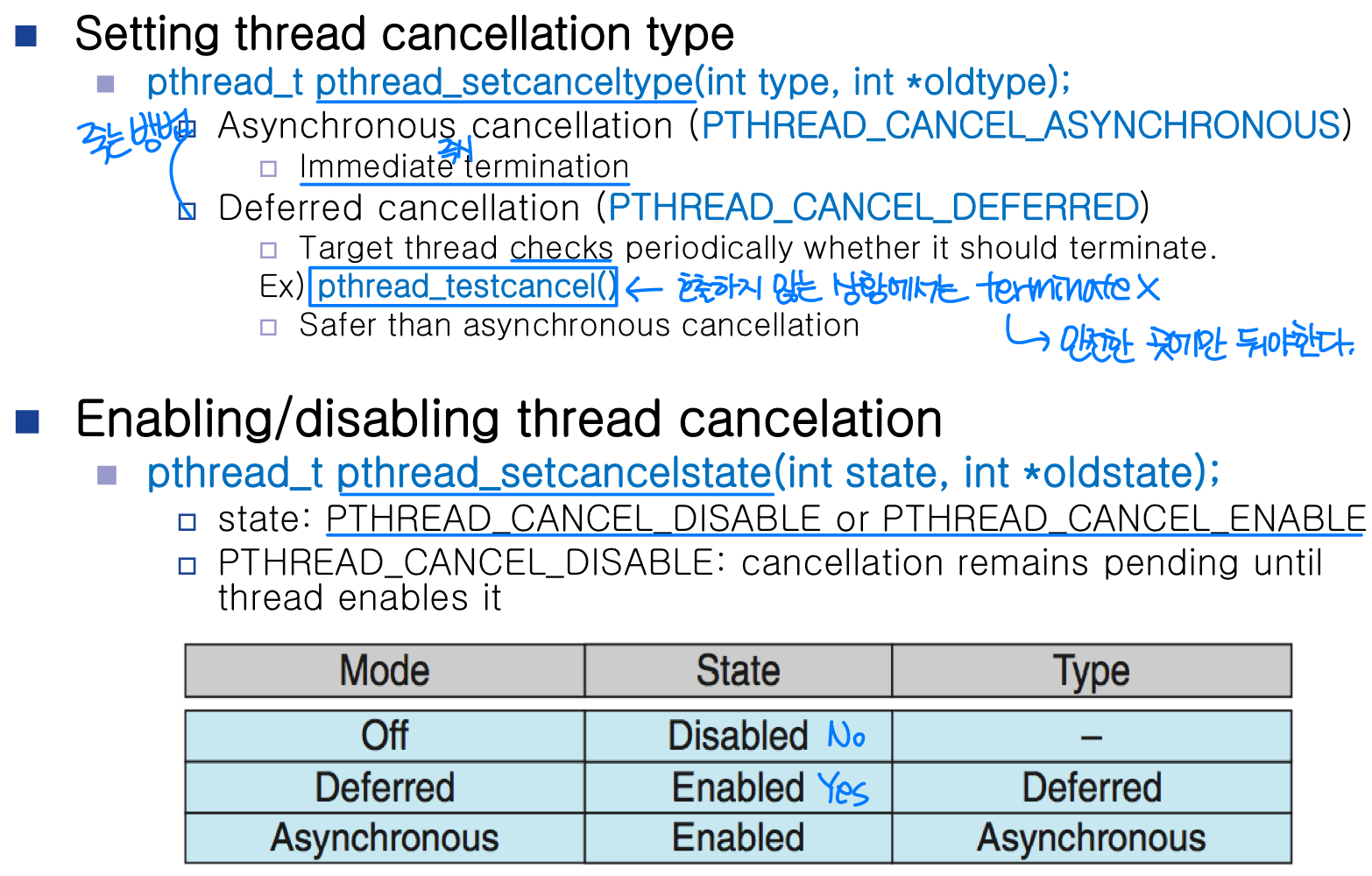
취소 유형 중 Deferred(지연) 취소에서 Disable 상태로 설정하면, Enable할 때까지 취소가 보류 상태로 유지된다.
시그널 처리 (Signal Handling)
시그널(Signal) 은 UNIX에서 프로세스에게 특정 이벤트가 발생했음을 알리는 메커니즘이다. 커널 모드의 인터럽트와 달리, 시그널은 사용자 모드에서 이벤트를 처리한다.
시그널의 동작 과정은 다음과 같다.
- 다양한 소스에서 시그널이 생성된다
- 시그널이 프로세스에 전달된다
- 프로세스가 시그널을 처리한다 - 기본 시그널 핸들러(커널 제공) 또는 사용자 정의 핸들러를 통해
시그널의 종류:
- 동기(Synchronous) 시그널: 같은 프로세스 내부에서 발생한다. 예를 들어 잘못된 메모리 접근이나 0으로 나누기 등이다.
- 비동기(Asynchronous) 시그널: 외부 소스에서 발생한다. 예를 들어
Ctrl+C입력 시 시그널 핸들러가 실행되어 프로세스가 종료된다.
운영체제는 시그널을 통해 실행 중인 프로그램에 예외 상황을 보고한다. 시그널은 UNIX 및 POSIX 호환 운영체제에서 사용되는 제한적인 형태의 IPC(Inter-Process Communication) 이며, 본질적으로 프로세스에 이벤트 발생을 알리는 비동기 통지(Notification) 다.


멀티스레드 환경에서의 문제: 어떤 스레드에 시그널을 전달해야 하는가?
가능한 옵션은 네 가지다.
- 시그널이 적용되는 해당 스레드에 전달
- 프로세스 내 모든 스레드에 전달
- 특정 스레드들에만 전달
- 모든 시그널을 수신할 전담 스레드를 지정
어떤 방식을 택할지는 시그널의 종류에 따라 달라진다. 특정 스레드에 시그널을 보내는 방법으로 POSIX에서는 pthread_kill(tid, signal) 함수를 사용할 수 있다. 참고로 pthread_kill은 시그널을 전달하는 것이며, 스레드를 종료시키려면 pthread_cancel을 사용한다.
스레드 로컬 저장소 (Thread-Local Storage)
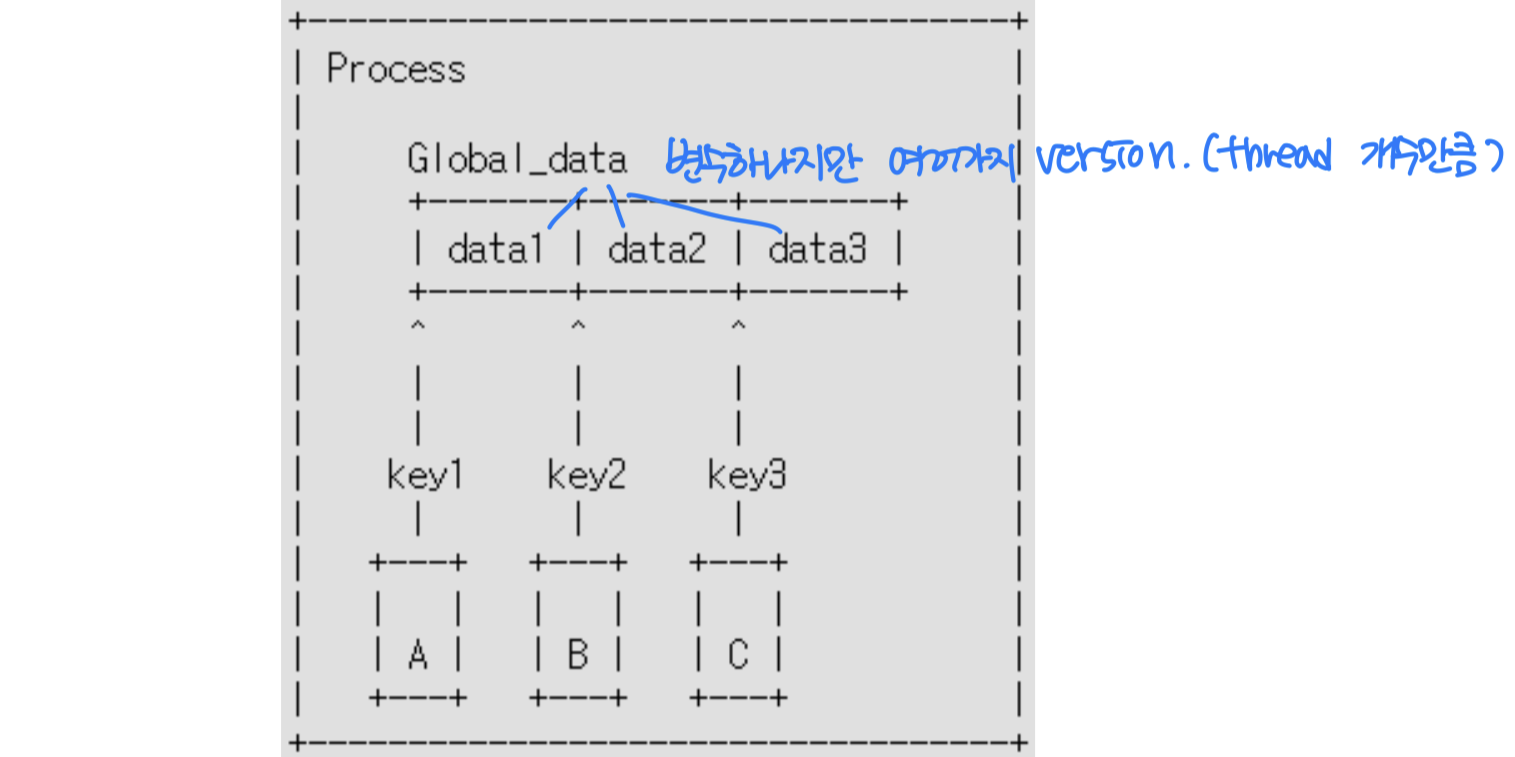
프로세스 내에서 모든 스레드는 전역 변수를 공유한다. 하지만 때로는 스레드마다 독립적인 데이터가 필요한 경우가 있다. 이를 위한 것이 스레드 로컬 저장소(TLS, Thread-Local Storage) 다.
많은 운영체제가 스레드 고유 데이터를 지원하며, 예를 들어 각 스레드에 고유한 키를 할당하는 방식으로 구현된다.
참고로 thread_demo2.c 예제에서는 main의 avg 배열(지역 변수)을 자식 스레드가 주소로 접근하는 방식을 사용한다. 이는 join으로 main이 자식 스레드를 기다리기 때문에 가능하다.
TLS는 각 스레드가 자신만의 데이터 복사본을 가질 수 있게 한다.
__thread int tls; // pthread에서의 TLS 선언위와 같이 선언하면 각 스레드가 자신만의 tls 변수를 갖게 된다.
TLS와 지역 변수의 차이:
| 구분 | 지역 변수 (Local Variable) | TLS |
|---|---|---|
| 수명 | 함수 호출 시 생성, 종료 시 소멸 | 함수 호출이 끝나도 스레드에서 유지 |
| 범위 | 단일 함수 내에서만 유효 | 함수 호출을 넘어서도 유효 |
TLS와 static 변수의 차이:
static 변수는 파일 내에서 전역적으로 사용되지만, TLS는 각 스레드에 고유하다. static은 모든 스레드가 공유하지만, TLS는 스레드마다 독립적인 복사본을 가진다.
TLS는 스레드 생성 과정을 직접 제어할 수 없는 경우, 특히 스레드 풀을 사용할 때 유용하다. 스레드 풀에서 작업자 스레드를 관리하면서도 스레드 간 변수의 값을 안전하게 유지할 수 있기 때문이다.


스케줄러 활성화 (Scheduler Activation)
앞서 멀티스레딩 모델 절에서 다룬 내용과 동일하다.
HGU 전산전자공학부 김인중 교수님의 23-1 운영체제 수업을 듣고 작성한 포스트이며, 첨부한 모든 사진은 교수님 수업 PPT의 사진 원본에 필기를 한 수정본입니다.