프로세스란?
프로세스(Process) 란 실행 중인 프로그램(program in execution) 과 그에 할당된 자원(resource) 을 합친 개념이다.
프로그램이 디스크에 저장된 정적인 파일이라면, 프로세스는 그 프로그램이 메모리에 올라가 CPU를 사용하며 실제로 동작하는 상태를 말한다.
프로세스 상태(Process State)
프로세스는 생성부터 종료까지 다음 다섯 가지 상태를 거친다.
- New: 프로세스가 생성되는 중
- Running: CPU에서 실행 중 (한 프로세서에서 동시에 실행되는 프로세스는 하나뿐이다)
- Ready: CPU 할당을 기다리는 상태
- Waiting: 특정 이벤트(I/O 완료 등)가 발생하기를 기다리는 상태
- Terminated: 실행이 종료된 상태
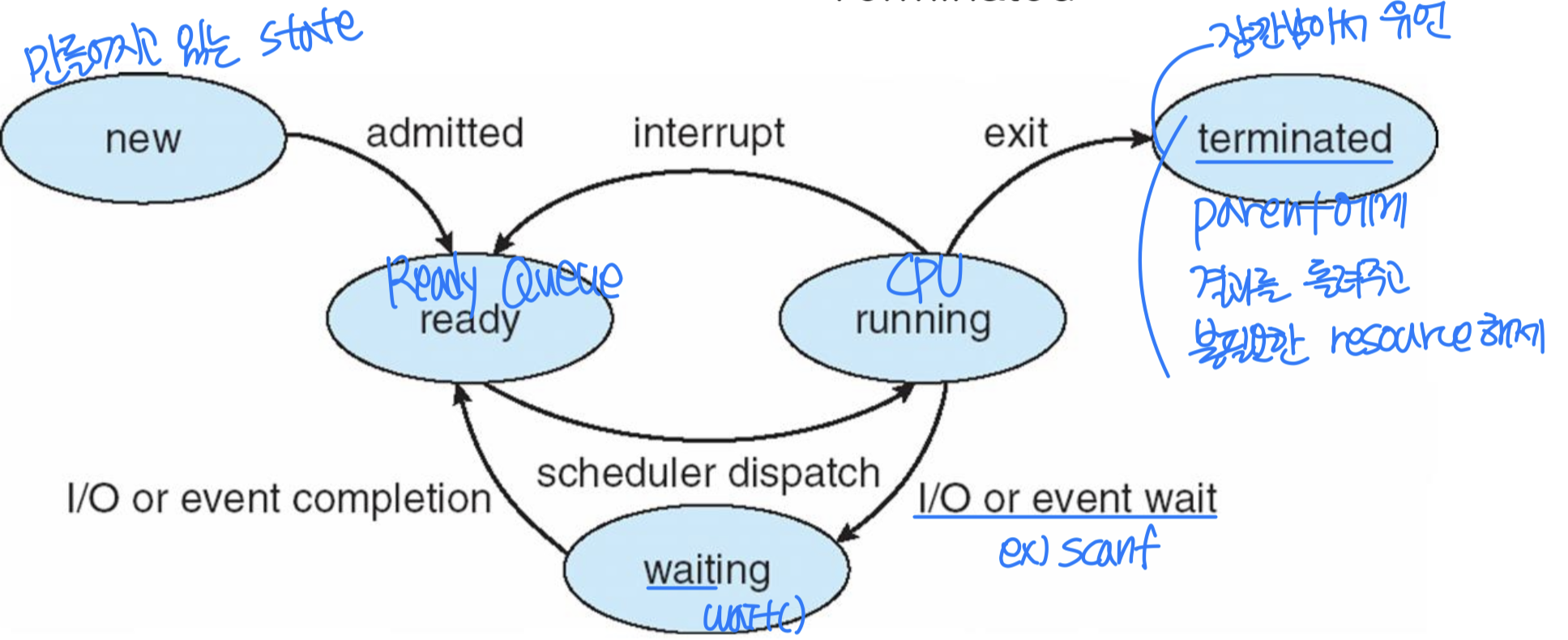
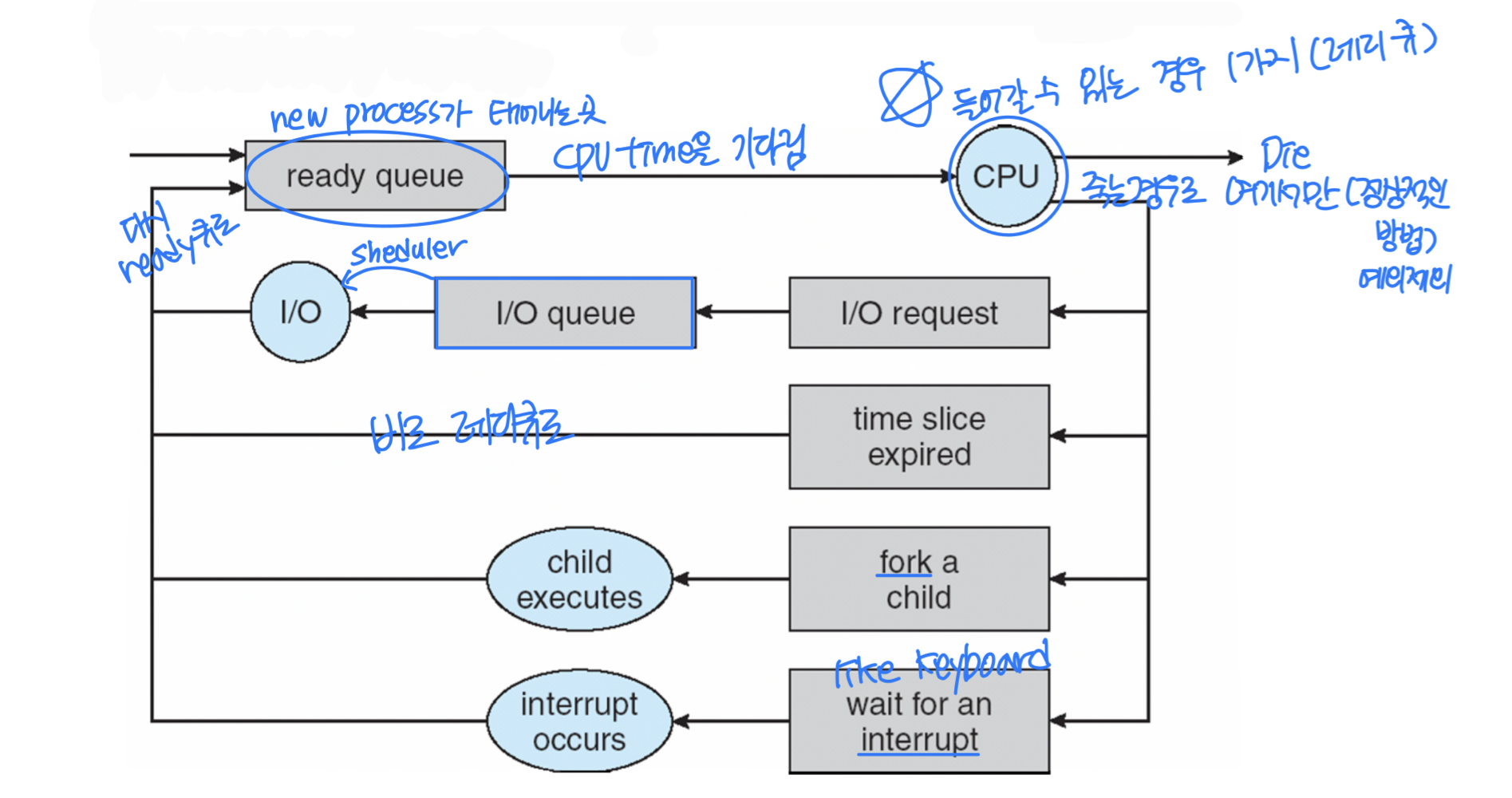
Ready 상태와 Running 상태 사이의 전환은 다음과 같이 이루어진다.
프로세스 제어 블록(PCB)
PCB(Process Control Block) 는 OS가 프로세스를 관리하기 위해 사용하는 자료구조다. 주민등록등본처럼, 프로세스에 대한 모든 정보가 담긴 저장소라고 생각하면 된다.
OS는 트리 구조로 PCB를 관리하며, 프로세스의 상태, 프로그램 카운터, 레지스터 값, 메모리 정보 등이 PCB에 저장된다.

프로세스 스케줄링
스케줄링이란?
스케줄링(Scheduling) 은 자원에 작업을 할당하는 행위이며, 본질은 "선택(Select)" 이다.
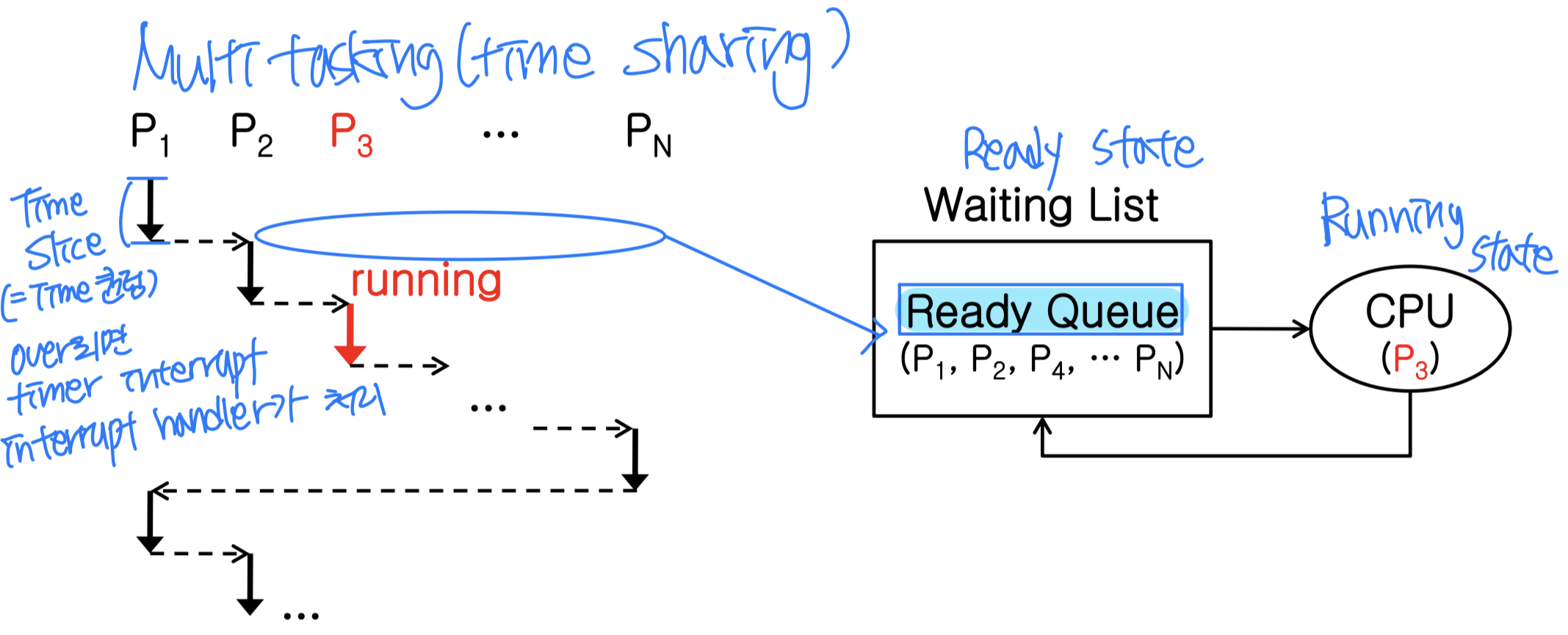
프로세스 스케줄링은 CPU에서 실행할 프로세스를 선택하는 과정이다. 한 프로세서에서는 한 번에 하나의 프로세스만 실행할 수 있으므로, 나머지 프로세스는 대기해야 한다.
스케줄링의 목표는 두 가지다.
- CPU 활용률 극대화: CPU가 가능한 한 쉬지 않고 일하게 만든다
- 사용자 상호작용 보장: 사용자가 각 프로그램과 원활하게 교류할 수 있어야 한다
프로세스 간 전환(switching)에는 트레이드오프가 있다. 성능 관점에서는 전환을 적게 할수록 좋지만, 응답성 관점에서는 전환을 자주 할수록 좋다. 로봇이나 자율주행처럼 빠른 반응이 필요한 시스템에서는 응답성이 더 중요하다.
스케줄링 큐(Scheduling Queue)
스케줄링 큐는 CPU 시간이나 기타 자원을 기다리는 프로세스의 대기 목록이다.
- Ready Queue: CPU 할당을 기다리는 프로세스 큐
- Job Queue: 시스템의 모든 프로세스 큐
- Device Queue: I/O 장치를 기다리는 프로세스 큐
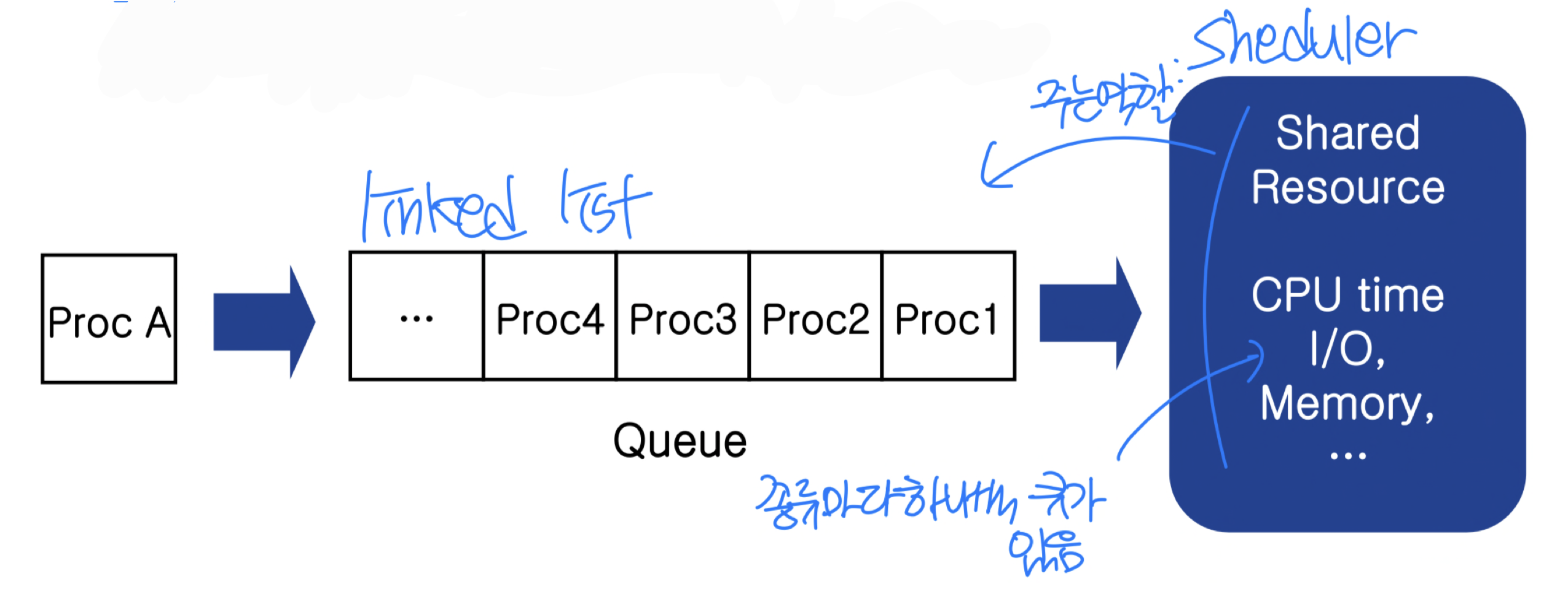
각 큐는 보통 PCB의 연결 리스트(Linked List) 로 구현된다.
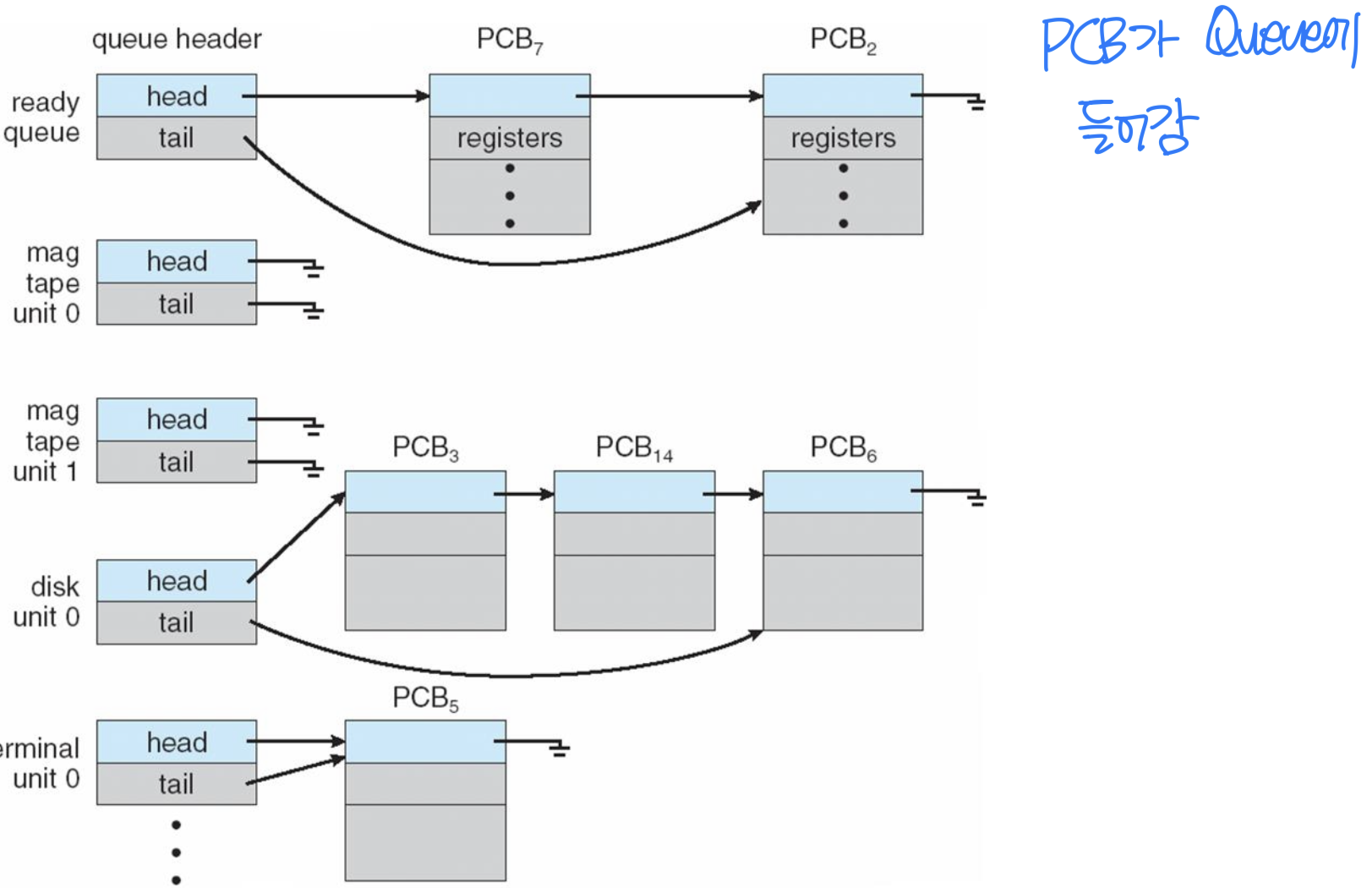
큐잉 다이어그램(Queueing Diagram)
프로세스 스케줄링의 흐름을 시각적으로 나타낸 것이다. 프로세스는 생애 주기 동안 여러 스케줄링 큐 사이를 이동한다.
스케줄러(Schedulers)
스케줄러는 큐에서 프로세스를 선택하는 역할을 한다. 크게 장기 스케줄러와 단기 스케줄러로 나뉜다.
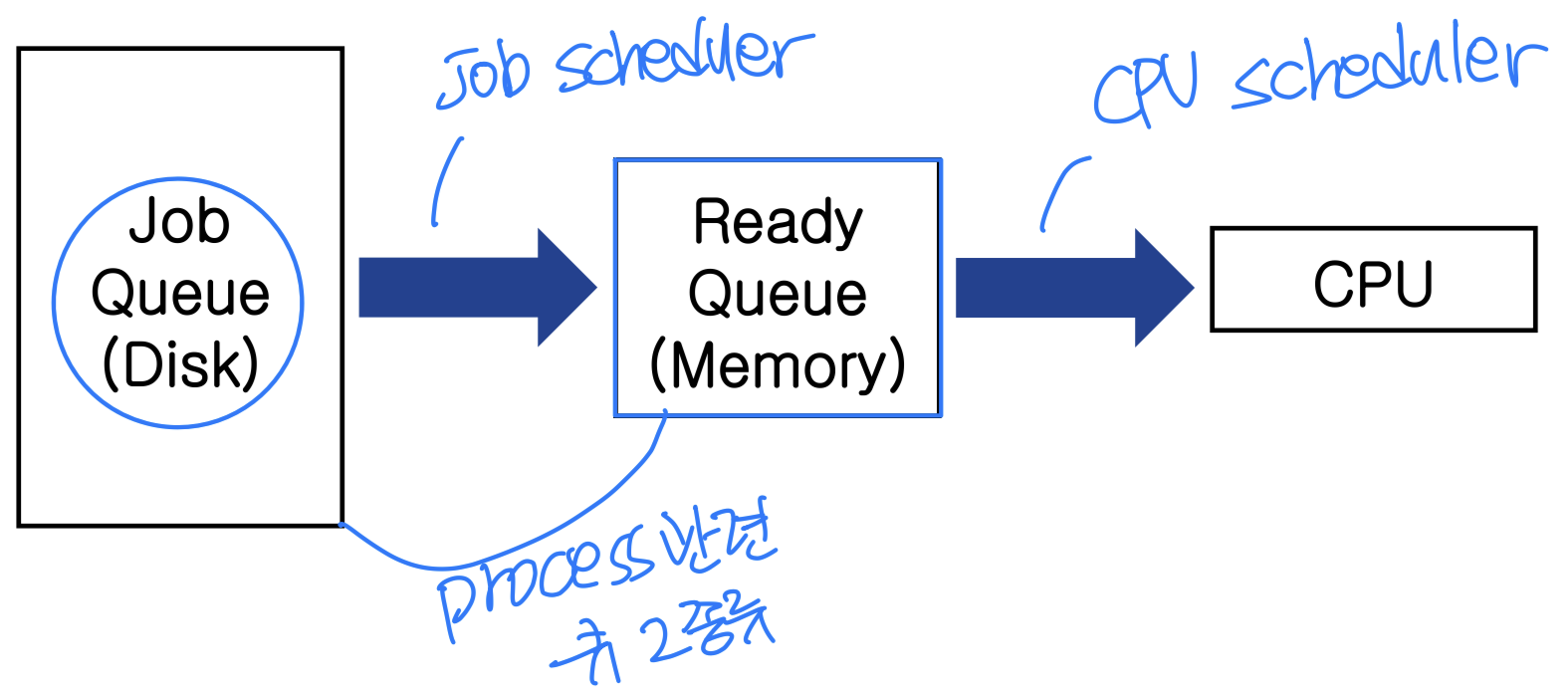
1. 단기 스케줄러(Short-term Scheduler, CPU Scheduler)

최소 100ms마다 한 번씩 실행될 정도로 매우 자주 호출된다. 그래서 알고리즘 자체가 단순할 수밖에 없다. 스케줄링에 걸리는 시간은 가능한 짧아야 한다.
2. 장기 스케줄러(Long-term Scheduler, Job Scheduler)

레디 큐의 크기를 조절하는 역할을 한다. 가끔씩만 실행되므로, 프로세스가 시스템을 떠날 때만 동작해도 충분하다.
- 다중 프로그래밍의 정도(Degree of Multiprogramming) , 즉 레디 큐의 크기를 제어한다
- 안정 상태에서는 프로세스 생성률과 이탈률이 같아야 한다
- I/O 바운드 프로세스와 CPU 바운드 프로세스를 적절히 섞어서 선택하는 것이 이상적이다
- I/O 바운드: Vim, Word, cmd 등 I/O에 시간을 많이 쓰는 프로세스
- CPU 바운드: 컴파일러, 동영상 인코더 등 CPU 연산이 많은 프로세스
실제로 UNIX, Windows 같은 시스템에서는 장기 스케줄러가 없거나 최소한으로만 존재한다. 이 경우 시스템 안정성은 물리적 제약이나 사용자의 자기 조절(불필요한 프로그램을 사용자가 직접 끄는 것)에 의존한다.
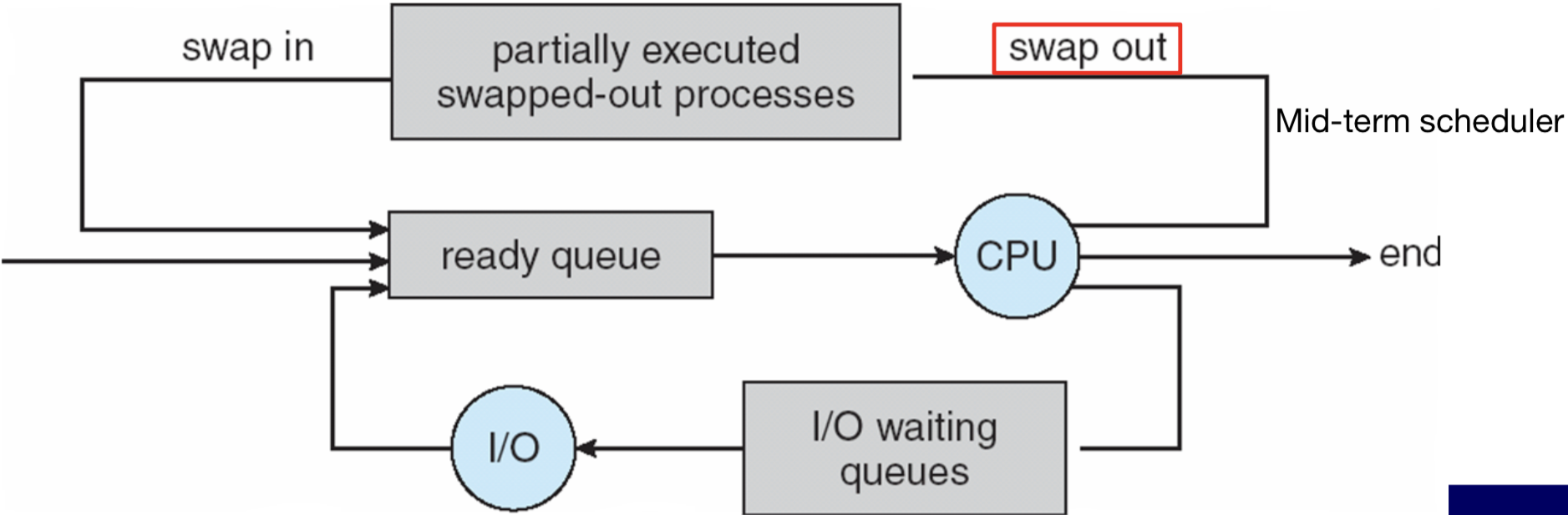
일부 시분할 시스템에서는 중기 스케줄러(Medium-term Scheduler) 를 두어, 메모리에서 프로세스를 제거하여 다중 프로그래밍 정도를 줄이기도 한다.
컨텍스트 스위치(Context Switch)
실행 중인 프로세스를 전환하려면 컨텍스트 스위치가 필요하다. 현재 프로세스의 상태(컨텍스트)를 PCB에 저장하고, 다음 프로세스의 상태를 복원하는 과정이다.
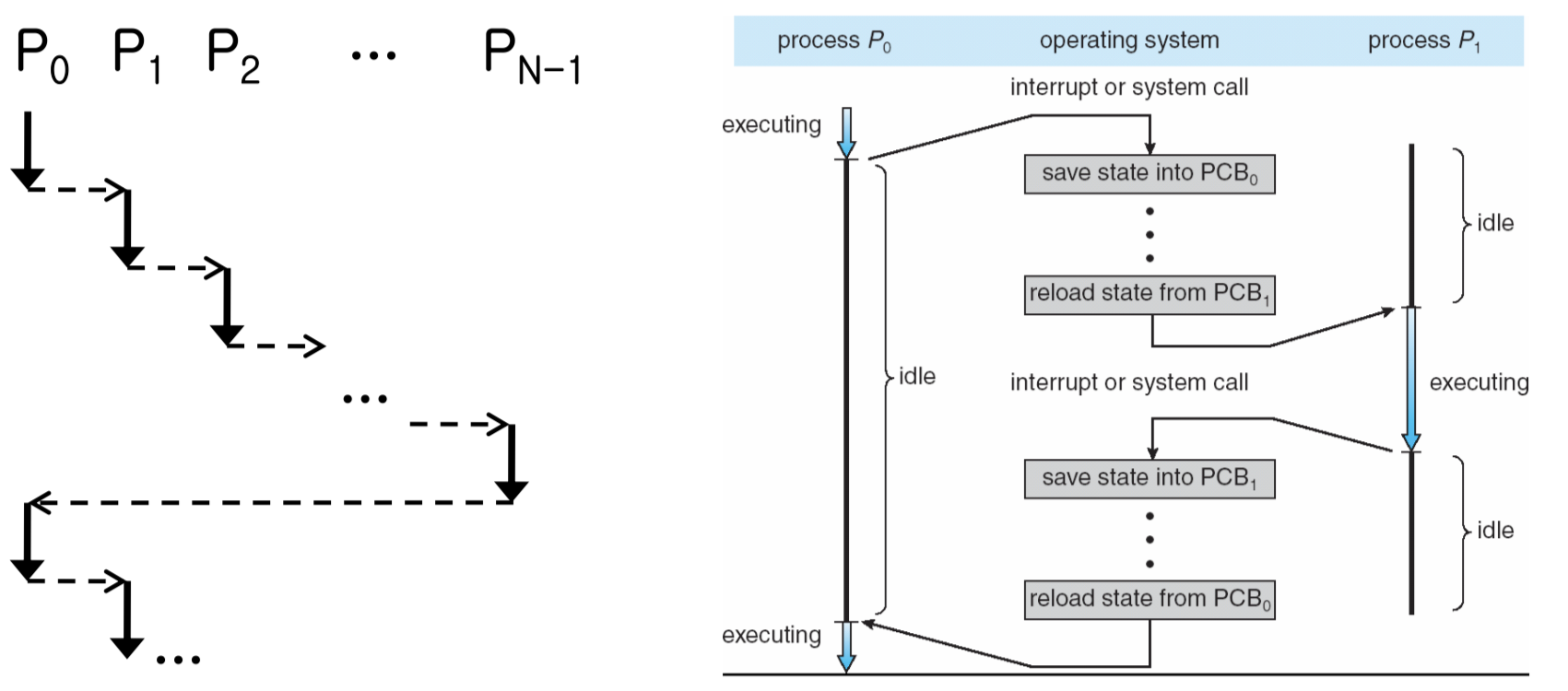
컨텍스트 스위치란, 여러 프로세스가 단일 CPU 자원을 공유할 수 있도록 CPU의 상태(컨텍스트)를 저장하고 복원하는 과정을 말한다.
컨텍스트에 포함되는 항목은 다음과 같다.
- 레지스터 내용
- OS 관련 데이터: 페이지 테이블, 세그먼트 테이블 등 고급 메모리 관리 기법에 필요한 데이터
컨텍스트 스위치가 발생하는 시점은 멀티태스킹 상황이나 인터럽트 처리 시점이다.
컨텍스트 스위치는 상당한 오버헤드를 수반한다. 이를 줄이기 위한 하드웨어 지원 방법이 있다.
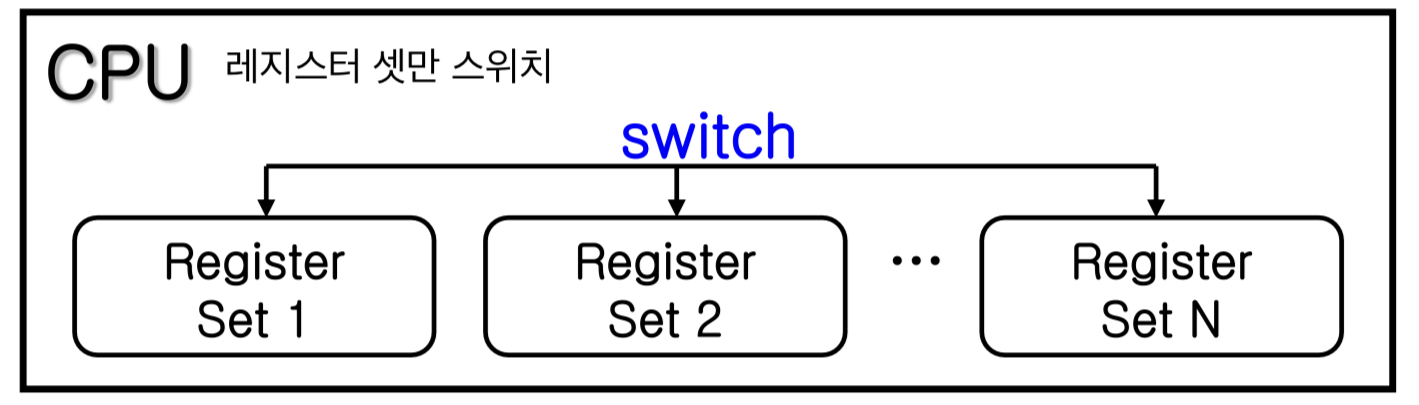
- H/W 스위칭: 모든 레지스터를 한 명령어로 저장/복원하는 방식
- 다중 레지스터 세트: 빠른 전환을 위해 여러 세트의 레지스터를 두는 방식 (예: UltraSPARC)
다만 S/W 스위칭은 실제로 저장이 필요한 부분만 선택적으로 처리할 수 있다는 장점이 있어, 두 방식 모두 널리 쓰이지는 않는다.
프로세스 연산
프로세스 생성(Process Creation)
프로세스 생성 시스템 콜은 프로세스를 만들고 pid(process ID) 를 부여한다.

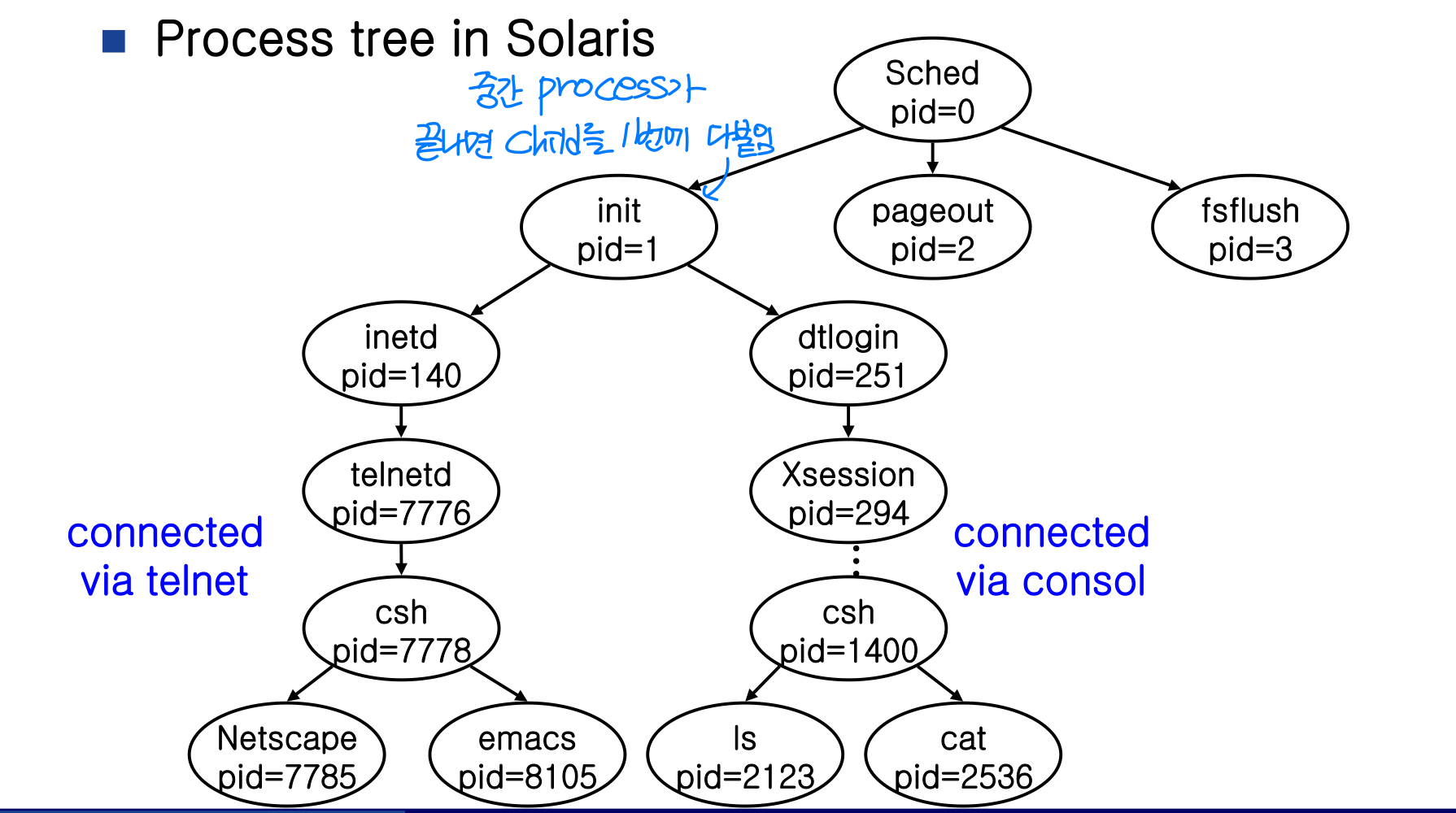
프로세스 간에는 부모-자식 관계가 형성되어 프로세스 트리를 이룬다.
UNIX에서의 프로세스 생성
UNIX에서 프로세스 생성에 사용되는 핵심 시스템 콜은 세 가지다.
fork(): 프로세스를 생성하고 pid를 반환한다- 부모 프로세스에서의 반환값: 자식의 pid
- 자식 프로세스에서의 반환값: 0
- 오류 시: 음수 값 반환
exec()계열: 프로그램을 실행한다. 새 프로그램이 기존 프로그램을 대체한다execl(),execv(),execlp(),execvp(),execle(),execve()
wait(): 자식 프로세스가 종료될 때까지 대기한다
프로세스 생성 예시


fork() 상세
자식 프로세스의 자원은 다음과 같이 결정된다.
데이터(변수): 부모 프로세스 변수의 복사본을 갖는다. 자식 프로세스는 독립된 주소 공간을 가지며, 유일한 차이는 fork()가 반환하는 자식의 pid 값뿐이다.
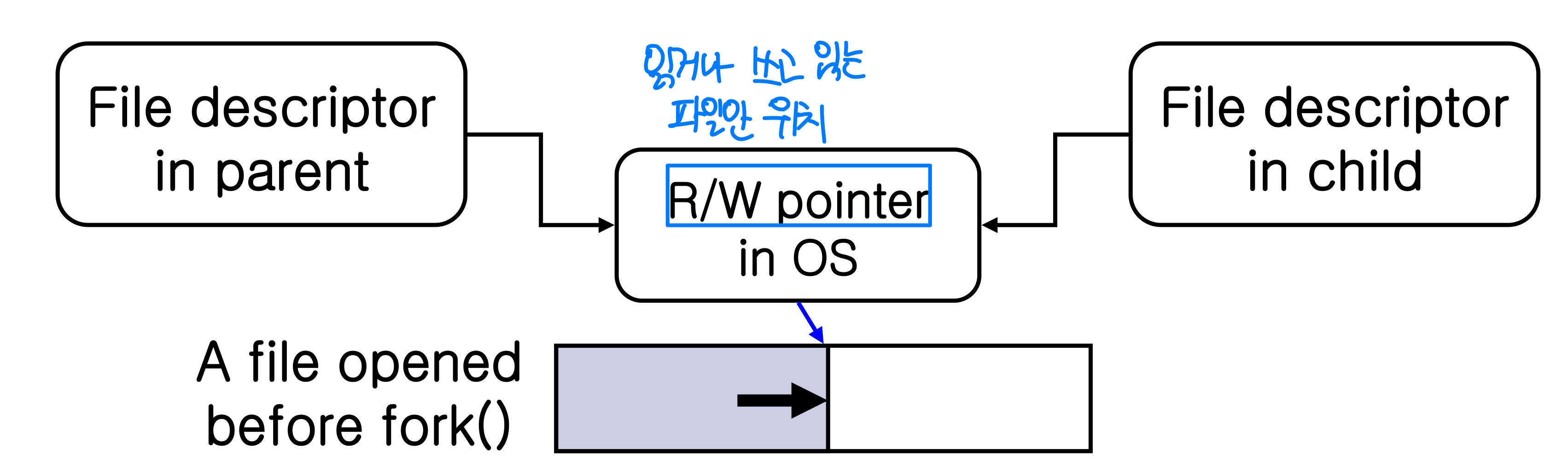
파일:
fork()이전에 열린 파일: 부모와 공유fork()이후에 열린 파일: 공유하지 않음
exec 계열 상세
exec 계열 함수는 <unistd.h>에 선언되어 있다.
intexecl(const char *path, const char *arg0, ..., const char *argn, (char *)NULL)--l은 list를 의미intexecv(const char *path, char *const argv[])--v는 vector를 의미.argv[]의 마지막은 NULLintexeclp(const char *file, const char *arg0, ..., const char *argn, (char *)NULL)--p가 붙으면 PATH 환경변수 자동 검색intexecvp(const char *file, char *const argv[])--p가 붙으면 PATH 환경변수 자동 검색execle(),execve(): 환경변수(environment)를 지정할 수 있는 버전
wait() 상세
pid_t wait(int *stat_loc);stat_loc은 정수 포인터로, 다음과 같이 동작한다.
stat_loc이 NULL이면 무시된다- 그렇지 않으면 자식 프로세스의 상태 정보를 받는다
- 부모:
wait(&stat); - 자식:
exit(code); code값이stat으로 전달되며, 부모에서code == (stat >> 8) & 0xff로 복원한다
- 부모:
반환값은 다음과 같다.
- 종료된 자식의 pid
- -1: 자식 프로세스가 없음을 의미
Win32에서의 프로세스 생성
CreateProcess(): UNIX의fork()+exec()와 유사하지만, 자식 프로세스의 속성을 지정하는 파라미터가 훨씬 많다WaitForSingleObject(): UNIX의wait()와 유사하며, 프로세스 또는 스레드 대기에 사용된다ZeroMemory(PVOID Destination, SIZE_T Length): 메모리 블록을 0으로 채운다
프로세스 종료(Process Termination)
프로세스가 정상 종료되면 exit(int return_code)를 호출한다. 이때 다음과 같은 정리 작업이 수행된다.
- 메모리 해제(Deallocate memory)
- 파일 닫기(Close files)
return_code는 부모 프로세스에 전달된다. 관례상 0은 성공을 의미한다. 부모는 다음과 같이 자식의 반환 코드를 읽을 수 있다.
int status = 0;
wait(&status); // 자식이 종료될 때까지 대기
ret = WEXITSTATUS(status); // 자식의 return_code 추출멀티프로세스 아키텍처 -- Chrome 브라우저
과거 대부분의 웹 브라우저는 단일 프로세스로 동작했다. 이 경우 하나의 웹 사이트에 문제가 생기면 브라우저 전체가 멈추거나 충돌할 수 있었다.
Google Chrome은 이를 해결하기 위해 멀티프로세스 아키텍처를 도입했으며, 세 종류의 프로세스를 사용한다.
- Browser 프로세스: 사용자 인터페이스, 디스크 및 네트워크 I/O를 관리한다
- Renderer 프로세스: 웹 페이지를 렌더링하며, HTML/CSS 파싱과 JavaScript 실행을 담당한다. 열린 각 웹 사이트마다 새로운 렌더러가 생성된다
- Plug-in 프로세스: 각 플러그인 유형마다 별도로 생성된다

각 탭이나 창마다 고유한 렌더러 프로세스가 생성되므로, 하나의 웹 사이트에서 발생한 문제가 다른 웹 사이트에 영향을 주지 않는다.
프로세스 간 통신(IPC)
IPC(Inter-Process Communication) 의 목적은 프로세스 간의 협력(Cooperation) 이다.
- 정보 공유: 공유 파일 등
- 계산 속도 향상: 여러 CPU나 I/O를 활용
- 모듈성: 시스템 기능을 분리
- 편리성: 편집, 인쇄, 컴파일을 병렬로 수행
IPC 모델은 크게 두 가지로 나뉜다.
- 메시지 패싱(Message Passing) 모델
- 공유 메모리(Shared Memory) 모델
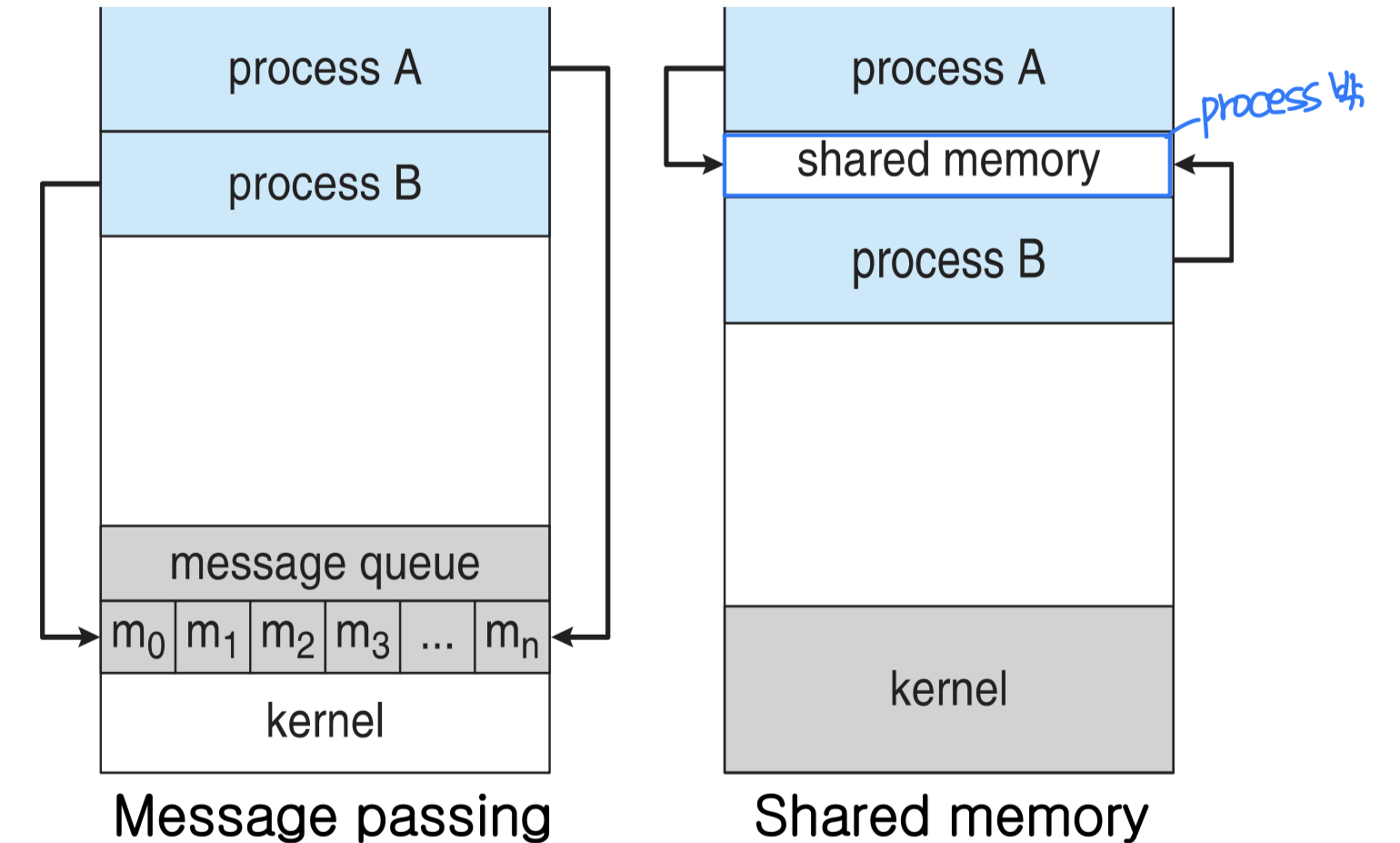
공유 메모리 시스템(Shared-Memory Systems)
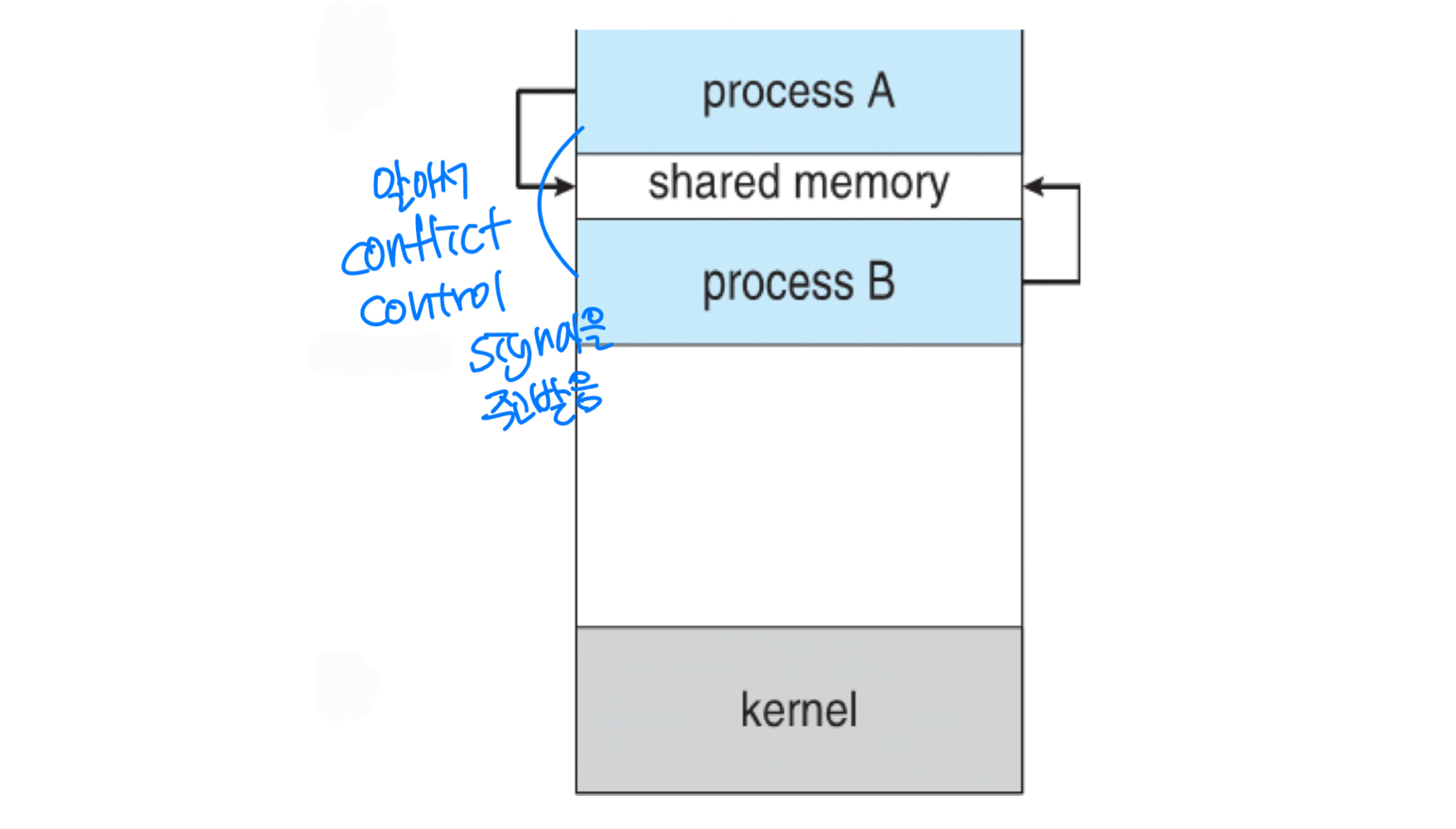
공유 메모리 세그먼트는 두 개 이상의 프로세스가 공유할 수 있는 특별한 메모리 공간이다.
- 데이터의 형태와 위치는 프로세스가 직접 결정하며, OS가 관여하지 않는다
- 동시 쓰기를 프로세스가 스스로 방지해야 한다
- 장점: 빠르다. 대용량 데이터에 적합하다
대표적인 예시로 생산자-소비자 문제(Producer-Consumer Problem) 가 있다.
생산자-소비자 문제
생산자(Producer)와 소비자(Consumer)는 공유 메모리를 통해 정보(아이템)를 주고받는다.
- 생산자: 소비자를 위해 정보를 생산
- 소비자: 생산자가 작성한 정보를 소비
- 예: 컴파일러-어셈블러, 서버-클라이언트
주의할 점은, 생산자와 소비자는 반드시 동기화(Synchronized) 되어야 한다는 것이다. (동기화 문제는 6장에서 다룬다)

버퍼의 종류는 두 가지다.
- 무한 버퍼(Unbounded Buffer): 버퍼 크기에 실질적 제한이 없어 생산자가 항상 생산 가능하다
- 유한 버퍼(Bounded Buffer): 버퍼가 가득 차면 생산자가 기다려야 한다
- Full 조건: 생산자 대기
- Empty 조건: 소비자 대기
유한 버퍼를 이용한 생산자-소비자 문제
버퍼는 원형 큐(Circular Queue) 로 표현된다.
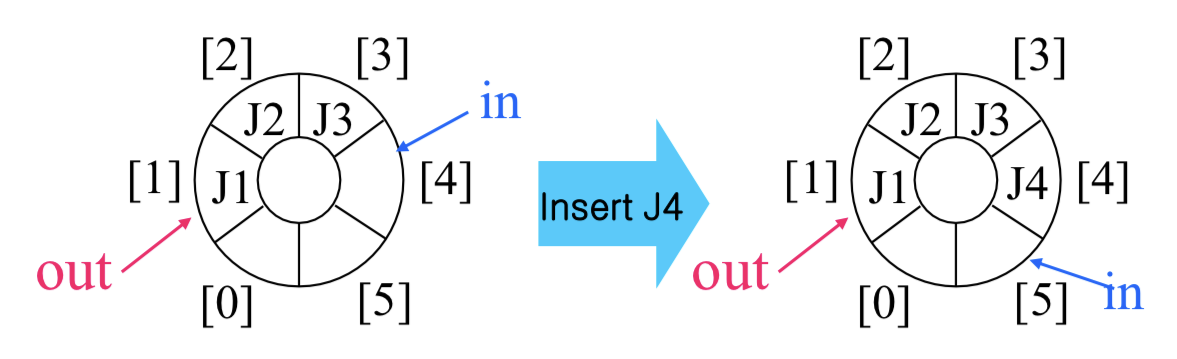
#define BUFFER_SIZE 6
typedef struct {
...
} item;
item buffer[BUFFER_SIZE];
int in = 0; // tail (rear)
int out = 0; // head (front)Empty/Full 조건은 다음과 같다.
- Empty:
in == out - Full:
(in + 1) % BUFFER_SIZE == out - 참고: 버퍼에 실제로 저장 가능한 최대 아이템 수는 BUFFER_SIZE - 1개다
원형 큐(Circular Queue)
원형 큐는 고정 크기 버퍼의 논리적 구조를 원형으로 만든 것이다. 마지막 원소 다음에 첫 번째 원소가 이어진다.
삽입(Inserting):
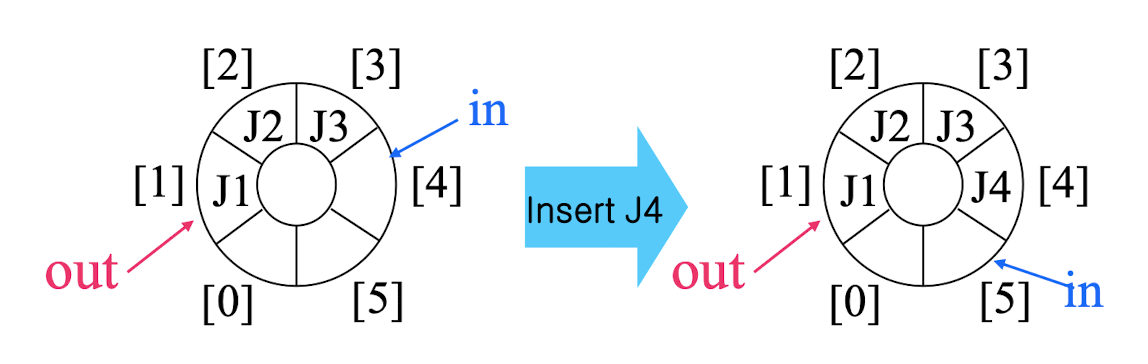
buffer[in] = newItem;
in = (in + 1) % n;추출(Extracting):
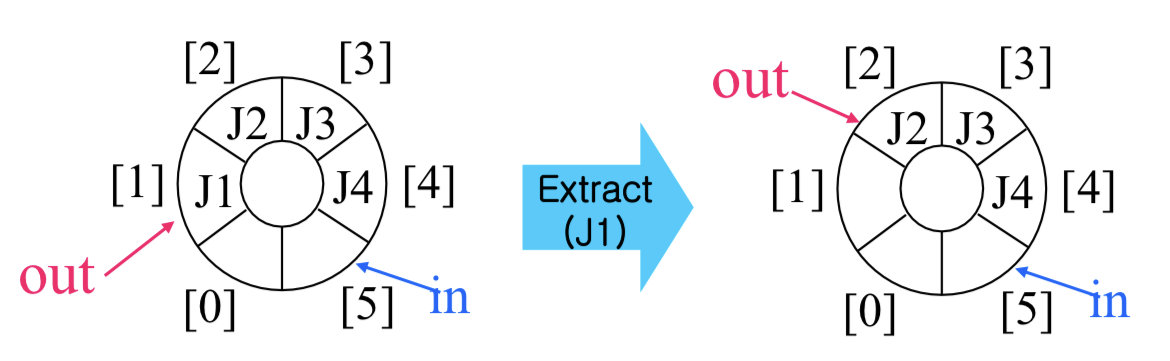
item = buffer[out];
out = (out + 1) % n;유한 버퍼 구현 코드
생산자(Producer):
item nextProduced; // local 변수, 나머지는 shared memory
while (1) {
// nextProduced에 아이템 생산
while (((in + 1) % BUFFER_SIZE) == out); // full이면 대기
buffer[in] = nextProduced; // 큐에 삽입
in = (in + 1) % BUFFER_SIZE;
}소비자(Consumer):
item nextConsumed; // local 변수, 나머지는 shared memory
while (1) {
while (in == out); // empty이면 대기
nextConsumed = buffer[out];
out = (out + 1) % BUFFER_SIZE; // 큐에서 삭제
// nextConsumed의 아이템 소비
}메시지 패싱 시스템(Message-Passing Systems)
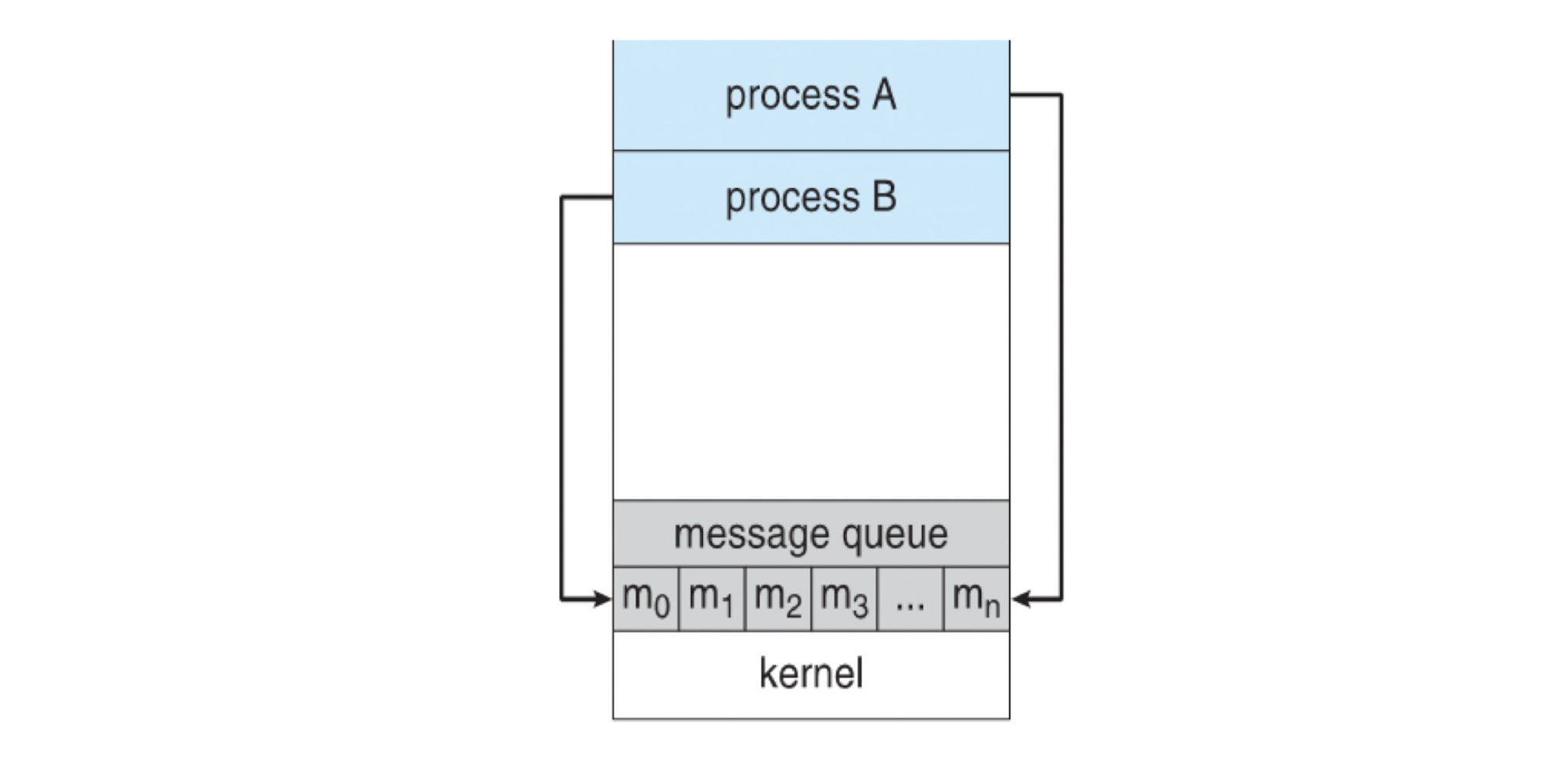
메시지 패싱은 OS가 제공하는 메시지 전달 기능을 통해 프로세스가 통신하는 방식이다.
장점:
- 충돌 없음: 동시에 write해도 OS가 조율해준다
- 소량의 데이터에 적합하다
- 서로 다른 컴퓨터 위의 프로세스 간 통신이 가능하다
단점:
- 공유 메모리보다 느리다. 대용량 데이터는 공유 메모리가 더 적합하다
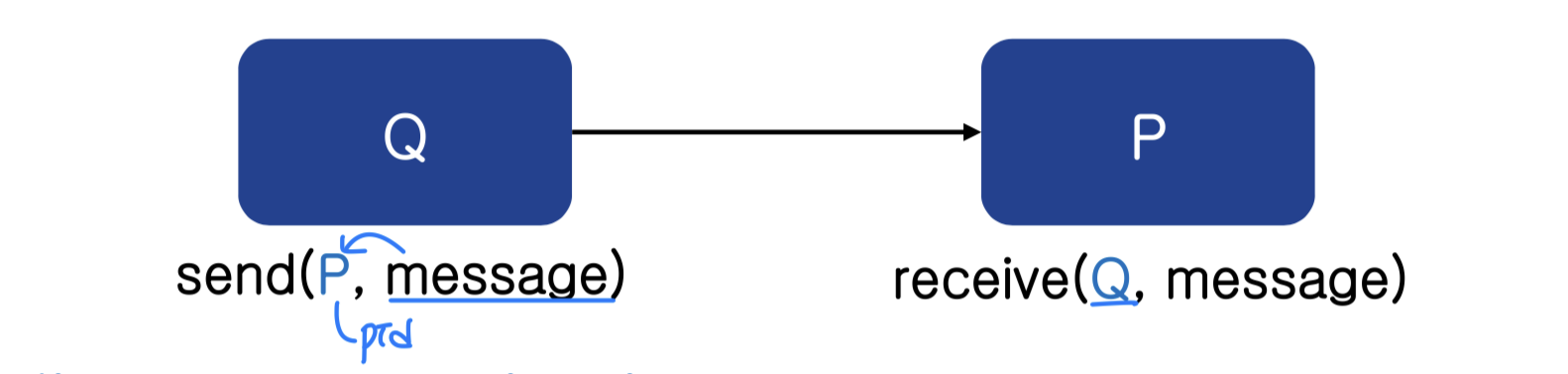
메시지 패싱에는 프로세스 간 통신 링크(Communication Link) 가 필요하며, 핵심 연산은 send와 receive 두 가지다.
논리적 구현 방법에는 다음이 있다.
- 직접(Direct) / 간접(Indirect) 통신
- 동기(Synchronous) / 비동기(Asynchronous) 통신
- 버퍼링(Buffering): Zero / Bounded / Unbounded 용량
직접 통신과 간접 통신
직접 통신(Direct Communication): 통신 링크가 프로세스를 직접 연결한다.
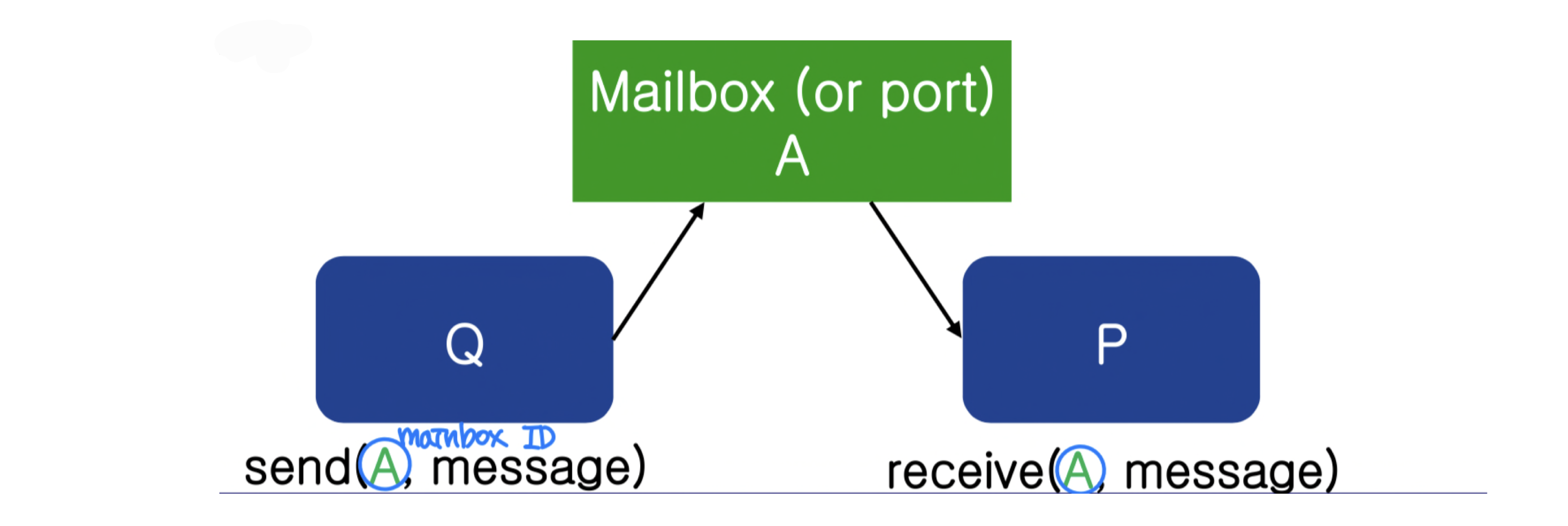
간접 통신(Indirect Communication): 프로세스가 메일박스(Mailbox) 를 통해 연결된다.
버퍼링(Buffering)
통신 중 메시지는 임시 큐(버퍼) 에 저장된다.

버퍼 용량에 따라 세 가지로 나뉜다.
- Zero capacity: 대기열의 최대 길이가 0이므로, 링크에 대기 중인 메시지가 있을 수 없다. 블로킹 전송(blocking send)만 가능하다
- Bounded capacity: 버퍼의 길이가 n으로 유한하다. 버퍼가 가득 차면 송신자가 블록되고, 그렇지 않으면 계속 전송 가능하다
- Unbounded capacity: 버퍼 용량이 무한하여 송신자가 절대 블록되지 않는다
IPC 시스템 예제
[System V] 공유 메모리
shmget() -- 공유 메모리 생성
int shmget(key_t key, int size, int shmflg);성공 시 seg_id를 반환하고, 실패 시 -1을 반환한다.
주소는 절대 주소가 아니라 프로세스 내에서만 통용되며, 물리 주소로 매핑된다.
파라미터:
key: 공유 메모리 세그먼트의 키.IPC_PRIVATE로 설정하면 중복되지 않는 임의의 키 값이 자동 생성된다size: 할당할 메모리의 바이트 단위 크기. 주로 버퍼 크기를 지정한다shmflg: 플래그S_IRUSR: 사용자 읽기 가능S_IWUSR: 사용자 쓰기 가능IPC_CREAT: 해당 키의 메모리가 없으면 공유 메모리를 생성 (0666)IPC_EXCL: 해당 키의 공유 메모리가 이미 있으면 실패를 반환하여 접근을 막는다
shmat() -- 공유 메모리 부착
공유 메모리를 프로세스의 주소 공간에 첨부(attach)한다.
void* shmat(int shmid, char *shmaddr, int shmflg);성공 시 메모리 주소를 반환하고, 실패 시 -1을 반환한다. 반환 타입이 void*인 이유는 특정 타입에 국한되지 않기 위해서다.
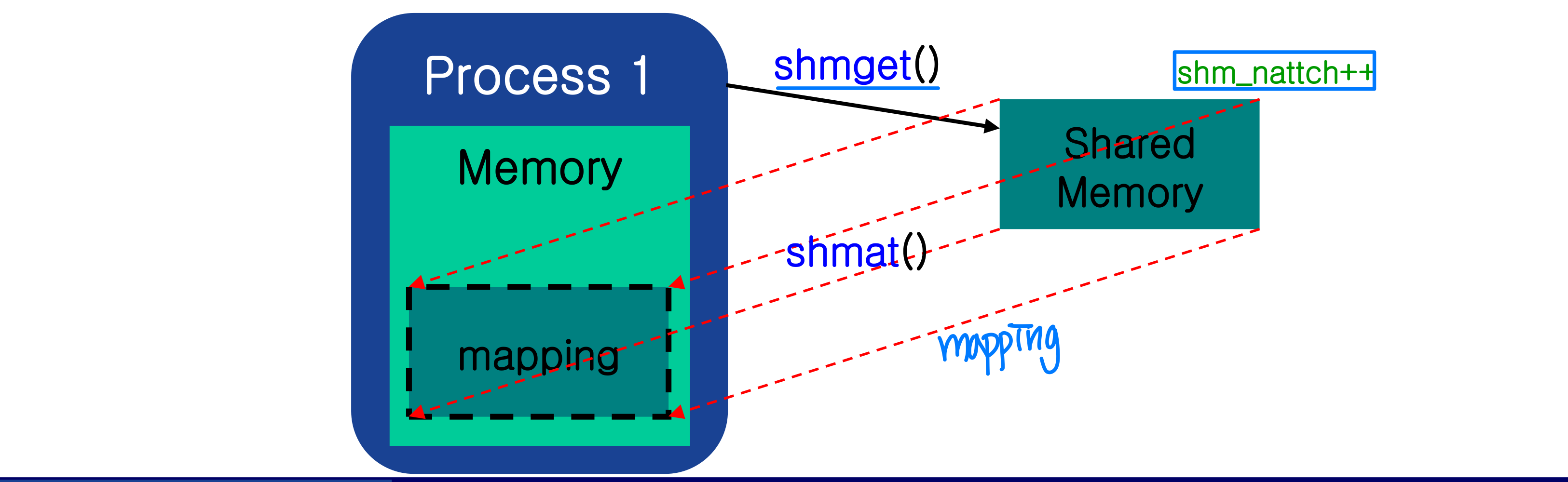
파라미터:
shmid:shmget()의 반환값으로 얻은 세그먼트 IDshmaddr: 매핑할 위치. NULL이면 커널이 알아서 지정한다shmflg: attach 플래그
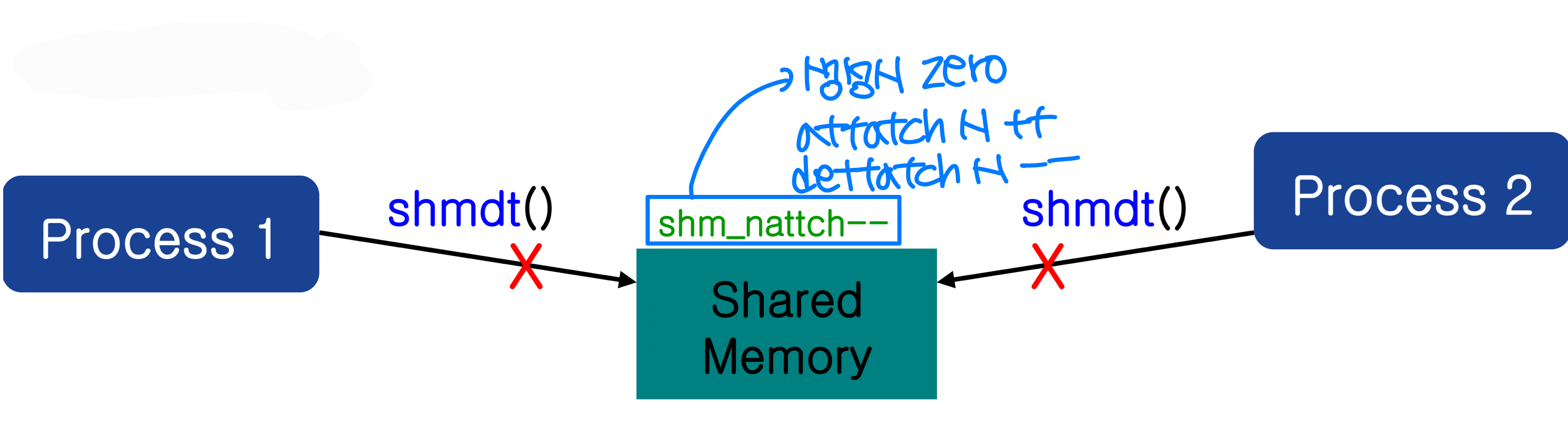
shmdt() -- 공유 메모리 분리
프로세스에 첨부된 공유 메모리를 분리(detach)한다.
void shmdt(char *shmaddr);성공 시 0, 실패 시 -1을 반환한다.
shmctl() -- 공유 메모리 제어 및 해제
공유 메모리의 정보를 확인, 변경, 제거한다.
shmctl(shmid, IPC_RMID, NULL);IPC_RMID는 Remove ID를 의미한다. 명령 직후 즉시 삭제되는 것이 아니라, 사용 중인 프로세스가 없을 때(shm_attach == 0) 삭제가 예약된다.
[POSIX] 공유 메모리

POSIX Producer:

POSIX Consumer:

POSIX 공유 메모리에서 사용하는 주요 함수는 다음과 같다.
shm_open(): 성공 시 file descriptor를 반환한다shm_unlink(): 공유 메모리를 제거한다. 공유 메모리는 커널이 종료되기 전까지는 제거되지 않는다ftruncate(): 실제 공유되고 있는 메모리 크기로shm_fd의 크기를 조절한다mmap(): fd로 지정된 파일에서 offset을 시작으로 length 바이트만큼을 start 주소로 매핑한다munmap(): 지정된 주소 공간에 대한 매핑을 해제한다. 프로세스 종료 시 자동으로 unmap된다
[POSIX] 메시지 패싱
메시지 구조체는 다음과 같다.
struct {
long data_type;
char data_buff[BUFF_SIZE];
};msgget() -- 메시지 큐 생성
int msgget(key_t key, int msgflg);성공 시 메시지 큐 식별자를 반환하고, 실패 시 -1을 반환한다.
파라미터:
key: 시스템에서 다른 큐와 구별되는 번호msgflg: 옵션
snd_queue = msgget((key_t)snd_key, IPC_CREAT | 0666);
rcv_queue = msgget((key_t)rcv_key, IPC_CREAT | 0666);msgsnd() -- 메시지 전송
int msgsnd(int msqid, const void *msgp, size_t msgsz, int msgflg);성공 시 0, 실패 시 -1을 반환한다.
파라미터:
msqid: 메시지 큐 식별자msgp: 전송할 자료msgsz: 전송할 자료의 크기. 전송 데이터의 첫 번째 필드가long타입(메시지 타입)이므로, 데이터 크기에서 long 크기를 제거해야 한다. 즉sizeof(msg) - sizeof(long)으로 지정한다msgflg: 동작 옵션- 0: 큐에 공간이 생길 때까지 대기
IPC_NOWAIT: 즉시 -1을 반환
if(-1 == msgsnd(snd_queue, &msg, sizeof(msg) - sizeof(long), IPC_NOWAIT)) {
perror("msgsnd error: ");
}msgrcv() -- 메시지 수신
ssize_t msgrcv(int msqid, void *msgp, size_t msgsz, long msgtyp, int msgflg);성공 시 데이터 크기를 반환하고, 실패 시 -1을 반환한다.
파라미터:
msgp: 수신한 데이터를 저장할 포인터msgtyp: 어떤 데이터를 읽을지에 대한 옵션- 0: 큐의 첫 번째 자료를 읽는다
- 양수: 지정한 값과 동일한 데이터 타입의 자료 중 첫 번째를 읽는다
- 음수: 절댓값 이하인 데이터 타입 중 가장 작은 타입의 데이터를 읽는다
msgflg: 동작 옵션- 0: 큐에 데이터가 올 때까지 대기
IPC_NOWAIT: 즉시 -1을 반환
msgrcv(rcv_queue, &rcv_data, sizeof(msg) - sizeof(long), 0, IPC_NOWAIT);msgctl() -- 메시지 큐 제어/해제
메시지 큐의 상태 정보를 확인, 변경, 삭제한다.
int msgctl(int msqid, int cmd, struct msqid_ds *buf);성공 시 0, 실패 시 -1을 반환한다.
파라미터:
cmd:IPC_RMID: 메시지 큐를 삭제한다. 버퍼가 필요 없으므로 buf를 0으로 지정한다IPC_STAT: 현재 상태를 buf에 저장한다IPC_SET: 현재 상태를 buf 값으로 변경한다
buf: 메시지 큐 정보를 받을 버퍼
msgctl(snd_queue, IPC_RMID, 0);
msgctl(rcv_queue, IPC_RMID, 0);지금까지 살펴본 IPC는 모두 같은 컴퓨터 안에서의 통신이다.
클라이언트-서버 시스템의 통신
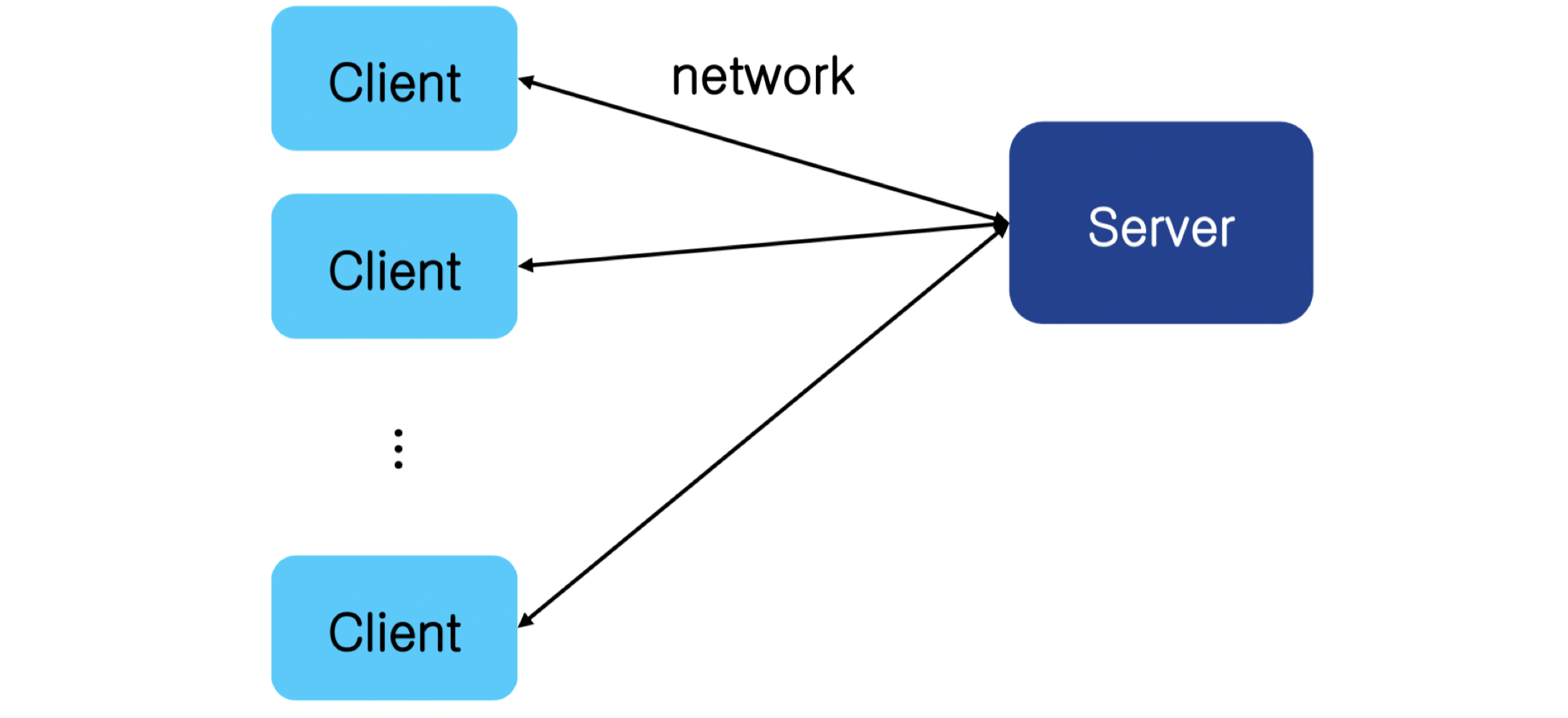
서로 다른 시스템 간의 통신에는 다음 네 가지 방식이 있다.
- 소켓(Socket): 통신의 논리적 종단점(Endpoint). 데이터 통신에 사용된다
- RPC(Remote Procedure Call): 시스템 간 프로시저 호출. 절차적 프로그래밍 패러다임
- 파이프(Pipes): 입출력 리다이렉션에 자주 사용된다
- RMI(Remote Method Invocation): Java에서 다른 시스템의 객체 메서드를 호출하는 방식. 객체지향 프로그래밍 패러다임
소켓(Socket)

소켓은 <IP 주소>:<포트 번호> 로 식별된다.

각 연결은 한 쌍의 소켓으로 식별된다.
포트(Port) 는 TCP/UDP 프로토콜이 인식하는, 컴퓨터에 대한 논리적 접점이다. 한 컴퓨터는 여러 포트(0 ~ 65535)를 가질 수 있다.

- 잘 알려진(Well-known) 서비스는 1024 미만의 포트를 사용한다
- 예: telnet(23), ftp(21), http(80)
- 서버는 해당 포트를 항상 수신 대기한다
- 1024 이상의 포트는 네트워크 통신을 위해 임의로 할당할 수 있다
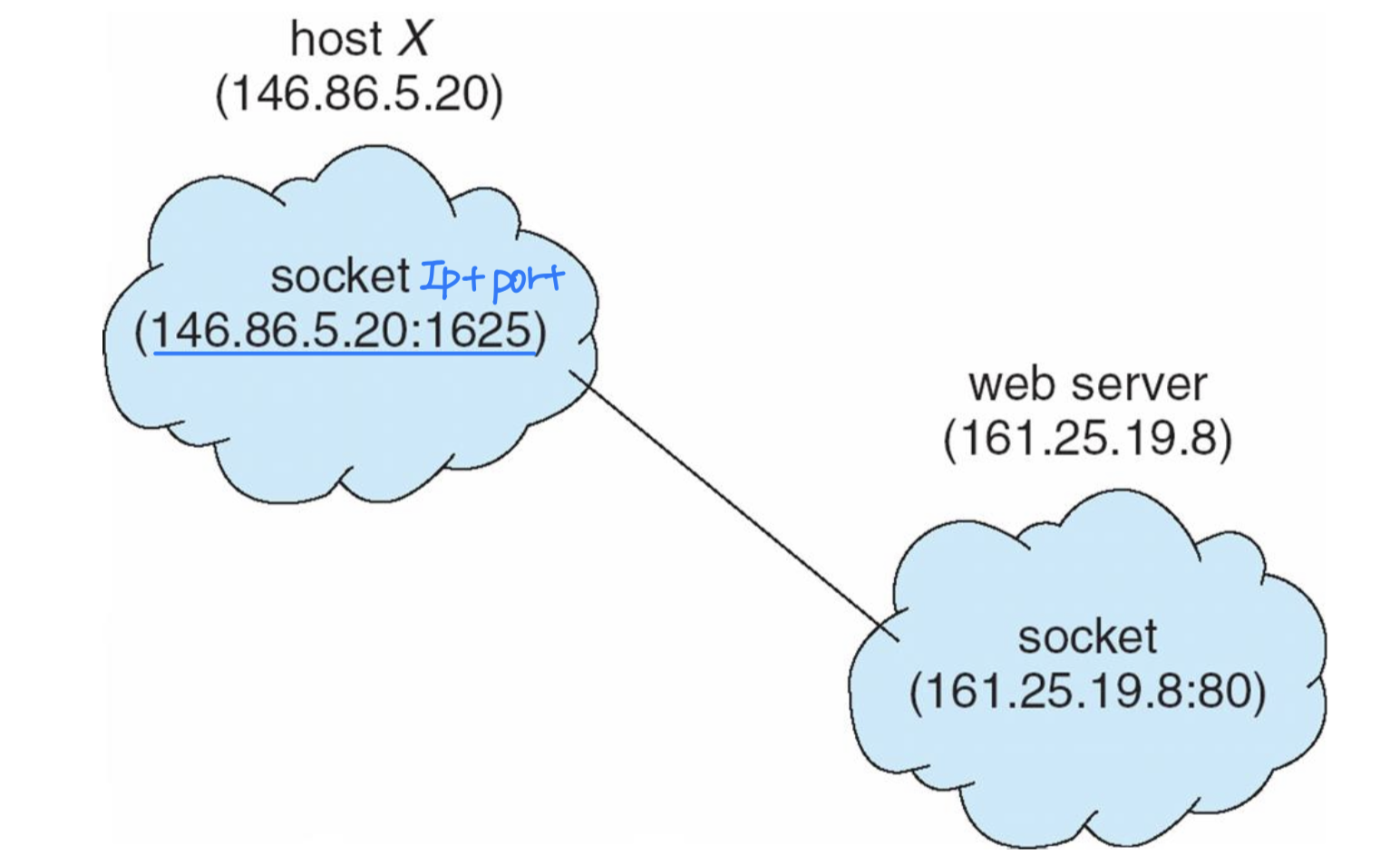
연결 과정:
- 서버가 포트를 열어 연결 요청을 받을 준비를 한다
- 클라이언트가 1024 이상의 포트를 임의로 할당한다 (예: 클라이언트 146.86.5.20의 포트 1625)
- 클라이언트가 서버에 연결을 요청한다 (예: 웹 서버 161.25.19.8, 포트 80)
- 서버가 요청을 수락하면 연결이 성립된다 (예: <146.86.5.20:1625> - <161.25.19.8:80>)
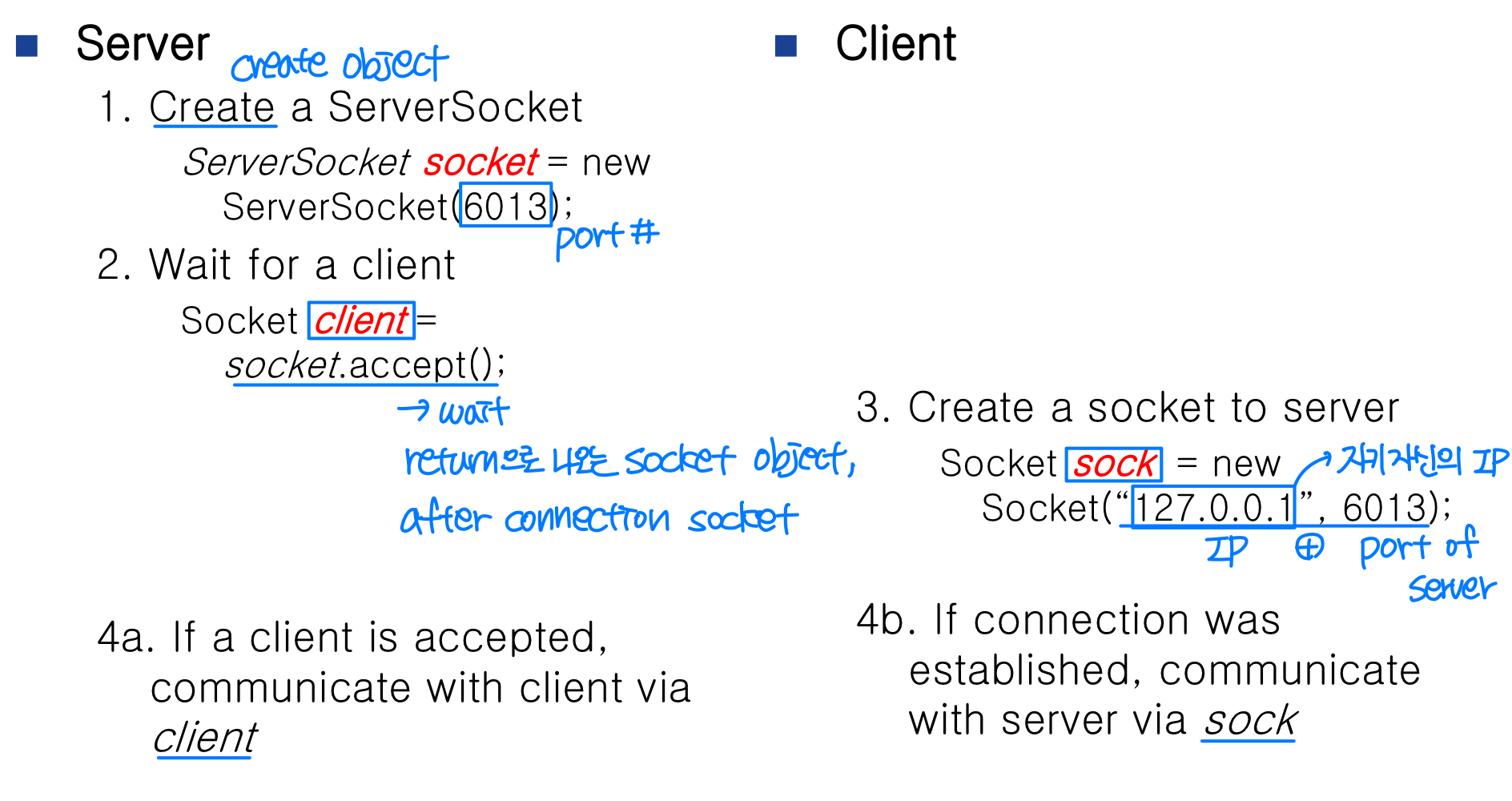
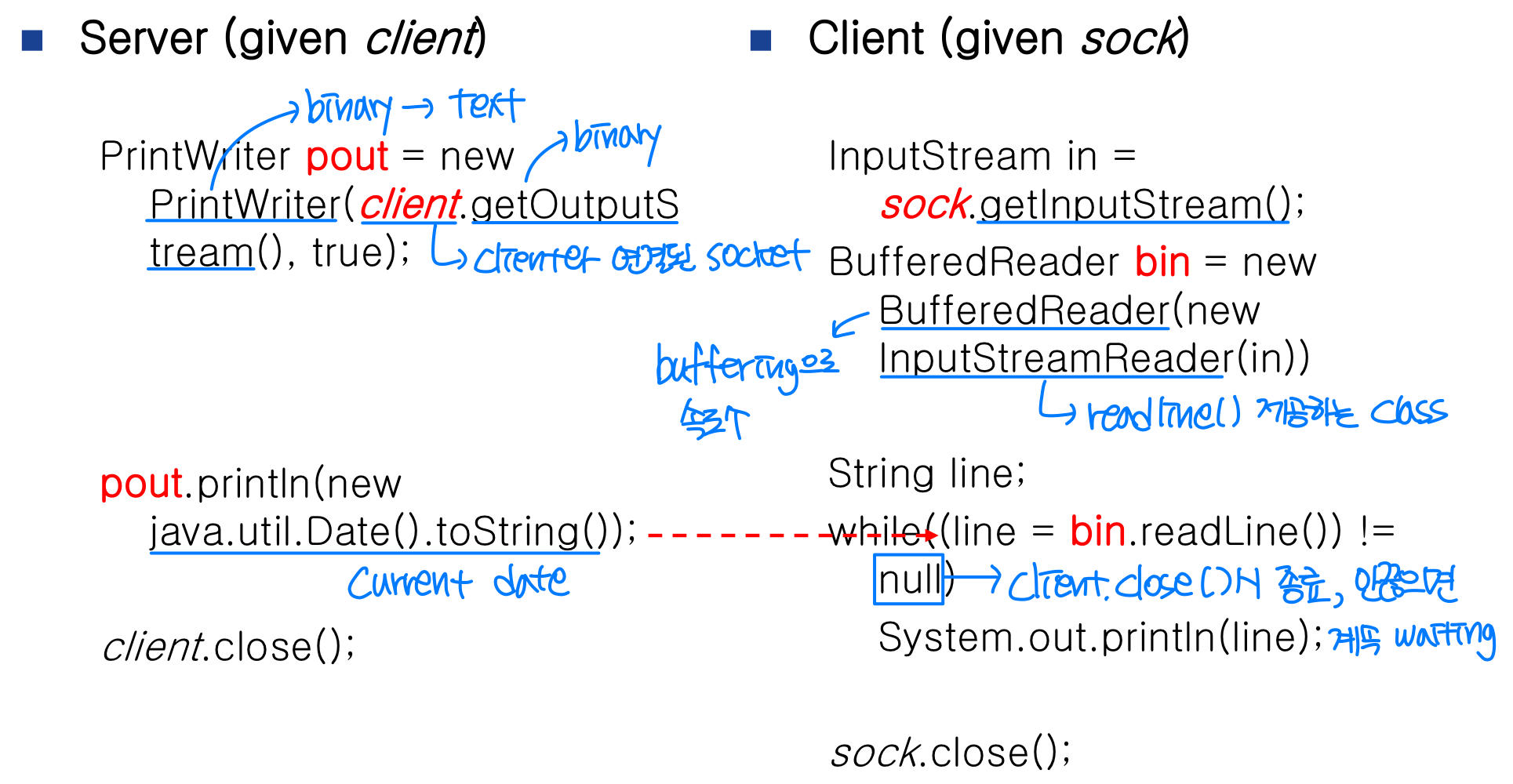
Java 소켓
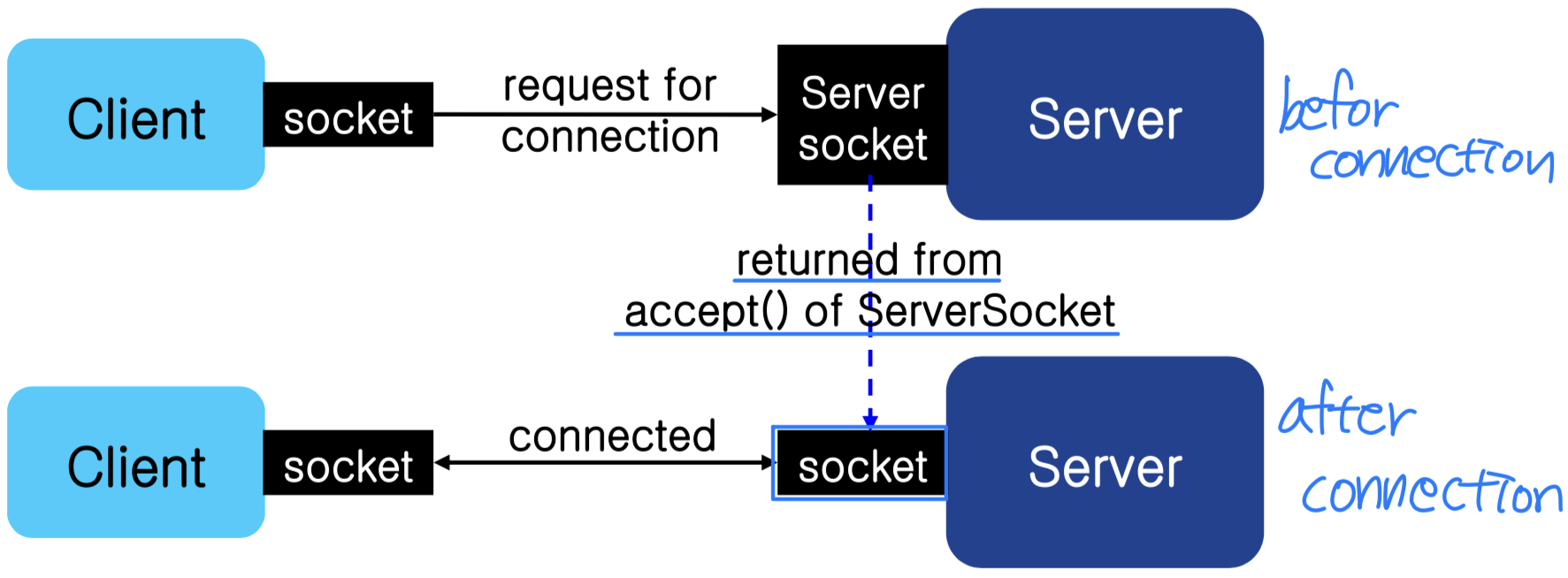
Java에서는 두 가지 소켓 클래스를 제공한다.
ServerSocket: 연결 요청을 수락하며, 포트를 열어둔다Socket: 실제 통신을 담당한다
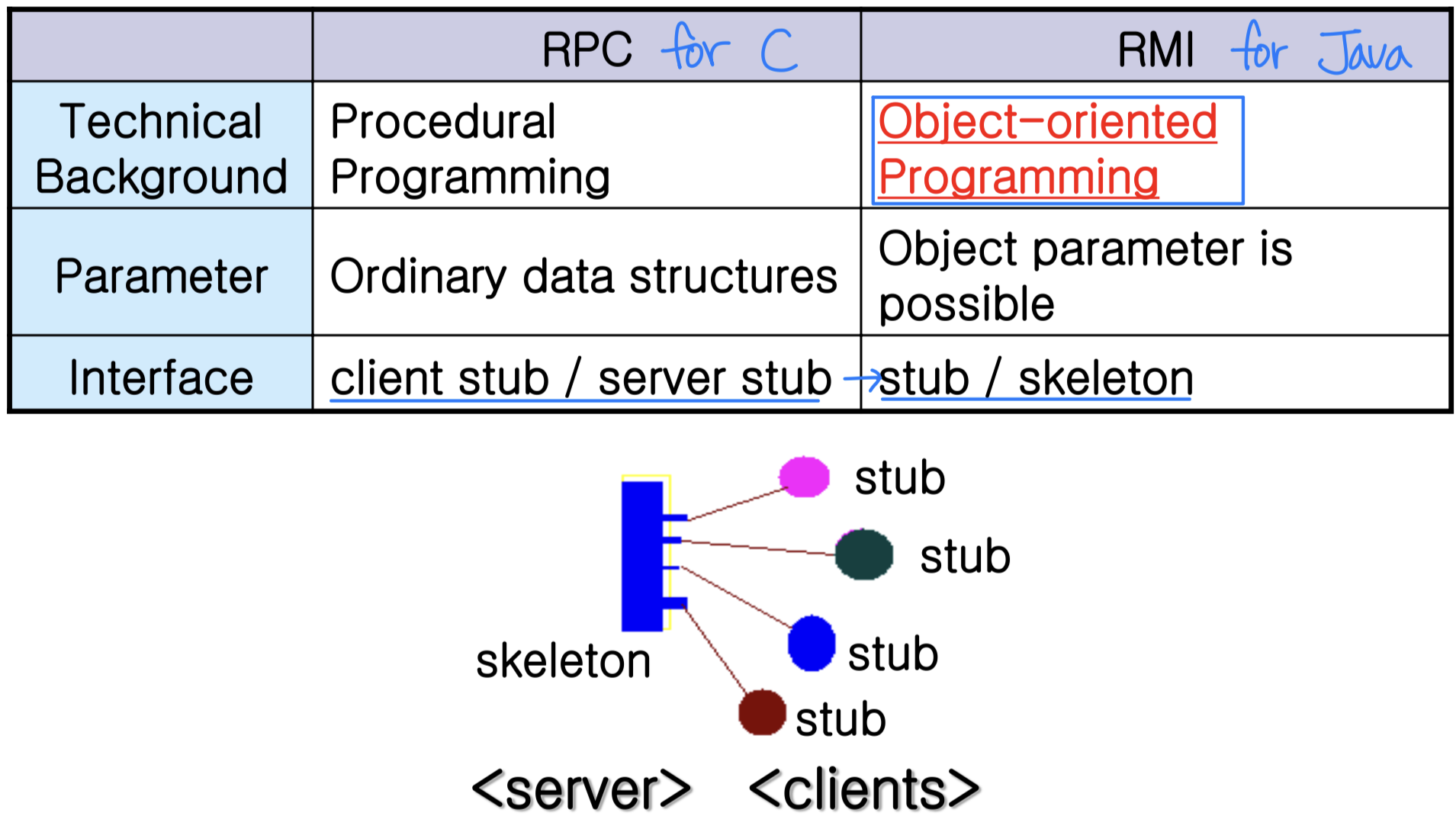
원격 프로시저 호출(RPC)
RPC(Remote Procedure Call) 는 시스템 간 프로시저 호출 메커니즘이다. 네트워크를 통해 다른 컴퓨터나 프로세스에서 실행 중인 함수를 마치 로컬 함수처럼 호출하는 기술이다.
서버에서는 RPC 데몬(daemon) 이 포트를 수신 대기하고, 클라이언트는 함수 식별자와 파라미터를 담은 메시지를 전송한다.
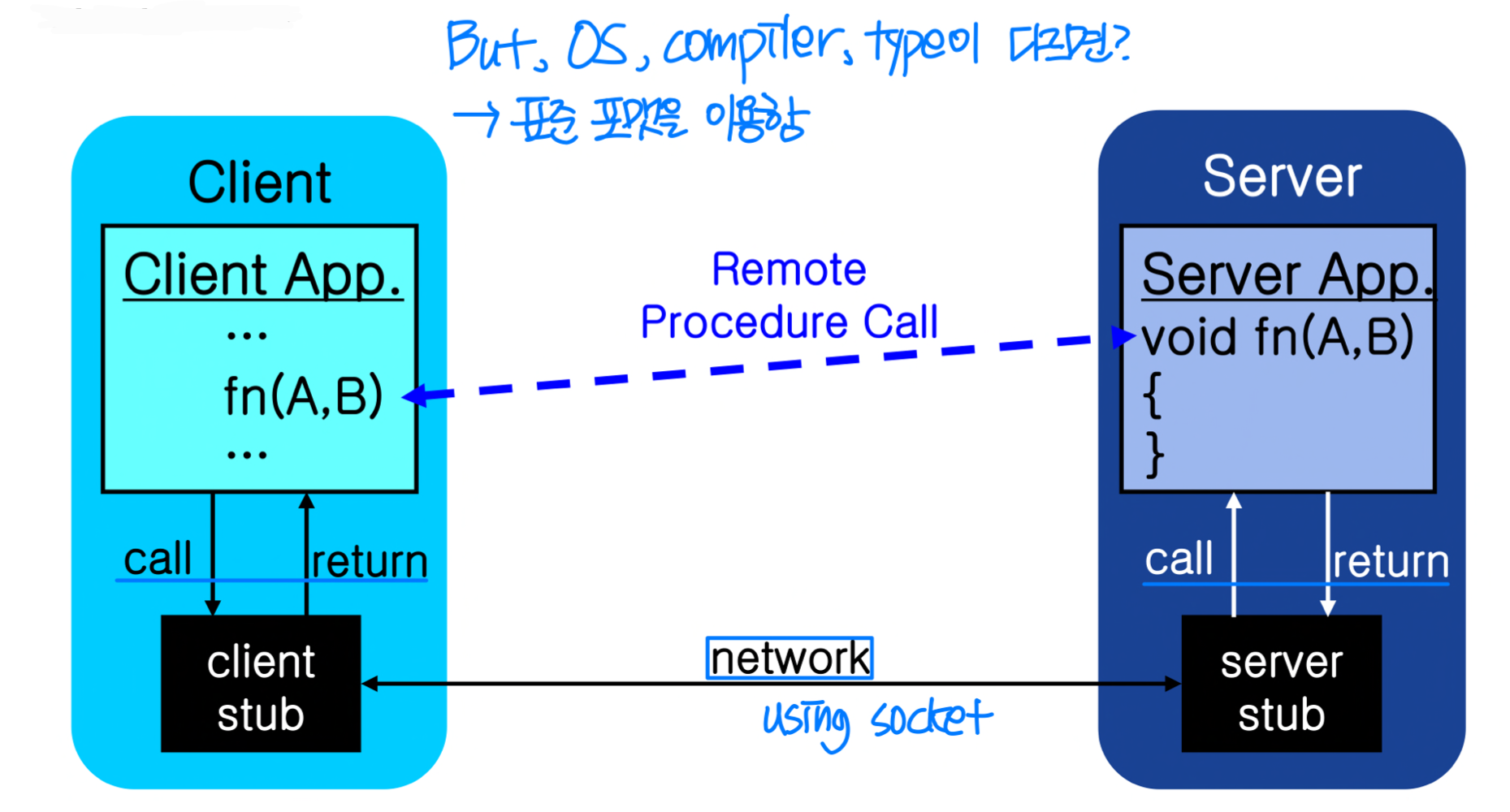
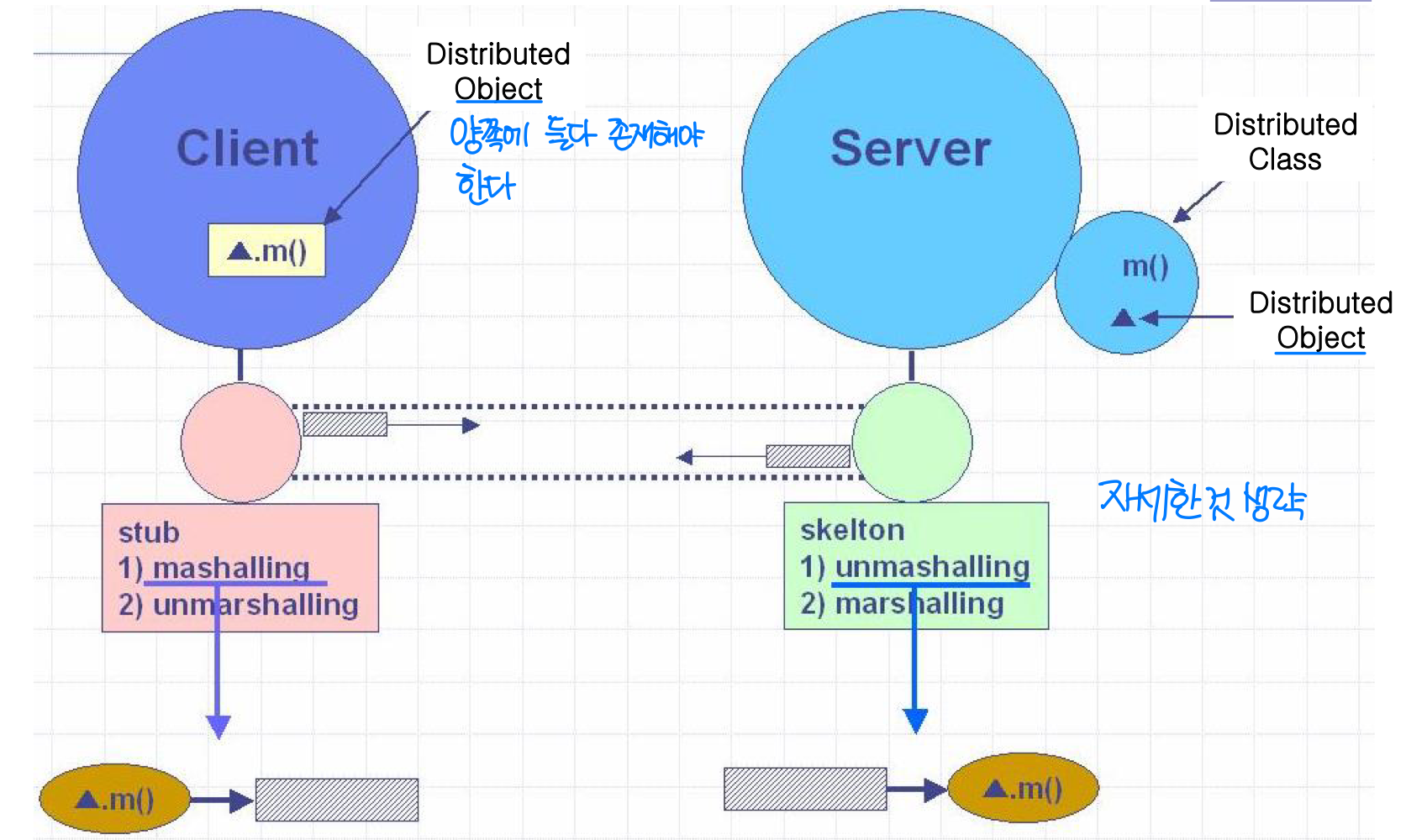
RPC는 스텁(Stub) 을 통해 제공된다. 클라이언트는 로컬 프로시저를 호출하듯 원격 프로시저를 호출한다.
스텁은 원격 측의 더 큰 프로그램이나 서비스에 대한 인터페이스를 제공하는 작은 프로그램이다.
- Client stub / Server stub
- 서버의 포트를 찾는다
- 파라미터를 마셜링(Marshal) / 언마셜링(Unmarshal) 한다
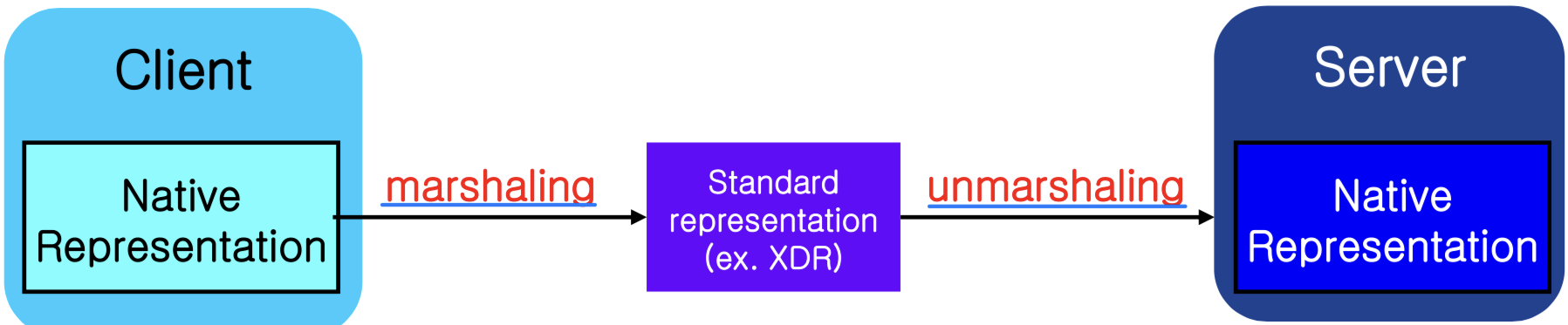
파라미터 마셜링(Parameter Marshaling):
각 시스템은 고유한 데이터 형식을 갖고 있으므로, 파라미터는 기계 독립적인 표준 표현(Machine-independent Standard Representation) 으로 변환되어야 한다. 예를 들어 XDR(eXternal Data Representation)이 있다.
- 마셜링(Marshalling): 네이티브 형식을 표준 형식으로 패키징
- 언마셜링(Unmarshalling): 표준 형식을 네이티브 형식으로 언패키징
파이프(Pipes)
파이프는 IPC에 속하며, 두 프로세스가 통신할 수 있게 하는 가상의 데이터 통로(Conduit)다.
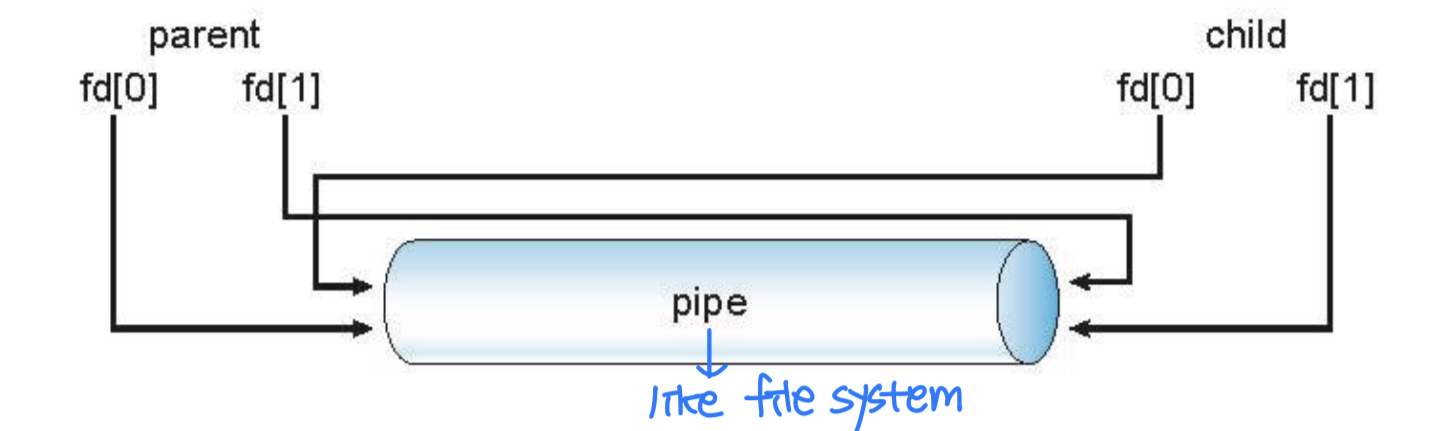
일반 파이프(Ordinary Pipes) 는 단방향(Unidirectional) 통신을 제공하며, 생산자-소비자 스타일로 동작한다.
- 생산자는 파이프의 쓰기 끝(write-end)에 쓴다
- 소비자는 파이프의 읽기 끝(read-end)에서 읽는다
- 통신하는 프로세스 간에 부모-자식 관계가 필요하다
일반적으로 부모 프로세스가 파이프를 생성하고, 자신이 생성한 자식 프로세스와 통신하는 데 사용한다.
Windows에서는 이를 익명 파이프(Anonymous Pipes) 라고 부른다.


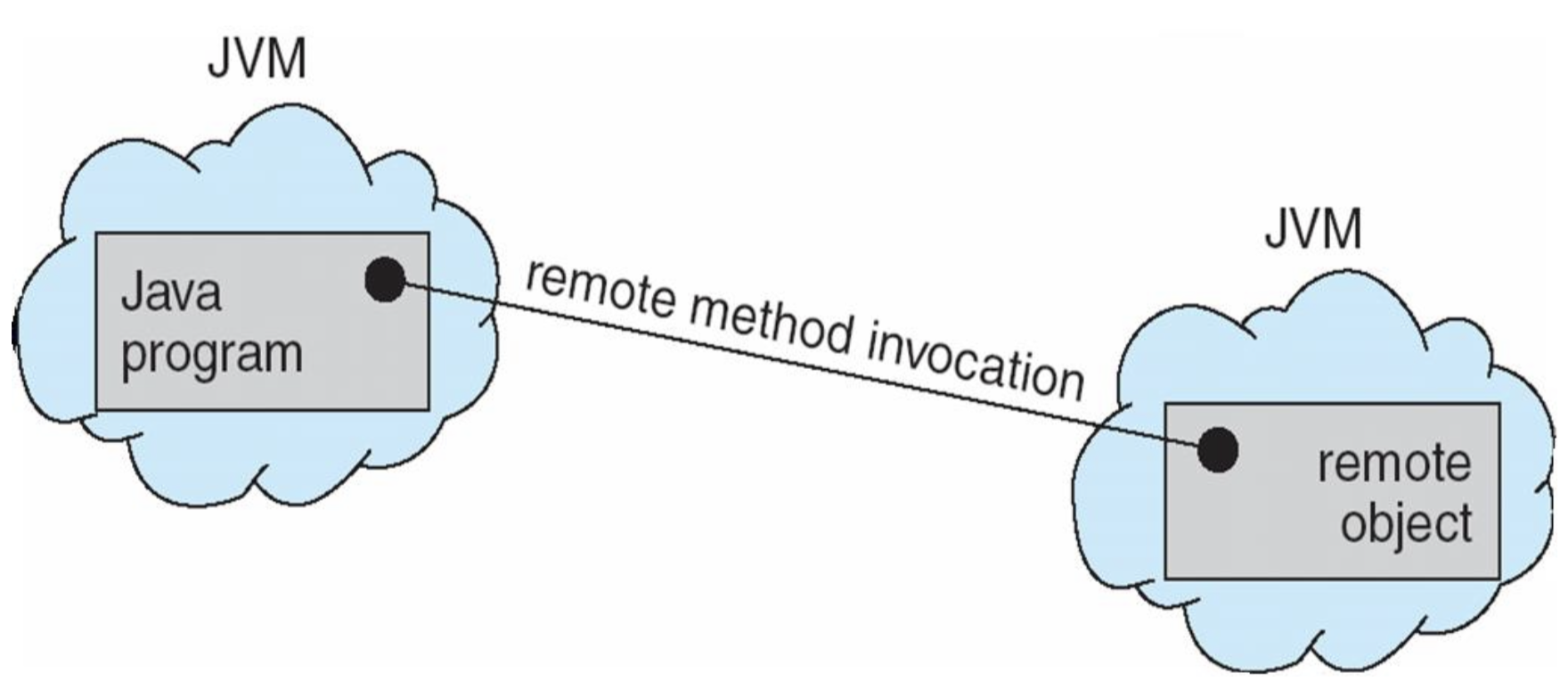
원격 메서드 호출(RMI)
RMI(Remote Method Invocation) 는 Java에서 원격 객체의 메서드를 호출할 수 있게 하는 기능이다. Java 애플리케이션에서 로컬 객체처럼 원격 객체에 접근하여 메서드를 호출할 수 있다.
HGU 전산전자공학부 김인중 교수님의 23-1 운영체제 수업을 듣고 작성한 포스트이며, 첨부한 모든 사진은 교수님 수업 PPT의 사진 원본에 필기를 한 수정본입니다.