0x15 해시
배열은 인덱스로 값에 접근하고, 그 시간복잡도는 O(1)이다. 그런데 만약 인덱스가 아니라 문자열이나 임의의 키로 값에 접근하고 싶다면 어떻게 해야 할까? 이때 등장하는 것이 바로 해시(Hash) 자료구조다.
0x00 알고리즘 설명
해시는 키(Key)에 대응하는 값(Value)을 저장하는 자료구조다. 핵심 아이디어는 간단하다. 키를 해시 함수(Hash Function)에 넣어서 특정 숫자(해시 값)로 변환하고, 그 숫자를 인덱스로 사용해 해시 테이블(Hash Table)에 값을 저장하는 것이다.
택배 물류센터를 떠올리면 이해가 쉽다. 수천 개의 택배가 들어오면 각 택배의 운송장 번호(키)를 기준으로 특정 구역(해시 테이블의 인덱스)에 배치한다. 나중에 찾을 때도 운송장 번호만 알면 바로 해당 구역으로 가서 꺼내면 된다.
이 덕분에 insert, erase, find 연산이 모두 O(1)에 수행된다. 배열처럼 빠르면서도, 키의 종류에 제한이 없다는 것이 해시의 강점이다.
0x01 충돌 회피 1 - Chaining
그런데 서로 다른 키가 같은 해시 값을 가지면 어떻게 될까? 이를 충돌(Collision)이라 하며, 해시 자료구조에서 반드시 해결해야 하는 문제다. 첫 번째 방법은 체이닝(Chaining)이다.
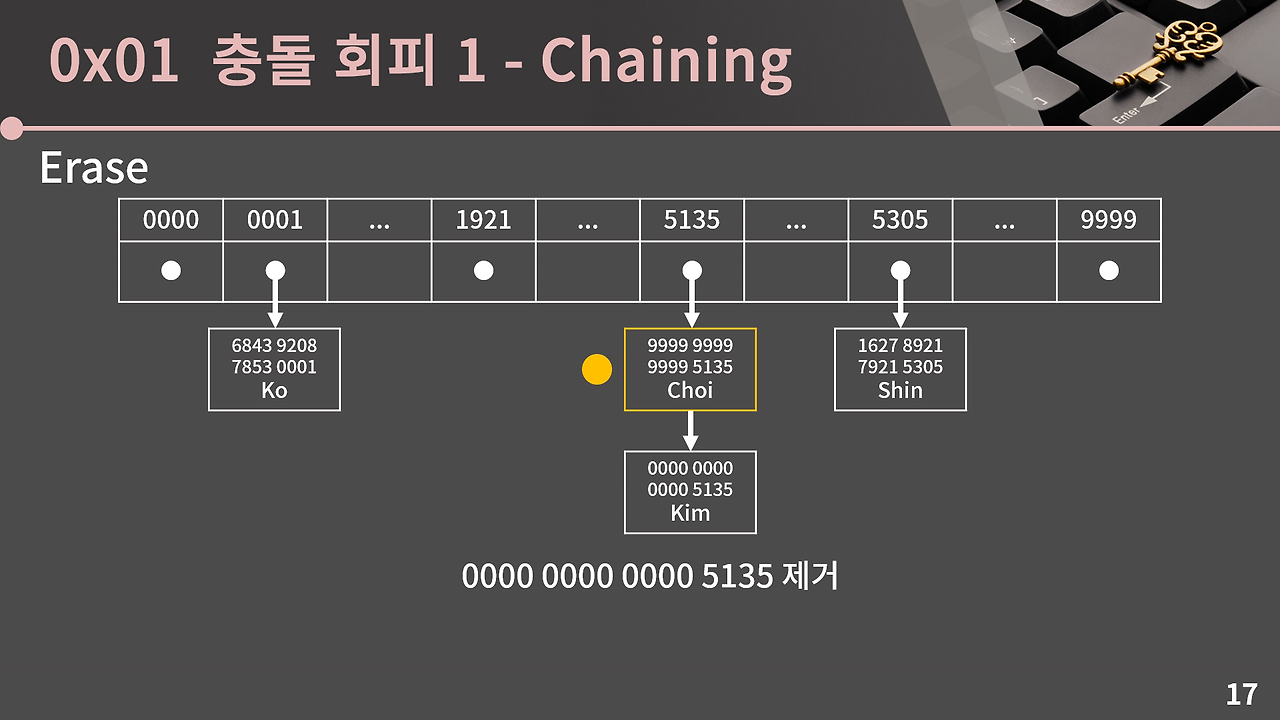
체이닝은 해시 테이블의 각 인덱스마다 연결 리스트(Linked List)를 두는 방식이다. 같은 해시 값을 가진 키들이 여러 개 있어도, 해당 인덱스의 연결 리스트에 차례로 매달아 두면 된다. 탐색 시에는 해당 인덱스의 연결 리스트를 순회하며 원하는 키를 찾는다.
해시 자료구조는 이상적인 상황에서 O(1)이지만, 충돌이 빈번해질수록 성능이 저하된다. 극단적으로, 모든 키의 해시 값이 동일한 최악의 경우에는 하나의 연결 리스트에 모든 데이터가 몰리면서 O(N)까지 떨어진다. 이는 뒤에서 다룰 Open Addressing에서도 마찬가지다.
결국 해시의 성능은 해시 함수의 품질에 달려 있다. 각 키의 해시 값이 테이블 전체에 최대한 균등하게 퍼져야 충돌이 줄어들고, 그래야 O(1)에 가까운 성능을 유지할 수 있다.
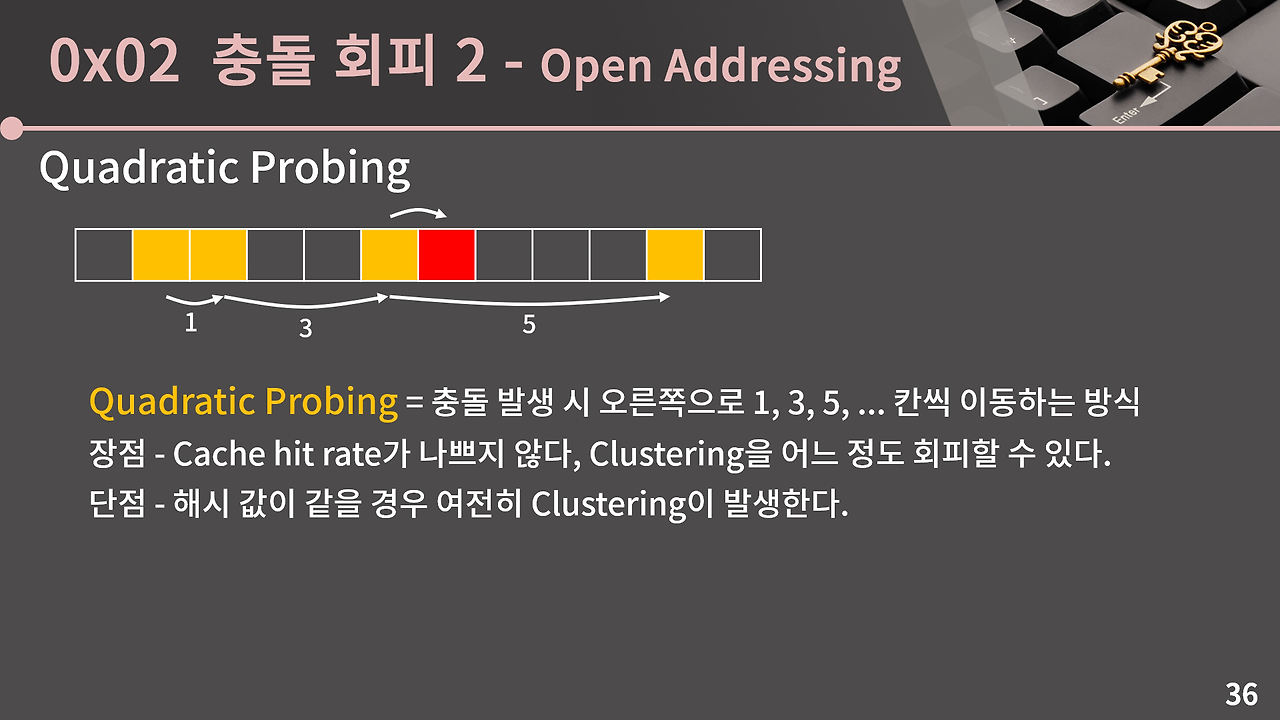
0x02 충돌 회피 2 - Open Addressing
두 번째 충돌 회피 방법은 개방 주소법(Open Addressing)이다. 체이닝과 달리 별도의 연결 리스트를 사용하지 않고, 충돌이 발생하면 테이블 내의 다른 빈 자리를 찾아 데이터를 저장한다.
아래 그림들은 Open Addressing의 동작 과정을 보여준다. 충돌이 발생했을 때 다음 빈 칸을 탐색하는 방식(Linear Probing 등)과, 삭제 시 발생할 수 있는 문제를 함께 확인할 수 있다.


0x03 STL
C++ STL에서는 해시 기반 자료구조를 unordered_ 접두어가 붙은 컨테이너로 제공한다. set이나 map의 정렬된 버전과 달리, 해시 테이블을 내부적으로 사용하기 때문에 삽입/삭제/탐색이 평균 O(1)이다. 대신 원소의 순서는 보장되지 않는다.
unordered_set
unordered_set은 중복 없는 원소의 집합을 해시 테이블로 관리한다. insert, erase, find, count 등 기본적인 집합 연산을 모두 지원한다.
다음 코드는 정수를 삽입하고, 삭제한 뒤 특정 원소가 존재하는지 확인하는 예시다.
void unordered_set_example() {
unordered_set<int> s;
s.insert(-10); s.insert(100); s.insert(15); // [-10, 100, 15]
for (auto e : s) cout << e << ' '; // 15, 100, -10 (order may vary)
cout << '\n';
s.erase(100);
if (s.find(15) = s.end()) cout << "15 in s\n";
else cout << "15 not in s\n";
cout << s.count(100) << '\n';
for (auto e : s) cout << e << ' ';
cout << '\n';
}find는 원소가 존재하면 해당 iterator를, 없으면 end()를 반환한다. count는 해당 원소의 개수를 반환하는데, unordered_set에서는 중복이 없으므로 0 또는 1만 나온다.
unordered_multiset
unordered_multiset은 unordered_set과 동일하지만 중복 원소를 허용한다는 차이가 있다.
void unordered_multiset_example() {
unordered_multiset<int> ms;
ms.insert(-10); ms.insert(100); ms.insert(15); // {-10, 100, 15}
ms.insert(-10); ms.insert(15); // {-10, -10, 100, 15, 15}
cout << ms.size() << '\n'; // 5
for(auto e : ms) cout << e << ' ';
cout << '\n';
cout << ms.erase(15) << '\n'; // {-10, -10, 100}, 2
ms.erase(ms.find(-10)); // {-10, 100}
ms.insert(100); // {-10, 100, 100}
cout << ms.count(100) << '\n'; // 2
}여기서 주의할 점이 하나 있다. erase에 키 값을 직접 넘기면 해당 키를 가진 원소가 전부 삭제된다. 위 코드에서 ms.erase(15)를 호출하면 15가 두 개 다 사라진다. 만약 하나만 삭제하고 싶다면, ms.erase(ms.find(-10))처럼 iterator를 넘겨야 한다.
unordered_map
unordered_map은 키-값 쌍(Key-Value Pair)을 해시 테이블로 관리하는 자료구조다. Python의 딕셔너리와 비슷하다고 생각하면 된다.
다음 코드는 문자열을 키로, 정수를 값으로 저장하고 조작하는 예시다. [] 연산자로 값에 직접 접근할 수 있으며, 이미 존재하는 키에 대입하면 값이 갱신된다.
void unordered_map_example() {
unordered_map<string, int> m;
m["hi"] = 123;
m["bkd"] = 1000;
m["gogo"] = 165; // ("hi", 123), ("bkd", 1000), ("gogo", 165)
cout << m.size() << '\n'; // 3
m["hi"]= -7; // ("hi", -7), ("bkd", 1000), ("gogo", 165)
if (m.find("hi") = m.end()) cout << "hi in m\n";
else cout << "hi not in m\n";
m.erase("bkd"); // ("hi", -7), ("gogo", 165)
for(auto e : m)
cout << e.first << ' ' << e.second << '\n';
}순회 시 e.first가 키, e.second가 값에 해당한다. find와 erase의 사용법은 unordered_set과 동일하다.
0x05 구현
해시 테이블의 직접 구현은 일단 스킵한다. 추후 필요할 때 다시 다룰 예정이다.
문제 풀이
추후 관련 문제를 풀면 정리할 예정이다.
리뷰
해시는 개념 자체는 단순하지만, 충돌 처리 방식과 해시 함수의 품질이 성능을 크게 좌우한다는 점이 핵심이다. PS에서는 직접 구현보다 STL의 unordered_set, unordered_map을 활용하는 경우가 대부분이므로, 각 컨테이너의 특성과 주의사항(특히 unordered_multiset의 erase 동작)을 잘 기억해두면 좋겠다.
출처: 바킹독님의 실전알고리즘 강의