0x12 수학
알고리즘 문제를 풀다 보면 결국 수학으로 돌아오는 순간이 온다. 소수 판별, 최대공약수, 이항계수 같은 개념은 PS에서 빠지지 않고 등장하는 단골 주제다. 이번 글에서는 이 핵심 수학 도구들을 하나씩 정리한다.
0x00 소수
소수(Prime Number)란 1과 자기 자신으로만 나누어지는 수, 즉 약수가 정확히 2개인 수를 의미한다. 반대로, 1과 자기 자신 외에 다른 약수를 가지는 수를 합성수(Composite Number)라고 한다.
어떤 수 N이 소수인지 판별하려면 2부터 N-1까지 전부 나눠볼 수도 있겠지만, 사실 2부터 sqrt(N)까지만 확인하면 충분하다. N이 합성수라면 반드시 sqrt(N) 이하의 약수를 가지기 때문이다.
아래 코드는 이 원리를 그대로 구현한 소수 판별 함수다.
bool isprime(int n) {
if(n == 0) return 0;
for(int i=2; i*i<=n; i++)
if(n % i == 0) return 0;
return 1;
}i*i <= n 조건으로 sqrt(N)까지만 순회하므로, 시간복잡도는 O(sqrt(N)) 이다.
에라토스테네스의 체 알고리즘
단일 숫자가 아니라 1부터 N까지의 모든 소수를 구해야 한다면 어떻게 할까? 하나씩 isprime을 호출하는 것보다 훨씬 효율적인 방법이 있다. 바로 에라토스테네스의 체(Sieve of Eratosthenes) 다.
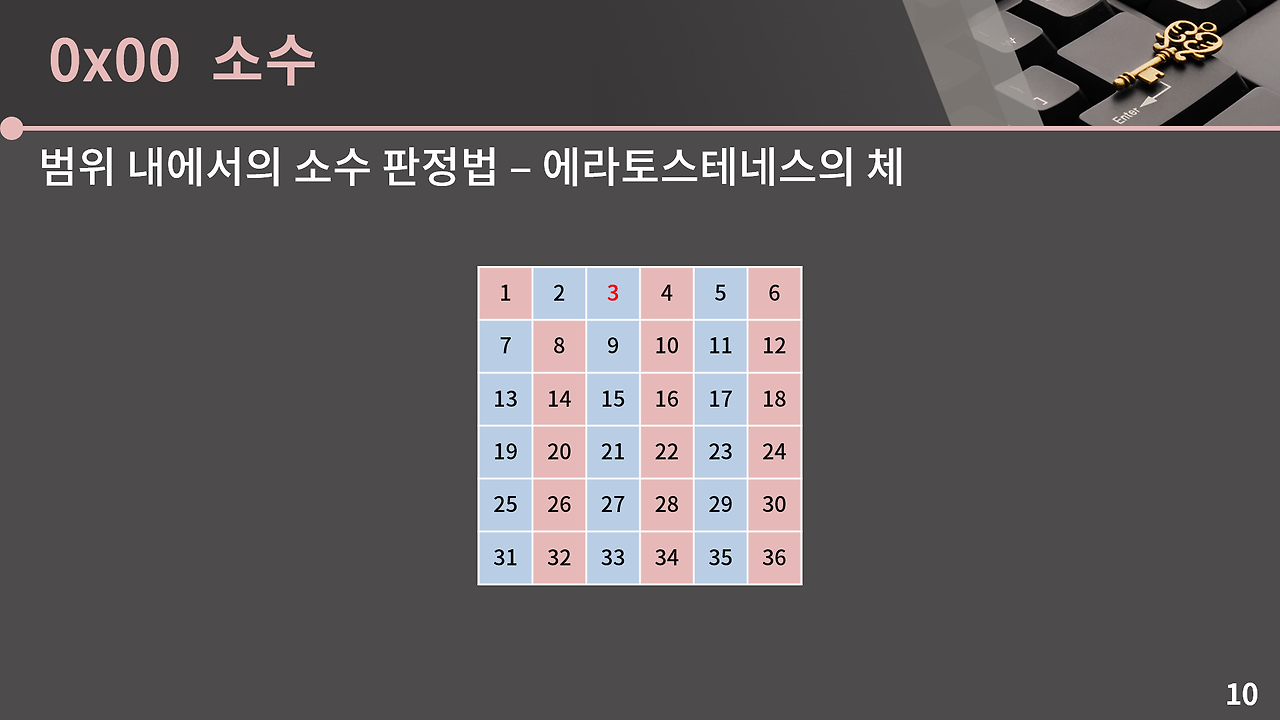
아이디어는 단순하다. 소수를 하나 찾을 때마다 그 소수의 배수를 전부 지워버리는 것이다. 2가 소수니까 4, 6, 8, ... 을 지우고, 3이 소수니까 9, 12, 15, ... 를 지우는 식이다.
vector<int> sieve(int n) {
vector<int> primes;
vector<bool> state(n+1, true);
state[1] = false;
for(int i=2; i*i<=n; i++) {
if(!state[i]) continue;
for(int j= i*i; j <= n; j = i)
state[j]= false;
}
for (int i= 2; i <= n; i++) {
if (state[i]) primes.push_back(i);
}
return primes;
}바깥 루프에서 i*i <= n까지만 돌리는 것 역시 앞서 설명한 O(sqrt(N)) 최적화를 적용한 것이다.
여기서 한 가지 구현 팁이 있다. bool state[n]처럼 일반 배열로 선언하면 시간이 꽤 느려진다. bool은 true/false만 저장하지만 실제 크기는 char처럼 1 byte를 차지한다. 반면 vector<bool>로 선언하면 각 원소가 1 bit만 차지하도록 최적화가 이루어진다. 이 덕분에 공간을 8배 적게 쓸 뿐만 아니라, cache hit rate가 올라가서 시간도 빨라진다. PS에서 체를 쓸 때는 vector<bool>을 쓰는 편이 유리하다.
소인수분해
소인수분해도 같은 원리를 활용한다. 2부터 시작해서 나눠지는 만큼 계속 나누고, 다음 수로 넘어가는 방식이다.
int n;
cin >> n;
for (int i = 2; i*i <= n; i++){
while(n % i == 0) {
cout << i << '\n';
n /= i;
}
}
if(n != 1) cout << n;루프가 끝난 뒤 n != 1이면 남아있는 n 자체가 소인수다. 예를 들어 n = 14일 때, 2로 한 번 나누면 7이 남는데, i*i <= 7을 만족하는 i가 2밖에 없으므로 루프가 끝나고 7을 출력하게 된다. 시간복잡도는 역시 O(sqrt(N)) 이다.
0x01 최대공약수
약수(Divisor)란 어떤 수를 나누어 떨어지게 하는 수를 뜻한다. N의 모든 약수를 구하는 함수는 다음과 같다.
vector<int> divisor(int n) {
vector<int> div;
for(int i=1; i*i<=n; i++)
if(n % i= 0) div.push_back(i);
for(int j=(int)div.size()-1; j>=0; j--) {
if(div[j] * div[j] == n) continue;
div.push_back(n / div[j]);
}
return div;
}sqrt(N)까지 순회하면서 약수 쌍의 작은 쪽만 먼저 담고, 역순으로 돌면서 큰 쪽을 추가하는 구조다. 제곱수인 경우 같은 약수가 두 번 들어가는 것을 div[j] * div[j] == n 조건으로 방지하고 있다. 시간복잡도는 O(sqrt(N)) 이다.
한 가지 재미있는 디테일이 있다. div.size() 앞에 (int) 캐스팅을 한 이유가 뭘까?
vector의 size() 멤버 함수는 unsigned를 반환한다. 만약 div.size()가 0일 때 (int) 없이 div.size() - 1을 계산하면, -1이 되는 것이 아니라 unsigned int로 처리되어 32비트 기준 2^32 - 1, 즉 4294967295라는 엉뚱한 값이 된다.
다만 이 코드에서는 적어도 1이 div에 들어가기 때문에 크기가 0일 일은 사실상 없다. 설령 억지로 divisor(0)을 호출해서 div의 크기를 0으로 만들더라도, 4294967295를 int j에 넣는 과정에서 형변환이 다시 일어나 j에 -1이 정상적으로 담긴다. 즉 (int) 캐스팅이 없어도 이 코드는 "소 뒷걸음질 치다가 쥐 잡은" 식으로 잘 동작하긴 한다. 하지만 명시적 캐스팅은 좋은 습관이다.
이제 본론인 최대공약수(Greatest Common Divisor, GCD) 로 넘어간다. GCD란 두 자연수의 공통된 약수 중 가장 큰 값이다.
GCD를 구하는 가장 효율적인 방법은 유클리드 호제법(Euclidean Algorithm) 이다. 핵심 원리는 다음과 같다.
두 수 A, B에 대해 A를 B로 나눈 나머지를 r이라고 하면, GCD(A, B) = GCD(B, r) 이다.
예를 들어 GCD(20, 12)를 구해보면:
GCD(20, 12) = GCD(12, 8) = GCD(8, 4) = GCD(4, 0) = 4
나머지가 0이 되는 순간, 나누는 수가 곧 GCD다. 코드로 옮기면 간단한 재귀 함수가 된다.
int gcd(int a, int b) {
if(a == 0) return b;
return gcd(b%a, a);
}시간복잡도는 O(log(max(a,b))) 로 매우 빠르다. 참고로 C++17부터는 <numeric> 헤더에 gcd 함수가 내장되어 있고, C++17 이전 gcc에서도 비표준이지만 __gcd 함수를 사용할 수 있다.
GCD를 구했다면 최소공배수(Least Common Multiple, LCM) 도 쉽게 따라온다. A x B = GCD(A, B) x LCM(A, B) 라는 관계를 이용하면 된다.
int lcm(int a, int b) {
return a / gcd(a, b) * b;
}여기서 a * b / gcd(a, b)가 아니라 a / gcd(a, b) * b 순서로 쓴 이유는 int overflow 방지 때문이다. a * b를 먼저 계산하면 int 범위를 넘어갈 수 있으므로, gcd로 먼저 나눠서 값을 줄인 뒤 곱하는 것이 안전하다.
0x02 연립합동방정식 - BOJ 6064 : 카잉달력
이 문제는 주어진 M, N, x, y에 대해 i % M == x이고 i % N == y를 동시에 만족하는 i를 찾는 것이다. 가장 직관적인 접근은 1부터 LCM(M, N)까지 하나씩 검사하는 것이다.
int main() {
int t;
cin >> t;
while(t--) {
cin >> m >> n >> x >> y;
if(x == m) x = 0;
if(y == n) y = 0;
int limit = lcm(m, n);
for(int i=1; i<=limit; i++) {
if(i % m == x && i % n == y) {
cout << i << endl;
break;
}
if(i == limit) cout << -1 << endl;
}
}
}하지만 이 방법의 시간복잡도는 O(LCM(N, M)) 이고, LCM(N, M)은 최대 NM이므로 O(NM) 이 된다. N, M이 최대 40000이면 최악의 경우 16억 번 연산이 필요해서 시간 초과가 발생한다.
핵심 최적화는 첫 번째 조건을 먼저 만족시키고, 두 번째 조건만 확인하는 것이다. i % M == x를 만족하는 수는 x, x+M, x+2M, ... 뿐이므로, 이 후보들만 순회하면서 i % N == y인지 확인하면 된다.
int main() {
int t;
cin >> t;
while(t--) {
cin >> m >> n >> x >> y;
if(x == m) x = 0; // edge case
if(y == n) y = 0; // edge case
int limit = lcm(m, n);
for(int i=x; ; i+=m) {
if(i == 0) continue; // x = M, y = N edge case
if(i > limit) {
cout << -1 << endl;
break;
}
if(i % n == y) {
cout << i << endl;
break;
}
}
}
}이렇게 하면 확인해야 할 수의 개수가 LCM(N, M) / M, 즉 최대 N개로 줄어든다.
흥미로운 확장 질문이 있다. 만약 조건이 3개로 늘어나서 <x:y:z> 꼴이 되고, K로 나눈 나머지가 z여야 한다는 조건이 추가된다면 어떻게 될까? 언뜻 보면 NK개의 수를 확인해야 할 것 같지만, 실제로는 N+K개의 수만 확인하면 된다. 두 번째 조건을 만족하는 후보를 먼저 찾고, 그 후보들 사이에서 세 번째 조건을 확인하는 방식으로 단계적으로 풀 수 있기 때문이다.
0x03 이항계수 - BOJ 11051 : 이항계수 2
이항계수 nCk를 구할 때, 팩토리얼을 직접 계산하면 값이 금방 넘친다. 대신 파스칼의 삼각형 성질을 이용하면 DP로 깔끔하게 구할 수 있다.
nCk = (n-1)C(k-1) + (n-1)Ck
n개 중 k개를 고르는 경우의 수는, 특정 원소를 "포함하는 경우"와 "포함하지 않는 경우"로 나뉜다는 뜻이다. 이 점화식을 그대로 테이블에 채워 나가면 된다.
for(int i=1; i<=n; i++) {
comb[i][0] = comb[i][i] = 1;
for(int j=1; j<i; j++) {
comb[i][j]= (comb[i-1][j] + comb[i-1][j-1]) % mod;
}
}comb[i][0]과 comb[i][i]는 항상 1이고(아무것도 안 고르거나 전부 고르는 경우), 나머지는 위 점화식으로 채운다. 모듈러 연산을 중간중간 적용해서 overflow를 방지하는 것이 포인트다.
문제 풀이
이번 챕터에서 풀었던 문제들 중 기억에 남는 것들을 정리한다.
BOJ 1700 멀티탭 스케줄링 - 멀티탭이 가득 찼을 때 어떤 플러그를 뽑아야 하는지 결정하는 문제다. 핵심은 현재 꽂혀 있는 전기용품 중 앞으로 가장 늦게 다시 사용되는 것을 뽑는 것이다. 운영체제의 페이지 교체 알고리즘(Optimal)과 같은 원리다.
BOJ 1193 분수찾기 - 분모와 분자를 따로 나눠서 생각해야 하는 문제다. 분자는 홀수 번째 대각선에서 증가하고 짝수 번째 대각선에서 감소한다. 분모는 i번째 대각선일 때 i+1에서 분자를 빼면 된다. 솔직히 이런 규칙을 찾아내는 것 자체가 꽤 까다롭다.
BOJ 1676 팩토리얼 0의 개수 - N!의 뒤에 붙는 0의 개수를 구하는 문제다. 뒤에 0이 붙으려면 10의 인수가 필요하고, 10 = 2 x 5이므로 2와 5가 몇 번 곱해지는지가 관건이다. 2의 개수는 항상 충분하므로, 결국 5의 개수만 세면 된다.
int n;
cin >> n;
cout << n/5 + n/25 + n/125 << endl;n/5는 5의 배수 개수, n/25는 25의 배수 개수(5를 두 번 포함), n/125은 125의 배수 개수(5를 세 번 포함)를 각각 세는 것이다. 이렇게 간단하게 풀리는 문제인데, 처음에는 다른 접근법으로 시도했다가 복잡해졌다.
int n;
cin >> n;
long long fact = 1;
int ans = 0;
for(int i=n; i>=2; i--) {
fact *= i;
if(fact % 10 == 0) {
fact /= 10;
fact %= 100000;
ans++;
}
}
cout << ans << endl;팩토리얼을 직접 계산하면서 10의 배수가 될 때마다 카운팅하고, 나머지 자릿수를 잘라내는 방식이다. 동작은 하지만, 수학적 성질을 이용한 풀이에 비하면 훨씬 복잡하다. 문제의 본질을 먼저 파악하는 것이 중요하다는 걸 다시 한번 느꼈다.
리뷰
소수, 최대공약수, 이항계수는 PS에서 너무 자주 나오는 도구여서, 한번 확실히 정리해두면 두고두고 써먹을 수 있다. 특히 에라토스테네스의 체와 유클리드 호제법은 구현이 짧으면서도 활용 범위가 넓으니 외워둘 만하다.
출처: 바킹독님의 실전알고리즘 강의