이전 글에서 Lakehouse 위에 데이터를 조직하는 Medallion Architecture를 살펴보았다. 이번 글에서는 Lakehouse를 가능하게 만드는 핵심 기술, Apache Iceberg의 내부 동작 원리를 파헤친다.
Iceberg가 해결하는 문제
Iceberg를 이해하려면 먼저 기존 데이터 레이크의 문제를 알아야 한다.
문제 1: 디렉토리 리스팅의 한계
기존 Hive 테이블은 데이터를 디렉토리 구조로 관리한다.
s3://data-lake/orders/
├── year=2025/month=01/ → 파일 수십 개
├── year=2025/month=02/ → 파일 수십 개
├── ...
├── year=2026/month=01/ → 파일 수십 개
└── year=2026/month=03/ → 파일 수십 개쿼리를 실행하면 엔진이 해야 할 일:
- S3에 "이 디렉토리에 파일이 뭐가 있어?" 요청 (디렉토리 리스팅)
- 수천 개 파티션 디렉토리를 하나씩 확인
- 각 디렉토리 안의 파일 목록도 확인
- 그제야 어떤 파일을 읽을지 결정
테이블이 커지면 (파티션 수천 개, 파일 수만 개) 이 "계획" 단계만 몇 분이 걸린다. 실제 데이터를 읽기도 전에 시간이 낭비된다. 디렉토리 리스팅은 O(n) — 파티션 수에 비례한다.
문제 2: 트랜잭션이 없다
Hive 데이터 레이크에는 ACID가 없다. 누군가 파일을 쓰는 도중에 다른 사람이 읽으면 깨진 데이터를 볼 수 있다. 파일을 덮어쓰다 실패하면 반쯤 쓰인 상태가 남는다.
문제 3: 스키마 변경이 위험하다
컬럼을 추가/삭제/이름 변경하면, 기존 Parquet 파일과 새 파일의 스키마가 달라진다. Hive는 컬럼을 위치(순서) 로 매핑하므로, 중간에 컬럼을 삭제하면 이후 컬럼이 전부 밀린다.
문제 4: 파티션이 사용자에게 노출된다
-- Hive: 사용자가 파티션 구조를 알아야 한다
SELECT * FROM orders WHERE year = 2026 AND month = 3;
-- "created_at >= '2026-03-01'"로 쓰면 파티션 프루닝이 안 됨!파티션 구조를 모르면 full scan이 된다. 파티션 전략을 바꾸려면 데이터 전체를 재작성해야 한다.
Iceberg의 해답
Iceberg는 디렉토리 리스팅을 완전히 대체한다. 모든 파일 목록과 통계를 메타데이터 파일 트리에 기록한다. 쿼리 엔진은 S3 디렉토리를 탐색할 필요 없이, 메타데이터만 읽으면 어떤 파일을 스캔할지 즉시 알 수 있다.
비유하면: Hive는 도서관에서 모든 서가를 걸어다니며 책을 찾는 것이고, Iceberg는 카탈로그(색인)를 보고 정확한 위치로 바로 가는 것이다.
아키텍처: 계층적 메타데이터
Iceberg의 메타데이터는 위에서 아래로 점점 더 세밀한 정보를 담는 트리 구조이다. 모든 레이어는 이뮤터블(불변) — 수정하지 않고 항상 새로 만든다.
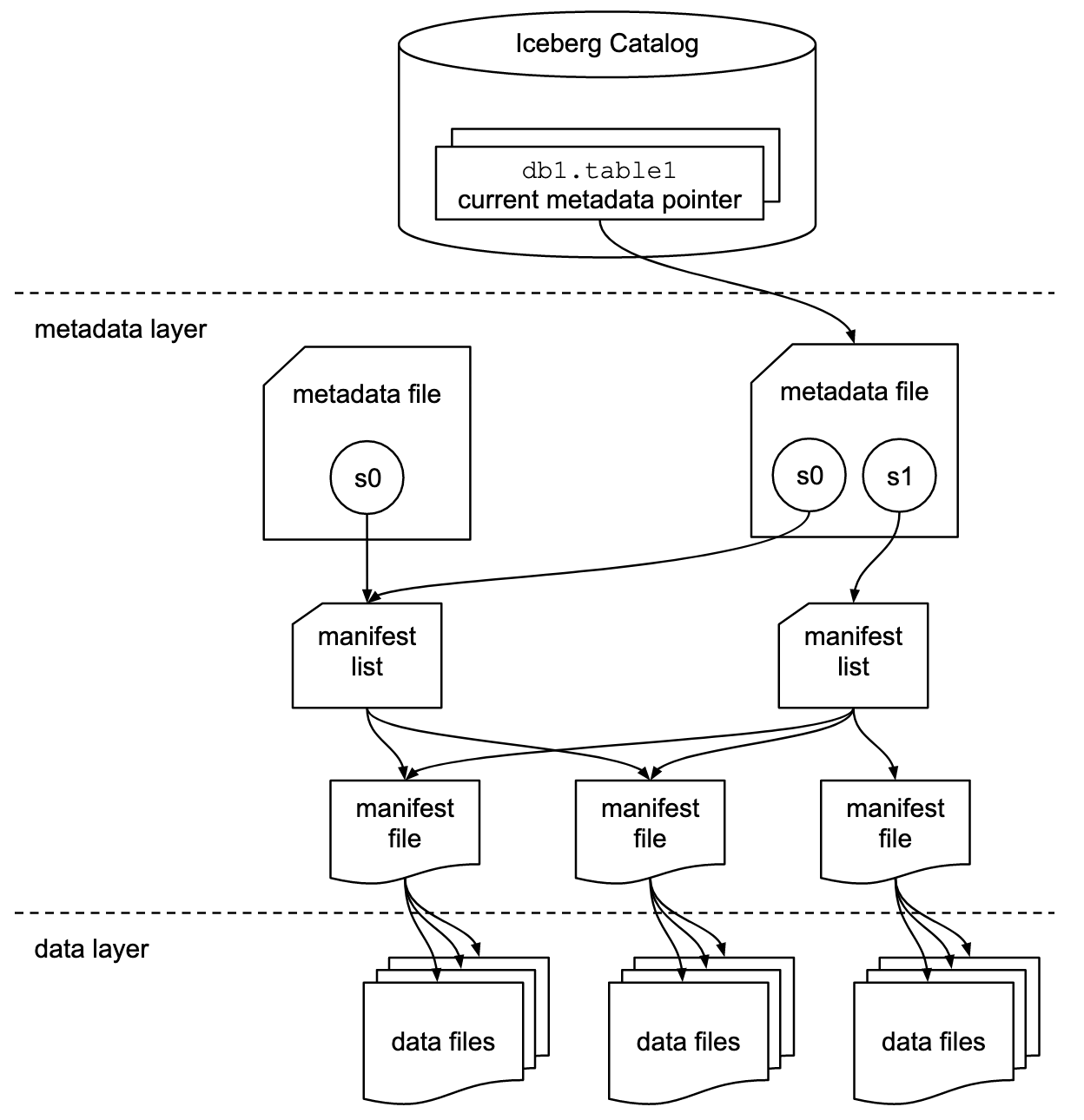
Catalog
└── "prod_db.orders" → metadata 위치
│
metadata.json (스키마, 파티션 스펙, 스냅샷 목록)
│
├── Snapshot 1 (과거) ··· Manifest List 1
├── Snapshot 2 (과거) ··· Manifest List 2
└── Snapshot 3 (현재) ─── Manifest List 3
│
┌──────────────┴──────────────┐
Manifest File A Manifest File B
(파티션: 2026-01~02) (파티션: 2026-03)
│ │ │ │
data-001 data-002 data-003 data-004
.parquet .parquet .parquet .parquet현재 스냅샷(Snapshot 3)이 활성 상태이고, 과거 스냅샷은 타임 트래블용으로 보존된다.
[1] Catalog — 출입구
테이블 이름(prod_db.orders)을 현재 metadata.json의 위치로 매핑한다.
"prod_db.orders" → s3://warehouse/orders/metadata/v3.metadata.json역할은 딱 하나: "이 테이블의 현재 상태가 어디에 있는지" 알려주는 것이다. 전화번호부와 같다.
종류: Hive Metastore, AWS Glue Data Catalog, Nessie (Git-like 브랜칭 지원), REST Catalog, Polaris (Snowflake 오픈소스)
[2] Table Metadata File — 테이블의 설계도
JSON 파일. 테이블에 대해 알아야 할 모든 것을 담고 있다.
{
"format-version": 2,
"table-uuid": "abc-123",
"schema": { "fields": [{"id": 1, "name": "order_id", "type": "long"}, ...] },
"partition-spec": [{"source-id": 4, "transform": "days", "name": "created_at_day"}],
"current-snapshot-id": 3,
"snapshots": [
{"snapshot-id": 1, "manifest-list": "s3://.../snap-1-manifest-list.avro"},
{"snapshot-id": 2, "manifest-list": "s3://.../snap-2-manifest-list.avro"},
{"snapshot-id": 3, "manifest-list": "s3://.../snap-3-manifest-list.avro"}
]
}핵심 포인트:
- 스냅샷 목록이 여기에 있다 — 타임 트래블의 기반
- 테이블 변경(INSERT, ALTER 등)이 일어나면 새 metadata.json을 생성하고, Catalog이 가리키는 포인터를 atomic swap한다
- 이것이 ACID의 핵심 — 읽기는 항상 이전 metadata를 참조하므로 중간 상태를 볼 수 없다
[3] Snapshot — 특정 시점의 테이블 상태
Git의 commit과 유사하다. 각 스냅샷은 "이 시점에서 테이블을 구성하는 파일 목록은 이것이다"를 나타낸다.
- INSERT → 새 스냅샷 생성 (파일 추가)
- DELETE → 새 스냅샷 생성 (파일 제거 표시)
- 이전 스냅샷은 삭제하지 않고 보존 → 타임 트래블 가능
- 오래된 스냅샷은 만료 정책(expiration)으로 정리
[4] Manifest List — 매니페스트들의 목차
Avro 파일. 이 스냅샷에 포함된 매니페스트 파일들의 목록과 요약 통계를 담는다.
manifest-list-3.avro:
┌──────────────────┬────────────────────┬──────────┐
│ manifest_path │ partition_summary │ added? │
├──────────────────┼────────────────────┼──────────┤
│ manifest-A.avro │ date: 2026-01~03 │ existing │
│ manifest-B.avro │ date: 2026-03~03 │ added │
└──────────────────┴────────────────────┴──────────┘왜 이 레이어가 필요한가? → 매니페스트 프루닝. 쿼리가 WHERE created_at = '2026-03-05'이면, 파티션 범위가 2026-01인 manifest-A는 읽지 않아도 된다. 수천 개 매니페스트 중 관련 있는 것만 골라낸다.
[5] Manifest File — 데이터 파일의 상세 카탈로그
Avro 파일. 실제 데이터 파일 하나하나의 경로, 파티션 값, 컬럼별 통계를 기록한다.
manifest-B.avro:
┌──────────────────────┬───────────┬─────────────────────────────┐
│ file_path │ partition │ column_stats │
├──────────────────────┼───────────┼─────────────────────────────┤
│ part-00042.parquet │ 2026-03-05│ amount: min=100, max=50000 │
│ │ │ rows=10000, nulls=0 │
│ part-00043.parquet │ 2026-03-05│ amount: min=50, max=99000 │
│ │ │ rows=8000, nulls=2 │
└──────────────────────┴───────────┴─────────────────────────────┘왜 이 레이어가 필요한가? → 파일 프루닝. 쿼리가 WHERE amount > 80000이면, max=50000인 part-00042.parquet는 열어볼 필요가 없다. 컬럼 통계만으로 스킵한다.
매니페스트 파일은 이뮤터블이고 스냅샷 간에 재사용된다. 데이터가 변하지 않은 파티션의 매니페스트는 다시 쓰지 않는다.
[6] Data Files — 실제 데이터
Parquet, ORC, Avro 형식의 파일이다. 이건 Hive와 동일하다. 차이는 이 파일들을 어떻게 찾고 관리하느냐이다.
쿼리 실행 흐름
SELECT * FROM orders WHERE created_at = '2026-03-05' AND amount > 80000이 실행되면:
1. Catalog에서 현재 metadata.json 위치 조회 → O(1)
2. metadata.json에서 현재 스냅샷 ID 확인 → O(1)
3. Manifest List에서 파티션 범위로 매니페스트 필터링 → 매니페스트 프루닝
(2026-01 파티션 매니페스트는 스킵)
4. 선택된 Manifest File에서 컬럼 통계로 파일 필터링 → 파일 프루닝
(amount max=50000인 파일은 스킵)
5. 최종 선택된 Parquet 파일만 읽기 → 최소 I/OHive: 1~4 과정 없이 모든 파일을 열어봐야 한다 → O(n)
Iceberg: 메타데이터로 사전 필터링 → O(1) 수준의 계획 + 최소 파일만 스캔
Hidden Partitioning
Iceberg의 핵심 차별점이다. 사용자가 파티션 구조를 몰라도 된다.
기존 문제: Hive 파티셔닝
-- 테이블 생성 시 파티션 컬럼을 별도로 정의
CREATE TABLE orders (...) PARTITIONED BY (year INT, month INT);
-- 쿼리할 때 사용자가 파티션 컬럼을 써야 최적화됨
SELECT * FROM orders WHERE year = 2026 AND month = 3; -- 파티션 프루닝 O
SELECT * FROM orders WHERE created_at >= '2026-03-01'; -- 프루닝 안 됨!문제점:
- 사용자가 year/month 컬럼의 존재를 알아야 한다
- 스키마에 합성 파티션 컬럼(year, month)이 추가되어 지저분하다
- 파티션 전략 변경(월별 → 일별) 시 데이터 전체를 재작성해야 한다
Iceberg: 자동으로 처리
-- 테이블 생성 시 transform 함수로 파티션 정의
CREATE TABLE orders (
order_id BIGINT,
amount DECIMAL(10,2),
created_at TIMESTAMP
) USING iceberg
PARTITIONED BY (days(created_at)); -- 내부적으로 일별 파티셔닝
-- 사용자는 원본 컬럼으로 쿼리하면 됨
SELECT * FROM orders WHERE created_at >= '2026-03-01';
-- Iceberg가 자동으로 days(created_at) 파티션에 매핑하여 프루닝- 스키마에 합성 컬럼이 없다 (
created_at만 존재) - 사용자는 파티션 구조를 신경 쓰지 않는다
- 지원하는 transform:
year,month,day,hour,bucket(N),truncate(N)
파티션 진화 (Partition Evolution)
데이터가 적을 때는 월별, 많아지면 일별로 파티셔닝을 바꾸고 싶다. Hive는 전체 재작성이 필요하지만, Iceberg는:
ALTER TABLE orders SET PARTITION SPEC (days(created_at));- 기존 데이터는 월별 파티셔닝 그대로 유지
- 새로 쓰이는 데이터만 일별 파티셔닝 적용
- 쿼리 시 Iceberg가 두 파티션 스펙을 모두 이해하고 최적화
- 데이터 재작성 없음 — 메타데이터만 변경
스키마 진화 (Schema Evolution)
기존 문제
Hive/Parquet은 컬럼을 위치(순서)로 매핑한다.
파일 A (구버전): [order_id, user_name, amount] → 3번째 = amount
파일 B (신버전): [order_id, amount] → 2번째 = amount
→ 위치가 달라서 user_name이 삭제되면 amount가 엉뚱한 값으로 읽힘Iceberg: 컬럼 ID 기반 매핑
Iceberg는 각 컬럼에 고유 ID를 부여한다.
order_id → ID: 1
user_name → ID: 2
amount → ID: 3파일 B에서 user_name(ID:2)이 없으면 → null 반환. amount(ID:3)는 ID로 찾으므로 위치가 바뀌어도 정확히 매핑된다.
지원하는 진화:
- 컬럼 추가/삭제/이름 변경 — 데이터 재작성 없음
- 타입 확장 (int → long, float → double)
- 중첩 struct 내부 필드 변경
ALTER TABLE orders ADD COLUMN category STRING;
ALTER TABLE orders RENAME COLUMN amount TO total_amount;
ALTER TABLE orders DROP COLUMN deprecated_field;타임 트래블 (Time Travel)
metadata.json에 모든 스냅샷 목록이 있으므로, 과거 시점의 데이터를 그대로 조회할 수 있다.
-- 스냅샷 ID로 조회
SELECT * FROM orders VERSION AS OF 123456789;
-- 타임스탬프로 조회
SELECT * FROM orders TIMESTAMP AS OF '2026-03-01 00:00:00';
-- 변경 이력 확인
SELECT * FROM catalog.db.orders.history;
SELECT * FROM catalog.db.orders.snapshots;Git의 git checkout <commit-hash>와 같은 개념이다. 활용 사례:
- 데이터 감사 (audit) — "이 데이터가 언제 이렇게 바뀌었지?"
- 잘못된 변환의 롤백 — "어제 ETL이 잘못 돌았으니 그 전 상태로 복구"
- ML 재현성 — "3월 1일 기준 데이터로 모델을 재학습"
ACID 트랜잭션
어떻게 보장하는가?
핵심은 "이뮤터블 메타데이터 + atomic swap" 이다.
[쓰기 흐름]
1. 새 데이터 파일을 S3에 업로드 (part-00099.parquet)
2. 새 매니페스트 파일 생성 (기존 + 새 파일 목록)
3. 새 매니페스트 리스트 생성
4. 새 metadata.json 생성 (새 스냅샷 추가)
5. Catalog의 포인터를 새 metadata.json으로 atomic swap ← 이 순간 커밋- 1~4 과정 중에 실패하면? → Catalog 포인터가 바뀌지 않았으므로 아무 일도 없었던 것
- 5가 성공해야만 변경이 보인다 → 원자성(Atomicity)
- 읽기는 항상 이전 포인터의 metadata를 참조 → 격리성(Isolation)
Optimistic Concurrency Control
동시에 두 작업이 쓰기를 시도하면?
- 둘 다 같은 metadata.json을 기반으로 새 metadata를 만든다
- 먼저 swap에 성공한 쪽이 커밋된다
- 늦은 쪽은 충돌을 감지하고, 최신 metadata를 기반으로 재시도한다
데이터베이스의 Optimistic Locking과 동일한 원리이다. 락을 잡지 않으므로 읽기 성능에 영향이 없다.
멀티 엔진 지원
| 엔진 | 읽기 | 쓰기 | 비고 |
|---|---|---|---|
| Apache Spark | O | O | 가장 성숙한 통합 |
| Apache Flink | O | O | 스트리밍 쓰기 지원 |
| Trino / Presto | O | O | 인터랙티브 쿼리 |
| Dremio | O | O | 네이티브 Iceberg 엔진 |
| Snowflake | O | O | 외부 테이블로 지원 |
| AWS Athena | O | O (v3) | 서버리스 쿼리 |
| ClickHouse | O | 제한적 | 분석 엔진 |
같은 테이블에 Spark으로 쓰고, Trino로 쿼리하고, Flink로 스트리밍 인제스트할 수 있다. 이것이 가능한 이유는 Iceberg가 특정 엔진에 종속되지 않는 포맷 스펙이기 때문이다. 이것이 Iceberg의 가장 큰 강점이다.
Catalog 종류
Iceberg 테이블의 현재 메타데이터 위치를 추적하는 시스템이다.
- Hive Metastore: 가장 전통적, 기존 Hadoop 환경과 호환
- AWS Glue Data Catalog: AWS 관리형, Athena/EMR과 통합
- Nessie: Git-like 브랜칭/태깅 지원 — 테이블을 브랜치해서 실험 가능
- REST Catalog: 표준 REST API 기반, 벤더 중립
- Polaris: Snowflake가 오픈소스화한 카탈로그
정리
Apache Iceberg는 기존 데이터 레이크의 근본적인 문제들 — 디렉토리 리스팅 병목, 트랜잭션 부재, 위험한 스키마 변경, 노출된 파티셔닝 — 을 계층적 메타데이터 트리로 해결한다.
- Catalog → Metadata → Manifest List → Manifest File → Data File 구조로 O(1) 수준의 쿼리 계획
- Hidden Partitioning으로 사용자는 파티션을 의식하지 않아도 된다
- 컬럼 ID 기반 스키마 진화로 안전한 스키마 변경
- 이뮤터블 메타데이터 + atomic swap으로 ACID 보장
- 스냅샷 기반 타임 트래블로 과거 데이터 조회와 롤백
- 벤더 중립 설계로 Spark, Flink, Trino 등 멀티 엔진 동시 접근
2026년 기준 가장 빠르게 채택률이 증가하는 테이블 포맷이며, Lakehouse 아키텍처의 핵심 기반 기술이다.