ETL 작업이 성공했다. 로그에 에러도 없다. 그런데 매출 대시보드 숫자가 2배로 뛰었다.
담당자가 알아차린 건 경영진이 "이번 달 매출이 왜 이렇게 좋아?"라고 물었을 때였다. 중복 적재였다. 모니터링은 "작업 성공, 행 수 정상"이라며 아무 알림도 보내지 않았다.
이것이 Silent Failure(조용한 실패)이다. 시스템은 정상인데 데이터는 망가진 상태. 데이터 파이프라인이 복잡해질수록 이런 장애는 기하급수적으로 늘어난다. Data Observability는 이 문제를 해결하기 위해 등장한 개념이다.
Data Downtime이란
Data Downtime은 데이터가 불완전하거나, 잘못되었거나, 누락되었거나, 부정확한 기간을 말한다. 소프트웨어의 "서버 다운타임"에 대응하는 데이터 세계의 개념이다.
문제는 Data Downtime이 소프트웨어 다운타임보다 발견이 훨씬 어렵다는 점이다. 서버가 죽으면 즉시 알 수 있지만, 데이터가 조용히 오염되면 누군가 잘못된 의사결정을 내리고 난 뒤에야 알게 된다.
Silent Failure의 전형적인 패턴:
- ETL 작업은 성공했지만, 소스 테이블 스키마가 변경되어 특정 컬럼이 전부 NULL로 적재됨
- 업스트림 시스템 장애로 데이터 수집이 중단되었지만, 파이프라인은 에러 없이 빈 데이터를 처리
- 중복 데이터가 적재되어 집계 결과가 2배로 부풀려졌지만 대시보드에서는 "정상 실행"으로 표시
실제 비용
이런 장애의 비용은 생각보다 크다.
- Gartner 조사: 낮은 데이터 품질로 인한 연평균 손실 $12.9M
- 데이터 품질 담당자의 **40%**가 비효율적인 품질 관리 작업에 시간을 소모
- Unity Software(2022): 대형 고객의 잘못된 데이터 수집 → 주가 30% 급락, $110M 매출 손실
반대로 Data Observability를 도입한 조직의 개선 사례도 뚜렷하다.
| 기업 | 개선 결과 |
|---|---|
| BlaBlaCar | 장애 해결 시간 50% 단축 |
| Choozle | 전체 Data Downtime 80% 감소 |
| Resident | 데이터 인시던트를 1년 전 대비 10% 수준으로 감소 |
Monitoring vs Observability
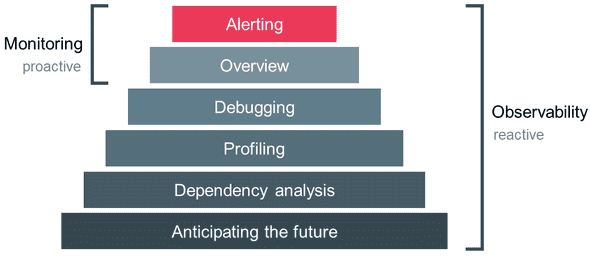
"Observability는 그냥 모니터링을 멋있게 부르는 거 아냐?"라는 질문을 자주 받는다. 결론부터 말하면, 모니터링은 Observability의 부분집합이다.
Known Unknowns vs Unknown Unknowns
둘의 핵심 차이는 어떤 종류의 문제를 다루는가이다.
- Known Unknowns (모니터링 영역): "CPU가 90% 넘으면 위험하다"처럼 무엇을 감시할지 이미 아는 상태. 미리 정의한 규칙과 임계값으로 감시한다.
- Unknown Unknowns (관측성 영역): "왜 화요일 오후 3시에만 특정 고객의 데이터가 누락되는가?"처럼 어떤 질문을 해야 할지조차 모르는 상태. 텔레메트리 데이터를 자유롭게 탐색하여 발견한다.
| 구분 | Monitoring | Observability |
|---|---|---|
| 대상 | Known Unknowns (예상 가능한 장애) | Unknown Unknowns (예측 불가능한 장애) |
| 관점 | 컴포넌트 뷰 (개별 지표 추적) | 시스템 뷰 (전체 상태 이해) |
| 접근 | Reactive — "문제가 발생했다" | Proactive — "왜 발생했고, 어떻게 고치는가" |
| 방식 | 사전 정의 메트릭·대시보드·임계값 | 탐색적 분석, ad-hoc 쿼리 |
| 답변 | What — 무엇이 잘못되었는가 | Why + How — 왜, 어떻게 고치는가 |
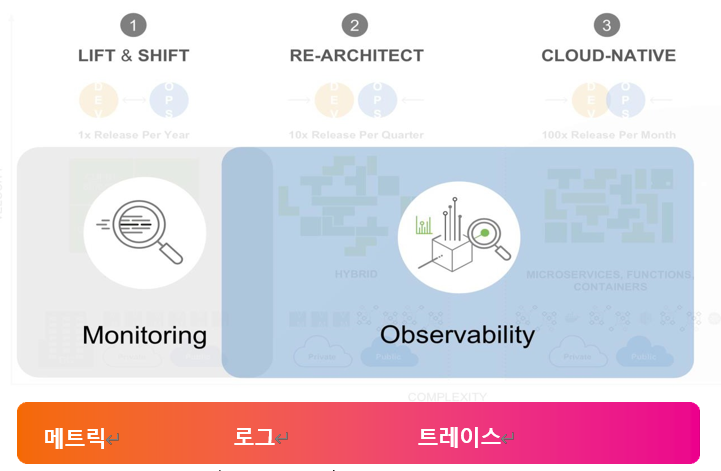
Observability의 3 Pillars
소프트웨어 관측성은 세 가지 텔레메트리 데이터를 결합하여 시스템 상태를 이해한다.
Metrics(메트릭): CPU 사용률, 응답 시간, 에러율 같은 수치 측정값이다. 시간에 따른 추세와 패턴 파악에 유용하며, "정상 상태의 베이스라인"을 정의할 수 있다.
Logs(로그): 시스템 이벤트의 타임스탬프 기록이다. 개별 이벤트의 상세 맥락을 제공하며, 평균이나 백분위에서 드러나지 않는 롱테일 이벤트를 발견할 수 있다.
Traces(추적): 분산 시스템에서 요청이 여러 서비스를 거치는 전체 경로를 추적한다. Logs와 Metrics만으로는 파악하기 어려운 병목, 의존성, 장애 근본 원인을 식별한다.
세 가지를 결합하면: Metrics가 "무언가 비정상"을 알리고 → Logs가 "어떤 이벤트가 발생했는지" 보여주고 → Traces가 "요청이 어디서 실패했는지" 경로를 추적한다.
Alert Fatigue 문제
모니터링의 구조적 한계는 사전에 예측한 문제만 감지할 수 있다는 것이다. 이로 인해 Alert Fatigue(알림 피로)가 발생한다.
- 정적 임계값 기반이라 일시적인 정상 스파이크에도 알림이 발생한다
- 규칙이 많아질수록 노이즈가 증가하고, 팀이 알림을 무시하기 시작한다
- 정작 중요한 알림이 노이즈에 묻혀 놓친다
Observability 도구는 베이스라인 학습으로 일시적 스파이크와 실제 이상을 구분하고, 고카디널리티(High Cardinality) 데이터로 알림에 맥락을 추가하여 이 문제를 완화한다.
고카디널리티의 중요성
카디널리티(Cardinality)란 데이터 속성의 고유한 값의 수를 말한다.
- 저카디널리티:
status_code(200, 404, 500 등 몇 개 안 됨) → 모니터링에 적합 - 고카디널리티:
request_id,user_id,commit_sha(수백만 개의 고유 값) → 관측성에 필수
디버깅할 때 "전체 에러율 5%"보다 "user_id=12345의 요청이 commit_sha=abc123 이후 100% 실패"라는 정보가 훨씬 유용하다. 이런 세밀한 슬라이싱은 고카디널리티 데이터 없이는 불가능하다. 전통적인 시계열 DB는 카디널리티가 높아지면 조합 폭발(Combinatorial Explosion)으로 성능이 급락하는데, 이것이 Honeycomb이나 ClickHouse 같은 관측성 전용 백엔드가 등장한 이유이다.
AIOps에서의 위치
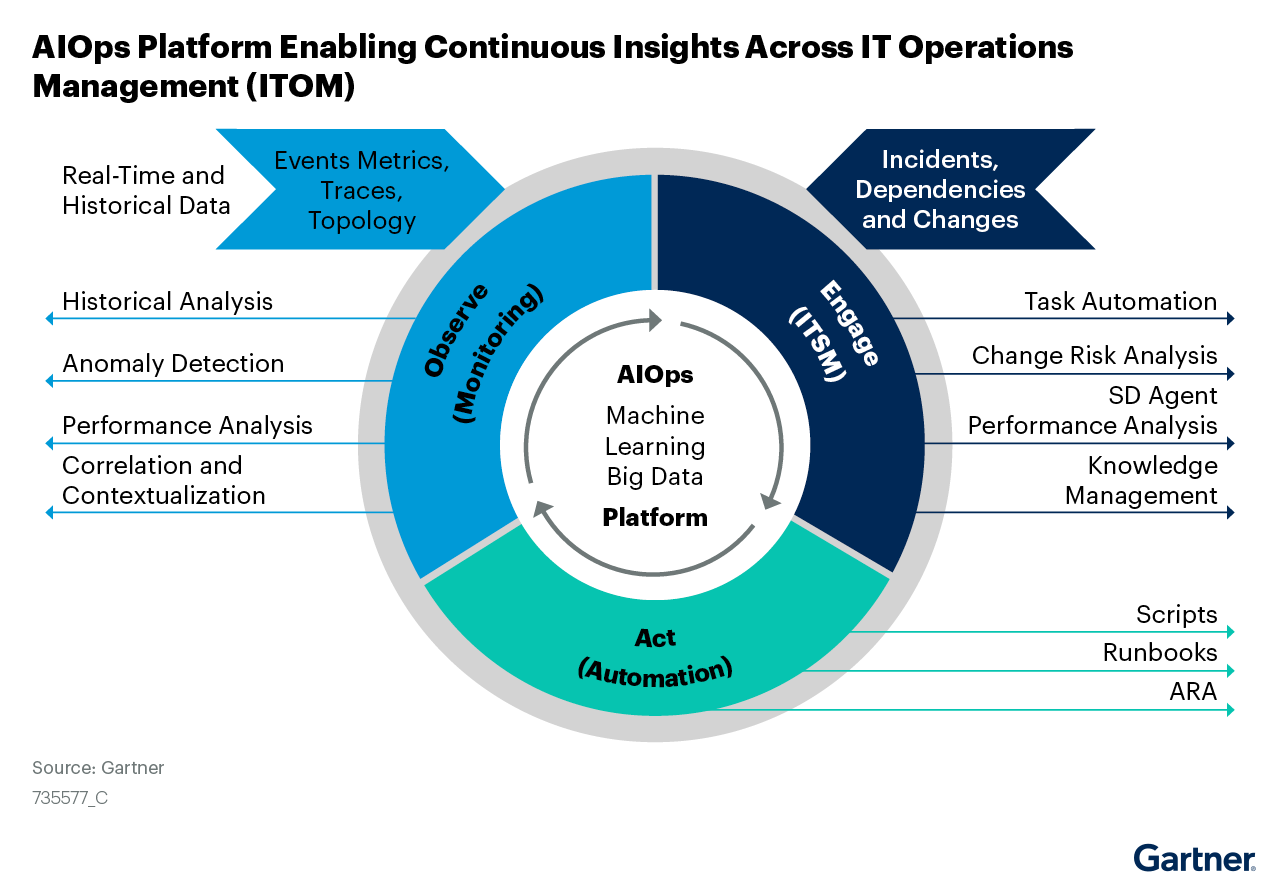
AIOps(AI for IT Operations)는 Observe → Engage → Act 세 단계가 순환하는 구조이다. Observability는 이 순환의 시작점이자 입력을 담당한다. Observe 단계에서 수집한 텔레메트리의 품질이 낮으면, 이후 Engage(인시던트 관리)와 Act(자동화)도 제대로 작동하지 않는다.
데이터 엔지니어링 맥락에서도 동일하다. Data Observability가 파이프라인의 이상을 정확히 감지해야(Observe), 인시던트 대응(Engage)과 자동 복구(Act)가 가능해진다.
Monitoring + Observability = 최선
비유하자면, Monitoring은 집에 화재 경보기를 설치하는 것이고, Observability는 왜 불이 났는지, 어디서 시작됐는지, 다른 방으로 번지고 있는지를 실시간으로 파악하는 것이다.
둘은 경쟁 관계가 아니라 함께 사용해야 한다.
Monitoring Observability
───────── ─────────────
"언제 문제가 생겼나" + "왜, 어디서, 어떻게 해결하나"
임계값 기반 알림 + ML 기반 이상 탐지
사전 정의 대시보드 + 탐색적 분석 (ad-hoc 쿼리)
빠른 설정, 낮은 비용 + 깊은 인사이트, 높은 투자
─────────────────────────────────────────────
= 종합적인 데이터 신뢰성 확보Software Observability vs Data Observability
Software Observability(Datadog, New Relic 등)와 Data Observability는 개념적 뿌리는 같지만 관측 대상이 다르다.
| 구분 | Software Observability | Data Observability |
|---|---|---|
| 대상 | 애플리케이션, 인프라 | 데이터 테이블, 파이프라인, 모델 |
| 신호 | Logs, Metrics, Traces | Freshness, Volume, Schema, Distribution, Lineage |
| 목표 | 시스템 가동 시간 & 성능 | 데이터 신뢰성 & 정확성 |
| 장애 유형 | 서버 다운, 레이턴시 증가 | Silent failure, 데이터 드리프트, 스키마 변경 |
| 도구 | Datadog, Grafana, PagerDuty | Monte Carlo, Atlan, Metaplane |
공통점이 있다. 두 영역 모두 다운타임이 발생하면 자가 치유되지 않으며, 시간이 지날수록 문제가 복합적으로 악화된다.
Data Observability의 5 Pillars
Monte Carlo가 정의한 Data Observability의 5대 축이다. 이 프레임워크로 데이터 건강 상태를 체계적으로 평가할 수 있다.
[Source A] ──▶ [ETL Job] ──▶ [Warehouse Table] ──▶ [BI Dashboard]
│ │ │ │
└── Schema? └── Freshness? └── Volume? └── 영향 범위
Distribution?1. Freshness (신선도)
데이터 테이블이 얼마나 최신인지, 업데이트 주기가 정상인지를 추적한다. 의사결정에서 오래된 데이터는 낭비된 시간과 비용의 동의어이다.
- 감지 예시: "매일 오전 6시에 갱신되는 테이블이 12시간째 업데이트 없음"
- 원인: 업스트림 소스 장애, ETL 작업 실패, 스케줄링 오류
2. Volume (볼륨)
데이터 테이블의 행 수나 크기에서 예기치 않은 변화를 감지한다. 누락이나 중복을 조기에 발견할 수 있다.
- 감지 예시: "어제 대비 90% 적은 데이터 적재", "갑자기 행 수가 2배로 증가"
- 원인: 소스 시스템 장애, 중복 적재, 필터 조건 변경
3. Distribution (분포)
데이터 값의 분포가 기대 범위 내에 있는지를 확인한다. NULL 비율, 유니크 값 비율, 값 범위 등을 추적한다.
- 감지 예시: "user_id 컬럼의 NULL 비율이 갑자기 40%로 증가", "price 컬럼에 음수 값 등장"
- 원인: 소스 데이터 변경, 매핑 오류, 비즈니스 로직 변경
4. Schema (스키마)
테이블 구조의 변경을 추적한다. 컬럼 추가, 삭제, 타입 변경은 데이터 장애의 가장 흔한 원인 중 하나이다.
- 감지 예시: "order_date 컬럼이 STRING에서 TIMESTAMP로 변경됨", "새 컬럼 3개 추가"
- 원인: 업스트림 팀의 스키마 마이그레이션, API 버전 변경
5. Lineage (리니지)
데이터가 소스에서 소비자까지 흐르는 전체 경로를 추적한다. 장애 발생 시 영향 범위를 파악하고 근본 원인을 역추적할 수 있다.
- 활용: "이 테이블에 문제가 생기면 어떤 대시보드가 영향받는가?"
- 가치: 장애 범위 파악, 영향도 분석, 데이터 소유권 관리
구현 접근 방식
Data Observability를 실현하는 데는 크게 두 가지 접근이 있다.
메타데이터 기반 자동 탐지 (ML 기반)
실제 데이터를 읽지 않고 메타데이터(행 수, 스키마 정보, 갱신 시각 등)를 ML로 분석하여 이상을 탐지한다. 데이터 접근 권한 문제를 우회하고 성능 부하를 최소화할 수 있다.
대표 도구인 Monte Carlo가 이 방식이다. 히스토리 패턴을 자동 학습하여 임계값 설정 없이 이상을 탐지하고, 필드 레벨 리니지와 자동 근본 원인 분석(RCA)을 제공한다.
규칙 기반 검증
팀이 명시적으로 검증 규칙을 정의하는 방식이다. 정밀도가 높고 비즈니스 로직을 직접 반영할 수 있다.
대표 도구인 Great Expectations(GX)가 이 방식이다. "이 컬럼은 NULL이 없어야 한다", "이 값은 0~100 사이여야 한다" 같은 Expectation을 Python으로 정의하고, Checkpoint로 파이프라인 내에서 자동 검증한다.
실무에서는 둘 다 쓴다
ML 기반으로 넓은 범위를 자동 감시하고, 핵심 테이블에는 규칙 기반 검증을 추가하는 것이 현실적인 전략이다.
Data Quality vs Data Observability
마지막으로 자주 혼동되는 Data Quality와 Data Observability의 관계를 정리한다.
| 구분 | Data Quality | Data Observability |
|---|---|---|
| 정의 | 데이터가 의도된 용도에 얼마나 부합하는지 | 데이터 건강 상태를 지속적으로 모니터링하는 능력 |
| 초점 | 정적 데이터의 정확성·완전성 평가 | 파이프라인 내 데이터 흐름의 신뢰성 모니터링 |
| 타이밍 | 스케줄된 검증 (배치, 특정 시점) | 연속적 실시간 모니터링 |
| 접근 | Reactive — 문제 발견 후 수정 | Proactive — 이상 조기 탐지 |
| 대상 | Data at rest (저장된 데이터) | Data in motion (흐르는 데이터) |
Quality가 목표라면, Observability는 수단이다. (goal vs means) Quality가 "좋은 데이터의 기준"을 정의하면, Observability가 그 기준이 실시간으로 충족되고 있는지 감시한다.
정리
데이터 파이프라인은 갈수록 복잡해지고, Silent Failure의 위험도 함께 커진다. 기존 모니터링만으로는 "시스템이 돌아가는지"는 알 수 있지만, "데이터가 정확한지"는 알 수 없다.
Data Observability는 이 간극을 메운다.
- 5 Pillars(Freshness, Volume, Distribution, Schema, Lineage)로 데이터 건강을 체계적으로 평가하고
- ML 기반 자동 탐지 + 규칙 기반 검증을 결합하여 Silent Failure를 조기에 포착하며
- 리니지로 근본 원인과 영향 범위를 즉시 파악한다
다음 글에서는 이 개념을 실현하는 대표 도구들 — Monte Carlo, Great Expectations, OpenTelemetry — 을 각각 깊이 다뤄본다.
참고 자료
- What Is Data Observability? 5 Key Pillars To Know — Monte Carlo Blog
- Incident Prevention: The 5 Pillars of Data Observability — Monte Carlo Blog
- 61 Data Observability Use Cases From Real Data Teams — Monte Carlo Blog
- Data Quality vs Data Observability — Metaplane
- Data Observability vs. Data Quality: 6 Key Differences — Atlan
- Observability vs. Monitoring: What's the Difference? — IBM
- Data Observability vs Software Observability — Metaplane
- Three Pillars of Observability: Logs, Metrics and Traces — IBM
- What is Data Observability? — Databricks