이전 글에서 Lakehouse 아키텍처의 원리를 살펴보았다. Lakehouse라는 그릇은 만들었는데, 그 안에 데이터를 어떻게 정리할 것인가? 그 답이 Medallion Architecture다.
Medallion이란?
Databricks가 대중화한 데이터 조직 패턴으로, 데이터를 Bronze → Silver → Gold 세 계층으로 나누어 품질을 점진적으로 향상시킨다.
데이터 소스 → [Bronze] → [Silver] → [Gold] → BI / ML / 분석
(원본) (정제) (비즈니스)각 계층을 거칠수록 데이터는 더 깨끗하고, 더 구조화되고, 더 비즈니스 친화적이 된다. Databricks가 이름을 지었지만, 벤더에 종속되지 않는 범용적인 설계 패턴이다.
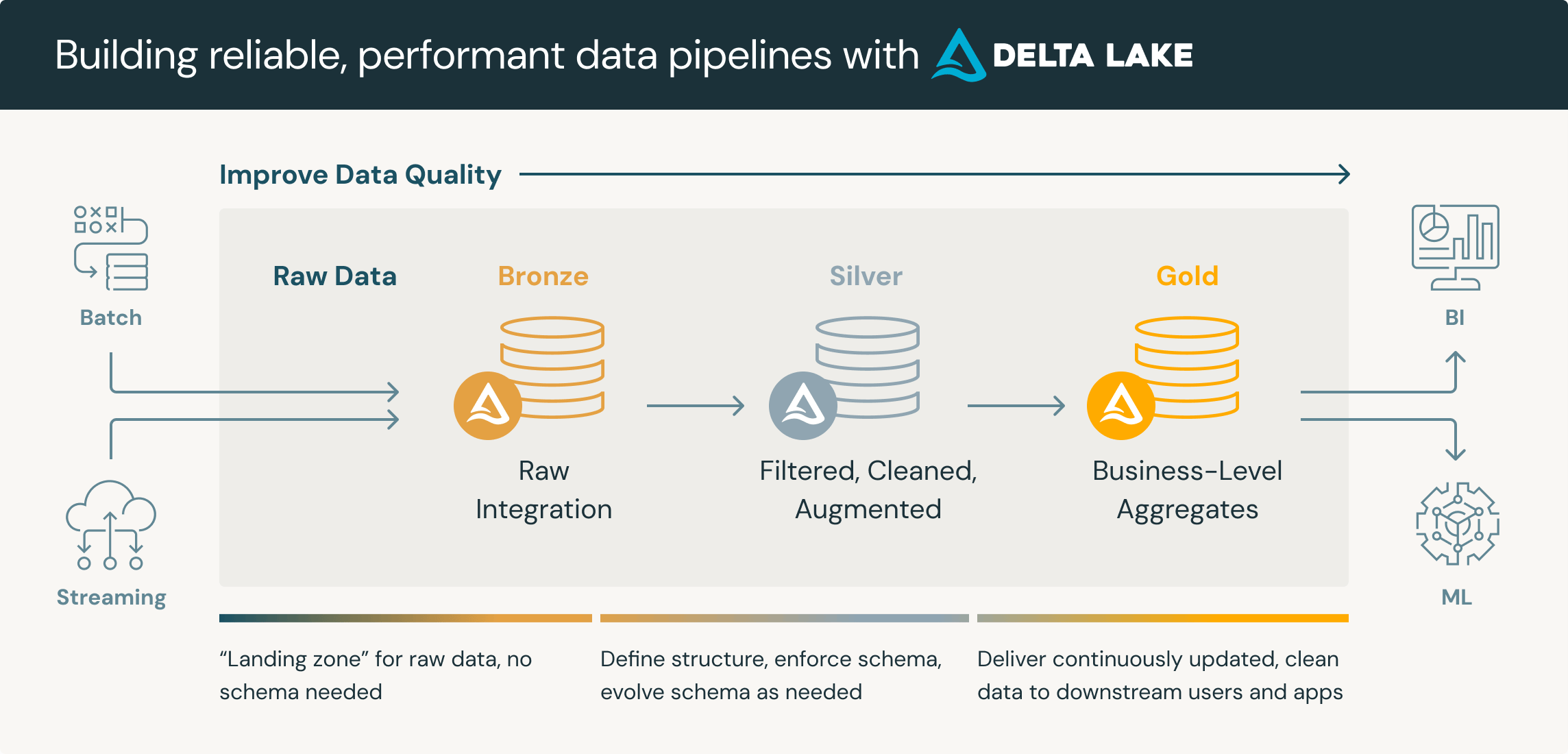
Bronze Layer (Raw)
원본 데이터를 있는 그대로 저장한다.
- Append-only 방식으로 수집
- 스키마 변환 없이 원본 그대로 보존
- 메타데이터 추가: 수집 타임스탬프, 소스 ID, 배치 ID
- 데이터 리니지(lineage)의 출발점
- 문제 발생 시 원본에서 재처리 가능
# Bronze: Kafka에서 원본 그대로 적재
bronze_df = (
spark.readStream
.format("kafka")
.option("subscribe", "orders")
.load()
.selectExpr(
"CAST(value AS STRING) as raw_data",
"topic",
"partition",
"offset",
"timestamp as kafka_timestamp",
"current_timestamp() as ingested_at"
)
)
bronze_df.writeStream \
.format("iceberg") \
.outputMode("append") \
.toTable("catalog.bronze.orders_raw")Bronze의 철학은 "일단 빠르게 저장하고, 변환은 나중에" 이다. 소스 시스템과의 커플링을 최소화하고, 원본을 절대 잃지 않는 것이 핵심이다.
저장 포맷은 JSON, Avro, CSV 등 원본 그대로이거나, Parquet으로 변환하되 내용은 변경하지 않는다.
Silver Layer (Curated)
정제되고 구조화된 데이터. "신뢰할 수 있는 진실의 원천(Single Source of Truth)"이다.
Bronze에서 읽어 다음을 수행한다:
- 중복 제거 (deduplication)
- 데이터 타입 변환 및 표준화
- NULL 처리, 유효성 검증
- 스키마 적용 (Schema Enforcement)
- 테이블 간 조인으로 관계 정립
- PII 마스킹, 데이터 품질 체크
# Silver: Bronze에서 읽어 정제
order_schema = "order_id STRING, user_id STRING, amount DOUBLE, status STRING, created_at TIMESTAMP"
silver_df = (
spark.read.table("catalog.bronze.orders_raw")
.select(from_json(col("raw_data"), order_schema).alias("data"), "ingested_at")
.select("data.*", "ingested_at")
.dropDuplicates(["order_id"]) # 중복 제거
.filter(col("order_id").isNotNull()) # NULL 필터링
.filter(col("amount") >= 0) # 유효성 검증
)
silver_df.writeTo("catalog.silver.orders") \
.using("iceberg") \
.createOrReplace()Silver는 데이터 엔지니어와 분석가 모두 사용할 수 있는 계층이다. 여기까지 오면 데이터를 "믿고 쓸 수 있다."
Gold Layer (Business)
비즈니스 로직이 적용된 분석용 데이터. 특정 유스케이스에 최적화되어 있다.
- 비즈니스 규칙에 따른 집계 (일별 매출, 월별 사용자 수)
- KPI 계산
- 도메인별 데이터 마트
- BI 대시보드, ML 피처용 데이터셋
# Gold: 일별 매출 집계
gold_daily_revenue = (
spark.read.table("catalog.silver.orders")
.filter(col("status") == "delivered")
.groupBy(col("created_at").cast("date").alias("order_date"))
.agg(
count("order_id").alias("total_orders"),
sum("amount").alias("total_revenue"),
avg("amount").alias("avg_order_value")
)
)
gold_daily_revenue.writeTo("catalog.gold.daily_revenue") \
.using("iceberg") \
.createOrReplace()Gold는 비즈니스 분석가나 ML 엔지니어가 바로 사용할 수 있어야 한다.
계층 간 비교
| 항목 | Bronze | Silver | Gold |
|---|---|---|---|
| 데이터 품질 | 원본 그대로 | 정제, 검증됨 | 비즈니스 로직 적용 |
| 스키마 | Schema-on-Read | Schema-on-Write | 도메인별 스키마 |
| 중복 | 있을 수 있음 | 제거됨 | 없음 |
| 사용자 | 데이터 엔지니어 | 엔지니어 + 분석가 | 분석가 + ML |
| 보존 기간 | 장기 보존 | 중기 | 단기~중기 |
| 변환 비용 | 없음 | 중간 | 높음 |
설계 원칙
ELT, ETL이 아니다
Lakehouse + Medallion에서는 ELT가 표준이다.
- Load first (Bronze): 원본을 빠르게 적재하여 소스 시스템과의 커플링을 최소화
- Transform later (Silver, Gold): Lakehouse 내에서 탄력적인 컴퓨팅으로 변환
ETL은 데이터를 웨어하우스에 넣기 전에 변환했다. ELT는 일단 넣고, 안에서 변환한다. Lakehouse의 스토리지-컴퓨팅 분리 구조 덕분에 이 방식이 가능해졌다.
독단적으로 적용하지 말 것
Medallion은 유용한 사고 모델이지만, 모든 경우에 세 계층이 필요한 건 아니다.
- 단순한 파이프라인은 Bronze → Gold로 충분할 수 있다
- 데이터 소스, 팀 워크플로우, 운영 제약에 맞게 조정한다
- 계층의 수보다 "원본 보존 + 점진적 정제"라는 원칙이 더 중요하다
데이터 품질 게이트
각 계층 전환 시 품질 검증을 넣어야 한다.
- Bronze → Silver: NULL 체크, 스키마 검증, 중복 탐지
- Silver → Gold: 비즈니스 규칙 검증, 볼륨 이상 탐지
- 도구: Great Expectations, Soda, dbt tests
품질 게이트 없이 계층을 나누는 것은, 문을 만들어 놓고 잠그지 않는 것과 같다.
Data Mesh와의 결합
최근 트렌드로, Medallion의 데이터 조직 패턴과 Data Mesh의 도메인 소유권을 결합하는 사례가 늘고 있다.
[주문 도메인] [사용자 도메인]
Bronze → Silver → Gold Bronze → Silver → Gold
(주문 팀 소유) (사용자 팀 소유)각 도메인 팀이 자신의 Medallion 파이프라인을 소유하고, Gold 레이어를 "데이터 프로덕트"로 외부에 제공한다.
정리
Medallion Architecture는 Lakehouse 안에서 데이터를 체계적으로 정리하는 검증된 패턴이다.
- Bronze: 원본을 있는 그대로 보존한다 (재처리의 기반)
- Silver: 정제하고 검증하여 신뢰할 수 있는 데이터를 만든다
- Gold: 비즈니스 로직을 적용하여 분석/ML에 바로 쓸 수 있게 한다
- ELT 방식으로 먼저 적재, 나중에 변환한다
- 세 계층이 항상 필요한 건 아니다 — 원본 보존 + 점진적 정제 원칙이 핵심이다
다음 글에서는 이 모든 것을 가능하게 하는 핵심 기술, Apache Iceberg의 아키텍처와 동작 원리를 깊이 파헤친다.