이전 글에서 데이터 레이크, 웨어하우스, 그리고 이 둘을 합치는 Lakehouse 패러다임을 개괄적으로 살펴보았다. 이번 글에서는 Lakehouse가 어떤 원리로 동작하는지, 그리고 이를 가능하게 하는 오픈 테이블 포맷을 깊이 파헤친다.
Two-Tier 아키텍처의 문제
많은 조직이 데이터 레이크와 웨어하우스를 동시에 운영한다.
[데이터 소스] → [Data Lake (S3)] → ETL → [Data Warehouse (Redshift)] → [BI/분석]
↓
[ML 플랫폼]이 구조의 고통:
- 데이터 중복: 같은 데이터가 레이크와 웨어하우스에 각각 존재한다
- ETL 파이프라인 부담: 레이크에서 웨어하우스로의 변환/동기화가 필요하다
- 데이터 불일치: 두 시스템 간 데이터가 어긋날 수 있다
- 비용 증가: 스토리지와 컴퓨팅을 이중으로 지불한다
ML에는 레이크를, BI에는 웨어하우스를 쓴다. 같은 데이터를 두 번 저장하고, 두 번 관리하고, 두 번 비용을 낸다.
Lakehouse의 해결
[데이터 소스] → [Lakehouse (S3 + 오픈 테이블 포맷)] → [BI / ML / 분석]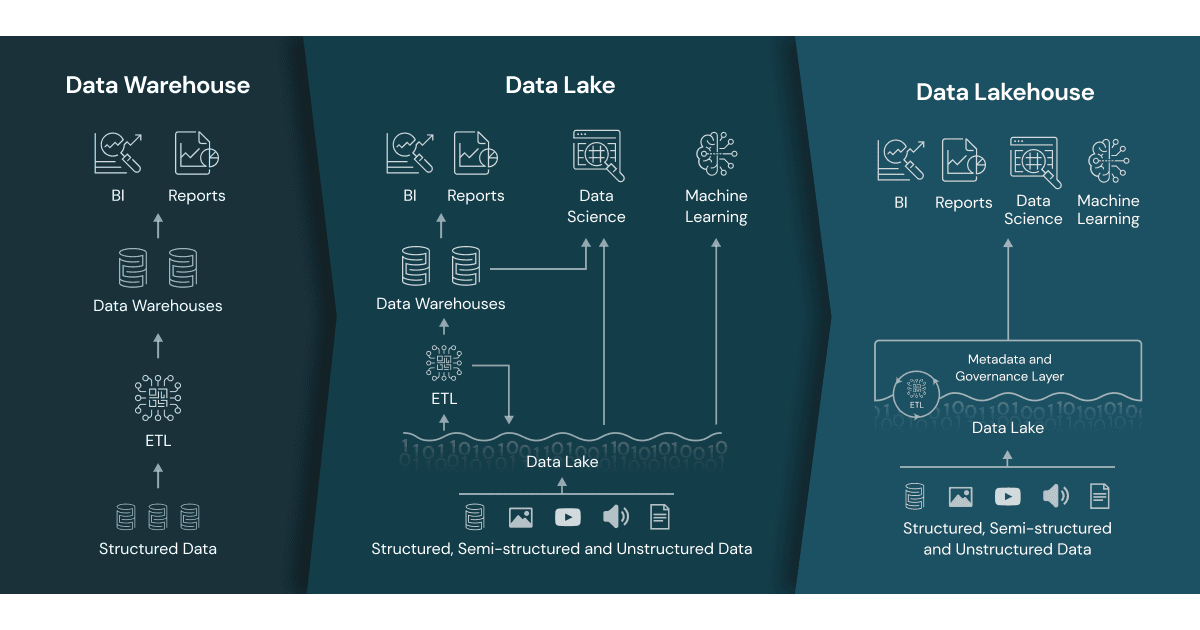
핵심 아이디어는 간단하다. S3 같은 저렴한 오브젝트 스토리지에 Parquet 파일을 저장하되, 그 위에 메타데이터 레이어를 추가해서 웨어하우스급 관리 기능을 제공하는 것이다.
이 메타데이터 레이어가 바로 오픈 테이블 포맷이다.
| 기능 | 전통적 데이터 레이크 | Lakehouse |
|---|---|---|
| ACID 트랜잭션 | X | O |
| 스키마 진화 (Schema Evolution) | X | O |
| 타임 트래블 (Time Travel) | X | O |
| MERGE / UPSERT | X | O |
| 파티션 진화 (Partition Evolution) | X | O |
| 통계 기반 파일 스킵 | 제한적 | O |
단일 저장소에서 BI와 ML을 모두 처리할 수 있으니, ETL 파이프라인도 간소화된다.
핵심 설계 원칙: 스토리지와 컴퓨팅 분리
Lakehouse의 기반이 되는 아키텍처 원칙이다.
[Object Storage (S3/GCS)] ← 데이터 저장 (저비용, 무한 확장)
↕
[Compute Engine (Spark/Trino/Flink)] ← 쿼리 실행 (필요시 스케일)- 스토리지와 컴퓨팅을 독립적으로 확장한다
- 여러 컴퓨트 엔진이 같은 데이터에 동시 접근 가능하다
- 컴퓨팅은 사용할 때만 비용이 발생한다
전통적인 웨어하우스는 스토리지와 컴퓨팅이 묶여 있어서, 둘 중 하나만 늘리고 싶어도 같이 확장해야 했다. Lakehouse는 이 결합을 끊는다.
오픈 테이블 포맷 삼국지
Lakehouse를 가능하게 만드는 핵심 기술이다. 2026년 기준 세 가지가 경쟁하고 있다.
Apache Iceberg
Netflix에서 개발하고, Apache Software Foundation이 관리한다.
- 벤더 중립적: Spark, Flink, Trino, Snowflake, AWS Athena 등 다양한 엔진을 네이티브로 지원
- Hidden Partitioning: 사용자가 파티션 구조를 몰라도 자동 최적화
- 계층적 메타데이터: Catalog → Metadata File → Manifest List → Manifest File → Data File
- 페타바이트 급 대규모 테이블에 최적화
- 2026년 기준 가장 빠르게 채택률이 증가하는 포맷
Delta Lake
Databricks에서 개발하고, Linux Foundation이 관리한다.
- Spark 에코시스템과 깊은 통합 — Databricks 환경에서 최고의 성능
- Transaction Log (
_delta_log): JSON/Parquet 기반 변경 이력 추적 - Change Data Feed: CDC를 스토리지 계층에서 지원
- UniForm: Delta 테이블을 Iceberg/Hudi로도 읽을 수 있게 하는 호환성 레이어
Apache Hudi
Uber에서 개발했다.
- 증분 처리(Incremental Processing) 에 강점
- Copy-on-Write / Merge-on-Read 두 가지 테이블 유형
- CDC 파이프라인에 특화
Iceberg vs Delta Lake
가장 많이 비교되는 두 포맷을 정리한다.
| 항목 | Apache Iceberg | Delta Lake |
|---|---|---|
| 개발 주체 | Netflix → ASF | Databricks → Linux Foundation |
| 엔진 호환성 | 멀티 엔진 (벤더 중립) | Spark 최적화 (타 엔진은 커넥터) |
| 메타데이터 구조 | 계층적 (manifest list → manifest) | Transaction Log (JSON + Parquet) |
| 파티셔닝 | Hidden Partitioning (자동) | 명시적 파티셔닝 |
| 스키마 진화 | 완전한 type-safe 진화 | 지원하지만 상대적으로 제한적 |
| 대규모 테이블 | 페타바이트 급 최적화 | 대규모 지원, Spark에서 최적 |
| 호환성 전략 | 네이티브 멀티 엔진 | UniForm으로 Iceberg/Hudi 호환 |
| 주요 채택처 | AWS, Snowflake, Netflix, Apple | Databricks, Microsoft, T-Mobile |
선택 가이드
- 멀티 엔진 환경 (Trino + Spark + Flink): → Iceberg
- Databricks/Spark 중심: → Delta Lake
- 벤더 락인 회피가 우선: → Iceberg
- CDC/증분 처리 중심: → Hudi 또는 Delta Lake
실제로 2026년에는 Delta Lake가 UniForm으로 Iceberg 호환성을 확보하면서, 두 포맷이 수렴하는 추세다. 어떤 포맷을 선택하든 Lakehouse 아키텍처 자체가 주는 이점은 동일하다.
2026년 동향
- Gartner가 Lakehouse를 "transformational"로 격상
- Apache Iceberg 채택률 급상승 — AWS, Snowflake, Google Cloud 모두 네이티브 지원
- Delta Lake는 UniForm으로 Iceberg 호환성을 확보하며 수렴 중
- 신규 데이터 플랫폼 프로젝트의 기본 아키텍처로 자리잡음
정리
Lakehouse는 "데이터 레이크냐 웨어하우스냐"라는 이분법을 해소한다. 저렴한 오브젝트 스토리지 위에 오픈 테이블 포맷의 메타데이터 레이어를 얹어, 하나의 저장소에서 BI와 ML을 모두 처리할 수 있다.
- 스토리지-컴퓨팅 분리로 독립적 확장이 가능하다
- 오픈 테이블 포맷(Iceberg, Delta Lake, Hudi)이 ACID, 스키마 진화, 타임 트래블을 제공한다
- 멀티 엔진 환경이면 Iceberg, Databricks 중심이면 Delta Lake가 유리하다
다음 글에서는 Lakehouse 위에서 데이터를 어떻게 조직하는지 — Bronze, Silver, Gold 세 계층으로 나누는 Medallion Architecture를 살펴본다.