2.1 네트워크 애플리케이션의 원리
이 장에서는 application-layer protocol의 개념과 구현을 다룬다. 애플리케이션 계층은 혼자서 서비스를 제공하지 못하기 때문에, transport-layer service model과의 관계를 이해하는 것이 중요하다. 주요 패러다임으로는 client-server와 peer-to-peer(P2P) 두 가지가 있다.
네트워크 앱 만들기
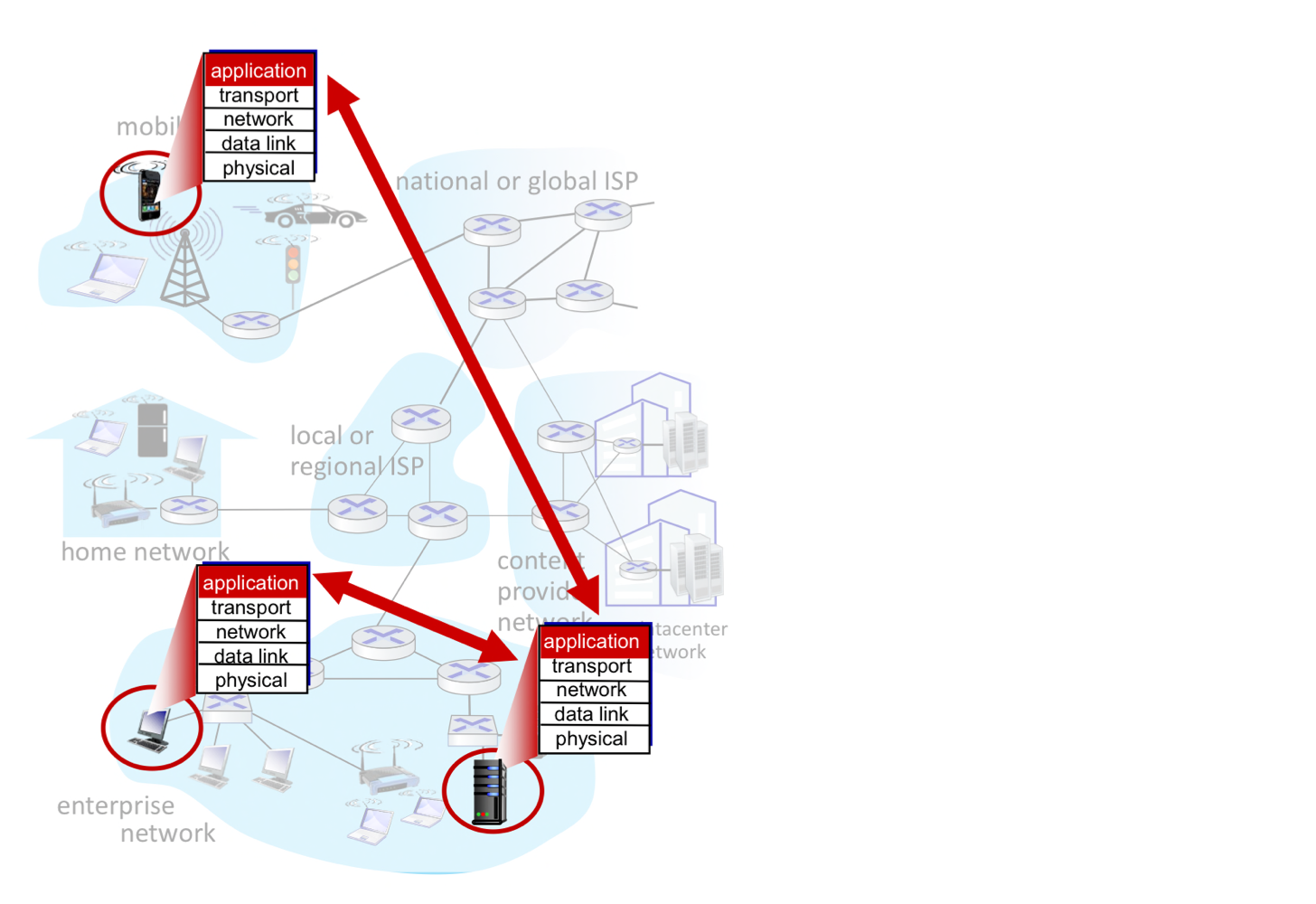
네트워크 애플리케이션을 만든다는 것은, 서로 다른 end system 위에서 실행되며 네트워크를 통해 통신하는 프로그램을 작성하는 것이다. 예를 들어 웹의 경우, web server 소프트웨어와 browser 소프트웨어가 서로 통신한다.
network-core device(라우터, 스위치 등)에는 애플리케이션 소프트웨어를 작성할 필요가 없다. 이들은 애플리케이션 계층에서 동작하지 않기 때문이다. 애플리케이션이 end system에서만 동작한다는 점 덕분에, 빠르게 앱을 개발할 수 있다.
여기서 네트워크 구조와 애플리케이션 구조는 구별해야 한다. 네트워크 구조는 개발자 관점에서 고정되어 있고, 특정 서비스 집합을 제공한다. 반면 애플리케이션 구조는 개발자가 설계하며, 여러 종단 시스템에서 어떻게 조직되어야 하는지를 결정한다.
Client-Server 아키텍처
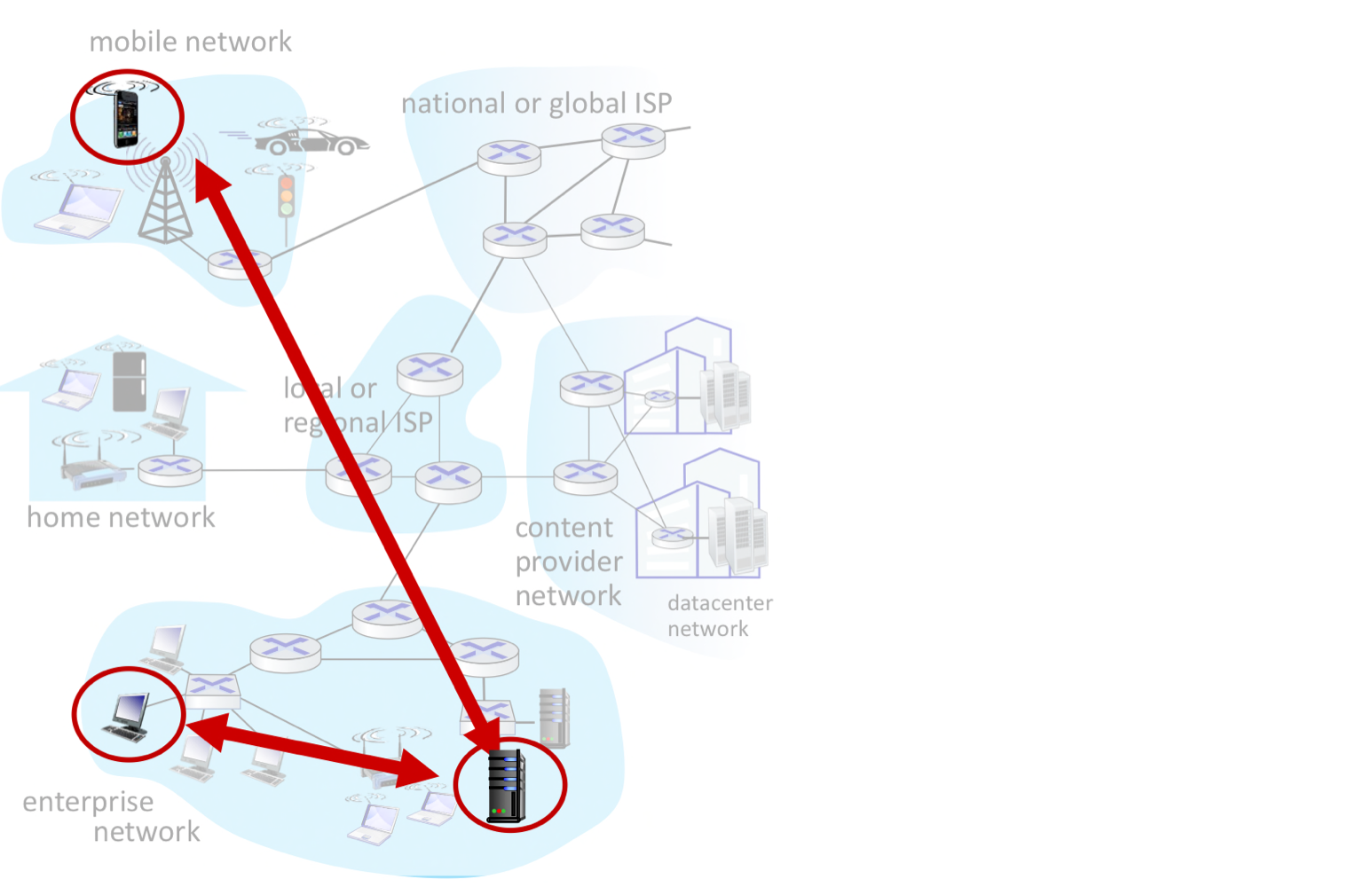
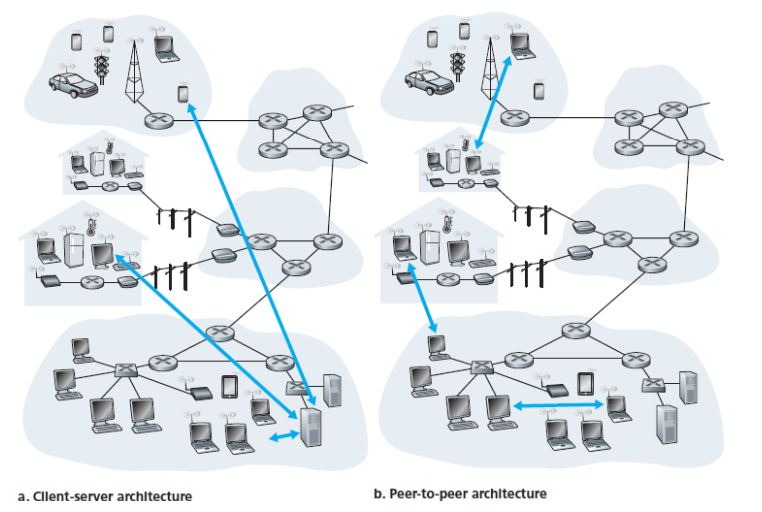
Server는 확장성(Scalability) 문제를 안고 있다.
- 항상 켜져 있는(always-on) 호스트
- 고정 IP 주소를 가짐
- 확장을 위해 주로 데이터 센터에 배치 (보통 10만 개 이상의 서버를 갖추고 있다)
Client는 다음과 같은 특징이 있다.
- 서버와 통신
- 간헐적(intermittently)으로 연결될 수 있음
- 동적 IP 주소를 가질 수 있음
- 클라이언트끼리는 직접 통신하지 않음
P2P 아키텍처
P2P에서는 항상 켜져 있는 서버가 없다. 임의의 end system들이 직접 통신한다. 각 peer는 다른 peer에게 서비스를 요청하는 동시에 서비스를 제공한다.
핵심 특징은 self scalability이다. 새로운 peer가 참여하면 서비스 수요도 늘어나지만, 동시에 서비스 용량도 함께 증가한다. 데이터 센터 등이 필요 없어 비용 효율적이기도 하다. 다만 peer들이 간헐적으로 연결되고 IP 주소가 바뀔 수 있어(NAT 문제: public IP와 private IP 변환), 관리가 복잡하다.
프로세스 간 통신
프로세스(process)란 호스트 내에서 실행 중인 프로그램이다. 실제 통신하는 것은 프로그램 자체가 아니라, 실행 중인 프로세스이다.
- 같은 호스트 내의 두 프로세스는 OS가 정의한 IPC(Inter-Process Communication)로 통신한다.
- 다른 호스트의 프로세스들은 메시지(message)를 교환하여 통신한다.
클라이언트-서버 관점에서 보면:
- Client process: 통신을 먼저 시작(초기화)하는 프로세스
- Server process: 세션을 시작하기 위해 접속을 기다리는 프로세스
P2P 아키텍처의 애플리케이션도 내부적으로는 client process와 server process를 모두 가진다.
Socket
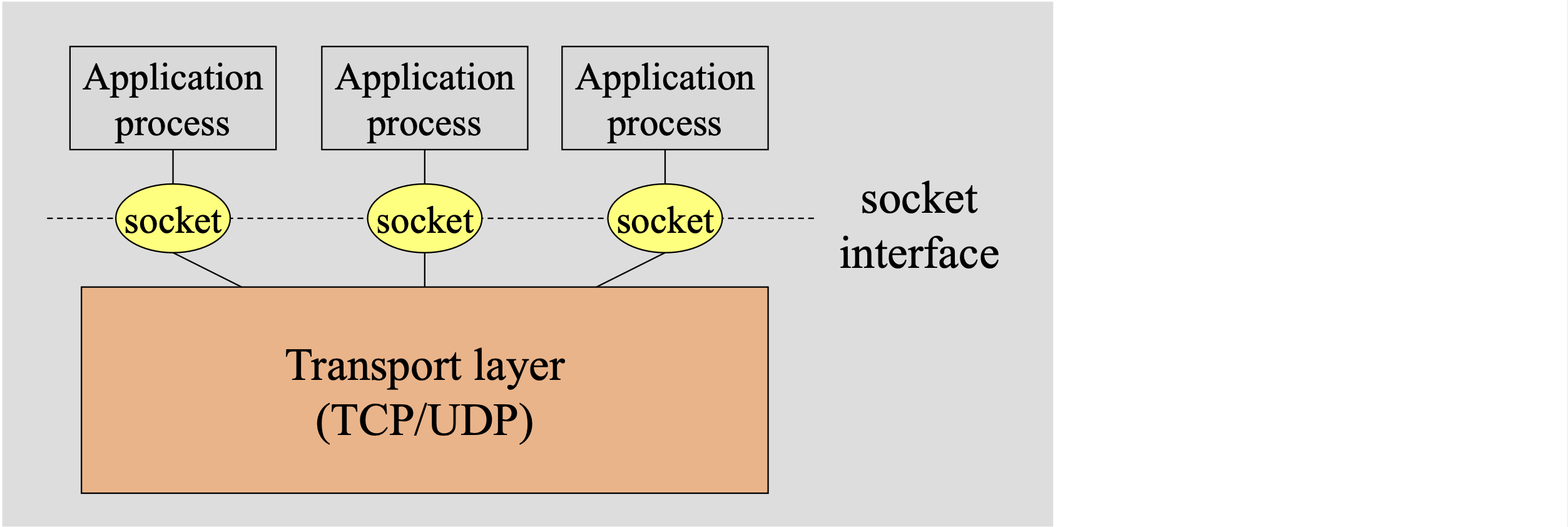
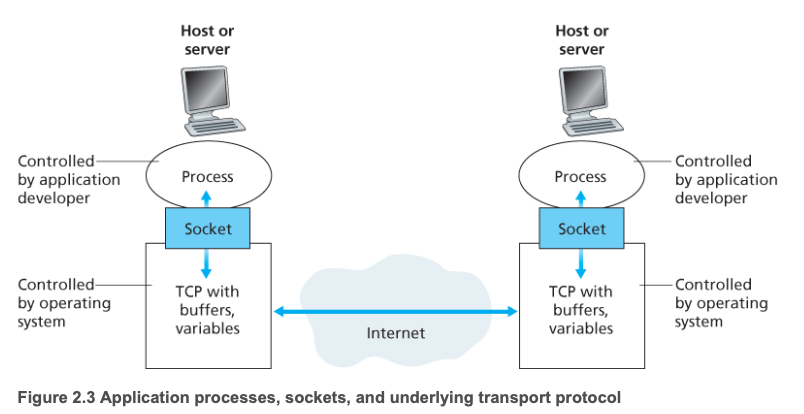
Socket은 애플리케이션과 TCP/UDP 등 프로토콜 스택 사이에 위치한 공통 인터페이스이다. 프로세스는 자신의 socket을 통해 메시지를 송수신한다. 네트워크에서 프로세스를 집이라 한다면, 소켓은 마치 문과 같은 존재이다.
소켓은 호스트의 애플리케이션 계층과 트랜스포트 계층 간의 인터페이스이므로, 애플리케이션과 네트워크 사이의 API라고도 한다. 애플리케이션 개발자는 소켓의 애플리케이션 계층에 대한 모든 통제권을 갖지만, 트랜스포트 계층에 대한 통제권은 거의 갖지 못한다. 개발자가 할 수 있는 것은 트랜스포트 프로토콜 선택과, 최대 버퍼/최대 세그먼트 크기 같은 약간의 매개변수 설정 정도이다.
프로세스 주소 지정
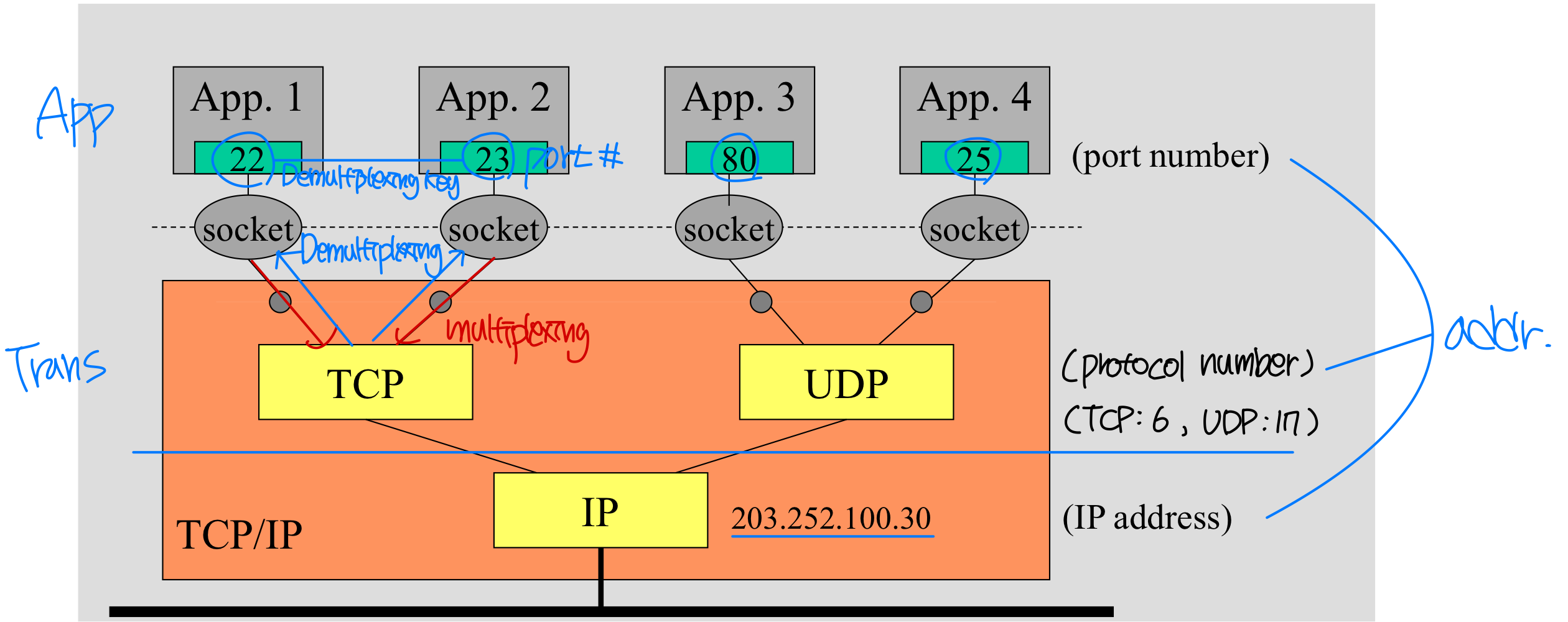
호스트 장치는 고유한 32-bit IP address(IPv4)를 가진다. 그러나 IP 주소만으로는 특정 프로세스를 식별할 수 없다. 하나의 호스트에서 여러 프로세스가 동시에 실행될 수 있기 때문이다.
따라서 메시지를 수신하려면 두 가지 정보가 필요하다.
- 호스트의 IP 주소
- 호스트 내의 수신 프로세스를 명시하는 포트 번호(port number)
대표적인 well-known 포트 번호:
- HTTP 서버: 80
- Mail 서버: 25
예를 들어, gaia.cs.umass.edu 웹 서버에 HTTP 메시지를 보내려면 IP address: 128.119.245.12, port number: 80을 지정한다.
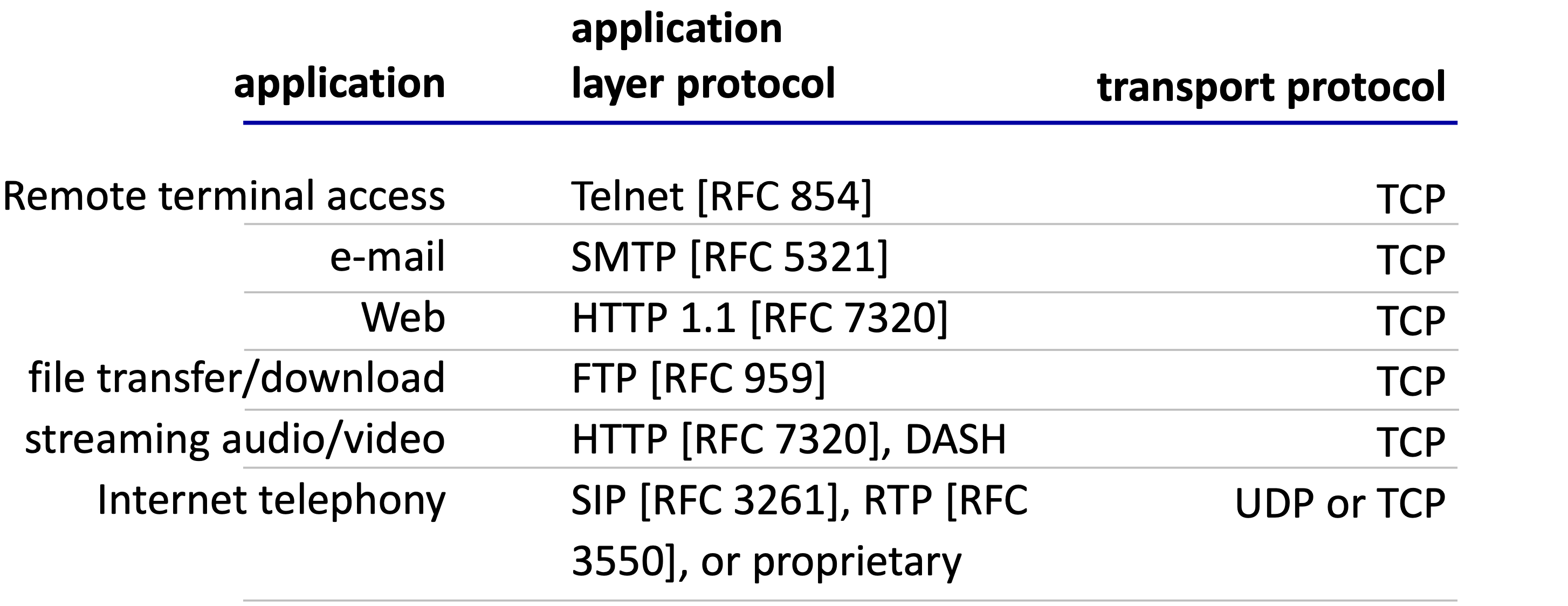
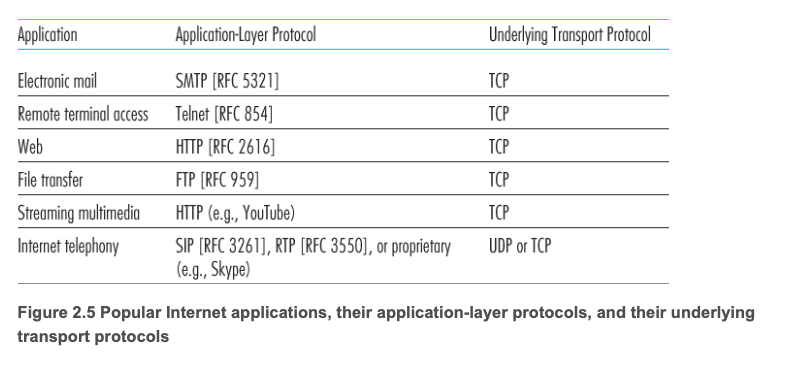
Application-layer 프로토콜이 정의하는 것

애플리케이션 계층 프로토콜은 다음을 정의한다.
- 교환되는 메시지의 유형: request, response 등
- 메시지 구문(Syntax): 메시지에 어떤 필드가 있고, 필드를 어떻게 구분하는지
- 필드의 의미(Semantics): 각 필드에 담긴 정보의 의미
- 규칙(Rules): 프로세스가 언제, 어떻게 메시지를 보내고 응답하는지
프로토콜의 종류:
- Open protocols: RFC로 정의되어 누구나 접근 가능하며, 상호운용성(interoperability)을 보장한다. 예: HTTP, SMTP. 브라우저 개발자가 HTTP 규칙을 따르면, HTTP 규칙을 따르는 어떤 웹 서버로부터도 웹 페이지를 가져올 수 있다.
- Proprietary protocols: 비공개 프로토콜. 예: Skype, Zoom
애플리케이션 계층 프로토콜은 네트워크 애플리케이션의 한 요소일 뿐이다. 예를 들어, 웹 애플리케이션은 문서 포맷 표준(HTML), 웹 브라우저, 웹 서버, 그리고 HTTP를 포함하는 여러 요소로 구성된다.
Transport 계층 서비스
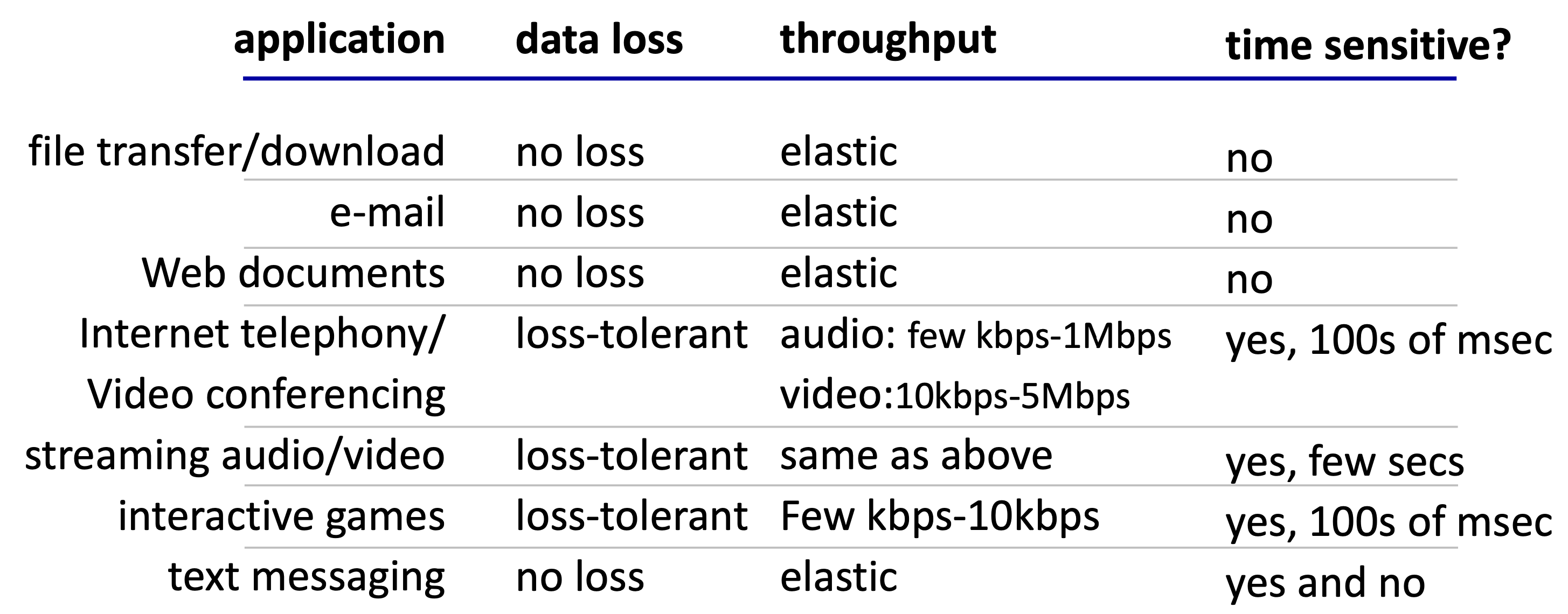
애플리케이션이 transport 계층에 기대하는 서비스는 네 가지로 분류된다.
- Reliable data transfer(신뢰적 데이터 전송): 파일 전송이나 웹 트랜잭션처럼 100% 신뢰성이 필요한 앱이 있고, 오디오처럼 일부 손실을 허용하는 손실 허용 애플리케이션도 있다.
- Timing(시간): 인터넷 전화나 인터랙티브 게임처럼 낮은 지연(low delay)이 필수인 앱이 있다.
- Throughput(처리율): 멀티미디어 앱처럼 최소 처리량이 필요한 대역폭 민감 애플리케이션이 있고, 탄력적 앱(elastic apps)은 주어지는 처리량을 그대로 활용한다.
- Security(보안): 기밀성(Confidentiality), 데이터 무결성(Data integrity), 인증(Authentication)
인터넷 전송 프로토콜 서비스
TCP service:
- 송수신 프로세스 간 reliable transport 제공 (에러 없이, 올바른 순서로 전달)
- Flow control: sender가 receiver의 버퍼를 넘치지 않도록 조절
- Congestion control: 네트워크가 과부하 상태이면 sender를 throttle
- Connection-oriented: 클라이언트와 서버 간 setup 필요 (핸드셰이킹)
- 제공하지 않는 것: timing, 최소 throughput 보장, security
UDP service (User Datagram Protocol):
- 송수신 프로세스 간 비신뢰적(unreliable) 데이터 전송. 언제든 손실이 발생할 수 있다.
- 비연결형으로 핸드셰이킹 과정이 없다.
- 혼잡 제어 방식을 포함하지 않아 프로세스의 속도 저하 없이 네트워크를 이용할 수 있다. 그러나 혼잡으로 인해 종단 간 처리율이 오히려 낮아질 수도 있다.
- 제공하지 않는 것: reliability, flow control, congestion control, timing, throughput 보장, security, connection setup
TCP와 UDP 모두 처리율 및 시간 보장 서비스를 제공하지 않는다. 시간 민감 애플리케이션은 이러한 한계에 대처할 수 있도록 설계되어야 한다.
TCP 보안
기본(Vanilla) TCP/UDP 소켓은 암호화가 없다. 비밀번호가 평문(cleartext)으로 인터넷을 통해 전송된다.
이를 해결하기 위해 TLS(Transport Layer Security)(구 SSL)가 사용된다. 현재는 대부분 TLS를 사용한다.

- 암호화된 TCP 연결을 제공
- 데이터 기밀성(confidentiality)과 end-point 인증(authentication) 보장
- TLS는 애플리케이션 계층에서 동작하며, 앱이 TLS 라이브러리를 사용하고 이것이 다시 TCP를 이용한다.
- UDP를 위한 DTLS(Datagram TLS)도 존재한다.
2.2 Web과 HTTP
웹 페이지(web page)는 여러 객체(object)로 구성된다. 객체는 HTML 파일, JPEG 이미지, Java applet, 오디오 파일 등이 될 수 있으며, 단일 URL로 지정할 수 있는 하나의 파일이다.
웹 페이지는 기본 HTML 파일(base HTML-file)과 여기서 참조하는 여러 객체(referenced objects)로 이루어진다. 예를 들어 웹 페이지가 HTML 텍스트와 5개의 JPEG 이미지로 구성되어 있으면, 6개의 객체를 갖는다. 각 객체는 URL(Uniform Resource Locator)로 주소가 지정된다.

URL은 객체를 갖고 있는 서버의 호스트 이름과 객체의 경로 이름으로 구성된다.
http://www.school.edu/picture.gif- 호스트 이름:
www.school.edu - 경로 이름:
/picture.gif
HTTP (HyperText Transfer Protocol)
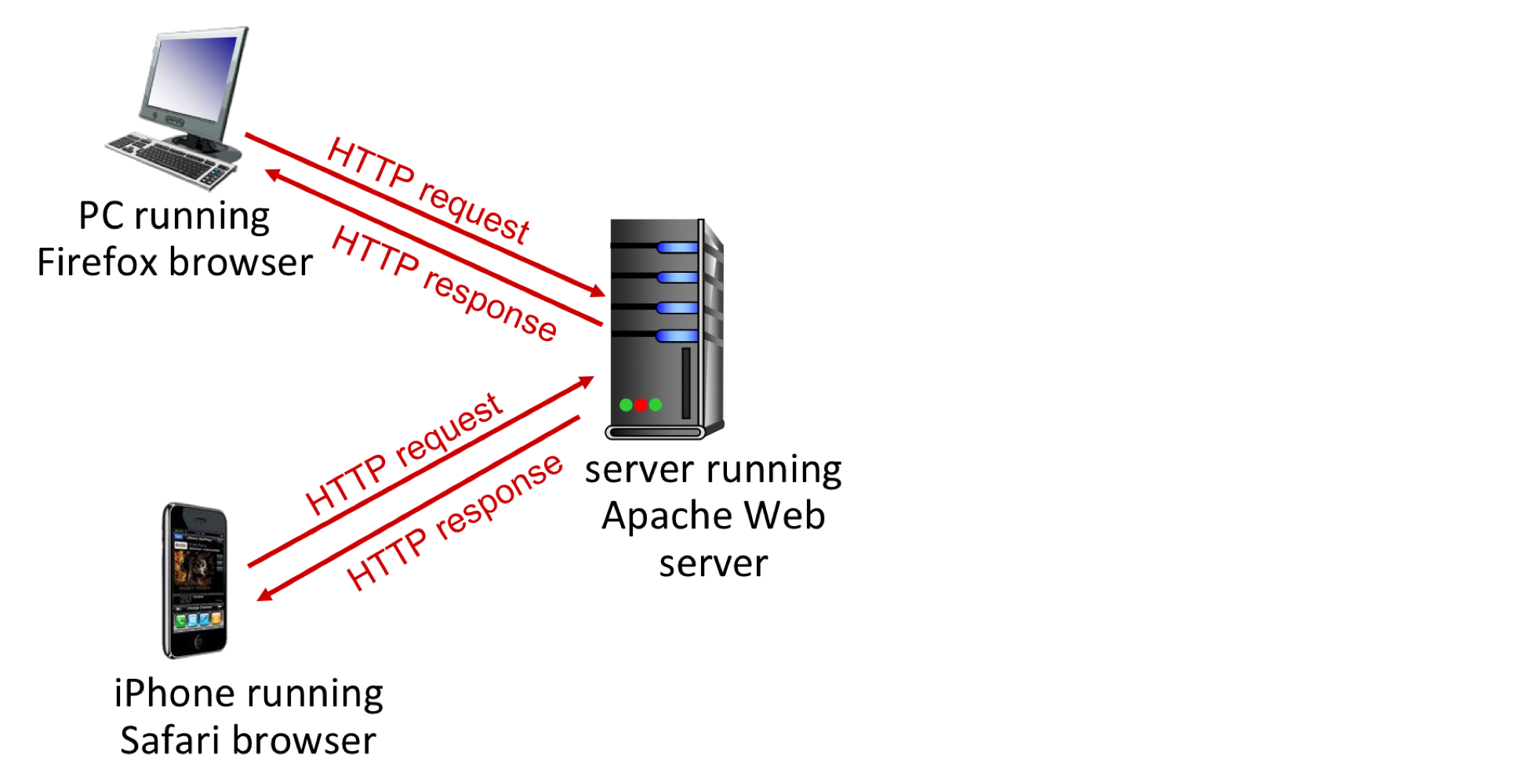
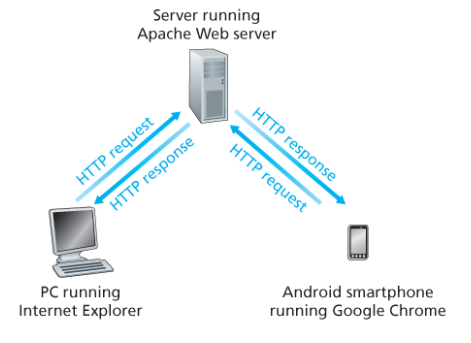
HTTP는 웹의 애플리케이션 계층 프로토콜이다. 메시지의 구조와 클라이언트와 서버가 메시지를 어떻게 교환하는지를 정의한다. 웹은 온디맨드(on-demand) 방식으로 사용자가 원할 때 원하는 것을 수신한다.
Client/Server 모델:
- Client: 브라우저가 HTTP를 사용하여 웹 객체를 요청, 수신, 표시한다.
- Server: 웹 서버가 HTTP를 사용하여 요청에 대한 응답으로 객체를 전송한다.
HTTP 표준의 변천사:
- HTTP/1.0: RFC 1945 (1996)
- HTTP/1.1: RFC 2068 (1997), 이후 RFC 2616 (1999), RFC 7230 (2014), RFC 9112 (2022)
- HTTP/2: RFC 7540 (2015), RFC 9113 (2022)
- HTTP/3: RFC 9114 (2022)
HTTP는 TCP를 기반 전송 프로토콜로 사용한다.
- 클라이언트가 TCP 연결을 시작(소켓 생성)하여 서버에 연결한다.
- HTTP well-known 포트: 80
- HTTPS 포트: 443
- 서버가 TCP 연결을 수락한다.
- HTTP 메시지가 브라우저(HTTP client)와 웹 서버(HTTP server) 사이에 교환된다.
- TCP 연결이 종료된다.
TCP를 통해 메시지를 보내면 TCP가 신뢰적인 데이터 전송 서비스를 제공하므로, 모든 HTTP 요청/응답 메시지가 궁극적으로 상대방에 도착한다. HTTP는 TCP가 어떻게 손실 데이터를 복구하고 올바른 순서로 배열하는지 전혀 걱정할 필요가 없다. 이것이 계층 구조의 장점이다.
HTTP는 "stateless protocol"이다. 서버는 과거 클라이언트 요청에 대한 정보를 유지하지 않는다. 특정 클라이언트가 같은 객체를 두 번 요청해도, 서버는 이전에 보냈다는 사실을 알려주지 않고 다시 보낸다. 상태를 유지하는 프로토콜은 복잡하다. 과거 이력(state)을 관리해야 하고, 서버나 클라이언트가 crash되면 양쪽의 state가 불일치할 수 있어 이를 reconcile해야 한다.
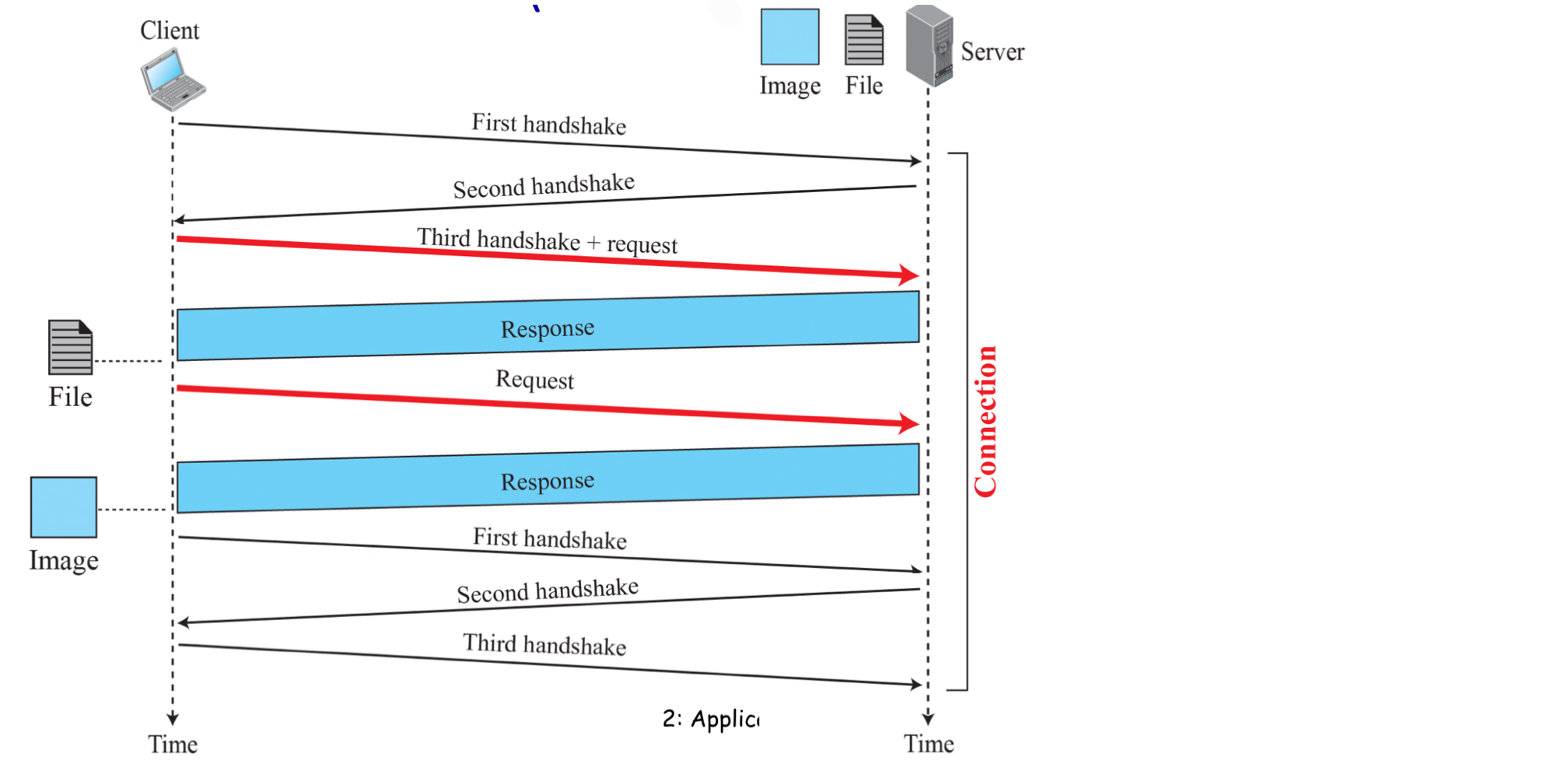
HTTP-TCP 연결: 두 가지 유형
Non-persistent HTTP (비지속 연결)
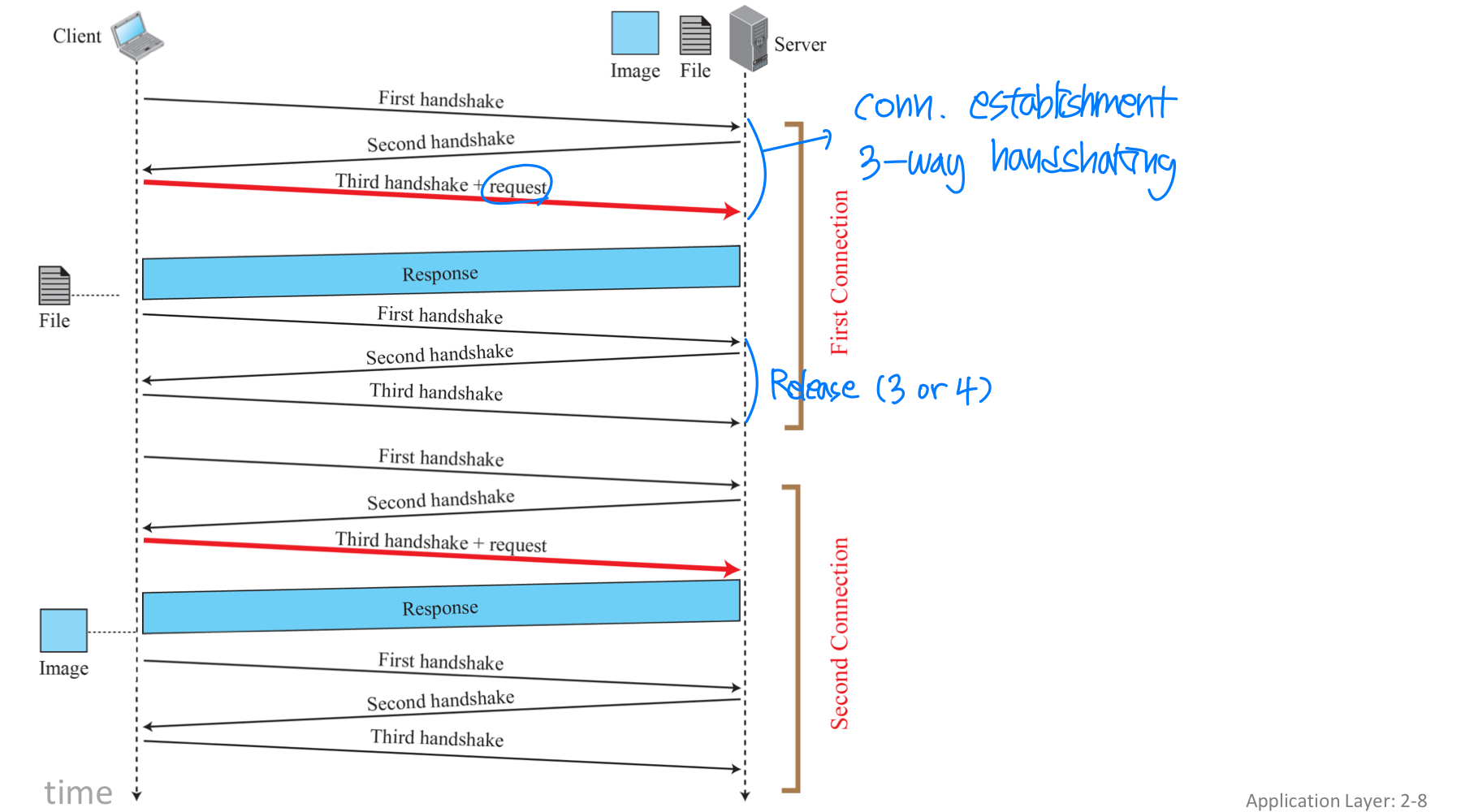
하나의 TCP 연결로 최대 하나의 객체만 전송한다. HTTP/1.0이 이 방식을 사용한다.
구체적인 동작 과정을 살펴보자. 페이지가 기본 HTML 파일과 10개의 이미지로 구성되어 있다고 가정한다.
- HTTP 클라이언트가 포트 80을 통해 서버로 TCP 연결을 시도한다.
- 클라이언트가 설정된 TCP 연결 소켓을 통해 HTTP 요청 메시지를 보낸다.
- 서버가 요청을 받아 객체를 추출하고, HTTP 응답 메시지에 캡슐화하여 소켓을 통해 클라이언트에 전송한다.
- 서버가 TCP에게 연결을 끊으라고 한다 (실제로는 클라이언트가 응답을 올바르게 받을 때까지 유지).
- 클라이언트가 응답을 받으면 TCP 연결이 중단된다. HTML 파일을 조사하여 10개의 이미지 참조를 발견한다.
- 참조되는 각 객체에 대해 1~4단계를 반복한다.
브라우저는 참조된 객체들을 빠르게 받기 위해 병렬 TCP 연결을 열기도 한다. 빠르게 정보를 받을 수 있지만, 서버에 부담이 커진다(연결 수 증가).
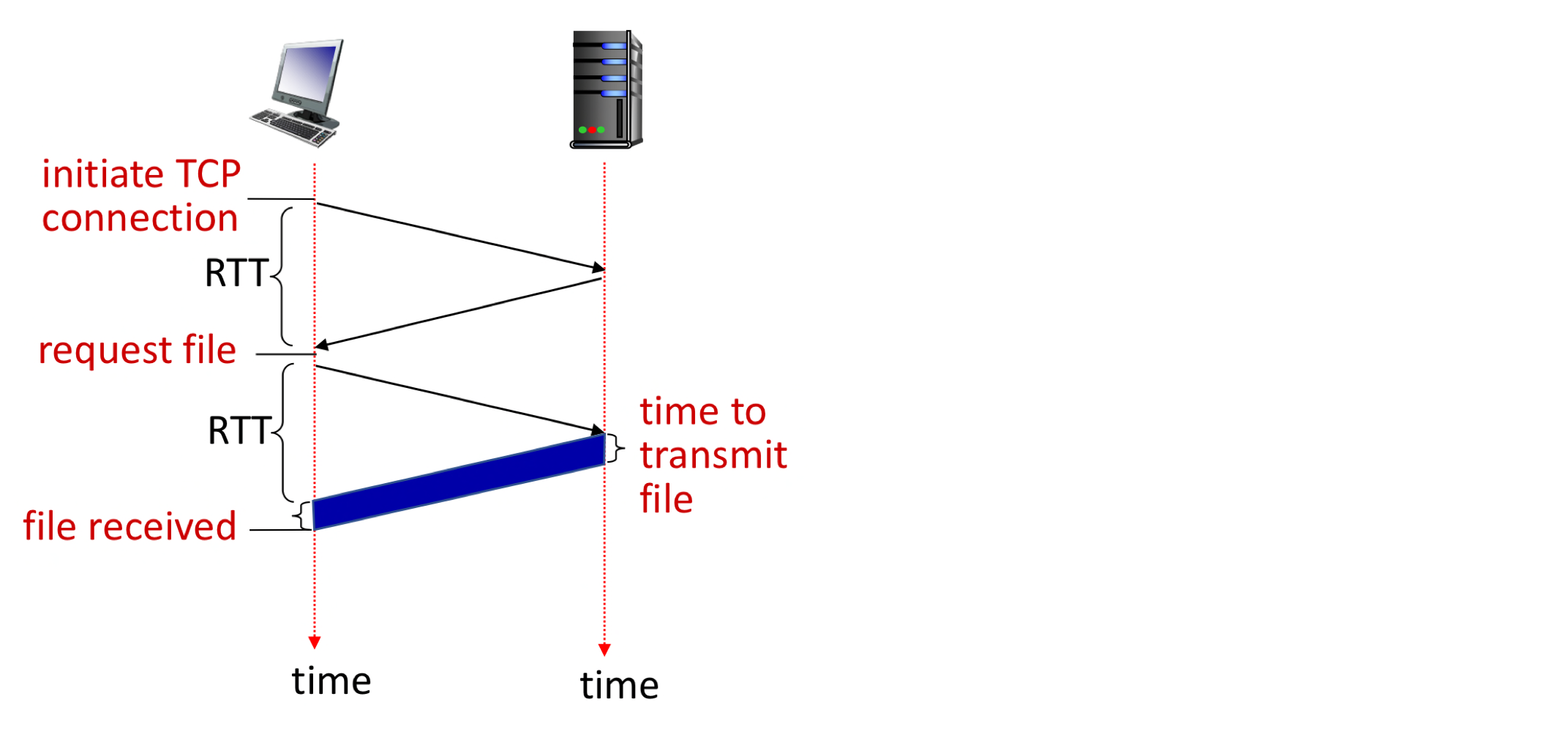
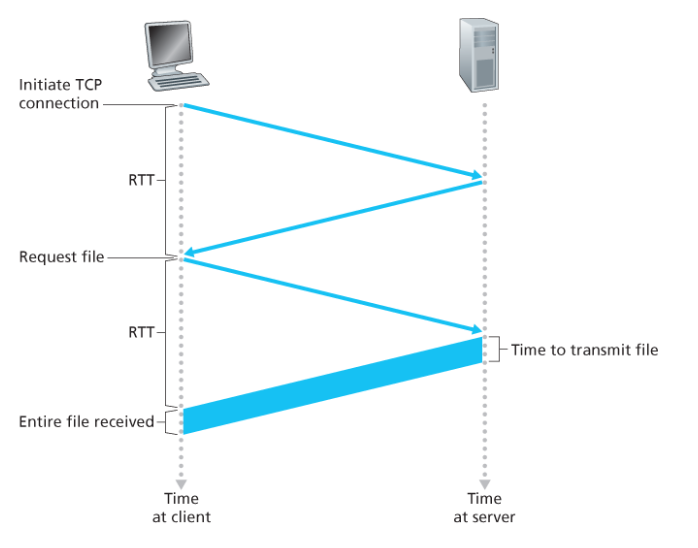
응답 시간(Response time):
- RTT(Round Trip Time): 작은 패킷이 클라이언트에서 서버로 갔다가 돌아오는 시간. 패킷 전파 지연, 큐잉 지연, 처리 지연 등을 포함한다.
- HTTP 응답 시간 (객체 하나당):
- TCP 연결 설정에 1 RTT (3-way handshake 중 처음 2단계)
- HTTP 요청과 응답 첫 바이트 수신에 1 RTT (handshake의 세 번째 단계와 HTTP 요청을 함께 전송)
- 파일 전송 시간
따라서 Non-persistent HTTP 응답 시간 = 2RTT + 파일 전송 시간 (+ 연결 해제 시간)
비지속 연결의 단점:
- 각 요청 객체에 대해 새로운 연결이 설정되고 유지되어야 한다. TCP 버퍼 할당과 TCP 변수 유지가 서버에 심각한 부담이 된다.
- 매번 2RTT가 필요하다.
Persistent HTTP (지속 연결)
하나의 TCP 연결로 여러 객체를 전송할 수 있다. 서버는 응답을 보낸 후에도 연결을 유지하며, 같은 클라이언트/서버 간의 후속 HTTP 메시지가 동일 연결로 전송된다. 일정 기간 사용되지 않으면 서버가 연결을 닫는다.
Pipelining
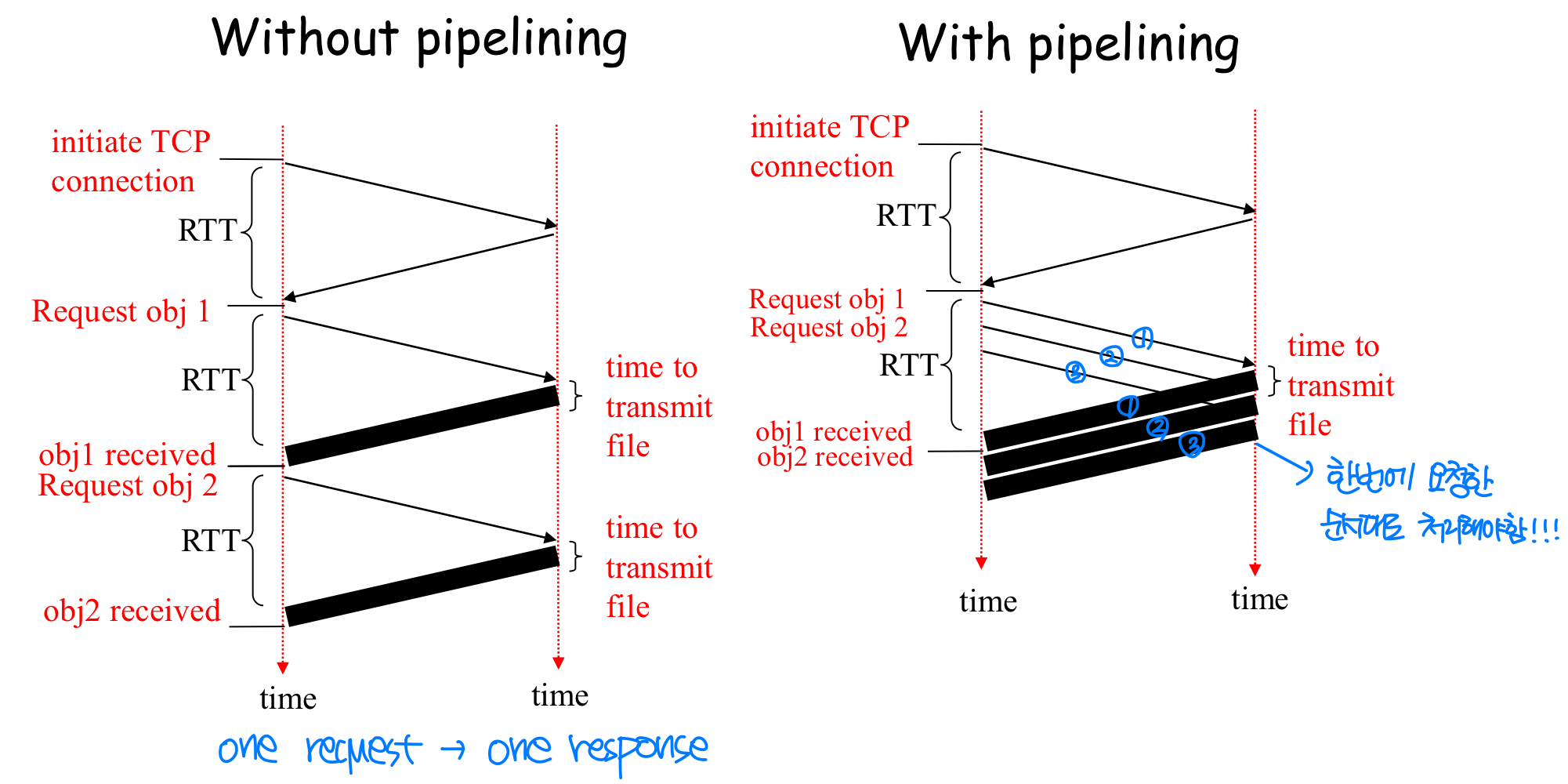
- Pipelining 없는 Persistent: 이전 응답을 받아야 다음 요청을 보냄. 참조 객체 하나당 1 RTT 소요.
- Pipelining 있는 Persistent: 참조 객체를 발견하는 즉시 요청을 보냄. 모든 참조 객체에 대해 최소 1 RTT면 충분하다. HTTP/1.1의 기본 설정이지만, 대부분의 브라우저에서는 이 기능을 사용하지 않는다.
HTTP 메시지 형식
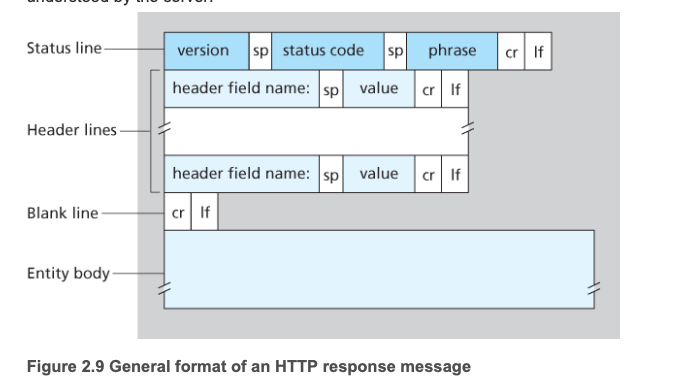
HTTP 메시지는 request와 response 두 가지 유형이 있다.
HTTP Request 메시지
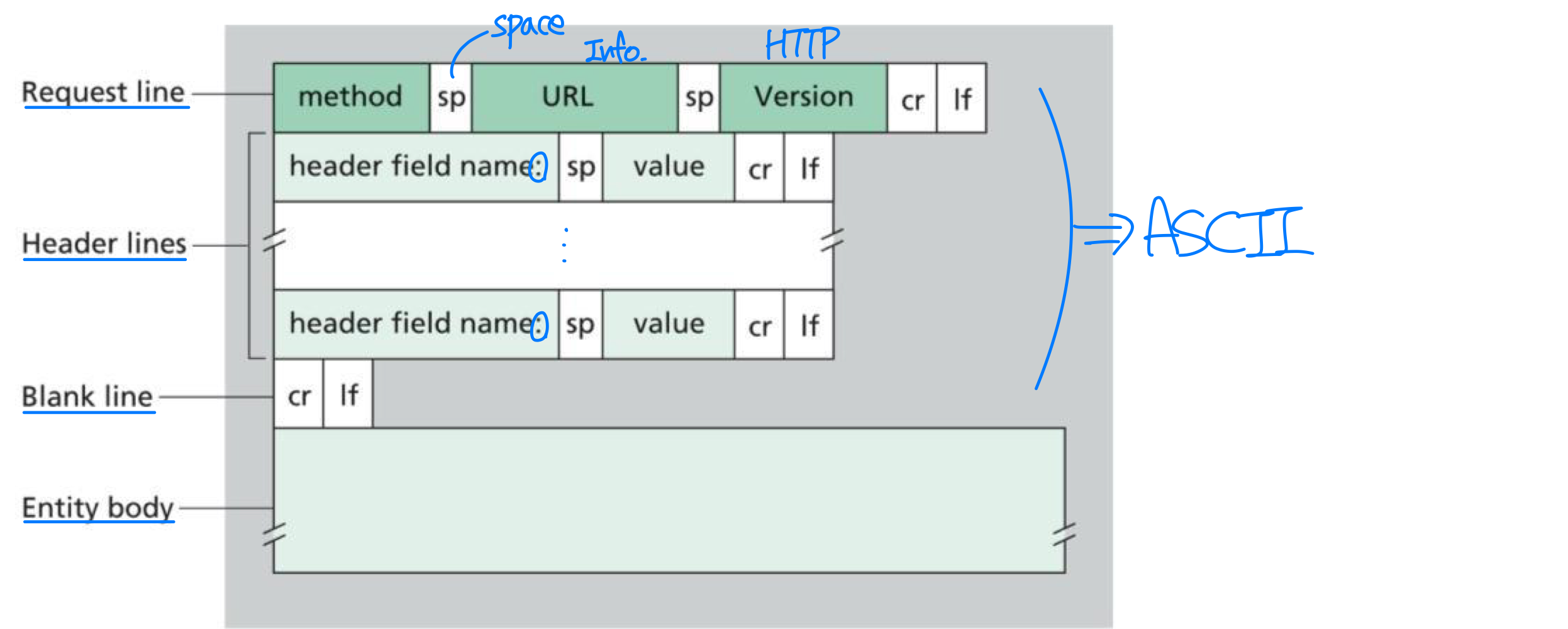

다음은 전형적인 HTTP 요청 메시지이다.
GET /somedir/page.html HTTP/1.1
Host: www.someschool.edu
Connection: close
User-agent: Mozilla/5.0
Accept-language: fr특징:
- ASCII 텍스트로 쓰여 있어 사람이 읽을 수 있다.
- 각 줄은 CR(carriage return)과 LF(line feed)로 구별된다.
첫 줄은 요청 라인(request line)이라 하고, 이후의 줄들은 헤더 라인(header line)이라 한다.
요청 라인은 3개의 필드를 갖는다: 방식(method) 필드, URL 필드, HTTP 버전 필드.
주요 헤더 라인:
- Host: 객체가 존재하는 호스트를 명시. 이미 TCP 연결이 맺어져 있어 불필요해 보이지만, 웹 프록시 캐시에서 필요하다.
- Connection: 지속 연결 또는 비지속 연결 사용 여부를 전달한다.
- User-agent: 요청을 하는 브라우저 타입을 명시한다.
- Accept-language: 원하는 언어 버전을 나타낸다.

RESTful 프로토콜은 CRUD 연산에 대응된다.
- C(Create) = POST
- R(Read) = GET
- U(Update) = PUT
- D(Delete) = DELETE
주요 메서드 정리:
- POST method: 웹 페이지에 input-form이 포함된 경우, 사용자 입력이 HTTP POST 요청 메시지의 entity body로 전송된다.
- GET method: POST 대신 GET 메서드를 사용하여 사용자 데이터를 URL에 포함시킬 수 있다.
?뒤에 데이터를 붙인다. 예:www.somesite.com/animalsearch?monkeys&banana - HEAD method: GET과 유사하지만, 서버가 요청 객체를 보내지 않는다. 흔히 디버깅을 위해 사용된다.
- PUT method: 특정 URL에 객체를 업로드한다(이미 존재하면 대체).
- DELETE method: 웹 서버에 있는 객체를 삭제한다.

HTTP Response 메시지
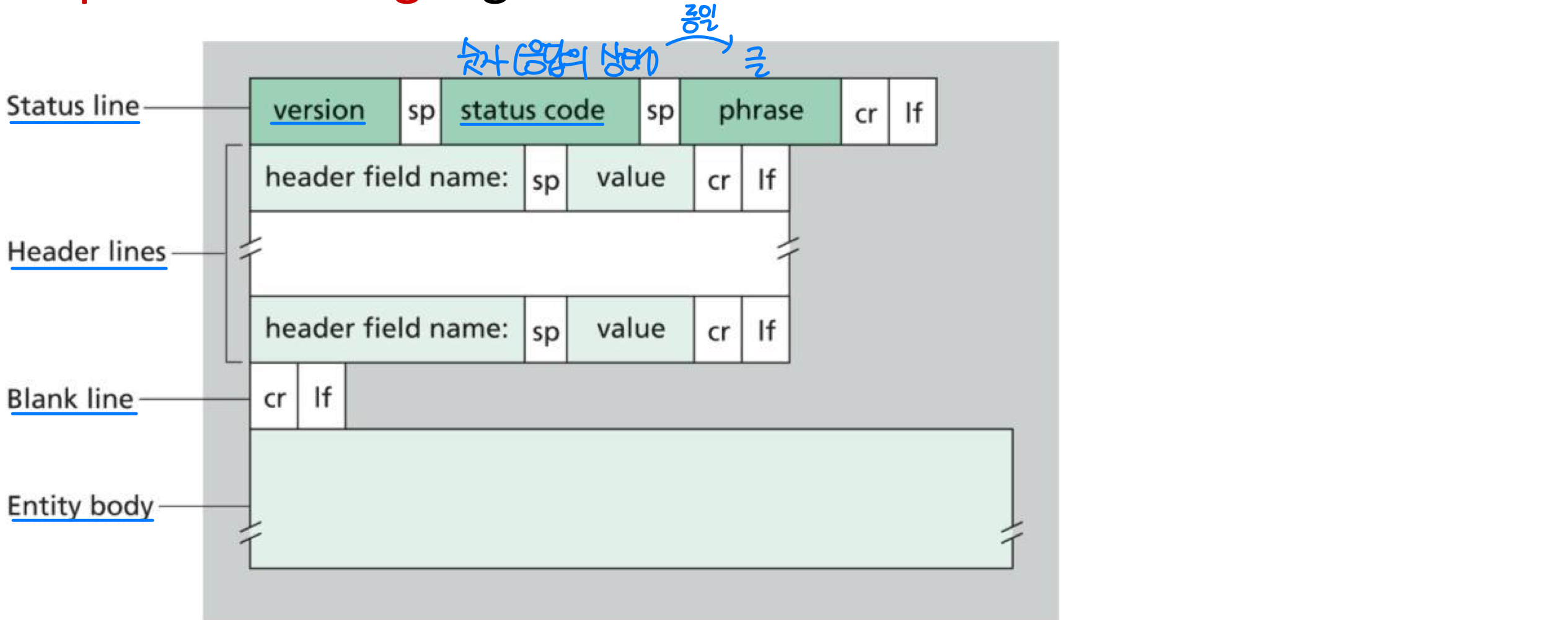
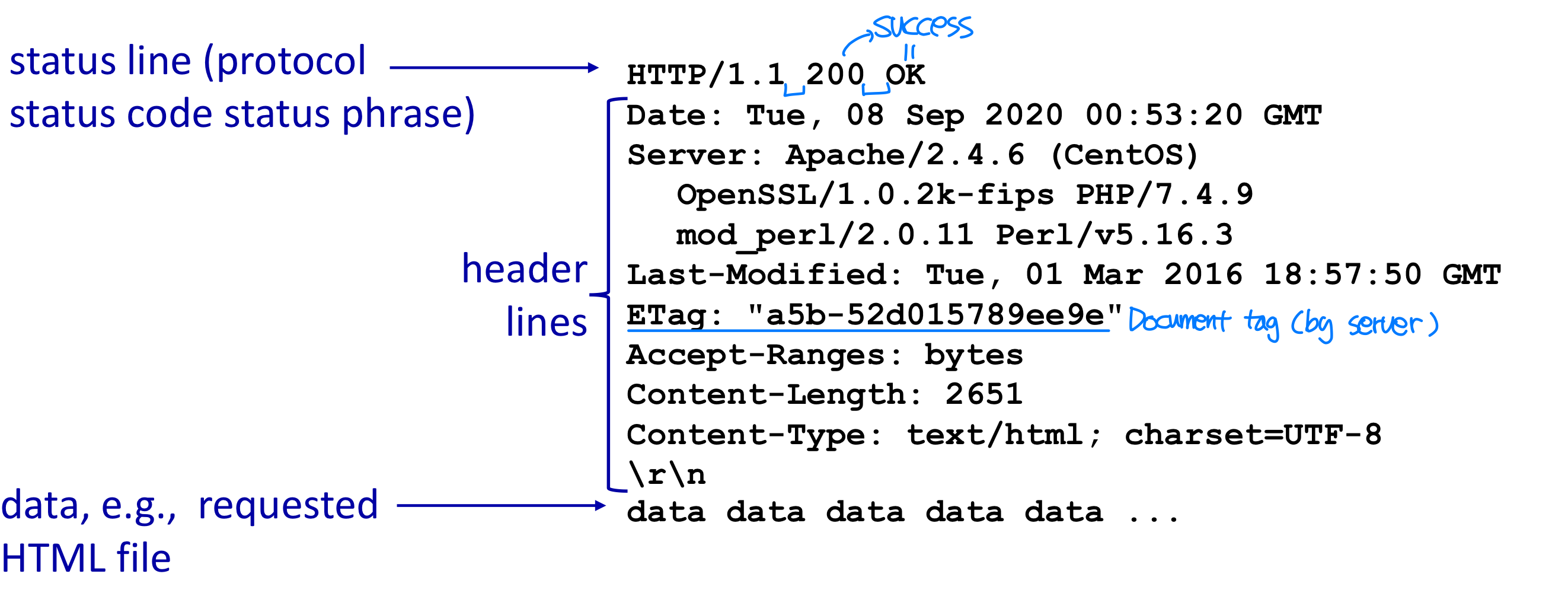
다음은 전형적인 HTTP 응답 메시지이다.
HTTP/1.1 200 OK
Connection: close
Date: Tue, 18 Aug 2015 15:44:04 GMT
Server: Apache/2.2.3 (CentOS)
Last-Modified: Tue, 18 Aug 2015 15:11:03 GMT
Content-Length: 6821
Content-Type: text/html
(data data data data data ...)상태 라인(status line)은 버전 필드, 상태 코드, 해당 상태 메시지를 갖는다. Status code는 수신된 요청에 대한 응답을 나타내는 3자리 정수이다.
주요 상태 코드:
- 200 OK: 요청 성공, 정보 반환
- 301 Moved Permanently: 요청한 객체가 이동됨. 새 위치는 Location 헤더에 명시
- 400 Bad Request: 요청의 구문 오류(syntax error)
- 404 Not Found: 요청한 문서가 서버에 존재하지 않음
- 505 Version Not Supported: HTTP 버전 미지원
상태 코드 범위: 1XX(정보), 2XX(성공), 3XX(리다이렉션), 4XX(클라이언트 오류), 5XX(서버 오류)
주요 헤더 라인:
- Connection: 메시지를 보낸 후 TCP 연결을 닫을지 여부
- Date: HTTP 응답이 서버에 의해 생성되고 보낸 날짜와 시간
- Server: 메시지를 만든 웹 서버 정보
- Last-Modified: 객체가 마지막으로 수정된 시간과 날짜
- Content-Length: 송신되는 객체의 바이트 수
- Content-Type: entity body 내부 객체의 타입
Cookies: 사용자/서버 상태 유지
HTTP는 stateless protocol이다. 서버는 응답을 보내는 즉시 클라이언트를 잊는다. 모든 HTTP 요청은 독립적이며, multi-step 트랜잭션의 상태를 추적할 필요가 없다.
그러나 stateless 방식에는 한계가 있다.
- 웹 사이트가 사용자를 식별하고 싶을 때
- 서버가 사용자 접근을 제한하고 싶을 때
- 서버가 사용자 신원에 따라 맞춤 콘텐츠를 제공하고 싶을 때
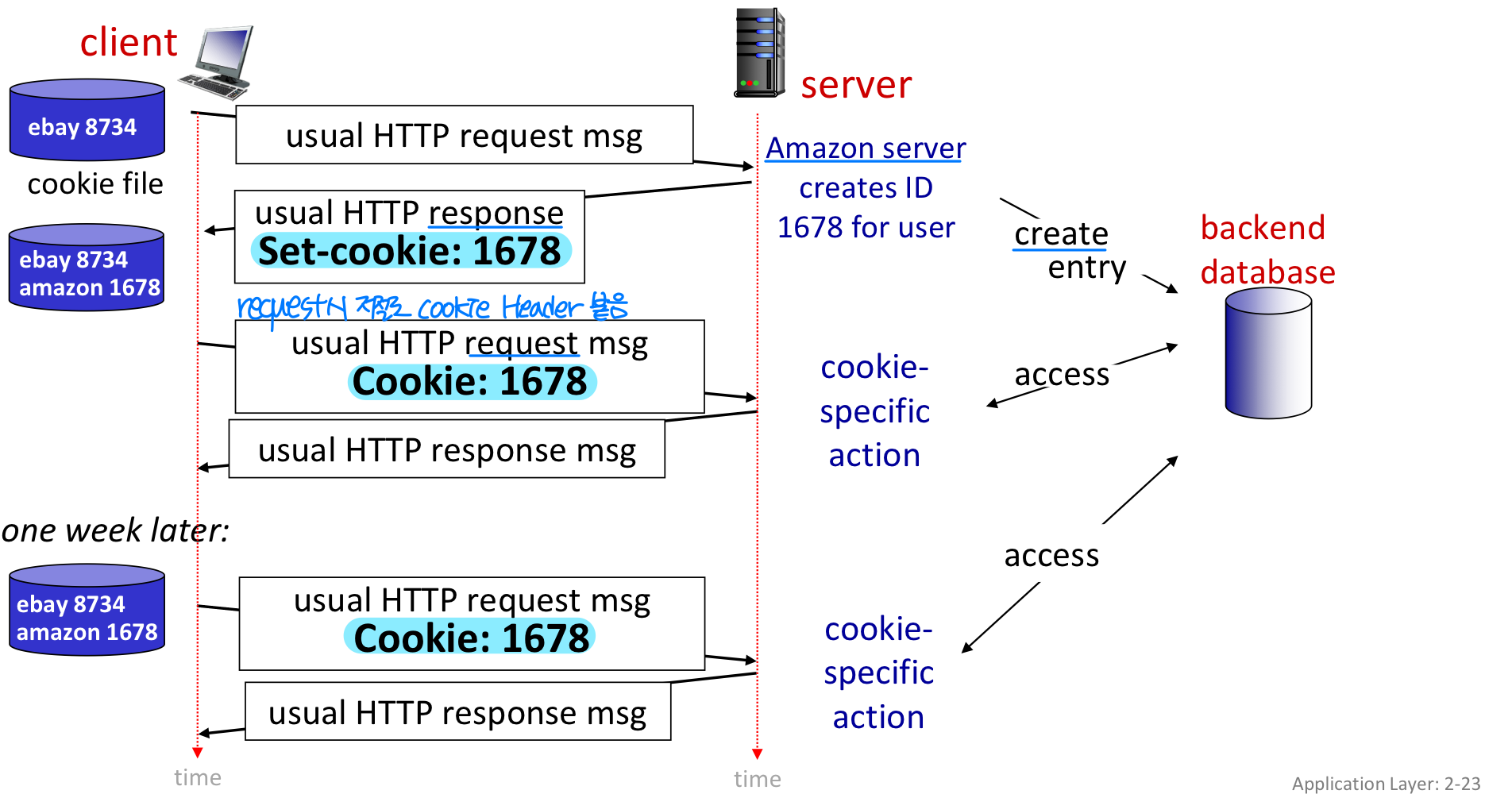
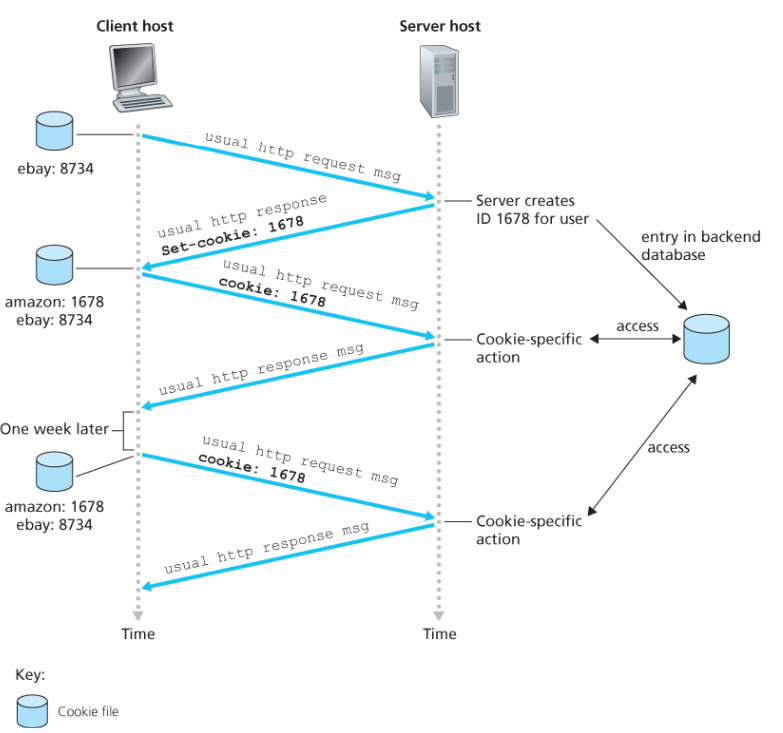
이를 해결하기 위해 웹 사이트와 클라이언트 브라우저는 cookie를 사용하여 트랜잭션 간 상태를 유지한다. Cookie는 짧은 데이터 조각이며, 실행 코드가 아니므로 머신에 직접적인 해를 끼치지 않는다. Stateless인 HTTP 위에서 cookie는 state 관련 서비스 레이어를 제공한다.
Cookie의 4가지 구성요소:
- HTTP 응답 메시지의 set-cookie 헤더 라인
- 다음 HTTP 요청 메시지의 cookie 헤더 라인
- 사용자 호스트에 저장되는 cookie 파일 (브라우저가 관리)
- 웹 사이트의 back-end 데이터베이스 (cookie를 해석하기 위한 DB)
Cookie 동작 과정:
- 웹 서버에 HTTP 요청 메시지를 전달한다.
- 웹 서버는 유일한 식별 번호를 만들고 백엔드 데이터베이스에 엔트리를 생성한다.
- HTTP 응답 메시지에
Set-cookie: 식별번호헤더를 포함하여 전달한다. - 브라우저는 쿠키 파일에 해당 정보를 저장한다.
- 이후 동일 서버에 요청을 보낼 때,
Cookie: 식별번호헤더를 함께 보낸다.
다만 cookie는 프라이버시 문제를 야기할 수 있다.
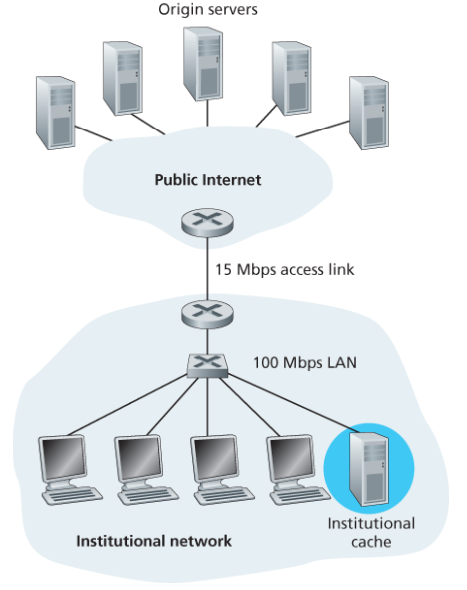
Web Cache (Proxy Server)
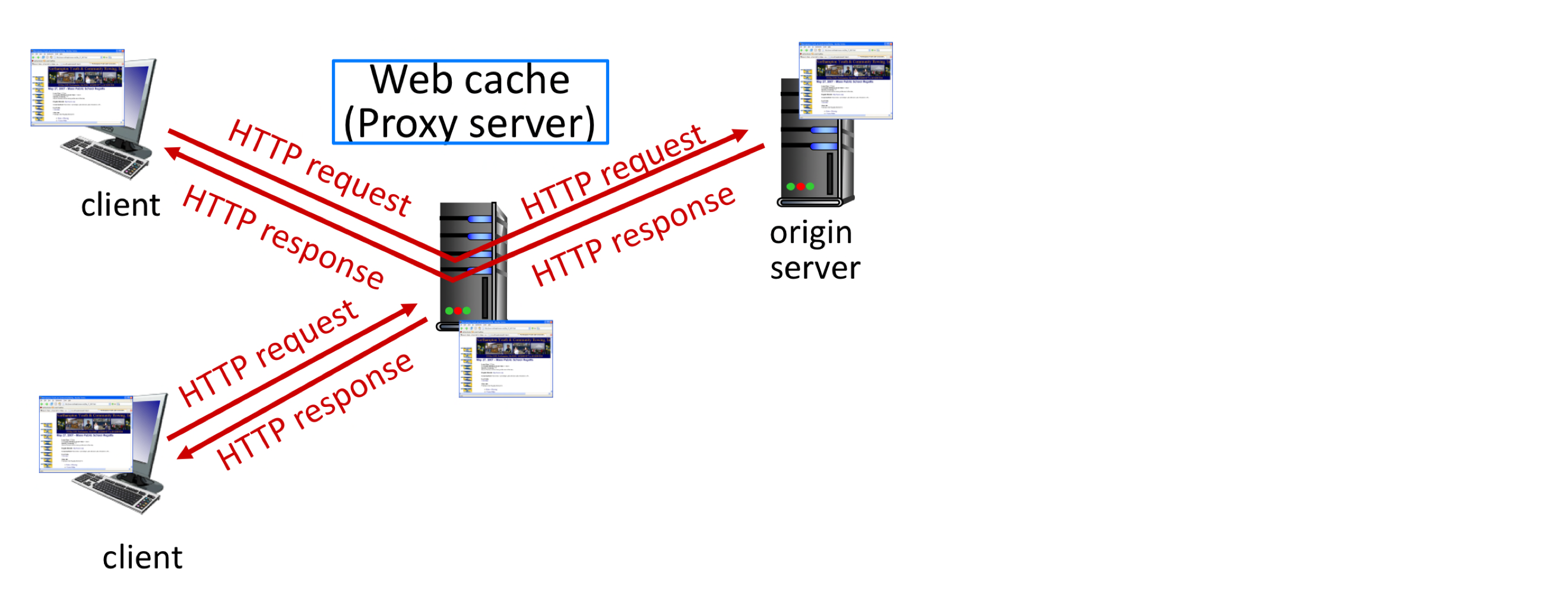
Web cache(프록시 서버)는 원본 웹 서버를 대신하여 HTTP 요청을 처리하는 중간 엔티티이다. 사용자 브라우저는 모든 요청이 먼저 Web cache로 향하도록 설정되어야 한다. 웹 캐시는 자체의 저장 디스크를 갖고 있어, 최근 호출된 객체의 사본을 저장 및 보존한다.
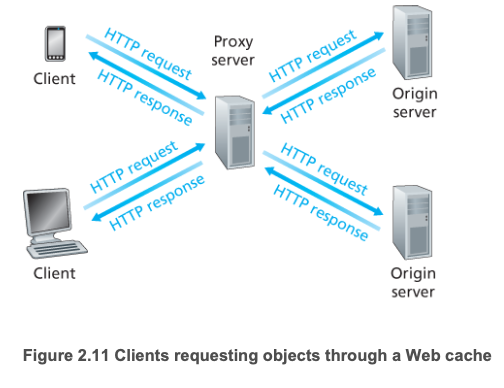
동작 방식:
- 브라우저가 웹 캐시와 TCP 연결을 설정하고 객체에 대한 HTTP 요청을 보낸다.
- 객체가 캐시에 있으면: 캐시가 클라이언트에게 객체를 반환
- 캐시에 없으면: 캐시가 원본 서버에 TCP 연결을 설정하여 요청하고, 받은 객체를 지역 저장장치에 복사한 후 클라이언트에게 반환
캐시는 클라이언트이면서 서버이다. 원래 요청 클라이언트에 대해서는 server 역할, 기점 서버에 대해서는 client 역할을 한다.
Web caching의 장점:
- 캐시가 클라이언트에 더 가까우므로 응답 시간 단축
- 기관의 access link 트래픽 감소 (핵심 이점)
- 인터넷 전체의 웹 트래픽을 줄여 모든 애플리케이션의 성능이 좋아진다.
단점:
- 캐시되지 않은 객체에 대해서는 오히려 성능이 저하될 수 있음
웹 캐시 성능 비교 예시

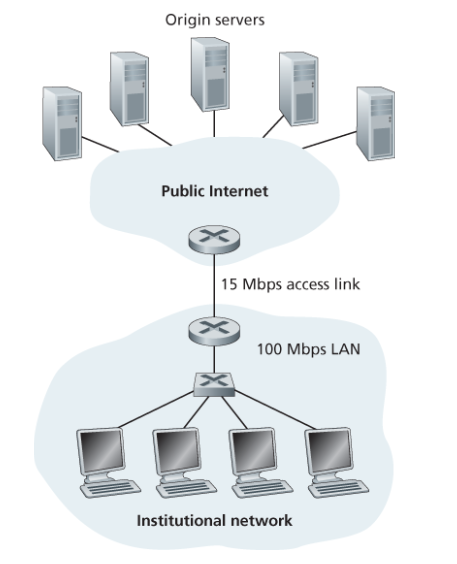
평균 객체 크기가 1 Mb, 평균 요청 비율이 초당 15 요청, 인터넷 지연이 2초라고 가정하자.
- LAN 트래픽 강도:
(15 x 1Mb) / 100Mbps = 0.15(무시 가능) - 접속 회선 트래픽 강도:
(15 x 1Mb) / 15Mbps = 1.0(지연이 무한히 증가)
Option 1: 더 빠른 access link 구매
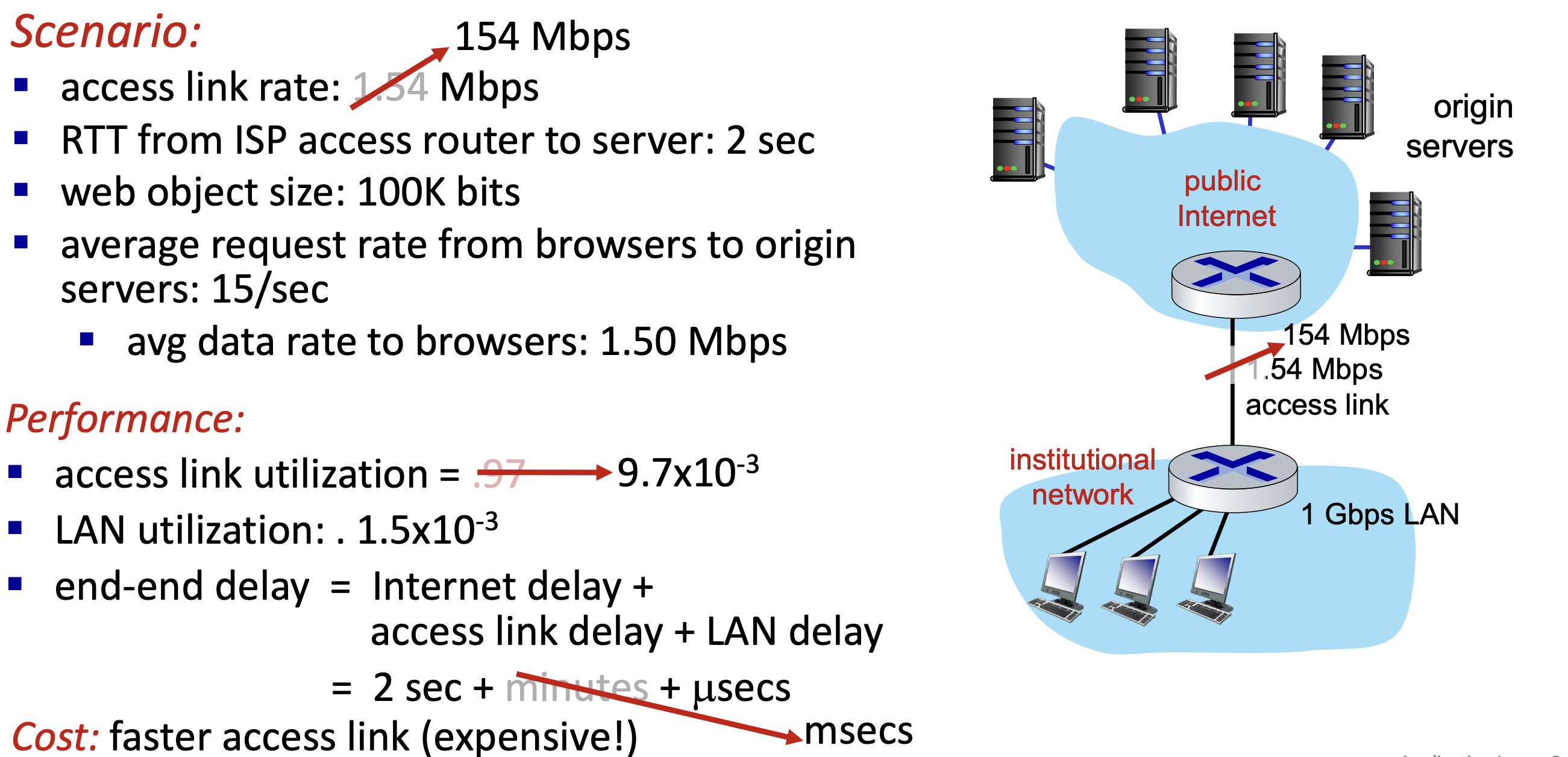
접속 회선을 100 Mbps로 업그레이드하면 트래픽 강도를 0.15로 낮출 수 있지만, 매우 높은 비용이 든다.
Option 2: Web cache 설치
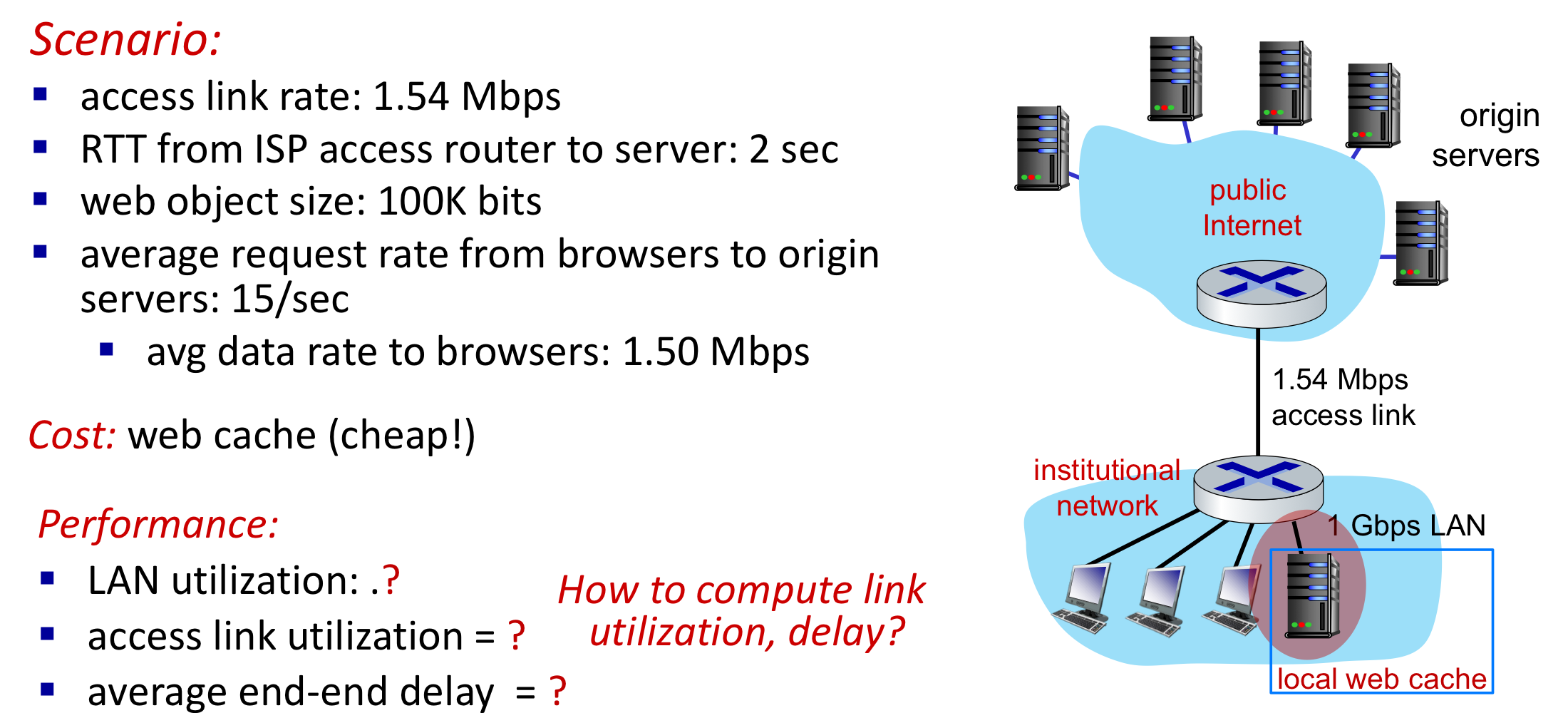
캐시 적중률(hit rate)이 0.4라고 가정하면:
- 요청의 40%는 캐시에 의해 즉시 만족 (10ms 이내)
- 나머지 60%는 기점 서버를 거침 (트래픽 강도 1.0 -> 0.6으로 감소)
- 평균 지연:
0.4 x 0.01초 + 0.6 x 2.01초 = 약 1.2초
캐시를 사용한 access link 이용률 및 end-to-end 지연 계산

문제점은 캐시 데이터와 원본 데이터가 다를 수 있다는 것이다. 이를 해결하기 위해 Conditional GET이 사용된다.
Conditional GET
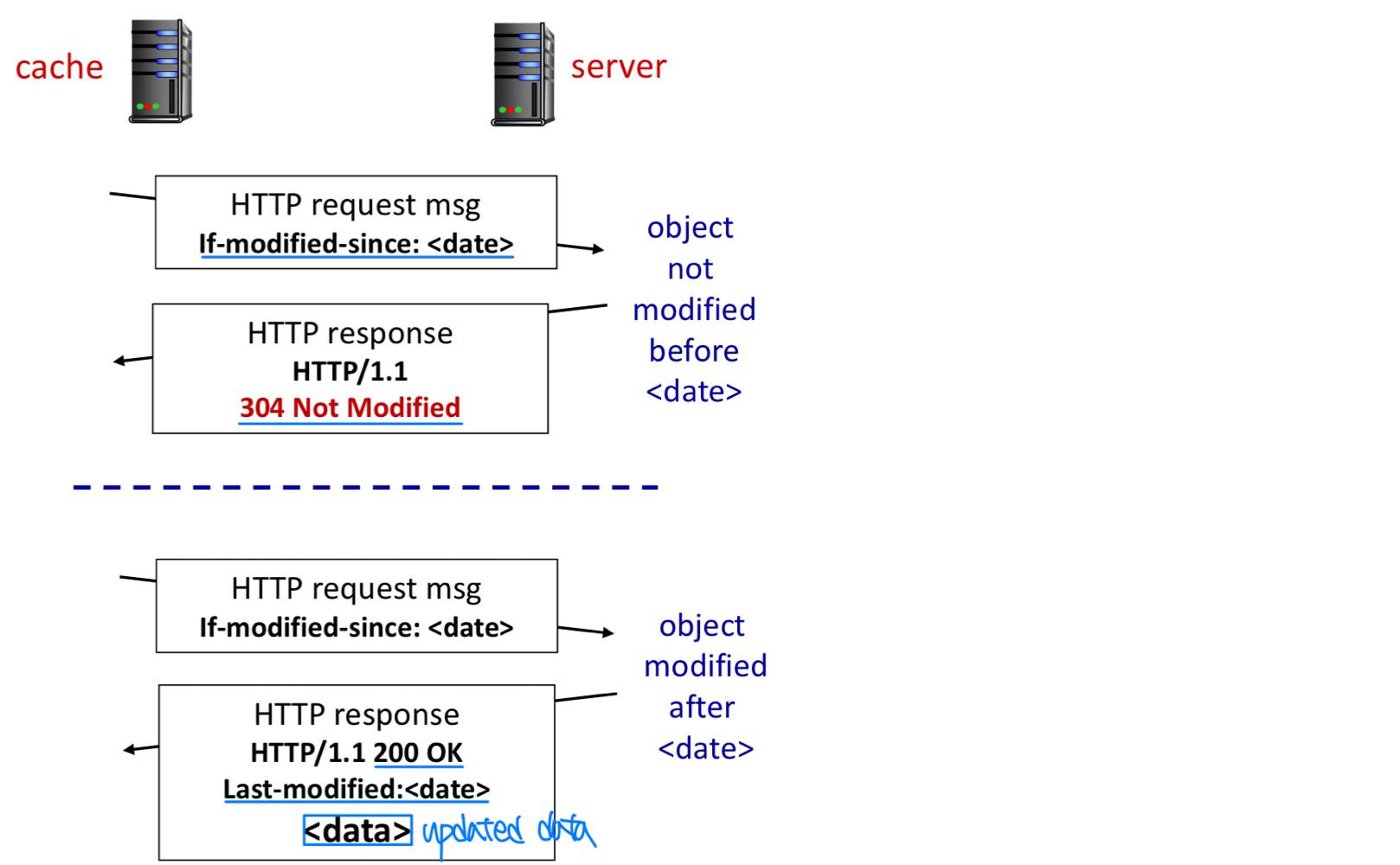
Conditional GET은 access link 트래픽을 줄이는 방법이다.
- 문제: 캐시에 있는 객체가 stale(오래된 상태)일 수 있다.
- 목표: 캐시가 최신 버전을 가지고 있으면 객체를 다시 보내지 않는다.
- 해결책: Conditional GET 사용
- 클라이언트가 HTTP 요청에 캐시된 사본의 날짜를 명시:
If-Modified-Since: <날짜> - 서버는 캐시 사본이 최신이면 객체 없이 응답: HTTP/1.1 304 Not Modified
- 클라이언트가 HTTP 요청에 캐시된 사본의 날짜를 명시:
Conditional GET 동작 과정:
- 프록시 캐시가 기점 서버에 요청을 보낸다.
GET /fruit/kiwi.gif HTTP/1.1
Host: www.exotiquecuisine.com- 서버가 객체와 함께 Last-Modified 날짜를 포함한 응답을 보낸다. 캐시는 객체와 마지막 수정 날짜를 함께 저장한다.
HTTP/1.1 200 OK
Last-Modified: Wed, 9 Sep 2015 09:23:24
Content-Type: image/gif
(data data data data data ...)- 이후 같은 객체를 요청받으면, 캐시가 조건부 GET으로 최신 여부를 확인한다.
GET /fruit/kiwi.gif HTTP/1.1
Host: www.exotiquecuisine.com
If-modified-since: Wed, 9 Sep 2015 09:23:24- 변경되지 않았다면 서버가 빈 body로 응답한다. 데이터 전송 없이 대역폭을 절약한다.
HTTP/1.1 304 Not Modified
Date: Sat, 10 Oct 2015 15:39:29
Server: Apache/1.3.0 (Unix)
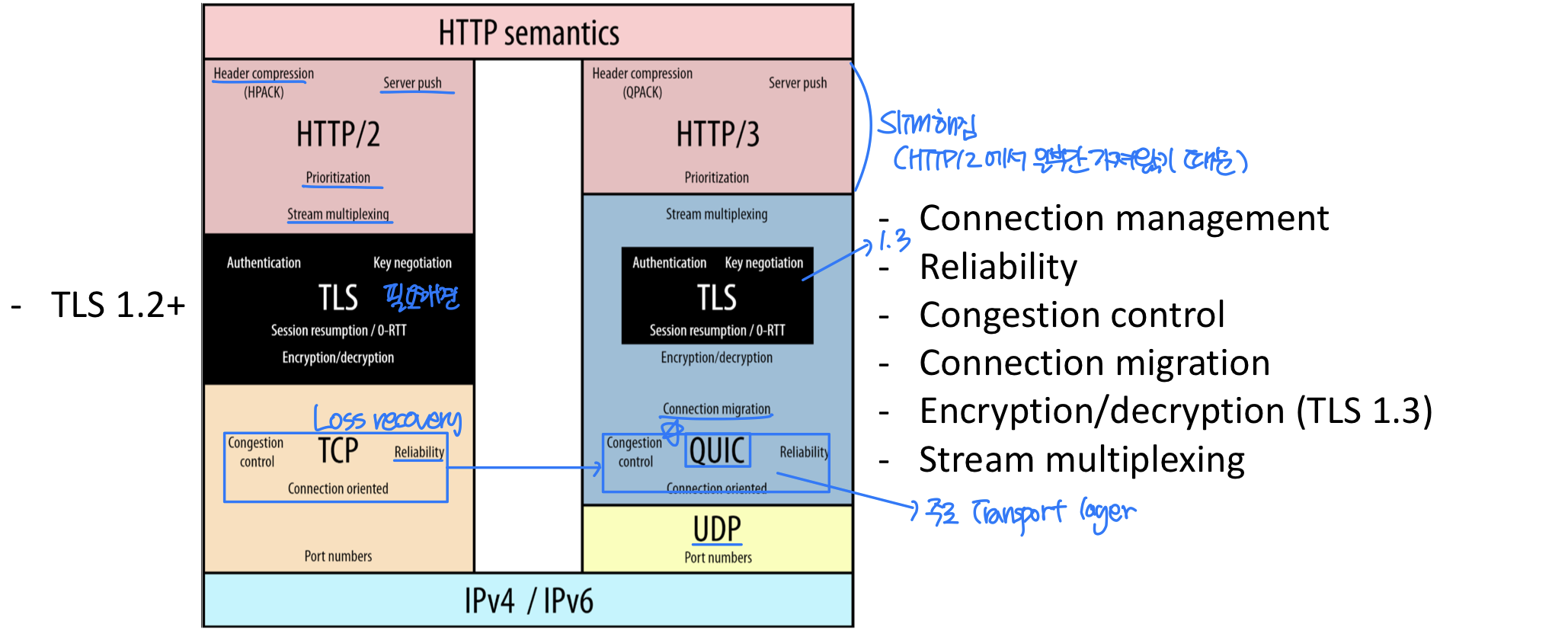
(empty entity body)HTTP/2
HTTP/1.1의 문제점: 단일 TCP 연결에서 pipelined GET을 사용할 때,
- 서버가 GET 요청에 순서대로(FCFS) 응답한다.
- FCFS 방식에서는 작은 객체가 큰 객체 뒤에서 전송을 기다려야 한다. 이것이 HOL(Head-of-Line) blocking이다.
- Loss recovery(손실된 TCP 세그먼트 재전송)가 전체 객체 전송을 지연시킨다.
HTTP/1.1에서는 여러 개의 병렬 TCP 연결(최대 6개)을 열어서 HOL blocking을 우회해왔다. TCP 혼잡 제어는 각 연결이 대역폭의 1/n을 사용하게 하므로, 여러 연결을 열면 더 많은 대역폭을 확보할 수 있었다.
HTTP/2의 주요 목표는 하나의 TCP 연결상에서 병렬 TCP 연결의 수를 줄이거나 제거하면서 멀티플렉싱 요청/응답 지연 시간을 줄이는 것이다.
주요 특징:
- Multiplexing으로 HOL blocking을 완화한다. 서버가 HTTP 응답을 보내려 할 때, 응답은 framing sub-layer에서 프레임으로 분할된다. 응답의 프레임이 다른 응답의 프레임과 인터리빙(interleaving)되어 단일 persistent TCP 연결로 전송된다.
- Binary format 사용 - 파싱하기에 효율적이고, 더 작은 프레임 크기를 갖고, 에러에 강하다.
- Header suppression (HPACK: RFC 7541) - Huffman coding과 인덱스 기반 압축
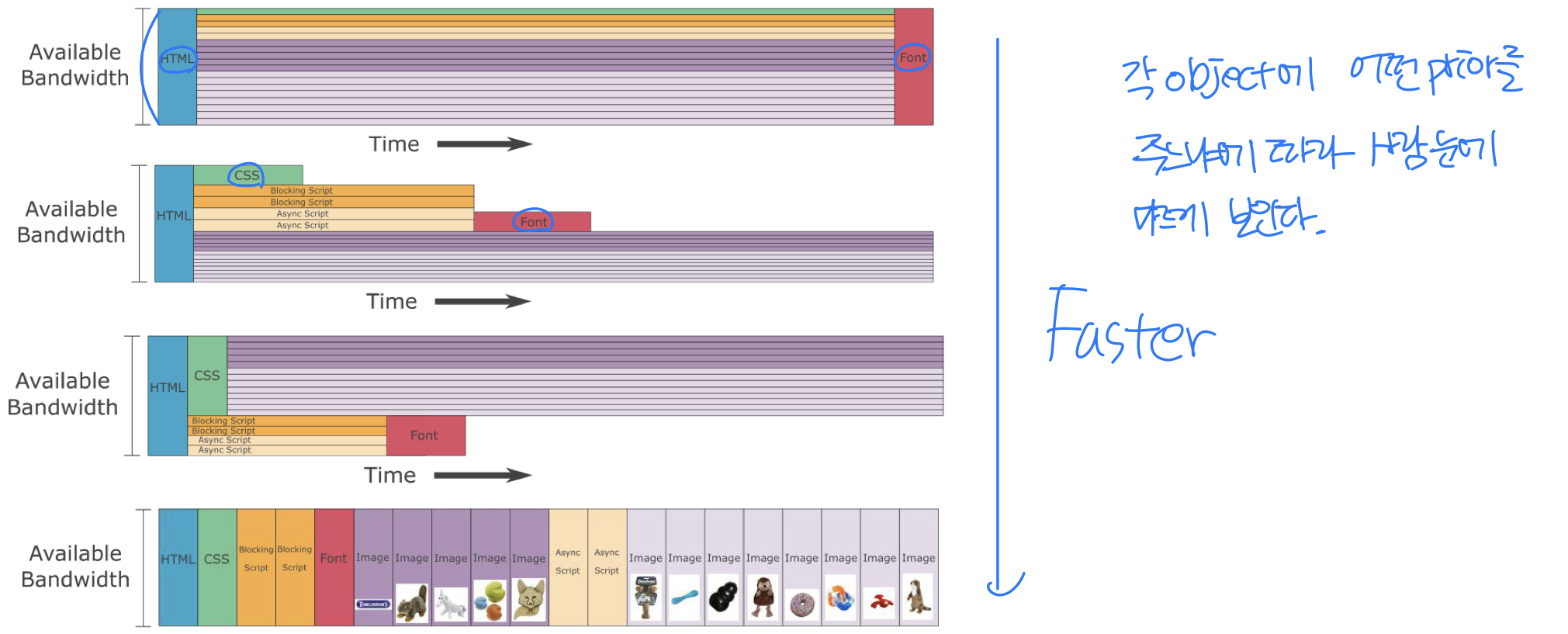
- Stream prioritization 지원 - 1에서 256 사이의 가중치로 요청 우선순위를 부여할 수 있다. 높은 수치일수록 높은 우선순위를 갖는다.
- Server push 메커니즘 지원: 클라이언트가 요청하지 않아도 요청할 것 같은 정보를 미리 제공한다. HTML을 분석하여 필요한 객체를 식별하고, 해당 객체들에 대한 요청이 도착하기 전에 보낸다. 추가 지연을 없앨 수 있지만, 불필요한 정보를 전송할 수도 있다는 단점이 있다.
HTTP 메시지를 독립된 프레임들로 쪼개고, 인터리빙하고, 반대편에서 재조립하는 것이 HTTP/2의 가장 중요한 개선점이다.
Multiplexing
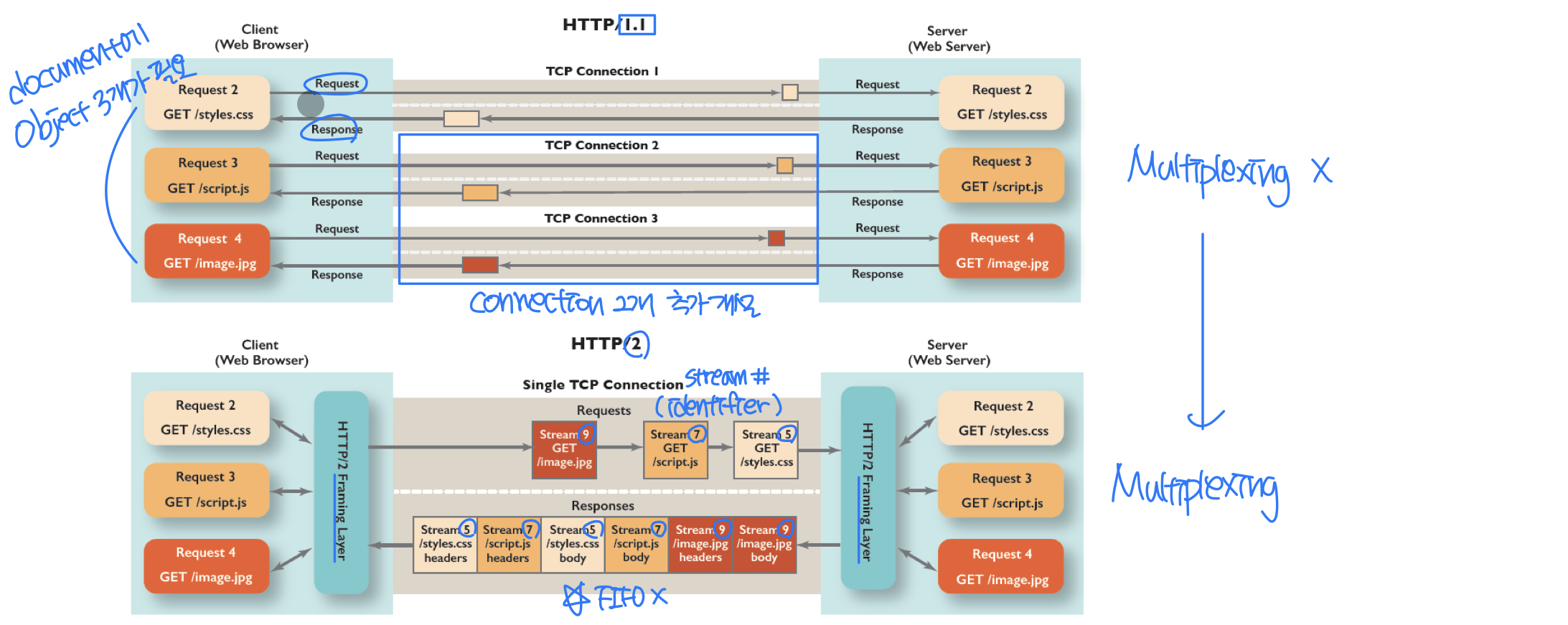
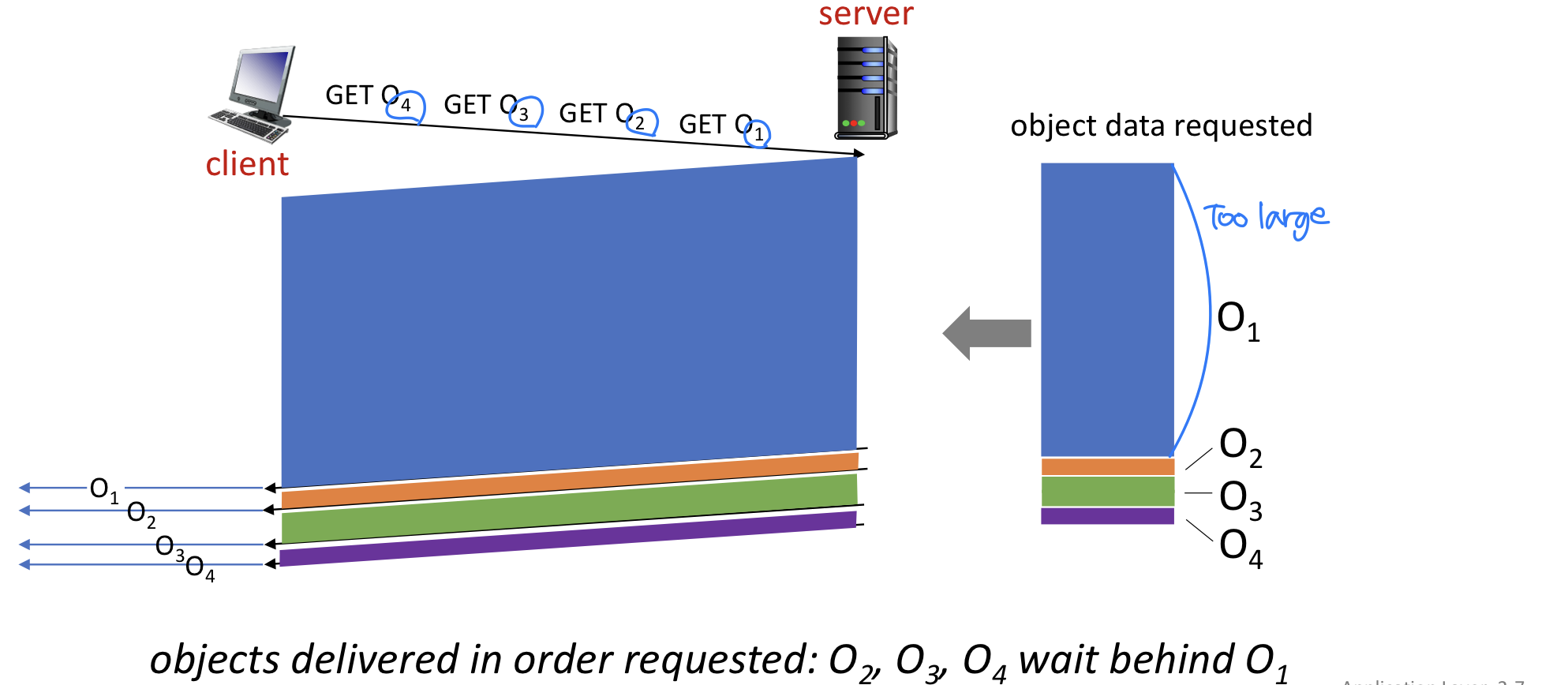
HOL blocking 완화
HTTP 1.1에서 클라이언트가 1개의 큰 객체(예: 비디오)와 3개의 작은 객체를 요청하는 경우:
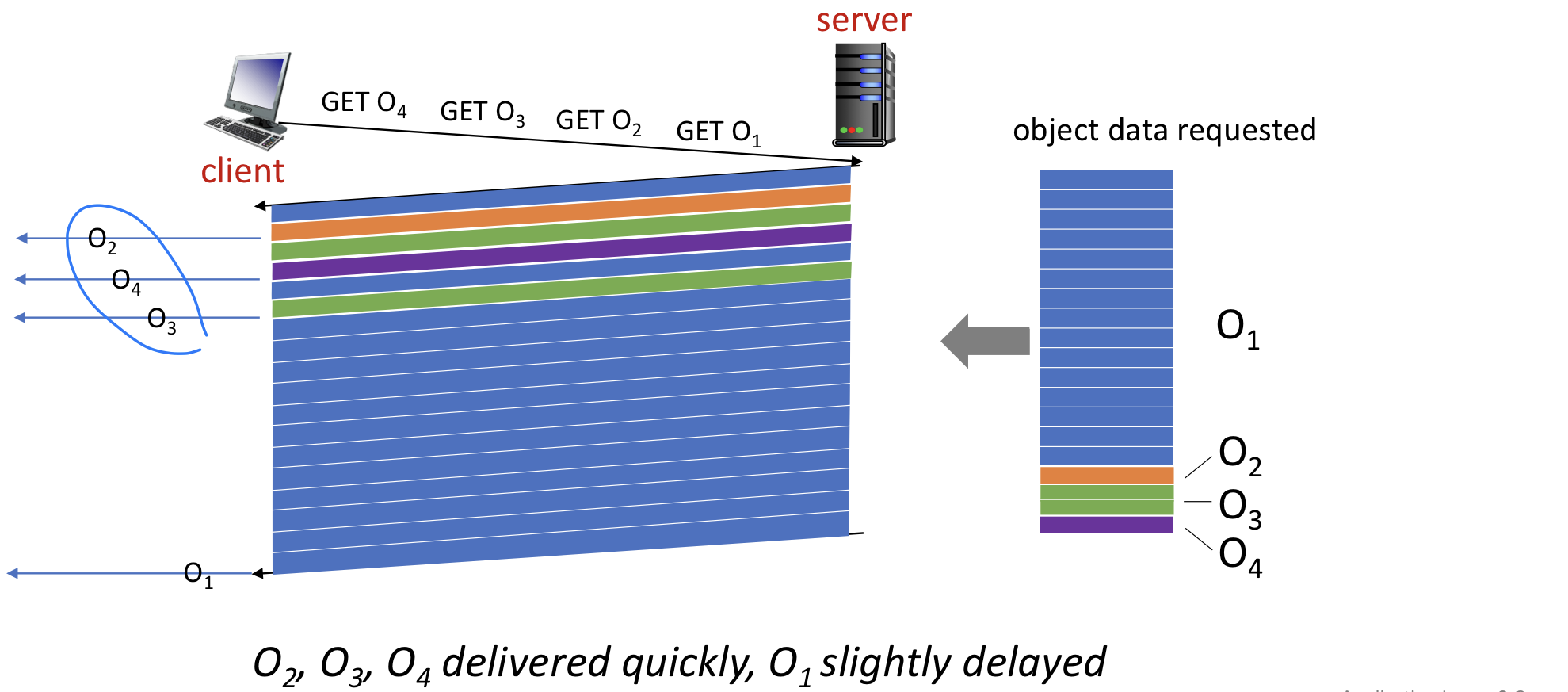
HTTP/2에서는 객체가 프레임으로 분할되고, 프레임 전송이 인터리빙된다:
Stream Prioritization
HTTP/2에서 HTTP/3으로
HTTP/2의 한계:
- 단일 TCP 연결을 사용하므로, 패킷 손실 복구가 모든 객체 전송을 지연시킨다.
- HTTP 1.1과 마찬가지로, 브라우저가 stalling을 줄이고 전체 throughput을 높이기 위해 병렬 TCP 연결을 열려는 유인이 있다.
- 기본 TCP 연결은 보안이 없어 TLS 암호화 오버헤드가 추가된다.
HTTP/3:
- QUIC(Quick UDP Internet Connection) 위에서 동작하는 HTTP
- HTTP/2를 QUIC과 호환되도록 일부 조정한 버전이 HTTP/3으로 명명되었다.
- HTTP/3의 핵심 기능인 빠른 연결 설정, 적은 HOL blocking, connection migration 등은 모두 QUIC에서 비롯된다. 특히 connection migration 덕분에 Wi-Fi에서 4G/5G로 전환해도 연결이 유지된다.
2.3 E-mail과 SMTP
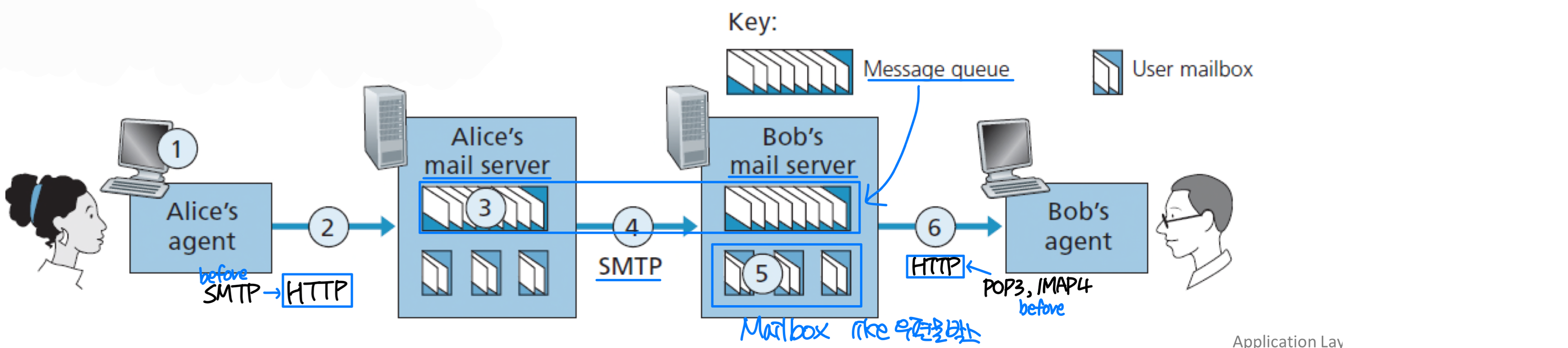
이메일 시스템은 세 가지 주요 구성요소로 이루어진다.
- User agent: "mail reader"라고도 하며, Outlook, Apple Mail 같은 프로그램이다. 사용자가 메시지를 읽고, 응답하고, 전달하고, 저장하고, 구성하게 해준다.
- Mail server:
- mailbox: 사용자의 수신 메시지를 보관
- message queue: 발송 대기 중인 메일 메시지 큐. 전달에 실패하면 약 30분마다 재시도하고, 계속 실패 시 메시지를 제거하고 송신자에게 통보한다.
- SMTP (Simple Mail Transfer Protocol):
- Client: 발신 메일 서버
- Server: 수신 메일 서버
SMTP
SMTP는 TCP를 사용하여 이메일 메시지를 포트 25의 서버로 신뢰성 있게 전송한다.
주요 특징:
- SMTP 전송에는 세 단계(three phases)가 있다: handshaking(greeting), transfer of messages, closure
- Command/response 상호작용 방식: commands는 ASCII 텍스트, response는 상태 코드와 문구
- 메시지(header + body)는 7-bit ASCII여야 한다. 이 때문에 전송 용량이 제한되어 큰 첨부 파일이나 비디오 전송에 문제가 있다.
- SMTP는 persistent connection을 사용하여, 같은 TCP 연결로 여러 메시지를 전송할 수 있다.
- Direct transfer: 발신 서버에서 수신 서버로 직접 전송. 두 메일 서버가 멼 거리에 떨어져 있더라도 중간 메일 서버를 이용하지 않는다. 실패 시에도 중간 서버에 저장되지 않고 송신자의 메일 서버에 남아있다.
- SMTP는 push protocol(발신자가 밀어넣음)이고, HTTP는 pull protocol(수신자가 당겨옴)이다.
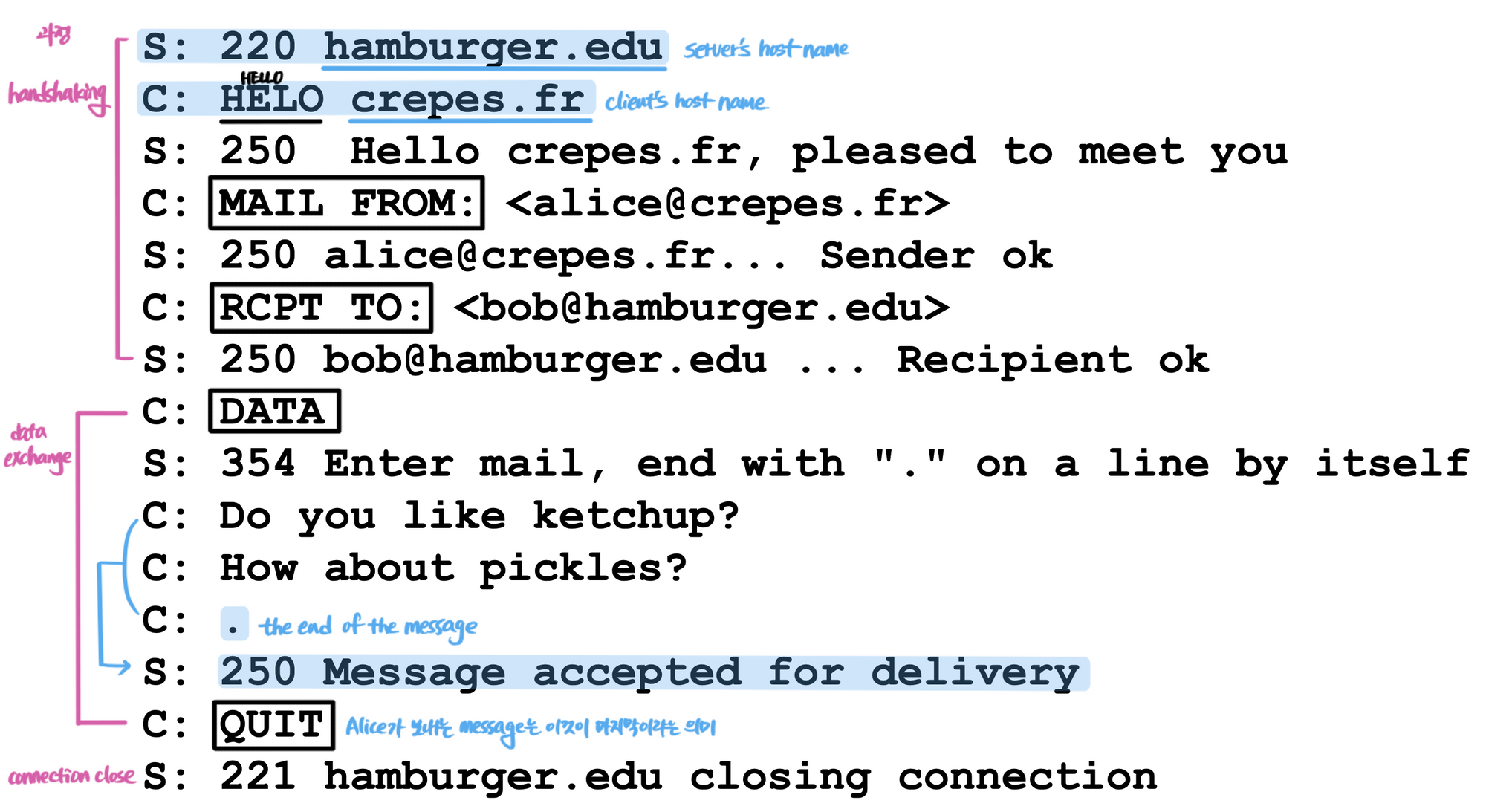
기본 동작 과정:

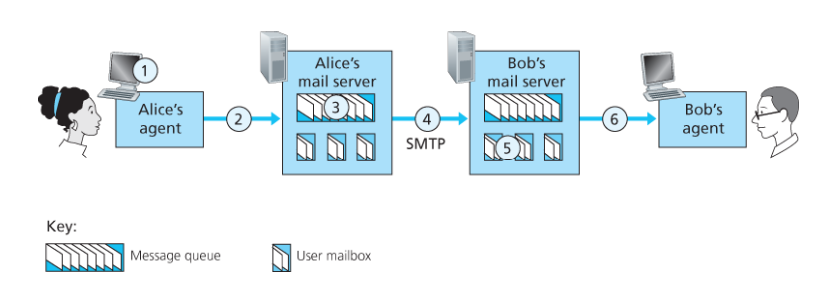
- 앨리스가 사용자 에이전트를 통해 밥에게 메일을 보낸다.
- 사용자 에이전트가 메시지를 앨리스의 메일 서버에 보내고, 메시지 큐에 놓인다.
- 앨리스 메일 서버의 SMTP 클라이언트가 밥의 메일 서버의 SMTP 서버에 TCP 연결을 설정한다 (포트 25).
- 핸드셰이킹 후 SMTP 클라이언트가 메시지를 전송한다.
- 밥의 메일 서버가 메시지를 밥의 메일박스에 저장한다.
- 밥이 편한 시간에 사용자 에이전트로 메시지를 읽는다.
SMTP 대화 예시:
S: 220 hamburger.edu
C: HELO crepes.fr
S: 250 Hello crepes.fr, pleased to meet you
C: MAIL FROM: <alice@crepes.fr>
S: 250 alice@crepes.fr ... Sender ok
C: RCPT TO: <bob@hamburger.edu>
S: 250 bob@hamburger.edu ... Recipient ok
C: DATA
S: 354 Enter mail, end with "." on a line by itself
C: Do you like ketchup?
C: How about pickles?
C: .
S: 250 Message accepted for delivery
C: QUIT
S: 221 hamburger.edu closing connection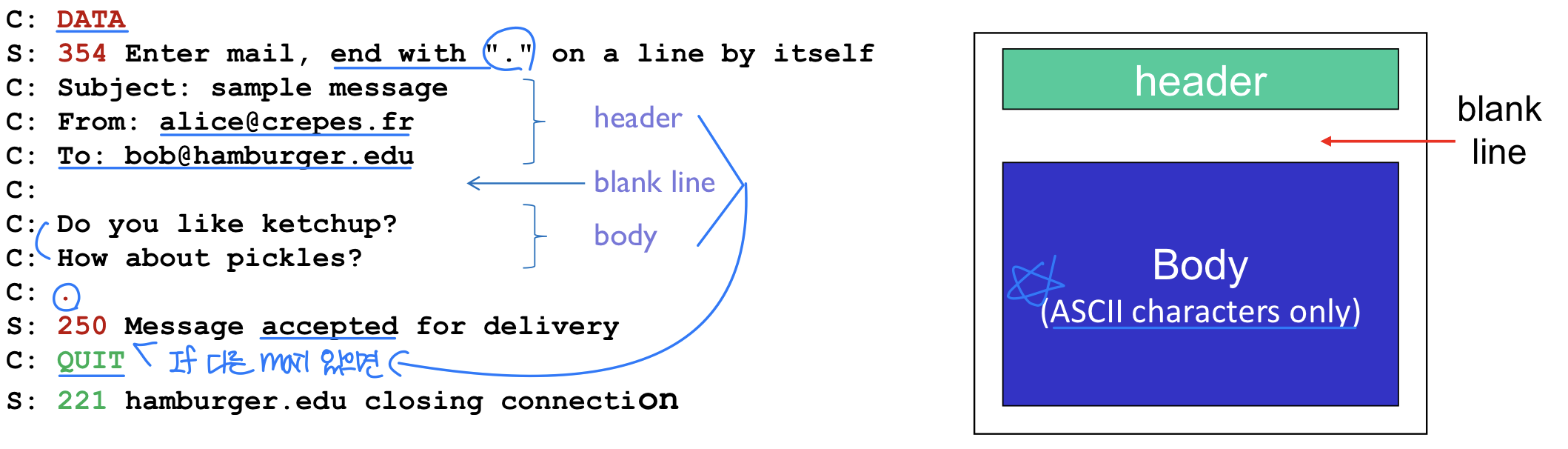
클라이언트는 HELO, MAIL FROM, RCPT TO, DATA, QUIT 명령을 보내고, 하나의 점(.)으로 된 라인이 메시지의 끝을 나타낸다.
MIME 확장

MIME(Multi-purpose Internet Mail Extensions)은 non-ASCII 데이터를 전송하기 위한 확장이다. 메시지 헤더에 MIME content type을 선언하는 추가 라인이 들어간다.
메일 메시지 포맷
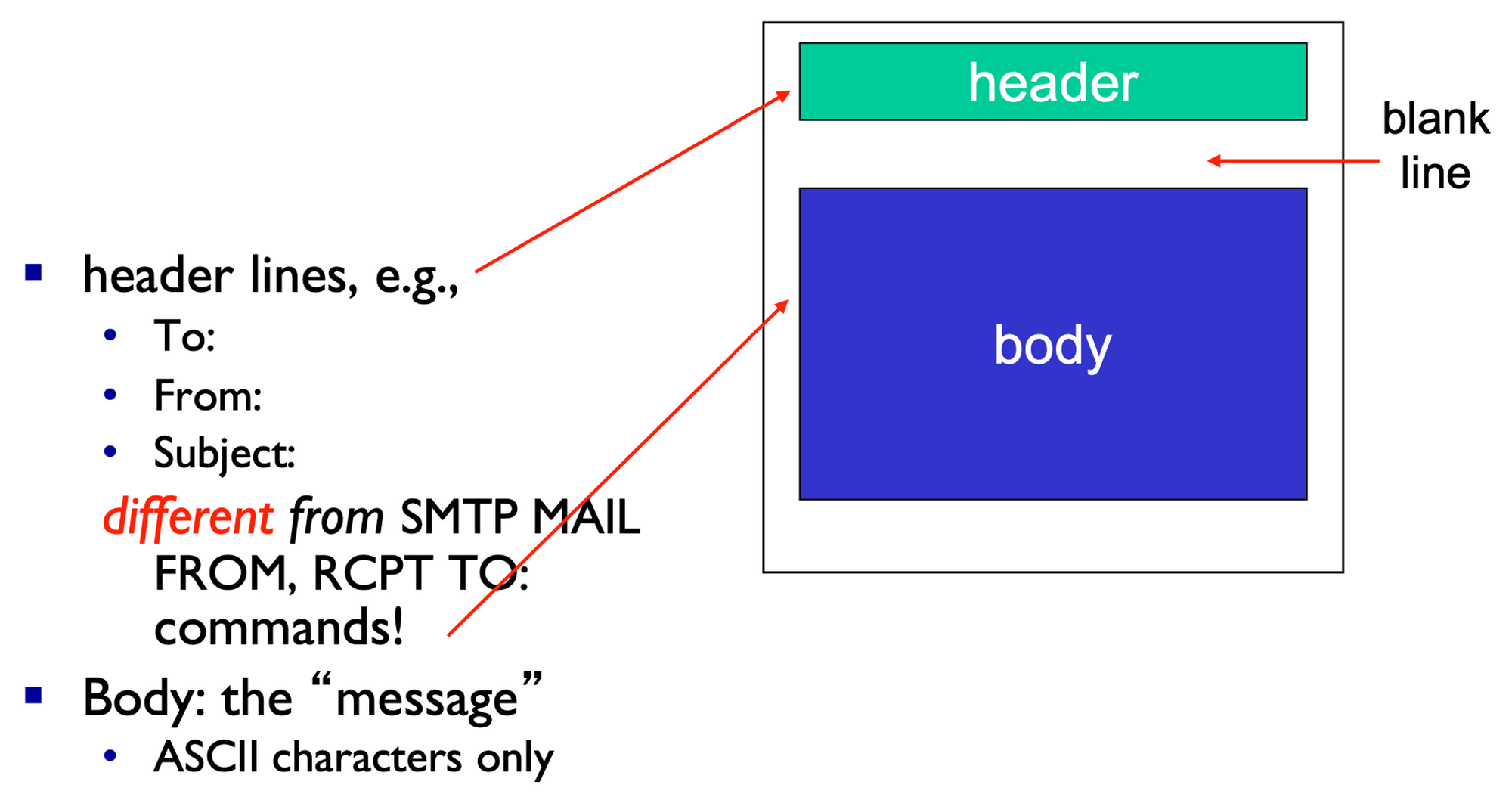
전자메일 헤더는 RFC 5322에 정의되며, 반드시 From:과 To: 헤더 라인을 가져야 한다.
From: alice@crepes.fr
To: bob@hamburger.edu
Subject: Searching for the meaning of life.
Message body here메일 접근 프로토콜


메일 접근 프로토콜은 서버에서 메일을 가져오는(retrieval) 역할을 한다. SMTP는 push 프로토콜이므로, 메일을 가져오는 pull 동작에는 다른 프로토콜이 필요하다.
송신자 에이전트에서 수신자 메일 서버까지:
- 송신자의 사용자 에이전트가 SMTP 또는 HTTP를 이용하여 자신의 메일 서버로 전송한다.
- 자신의 메일 서버가 SMTP를 이용하여 수신자의 메일 서버로 중계한다.
수신자 메일 서버에서 수신자 에이전트까지:
- HTTP: Gmail, Hotmail, Yahoo!Mail 등 웹 기반 전자메일에서 사용. 메일 서버는 SMTP와 HTTP 인터페이스를 모두 가지고 있어야 한다.
- IMAP (Internet Mail Access Protocol) [RFC 3501]: POP3보다 더 많은 기능을 제공하며, 폴더 기능을 지원한다.
- POP3 (Post Office Protocol 3) [RFC 1939]: 인증 단계와 트랜잭션 단계(다운로드)로 구성된다.
2.4 DNS (Domain Name System)
이름과 주소
- Name(호스트 이름): 사람이 사용하는 문자열. 예: www.naver.com. 기억하기 쉬운(Mnemonic) 형태이지만, 인터넷에서의 호스트 위치 정보를 거의 제공하지 않으며, 가변 길이의 알파뉴메릭 문자로 구성되어 라우터가 처리하기 어렵다.
- Address(IP 주소): 패킷에서 호스트를 식별하기 위한 주소. IPv4가 32비트(4바이트), IPv6가 128비트이다. 계층 구조를 가져서 왼쪽에서 오른쪽으로 조사하면 호스트의 위치 정보를 얻을 수 있다.
IP 주소와 이름을 어떻게 매핑(mapping)할 것인가? 이름을 주소로, 또는 주소를 이름으로 변환하는 것을 name-address resolution이라 한다.
해결책 1: hostname-to-IP 매핑 파일(hosts 파일). ARPANET 시절에 사용되었다. (예: 127.0.0.1 = loopback address)
해결책 2: 인터넷에는 너무 많은 객체가 있어서 단일 관리 센터로는 불가능하다. 중앙화된 시스템은 하나가 죽으면 전체가 마비되고(single point of failure), 모든 질의를 처리해야 하는 트래픽 문제, 먼 거리의 지연 문제, 유지 관리 문제가 발생한다. 따라서 분산 데이터베이스 시스템을 사용하며, 이름 공간(name space)을 계층적 트리(hierarchical tree) 구조로 분할한다.
DNS의 의미
DNS는 두 가지 의미를 가진다.
- DNS 서버의 계층 구조로 구현된 분산 데이터베이스
- 호스트가 DNS 서버에 질의(query)하여 hostname을 IP 주소로 변환할 수 있게 하는 애플리케이션 계층 프로토콜
- UDP 위에서 동작한다. 서버 포트: 53
DNS가 UDP를 사용하는 이유:
- 빠른 속도: TCP는 3-way handshake가 필요하지만, UDP는 연결 설정 비용이 없다. DNS가 전송하는 패킷 사이즈가 매우 작아(512 bytes 이내) 신뢰성이 보장되지 않아도 된다. 못 받으면 다시 요청하면 되기 때문이다.
- 연결 상태 유지 불필요: TCP는 호스트 간 연결 상태를 유지하지만, UDP는 어떤 정보도 기록하지 않는다. DNS 서버는 TCP보다 더 많은 클라이언트를 수용할 수 있다.
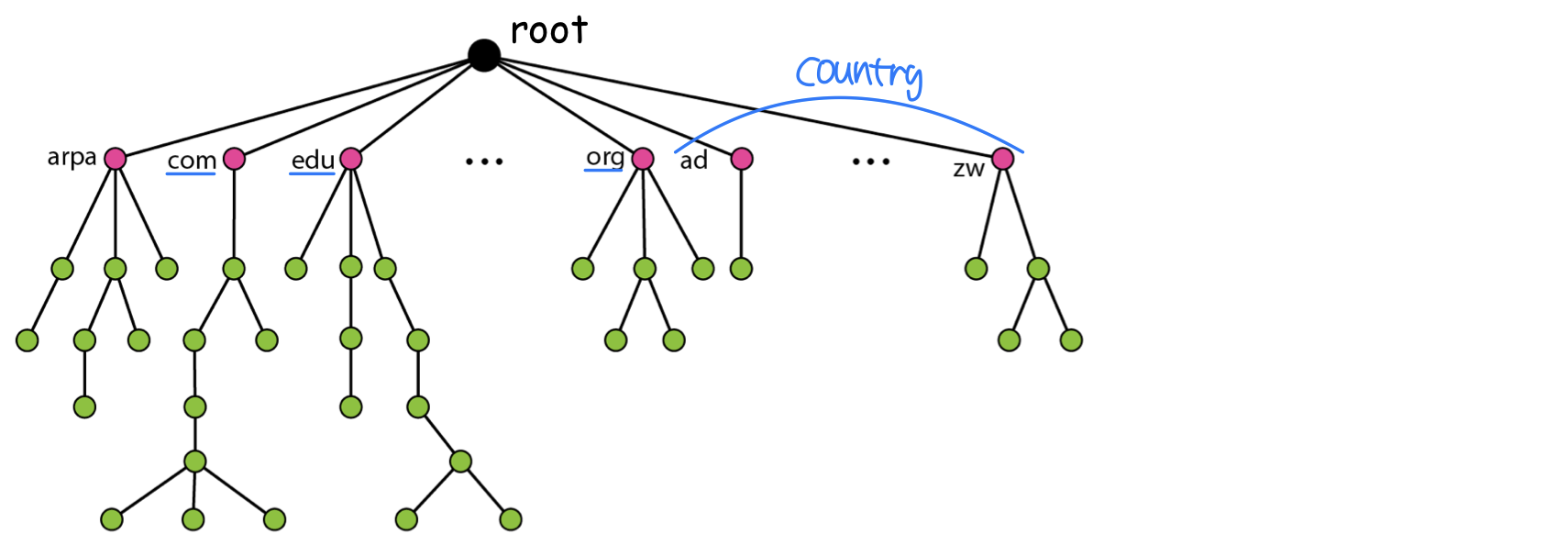
도메인 이름 트리는 최대 128 레벨(level 0 root ~ level 127)을 가질 수 있으며, 레벨당 최대 63 문자이다. 계층은 zone이라 불리는 서브트리로 분할되며, 각 zone은 해당 부분의 계층을 책임지는 관리 주체(administrative authority)에 대응된다.
DNS의 추가 서비스
hostname을 IP 주소로 변환하는 것 외에도 DNS는 다음 서비스를 제공한다.
- 호스트 에일리어싱(Host Aliasing): 복잡한 정식 호스트 이름(canonical hostname)에 대해 간단한 별칭을 제공한다. 예:
relay1.west-coast.enterprise.com의 별칭이enterprise.com - 메일 서버 에일리어싱(Mail Server Aliasing): 메일 서버의 정식 호스트 이름에 대한 간단한 별칭을 제공한다.
- 부하 분산(Load Distribution): 인기 있는 사이트는 여러 서버에 중복되어 있어, 하나의 호스트 이름에 여러 IP 주소가 연관된다. DNS는 IP 주소 집합을 순환식(round-robin)으로 응답하여 트래픽을 분산한다.
DNS: 분산, 계층적 데이터베이스
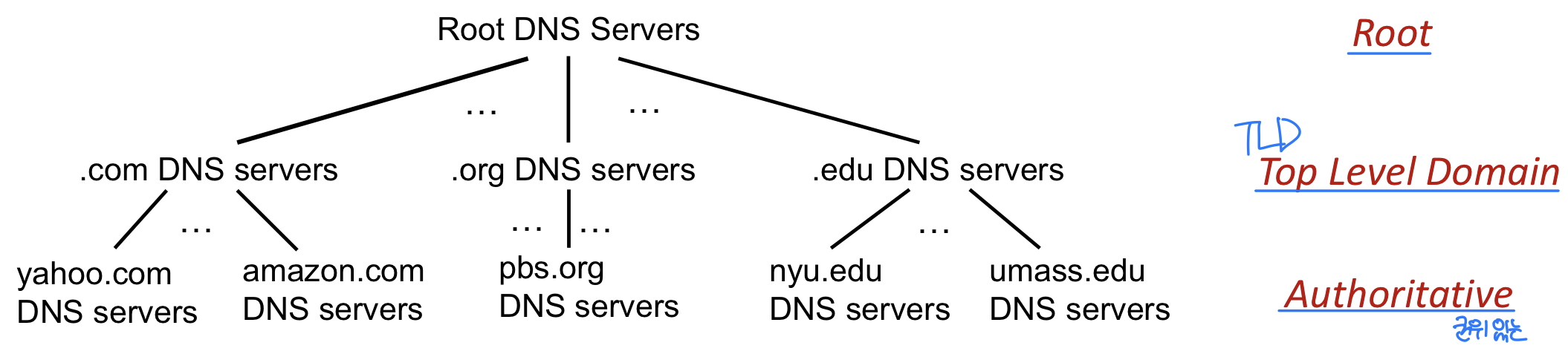
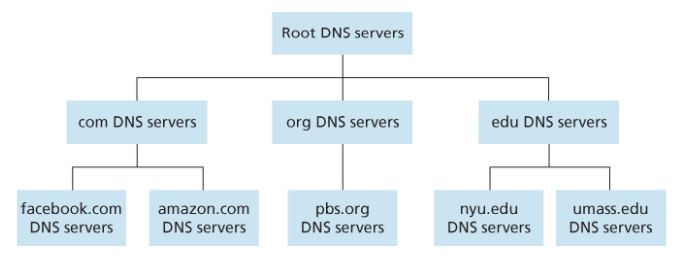
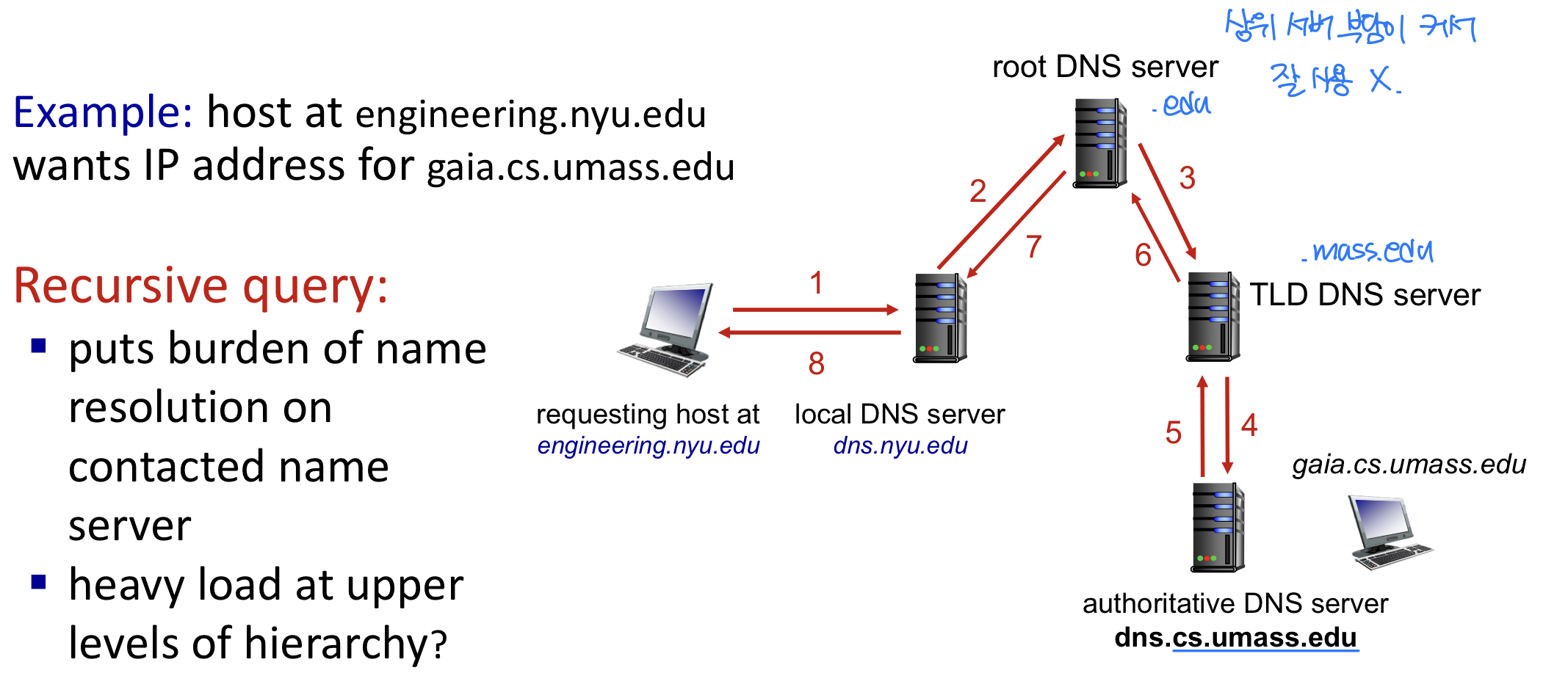
예를 들어 클라이언트가 **www.amazon.com**의 IP 주소를 원한다면:
- 클라이언트가 root server에 질의하여 .com DNS 서버를 찾는다.
- .com DNS 서버에 질의하여 amazon.com DNS 서버를 찾는다.
- amazon.com DNS 서버에 질의하여 www.amazon.com의 IP 주소를 얻는다.
Root DNS 서버:
- 인터넷에 13개의 root server 조직(A~M)이 있다 (www.root-servers.org)
- 전 세계에 1000개 이상의 root server가 분산 배치되어 있다.
- TLD 서버의 IP 주소를 제공한다.
- ICANN(Internet Corporation for Assigned Names and Numbers)에 의해 조정된다.
TLD(Top-Level Domain) 서버:
- .com, .org, .net, .edu, .kr 등 최상위 도메인과 국가 코드 도메인을 관리한다.
- Authoritative DNS 서버의 IP 주소를 제공한다.
Authoritative DNS 서버:
- 조직 자체의 DNS 서버로, 해당 조직의 호스트에 대한 공식적인 hostname-to-IP 매핑을 제공한다.
- 조직 자체 또는 서비스 제공자가 관리할 수 있다.
Local DNS Name Server
호스트가 DNS query를 보내면, 먼저 local DNS server로 전달된다. 로컬 DNS 서버는 서버들의 계층 구조에 엄밀히 속하지는 않지만 DNS 구조의 중심에 있다. ISP가 로컬 DNS 서버를 관리하며, 대체로 호스트에 가까이 있어 지연이 적다.
Local DNS server는 다음 방법으로 응답한다.
- 최근 name-to-address 변환 쌍의 local cache에서 응답
- Windows:
ipconfig /displaydns로 확인,ipconfig /flushdns로 삭제
- Windows:
- cache에 없으면 DNS 계층으로 요청을 전달(forwarding)하여 해석
DNS 이름 해석: Iterated Query
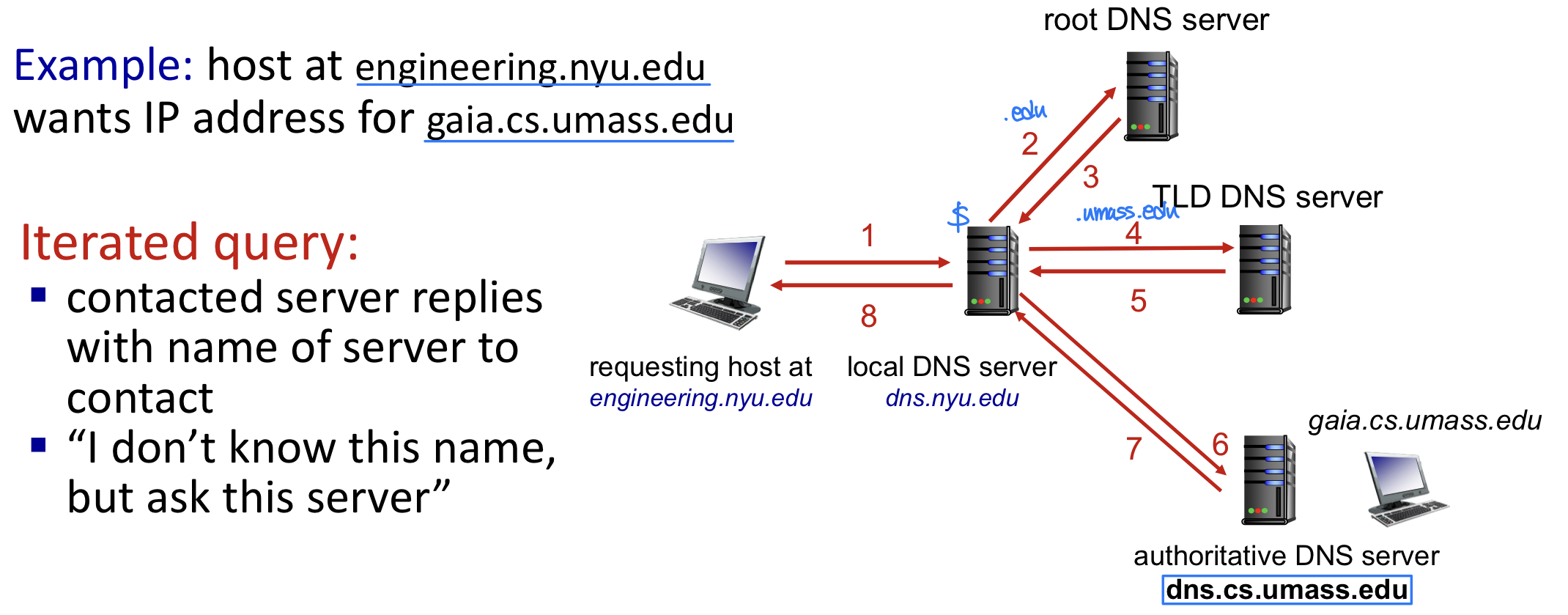
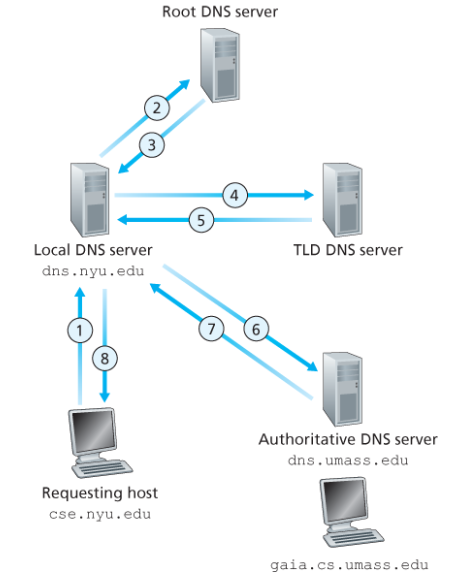
대부분의 경우 iterated query(반복적 질의)를 사용한다. 로컬 DNS 서버가 루트 서버에 질의하면, 루트 서버가 TLD 서버의 주소를 알려주고, 로컬 DNS 서버가 다시 TLD 서버에 질의하는 식이다.
반복적 질의를 선호하는 이유: 재귀적 질의에서는 높은 계층의 DNS 서버가 책임져야 하는 것이 많다. 중요한 인프라인 root name server보다 local DNS server가 더 많은 일을 하는 것이 바람직하다.
DNS 이름 해석: Recursive Query
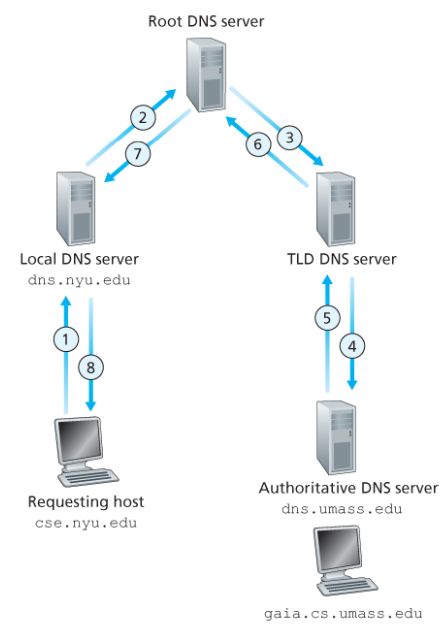
DNS Caching
네임 서버가 매핑을 학습하면, 이를 캐시하고 이후 질의에 대해 즉시 캐시된 매핑을 반환한다.
- 캐싱은 응답 시간을 개선한다.
- 캐시 항목은 일정 시간(TTL: Time To Live) 후에 만료된다.
- TLD 서버는 보통 local name server에 캐시되어 있어 루트 서버를 우회할 수 있다.
캐시된 항목은 out-of-date(오래된 상태)일 수 있다. 호스트가 IP 주소를 변경하면, 모든 TTL이 만료될 때까지 인터넷 전체에 알려지지 않을 수 있다. 이것은 best-effort name-to-address translation이다.
업데이트/알림 메커니즘이 IETF 표준(RFC 2136)으로 제안되어 있다.
DNS 레코드

DNS 레코드는 Resource Record(RR) 형식으로 저장된다. 4개의 Tuple로 구성된다:
(Name, Value, Type, TTL)Type에 따라 Name과 Value의 의미가 달라진다.
- type=A (Address): name은 hostname, value는 IPv4 주소(32bit). 표준 호스트 이름의 IP 주소 매핑을 제공한다.
- type=NS (Name Server): name은 domain(예: foo.com), value는 해당 도메인의 authoritative name server의 hostname
- type=CNAME (Canonical Name): name은 alias(별칭), value는 canonical name(정식 호스트 이름). 예: www.ibm.com의 실제 이름이 servereast.backup2.ibm.com일 수 있다.
- type=MX (Mail Exchange): value는 해당 name과 연관된 SMTP 메일 서버의 정식 이름. 메일 서버의 정식 이름을 얻으려면 MX 레코드를, 다른 서버의 정식 이름을 얻으려면 CNAME 레코드를 질의한다.
- type=AAAA: name은 hostname, value는 IPv6 주소(128bit)
- type=TXT: name은 hostname, value는 임의의 사람이 읽을 수 있는 텍스트
DNS 프로토콜 메시지

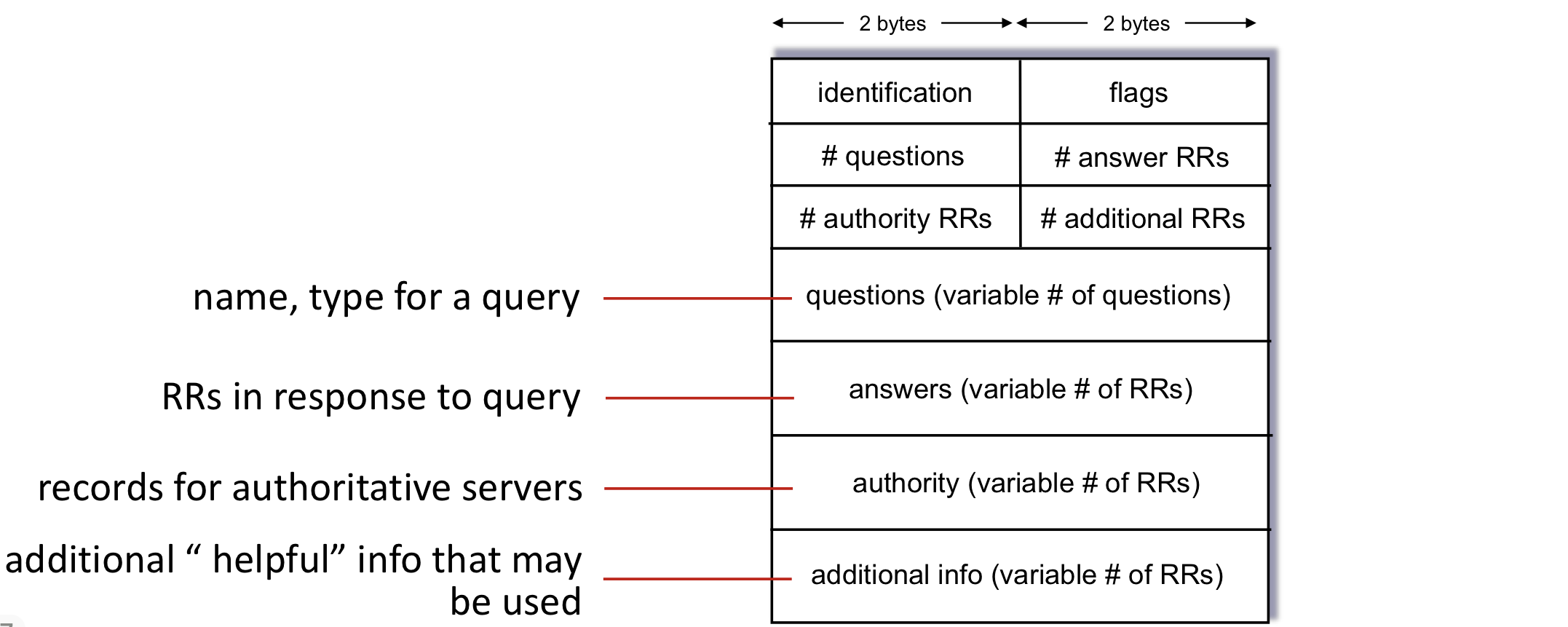
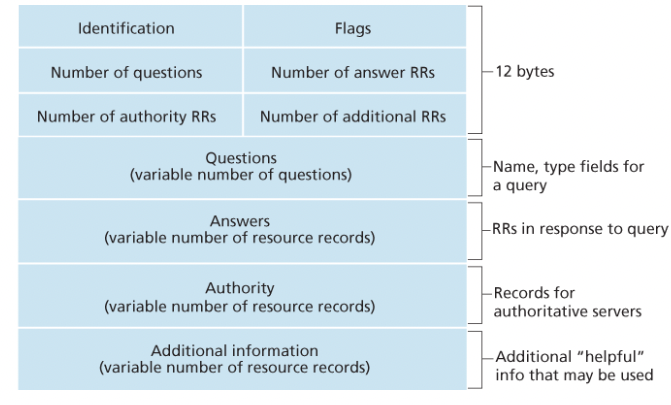
DNS의 요청과 응답 메시지는 동일한 포맷을 사용한다.
Header (처음 12바이트):
- 식별자: 16비트 숫자로 질의와 응답을 매칭한다.
- 플래그 필드: 질의/응답 구분, 책임 플래그, 재귀 요구/가능 플래그 등
- 개수 필드: 이후 데이터 영역의 네 가지 타입의 발생 횟수
Payload:
- 질문 영역: 질의되는 이름과 타입(A, NS 등)
- 답변 영역: 질의된 이름에 대한 자원 레코드. 하나의 호스트 이름이 여러 IP를 가질 수 있어 여러 개의 레코드를 포함할 수 있다.
- 책임 영역: 다른 책임 서버의 레코드
- 추가 영역: 도움이 되는 추가 레코드 (예: MX 질의에 대한 A 레코드)
DNS에 정보 등록하기
예를 들어 새로운 스타트업 "Network Utopia"가 도메인을 등록하는 경우:
- ICANN이 인증한 상업 기관인 registrar(등록 기관)를 통해 등록한다.
- Registrar는 요청된 도메인 이름이 고유한지 확인한 후 DNS 데이터베이스에 등록한다.
- Registrar에게 authoritative name server(primary, secondary)의 이름과 IP 주소를 제공해야 한다.
- Registrar가 .com TLD 서버에 두 개의 RR을 삽입한다:
(networkutopia.com, dns1.networkutopia.com, NS)(dns1.networkutopia.com, 212.212.212.1, A)
- IP 주소 212.212.212.1로 로컬에 authoritative server를 생성한다.
- www.networkutopia.com에 대한 type A 레코드
- networkutopia.com에 대한 type MX 레코드
DNS 보안
DDoS 공격:
- Root server에 대량의 트래픽을 보내 query 서비스를 마비시킨다.
- 2002년 BW flooding(Ping attack) 발생. 피해는 적었는데, 트래픽 필터링과 local DNS 서버가 TLD 서버의 IP를 캐시하여 root server를 우회할 수 있었기 때문이다.
- TLD 서버 공격: 더 위험할 수 있다. 2016년 최상위 도메인 서비스 제공자 Dyn에 대한 공격으로 유명 애플리케이션들이 무차별 교란되었다.
Spoofing 공격:
- 중간자 공격(man-in-the-middle attack)
- DNS 질의를 가로채서 가짜(bogus) 응답을 반환한다.
- DNS cache poisoning: 캐시에 잘못된 정보를 주입
- RFC 4033: DNSSEC 인증 서비스로 방어
2.5 P2P 애플리케이션
P2P에서는 모든 노드가 클라이언트이자 서버이다. Peer들은 다른 peer에게 서비스를 요청하고, 동시에 서비스를 제공한다. 항상 켜져 있는 인프라스트럭처 서버에 최소로 의존하고(혹은 의존하지 않고), 간헐적으로 연결되는 호스트 쌍들이 서로 직접 통신한다.
핵심 특징:
- Self scalability(자가 확장성): 새로운 peer가 참여하면 서비스 용량과 수요가 함께 증가한다.
- Peer들은 독자적(autonomous)으로 동작하며, 간헐적으로 연결되고 IP 주소가 변할 수 있다.
대표적인 예: Gnutella(완전 분산 P2P), BitTorrent(파일 공유), KanKan(스트리밍)
P2P의 문제점
- Robustness 부족: churn(노드의 빈번한 join/leave)으로 인한 불안정
- 각 노드의 낮은 성능: 낮은 bandwidth, 낮은 컴퓨터 성능, 낮은 uptime(가동 시간)
- 자원 검색의 어려움: 원하는 콘텐츠를 누가 가지고 있는지 찾기 어렵다.
- NAT traversal: 서버 역할을 할 때 public IP 주소와 port가 필요하다. 대부분의 PC는 NAT 장치를 통해 인터넷에 연결된다.
- Free riding: 클라이언트 역할만 하고 떠나버리는 노드
- 보안 문제
파일 분배: Client-Server vs P2P
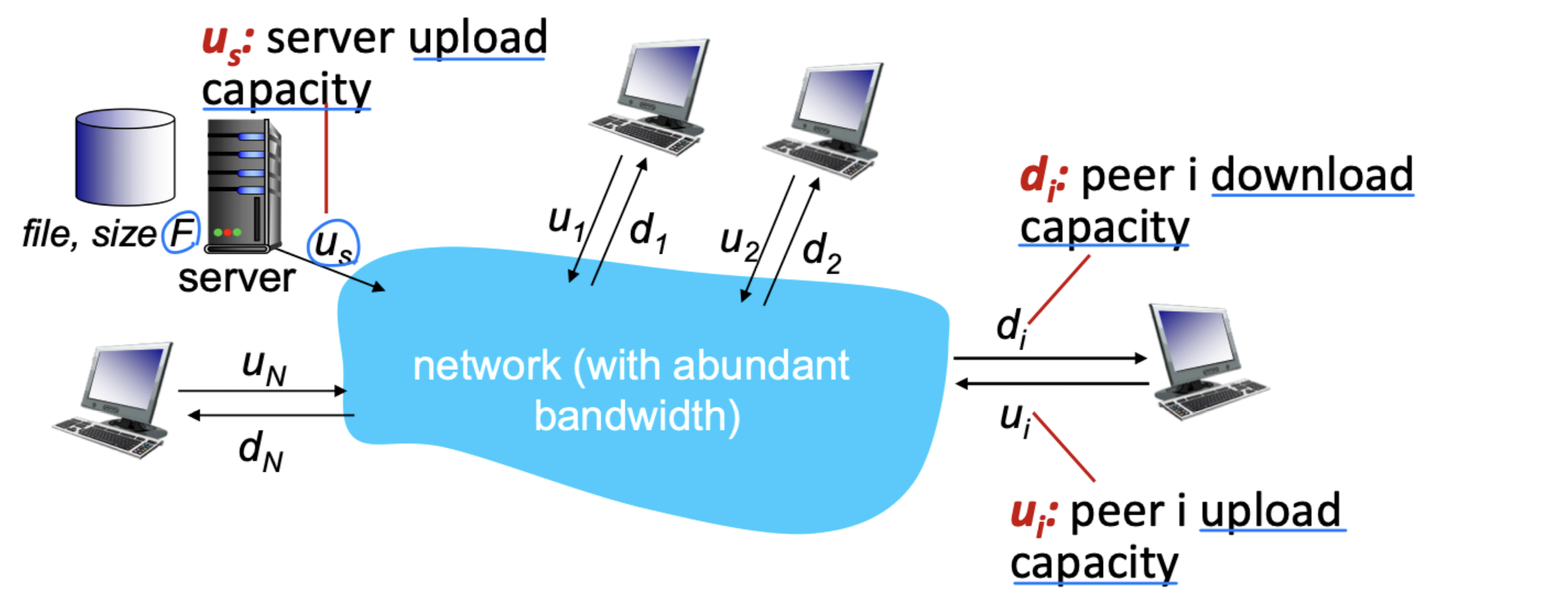
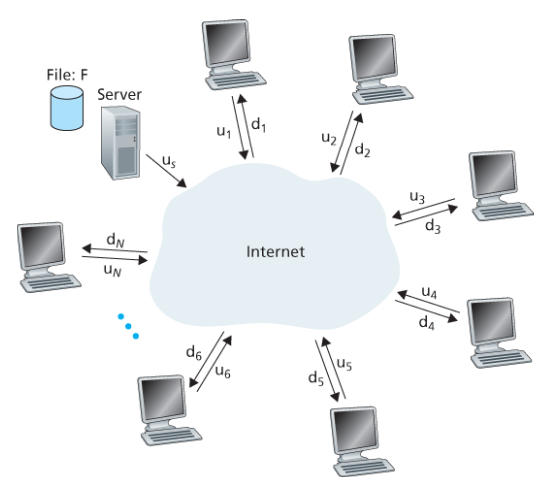
크기 F인 파일을 하나의 서버에서 N개의 peer에게 분배하는 데 얼마나 걸리는가? 인터넷 코어는 풍부한 대역폭을 가지고 있다고 가정하며, 모든 병목은 접속 링크에서 발생한다.
Client-Server 방식:
- Server 전송: N개의 파일 사본을 순차적으로 업로드해야 한다. NF 비트를 전송하므로 시간은 NF/u_s
- Client: 가장 느린 클라이언트의 다운로드 시간 F/d_min
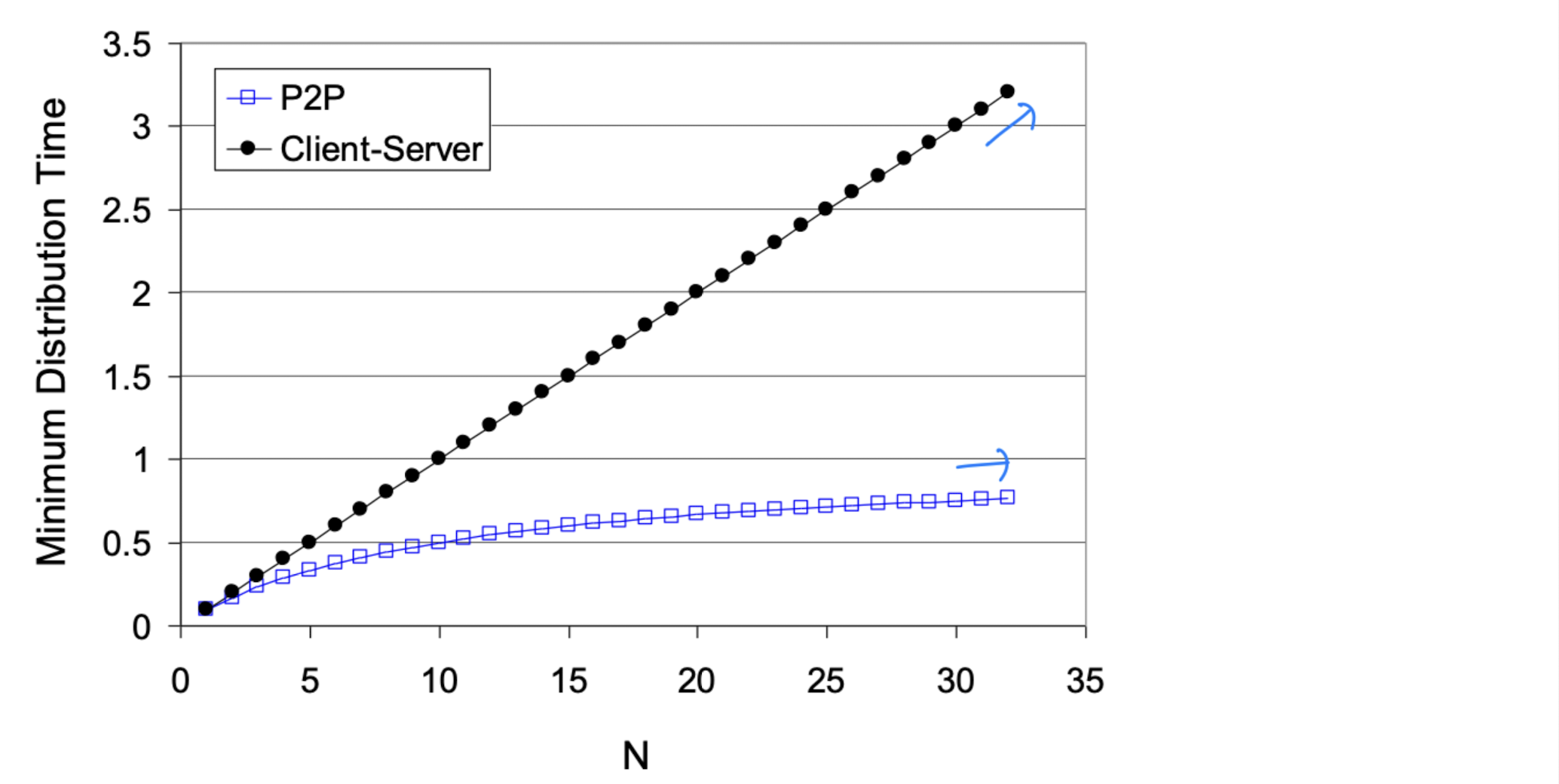
D(cs) >= max( NF/u_s, F/d_min )충분히 큰 N에 대해 N에 선형적으로 증가한다.
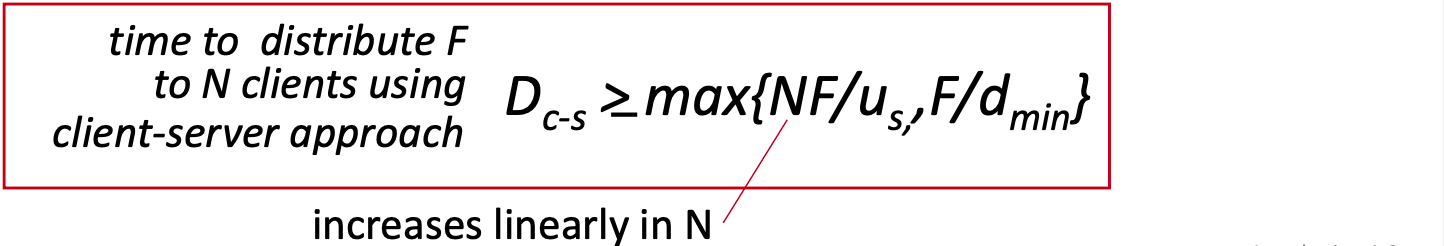
파일 분배 시간: P2P
- Server 전송: 최소 한 개의 사본만 업로드하면 된다. 시간: F/u_s
- Client: 가장 느린 링크의 클라이언트 다운로드 시간: F/d_min
- 전체 클라이언트: 총 다운로드 양은 NF bits. 모든 노드의 업로드 용량 합계 u_s + Sigma(u_i)
D(p2p) >= max( F/u_s, F/d_min, NF/(u_s + Sigma(u_i)) )P2P는 N이 증가해도 전체 업로드 용량이 함께 증가하므로 자가 확장성을 갖는다.
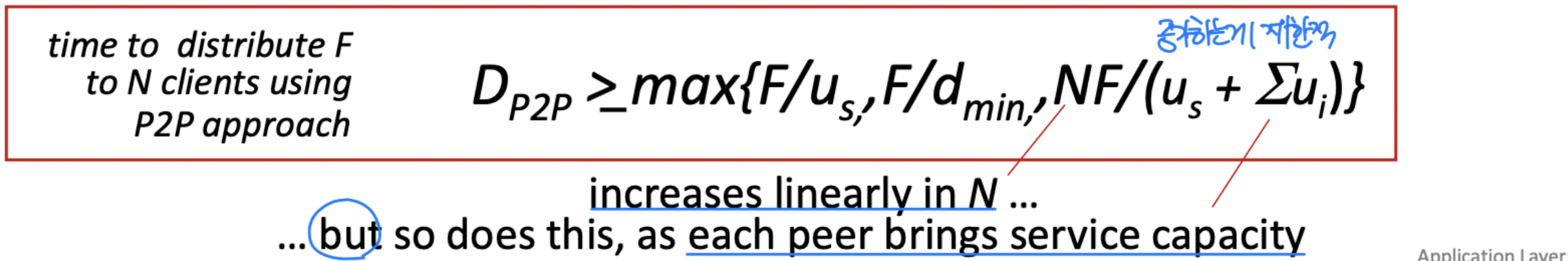
BitTorrent
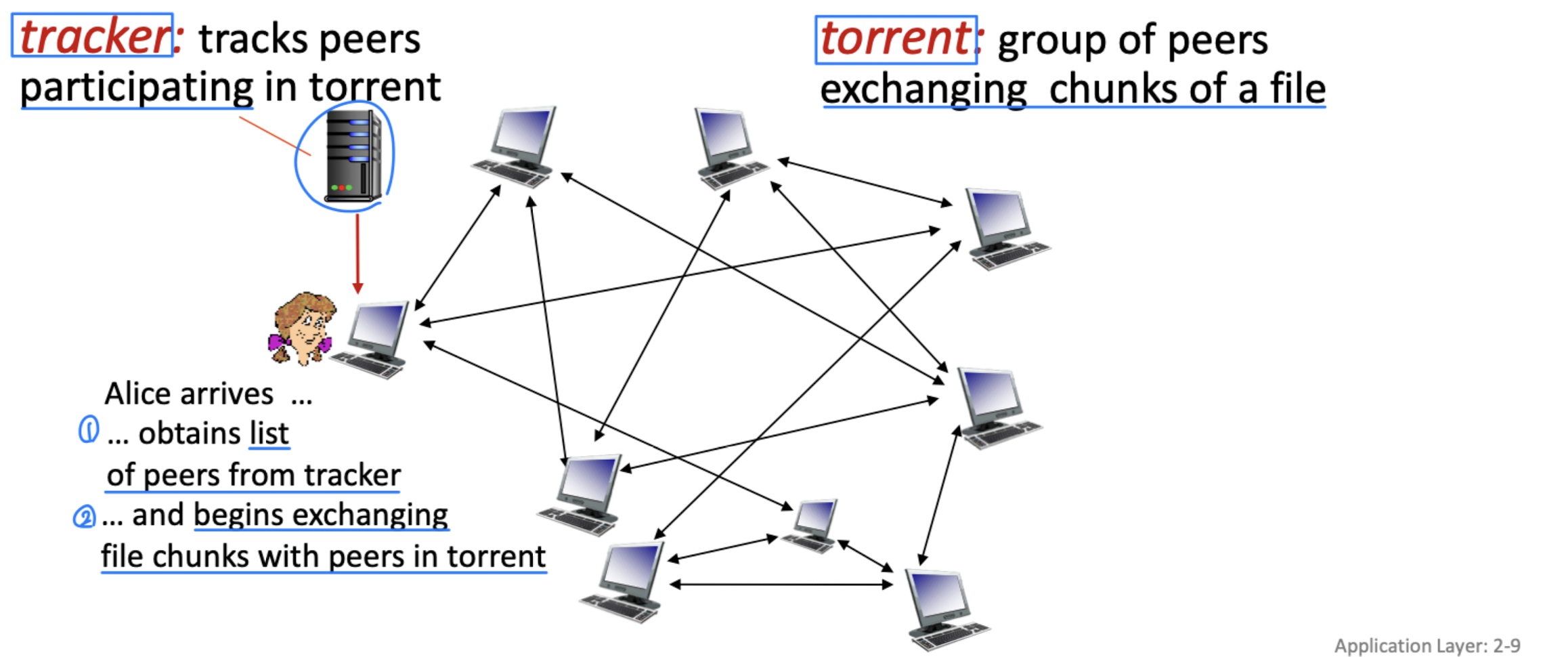
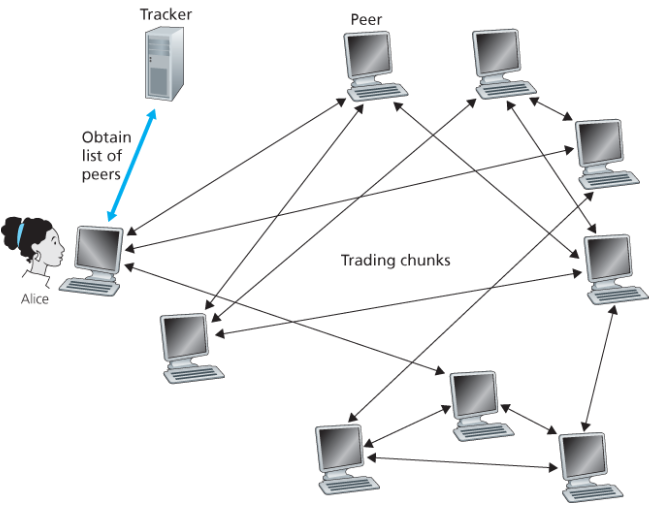
BitTorrent에서 파일은 보통 256kB 크기의 chunk로 분할된다. torrent 안의 peer들이 파일 chunk를 송수신한다.
Peer가 torrent에 참여하면:
- tracker에 자신을 등록하고 peer 목록(임의의 50개 피어의 IP 주소)을 받는다.
- 주기적으로 tracker에 아직 torrent에 있음을 알린다.
- 목록에서 일부 peer("이웃")에 TCP 연결을 맺는다.
- 처음에는 chunk가 없지만, 시간이 지나면서 다른 peer로부터 chunk를 축적한다.
다운로드하는 동안 동시에 다른 peer에게 chunk를 업로드한다. Peer는 chunk를 교환하는 상대를 바꿀 수 있다. Churn이 발생하며 peer들이 수시로 들어오고 나간다.
파일 전체를 받은 peer는 이기적(selfishly)으로 떠나거나, 이타적(altruistically)으로 torrent에 남을 수 있다.
Chunk 요청: Rarest First
- 각 시점에서 서로 다른 peer가 서로 다른 chunk 부분집합을 가진다.
- 주기적으로 각 peer에게 가진 chunk 목록을 요청한다.
- 누락된 chunk 중 이웃 가운데 가장 드문 청크를 결정하고 이를 먼저 요구한다.
- 이를 통해 가장 드문 청크들이 더 빨리 재분배되어, 각 청크의 복사본 수가 대략 동일해질 수 있다.
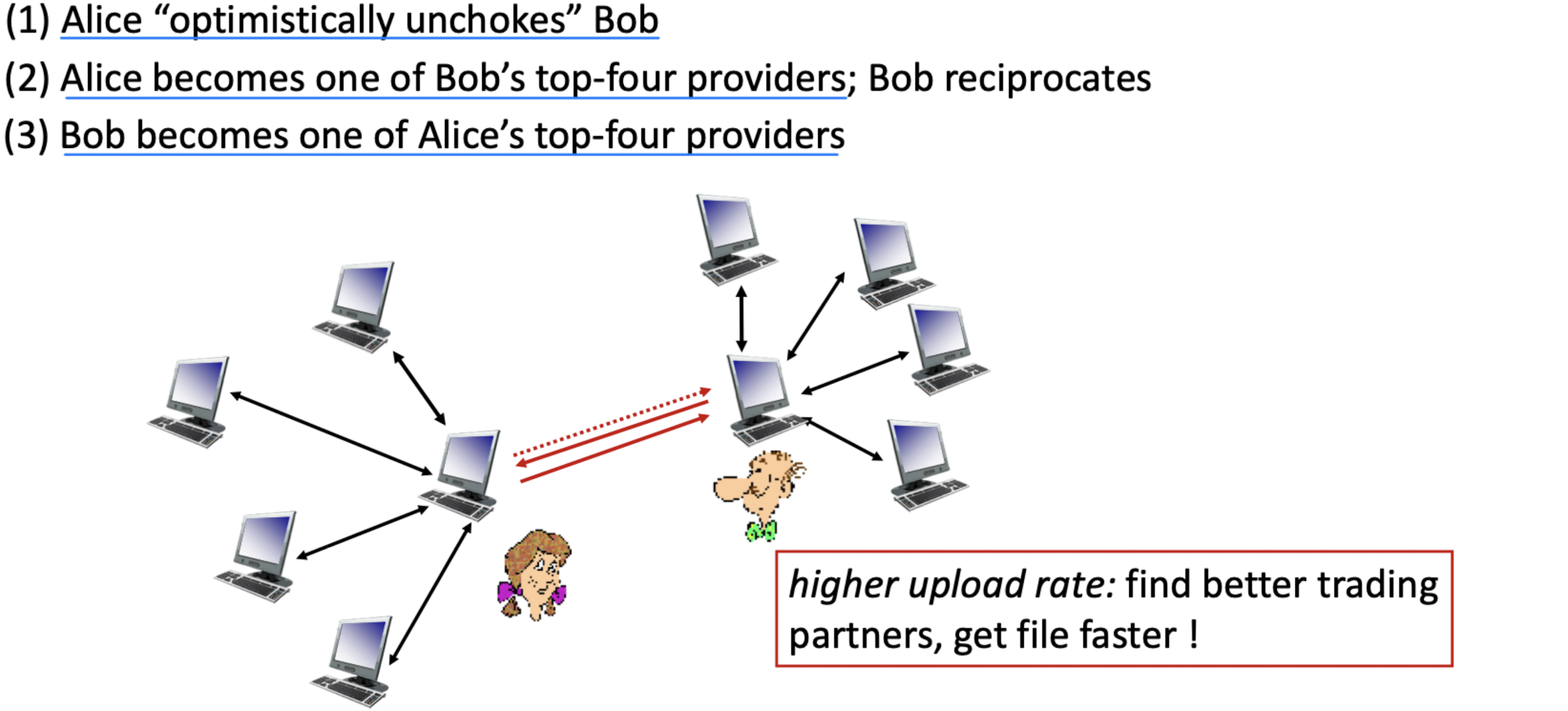
Chunk 전송: Tit-for-Tat
- 자신에게 가장 빠른 속도로 chunk를 보내는 4개의 이웃에게 chunk를 전송한다 (unchoked).
- 나머지 peer들은 choke(차단)되어 chunk를 받지 못한다.
- 매 10초마다 상위 4를 재평가한다.
- 매 30초(40초)마다 무작위로 다른 peer를 선택하여 chunk를 보낸다.
- "optimistically unchoke"라 한다.
- 새로 선택된 peer가 상위 4에 진입할 수도 있다.
- 이를 통해 고정된 피어들과만 교역하지 않고, free riding을 방지한다.
DHT (Distributed Hash Table)
DHT는 P2P 분야에서 중요한 주제이다. 분산 P2P 데이터베이스로서, 미리 정의된 규칙에 따라 노드(peer) 집합에 데이터를 분배한다. 대표적인 예로 Chord 알고리즘이 있다.
2.6 비디오 스트리밍과 CDN
스트리밍 비디오 트래픽은 인터넷 대역폭의 주요 소비자이다. Netflix, YouTube, Amazon Prime이 가정용 ISP 트래픽의 약 **80%**를 차지한다(2020년 기준).
두 가지 과제:
- 과제 1 - 규모: 약 10억 명의 사용자에게 어떻게 도달할 것인가? 단일 대형 비디오 서버로는 불가능하다.
- 과제 2 - 다양성(heterogeneity): 사용자마다 환경이 다르다 (유선 vs 모바일, 높은 대역폭 vs 낮은 대역폭).
- 해결: 분산(과제1), 애플리케이션 수준(과제2) 인프라
멀티미디어: 비디오
비디오는 일정 속도로 표시되는 이미지 시퀀스이다. 일반적으로 초당 24~30개의 이미지를 사용한다.
디지털 이미지는 픽셀 배열이며, 각 픽셀은 휘도와 색상을 나타내는 비트로 표현된다. 인코딩은 이미지 내부 및 이미지 간의 중복(redundancy)을 활용하여 비트 수를 줄인다.
- Spatial coding: 한 이미지 내부의 중복 활용
- Temporal coding: 연속된 이미지 간의 중복 활용
- 비디오 품질과 비트 레이트 간 trade-off 존재 (비트 전송률이 높을수록 품질이 좋다)

인코딩 방식:
- CBR(Constant Bit Rate): 고정된 인코딩 속도
- VBR(Variable Bit Rate): spatial/temporal 코딩 양에 따라 인코딩 속도가 변함. 성능은 좋지만 네트워크 상황에 영향을 받는다.
주요 표준:
- MPEG 1 (CD-ROM): 1.5 Mbps
- MPEG 2 (DVD): 3-6 Mbps
- MPEG 4 (인터넷): 64Kbps ~ 12 Mbps
같은 비디오의 여러 버전을 다른 품질 수준으로 만들 수 있다. 사용자는 현재 가용 대역폭에 따라 어떤 버전을 볼지 선택할 수 있다.
저장된 비디오 스트리밍
주요 과제:
- 서버-클라이언트 간 대역폭이 시간에 따라 변한다. 네트워크 혼잡 수준이 지속적으로 바뀌기 때문이다.
- 혼잡으로 인한 패킷 손실과 지연이 재생을 지연시키거나 비디오 품질을 저하시킨다.
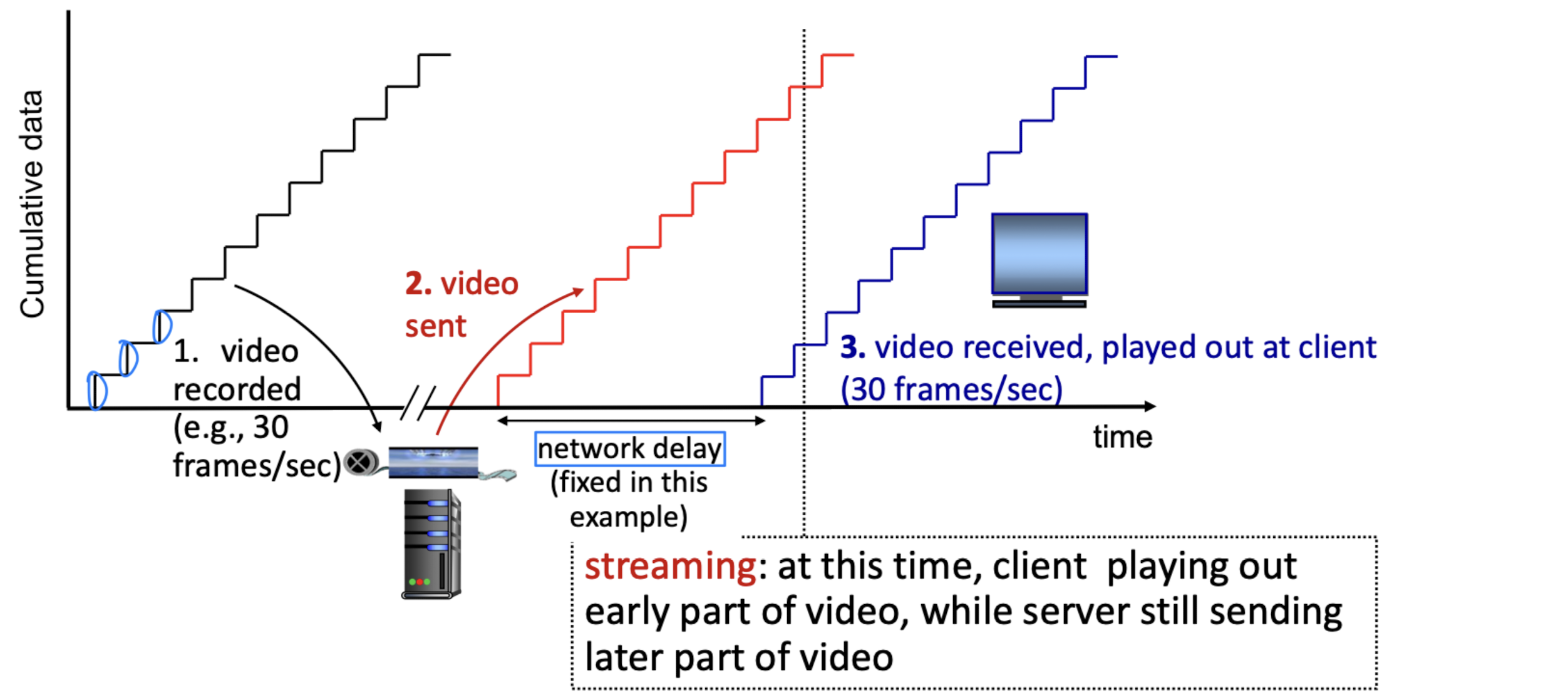
스트리밍 과제
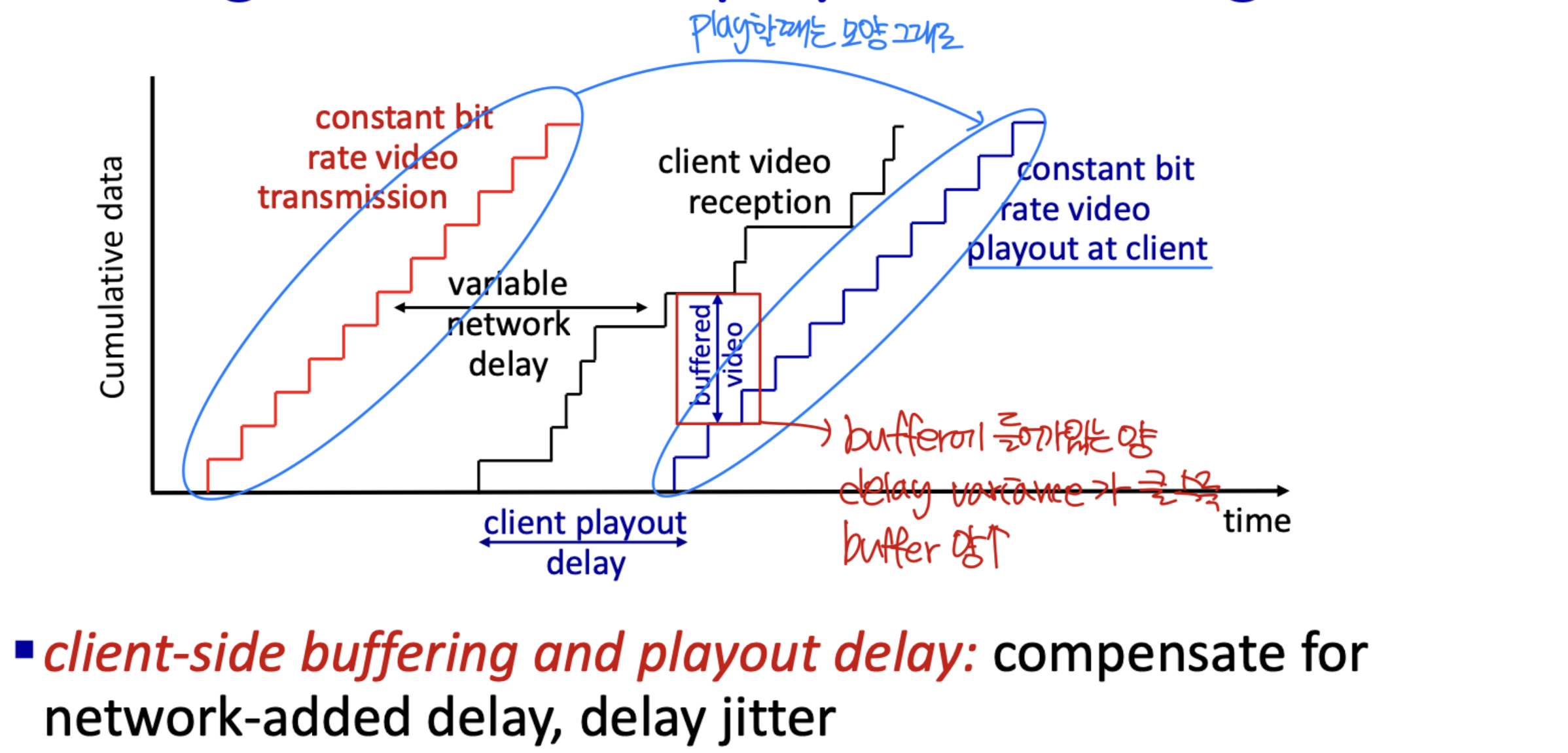
Continuous playout constraint: 클라이언트에서 비디오를 재생할 때, 재생 타이밍이 원래 타이밍과 일치해야 한다. 그러나 네트워크 지연이 가변적(jitter)이므로, 이를 맞추기 위해 client-side buffer가 필요하다.
기타 과제:
- 클라이언트 상호작용: 일시정지, 빨리감기, 되감기, 점프
- 비디오 패킷 손실 및 재전송
Playout Buffering
HTTP를 통한 스트리밍

HTTP 스트리밍은 TCP를 기반으로 한다.
- 클라이언트가 서버에 TCP 연결을 설립하고 해당 URL에 대한 HTTP GET 요청을 발생시킨다.
- 서버가 HTTP 응답 메시지 내에서 비디오 파일을 전송한다.
- 애플리케이션 버퍼에 바이트가 저장된다.
- 버퍼의 바이트 수가 임계값을 초과하면 재생을 시작한다.
문제는 가용 대역폭이 달라도 똑같이 인코딩된 비디오를 전송 받는다는 점이다. 이 문제를 해결하기 위해 HTTP 기반 스트리밍인 DASH가 개발되었다.
DASH (Dynamic, Adaptive Streaming over HTTP)
Server 측:
- 비디오 파일을 여러 chunk로 분할
- 각 chunk를 다른 비트레이트로 인코딩하여 저장. 다른 비트레이트의 인코딩은 별도 파일에 저장되고, 각 버전은 서로 다른 URL을 갖는다. 파일은 다양한 CDN 노드에 복제된다.
- Manifest file: 다양한 chunk의 URL을 제공. MPEG-DASH에서는 MPD(Media Presentation Description)라고 한다.
Client 측:
- 먼저 manifest file을 요청한다.
- 주기적으로 서버-클라이언트 간 대역폭을 측정한다.
- Manifest를 참고하여 한 번에 하나의 chunk를 요청한다.
- 현재 대역폭에서 지속 가능한 최대 인코딩 속도를 선택
- 시간에 따라 다른 인코딩 속도를 선택할 수 있다 (가용 대역폭에 따라)
- HTTP GET 요청에 URL과 byte-range를 지정하여 요청한다.
"Intelligence at client": 클라이언트가 결정하는 것들 (서버 부담을 분산)
- when: chunk를 언제 요청할지 (buffer starvation이나 overflow 방지)
- what encoding rate: 어떤 인코딩 속도로 요청할지 (대역폭이 많으면 높은 품질)
- where: 어디서 chunk를 요청할지 (가깝거나 대역폭이 높은 URL 서버 선택)
Streaming video = encoding + DASH + playout buffering
CDN (Content Distribution Network)
과제: 수백만 개의 비디오 중에서 선택된 콘텐츠를 수억 명의 동시 사용자에게 어떻게 스트리밍할 것인가?
Option 1: 단일 대규모 데이터 센터
- 먼 클라이언트까지의 긴 경로(혼잡, 병목 가능)
- 인기 있는 비디오가 같은 통신 링크를 통해 여러 번 전송됨 (반복 비용)
- 단일 장애점(single point of failure)
- 결론: 확장 불가능(doesn't scale)
Option 2: CDN - 여러 지리적으로 분산된 사이트에 비디오 사본을 저장/제공
CDN의 유형:
- Private CDN: 콘텐츠 제공자 자체가 소유. 예: Google CDN, Netflix
- Third-party CDN: 여러 콘텐츠 제공자를 대신하여 배포. 예: Akamai, Limelight
CDN의 서버 배치 전략
Enter deep 전략:
- CDN 서버를 많은 access network 깊숙이 배치한다.
- 전 세계 access ISP에 서버 클러스터를 배포하여 사용자에게 가깝게 위치시킨다.
- end user와 CDN 서버 사이의 링크와 라우터 수를 줄여 사용자가 체감하는 지연과 throughput을 개선한다.
- Akamai: 120개국 이상에 240,000개 서버 배포 (2015). 서버 수가 매우 많아야 한다.
Bring home 전략:
- Access ISP 내부까지 들어가는 대신, IXP(Internet Exchange Point)에 클러스터를 배치한다.
- 유지보수 및 관리 오버헤드가 적어 비용이 저렴하다.
- Enter Deep보다 throughput은 더 낮고 delay가 더 걸릴 수 있다.
- Limelight 등 많은 CDN이 이 전략을 사용한다.
CDN은 모든 복사본을 유지하지는 않는다. 사용자 요청 시 중앙 서버에서 전송받아 서비스하면서 복사본을 만드는 pull 방식을 이용하며, 저장 공간이 가득 차면 자주 사용되지 않는 데이터를 삭제한다.
CDN Operation
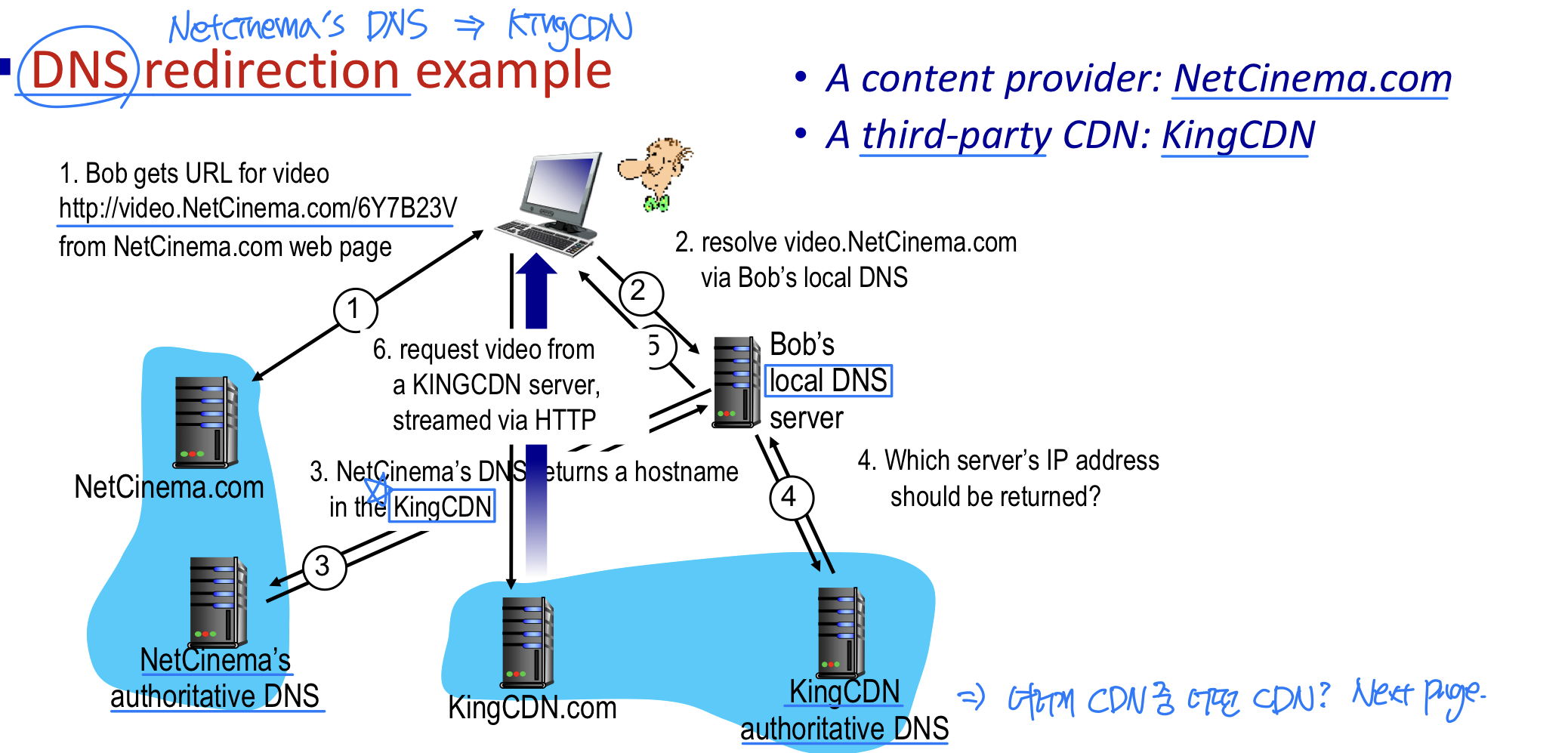
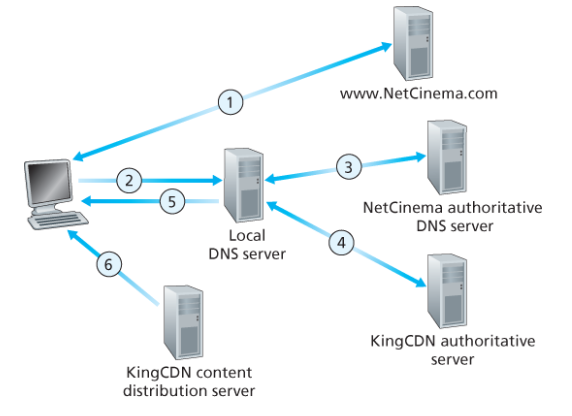
CDN은 DNS를 활용하여 요청을 가로챈다 (DNS redirection).
- 사용자가 URL을 입력한다.
- 사용자의 호스트가 URL의 호스트 이름에 대한 DNS 질의를 로컬 DNS로 보낸다.
- 로컬 DNS가 책임 DNS 서버로 질의를 전달한다. 책임 DNS 서버는 CDN 서버의 책임 DNS 서버 IP를 전달한다.
- 로컬 DNS가 CDN 책임 DNS로 질의를 보내고, CDN 콘텐츠 서버의 IP 주소를 응답받는다. 이때 클라이언트가 연결될 서버가 결정된다.
- 로컬 DNS가 사용자 호스트에게 CDN 서버의 IP 주소를 알려준다.
- 클라이언트가 해당 IP 주소로 HTTP 또는 DASH를 통해 비디오를 받아온다.
Cluster 선택 전략 (두 전략 모두 이슈가 있다):
전략 1: 지리적 거리 기반(Geographically Closest)
- LDNS(Local DNS)에서 지리적으로 가장 가까운 클러스터를 선택한다.
- 문제점:
- 사용자가 원격지의 LDNS를 사용할 수 있다.
- 인터넷 경로의 지연과 가용 대역폭 변동을 무시하고 항상 같은 클러스터를 할당한다.
- 지리적으로 가까운 클러스터가 네트워크 경로상 가장 가까운 클러스터가 아닐 수 있다.
전략 2: 주기적 실시간 측정 기반(Real-time Measurements)
- 클러스터와 LDNS 간의 지연과 손실 성능을 주기적으로 실시간 측정한다.
- RTT가 가장 낮은 클러스터를 선택하되, load balance도 고려한다.
- 문제: 많은 로컬 DNS 서버가 측정에 응답하지 않도록 설정되어 있다.
Case Study: Netflix
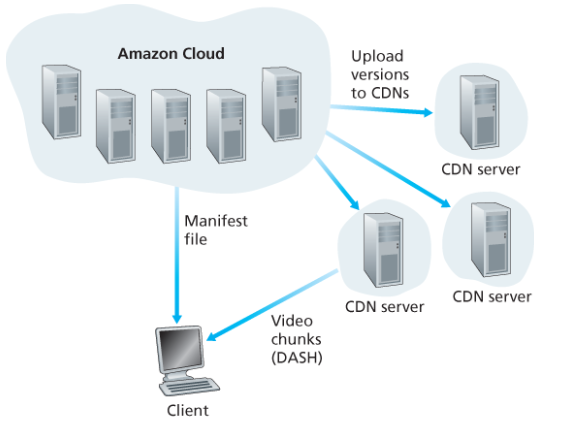
Netflix는 Amazon 클라우드와 자체 private CDN을 함께 사용한다.
Amazon 클라우드의 역할:
- 사용자 등록, 로그인, 결제
- 영화 카탈로그 검색, 영화 추천 시스템
- 다양한 클라이언트 비디오 플레이어에 맞게 영화를 여러 포맷으로 처리 (DASH를 이용하여 각 형식별로 다양한 비트율의 버전을 생성)
- 처리된 버전을 CDN에 업로드
자체 Private CDN:
- 비디오만 배포한다.
- IXP 및 거주용 ISP 자체에 서버 랙(rack)을 설치. 200개 이상의 IXP 위치와 수백 개의 ISP 장소를 보유한다.
- 각 랙 서버에는 10 Gbps 이더넷 포트와 100 테라바이트 이상의 스토리지가 있다.
넷플릭스의 특징:
- 푸시 캐싱(push caching) 방식으로 CDN 서버를 채운다. 캐시 미스 중 동적으로 사용되는 pull 방식이 아니라, 사용량이 적은 시간에 예약된 시간에 푸시한다. 전체 라이브러리를 보유할 수 없는 위치에는 매일 가장 인기 있는 비디오만 푸시한다.
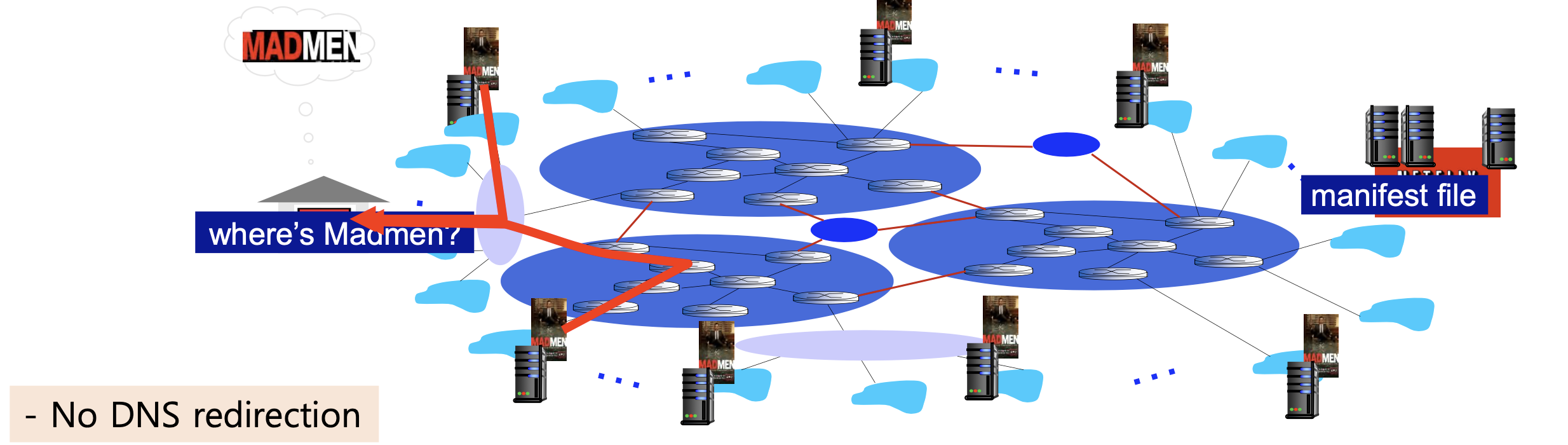
- DNS redirection을 사용하지 않는다. 자체 CDN이므로, Amazon 클라우드의 넷플릭스 소프트웨어가 직접 클라이언트에게 특정 CDN 서버를 사용하도록 알려준다.
동작 과정:
- 사용자가 재생할 영화를 선택한다.
- Amazon 클라우드의 넷플릭스 소프트웨어가 영화 사본을 가진 CDN 서버를 결정한다.
- 최적의 서버를 결정한다 (로컬 ISP의 CDN 랙 또는 근처 IXP).
- 클라이언트에게 manifest 파일과 서버 IP 주소를 보낸다.
- 클라이언트가 독점 버전의 DASH를 이용하여 CDN 서버와 직접 상호작용한다.
2.7 소켓 프로그래밍
네트워크 애플리케이션을 생성할 때는 클라이언트와 서버 프로그램 두 개를 작성해야 한다. 두 프로그램을 실행하면 프로세스가 생성되고, 두 프로세스가 소켓으로부터 읽고 쓰기를 통해 서로 통신한다.
클라이언트-서버 애플리케이션에는 두 가지 형태가 있다.
- HTTP 등 RFC에 정의된 표준 프로토콜을 구현하는 애플리케이션 (해당 프로토콜의 well-known port를 사용)
- 독점적인 프로토콜을 채택한 애플리케이션 (well-known 포트 번호 사용을 피해야 한다)
UDP 소켓 프로그래밍
UDP를 사용할 때에는 송신 프로세스가 패킷에 목적지 주소(IP 주소 + 포트 번호)를 붙여야 한다. 출발지 주소(IP, port)는 하부 운영체제가 자동으로 붙인다.
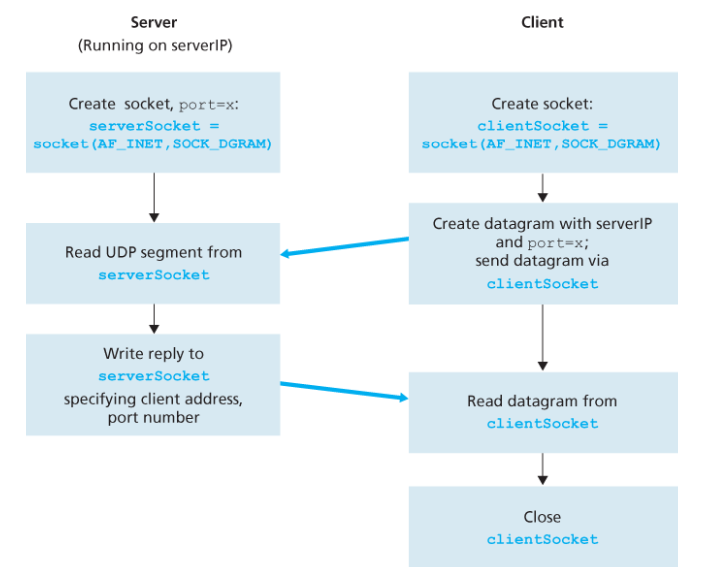
UDPClient.py:
from socket import *
serverName = 'hostname'
serverPort = 12000
# AF_INET: IPv4, SOCK_DGRAM: UDP 소켓
clientSocket = socket(AF_INET, SOCK_DGRAM)
message = input('Input lowercase sentence:')
# 목적지 주소를 붙이고 패킷을 전송
clientSocket.sendto(message.encode(), (serverName, serverPort))
# 서버로부터 응답 수신 (2048 byte 버퍼)
modifiedMessage, serverAddress = clientSocket.recvfrom(2048)
print(modifiedMessage.decode())
clientSocket.close()UDPServer.py:
from socket import *
serverPort = 12000
serverSocket = socket(AF_INET, SOCK_DGRAM)
# 12000 포트를 소켓에 바인딩
serverSocket.bind(('', serverPort))
print("The server is ready to receive")
while True:
message, clientAddress = serverSocket.recvfrom(2048)
modifiedMessage = message.decode().upper()
serverSocket.sendto(modifiedMessage.encode(), clientAddress)TCP 소켓 프로그래밍
TCP는 연결 지향 프로토콜로, 데이터를 보내기 전에 TCP 연결을 설정해야 한다.
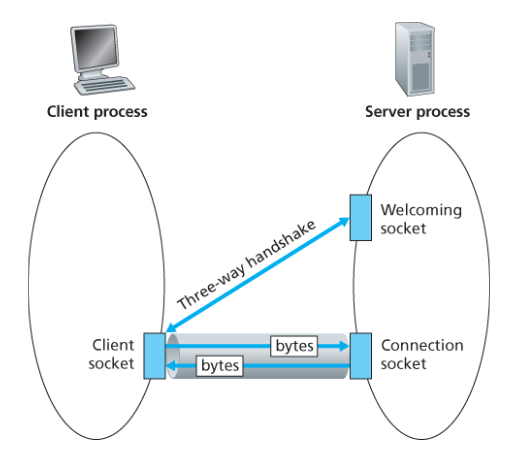
서버 프로세스가 실행되면, 클라이언트가 서버의 환영 소켓(welcome socket)에 TCP 연결을 시도한다. 핸드셰이킹이 완료되면 서버는 해당 클라이언트에게 지정되는 연결 소켓(connection socket)을 생성한다. 클라이언트의 소켓과 서버의 연결 소켓은 마치 파이프처럼 직접 연결된다.
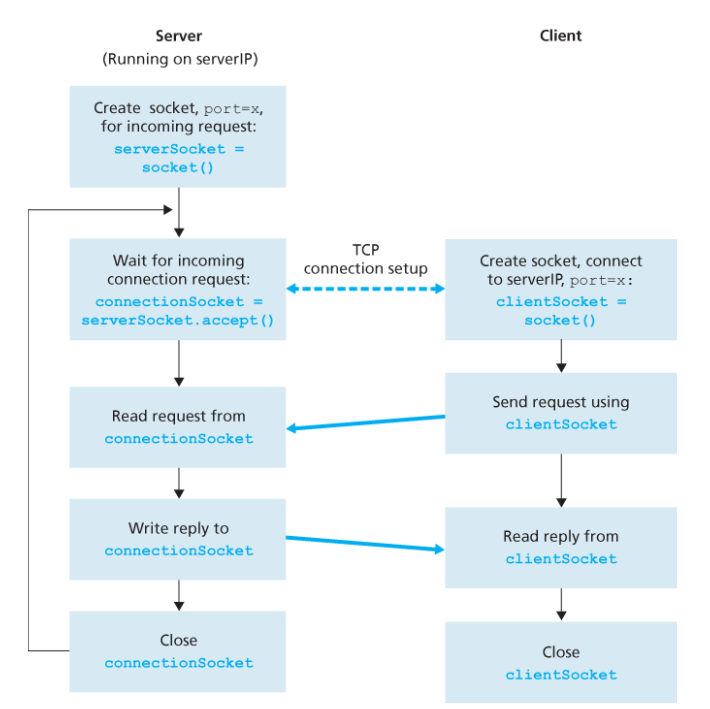
TCPClient.py:
from socket import *
serverName = 'servername'
serverPort = 12000
# SOCK_STREAM: TCP 소켓
clientSocket = socket(AF_INET, SOCK_STREAM)
# TCP 연결 설정 (3-way handshake)
clientSocket.connect((serverName, serverPort))
sentence = input('Input lowercase sentence:')
# 목적지 주소 불필요 - TCP 연결이 이미 설정되어 있음
clientSocket.send(sentence.encode())
modifiedSentence = clientSocket.recv(1024)
print('From Server: ', modifiedSentence.decode())
# 연결 종료
clientSocket.close()TCPServer.py:
from socket import *
serverPort = 12000
serverSocket = socket(AF_INET, SOCK_STREAM)
serverSocket.bind(('', serverPort))
# 연결 대기 (큐잉되는 연결의 최대 수: 1)
serverSocket.listen(1)
print('The server is ready to receive')
while True:
# 클라이언트를 위한 연결 소켓 생성
connectionSocket, addr = serverSocket.accept()
sentence = connectionSocket.recv(1024).decode()
capitalizedSentence = sentence.upper()
connectionSocket.send(capitalizedSentence.encode())
# 연결 소켓 종료 (환영 소켓은 유지)
connectionSocket.close()UDP와 TCP 소켓 프로그래밍의 핵심 차이: TCP는 연결 설정(connect, accept) 후 send/recv로 통신하며 목적지 주소를 명시하지 않는다. UDP는 매번 sendto/recvfrom으로 목적지 주소를 명시해야 한다.
참고: Computer Networking: A Top-Down Approach - IT-Book-Organization