5.1 개요
포워딩 테이블(목적지 기반 포워딩의 경우)과 플로우 테이블(일반화된 포워딩의 경우)이 네트워크 계층의 데이터 평면과 제어 평면을 연결하는 수요 요소였는데,
이 테이블들이 라우터의 로컬 데이터 평면에서의 포워딩을 지정했다.
바로 이전 장에서의 그림을 상기해보자.
일반화된 포워딩의 경우에 라우터가 취하는 행동은 다양한 형태로 나타날 수 있었다.
- 라우터의 출력 포트로 패킷을 전달
- 패킷을 버리거나 복제
- 2, 3, 4계층의 헤더 필드를 재작성
이 장에서는 포워딩 테이블이나 플로우 테이블이 어떻게 만들어지고 유지 및 설치되는지를 알아볼 것이다.
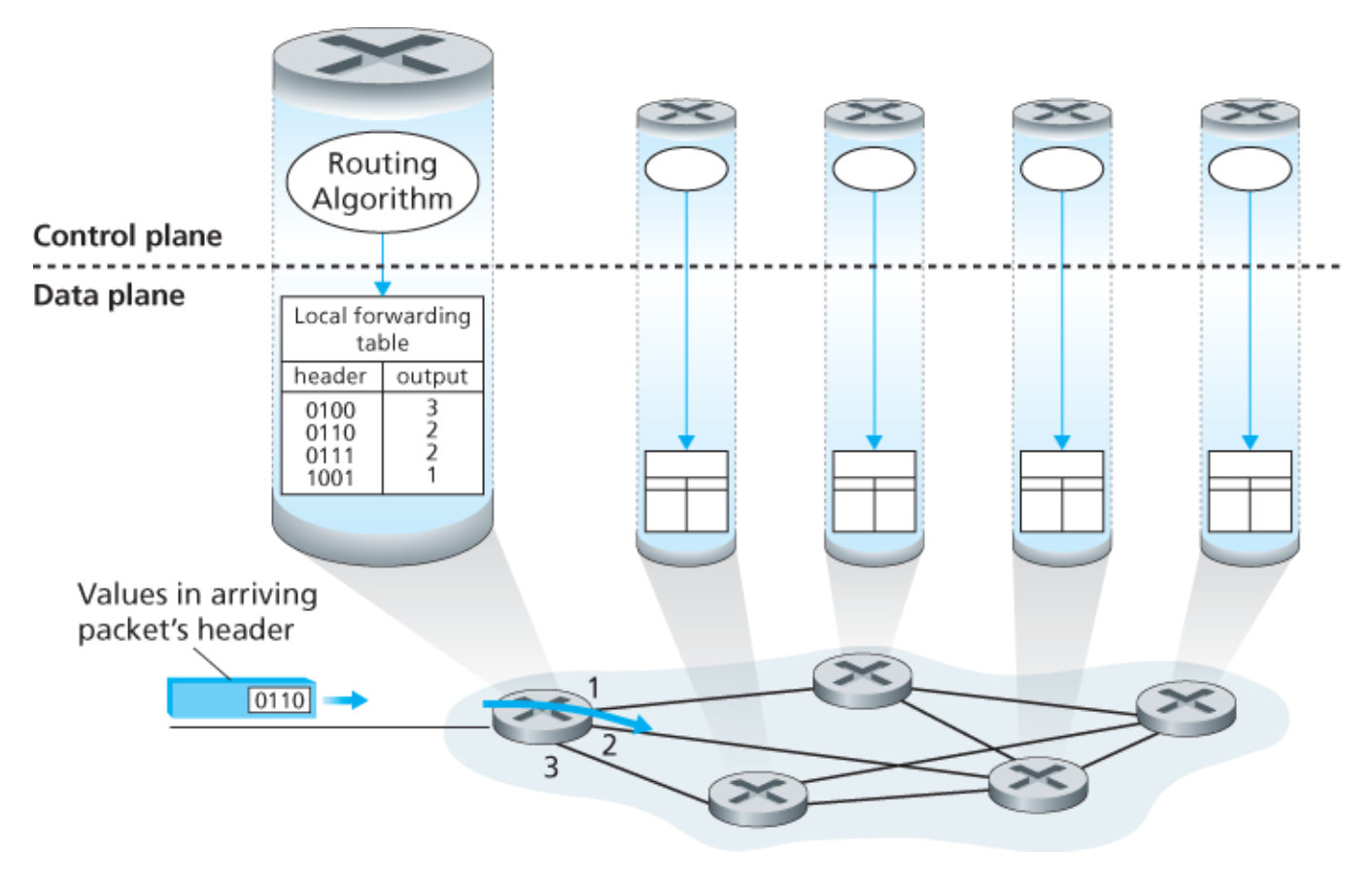
라우터별 제어
💡 개별 라우팅 알고리즘들이 제어 평면에서 상호작용한다.
아래 그림은 라우팅 알고리즘들이 모든 라우터 각각에서 동작하는 경우를 나타낸다.
- 포워팅과 라우팅 기능이 모두 개별 라우터에 포함되어 있다.
- 각 라우터는 다른 라우터의 라우팅 구성요소와 통신하여 자신의 포워딩 테이블의값을 계산하는 라우팅 구성요소를 갖고 있다.
OSPF,BGP프로토콜이 이 라우터별 제어 방식을 기반으로 한다.
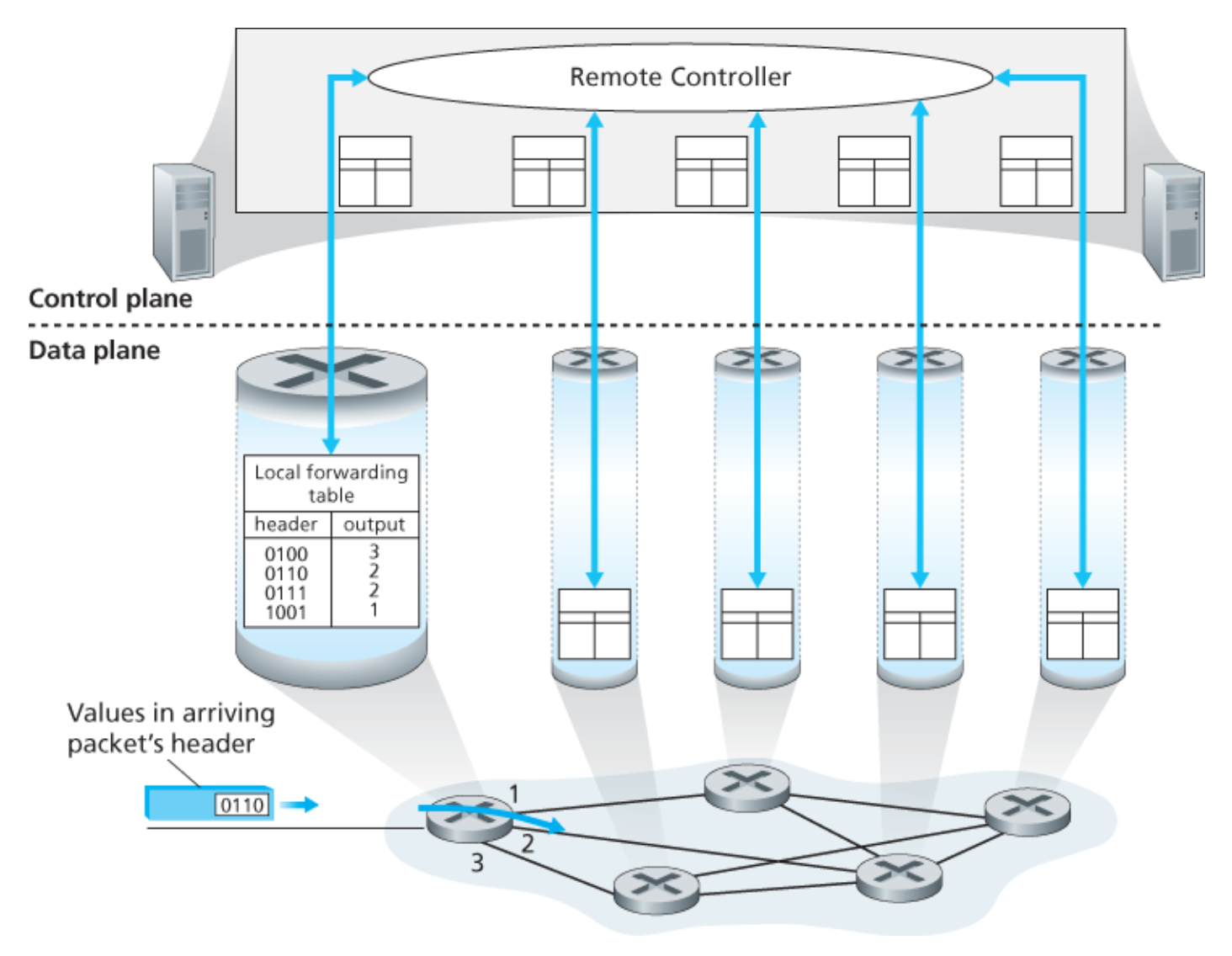
논리적 중앙 집중형 제어
💡 일반적으로 원격에 위치한 별개의 컨트롤러가 지역의 제어 에이전트(CA)와 상호작용한다.
아래 그림은 논리적 중앙 집중형 컨트롤러가 포워딩 테이블을 작성하고, 이를 모든 개별 라우터가 사용할 수 있도록 배포한 경우를 나타낸다.
일반화된 ‘매치 플러스 액션(match plus action)’ 추상화를 통해
라우터는 기존에는 별도로 장치로 구현되었던 다양한 기능(부하 분산, 방화벽, NAT) 뿐만 아니라 전통적인 IP 포워딩을 수행할 수 있다.
컨트롤러는 프로토콜을 통해 각 라우터의 제어 에이전트(control agent, CA)와 상호작용하여 라우터의 플로우 테이블을 구성 및 관리한다.
라우터별 제어 방식과는 다르게, CA는 서로 직접 상호작용하지 않으며, 포워딩 테이블을 계산하는 데도 적극적으로 참여하지 않는다.
5.2 라우팅 알고리즘
💡
라우팅 알고리즘(routing algorithm)의 목표 : 송신자부터 수신자까지 라우터의 네트워크를 통과하는 좋은 경로(루트)를 결정하는 것
일반적으로 ‘좋은’ 경로란 최소 비용 경로(least-cost path)를 말한다.
그러나 현실적으로는 네트워크 정책과 같은 실제 문제가 고려된다.
(e.g., Y 기관에 속해 있는 라우터 x는 Z 기관이 소유한 네트워크가 보낸 패킷을 전달해서는 안 됨)
그래프
라우팅 문제를 나타내는 데는 그래프가 사용된다.
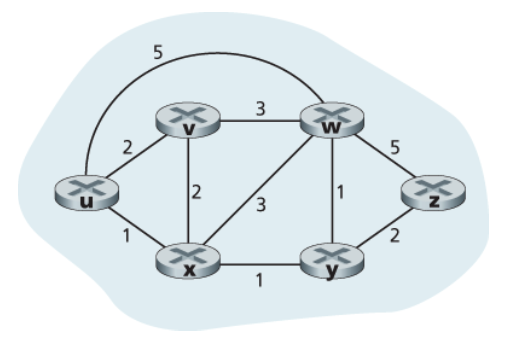
그래프(graph), G(N, E)
-
N- 노드(node)의 집합
- 네트워크 계층 라우팅 상황에서 그래프상의
노드는 패킷 전달 결정이 이루어지는 지점인 라우터를 나타낸다.
-
E- 에지(edge)의 집합
- 네트워크 계층 라우팅 상황에서 그래프상의
에지는 라우터들 간의 물리 링크를 나타낸다. - 에지는 그 비용을 나타내는 값을 가진다.
(일반적으로 해당 링크의 물리적인 거리, 링크 속도, 링크와 관련된 금전 비용 등을 반영) - 집합 E에 포함된 어떤 에지 (x, y)에 대해
c(x, y)는 노드 x와 y 간의 비용을 의미한다. - 에지 (x, y)가 집합 E에 속하면, 노드 y는 노드 x의 이웃(neighbor)이라고 한다.
-
하나의 에지는 집합 N에 속하는 한 쌍의 노드로 표시된다.
그래프 G(N, E)에서의 경로(path)는 노드의 연속(x1, x2, x3, …, xp)이고,
노드 쌍 (x1, x2), (x2, x3), … , (xp-1, xp)는 집합 E에 속한 에지들이다.
경로 (x1, x2, x3, … , xp)의 비용은 경로상 모든 에지 비용의 단순 합이다.
c(x1, x2) + c(x2, x3) + … + c(xp-1, xp)
라우팅 알고리즘의 분류
라우팅 알고리즘을 분류하는 일반적인 방법 한 가지는 알고리즘이 중앙 집중형인지 분산형인지다.
중앙 집중형 라우팅 알고리즘(centralized routing algorithm)
💡 네트워크 전체에 대한 완전한 정보를 가지고 출발지와 목적지 사이의 최소 비용 경로를 계산한다.
계산 자체는 한 장소에서 수행되거나 모든 라우터 각각의 라우팅 모듈로 복사될 수 있다.
전체 상태 정보를 갖는 알고리즘을 링크 상태(link-state, LS) 알고리즘이라고 하는데,
이는 이 알고리즘이 네트워크 내 각 링크의 비용을 알고 있어야 하기 때문이다.
분산 라우팅 알고리즘(decentralized routing algorithm)
최소 비용 경로의 계산이 라우터들에 의해 반복적이고 분산된 방식으로 수행된다.
💡 각 노드는 자신에게 직접 연결된 링크에 대한 비용 정보만을 가지고 시작한다.
이후 반복된 계산과 이웃 노드와의 정보 교환을 통해 노드는 점차적으로 목적지 또는 목적지 집합까지의 최소 비용 경로를 계산한다.
분산 라우팅 알고리즘은 거리 벡터(distance-vector, DV) 알고리즘이라고도 하는데,
이는 각 노트가 네트워크 내 다른 모든 노드까지 비용(거리)의 추정값을 벡터 형태로 유지하기 때문이다.
라우팅 알고리즘을 분류하는 일반적인 두 번째 방식은 정적 알고리즘과 동적 알고리즘으로 분류하는 것이다.
정적 라우팅 알고리즘(static routing algorithm)
사람이 직접 링크 비용을 수정하는 경우와 같은 종종 사람이 개입하는 상황 때문에 정적 라우팅 알고리즘에서 경로는 아주 느리게 변한다.
동적 라우팅 알고리즘(dynamic routing algorithm)
네트워크 트래픽 부하(load)나 토폴로지 변화에 따라 라우팅 경로를 바꾼다.
동적 알고리즘은 주기적으로, 혹은 토폴로지나 링크 비용의 변경에 직접적으로 응답하는 방식으로 수행된다.
- 장점 : 네트워크 변화에 빠르게 대응한다.
- 단점 : 경로의 루프(loop)나 경로 진동(oscillation) 같은 문제에 취약하다.
[참고] 토폴로지(topology, 망구성방식) : 컴퓨터 네트워크의 요소들(링크, 노드 등)을 물리적으로 연결해 놓은 것, 또는 그 연결 방식
라우팅 알고리즘을 분류하는 세 번재 방식은 라우팅 알고리즘이 부하에 민감한지 아닌지에 따른다.
부하에 민감한 알고리즘(load-sensitive algorithm)
링크 비용은 해당 링크의 현재 혼잡 수준을 나타내기 위해 동적으로 변한다.
현재 혼잡한 링크에 높은 비용을 부과한다면, 라우팅 알고리즘은 혼잡한 링크를 우회하는 경로를 택하는 경향을 보일 것이다.
초기 ARPAnet 라우팅 알고리즘이 부하에 민감해서 많은 어려움이 있었다.
부하에 민감하지 않은 알고리즘(load-insensitive algorithm)
오늘날 인터넷 라우팅 알고리즘(RIP, OSPF, BGP 등)은 링크 비용이 현재(또는 가장 최근)의 혼잡을 반영하지 않기 때문에 부하에 민감하지 않다.
5.2.1 링크 상태(LS) 라우팅 알고리즘
링크 상태 알고리즘에서는 네트워크 토폴로지와 모든 링크 비용이 알려져 있어서 링크 상태 알고리즘의 입력값으로 사용될 수 있다.
이것은 각 노드가 자신과 직접 연결된 링크의 식별자와 비용 정보를 담은 링크 상태 패킷을
네트워크상의 다른 모든 노드로 브로드캐스트하게 함으로써 가능하며,
이는 종종 인터넷 OSPF 라우팅 프로토콜 같은 링크 상태 브로드캐스트(link-state broadcast) 알고리즘에 의해 수행된다.
다익스트라 알고리즘(Dijkstra’s algorithm)
💡 다익스트라 알고리즘은 하나의 노드(출발지,
u라고 지칭)에서 네트워크 내 다른 모든 노드로의 최소 비용 경로를 계산한다.
알고리즘의 k번째 반복 이후에는 k개의 목적지 노드에 대해 최소 비용 경로가 알려지며,
이들은 모든 목적지 노드로의 최소 비용 경로 중에서 가장 낮은 비용을 갖는 k개의 경로다.
기호 정의
D(v): 알고리즘의 현재 반복 시점에서 출발지 노드부터목적지 v까지의 최소 비용 경로의 비용p(v): 출발지에서 v까지의 현재 최소 비용 경로에서 v의 직전 노드N’: 노드의 집합
출발지에서 v까지의 최소 비용 경로가 명확히 알려져 있다면, v는 N’에 포함된다.
출발지 노드 u를 위한 링크 상태(LS) 알고리즘
중앙 집중형 라우팅 알고리즘은 2단계로 구성된다.
- 초기화 단계(Initialization)
- 반복 부분(Loop) : 수행 횟수는 네트워크의 노드 수와 같다.

아래 그래프의 네트워크에서 링크 상태 알고리즘을 수행한 결과는 다음과 같다.
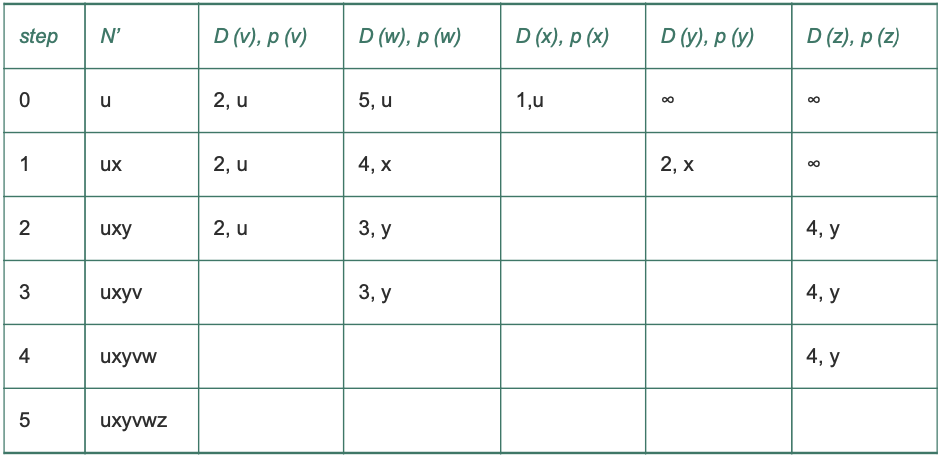
포워딩 테이블
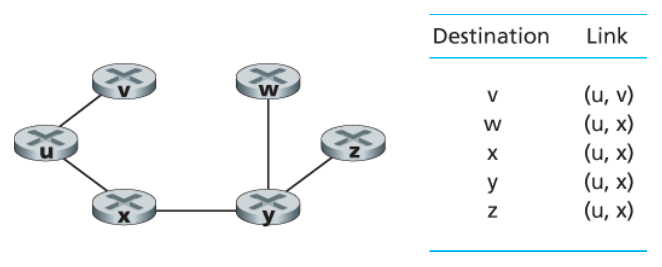
링크 상태 알고리즘이 종료된 후에 우리는 각 노드에 대해 출발지 노드로부터의 최소 비용 경로상의 직전 노드를 알게 된다.
노드 u의 포워딩 테이블은 각 목적지에 대해 / 노드 u에서 그 목적지까지의 최소 비용 경로상의 다음 홉 노드 정보를 저장하여 구성한다.
아래 그림은 최소 비용 경로의 결과와 노드 u의 포워딩 테이블을 보여준다.
계산 복잡도
n개의 노드(출발지 노드 제외)가 있다면 출발지에서 모든 목적지까지 최단 비용 경로를 찾기 위해 최악의 경우 얼마나 많은 계산이 필요한가?
첫 번째 반복에서 최소 비용이 이미 계산된 노드의 집합 N’에 포함되지 않은 노드 w를 결정하기 위해 모든 n개의 노드를 검사해야 하며,
두 번째 반복에서는 n-1개의 노드를, 세 번째 반복에서는 n-2개의 노드를 검사해야 한다.
따라서 찾아야 하는 노드의 총수는 n(n+1)/2가 되며,
링크 상태 알고리즘은 최악의 경우 O(n^2)의 복잡성을 갖는다.
진동(oscillation) 문제
진동 문제는 링크 상태 알고리즘뿐만 아니라 혼잡이나 지연 시간을 기반으로 링크 비용을 산출하는 모든 알고리즘에서 발생할 수 있다.
아래의 과정을 통해 진동 문제에 대하여 살펴보자.
초기의 라우팅은 다음과 같다.
링크의 비용은 통과하는 트래픽 양에 따른다.
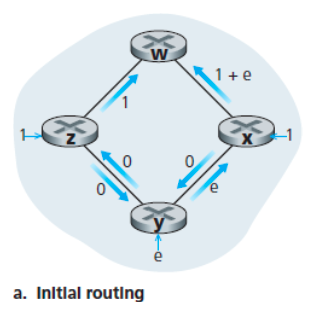
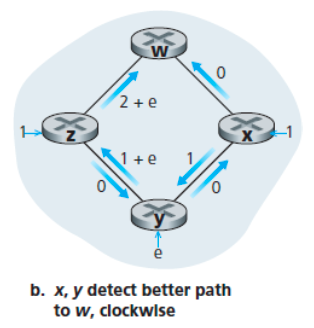
링크 상태 알고리즘이 다시 수행되면 노드 y는 w로 가는 시계 방향의 경로 비용이 1인 반면,
지금까지 사용해왔던 반시계 방향으로의 경로 비용은 1+e임을 알게 된다.
따라서 w로 가는 y의 최소 비용 경로는 시계 방향이며,
x도 마찬가지로 w로 가는 시계 방향 경로를 새로운 최소 비용 경로로 결정한다.
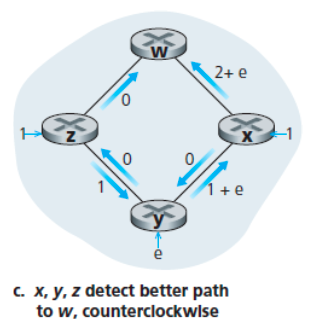
링크 상태 알고리즘이 다시 한번 수행되면
노드 x, y, z 모두 w로 가는 반시계 방향의 경로 비용이 0임을 알게 되어 모든 트래픽을 반시계 방향 경로로 보낸다.
다음번 링크 상태 알고리즘 수행 시에는 x, y, z 모두 시계 방향으로 트래픽을 전송한다.
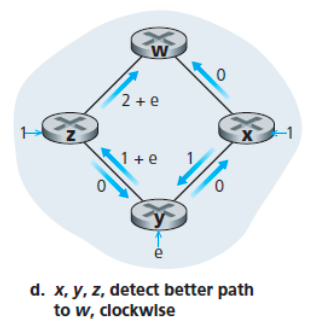
이러한 진동 문제를 방지하기 위한 방법들 중 하나는 모든 라우터가 동시에 링크 상태 알고리즘을 실행하지 못하도록 하는 것이다.
라우터들이 동일한 주기 간격으로 링크 상태 알고리즘을 수행한다 하더라도
각 노드에서의 알고리즘의 실행 시각은 같지 않을 것이기 때문에 합리적인 방법이라고 생각된다.
하지만 연구자들은 라우터들이 알고리즘을 처음에는 각기 다른 시작 시각에, 그러나 같은 주기를 갖도록 해서 실행하더라도
점진적으로 결국엔 서로 동기화된다는 것을 발견하였다.
이러한 자기 동기화는 각 노드가 링크 상태 정보를 송신하는 시각을 임의로 결정하게 함으로써 회피할 수 있다.
5.2.2 거리 벡터(DV) 라우팅 알고리즘
오늘날 실제로 사용되는 알고리즘은 거리 벡터(distance-vector, DV) 라우팅 알고리즘이다.
링크 상태 알고리즘이 네트워크 전체 정보를 이용하는 알고리즘인 반면,
거리 벡터 알고리즘은 반복적이고 비동기적이며 분산적이다.
분산적(distributed): 각 노드는 하나 이상의 직접 연결된 이웃으로부터 정보를 받고, 계산을 수행하며, 계산된 결과를 다시 이웃들에게 배포한다.반복적(iterative): 이웃끼리 더 이상 정보를 교환하지 않을 때까지 프로세스가 지속된다.비동기적(asynchronous): 모든 노드가 서로 정확히 맞물려 동작할 필요가 없다.
벨만-포드(Bellman-Ford) 식
노드 x부터 y까지 최소 비용 경로의 비용은 다음과 같이 나타낼 수 있다.
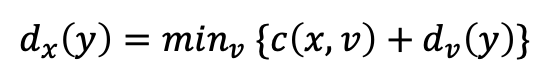
- min.v는 x의 모든 이웃에 적용된다.
- x에서 v로 이동한 후, v에서 y까지의 최소 비용 경로를 택한다면, 경로 비용은
c(x, v) + d.v(y)일 것이다. - 반드시 하나의 이웃 v로 가는 것부터 시작해야 하므로,
- x에서 y까지의 최소 비용은 모든 이웃 노드 v에 대해 계산된
c(x, v) + d.v(y) 중 최솟값이 된다.
벨만-포드 식의 해답은 각 노드 포워딩 테이블의 엔트리를 제공한다.
- 위의 식을 최소로 만드는 이웃 노드를
v*라고 해보자. - 만약 노드 x가 노드 y에게 최소 비용 경로로 패킷을 보내기 원한다면, 노드 x는 패킷을 노드 v*로 전달해야 한다.
그러므로 노드 x의 포워딩 테이블에는 최종 목적지 y로 가기 위한 다음 홉 라우터로 v*가 지정되어 있어야 한다.
따라서 거리 벡터 라우팅 알고리즘의 기본 아이디어는 다음과 같다.
출발지 노드를 x라고 가정하면, 노드 x는 자신으로부터 집합 N에 속한 다른 모든 노드 y까지의 최소 비용 경로의 비용 D.x(y)를 추정한다.
D.x을 노드 x에서부터 N에 속한 모든 다른 노드 y까지의 비용 추정값의 벡터라고 하자.
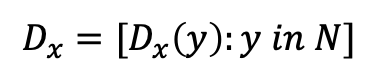
DV 알고리즘으로 각 노드 x는 다음과 같은 라우팅 정보를 유지한다.
- 각 이웃 노드 v 중에서 x에 직접 접속된 이웃 노드까지의 비용
c(x, v) - 노드 x의 거리 벡터, 즉 x로부터 N에 있는 모든 목적지 y로의 비용 예측값을 포함하는 벡터
D.x - 이웃 노드들의 거리 벡터들, 즉 v가 x의 이웃이라고 하면
D.v = [D.v(y): y in N]
분산적이고 비동기적으로 동작하는 알고리즘에서는 때때로 각 노드가 자신의 거리 벡터를 이웃들에게 보낸다.
노드 x가 이웃 w에게서 새로운 거리 벡터를 수신하면,
x는 w의 거리 벡터를 저장하고 벨만-포드 식을 사용하여 다음처럼 자신의 거리 벡터를 갱신한다.
(N에 속하는 각 노드 y에 대해)
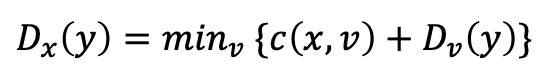
만약 이 갱신으로 인해 노드 x의 거리 벡터가 변경된다면
- 노드 x는 이 수정된 거리 벡터를 자신의 이웃들에게 보내고
- 그에 따라 이웃들도 자신의 거리 벡터를 갱신한다.
모든 노드가 자신의 거리 벡터를 비동기적으로 교환하는 동작을 계속하다 보면,
비용 추정값 D.x(y)는 노드 x에서 노드 y까지의 실제 최소 비용 경로의 비용인 d.x(y)로 수렴하게 된다.
거리 벡터(DV) 알고리즘
각 노드 x에서,

특정 목적지 y에 대한 자신의 포워딩 테이블을 갱신하기 위해 노드 x가 알아야 하는 것은 y로의 최단 경로상의 다음 홉 라우터인 이웃 노드 v*(y)다.
다음 홉 라우터 v*(y)는 위 DV 알고리즘의 14번째 줄에서 최솟값을 갖게 하는 이웃 v이기에,
13~14번째 줄에서 각 목적지 y에 대해 노드 x는 v*(y)를 결정하고 목적지 y에 대해 포워딩 테이블도 갱신한다.
💡 DV 알고리즘에서 하나의 노드가 갖는 정보는 단지 자신에게 직접 연결된 이웃으로의 링크 비용과 그 이웃들로부터 수신하는 정보뿐이다.
- 각 노드는 이웃으로부터의 갱신을 기다리고 (10~11번째 줄)
- 업데이터를 수신하면 새로 거리 벡터를 계산하고 (14번째 줄)
- 이 새로운 거리 벡터를 이웃들에게 배포한다. (16~17번째 줄)
이 과정은 더 이상의 갱신 메시지가 없을 때까지 계속된다.
갱신 메시지가 더 이상 없으면 라우팅 테이블 계산도 더 이상 없고 알고리즘은 정지 상태가 된다. (10~11번째 줄 대기 명령을 수행)
이 알고리즘은 링크 비용이 변할 때까지 정지 상태로 있는다.
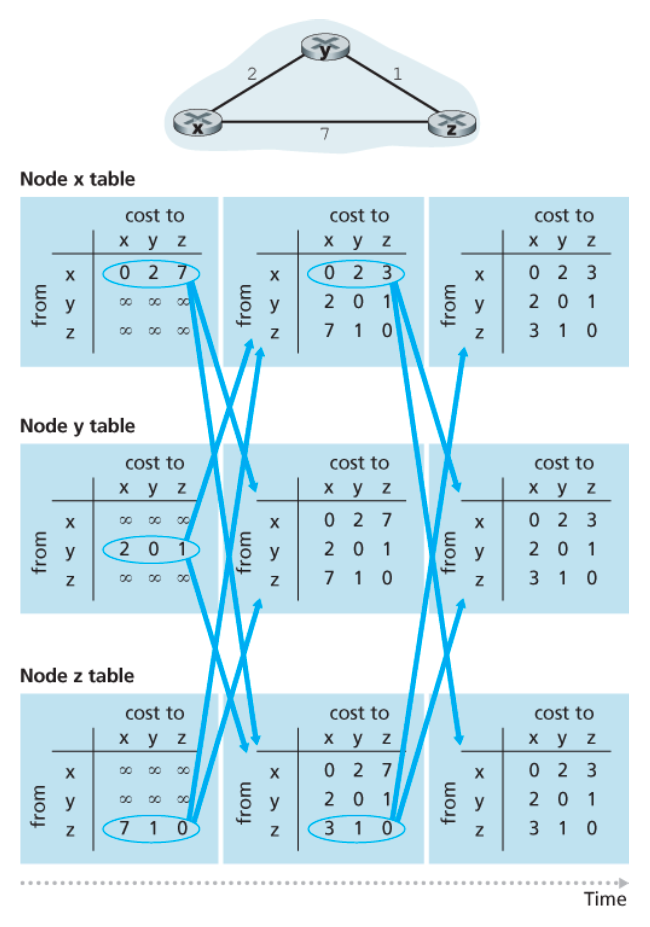
아래 그림은 세 노드로 이루어진 단순한 네트워크에서의 거리 벡터 알고리즘의 동작을 보여준다.
여기서는 모든 노드가 동기적 방식으로 동작하지만, 비동기적 방식으로도 알고리즘은 올바르게 동작한다.
거리 벡터(DV) 알고리즘: 링크 비용 변경과 링크 고장
거리 벡터 알고리즘을 수행하는 노드가
- 자신과 이웃 사이 링크의 비용이 변경된 것을 알게 되면
- 자신의 거리 벡터를 갱신한 후
- 최소 비용 경로의 비용에 변화가 있는 경우에는 이웃에게 새로운 거리 벡터를 보낸다.
이때 최소 비용 경로의 비용이 감소한 상황과 증가한 상황 두 가지를 전부 살펴보자.
a. 비용이 감소한 상황
아래는 y에서 x로의 링크 비용이 4에서 1로 변한 상황을 나타낸 것이다.
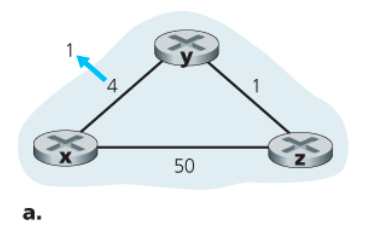
이 상황에서의 DV 알고리즘은 다음과 같은 일련의 사건을 발생시킨다.
-
시각 t0 :
y가 링크 비용의 변화를 감지하고, 자신의 거리 벡터를 갱신한 후 이 변경값을 이웃에게 알린다. -
시각 t1 :
z는 y로부터 갱신 정보를 받고 자신의 테이블을 갱신한다.- z는 x까지의 새로운 최소 비용을 계산한다.
- 이웃에게 자신의 새로운 거리 벡터를 전송한다.
-
시각 t2 :
y는 z로부터 갱신 정보를 받고 자신의 테이블을 갱신한다.- y의 최소 비용은 변화가 없으므로 y는 z에게 아무런 메시지를 보내지 않는다.
- 이에 알고리즘은 정지 상태가 된다.
따라서 거리 벡터 알고리즘은 정지 상태가 될 때까지 두 번만 반복하면 된다.
b. 비용이 증가한 상황
아래는 y에서 x로의 링크 비용이 4에서 60로 변한 상황을 나타낸 것이다.
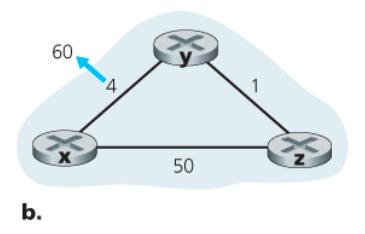
이 상황에서의 DV 알고리즘은 다음과 같은 일련의 사건을 발생시킨다.
-
시각 t0 :
y가 링크 비용 변화를 감지하고 노드 x까지 다음의 비용을 갖는 새로운 최소 비용 경로를 계산한다.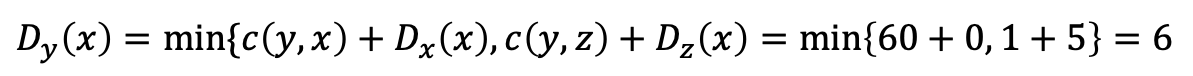
- 이때 우리는 네트워크 전체를 한눈에 볼 수 있기 때문에 z를 경유하는 이 새로운 비용이 잘못되었다는 사실을 알 수 있지만,
노드 y의 입장에서는 아니다.
- 이때 우리는 네트워크 전체를 한눈에 볼 수 있기 때문에 z를 경유하는 이 새로운 비용이 잘못되었다는 사실을 알 수 있지만,
-
시각 t1
-
x로 가기 위해 y는 z로 경로 설정을 하고, z는 y로 경로 설정을 하는
라우팅 루프(routing loop)가 발생한다.t1에 x를 목적지로 하는 패킷이 y나 z에 도착하면 포워딩 테이블이 변할 때까지 이 두 노드 사이에서 왔다 갔다 순환할 것이다.
-
노드 y는 x까지의 새로운 최소 비용을 계산했으므로 z에게 새로운 거리 벡터를 알린다.
-
-
시각 t2 : z는 y로부터 갱신 정보를 받고 새로운 최소 비용을 계산한다.
- D.z(x) = min7 = 7
- x까지의 z의 최소 비용이 증가했으므로, 새로운 거리 벡터를 y에 알린다.
-
시각 t3 : y는 z로부터 새로운 거리 벡터를 수신하고 새로운 최소 비용을 계산한다.
- Dy(x) = min8 = 8
- x까지의 y의 최소 비용이 증가했으므로, 새로운 거리 벡터를 z에 알린다.
-
…
이렇게 계속 반복되는 문제를 무한 계수 문제(count-to-infinity)라고 한다.
거리 벡터 알고리즘: 포이즌 리버스 추가
방금 설명한 특정한 라우팅 루프 시나리오는 포이즌 리버스(poisoned reverse)라는 방법을 통해 방지할 수 있다.
즉, 만약 z가 y를 통해 목적지 x로 가는 경로 설정을 했다면, z는 y에게 x까지의 거리가 무한대라고 알린다.
z는 y를 통과해서 x로 가는 동안은 이러한 거짓말을 계속한다.
이에 y는 z에서 x로 가는 경로가 없다고 믿으므로,
z가 계속해서 y를 통해 x로 가는 경로를 사용하는 동안은 y는 z를 통해 x로 가는 경로를 시도하지 않을 것이다.
하지만 포이즌 리버스는 모든 무한 계수 문제를 해결할 수는 없다.
단순히 직접 이웃한 2개의 노드가 아닌, 3개 이상의 노드를 포함한 루프는 포이즌 리버스로는 감지할 수 없다.
링크 상태 알고리즘과 거리 벡터 라우팅 알고리즘의 비교
✅ 경로 계산 방법
LS와 DV 알고리즘은 경로를 계산할 때 서로 대비되는 방법을 취한다.
LS 알고리즘
- 전체 정보를 필요로 한다.
- 각 노드는 다른 모든 노드와 (브로드캐스트를 통해) 통신한다.
- 오직 자신에게 직접 연결된 링크의 비용만 알린다.
DV 알고리즘
- 각 노드는 오직 직접 연결된 이웃과만 메시지를 교환한다.
- 자신으로부터 네트워크 내 (자신이 알고 있는) 모든 노드로의 최소 비용 추정값을 이웃들에게 제공한다.
✅ 메시지 복잡성
LS 알고리즘
- 각 노드는 네트워크 내 각 링크 비용을 알아야 하며, 이를 위해서는
O(|N| |E|)개의 메시지가 전송되어야 한다. - 링크 비용이 변할 때마다 새로운 링크 비용이 모든 노드에게 전달되어야 한다.
DV 알고리즘
- 매번 반복마다 직접 연결된 이웃끼리 메시지를 교환한다.
- 알고리즘의 결과가 수렴하는 데 걸리는 시간은 많은 요소에 좌우된다.
- 링크 비용이 변하고, 이 새로운 링크 비용이 이 링크에 연결된 어떤 노드의 최소 비용 경로에 변화를 준 경우에만
DV 알고리즘은 수정된 링크 비용을 전파한다.
✅ 견고성
라우터가 고장나거나 오동작하거나 파손된다면 어떤 일이 발생할까?
LS 알고리즘
- 라우터는 연결된 링크에 대해 잘못된 비용 정보를 브로드캐스트할 수 있다.
- 노드는 링크 상태 브로드캐스트를 통해 받은 패킷을 변질시키거나 폐기할 수 있다.
그러나 하나의 링크 상태 노드는 자신의 포워딩 테이블만 계산하기 때문에 링크 상태 알고리즘에서 경로 계산은 어느 정도 분산되어 수행된다.
따라서 링크 상태 알고리즘은 어느 정도의 견고성을 제공한다.
DS 알고리즘
- 노드는 잘못된 최소 비용 경로를 일부 혹은 모든 목적지에 알릴 수 있다.
각 반복마다 한 노드의 거리 벡터 계산이 이웃에게 전달되고 다음 반복에서 이웃의 이웃에게 간접적으로 전달된다.
따라서 거리 벡터 알고리즘을 사용하는 네트워크에서 한 노드의 잘못된 계산은 전체로 확산될 수 있다.
실제로 1997년에 작은 ISP에서 오작동한 라우터가 잘못된 라우팅 정보를 전국망의 백본 라우터에 제공한 적이 있었다.
이는 다른 라우터들이 오작동한 라우터에게 대규모 트래픽을 보내게 만들었고,
인터넷의 상당 부분이 여러 시간 동안 단절되었다고 한다.
결국 어떤 알고리즘이 다른 알고리즘보다 명백히 낫다고 말할 수는 없으며,
실제로 두 알고리즘 모두는 인터넷에서 사용되고 있다.
5.3 인터넷에서의 AS 내부 라우팅: OSPF
네트워크를 동일한 라우팅 알고리즘을 수행하는 동종의 라우터 집합으로 간주하는 관점은 다음의 두 가지 문제점이 존재한다.
-
확장라우터의 수가 증가함에 따라 라우팅 정보의 통신, 계산, 저장에 필요한 오버헤드가 걷잡을 수 없이 증가한다.
-
관리 자율성ISP는 일반적으로 자신의 네트워크를 원하는 대로 운용하거나(e.g., 어떠한 라우팅 알고리즘이라도 수행할 수 있도록),
네트워크 내부 구성을 외부에 감추기를 원한다.
자율 시스템
위의 문제점들은 라우터들을 자율 시스템(autonomous system, AS)으로 조직화하여 해결할 수 있다.
- 각 AS는 동일한 관리 제어하에 있는 라우터의 그룹으로 구성된다.
- 자율 시스템은 전 세계적으로 고유한
AS 번호(autonomous system number, ASN)으로 식별된다. - 같은 AS 안에 있는 라우터들은 동일한 라우팅 알고리즘을 사용하고 상대방에 대한 정보를 갖고 있다.
- 자율 시스템 내부에서 동작하는 라우팅 알고리즘을
AS 내부 라우팅 프로토콜(intra-autonomous system routing protocol)이라고 한다.
개방형 최단 경로 우선(OSPF) 프로토콜
개방형 최단 경로 우선(open shortest path first, OSPF) 라우팅과 IS-IS(Intermediate System to Intermediate System)는
인터넷에서 AS 내부 라우팅에 널리 사용된다.
OSPF는 링크 상태 정보를 플러딩(flooding)하고 다익스트라 최소 비용 경로 알고리즘을 사용하는 링크 상태 알고리즘이다.
-
OSPF를 이용하여 각 라우터는 전체 AS에 대한 완벽한 토폴로지 지도(그래프)를 얻는다.
-
각 라우터는 자신을 루트 노드로 두고 모든 서브넷에 이르는 최단 경로 트리를 결정하기 위해 혼자서 다익스트라의 최단 경로 알고리즘을 수행한다.
-
OSPF를 사용하는 라우터는 자율 시스템 내의 다른 모든 라우터에게 라우팅 정보를 브로드캐스팅한다.
- 링크 상태가 변경될 때마다
- 링크 상태가 변경되지 않았더라도 정기적으로(최소한 30분마다 한 번씩)
-
OSPF 메시지에 포함된 상태 정보는 인터넷 프로토콜에 의해 전달되며, 상위 계층 프로토콜 번호로는 OSPF를 의미하는
89를 갖는다.- 따라서 OSPF 프로토콜은 신뢰할 수 있는 메시지 전송과 링크 상태의 브로드캐스트와 같은 기능을 스스로 구현해야 한다.
- 또한 OSPF 프로토콜은 링크가 동작하고 있는지 검사하고,
OSPF 라우터가 네트워크 전반의 링크 상태에 대한 이웃 라우터의 데이터베이스를 얻을 수 있도록 해야 한다.
OSPF 링크 가중치 설정
링크 상태 라우팅을 설명하면서 우리는 순서를 묵시적으로 아래와 같이 가정했다.
- 링크 가중치가 설정되고,
- OSPF 같은 라우팅 알고리즘이 수행되며,
- LS 알고리즘에 의해 계산된 라우팅 테이블의 내용에 따라 트래픽이 흐른다.
이를 원인과 결과 방식으로 설명하면,
- 원인 : 링크 가중치가 주어지고
- 결과 : 이에 따라 전체 비용을 최소화하는 라우팅 경로가 결정된다.
실제로는 링크 가중치와 라우팅 경로 간의 원인과 결과 관계는 반대가 될 수도 있다.
네트워크 운영자가 어떤 트래픽 관리 목표를 충족시키는 라우팅 경로를 얻기 위해 링크 가중치를 설정할 수 있다.
즉, 트래픽 흐름에 대한 바람직한 경로가 알려져 있고, OSPF 라우팅 알고리즘이 이 경로대로 구성하게 되도록 OSPF 링크 가중치를 찾아야 한다.
따라서 관리자는 모든 링크 비용을 1로 설정함으로써 최소 홉 라우팅이 이루어지게 하거나,
적은 대역폭을 가진 링크 사용을 억제하기 위해 링크 용량에 반비례하게 링크 가중치를 설정할 수 있다.
OSFP에 구현된 개선사항들
보안
OSPF 라우터들 간의 정보 교환(e.g., 링크 상태 갱신)을 인증할 수 있으며,
인증을 통해 신뢰할 수 있는 라우터들만이 AS 내부의 OSPF 프로토콜에 참여할 수 있다.
원래 라우터 간의 OSPF 패킷은 인증을 하지 않으므로 위조될 수 있다.
두 종류의 인증
- 단순 인증 : 동일한 패스워드가 각 라우터에 설정되며, 라우터가 OSPF 패킷을 보낼 때 패스워드를 평문 그대로 포함하기 때문에 안전하지 않다.
- MD5 인증 : 모든 라우터에 설정된 공유 비밀키를 기반으로 한다. (8장 내용)
복수 동일 비용 경로
하나의 목적지에 대해 동일한 비용을 가진 여러 개의 경로가 존재할 때 OSPF는 여러 개의 경로를 사용할 수 있도록 한다.
즉, 비용이 동일한 여러 개의 경로가 있을 때 모든 트래픽을 전달하기 위한 단 하나의 경로를 선택할 필요가 없다.
유니캐스트와 멀티캐스트 라우팅의 통합 지원
MOSPF(multicast OSPF)는 멀티캐스트 라우팅 기능을 제공하기 위해 OSPF를 단순 확장했다.
- 기존의 OSPF 링크 데이터베이스를 사용
- OSPF 링크 상태 브로드캐스트 메커니즘에 새로운 형태의 링크 상태 알림을 추가
[참고]
MAC 주소: 네트워크 상에서 서로를 구분하기 위해 디바이스마다 할당된 물리적 주소유니캐스트(Unicast): 정보를 전송하기 위한 프레임에 자신의 MAC 주소와 목적지의 MAC 주소를 첨부하여 전송하는 방식 (일대일 통신)브로드캐스트(Broadcast): 로컬 네트워크에 연결되어 있는 모든 시스템에게 프레임을 보내는 방식
(송신 노드 하나가 네트워크에 연결된 수신 가능한 모든 노드에 데이터를 전송)멀티캐스트(Multicast): 네트워크에 연결되어 있는 시스템 중 특정 그룹을 지정해서 해당 그룹원에게만 한 번에 정보를 전송하는 방식
(라우터가 멀티캐스트를 지원해야만 사용 가능)
단일 AS 내에서의 계층 지원
OSPF의 자율 시스템(AS)는 계층적인 영역(area)으로 구성될 수 있다.
- 각 영역은 자신의 OSPF 링크 상태 라우팅 알고리즘을 수행한다.
- 한 영역 내의 라우터는 같은 영역 내의 라우터들에게만 링크 상태를 브로드캐스트한다.
- 각 영역 내에서 하나 혹은 그 이상의
영역 경계 라우터(area border router)가 영역 외부로의 패킷 라우팅을 책임진다. 백본 영역의 주요 역할은 AS 내 영역 간의 트래픽을 라우팅하는 것이다.
AS 내 영역 간 라우팅을 위해서는,
- 영역 경계 라우터로 패킷을 라우팅한다. (영역 내 라우팅)
- 백본을 통과하여 목적지 영역의 영역 경계 라우터로 라우팅한다.
- 그 후 최종 목적지로 라우팅한다.
5.4 인터넷 서비스 제공업자(ISP) 간의 라우팅: BGP
패킷이 여러 AS를 통과하도록 라우팅할 때,
(e.g., 한국에 있는 스마트폰이 실리콘 밸리에 있는 데이터 센터로 전송을 할 경우)
자율 시스템 간 라우팅 프로토콜(inter-autonomous system routing protocol)이 필요하다.
통신하는 AS들은 같은 AS 간 라우팅 프로토콜을 수행해야만 한다.
실제로 인터넷의 모든 AS는 경계 게이트웨이 프로토콜(Border GateWay Protocol, BGP)을 사용하며,
이는 거리 벡터 라우팅과 같은 줄기에서 나왔다고 볼 수 있는 분산형 비동기식 프로토콜이다.
5.4.1 BGP의 역할
같은 AS 내에 있는 목적지에 대해서는 라우터의 포워딩 테이블 엔트리들이 해당 AS의 AS 내부 라우팅 프로토콜에 의해 결정된다.
하지만 목적지가 AS 외부에 있는 경우, BGP가 필요하다.
BGP에서는 패킷이 CIDR(Classless Inter-Domain Routing) 형식으로 표현된, 주소의 앞쪽 프리픽스(prefix)를 향해 전달된다.
각 프리픽스는 서브넷이나 서브넷의 집합을 나타낸다. (e.g., 139.16.68/22)
라우터의 포워딩 테이블은 (x, I) 같은 형식의 엔트리들을 갖게 된다
x: 주소 프리픽스 (e.g., 139.16.68/22)I: 라우터 인터페이스의 인터페이스 번호
AS 간 라우팅 프로토콜로서 BGP는 각 라우터에게 다음과 같은 수단을 제공한다.
-
이웃 AS를 통해 도달 가능한 서브넷 프리픽스 정보를 얻는다.
- 특히 각 서브넷이 자신의 존재를 인터넷 전체에 알릴 수 있도록 한다.
-
서브넷 주소 프리픽스로의 가장 좋은 경로를 결정한다.
- 라우터는 특정한 주소 프리픽스를 향한 2개 이상의 경로를 알 수도 있다.
- 가장 좋은 경로를 결정하기 위해 라우터는 BGP의 경로 결정 프로시저를 수행한다.
5.4.2 BGP 경로 정보 알리기
아래의 단순한 네트워크는 3개의 자율 시스템 AS1, AS2, AS3를 가지며,
AS3는 주소 프리픽스가 x인 서브넷을 포함한다.
각 AS에서 각각의 라우터들은 게이트웨이 라우터(gateway router) 또는 내부 라우터(internal router)다.
게이트웨이 라우터(gateway router)
- AS의 경계에 있는 라우터
- 다른 AS들에 있는 하나 또는 여러 개의 라우터와 직접 연결된다.
- e.g., AS1의
라우터 1c
내부 라우터(internal router)
- 자신의 AS 내에 있는 호스트 및 라우터와만 연결된다.
- e.g., AS1의
라우터 1a, 1b, 1d
자율 시스템은 서로 메시지를 보내지 않고 라우터가 보낸다.
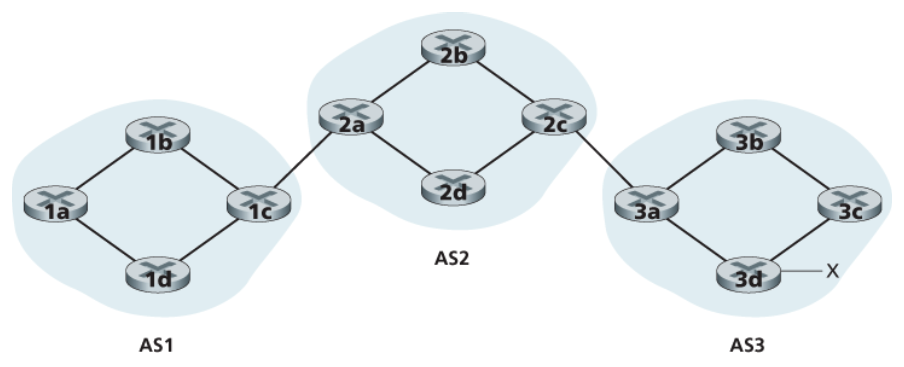
BGP 연결(BGP connection)
- BGP에서 라우터의 쌍들은 포트 번호가
179이고반영구적인 TCP 연결을 통해 라우팅 정보를 교환한다. - 이 TCP 연결을 통해 모든 BGP 메시지가 전송된다.
외부 BGP(external BCP, eBGP) 연결
- 2개의 AS를 연결하는 BGP 연결
내부 BGP(internal BGP, iBGP) 연결
- 같은 AS 내의 라우터를 연결하는 BGP 연결
보통 각기 다른 AS에 속하는 게이트웨이 라우터들을 직접 연결하는 링크에는 eBGP 연결이 존재한다.
각 AS 내부 라우터 간에는 iBGP 연결도 존재하며,
아래 그림은 한 AS 내 모든 라우터의 쌍 각각에 대해 하나씩의 BGP 연결을 두는 일반적인 설정 모습을 보인다.
iBGP 연결은 물리적인 링크와 항상 일치하지는 않는다.
위 예시에서 프리픽스 x에 대한 도달 가능성 정보를 AS1과 AS2의 모든 라우터에게 알리는 작업을 생각해보자.
아래의 과정이 완료되면 AS1과 AS2의 각 라우터들은 x의 존재와 x로 향하는 AS 경로를 알게 된다.
-
먼저 게이트웨이 라우터 3a는 게이트웨이 라우터 2c에게 ‘
AS3 x’라는eBGP 메시지를 보낸다.
(**’x가 존재하고 AS3 내에 있다’**는 의미) -
게이트웨이 라우터 2c는
iBGP 메시지‘AS3 x’를 게이트웨이 라우터 2a를 포함한 AS2 내부의 모든 라우터에게 전송한다. -
게이트웨이 라우터 2a는
eBGP 메시지‘AS2 AS3 x’를 게이트웨이 라우터 1c에게 보낸다.
(’x가 존재하고 x에 도달하기 위해서는 먼저 AS2를 통과하고 그 후 AS3으로 갈 수 있다’는 의미) -
마지막으로, 게이트웨이 라우터 1c는 iBGP를 사용하여 AS1 내의 모든 라우터에게 메시지 ‘
AS2 AS3 x’를 전달한다.
실제 네트워크에서는 주어진 라우터에서 특정 목적지까지 다른 많은 경로가 존재할 수 있고, 심지어 각기 다른 일련의 AS들을 통과하기도 한다.
아래 그림은 라우터 1d에서 3d로 연결되는 물리적인 링크를 추가한 것이다.
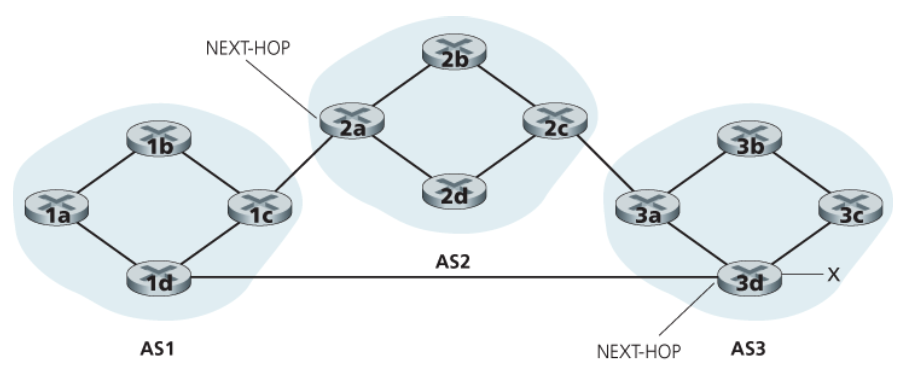
이 경우에 AS1에서 x로는 2개의 경로가 존재한다.
- 라우터 1c를 통과하는 경로 ‘
AS2 AS3 x’ - 라우터 1d를 통과하는 새로운 경로 ‘
AS3 x’
5.4.3 최고의 경로 결정
주어진 라우터에서 목적지 서브넷까지는 많은 경로가 있을 수 있는데,
이런 경로들 중에서 라우터는 어떻게 선택을 할까? 그리고 어떻게 그에 따라 포워딩 테이블을 설정할까?
BGP 관련 용어들
라우터가 BGP 연결을 통해 주소 프리픽스를 알릴 때 몇몇 BGP 속성(attribute)을 함께 포함한다.
BGP의 용어로는 프리픽스와 그것의 속성을 경로(route)라고 한다.
AS-PATH
-
알림 메시지가 통과하는 AS들의 리스트를 담는다.
- 프리픽스가 어떤 AS에 전달되었을 때
- 그 AS는 자신의 ASN을
AS-PATH내 현재 리스트에 추가한다.
-
메시지의 루프를 감지하고 방지하기 위해 활용한다.
- 어떤 라우터가 자신의 AS가 경로 리스트에 포함되어 있는 것을 발견하면
- 그 알림 메시지를 버린다.
NEXT-HOP
- AS-PATH가 시작되는 라우터 인터페이스의 IP 주소
e.g.,
AS1에서 AS2를 통과하여 x로 가는 ‘AS2 AS3 x’ 경로의 NEXT-HOP 속성은 라우터 2a의 왼쪽 인터페이스의 IP 주소다.
AS1에서 AS2를 우회하여 x로 가는 ‘AS3 x’ 경로의 NEXT-HOP 속성은 라우터 3d의 맨 왼쪽 인터페이스의 IP 주소다.
즉, AS1의 각 라우터는 프리픽스 x로 가는 2개의 BGP 경로를 알게 된다.
라우터 2a의 맨 왼쪽 인터페이스의 IP 주소; AS2 AS3; x
라우터 3d의 맨 왼쪽 인터페이스의 IP 주소; AS3; x
NEXT-HOP 속성은 AS1에 속하지 않는 라우터의 IP 주소이다.
그러나 이 IP 주소를 포함하는 서브넷이 AS1에 직접적으로 연결된다.
뜨거운 감자 라우팅(hot potato routing)
💡 가능한 모든 경로 중, 경로 각각의 시작점인 NEXT-HOP 라우터까지의 경로 비용이 최소가 되는 경로를 선택한다.
-
여러 게이트웨이를 통해 서브넷 x에 도달할 수 있다는 사실을 AS 간 프로토콜로부터 알게 된다.
-
각 게이트웨이까지의 최소 비용 경로를 정하기 위해 AS 내부 프로토콜을 통해 얻은 라우팅 정보를 이용한다.
-
뜨거운 감자 라우팅: 가장 적은 비용의 게이트웨이를 선택한다.
-
포워딩 테이블로부터 최소 비용 게이트웨이로의 인터페이스 I를 결정한 후 포워딩 테이블에
(x, I)를 추가한다.
포워딩 테이블에 AS 외부의 목적지를 추가할 때
AS 간 라우팅 프로토콜(BGP)과 AS 내부 라우팅 프로토콜(e.g., OSPF) 둘 다가 사용된다.
e.g.,
-
라우터 1b는 주소가x로 시작하는 서브넷으로 가는 2개의 BGP 경로를 안다. -
NEXT-HOP 라우터 2a와 3d각각에 대해 최소 비용을 가진 AS 내부 경로를 찾기 위해 AS 내부 라우팅 정보를 조사한다. -
이들 최소 비용 경로 중에서도 가장 적은 비용을 가진 경로를 선택한다.
비용을 거쳐가야 하는 링크의 수로 정의하면,
- 라우터 1b에서
라우터 2a까지의 최소 비용 : 2 - 라우터 1b에서
라우터 3d까지의 최소 비용 : 3
따라서 라우터 2a가 선택된다.
- 라우터 1b에서
-
라우터 1b는 자신의 (AS 내부 알고리즘에 의해 설정된) 포워딩 테이블을 관찰하여 라우터 2a로 가기 위한 인터페이스 I를 찾아내고,
엔트리(x, I)를 자신의 포워딩 테이블에 추가한다.
💡 기본 아이디어
라우터가 목적지까지의 경로 중 자신의 AS 바깥에 있는 부분에 대한 비용은 신경 쓰지 않고
최대한 신속하게(가능한 한 최소의 비용으로) 패킷을 자신의 AS 밖으로 내보내는 것이다.
즉, 뜨거운 감자 라우팅은 오로지 자신의 경로 중에서 자기 AS 내부 비용만 줄이려는 이기적인 알고리즘이다.
이를 사용하면 한 AS 내 2개의 라우터가 동일한 목적지 주소에 대해 각기 다른 AS 경로를 선택할 수도 있다.
e.g.,
위의 예시에서 라우터 1b는 AS2를 통해 서브넷 x로 패킷을 보냈지만, 라우터 1d는 바로 AS3으로 보내 서브넷 x에 도달한다.
경로 선택 알고리즘
실제로 BGP는 뜨거운 감자 라우팅을 포함하는 더 복잡한 알고리즘을 사용한다.
목적지 주소의 프리픽스가 주어지면, 지금까지 라우터가 알아낸 해당 목적지까지의 모든 경로가 BGP의 경로 선택 알고리즘에 입력으로 주어진다.
💡 하나의 목적지에 대해 2개 이상의 경로가 존재한다면 BGP는 하나의 경로가 남을 때까지 다음의
제거 규칙을 계속 수행한다.
여기서 뜨거운 감자 라우팅에서 추가된 것은 속성 중의 하나로서 지역 선호도(local preference)가 경로에 할당되었다는 것이다.
한 경로의 지역 선호도는 라우터에 의해 설정되었거나 같은 AS 내부의 다른 라우터로부터 학습된 것이다.
-
최고 지역 선호 값을 가진 경로가 선택된다. -
최고 지역 선호 값을 가진 경로가 여러 개 있다면 이들 중에서
최단 AS-PATH를 가진 경로가 선택된다.- 만약 이 규칙이 경로 선택을 위한 유일한 규칙이라면, BGP는 경로 결정을 위해
DV 알고리즘을 사용할 것이다. - 여기서 거릿값으로는 AS 홉 수를 사용한다.
- 만약 이 규칙이 경로 선택을 위한 유일한 규칙이라면, BGP는 경로 결정을 위해
-
(같은 최고 지역 선호 값 및 같은 AS-PATH 길이를 가진) 모든 남은 경로들에 대해
뜨거운 감자 라우팅을 수행한다. -
만일 아직도 하나보다 많은 경로가 남아 있다면 라우터는
BGP 식별자를 사용하여 경로를 선택한다.
e.g.,
라우터 1b에서 서브넷 x로 가는 BGP 경로는 2가지가 존재했고(AS2를 통과 또는 우회),
뜨거운 감자 라우팅이 바로 사용된다면 BGP는 AS2를 통과하는 경로로 패킷을 보내야 한다.
하지만 위의 경로 선택 알고리즘에서 규칙 2가 규칙 3보다 먼저 적용되므로, 더 짧은 AS-PATH를 가진 AS2 우회 경로가 선택된다.
따라서 이는 더이상 이기적인 알고리즘이 아니며, 결과적으로 종단 간 지연 시간이 줄어들 것이다.
5.4.4 IP 애니캐스트
BGP는 IP 애니캐스트(anycast) 서비스를 구현하는 데도 활용된다.
[참고] 애니캐스트(anycast) : 송신노드가 네트워크에 연결된 수신 가능한 노드 중에서 가장 가까운 한 노드에만 데이터를 전송한다. (IPv6 기반으로 작동)
많은 애플리케이션에서 (1) 같은 콘텐츠를 지리적으로 분산된 다른 많은 서버에 복제하고,
(2) 각 사용자를 가장 가까운 서버의 콘텐츠로 접근하게 하려고 하는 경우를 생각해보자.
e.g., CDN은 비디오 등을 각기 다른 나라의 서버들에 복제해두며, DNS 시스템도 DNS 정보를 전 세계 DNS 서버에 복제할 수 있다.
이 경우, BGP의 경로 선택 알고리즘을 사용할 수 있다.
아래 그림은 사용자를 가장 가까운 CDN 서버로 보내기 위한 IP 애니캐스트의 활용을 보여주는 그림이다.
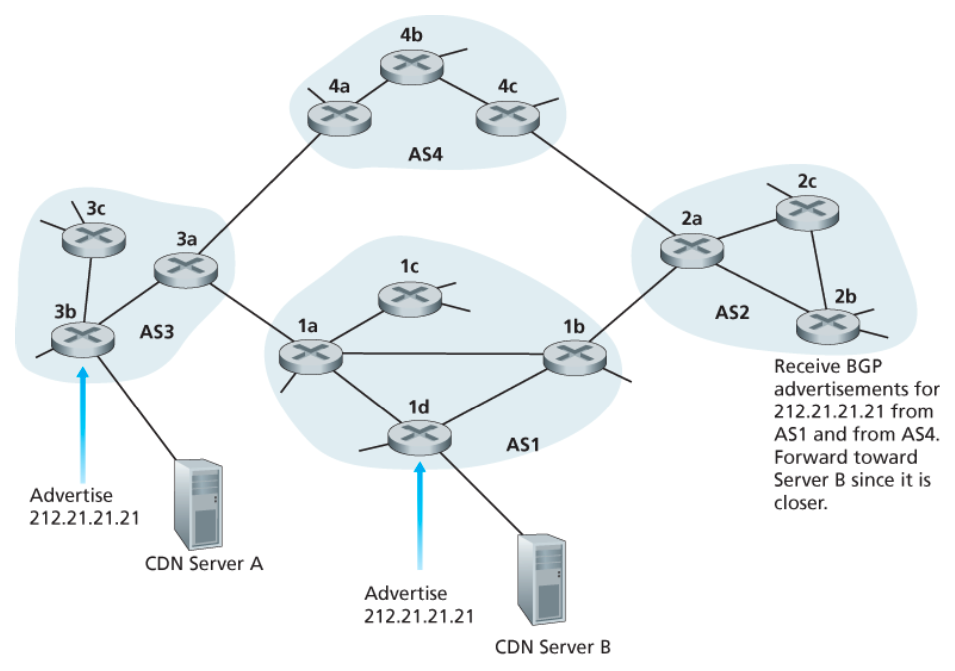
-
IP 애니캐스트 설정 단계에서
(1) CDN 사업자가 자신의 서버 여러 대에 동일한 IP 주소를 할당하고
(2) 표준 BGP를 활용하여 이 주소를 서버 각각으로부터 알린다.-
라우터가 이 IP 주소에 대한 복수 개의 경로 알림 메시지를 받으면
이를 동일한 물리적 위치로의 서로 다른 경로에 대한 정보를 제공받고 있는 것으로 생각한다. -
실제로는 서로 다른 물리적 위치로 가는 서로 다른 경로다.
-
-
각 라우터는 라우팅 테이블을 설정하면서
BGP 경로 선택 알고리즘을 수행하여 해당 IP 주소로의 최고의 경로를 골라낸다.
이러한 최초의 BGP 주소 알림 단계 이후에 CDN는 콘텐츠 배포를 할 수 있다.
-
사용자가 비디오를 요청하면 CDN은 사용자가 어디에 위치해 있든 상관없이
지리적으로 분산되어 있는 서버들이 공통적으로 사용하는 IP 주소를 사용자에게 돌려준다. -
사용자가 그 주소로 요청을 보내면 인터넷 라우터는 그 요청 패킷을 BGP 경로 선택 알고리즘이 정의한 가장 ‘가까운’ 서버로 전달한다.
실제로는 BGP 라우팅이 변경되면 하나의 TCP 연결에 속한 패킷들이 서로 다른 복제 웹 서버로 도착될 수 있기 때문에
CDN은 위의 예처럼 IP 애니 캐스트를 사용하지 않으며,
DNS 시스템에서는 DNS 질의를 가장 가까운 루트 DNS 서버로 전달하기 위해 IP 애니캐스트를 광범위하게 사용된다.
5.4.5 라우팅 정책
라우터가 목적지까지의 경로를 선택하려고 할 때
AS 라우팅 정책은 최단 AS-PATH나 뜨거운 감자 라우팅 등의 다른 모든 고려사항보다 우선시된다.
아래 그림에서는 A, B, C, W, X, Y 이렇게 6개의 자율 시스템(AS)이 서로 연결되어 있다.
-
W, X, Y는
사용자 접속 ISP -
A, B, C는
백본 제공자 네트워크- 트래픽을 서로에게 직접 보낸다.
- 그들의 사용자 네트워크에 완전한 BGP 정보를 제공한다.
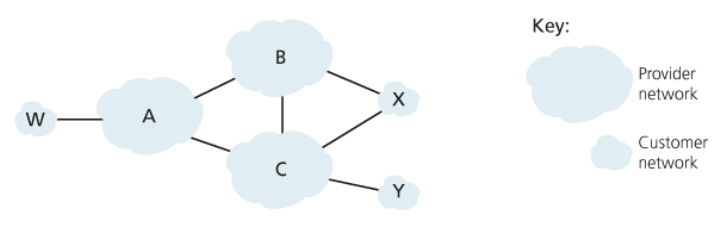
ISP 접속 네트워크로
들어오는모든 트래픽은 그 네트워크를 목적지로 해야만 하고,
ISP 접속 네트워크에서나가는트래픽은 그 네트워크 안에서 생성된 것이어야만 한다.
- W와 Y는 명백히 접속 ISP다.
- X는 각기 다른 두 제공자를 통해 네트워크의 다른 부분들과 연결되어 있으므로
다중 홈 접속 ISP(multi-homed access ISP)라고 한다.
X도 W나 Y처럼 자신에게 들어오고 나가는 모든 트래픽의 목적지 또는 출발지여야 한다.
이 접속 네트워크의 동작을 구현하고 강제하며, X가 B와 C간 트래픽을 전달하는 것을 방지하는 것은
BGP 경로의 알림 방식을 제어하는 것으로 가능하다.
즉, X는 이웃인 B와 C에게 자기 자신을 제외하고는 다른 어떤 목적지로도 경로가 없다고 알리는 것이다.
(X가 Y까지 가는 XCY라는 경로를 알고 있더라도 이 경로를 B에게 알리지 않음)
따라서 B는 X가 Y로의 경로를 갖고 있음을 모르기 때문에 C 또는 Y로 가야 하는 트래픽을 X에게 절대 전달하지 않을 것이다.
서비스 제공자 네트워크 B는 (A로부터) A가 W까지의 경로 AW를 갖고 있음을 알게 되었다고 가정하자.
그러면 B는 경로 AW를 자신의 라우팅 정보 테이블에 기록하고,
자신의 고객인 X가 B를 통해 W로 갈 수 있음을 알게 하기 위해 경로 BAW를 X에게 알리길 원할 것이다.
하지만 B는 C에게도
BAW경로를 알려야 할까?
만약 그렇게 한다면, C는 해당 경로를 통해 W까지 트래픽을 보낼 수 있게 되는데,
A, B, C가 모두 백본 제공자라면 B는 당연히 A와 C 사이의 트래픽을 전달하는 짐을 져서는 안 된다고 생각할 것이다.
현재는 백본 ISP들 사이의 경로를 결정하는 방법에 대한 공식적인 표준은 없지만,
상업적 ISP들이 따르는 대략적인 규칙은
ISP 백본 네트워크를 통해 흐르는 트래픽은 해당 ISP의 고객 네트워크를 출발지로 하거나 목적지로 해야 한다는 것이다(또는 둘 다).
개별적인 상호 협정은 전통적으로 두 ISP 간에 협상되고 종종 기밀사항이다.
왜 AS 간 라우팅과 AS 내부 라우팅 프로토콜이 다를까?
이는 AS 내부 라우팅과 AS 간 라우팅의 목적의 차이에 있다.
정책
AS 간 라우팅은 정책 이슈가 지배한다.
특정 AS에서 시작된 트래픽이 다른 특정 AS를 통과할 수 없다는 것은 중요할 수 있으며,
특정 AS가 다른 AS들 사이에서 어떤 트래픽을 전달할지 결장할 수 있기를 원하는 것 역시 당연하다.
반면, 하나의 AS 안에서는 모든 것이 동일한 관리 통제하에 있으므로 정책 문제는 경로 선택에 그리 중요하지 않다.
확장성
AS 간 라우팅에서 수많은 네트워크로, 또는 네트워크 간 경로 설정을 처리하기 위한 라우팅 알고리즘과 자료 구조의 능력은 매우 중요한 문제다.
반면, 한 AS 내에서는 확장성이 중요하지 않다.
하나의 ISP가 너무 커지면 이를 2개의 AS로 분리하고, 이 새로운 두 AS 사이에서 AS 간 라우팅을 수행할 수 있다.
(OSPF가 하나의 AS를 여러 영역으로 나눔으로써 계층을 만드는 것을 허용함)
성능
AS 간 라우팅은 정책 지향형이므로 사용하는 라우터의 품질(e.g., 성능)은 부수적인 관심사에 지나지 않는다.
단일 AS에서는 이러한 정책의 고려가 중요하지 않으므로, 경로의 성능 수준에 좀 더 초점을 두고 라우팅을 한다.
5.4.6 조각 맞추기: 인터넷 존재 확인하기
이 절은 본질적으로 BGP에 관한 내용은 아니지만,
IP 주소체계, DNS, BGP를 포함하여 지금까지 살펴본 많은 프로토콜과 개념을 한데 모은다.
작은 회사를 설립했다고 가정하다.
회사에는 회사의 제품과 서비스를 설명하는 공개 웹 서버, 메일 서버, DNS 서버를 포함한 많은 서버가 있다.
-
먼저
지역 ISP와 계약하여 인터넷 연결을 해야 한다.- 회사는
게이트웨이 라우터를 갖게 될 텐데, 이는 지역 ISP의 라우터에 연결될 것이다. - 지역 ISP는 특정 범위의
IP 주소를 제공한다. (e.g., 256개의 주소를 포함하는 /24 주소 범위) - 물리적 연결과 IP 주소 범위를 가지면
회사의 웹 서버, 메일 서버, DNS 서버, 게이트웨이 라우터와 다른 서버 및 네트워킹 장치들에 IP 주소(주소 범위에서)를 할당해야 한다.
- 회사는
-
회사의
도메인 이름(e.g., xanadu.com)을 얻기 위해 인터넷 등록 기관과 계약을 해야 하며,DNS 시스템에 등록해야 한다.- 회사의
DNS 서버의 IP 주소를 등록 기관에 제공해야 한다. - 그러면 등록 기관은
.com 최상위 도메인 서버에 회사의 DNS 서버(도메인 이름과 해당 IP 주소)를 추가한다.
- 회사의
-
사람들이 회사의 웹 서버 IP 주소를 검색할 수 있도록
회사의DNS 서버에웹 서버의 호스트 이름(e.g.,www.xanadu.com)과IP 주소의 사상 항목을 포함시켜야 한다.
(메일 서버를 포함하여 회사의 공개적으로 사용 가능한 다른 서버들에 대해서도 유사한 항목들을 가져야 한다.)- 만일 앨리스라는 사람이 회사의 웹 서버를 방문하기를 원하는 경우,
- DNS 시스템은 회사의 DNS 서버에 접촉하여 웹 서버의 IP 주소를 알아낸 후
- 이를 앨리스에게 제공한다.
- 이제 앨리스는 회사의 웹 서버에 직접적으로 TCP 연결을 설립할 수 있다.
- 만일 앨리스라는 사람이 회사의 웹 서버를 방문하기를 원하는 경우,
-
전 세계의 외부인이 회사의 웹 서버에 접근할 수 있도록 하기 위해서는
라우터가 회사 주소 범위에 해당하는IP 주소 프리픽스24비트(또는 다른 길이의 엔트리)의 존재를 알고 있어야 한다.- 예시 상황
- 회사의 웹 서버의 IP 주소를 알아낸 앨리스가 그 IP 주소로 IP 데이터그램(e.g., TCP SYN 세그먼트)을 보낸다.
- 이 데이터그램은 인터넷을 통해 라우팅되어 여러 자율 시스템의 라우터들을 연속적으로 거친 후 마침내 웹 서버에 도착하게 된다.
- 라우터들 각각은 이 데이터 그램을 수신하면,
어느 출력 포트로 내보내야 하는지 결정하기 위해 자신의포워딩 테이블에서 해당 엔트리를 찾는다.
- 라우터들 각각은 이 데이터 그램을 수신하면,
- 이는
BGP를 통해서 이루어지게 된다.- 회사가 지역 ISP와 계약하고 주소 프리픽스(즉, 주소 범위)를 할당 받을 때,
지역 ISP는 BGP를 사용하여 자신과 연결되어 있는 ISP들에게 회사의 주소 프리픽스를 알린다. - 연결된 ISP들 역시 BGP를 활용하여 이 알림 정보를 전파한다.
- 회사가 지역 ISP와 계약하고 주소 프리픽스(즉, 주소 범위)를 할당 받을 때,
- 예시 상황
5.5 소프트웨어 정의 네트워크(SDN) 제어 평면
이 절에서는 4.4절에서 사용한 SDN 용어들을 다시 채택하여
네트워크의 포워딩 장비들은 ‘패킷 스위치’ 또는 그냥 ‘스위치’라고 부를 것이다.
이 스위치들에서의 포워딩 결정은 네트워크 계층에서의 출발지/목적지 주소, 링크 계층에서의 출발지/목적지 주소 외에도
트랜스포트 계층, 네트워크 계층, 링크 계층 패킷 헤더의 다른 많은 값에 기반하여 이루어진다.
SDN 구조의 특징
플로우 기반 포워딩
SDN으로 제어되는 스위치들에서의 패킷 전달은 트랜스포트 계층, 네트워크 계층, 또는 링크 계층 헤더의 어떤 값을 기반으로 하든 이루어질 수 있다.
이는 앞 절에서 살펴본,
IP 데이터그램의 포워딩이 온전히 데이터그램의 목적지 주소를 기반으로 이루어지는 전통적인 라우터 기반 포워딩과는 매우 대조적인 특성이다.
💡 SDN에서는 모든 네트워크 스위치의 플로우 테이블 항목들을 계산하고 관리, 설치하는 일이 모두
SDN 제어 평면의 임무다.
데이터 평면과 제어 평면의 분리
데이터 평면
- 네트워크의
스위치들로 구성된다. (이들은 상대적으로 단순하지만 빠른 장치들) - 자신들의 플로우 테이블 내용을 기반으로 ‘매치 플러스 액션’을 수행한다.
제어 평면
- 서버와 스위치들의 플로우 테이블을 결정, 관리하는
소프트웨어로 이루어진다.
네트워크 제어 기능이 데이터 평면 스위치 외부에 존재
SDN 제어 평면은 소프트웨어로 구현되어 있으며, 네트워크 스위치로부터 멀리 떨어진 별도의 서버에서 수행된다.
아래의 그림에서 볼 수 있듯, 제어 평면은 2개의 구성요소로 이루어진다.
SDN 컨트롤러(또는 네트워크 운영체제)SDN 네트워크 제어 애플리케이션들의 집합
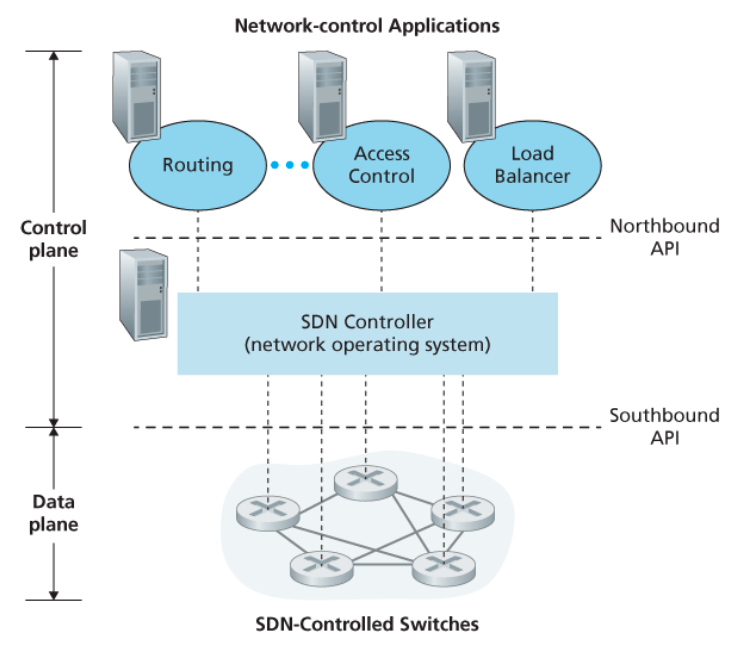
SDN 컨트롤러는
- 정확한 상태정보(e.g., 원격 링크와 스위치, 호스트들의 상태)를 유지하고,
- 이 정보를 네트워크 제어 애플리케이션들에 제공하며,
- 애플리케이션들이 하부 네트워크 장치들을 모니터하고 프로그램하고 제어까지 할 수 있도록 수단을 제공한다.
그림에서의 컨트롤러는 단일 중앙 서버의 형태이지만, 실제로 컨트롤러는 논리적으로만 중앙 집중 형태다.
(일반적으로는 협업 능력과 확장성, 높은 이용성을 갖도록 몇 개의 서버에 구현)
프로그램이 가능한 네트워크
제어 평면에서 수행 중인 네트워크 제어 애플리케이션을 통해 네트워크를 프로그램할 수 있다.
이 애플리케이션들은 SDN 컨트롤러가 제공하는 API를 이용하여 네트워크 장치들에 있는 데이터 평면을 명세하고 제어한다.
e.g.,
라우팅 네트워크 제어 애플리케이션은 SDN 컨트롤러가 갖고 있는 노드 상태 및 링크 상태 정보에 기반한 다익스트라 알고리즘을 수행하여
출발지와 목적지 사이의 종단 간 경로를 결정한다.
5.5.1 SDN 제어 평면
: SDN 컨트롤러와 SDN 네트워크 제어 애플리케이션
SDN 컨트롤러
컨트롤러의 기능은 크게 3개의 계층으로 구성된다.
네트워크 제어 애플리케이션 계층과의 인터페이스네트워크 전역 상태 관리 계층통신 계층
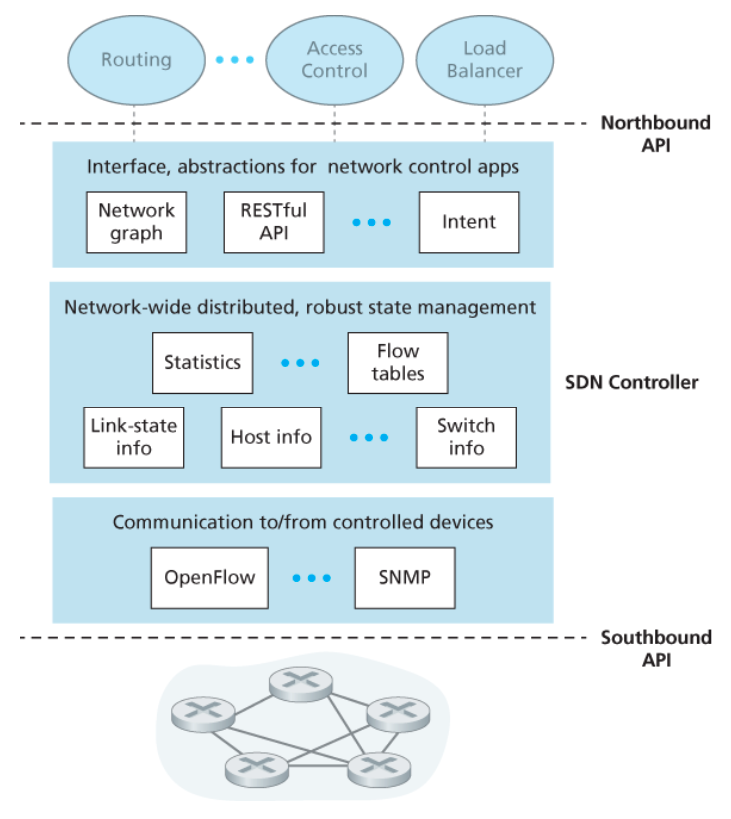
통신 계층: SDN 컨트롤러와 제어받는 네트워크 장치들 사이의 통신
💡 제어받는 장치들과의 통신
- SDN 컨트롤러가 원격의 SDN 기능이 가능한 장치들의 동작을 제어하려면 컨트롤러와 그 장치들 사이에 정보를 전달하는 프로토콜이 필요하다.
- 장치는 주변에서 관찰한 이벤트를 컨트롤러에 알려, 네트워크 상태에 대한 최신의 정보를 제공해야 한다.
컨트롤러와 제어받는 장치들 간의 통신은 ‘사우스바운드(southbound)’라고 알려진 컨트롤러 인터페이스를 넘나든다.
이 통신 기능을 제공하는 구체적 프로토콜은 OpenFlow이며, 이는 모두는 아니지만 대부분의 SDN 컨트롤러에 구현되어 있다.
네트워크 전역 상태 관리 계층
💡 네트워크 전역에 분산되고 견고한 상태 관리
SDN 제어 평면의 궁극적인 제어 결정을 위해서는
컨트롤러가 네트워크 호스트와 링크, 스위치, 그리고 SDN으로 제어되는 다른 장치들에 대한 최신 정보를 알아야 한다.
제어 평면의 궁극적인 목적은 다양한 제어 장치들의 플로우 테이블을 결정하는 것이므로 컨트롤러도 이 테이블들의 복사본을 유지해야 할 것이다.
스위치의 플로우 테이블이 가지는 카운터들과 같은 이러한 정보 조각들은 모두 SDN 컨트롤러가 유지하는 **네트워크 전역 ‘상태’**의 예들이다.
네트워크 제어 애플리케이션 계층과의 인터페이스
💡 네트워크 제어 애플리케이션들을 위한 인터페이스와 추상화
컨트롤러는 ‘노스바운드(northbound)’ 인터페이스를 통해 네트워크 제어 애플리케이션과 상호작용한다.
이 API는 네트워크 제어 애플리케이션이 상태 관리 계층 내의 네트워크 상태 정보와 플로우 테이블을 읽고 쓸 수 있도록 해준다.
SDN 컨트롤러는 외부에서 볼 때 ‘논리적으로 중앙 집중된’, 잘 짜여진 하나의 서비스로 보일 수 있지만,
이 서비스들과 상태 정보를 보관하기 위한 데이터베이스는
장애 허용성(fault tolerance)과 높은 가용성, 또는 다른 성능상의 이유로 실제로는 분산된 서버의 집합에 구현된다.
근래의 컨트롤러는 논리적으로는 중앙 집중 형태이나 물리적으로는 분리된 컨트롤러 플랫폼 구조이다.
이런 구조는 제어되는 장치와 네트워크 제어 애플리케이션에게 늘어나는 장치 수에 따라 확장 가능한 서비스와 높은 가용성을 제공한다.
5.5.2 OpenFlow 프로토콜
- OpenFlow 프로토콜은 SDN 컨트롤러와 SDN으로 제어되는 스위치 또는 OpenFlow API를 구현하는 다른 장치와의 사이에서 동작한다.
- OpenFlow 프로토콜은 TCP상에서 디폴트 포트 번호
6653을 가지고 동작한다.
컨트롤러가 제어되는 스위치로 전달하는 중요한 메시지는 다음과 같다.
-
설정: 이 메시지는 컨트롤러가 스위치의 설정 파라미터들을 문의하거나 설정할 수 있도록 한다. -
상태 수정: 이 메시지는 컨트롤러가 스위치 플로우 테이블의 엔트리를 추가/제거 또는 수정하거나 스위치 포트의 특성을 설정하기 위해 사용한다. -
상태 읽기: 이 메시지는 컨트롤러가 스위치 플로우 테이블과 포트로부터 통계 정보와 카운터값을 얻기 위해 사용한다. -
패킷 전송: 이 메시지는 컨트롤러가 제어하는 스위치의 지정된 포트에서 특정 패킷을 내보내기 위해 사용한다.
이 메시지 자체는 페이로드 부분에 보낼 패킷을 포함한다.
SDN으로 제어되는 스위치에서 컨트롤러로 전달되는 주요 메시지는 다음과 같다.
플로우 제거: 이 메시지는 컨트롤러에게 어떤 플로우 테이블 엔트리가 시간이 만료되었거나 상태 수정 메시지를 수신한 결과로 삭제되었음을 알린다.포트 상태: 이 메시지는 스위치가 컨트롤러에게 포트의 상태 변화를 알리기 위해 사용된다.패킷 전달- 4.4절에서 스위치 포트에 도착한 패킷 중에서 플로우 테이블의 어떤 엔트리와도 일치하지 않는 패킷은 처리를 위해 컨트롤러에게 전달된다고 했다.
- 어떤 엔트리와 일치한 패킷 중에서도 일부는 그에 대한 작업을 수행하기 위해 컨트롤러에게 보내지기도 한다.
이 메시지는 그러한 패킷을 컨트롤러에게 보내기 위해 사용한다.
5.5.3 데이터 평면과 제어 평면의 상호작용: 예제
아래 그림은 SDN의 제어를 받는 스위치와 SDN 컨트롤러 간의 상호작용에 대한 것이다.
-
여기서는 다익스트라 알고리즘이 최단 경로를 결정하기 위해 사용되는데,
다익스트라 알고리즘은 패킷 스위치 외부에서 별도의 애플리케이션으로 수행된다. -
패킷 스위치들이 링크 갱신 정보를 서로 간이 아닌 SDN 컨트롤러에게 전송한다.
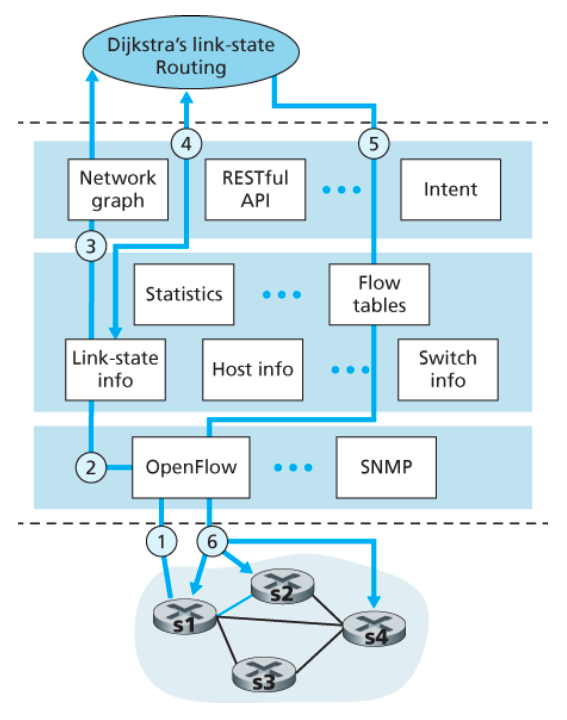
- 최단 경로 알고리즘이 사용되고 있다.
스위치 s1과 s2 사이의 링크가 단절되었다고 가정해보자.- 따라서 s1, s3, s4로 들어오고 나가는 플로우 포워딩 규칙은 변경되었으나, s2의 동작은 바뀌지 않았다고 가정한다.
- 통신 계층 프로토콜로는 OpenFlow가 사용된다.
- 제어 평면은 링크 상태 라우팅 외의 기능은 수행하지 않는다.
-
스위치 s2와의 링크 단절을 감지한 s1은 OpenFlow의
포트 상태 메시지를 사용하여 링크 상태의 변화를 SDN 컨트롤러에게 알린다. -
링크 상태 변화를 알리는 OpenFlow 메시지를 받은
SDN 컨트롤러는 링크 상태 관리자에게 알리고,
링크 상태 관리자는 링크 상태 데이터베이스를 갱신한다. -
다익스트라 링크 상태 라우팅을 담당하는
네트워크 제어 애플리케이션은 링크 상태의 변화가 있을 경우 알려달라고 이전에 등록해두었다.
이 애플리케이션이 링크 상태의 변화에 대한 알림을 받게 된다. -
링크 상태 라우팅 애플리케이션이 링크 상태 관리자에게 요청하여 갱신된 링크 상태를 가져온다.- 이 작업은 상태 관리 계층에 있는 다른 구성 요소의 도움이 필요할 수도 있다.
- 그 후 새로운 최소 비용 경로를 계산한다.
-
링크 상태 라우팅 애플리케이션은 갱신되어야 할 플로우 테이블을 결정하는 플로우 테이블 관리자와 접촉한다.
-
플로우 테이블 관리자는 OpenFlow 프로토콜을 사용하여 링크 상태 변화에 영향을 받는 스위치들의 플로우 테이블을 갱신한다.- 이 예에서는 s1, s2, s4가 이에 해당한다.
- s1 : 이제부터 s2를 목적지로 하는 패킷을 s4로 보낸다.
- s2 : 이제부터 s1로부터의 패킷을 중간 스위치 s4를 통해 받는다.
- s4 : s1에서 s2로 가는 패킷을 전달해야 한다.
💡 컨트롤러가 플로우 테이블을 마음대로 변경할 수 있기 때문에
단순히 애플리케이션 제어 소프트웨어를 바꿈으로써 원하는 어떤 형태의 포워딩 방식도 구현할 수 있다.
5.5.4 SDN: 과거와 미래
과거
SDN이 많은 관심을 받게 된 것은 비교적 최근의 현상이지만,
SDN의 기술적인 뿌리, 특히 데이터와 제어 평면의 분리를 상당히 거슬러 올라간다.
-
2004년에 [Feamster 2004, Lakshman 2004, RFC 3746]은 모두 네트워크 데이터와 제어 평면의 분리를 주장했다.
-
에탄(Ethane) 프로젝트[Casado 2007]는
(1) ‘매치 플러스 액션’ 플로우 테이블이 있는 간단한 플로우 기반 이더넷 스위치,
(2) 플로우 수용 및 라우팅을 관리하는 중앙 집중식 컨트롤러,
(3) 그리고 플로우 테이블의 어떤 엔트리와도 일치하지 않는 패킷을 스위치에서 컨트롤러로 전달하는 개념을 개척했다.- 300개 이상의 에탄 스위치로 구성된 네트워크가 2007년에 운영되었다.
- 에탄은 OpenFlow 프로젝트로 빠르게 진화했다.
미래
SDN 혁명은 ‘단순한 상용 스위칭 하드웨어와 정교한 소프트웨어 제어 평면’으로
’모든 기능이 하나로 통합된 스위치와 라우터(데이터 및 제어 평면 모두)’를 교체해나가고 있다.
네트워크 기능 가상화(network functions virtualization, NFV)로 알려진 SDN의 일반화는 단순한 상용 서버, 스위칭 및 저장소를 가지고
복잡한 미들박스(전용 하드웨어 및 미디어 캐싱/서비스를 위한 고유의 소프트웨어를 가진 미들박스)를 혁신적으로 교체하는 것을 목표로 한다.
연구의 중요한 두 번째 영역은 SDN 개념을 AS 내부 설정에서 AS 간 설정으로 확장하려는 것이다.
SDN 컨트롤러 사례연구: OpenDaylight와 ONOS 컨트롤러
일부 SDN 컨트롤러는 특정 회사를 위한 고유 제품이다.
그러나 더 많은 컨트롤러는 오픈소스이며 다양한 프로그래밍 언어로 구현된다.
가장 최근에는 OpenDaylight 컨트롤러와 ONOS 컨트롤러가 산업계에서 상당한 지지를 얻었다.
이 둘은 모두 오픈소스이며, 리눅스 재단(Linux Foundation)과 공동으로 개발 중이다.
OpenDaylight 컨트롤러
아래 그림은 ODL(OpenDaylight) 컨트롤러 플랫폼[OpenDaylight 2020, Eckel 2017]의 간략한 구조다.
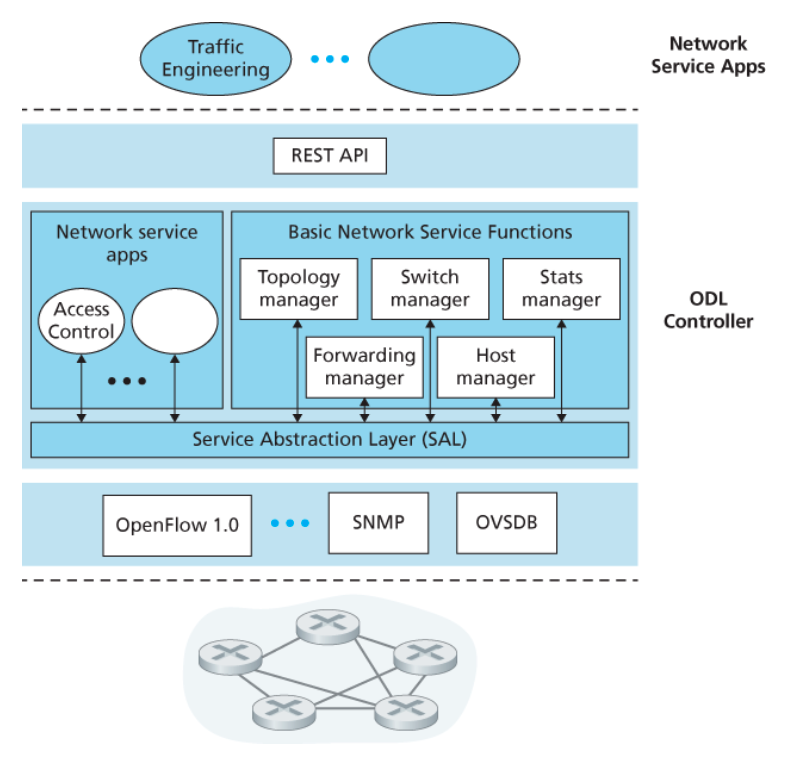
-
ODL의 기본 네트워크 서비스 기능들은 컨트롤러의 핵심부에 있다.
-
서비스 추상 계층(Service Abstraction Layer, SAL)- 컨트롤러 구성요소와 애플리케이션이 서로의 서비스를 호출하고 그들이 생성한 이벤트에 대한 알림을 받을 수 있도록 한다.
- OpenFlow와 SNMP(Simple Network Management Protocol) 및 NETCONF(Network Configuration) 같은,
ODL 컨트롤러와 제어 장치 간 프로토콜들에게 균일한 추상 인터페이스를 제공한다.
-
OVSDB(Open vSwitch Database Management Protocol)는 데이터 센터 스위칭을 관리하는 데 사용된다.
(데이터 센터 네트워킹에 대해서는 6장에서 다룸)
가장 상단의 네트워즈 조정 및 애플리케이션부는
데이터 평면의 포워딩과 방화벽 및 로드 밸런싱 같은 서비스들이 제어 장치에서 어떻게 수행될지를 결정한다.
ONOS 컨트롤러
아래 그림은 ONOS 컨트롤러[ONOS 2020]를 간략화한 모습이다.
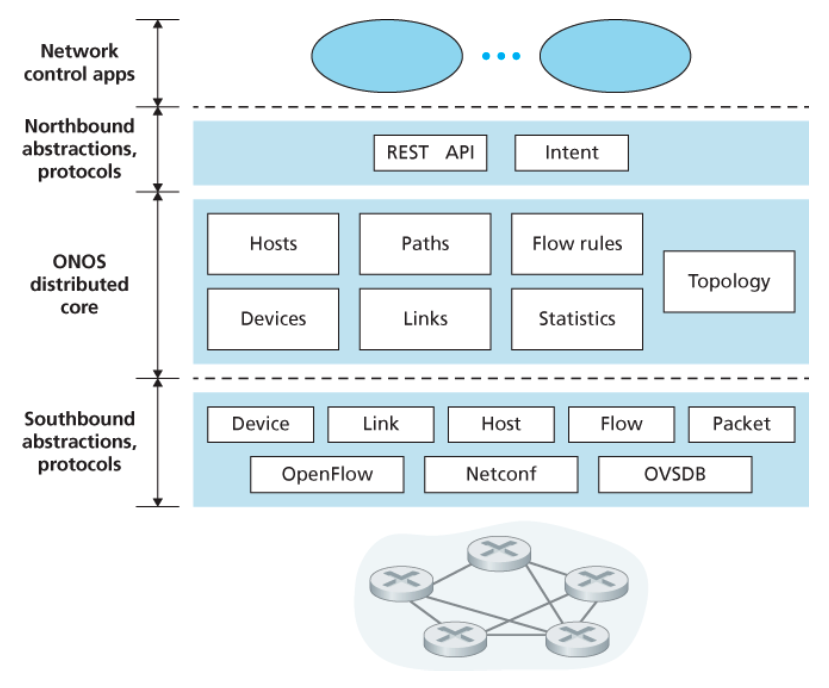
표준 컨트롤러와 유사하게 3개의 계층을 구분할 수 있다.
-
노스바운드추상화 프로토콜- ONOS는 의도(intent) 프레임워크이다.
- 이는 애플리케이션이 해당 서비스가 구체적으로 어떻게 구현되는지 몰라도
높은 수준의 서비스(e.g., 어떤 호스트 A와 B 사이의 연결을 설정)를 요청할 수 있게 해준다.
- 이는 애플리케이션이 해당 서비스가 구체적으로 어떻게 구현되는지 몰라도
- 상태 정보가 노스바운드 API를 통과하여
네트워크 제어 애플리케이션에게 동기적(직접 질의를 통해) 또는 비동기적(e.g,. 네트워크 상태가 변화했을 때 알림 기능)으로 제공된다.
- ONOS는 의도(intent) 프레임워크이다.
-
분산 코어- 네트워크 링크, 호스트, 장치의 상태는 ONOS의 분산 코어에 유지된다.
- ONOS 코어는 서비스 복제와 인스턴스 간 협력 메커니즘을 제공함으로써
상부의 애플리케이션과 하부의 네트워크 장치에게 논리적 중앙 집중형 코어 서비스의 추상화를 제공한다.
-
사우스바운드추상화와 프로토콜- 사우스바운드 추상화는 하부의 호스트, 링크, 스위치, 프로토콜의 이질성을 숨겨준다.
- 따라서 분산 코어가 장치나 프로토콜 종류에 상관없이 동작할 수 있다.
- 이 추상화 때문에 분산 코어 아래의 사우스 바운드 인터페이스는 표준 컨트롤러나 ODL 컨트롤러보다 논리적으로 높다.
5.6 인터넷 제어 메시지 프로토콜(ICMP)
인터넷 제어 메시지 프로토콜(Internet Control Message Protocol, ICMP)은 호스트와 라우터가 서로 간에 네트워크 계층 정보를 주고받기 위해 사용된다.
ICMP는 종종 IP의 한 부분으로 간주되지만, ICMP 메시지가 IP 데이터그램에 담겨 전송되므로 구조적으로는 IP 바로 위에 있다.
즉, ICMP 메시지도 IP 페이로드로 전송되며,
호스트가 상위 계층 프로토콜이 ICMP라고 표시된(상위 계층 프로토콜 번호가 1번인) IP 데이터그램을 받으면 ICMP로 내용을 역다중화한다.
ICMP 메시지는 타입(type)과 코드(code) 필드가 있고,
ICMP 메시지의 발생 원인이 된 IP 데이터그램의 헤더와 첫 8바이트를 갖는다.
이는 송신자가 오류를 발생시킨 패킷을 알 수 있도록 하기 위해서이다.
중요한 ICMP 메시지 타입들은 다음과 같다
💡 ICMP 메시지는 오류 상태를 알리기 위해서만 사용되는 것이 아니다.
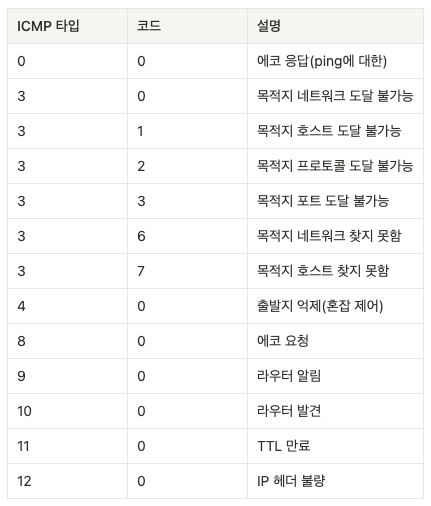
ping 프로그램
타입 8, 코드 0인 ICMP 메시지를 특정 호스트에 보낸다.- 목적지 호스트는 에코 요청을 보고 나서
타입 0, 코드 0인 ICMP 에코 응답을 보낸다.
대부분의 TCP/IP 구현은 ping 서버를 운영체제에서 직접 지원한다.
(즉, ping 서버는 별도의 프로세스가 아님)
출발지 억제 메시지
이 메시지의 원래 목적은 혼잡 제어를 수행하기 위한 것이다.
즉, 혼잡이 발생한 라우터가 호스트의 전송 속도를 늦추도록 ICMP 출발지 억제 메시지를 해당 호스트에 보낸다.
하지만 우리는 앞서 TCP가 ICMP 출발지 억제 메시지와 같은 네트워크 계층의 피드백 없이도
전달 계층에서 동작하는 자신만의 혼잡 제어 메커니즘을 갖고 있음을 보았고, 이에 이 메시지는 실제로는 잘 사용되지 않는다.
Traceroute 프로그램
아래의 방식으로 출발지 호스트는 자신과 목적지 호스트 사이에 있는 라우터들의 수와 정체, 그리고 두 호스트 간의 왕복 시간을 알게 된다.
-
출발지와 목적지 사이의 라우터 이름과 주소를 알아내기 위해
출발지의 Traceroute는 일련의IP 데이터그램을 목적지에 보낸다.- 각각의 데이터그램은 UDP 포트 번호를 가진 UDP 세그먼트를 운반한다.
- TTL 값은 첫 번째 데이터그램이 1, 두 번째는 2, 세 번째는 3, 이런 식이다.
-
출발지는 각 데이터그램에 대해 타이머를 작동시킨다.
- n번째 데이터그램이 n번째 라우터에 도착하면 해당 라우터는 데이터그램의 TTL이 방금 만료되었음을 알게 된다.
-
IP 프로토콜 규칙에 따라 라우터는 데이터그램을 폐기하고
ICMP 경고 메시지(타입 11, 코드 0)를 출발지에 보낸다.- 이 경고 메시지는 라우터의 이름과 IP 주소를 포함한다.
-
이 ICMP 메시지가 출발지에 도착하면, 출발지는
(1) 타이머로부터 왕복 시간(round-trip time, RTT),
(2) ICMP 메시지로부터 n번째 라우터의 주소와 이름을 획득한다.
Traceroute 출발지는 UDP 세그먼트 전송을 언제 멈춰야 하는지 어떻게 알까?
-
출발지가 자신이 보내는 각 데이터그램마다 차례로 TTL을 1씩 증가시키기 때문에
이들 데이터그램 중 하나는 결국 목적지 호스트에 도착하게 될 것이다. -
이 데이터그램은 없을 것 같은 UDP 포트 번호를 가진 UDP 세그먼트를 포함하고 있으므로,
목적지 호스트는포트 도달 불가능 ICMP 메시지(타입 3, 코드 3)를 출발지에 보낸다. -
출발지 호스트가 이 ICMP 메시지를 받게 되면 추가적인 탐색 패킷을 보낼 필요가 없음을 알게 된다.
5.7 네트워크 관리와 SNMP, NETCONF/YANG
네트워크 관리란 무엇인가?
[Saydam 1996]에는 이에 대해 잘 정리된, 한 문장으로 된 정의가 나온다.
네트워크 관리는 적정한 비용으로 실시간, 운용 성능, 서비스 품질 등의 요구사항을 만족시키기 위해
네트워크와 구성요소 자원을 감시, 테스트, 폴링, 설정, 분석, 평가, 제어하는
하드웨어, 소프트웨어, 인간 요소 등을 배치하고, 통합, 조정하는 것이다.
이 절에서는 이 광범위한 정의 중에서 네트워크 관리의 기초,
즉 네트워크 관리자가 자신의 일을 수행하는 데 사용하는 구조, 프로토콜, 데이터만을 다룬다.
5.7.1 네트워크 관리 프레임워크
아래 그림은 네트워크 관리의 핵심 요소들을 나타낸다.
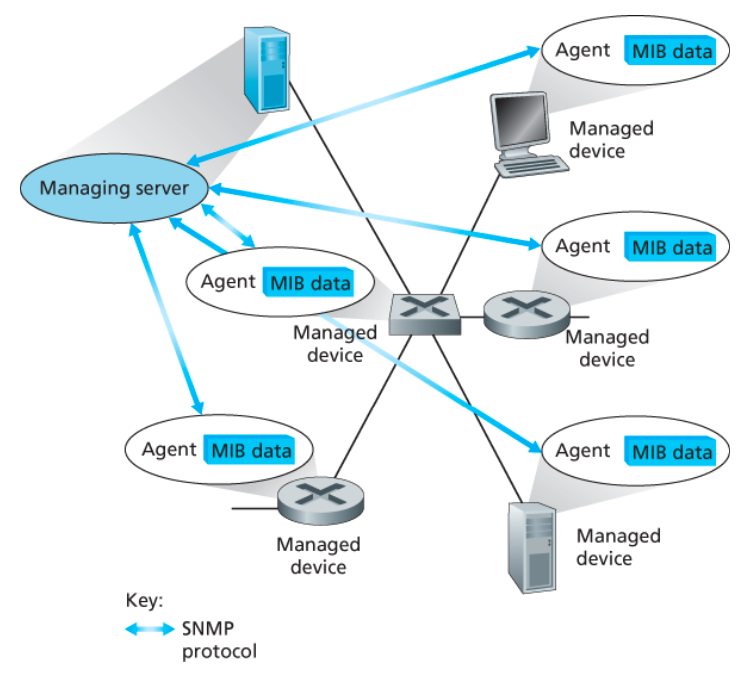
관리 서버(managing server)
관리 서버는
네트워크 운영 센터(network operations center, NOC)의 중앙 집중형 네트워크 관리 스테이션에서 동작하는,
일반적으로네트워크 관리자(network managers, 사람)와 상호작용하는 애플리케이션이다.
- 네트워크 관리 활동이 일어나는 장소로서 네트워크 관리 정보의 수집, 처리, 분석, 발송을 제어한다.
- 여기서 네트워크의 피관리 장치를 설정, 감시, 제어하기 위한 작업이 시작된다.
- 하나의 네트워크는 여러 개의 관리 서버를 가질 수 있다.
피관리 장치(managed devicE)
피관리 장치는 관리 대상 네트워크에 존재하는 네트워크 장비(소프트웨어 포함)들이다.
- e.g., 호스트, 라우터, 스위치, 미들박스, 모뎀, 온도계, 그 외 네트워크에 연결된 그 밖에 장치들
- 이 장치들은 많은 관리 가능한 요소들(e.g,. 네트워크 인터페이스 카드는 호스트나 라우터의 구성요소)과
이러한 하드웨어 및 소프트웨어 요소에 대한 설정 매개변수들(e.g., OSPF와 같은 AS 내부 라우팅 프로토콜)을 갖는다.
데이터(data)
각 피관리 장치는 ‘
상태(state)’라고 부르는, 장치와 관련된 데이터를 갖는다.
데이터의 유형들
-
설정 데이터(configuration data)- 장치 인터페이스에 관리자가 할당 및 설정한 장치 정보
- e.g., IP 주소 또는 인터페이스 속도
-
동작 데이터(operational data)- 장치가 동작하면서 획득하는 정보
- e.g., OSPF 프로토콜의 인접 항목 목록
-
장치 통계(device statistics)- 장치가 운영되면서 갱신되는 상태 표시기 및 계수기
- e.g., 인터페이스에서 삭제된 패킷 수 또는 장치의 냉각 팬 속도
관리 서버는 네트워크 토폴로지 같은 전체 네트워크와 관련된 데이터뿐만 아니라
관리 대상 장치들의 구성과 운영, 그리고 통계 데이터의 복사본도 유지 관리한다.
네트워크 관리 에이전트(network management agent)
네트워크 관리 에이전트는 관리 서버와 통신하는 피관리 장치상의 소프트웨어 프로세스다.
관리 서버의 명령과 제어에 따라 피관리 장치에 국한되는 행동을 취한다.
네트워크 관리 프로토콜(network management protocol)
네트워크 관리 프로토콜은 관리 서버와 피관리 장치들 사이에서 동작하면서
(1) 관리 서버가 피관리 장치의 상태에 대해 질의하고
(2) 에이전트를 통해 피관리 장치에 행동을 취할 수 있도록 해준다.
에이전트는 예외적인 사건을 관리 서버에게 알리기 위해 네트워크 관리 프로토콜을 사용할 수 있다.
(e.g., 부품의 고장 또는 성능 임계치의 위반)
💡 네트워크 관리 프로토콜 스스로가 네트워크를 관리하지 않는다.
대신에 네트워크 관리자가 네트워크를 관리(감시, 테스트, 폴링, 설정, 분석, 평가, 제어)할 수 있도록 기능을 제공한다.
네트워크 운영자가 위의 구성요소들을 활용하여 네트워크를 관리할 수 있는, 흔히 사용하는 세 가지 방법이 있다.
1️⃣ CLI
네트워크 운영자는
명령줄 인터페이스(Command Line Interaface, CLI)를 통해 장치에 직접 명령을 보낼 수 있다.
이러한 명령은
(1) 운영자가 피관리 장치과 물리적으로 같은 공간에 있는 경우 피관리 장치의 콘솔에 직접 입력하거나
(2) 피관리 장치 사이의 텔넷(Telnet) 또는 SSH(secure shell) 연결을 통해 전달할 수 있다.
이 방법을 통해서는 대체로 오류가 발생하기 쉽고, 대규모 네트워크를 자동화하거나 효율적으로 관리하기 어렵다.
2️⃣ SNMP/MIB
이 방식에서 네트워크 운영자는
SNMP(Simple Network Management Protocol)를 사용하여
장치의MIB(Management Information Base)에 있는 데이터를 질의하거나 설정할 수 있다.
일부 MIB 데이터는 장치 및 공급업체에 따라 다르지만,
다른 MIB 데이터(e.g., IP 데이터그램 헤더의 오류 때문에 라우터에서 버려지는 IP 데이터그램의 개수, 호스트에서 수신하는 UDP 세그먼트 개수)는
장치에 종속되지 않고 추상성과 일반성을 갖는다.
일반적으로 네트워크 운영자는
- 이 방식으로 동작 상태 및 장치 통계 정보를 질의 및 모니터링한 다음
- 명령줄 인터페이스를 사용하여 장치를 실제로 제어하고 설정한다.
💡 CLI와 SNMP/MIB 모두 장치를 개별적으로 관리한다.
SNMP/MIB로도 장치 설정 및 대규모 네트워크 관리의 어려움이 존재한다.
이로 인해 NETCONF와 YANG을 사용하는 가장 최근의 네트워크 관리 방식이 나타났다.
3️⃣ NETCONF/YANG
이 방식은 네트워크 관리에 대해 좀 더 추상적이고 네트워크 전체를 아우르는 전체론적인 관점을 취하면서도,
정확성의 제약 정도를 구체화하고 여러 장치에 대한 세세한 관리 작업을 제공하는 등 설정 관리에 훨씬 더 중점을 둔다.
YANG: 설정 및 동작 데이터를 모델링하는 데 사용되는 데이터 모델링 언어NETCONF 프로토콜: 원격 장치과 YANG 호환 작업 및 데이터를 주고받거나 원격 장치 간에 통신하는 데 사용됨
5.7.2 SNMP와 MIB
SNMP
SNMPv3(Simple Network Management Protocol version 3)는
관리 서버와 그 관리 서버를 대표하여 실행되고 있는 에이전트 사이에서 네트워크 관리 제어 및 정보 메시지를 전달하기 위해 사용된다.
요청-응답 모드(request-response mode)
이는 SNMP의 가장 흔한 사용 행태이다.
- SNMP 관리 서버는 에이전트에게
요청을 송신하고- 일반적으로 요청은 피관리 장치과 관련된 MIB 객체 값들을 질의(검색) 또는 수정(설정)하기 위해 이용
- 이를 받은 SNMP 에이전트는 이를 수행한 후 요청에 대한
응답을 보낸다.
트랩 메시지(trap message)
SNMP의 두 번째로 일반적인 사용은
에이전트가 요구받지 않았더라도 트랩 메시지라는 이름의 메시지를 관리 서버에게 전송하는 것이다.
트랩 메시지들은 관리 서버들에게
MIB 객체 값들을 변화시킨 예외 사항(e.g., 링크 인터페이스의 활성 또는 비활성)의 발생을 통지하기 위해 이용된다.
아래 표는 SNMPv2에 대한 것이며, 일반적으로 PDU(Protocol Data Unit)으로 알려진 일곱 가지 타입의 메시지를 정의하고 있다.
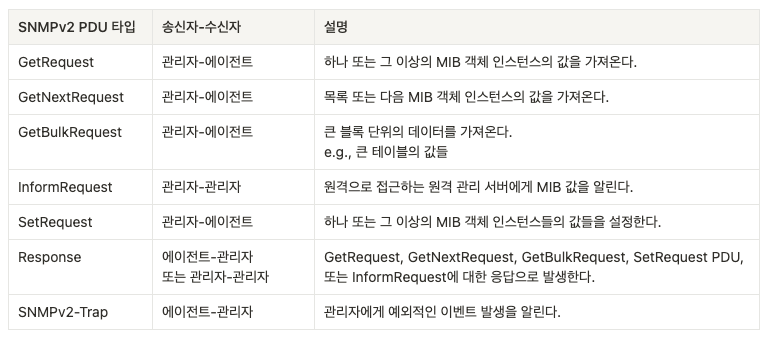
-
GetRequest,GetNextRequest,GetBulkRequestPDU들은 모두
에이전트의 피관리 장치 내 하나 이상의 MIB 객체의 값을 요청하기 위해 관리 서버로부터 에이전트로 전송된다.- 이들은 데이터 요청들의 정밀도(granularity) 면에서 다르다.
- 에이전트는 객체 식별자들과 그에 관련된 값들을
ResponsePDU에 담아 응답한다.
-
SetRequestPDU는 관리 서버가 피관리 장치 안의 하나 또는 그 이상의 MIB 객체들의 값을 설정하기 위해 사용한다.- 에이전트는 값이 제대로 설정되었음을 알려주기 위해 ‘noError’라는 오류 상탯값을
ResponsePDU에 담아 응답한다.
- 에이전트는 값이 제대로 설정되었음을 알려주기 위해 ‘noError’라는 오류 상탯값을
-
SNMPv2-Trap은 트랩 메시지로, 비동기적으로 발생한다.- 즉, 요청을 수신했을 때가 아니라 관리 서버가 통지를 요구한 이벤트가 발생했을 때 발생한다.
- 수신된 트랩 요청은 관리 서버로부터 어떤 응답도 요구하지 않는다.
아래 그림은 SNMP PDU의 포맷을 나타낸 것이다.
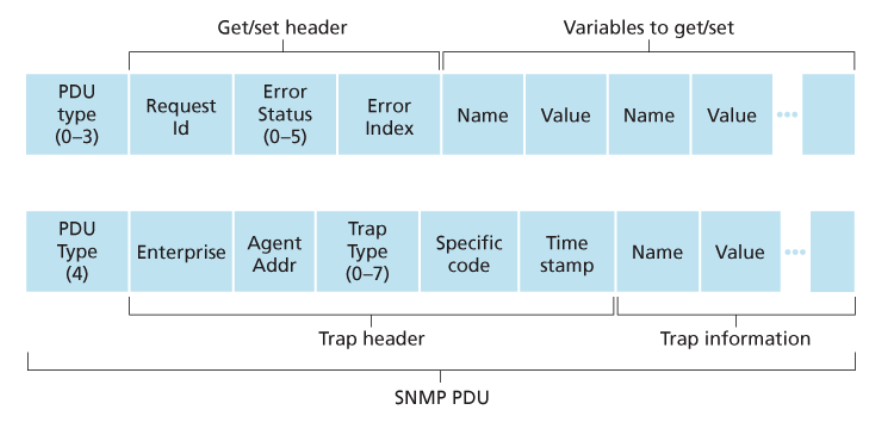
SNMP PDU들이 다른 많은 전송 프로토콜에 의해 운반될 수 있기는 하지만 일반적으로는 UDP 데이터그램의 페이로드 부분에 실린다.
그러나 UDP는 신뢰성이 보장되지 않는 전송 프로토콜이므로,
요청 또는 그에 대한 응답이 의도한 목적지에 도착한다는 보장이 없다.
따라서 아래처럼 요청 ID 필드는 관리 서버가 요청 또는 응답의 분실을 검출하는 데 이용될 수 있다.
- PDU의 요청 ID 필드는 관리 서버가 에이전트에 보내는 요청에 번호를 매기기 위해 사용된다.
- 에이전트의 응답은 수신된 요청으로부터 요청 ID 값을 취한다.
MIB
MIB 객체는 SMI(Structure of Management Information, 관리 정보 구조)라고 하는 데이터 기술 언어로 명세되는데,
이 이름은 그 기능에 대한 아무런 힌트를 주지 않는 다소 엉뚱한 이름의 네트워크 관리 프레임워크 구성요소다.
SMI는 SNMP(네트워크 관리를 위해 관리 정보 및 정보 운반을 위한 프로토콜)에서 관리 정보의 구조를 말하며,
MIB 객체를 정의하는 일반적인 규칙들의 모음이다.
MIB는 망관리 자원 정보를 구조화시킨, 대규모 관리 정보 집합을 말한다.
앞에서 SNMP/MIB 방식의 네트워크 관리에서
피관리 장치의 동작 상태 데이터가 해당 장치를 위한 MIB에 수집된 객체들로 표현된다는 사실을 배웠다.
MIB 객체는 다음과 같은 정보일 수도 있다.
- IP 데이터그램 헤더의 오류로 인해 라우터에서 버려지는 데이터그램 개수
- 이더넷 엔터페이스 카드의 반송파 감지 오류 횟수를 세는 카운터
- DNS 서버에서 실행되는 소프트웨어 버전과 같은 설명 정보
- 특정 장치가 올바르게 작동하는지 여부와 같은 상태 정보
- 어떤 목적지로의 라우팅 경로 같은 프로토콜에 특정된 정보 등..
관련된 MIB 객체들은 MIB 모듈로 합쳐진다.
5.7.3 네트워크 설정 프로토콜(NETCONF)과 YANG
NETCONF
NETCONF 프로토콜은 관리 서버과 피관리 네트워크 장치 사이에서 동작하면서
- 피관리 장치의 설정 데이터를 검색, 셋업, 수정하거나
- 피관리 장치의 동작 데이터 및 통계를 질의하거나
- 피관리 장치에서 생성된 알림을 구독하기 위한 메시지 전송 기능을 제공한다.
관리 서버는 피관리 장치를 제어하기 위해 구조화된 XML 문서 형식의 설정 내용을 보내 피관리 장치에서 활성화한다.
- NETCONF는
원격 프로시너 호출(remote procedure call, RPC) 패러다임을 사용한다. - XML로 인코딩된 프로토콜 메시지는 TCP상의
TLS(Transport Layer Security) 프로토콜과 같은
안전한 연결 지향 세션을 통해 관리 서버와 피관리 장치 사이에서 교환된다.
e.g., NETCONF <get> 명령
이 명령을 통해 서버는 장치의 설정에 대해 알 수 있다.
<?xml version="1.0" encoding="UTF-8"?>
<rpc message-id="101"
xmlns="urn:ietf:params:xml:ns:netconf:base:1.0">
<get/>
</rpc>아래는 NETCONF 세션의 예다.
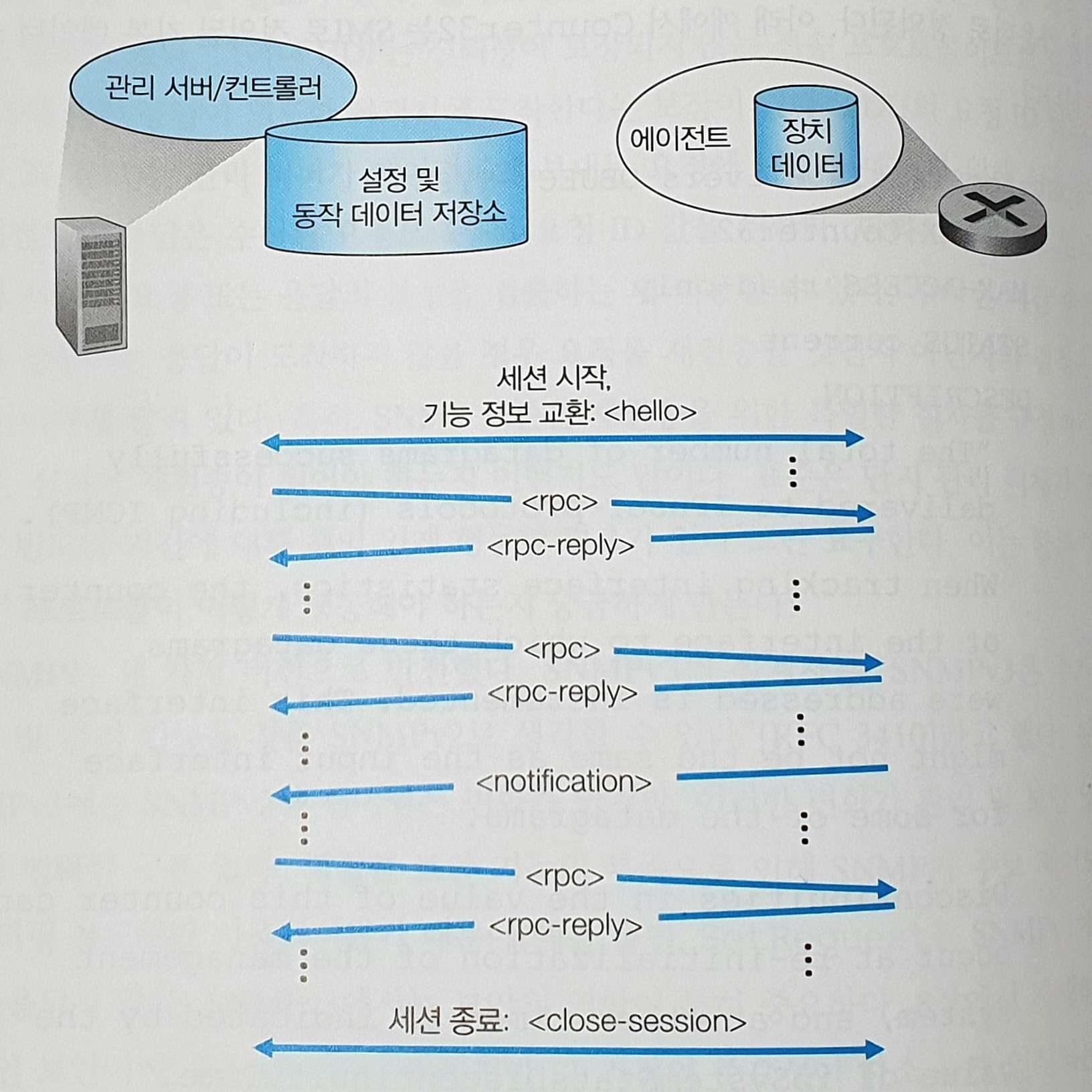
-
관리 서버는 피관리 장치와 보안 연결을 설정한다.
-
보안 연결이 설정되면 관리 서버와 피관리 장치는
<hello>메시지를 교환하고,
기본 NETCONF 명세를 보완하는 어떠한 추가 ‘기능’이 있는지를 알린다. -
관리 서버와 피관리 장치 간의 상호작용은
<rpc>와<rpc-reply>메시지를 사용하는 원격 프로시저 호출 형식을 갖는다.- 이러한 메시지는 장치 설정 데이터와 동작 데이터 및 통계를 검색, 설정, 질의, 수정하고 장치의 알림을 구독하는 데 사용된다.
-
<close-session>메시지로 세션을 종료한다.
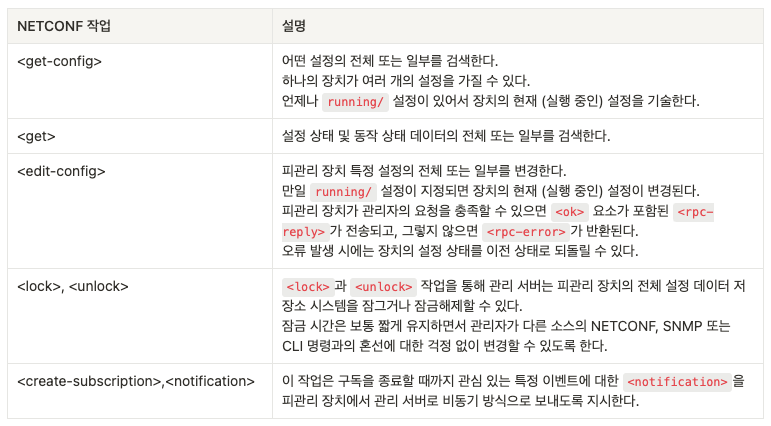
아래 표는 관리 서버가 피관리 장체에서 수행할 수 있는 여러 가지 중요한 NETCONF 작업을 보인다.
YANG
YANG은 NETCONF가 사용하는 네트워크 관리 데이터의 구조, 구문 및 의미를 정확하게 표현하는 데 사용되는 데이터 모델링 언어다.
모든 YANG 정의는 모듈에 포함되고, 장치와 해당 기능을 설명하는 XML 문서는 YANG 모듈에서 생성할 수 있다.
참고: Computer Networking: A Top-Down Approach - IT-Book-Organization