8.1 네트워크 보안이란 무엇인가?
안전한 통신에 요구되는 특성
- 기밀성 : 송신자와 지정된 수신자만이 전송되는 메시지 내용을 이해할 수 있어야 한다. 도청자가 메시지를 가로챌 수도 있으므로 도청자가 해석할 수 없도록 메시지를 어떠한 방식으로 암호화해야 한다.
- 메시지 무결성 : 통신하는 내용이 전송 도중에 변경되지 않아야 한다.
- 종단점 인증 : 통신에 참여하는 상대방이 누구인지 확인하기 위해 상대방의 신원을 확인할 수 있어야 한다.
- 운영 보안 : 오늘날 대부분 기관들의 네트워크는 공공 인터넷에 연결되어 있다. 따라서 외부로부터의 공격을 받을 수 있는 위험을 갖고 있고 대비하여 방화벽이나 보안 체계를 갖고 있어야 한다.
보안 시나리오
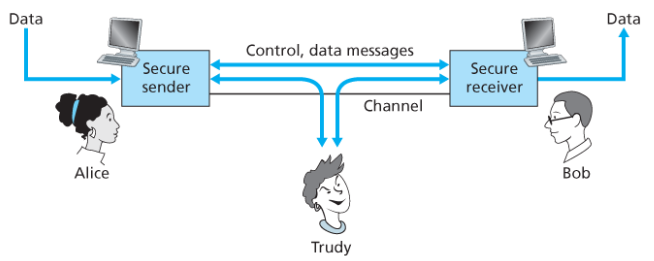
- 송신자와 수신자 : 데이터 일부 혹은 전부를 암호화하여 안전한 통신을 하려고 할 것이다.
- 침입자 : 채널상의 제어 메시지 및 데이터 메시지를 스니핑하거나 기록하고, 메시지 혹은 메시지 내용의 조작, 삽입 혹은 삭제를 시도한다.
8.2 암호의 원리
송신자가 보내는 원래 형태의 메시지를 평문 또는 원문이라고 한다.
송신자는 평문을 암호화 알고리즘을 사용해서 암호화하며, 암호화된 메시지인 암호문은 다른 침입자가 해석할 수 없다.
이 암호화 알고리즘은 모든이에게 알려져 있고, 누구나 쉽게 사용할 수 있다.
즉, 전송한 데이터를 침입자가 복원할 수 없게 해주는 비밀 정보가 필요한데 이것이 바로 키이다.
시나리오
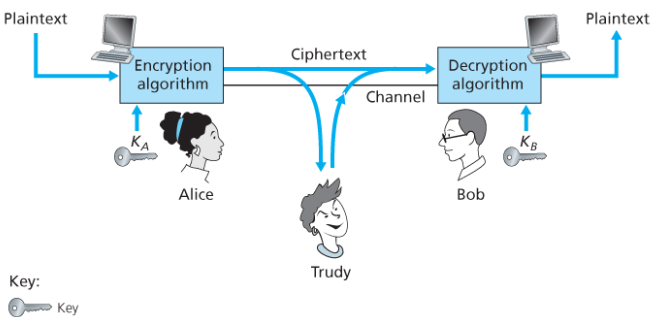
- 앨리스는 숫자나 문자의 열인 키 A를 암호화 알고리즘의 입력값으로 사용하여 암호화된 메시지
A(m)을 완성한다. - 밥은 키 B와 암호문
A(m)을 복호화 알고리즘에 입력값으로 넣어B(A(m)) = m의 출력을 받는다.
대칭키 시스템
앨리스와 밥의 키가 동일하며 이 키는 둘만의 비밀이다.
공개키 시스템
키 중 하나는 세상 모두에게 알려져 있고 다른 키는 앨리스 밥 중 한명만 알고 있다.
8.2.1 대칭키 암호화
카이사르 암호
영어로 된 원문에 대해 평문의 각 철자를 알파벳 순서로 k번째 뒤에 오는 철자로 대치한다. (철자들의 순환을 가정. z의 1번째 뒤에 오는 철자는 a다.)
여기서는 k의 값이 암호화 키가 된다.
하지만 카이사르 암호인 것을 알고 있다면 금방 암호문을 복호화할 수 있을 것이다.
단일 문자 대응 암호
카이사르 암호처럼 일정한 규칙에 따라 대치하는 대신 아무 규칙 없이 각 철자들을 고유한 대응 글자로 변환한다.
26! 정도의 문자 대응쌍이 가능하여 더 안전하다.
그러나 e나 t가 흔하게 나타나거나 3개 혹은 3개의 특정 문자가 함께 나오거나 하는 특성 탓에 암호를 해독하기 쉬워진다.
예를 들어 암호문을 사용하는 사람의 이름이 평문에 들어가 있다는 것을 안다면 즉시 알파벳 중 몇 쌍을 확정 지을 수 있다.
침입자가 갖고 있는 정보에 따른 시나리오
- 암호문만을 이용한 공격 : 평문 메시지에 대한 어떠한 정보도 없는 경우
- 알려진 평문 공격 : 침입자가 평문과 암호문에 나올 단어(이름 등)를 미리 알고 있는 경우 해당 단어에 대한 단어 쌍을 알 수 있다.
- 선택 평문 공격 : 침입자가 특정 평문 메시지를 선택하여 송신자에게 보내게 하고 이에 대응하는 암호문의 형태를 얻을 수 있다.
다중 문자 대응 암호화
여러 개의 단일 문자 대응법을 가지고 평문 메시지에서의 위치에 따라 서로 다른 단일 문자 대응 암호법을 사용한다.
즉, 같은 문자라도 평문 메시지에서의 위치에 따라 다르게 암호화 된다.
예를 들어, 단일 문자 대응법 첫번째를 C1, 단일 문자 대응법 두번째를 C2라고 해보자.
평문의 첫번째 메시지는 C1, 두번째는 C2, 세번째는 C1 ... 식으로 평문 메시지의 위치에 따라 단일 문자 대응법을 달리 한다.
블록 암호화
현재 TLS, PGP, IPsec 등에 사용되는 암호화 기법이다.
오늘날 널리 활용되는 블록 암호화 방법에는 AES, DES, 3DES 등이 있다.

블록 암호화에서는 메시지가 k 비트의 블록 단위로 쪼개어져 암호화 된다.
k 비트의 평문은 k 비트 블록의 평문을 k비트 블록의 암호문으로 일대일 사상 시킨다.
위 표와 같이 사상한다면 010110001111은 101000111001로 암호화 된다.
k 비트에 대해서 총 (2^k)!로 사상의 수가 천문학적으로 커진다.
그러나 k=64라고 하면 송신자와 수신자 모두 개의 입력 테이블에 대한 테이블을 유지해야 하는데 이는 실행이 거의 불가능하고, 키가 바뀌면 큰 테이블을 재생성해야 하기 때문에 실제 사용은 불가능하다.
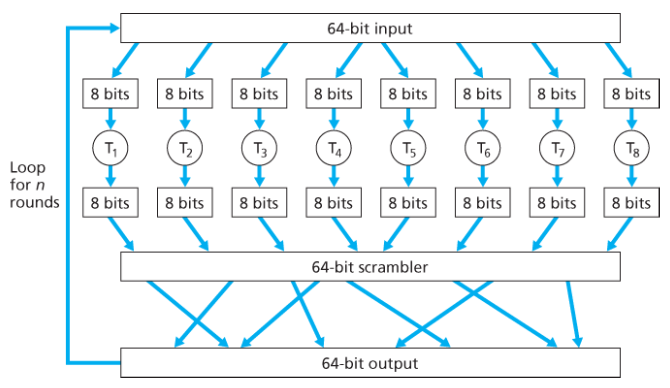
대신 블록 암호화 기법은 입출력 블록의 순열 테이블을 임의로 모방 생성하는 함수를 사용한다.
위 그림은 k=64일 때의 예시를 나타낸다.
시나리오
- 64 비트의 블록을 8 비트씩 8개의 청크로 나눈다.
- 각 8 비트 청크는 관리 가능한 크기인 8비트 입력 블록에 대응하는 8비트 출력 블록을 가진 테이블에 의해 처리된다.
- 각 청크는 관리 가능한 크기인 8 비트 입력 블록에 대응하는 8 비트 출력 블록을 가진 테이블에 의해 처리된다.
- 암호화된 청크는 하나의 64 비트 블록으로 다시 합쳐진다. 각각의 위치는 뒤섞여서 합쳐진다.
- 64 비트 블록을 다시 입력부로 넣는다.
- 이 사이클을 n번 반복한다. 각 입력 비트가 대부분의 최종 출력 비트들에 영향을 미치게 하기 위해서이다. 라운드를 한번만 수행하면 하나의 입력 비트는 8개의 출력 비트에만 영향을 끼친다.
이 블록 암호화 알고리즘의 키는 블록을 뒤섞는 규칙이 알려져 있다면 8개의 순열 테이블이다.
암호 블록 체이닝
네트워크 애플리케이션에서는 일반적으로 긴 메시지를 암호화할 필요가 있는데, 블록 암호화를 이용하면 미묘하지만 중요한 문제가 발생한다.
2개 이상의 평문 블록이 동일하다면 같은 암호문을 생성해내고, 공격자는 동일한 암호문으로 원문을 추측해낼 수 있는 가능성이 생긴다.
여기에 하위 프로토콜에 대한 지식까지 활용하면 전체 메시지를 복호화할 수 있다.
이를 해결하기 위해 같은 평문 블록에 대해 다른 암호문 블록이 생성될 수 있도록 임의성을 추가할 수 있다.
시나리오
- 송신자는 i번째 평문 블록 m(i)를 위해 k비트 길이의 임의의 수 r(i)를 생성한다.
K(r(i) xor m(i)) = c(i)암호문을 만든다. r(i)로 인해 m(i)와 m(j)가 같아도 암호문은 달라지게 된다.- 수신자는 r(i)와 c(i)를 받아서
m(i) = K(c(i)) xor r(i)를 수행한다. 침입자는 암호화되지 않은 r(i)를 볼 수는 있지만 키를 알지 못하므로 평문 m(i)를 복호화할 수 없다.
그러나 송신자는 2배의 비트를 더 보내야 하고 2배의 대역폭을 필요로 한다.
이 문제를 해결하기 위해 암호 블록 체이닝(Cipher Block Chaining, CBC) 기법을 사용한다.
CBC 시나리오
- 메시지를 암호화하기 전에 송신자는 초기화 벡터라 불리는 임의의 k 비트열 c(0)을 생성한다.
- 송신자는 c(0)를 수신자에게 보낸다.
- 첫번째 블록에 대해 송신자는
c(1) = K(m(1) xor c(0))을 계산한다. - 암호화된 c(1)을 수신자에게 보낸다.
- 송신자는 이를 계속
c(i) = K(m(i) xor c(i-1))암호문 블록을 생성하고 보낸다.- 수신자는 c(i-1)을 알고 있으므로 계속 복호화할 수 있다.
- 마찬가지로 같은 평문을 가지고 있어도 다른 암호문을 갖게 된다.
- 침입자는 암호화되지 않은 c(0)을 볼 수는 있지만 키를 알지 못하므로 평문 m(i)를 복호화할 수 없다.
- 송신자는 하나의 초기화 벡터만 더 전송하면 되므로 대역폭 증가량이 미미하다.
8.2.2 공개키 암호화
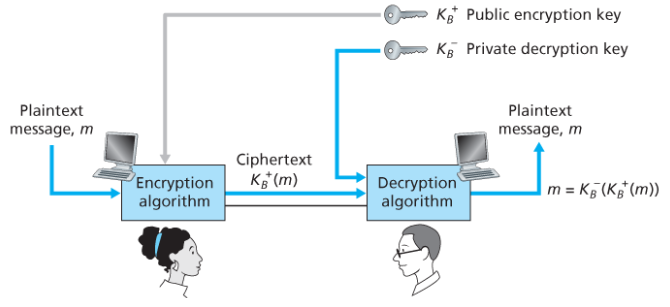
공개키 암호화에서는 송수신자가 각각 키를 갖는다기보다 수신자가 2개의 키를 갖는다.
하나는 세상 모두에게 알려진 공개키이고, 다른 하나는 수신자만 아는 개인키이다.
시나리오
- 송신자는 수신자에게 메시지를 보내기 위해 수신자의 공개키를 확인한다.
- 수신자의 공개키로 메시지를 암호화하고 송신한다.
- 수신자는 자신의 개인키로 암호문을 복호화 알고리즘을 사용하여 복호화한다.
RSA
RSA는 모듈로 n 연산(나머지)을 많이 사용한다.
모듈로 연산의 유용한 성질
[(a mod n)+(b mod n)] mod n = (a+b) mod n
[(a mod n)-(b mod n)] mod n = (a-b) mod n
[(a mod n)*(b mod n)] mod n = (a*b) mod n
// 3번째 성질로부터 나오는 식
(a mod n)^d mod n = a^d mod n공개키와 개인키의 선택
- 2개의 큰 소수 p와 q를 선택한다. 값이 클수록 RSA를 깨기가 어려워지지만 암호화 복호화를 수행하는 데 시간이 더 걸린다.
n = pq,z = (p-1)(q-1)식을 계산한다.- 1을 제외하고 z의 서로소 n보다 작은 e를 선택한다. (암호화 encryption의 e를 따왔다.)
- ed-1이 z로 정확히 나누어 떨어지는 숫자 d를 찾는다. (복호화 decryption의 d를 따왔다.) 이 말은 즉슨,
ed mod z = 1이 성립하도록 d를 선택한다와 같다. - 공개키는 숫자쌍**(n, e)** 이다. 개인키는**(n, d)** 이다.
큰 p와 q를 고르는 방법, 지수 연산 방법, e와 d를 고르는 방법 등은 이 책의 범위에서 벗어나므로 생략한다.
알고리즘 시나리오
- 암호화를 위해 공개키 (n, e)를 활용한다. 메시지에 e승을 하고 이를 n으로 나눈 나머지를 계산한 값이 암호문 c가 된다. 메시지는 k 비트열로 하나의 정수와 같아서 e의 제곱을 할 수 있다.
c = m^e mod n
- 수신된 암호 메시지 c를 복호화하기 위해 개인키 (n, d)를 활용한다.
m = c^d mod n = m^ed mod n을 수행하여 복호화한다.
예시
수신자가 p=5, q=7로 선택한다.
이때 n = 35, z = 24가 된다.
5와 z가 공통인수가 없으므로 e = 5를 선택한다.
5x29-1 (즉, ed-1)이 24로 나누어떨어지므로 d = 29를 선택한다.
이제 공개키 (35, 5)와 비밀키 (35, 29)가 완성되었다.
이제 평문 m을 암호화 복호화 해보자.
m은 비트열 1100으로 숫자 12에 대응된다고 가정하자.
- 암호화 :
m^e = 248832,17(c) = 248832(m^e) mod 35(n) - 복호화 :
12(m) = 4819685721067509150915091411825223071697(c^d) mod 68(n)
세션키
RSA에 필요한 지수 연산은 시간이 많이 필요하여 실제로 종종 대칭키 암호화와 함께 사용된다.
시나리오
- 송신자는 데이터 암호화에 사용할 세션키를 고른다. 세션키는 대칭키 암호화에 사용된다. 즉, 밥에게 세션키를 알려야 한다.
- 송신자는 수신자의 공개키로 세션키를 RSA 암호화한다.
- 수신자는 암호문을 받고 자신의 개인키로 복호화한다.
- 수신자는 세션키를 얻고, 송신자가 보낸 데이터를 복호화할 수 있다.
RSA가 동작하는 이유
m = m mod n = m^ed mod n임을 증명하면 된다.
정수론에 의하면 p와 q가 소수이고 n = pq, z = (p-1)(q-1)이면, x^y mod n이 x^(y mod z) mod n과 같다.
즉, 다음과 같은 식을 얻을 수 있다.
m^ed mod n = m^(ed mod z) mod n
ed mod z = 1이 되도록 e와 d를 선택하였으므로, m = m mod n = m^ed mod n이다.
여기서 e와 d는 단순 제곱이므로 둘을 바꿔도 정상 동작한다.
8.3 메시지 무결성과 전자서명
메시지 무결성
- 메시지가 정말 해당 출발지로부터 왔는가?
- 메시지가 전달되는 도중 변경되지는 않았는가?
8.3.1 암호화 해시 함수
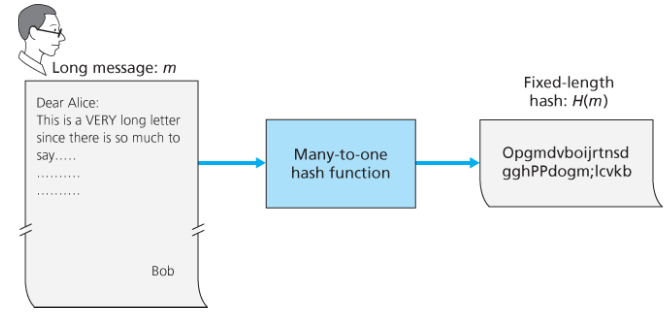
해시 함수는 입력 m을 받아서 해시라 불리는 고정된 크기의 문자열 H(m)을 계산해낸다.
암호화 해시 함수는 H(x) = H(y)가 되는 서로 다른 두 메시지 x와 y를 찾는 일이 산술적으로 실행 불가능하다.
즉, (m, H(m))이 원래 메시지와 그 메시지에 대해 송신자가 만들어낸 해시값이라고 할 때, 침입자가 원래 메시지와 동일한 해시값을 갖는 다른 메시지 y를 위조해낼 수 없다.
인터넷 체크섬과 같은 간단한 체크섬은 같은 값을 만들기 쉬워 암호화 해시 함수로 사용하기에는 너무 허술하다.
MD5, SHA
MD5 해시 알고리즘이 오늘날 널리 쓰이고 있다.
- 덧붙이는 단계 : 하나의 1을 메시지 뒤에 붙이고 충분히 많은 0을 뒤에 덧붙여서 메시지 길이가 단위 길이 조건을 만족시킨다.
- 추가 단계 : 덧붙이기 전 메시지 길이를 64비트로 표현하여 추가
- 어큐뮬레이터 초기화
- 루프 단계 : 메시지를 16워드 길이의 단위 블록들로 나누어 4개 라운드로 처리한다.
SHA 알고리즘은 MD4에 사용된 원리와 유사한 원리를 사용하여 널리 사용된다.
8.3.2 메시지 인증 코드(MAC)
메시지 무결성을 얻는 과정
- 송신자는 메시지 m을 생성하고 해시값 H(m)을 만든다. 이때 SHA 등이 사용된다.
- 송신자는 메시지 m에 H(m)을 첨부하여 확장 메시지 (m, H(m))을 생성한 후 수신자에게 보낸다. (수신자의 입장에서는 (m, h)로 보임)
- (m, h)를 받은 수신자는 H(m)을 계산하고 이것이 h와 같다면 문제 없이 처리되었음을 확인한다.
이때, 침입자가 (m', H(m'))을 자신이 수신자라고 주장하며 보내면 위 단계를 통과하고 부적절한지 알 수 없다.
인증키를 사용한 메시지 무결성
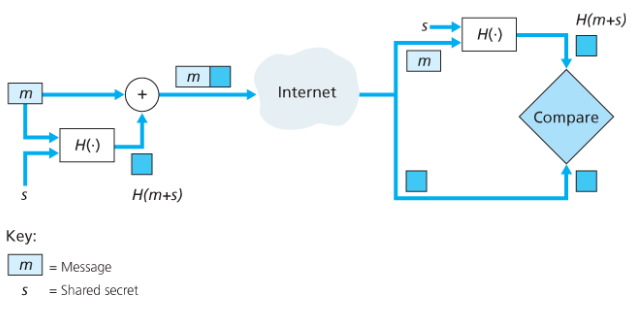
송신자를 확인하기 위해 송신자 수신자는 비트열 형태의 인증키인 비밀키를 공유하여야 한다.
- 송신자는 메시지 m을 생성하고 인증키 s와 합하여 m+s를 만들고, H(m+s)를 생성한다. H(m+s)를 메시지 인증 코드(message authentication code, MAC)라고 부른다. (이는 링크 계층의 MAC 주소와는 다르다.)
- 송신자는 (m, H(m+s))를 보낸다. (수신자의 입장에서는 (m, h)로 보임)
- 수신자는 (m, h)를 받으면 H(m+s)를 계산하고 값이 h와 같다면 문제가 없다고 결론 짓는다.
메시지 인증 코드는 복잡한 암호화 알고리즘을 필요로 하지 않는다.
MD5와 SHA와 함께 사용되는 메시지 인증코드는 HMAC으로 가장 많이 사용되는 표준이다.
통신 개체들에게 인증키를 전달하는 방법은 네트워크 관리자가 각각의 라우터에 직접 접근하거나 인증키를 각 라우터의 공개키로 암호화하여 네트워크를 통해 전달할 수 있다.
8.3.3 전자 서명
디지털 세계에서 문서의 소유자를 명시하거나 어떤 사람이 문서의 내용에 동의했다는 것을 표시하길 원하고, 전자 서명은 디지털 세계에서 이러한 목적으로 사용된다.
서명 시 실제로 그 사람이 서명했다는 사실, 그리고 오직 그 사람만이 문서에 서명할 수 있었다는 사실을 증명할 수 있어야 한다.
공개키 암호화 방법은 개인키와 공개키를 따로 가지고 있어 전자 서명에 효과적이다. (다른 사람은 개인키로 서명할 수 없다.)
시나리오
- 서명자는 문서 m을 서명하려 한다.
- 서명자는 자신의 개인키로 K(m)을 만든다. 이것이 바로 전자 서명이다. 전자서명 K(m)은 서명자의 개인키로 만들어져 서명자만 만들 수 있다.
- 전자서명 K(m)을 받은 사람들은 서명자의 공개키를 사용해 원래의 m을 다시 확인할 수 있다. 즉, 공개키의 주인인 서명자가 쓴 서명이라는 것이 확인된다. 어느 한 사람이 중간에 문서를 조작해 m'을 만들었어도 m과 같지 않으므로 유효하지 않음을 알 수 있다. 즉, 메시지 무결성을 확인할 수 있다.
자신의 개인키로 먼저 암호화하고 공개키로 복호화해도 되는 이유는, m^ed mod n = m^de mod n = m mod n이기 때문이다.
m 자체에 암호화 복호화를 하면 계산의 부하가 심하다.
이때, 해시 알고리즘을 사용하여 해결할 수 있다.
즉, m을 H(m)으로 표현되는 고정 길이의 지문을 계산해내고, K(H(m))을 계산하여 계산의 부하를 줄인다.
서명자 시나리오
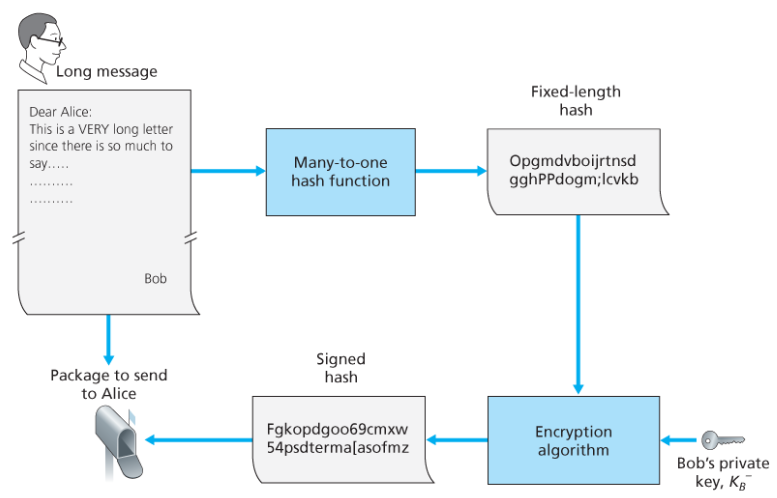
- 메시지 m을 해시 알고리즘을 이용하여 고정 길이로 바꿔 H(m)을 만든다.
- H(m)을 자신의 개인키로 암호화 한다.
- (m, K(H(m)))을 보낸다.
수신 시나리오
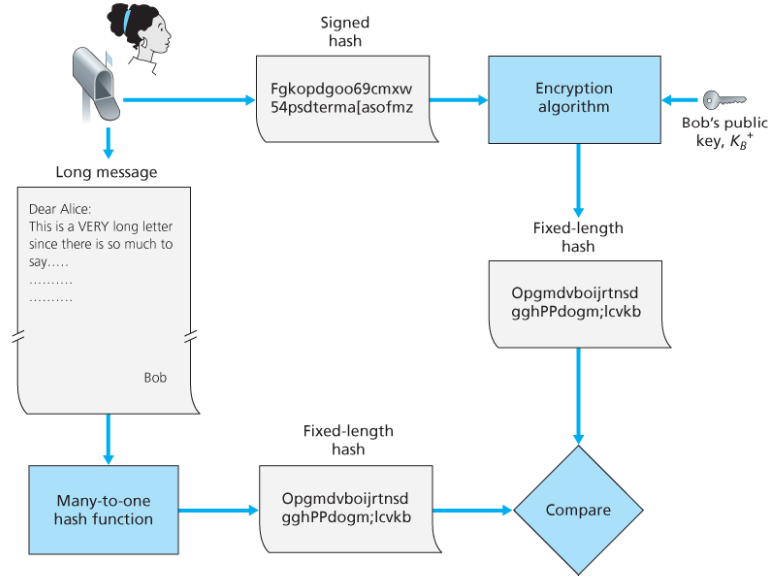
- 서명자로부터 (m, K(h))를 받는다.
- 서명자의 공개키로 K(h)를 복호화하여 h를 알아낸다.
- m을 해시 알고리즘을 이용하여 H(m)으로 만들고 h와 일치하는지 알아낸다.
MAC vs 전자서명
전자 서명은 인증기관과 함께 공개키 하부 구조를 요구하기 때문에 MAC에 비해 더 무거운 기술이다.
많은 프로토콜에서는 MAC이 사용된다.
공개키 인증
전자 서명에서는 공개키가 특정 통신 개체에 속한다는 것을 보증하여야 한다. (IPsec과 TLS를 포함한 많은 보안 네트워킹 프로토콜에서 사용된다.)
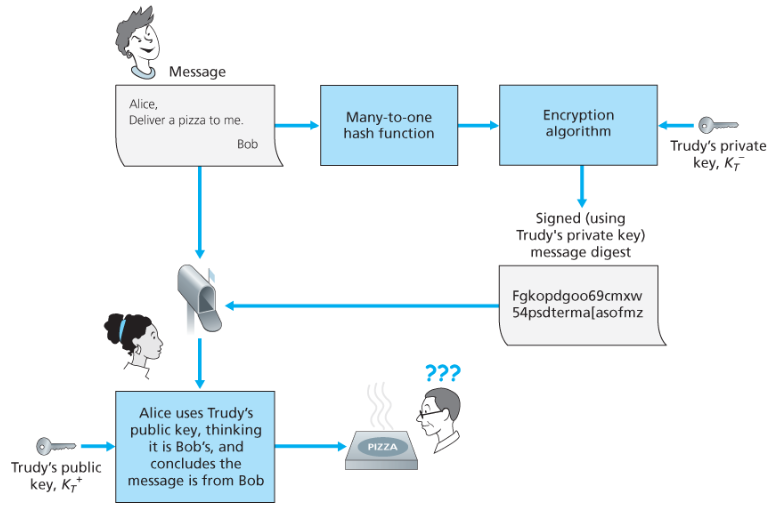
중간에 침입자가 자신이 서명자라고 주장하며 메시지를 보내는데, 이때 공개키를 자신의 공개키를 담아 보낸다.
수신자는 침입자의 공개키를 사용해 메시지를 복호화할 것이고, 수신자는 서명자가 쓴 서명임을 확신할 것이다.
즉, 공개키 암호를 사용하려면 서명자의 공개키라고 생각되는 것이 정말 서명자의 것인지 확인하여야 한다.
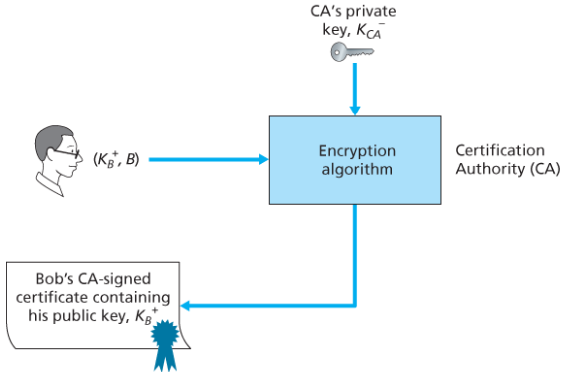
공개키가 어떤 통신 개체(서명자)의 것인지 보증하는 일은 일반적으로 CA(인증 기관)에서 담당한다.
CA는 신원을 확인하고 인증서를 발행한다.
- CA는 어떤 개체(사람, 라우터)가 스스로 주장하는 자신의 신분이 바로 그 개체가 맞는지 확인한다. 인증에 정해진 방법은 없고 CA가 적절한 방법으로 엄격하게 식별자 검증을 수행하리라는 점을 신뢰해야 한다.
- 일단 CA가 신원을 확인하면, CA는 개체의 공개키와 신분 확인서를 결합한 인증서를 만든다. 인증서에는 CA가 서명한다.
8.4 종단점 인증
종단점 인증이란 하나의 통신 개체가 다른 개체에게 자신의 신원을 컴퓨터 네트워크상으로 증명하는 작업이다.
예를 들어, 전자 메일 사용자가 서버에 신원을 입증할 수 있다.
서로 간의 인증은 인증 프로토콜의 한 부분으로서 교환된 메시지와 데이터만을 기반으로 수행되어야 한다.
대부분의 인증 프로토콜은 다른 프로토콜을 수행하기 전에 수행된다. 즉, 인증 후에 작업을 수행한다.
인증 프로토콜 ap 2.0
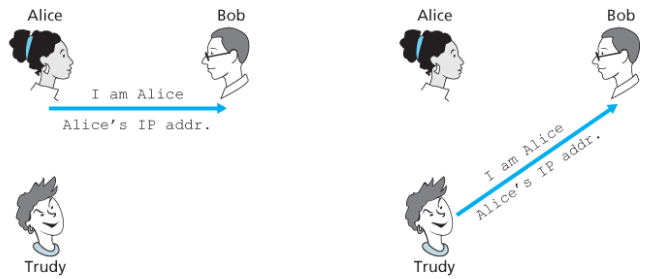
송신자가 이미 알려진 네트워크 주소(IP 주소)를 가지고 통신을 한다면 수신자는 인증 메시지를 가지고 온 IP 데이터그램 출발지 주소가 송신자의 IP 주소와 일치하는지 확인함으로써 앨리스를 인증할 수 있다.
그러나 IP 데이터그램을 생성해서 원하는 출발지 IP 주소를 넣고 그 데이터그램을 라우터로 보낼 수 있으므로 이는 안전하지 못하다.
예를 들어, 침입자가 가짜 출발지 주소를 쓰고 데이터를 보낼 수 있는데 이 방법은 IP 스푸핑의 한 형태이다.
침입자가 출발지 주소를 바꾸지 못하게 하면 되겠지만, 이는 강제할 수 없다.
인증 프로토콜 ap 3.0
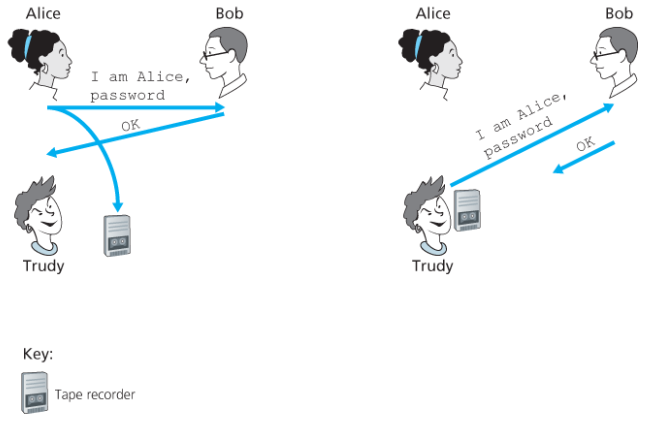
인증자와 인증 받는 사람 간에 공유된 비밀번호를 사용할 수 있다.
지메일, 페이스북 등 많은 서비스가 비밀번호 인증을 사용한다.
그러나 이 프로토콜은 안전하지 못하다.
침입자가 송신자의 통신을 도청한다면 송신자의 비밀번호를 알아낼 수 있고, 이후 송신자인 척 할 수 있다.
인증 프로토콜 ap 3.1
비밀번호를 암호화하여 비밀번호를 엿듣는 것을 막을 수 있다.
송신자와 수신자는 대칭 비밀키를 공유하여 비밀번호를 암호화 복호화할 수 있다.
그러나 수신자는 재생 공격(playback attack)의 위험에 노출되어 있다.
침입자는 도청하여 송신자의 암호화된 비밀번호를 저장했다가 나중에 그대로 수신자에게 보낸다. 즉, 송신자인 척 할 수 있다.
인증 프로토콜 ap 4.0
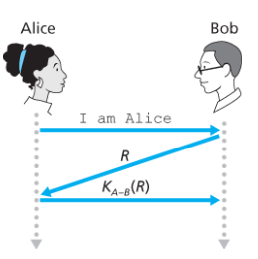
넌스(nonce)는 프로토콜이 평생에 단 한 번만 사용하는 숫자를 뜻한다.
시나리오
- 송신자는 메시지를 보낸다.
- 수신자는 넌스 R을 선택하고 그것을 송신자에게 보낸다.
- 송신자는 대칭 비밀키를 이용하여 그 넌스를 암호화하고, 암호화된 넌스 K(R)을 수신자에게 보낸다. 해당 송신자가 다음에 또 통신을 하면 R이 바뀌어도 비밀키를 알고 있으므로 또 인증을 받을 수 있다. 그러나 침입자라면 비밀키를 모르고 있으므로 암호화할 수 없다.
- 수신자는 상대방이 대칭 비밀키를 알고 있으므로 상대방인 것을 확인한다.
8.5 전자메일의 보안
보안은 인터넷 프로토콜 스택 위쪽 4개 계층의 어느 곳에서나 보안 서비스를 제공할 수 있다.
보안이 특정 애플리케이션 계층 프로토콜을 위해 제공되면 그 프로토콜을 사용하는 애플리케이션은 보안 서비스를 사용할 수 있게 된다.
보안 기능이 하나 이상의 계층에서 제공되는 이유
보안은 네트워크 계층에서 제공하는 것으로 충분하지 않을까?
- 네트워크 계층에서 데이터그램의 모든 데이터를 암호화하고 IP 주소를 인증함으로써 '전면적 범위'의 보안을 제공하더라도 사용자 레벨의 보안은 제공할 수 없다. 예를 들어, 인터넷 상거래 사이트는 물건을 구입하려는 고객을 인증하는 데 IP 계층 보안에만 의존할 수는 없다.
- 프로토콜 상위 계층에서 보안 서비스를 포함한 새로운 인터넷 서비스를 구현하는 일이 점차 쉬워지고 있다.
8.5.1 보안 전자메일
보안 전자메일 시스템을 만들기 위해 암호화 원리들을 이용해보자.
기밀성
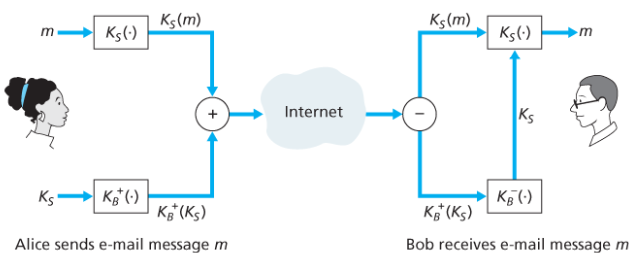
메시지를 대칭키 기술(AES, DES 등)으로 암호화 복호화하여 기밀성을 얻을 수 있다.
그러나 송수신자만 대칭키를 알기에 어렵기 때문에 공개키 암호화(RSA)를 고려하게 된다.
그러나 RSA를 통해 메시지를 암호화 복호화한다면 계산 부하가 너무 심해서 실질적으로 쓸 수 없다.
이를 위해 세션키를 사용한다.
- 송신자는 임의의 대칭 세션키 Ks를 선택한다. 이 대칭 세션키는 AES나 DES에 사용된다.
- Ks로 메시지 m을 암호화하여 암호문 1을 얻는다.
- Ks는 송신자의 공개키로 암호화하여 암호문 2를 얻는다.
- 이 두 개의 암호문을 수신자에게 보낸다.
- 수신자는 자신의 개인키로 암호문 1을 복호화하여 Ks를 얻을 수 있다.
- 얻은 Ks로 암호문 2를 복호화하여 m을 얻을 수 있다.
이렇게 기밀성을 얻을 수 있다.
송신자 인증과 메시지 무결성
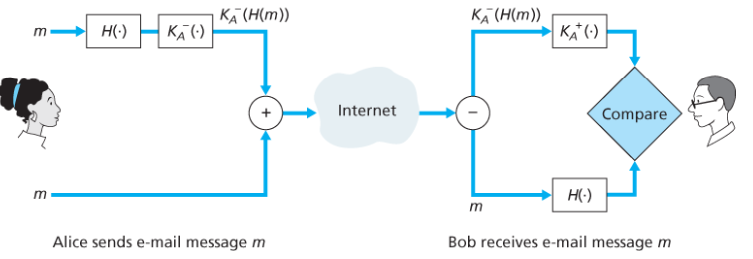
이 둘을 얻기 위해 전자서명과 해시 알고리즘을 이용한다.
- 송신자는 메시지 요약문을 얻기 위해 m에 해시함수를 적용하여 H(m)을 얻는다.
- 전자 서명을 만들기 위해 해시의 결과를 자신의 개인키로 암호화한다.
- 메시지 m과 전자서명을 수신자에게 보낸다.
- 수신자는 송신자의 공개키로 전자서명을 복호화한다.
- 메시지 m에 해시 알고리즘을 적용한 결과와 4의 결과를 비교하여 같으면 보낸 사람을 확인할 수 있고, 메시지의 무결성을 확인할 수 있다.
통합
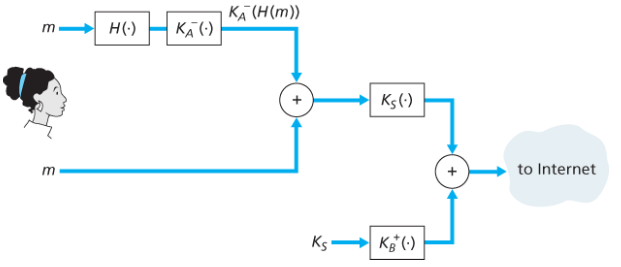
- 먼저 송신자 인증과 무결성 과정을 통해 얻은 메시지와 전자서명 꾸러미를 만든다.
- 이 꾸러미를 메시지 취급하여 기밀성 과정을 통해 수신자에게 전달한다.
- 수신자는 순서대로 복호화하여 확인한다.
그러나 수신자는 송신자의 공개키를 알아야 하고, 송신자는 수신자의 공개키를 알아야 하므로 CA를 통해 공개키를 인증 받아야 한다.
8.5.2 PGP(Pretty Good Privacy)
PGP는 암호화 기법의 좋은 예로 본질적으로 위 통합과 동일하다.
- PGP가 설치되면 소프트웨어는 사용자를 위한 공개키 쌍을 만든다.
- 공개키는 사용자 웹사이트에 게시되거나 공개키 서버에 놓인다.
- PGP 공개키는 사용자간 신뢰의 그물(web of trust) 속에서 인증된다.
- 어떤 PGP 사용자들은 키 서명을 위한 모임을 열어 같은 물리적 공간에 모여서 공개키를 교환하고 그들의 개인키로 서명하는 것으로 서로의 키를 보증한다.
- 개인키는 비밀번호로 보호된다. 개인키를 사용하려면 사용자는 비밀번호로 인증해야 한다.
- PGP는 전자메일과 같은 방식으로 사용자에게 메시지를 전자서명하거나 암호화하거나 둘 다 하거나 하는 선택지를 제공한다. 개인키, 공개키, 해시 알고리즘, RSA가 있으니 모두 가능하다.
8.6 TCP 연결의 보안: TLS
보안 서비스가 추가되어 향상된 TCP 버전을 흔히 TLS(Transport Layer Security)라고 부른다.
TLS는 기밀성, 데이터 무결성, 서버인증과 클라이언트 인증을 통해 TCP를 향상하여 보안 서비스를 제공한다.
TLS는 TCP를 보호하기 때문에 TCP 상에서 일어나는 어떠한 애플리케이션에든 사용될 수 있다.
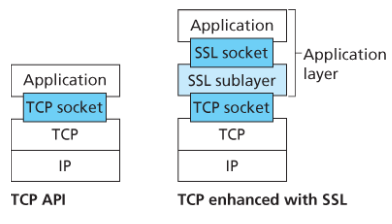
TLS는 소켓을 사용하는 간단한 API를 제공하는데, TCP의 API와 유사하다.
TLS는 애플리케이션 계층에 존재하나 개발자의 관점에서는 보안 서비스로 강화된 TCP 서비스를 제공하는 트랜스포트 프로토콜이다.
8.6.1 TLS 개요: almost TLS
TLS를 이해하기 위해 TLS의 단순화된 버전인 almost-TLS를 먼저 설명한다.
almost-TLS는 핸드셰이크, 키 유도, 데이터 전송이라는 세 단계로 되어 있다.
핸드셰이크
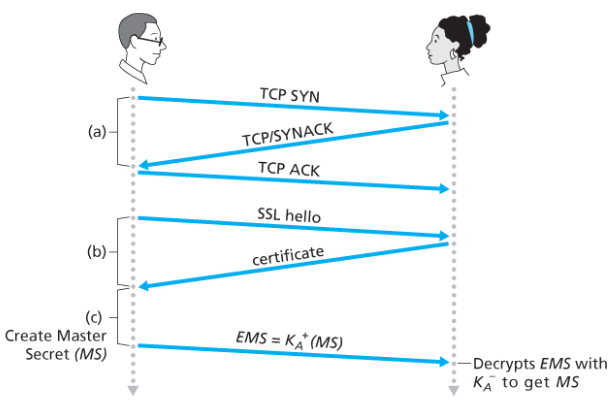
- 클라이언트는 서버와 TCP 연결을 설립한다.
- 서버가 진짜 서버인지 확인한다. 클라이언트는 hello 메시지를 보내고, 서버는 CA로부터 인증된 인증서를 보내어 클라이언트는 인증서 내의 공개키가 서버의 것이라는 것을 믿을 수 있다.
- TLS 세션에 필요한 모든 대칭키를 생성하기 위해 서버와 클라이언트가 사용할 주 비밀키(Master Secret, MS)를 생성하여 전송한다.
- MS를 보낼 때, 서버의 공개키로 암호화하여 EMS(Encrypted Master Secret)를 만든다.
- 서버는 자신의 개인키로 EMS를 복호화하여 MS를 얻는다.
- 즉, 둘은 둘만 아는 MS를 알게 된다.
키 유도
공유한 MS는 모든 암호화와 데이터 무결성 검사를 위한 대칭 세션키로 사용될 수 있으나 일반적으로 각각 다른 암호화 키를 사용하는 것이 좀 더 안전하다.
따라서 MS를 이용하여 4개의 키를 만든다.
- E(b) = 클라이언트가 서버에 보내는 데이터에 대한 세션 암호화 키
- M(b) = 클라이언트가 서버에 보내는 데이터에 대한 세션 HMAC(메시지 인증 코드) 키
- E(a) = 서버가 클라이언트에 보내는 데이터에 대한 세션 암호화 키
- M(a) = 서버가 클라이언트에 보내는 데이터에 대한 세션 HMAC(메시지 인증 코드) 키
이는 단순히 MS를 4개의 키로 쪼개어 이루어진다.
2개의 암호화 키는 데이터를 암호화하고, 2개의 HMAC 키는 데이터 무결성을 확인하는 데 사용된다.
데이터 전송
TCP는 바이트 스트림 프로토콜이므로, TLS가 애플리케이션 데이터를 끊임없이 암호화하고 암호화된 데이터를 TCP에 쉴 새 없이 전달하는 것이 자연스럽다.
그렇다면 HMAC은 언제 해야할까?
분명한 건 전체 세션 시간 동안 전송된 모든 데이터의 무결성을 확인하는 일이 TCP 세션이 종료될 때까지 미뤄둘 수 없다는 것이다.
TLS는 데이터 스트림을 레코드로 쪼개고 각 레코드에 무결성 검사를 위한 HMAC을 덧붙인 후 이 레코드+HMAC을 암호화한다.
HMAC을 생성하기 위해 클라이언트는 레코드 데이터와 키 M(b)를 해시 함수에 넣는다.
레코드+HMAC 꾸러미를 암호화하기 위해 E(b)를 사용하여 TCP로 전송한다.
그러나 만약 침입자가 TCP 세그먼트 스트림에서 스트림을 삽입, 삭제, 교환할 수 있다면 위 방법은 안전하지 않다.
예를 들어, 침입자가 2개의 세그먼트 순서를 바꾼 후 TCP 세그먼트 번호까지 그에 맞게 변경하여 서버에 보낸다면 서버의 TLS는 문제 없이 이를 애플리케이션 계층에 넘겨준다.
TLS는 순서번호를 이용해서 이 문제를 해결한다.
클라이언트는 순서 번호 카운터를 유지하며 TLS 레코드를 보낼 때마다 하나씩 증가시킨다.
HMAC을 계산할 때 HMAC 키 M(b)와 레코드 데이터와 순서 번호를 합친 결과의 해시로 사용한다.
서버는 클라이언트의 순서번호를 추적해서 자신의 HMAC 계산을 할 때 적절한 순서 번호를 포함시켜 레코드의 데이터 무결성을 확인한다.
TLS 레코드

첫 세 필드는 암호화되지 않는다.
타입 필드는 핸드셰이크 메시지인지 데이터를 담은 메시지인지 나타낸다.
8.6.2 TLS의 완전한 개념: TLS
이제 완전한 버전의 TLS를 살펴보자.
TLS 핸드셰이크
TLS는 서버와 클라이언트에게 특정 대칭키 알고리즘이나 공개키 알고리즘을 사용하도록 강제하지 않는다.
대신 핸드셰이크 과정에서 암호화 알고리즘을 합의하고, 서로에게 넌스를 보내 세션키를 생성한다.
시나리오
- 클라이언트는 넌스와 함께 자신이 지원하는 암호화 알고리즘의 목록을 보낸다. 넌스를 사용하는 이유는 만약 침입자가 모든 메시지를 엿들은 후 그대로 서버에게 보내게 된다면, 순서번호를 둔다고 하더라도 그것 또한 그대로 일치하므로 서버에서는 똑같은 메시지를 한번 더 들은 것으로 인지하기 때문이다. 넌스를 포함하면 모든 메시지는 유일성을 가지게 되므로 보안에 안전해진다.
- 목록으로부터 서버는 대칭키 알고리즘, 공개키 알고리즘, HMAC 키와 함께 HMAC 알고리즘을 선택한다.
- 선택 결과와 인증서, 서버 넌스를 클라이언트에게 보낸다.
- 클라이언트는 인증서를 확인하고 서버의 공개키를 알아낸 후 PMS(Pre-Master-Secret)를 생성한다. 이 PMS를 서버의 공개키로 암호화한 후 서버에게 보낸다.
- 클라이언트와 서버는 같은 키 유도 함수를 사용하여 PMS와 넌스로부터 MS를 계산한다.
- 이 MS는 2개의 암호화 키와 2개의 HMAC 키를 생성하기 위해 분할된다.
- 이후 모든 메시지는 암호화되고 인증된다.
- 클라이언트는 모든 핸드셰이크 메시지의 HMAC을 전송한다.
- 서버는 모든 핸드셰이크 메시지의 HMAC을 전송한다. 8, 9번 과정은 처음 암호화되지 않은 메시지에 대한 침입자의 수정을 대비해서 지금까지 주고 받은 메시지의 일치 불일치를 확인하는 것이다.
연결 종료
단순히 바로 TCP FIN 세그먼트를 보내 종료시키면 문제를 발생시킬 수도 있다.
침입자가 임의로 TCP FIN 세그먼트를 보내 종료시키는 절단 공격 문제가 발생한다.
이를 해결하기 위해 레코드의 타입 필드에 그 레코드가 TLS 세션 종료를 수행할 것인지를 표시한다.
8.7 네트워크 계층 보안: IPsec과 가상 사설 네트워크
IPsec이라고 알려진 IP 보안 프로토콜은 네트워크 계층의 보안을 제공한다.
IPsec 특징
- 호스트나 라우터 같은 네트워크 계층의 어떤 두 개체 사이에서 IP 데이터그램을 보호한다. 데이터그램의 페이로드 부분을 암호화하여 TCP 세그먼트 등이 암호화된다.
- 위의 기밀성을 제공하는 것처럼 출발지 인증, 데이터 무결성, 재생 공격 방지 같은 보안 서비스를 제공할 수 있다.
8.7.1 IPsec과 가상 사설 네트워크
흩어져 있는 기관들은 그들의 호스트와 서버가 기밀성을 유지하며 안전하게 서로에게 데이터를 전송할 수 있도록 종종 자신만의 IP 네트워크를 갖기를 원한다.
이를 위해 공공 인터넷과 완전히 분리된 라우터, 링크, DNS 시스템을 포함하는 물리적으로 독립된 네트워크를 실제로 설치할 수 있고, 이러한 네트워크를 사설 네트워크(private network)라고 한다.
큰 유지 비용이 드는 사설 네트워크 대신 오늘날에는 기존 공공 인터넷 상에 VPN을 설치한다.
VPN을 이용하면 기관의 사무실간 트래픽은 공공 인터넷을 통해 전송된다.
그러나 기밀성을 제공하기 위해 이 트래픽들은 공공 인터넷에 들어가기 전에 암호화된다.
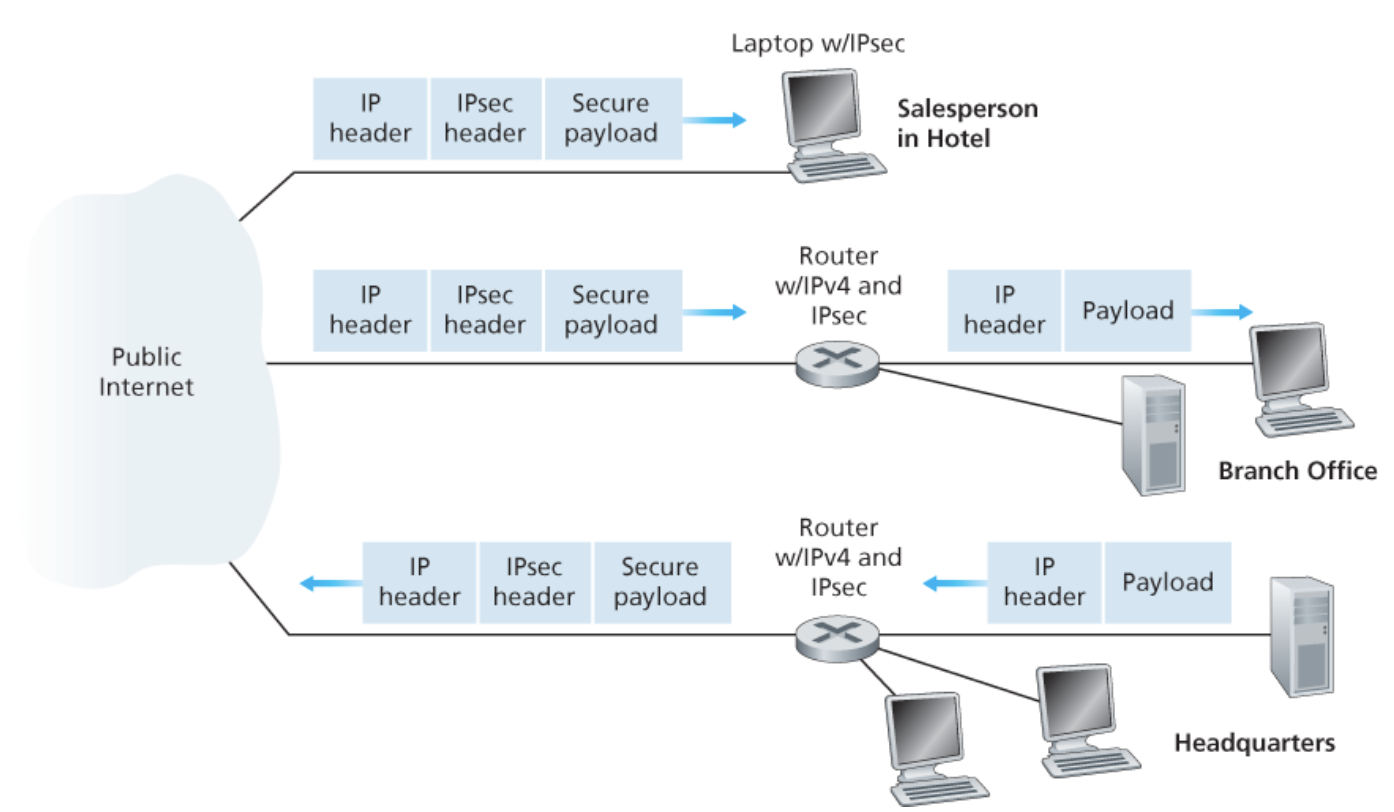
공공 인터넷을 통과하지 않을 때는 평범한 IPv4 데이터그램이 사용되고, 통과해야 할 때는 IPsec을 지원하는 라우터가 IPv4 데이터그램을 IPsec 데이터그램으로 바꾼 후 인터넷으로 전송한다.
IPsec 데이터그램은 전형적인 IPv4 헤더를 가지고 있어 공공 인터넷의 라우터는 IPv4 데이터그램과 똑같이 이를 전달한다.
실질적으로는 IPsec 데이터그램의 페이로드는 IPsec 헤더를 포함하고, 이는 IPsec 처리를 위해 사용된다.
8.7.2 AH와 ESP 프로토콜
출발지 IPsec 개체가 보안 데이터그램을 목적지 개체에 보낼 때 AH 프로토콜이나 ESP 프로토콜을 사용한다.
- AH 프로토콜 : 출발지 인증과 데이터 무결성을 제공하지만, 기밀성을 제공하지 않는다.
- ESP 프로토콜 : 출발지 인증과 데이터 무결성, 기밀성을 제공한다. 대부분 기밀성을 필요로 하여 널리 사용된다.
8.7.3 SA
IPsec 데이터그램을 전송하기 전 출발지 개체와 목적지 개체는 네트워크 계층에서 논리적 연결을 설립하는데 이것이 바로 SA(security association)이다.
SA는 단방향이어서 서로에게 데이터를 보내기 위해서는 두 개의 SA가 필요하다.
기관 내에 n개의 호스트가 있다면, SA는 2n개 그리고 지점의 라우터가 m개가 있다면 추가로 2m개 즉, 2n + 2m개 필요하다.
게이트웨이 라우터나 랩톱이 인터넷으로 보내는 모든 트래픽이 IPsec 방식으로 보호되지는 않는다.
예를 들어, 보안이 필요한 기관 내의 호스트가 아닌 구글 등의 공공 인터넷의 웹서버에 접속할 수도 있기 때문에 라우터나 랩톱은 IPv4 데이터그램과 IPsec 모두를 전송한다.
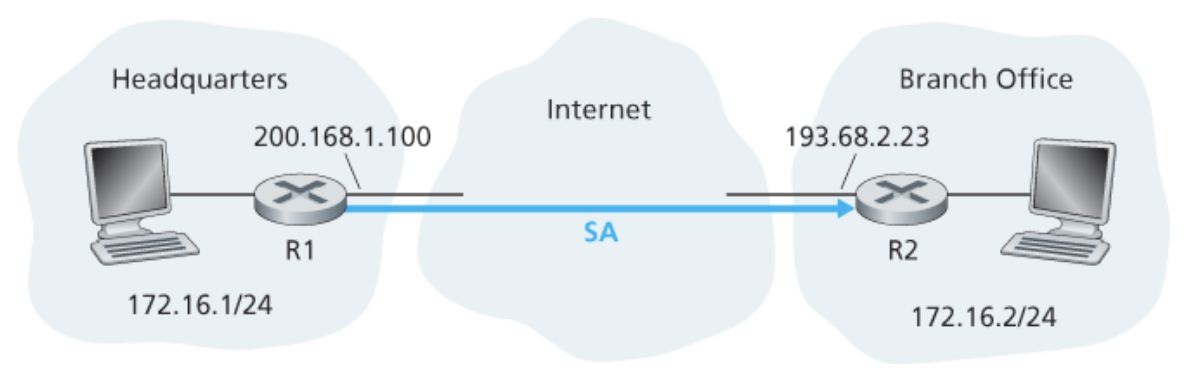
R1은 SA에 대해 다음과 같은 상태 정보를 포함한다.
- SA에 대한 32 비트 식별자 SPI
- SA 시작점의 인터페이스(200.168.1.100)와 최종점의 인터페이스(193.68.2.23)
- 사용되는 암호화 타입 (AES, DES 등)
- 암호화 키
- 무결성 검사 타입 (MD5, SHA 등)
- 인증키
이들을 사용해 암호화하고, 인증을 하며 R2도 마찬가지로 같은 상태정보를 유지한다.
SA가 많을 수 있어 그 상태정보를 유지해야 하는데 IPsec 개체는 모든 SA에 대한 상태 정보를 그 개체의 OS 커널에 있는 SAD(Security Association Database)라는 데이터 구조에 저장한다.
8.7.4 IPsec 데이터그램
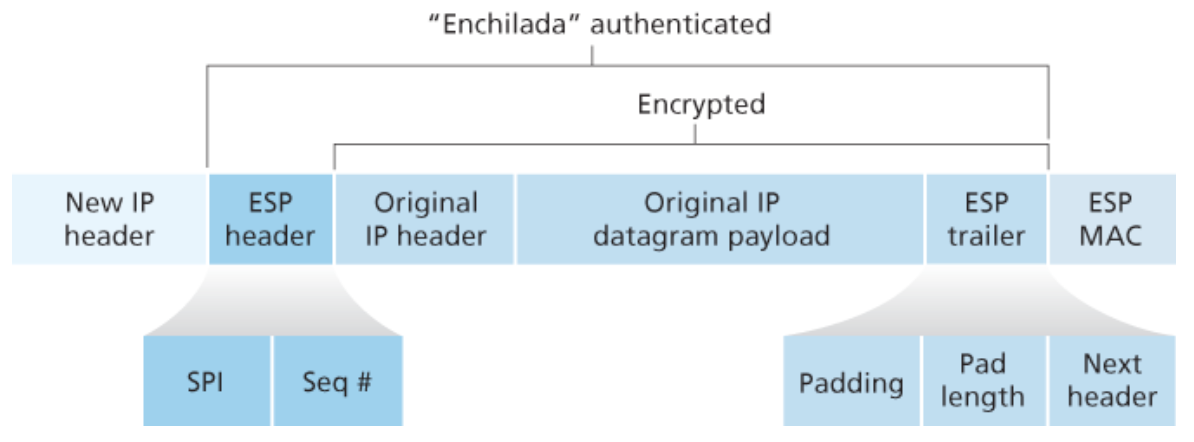
라우터 R1은 원본 IPv4 데이터그램을 IPsec 데이터그램으로 변환하기 위해 다음 과정을 이용한다.
- 원래 IPv4 데이터그램의 뒤에 ESP 트레일러를 덧붙인다.
- 원래 IPv4 데이터그램에 원래 목적지 IP 주소, 출발지 IP 주소가 들어가 있다.
- ESP 트레일러는 패딩, 패딩 길이, 다음 헤더라는 3개의 필드로 이루어져 있다.
- 패딩 : 원래 데이터그램에 덧붙어 최종 메시지가 정수개의 고정 길이 블록으로 분할될 수 있게 한다.
- 패딩 길이 : 패딩 비트가 얼마나 삽입되었는지 알려주고, 이를 이용해 패딩을 삭제한다.
- 다음 : 페이로드에 포함된 데이터의 타입(ex: UDP)을 지시한다.
- SA에 의해 지정된 알고리즘과 키를 이용하여 위 결과를 암호화한다.
- 암호화된 결과의 앞에 ESP 헤더 필드를 덧붙인다. 결과로 나온 패키지를 엔칠라다라고 부르자.
- ESP 헤더에는 SPI와 순서번호를 포함한다.
- SPI : 수신 개체에게 데이터그램이 어느 SA에 속해 있는지 지시한다. 이 SPI를 가지고 자신의 SAD를 검색하여 알맞은 인증 및 복호화 알고리즘과 키를 결정한다.
- 순서 번호 : 재생 공격을 막기 위해 사용된다.
- ESP 헤더에는 SPI와 순서번호를 포함한다.
- SA가 지정한 알고리즘과 키를 이용하여 전체 엔칠라다에 대한 인증 MAC을 생성한다.
- 엔칠라다 뒤에 MAC을 붙여 페이로드를 만든다. 비밀 MAC 키를 엔칠라다에 붙이고 그 결과에 대해 고정 길이의 해시를 계산한다.
- 전형적인 IPv4 헤더 필드를 가지고 완전히 새로운 IP 헤더를 만들어 위의 페이로드 앞에 붙인다.
- 새로운 IP 헤더에는 출발지와 목적지 주소는 전달될 라우터 인터페이스의 주소가 들어간다.
- 헤더 필드의 상위 프로토콜 값으로는 TCP, UDP 등을 나타내지 않고 이것이 ESP 프로토콜을 사용하는 IPsec임을 나타내는 값을 사용한다.
결과로 나온 IPsec 데이터그램은 전형적인 IPv4 헤더를 가지고 페이로드가 따라오는 진짜 IPv4 데이터그램이다.
전달하는 라우터들은 IPsec으로 암호화된 정보라는 것을 모른 채 목적지 라우터 인터페이스로 이를 전달한다.
라우터 R2는 IPsec 데이터그램을 받으면 다음과 같은 과정을 수행한다.
- IP 헤더를 보고 IPsec ESP 프로토콜을 적용해야 함을 알게 된다.
- 엔칠라다를 들여다보고 R2는 SPI를 이용하여 데이터그램이 어느 SA에 속한 것인지 알아낸다.
- 엔칠라다의 MAC을 계산하여 ESP MAC 필드의 값과 일치하는지 확인한다. 일치하여야 조작되지 않은 것이다.
- 데이터그램이 재생된 것이 아닌지 순서 번호 필드를 검사한다.
- SA와 관련된 복호화 알고리즘과 키를 이용하여 암호화된 부분을 복호화한다.
- 원래의 IP 데이터그램을 최종 목적지로 전송하기 위해 지점 네트워크로 전달한다.
IPsec 개체는 SAD와 함께 SPD(Security Policy Database)라 불리는 자료구조를 유지한다.
SPD는 어떤 형태의 데이터그램(출발지 IP 주소, 목적지 IP 주소, 프로토콜 타입으로 결정)이 IPsec으로 처리되어야 하는지와 그때 사용될 SA를 지시한다.
즉, SPD의 정보는 도착한 데이터그램으로 무엇을 할지 알려주고, SAD의 정보는 어떻게 할 것인지를 알려준다.
8.7.5 IKE: IPsec에서의 키 관리
수백 수천 개의 IPsec 라우터와 호스트로 이루어진 큰 VPN에서는 종단점의 SAD에 직접 SA 정보를 입력하는 방법은 불가능하다.
즉, SA를 생성하는 자동화된 방법이 필요한데 이 방법으로 IKE 프로토콜을 이용한다.
각 IPsec 개체는 그 개체의 공개키가 포함된 인증서를 갖는다.
SSL에서와 마찬가지로 IKE 프로토콜은 두 개체가 인증서를 교환하고 인증과 암호화 알고리즘에 대한 협상을 하게 하며 IPsec SA의 세션키를 생성하기 위한 중요한 자료를 안전하게 교환할 수 있게 한다.
IKE는 이러한 작업을 수행하기 위해 두 단계를 거친다.
첫번째 단계
R1과 R2는 메시지 쌍을 두 번 교환한다.
- 첫 번째 메시지 교환 시에는 양측이 라우터 사이의 IKE SA를 설립하기 위해 디피-헬만 알고리즘을 사용한다.
- IKE SA는 IPsec SA와는 완전히 다르다.
- IKE SA는 두 라우터 사이에 인증되고 암호화된 채널을 제공한다.
- 이 첫 번째 메시지를 교환하는 동안 IKE SA의 암호화와 인증을 위한 키가 설립된다.
- 또한, 두번째 단계에서 IPsec SA 키를 계산하기 위해 사용될 주 비밀키도 만들어진다.
- 첫번째에서는 누구도 비밀키로 서명함으로써 자신의 신분을 드러내지 않는다.
- 두번째 교환에서는 양측이 메시지에 서명하여 서로에게 신분을 드러낸다.
- 그러나 메시지가 보안 처리된 IKE SA 채널을 통해 전송되므로 단순한 도청자에게는 신분이 누설되지 않는다.
- 양측이 IPsec SA에 의해 사용될 IPsec 암호화 및 인증 알고리즘에 대해 협의한다.
두번째 단계
양측이 각 방향으로 하나씩 SA를 설립한다.
이 단계를 마칠 때는 이 2개의 SA에 대한 암호화 및 인증 세션키가 양측에 만들어져 있다.
이후 보안 처리된 데이터그램을 만들기 위해 SA를 사용할 수 있다.
8.8 무선 랜과 4G/5G 셀룰러 네트워크 보안
8.8.1 802.11(와이파이) 무선 랜의 인증키와 키 합의
802.11 네트워크에서 다루어야 할 핵심적인 보안 관심사
- 상호인증 : 이동 장치가 AP에 접속하여 데이터그램을 외부에 전송하기 전에, 네트워크는 접속하는 이동 장치의 신원을 확인하고, 그 장치의 접속 권한을 점검하기 위해 장치를 인증하기를 원한다. 이동장치의 경우도 접속하는 네트워크가 진짜 접속을 원하는 네트워크가 맞는지 인증하기를 원한다. 이런 양방향 인증을 상호 인증이라고 한다.
- 암호화 : 802.11 프레임은 무선 채널을 통해 교환되기 때문에, 이동 장치와 AP 간에 교환되는 사용자 레벨 데이터를 지니고 있는 링크 레벨 프레임의 암호화가 중요하다. 높은 속도를 요해 대칭키 암호화가 사용된다.
상호 인증과 암호화 키 생성 및 사용 절차
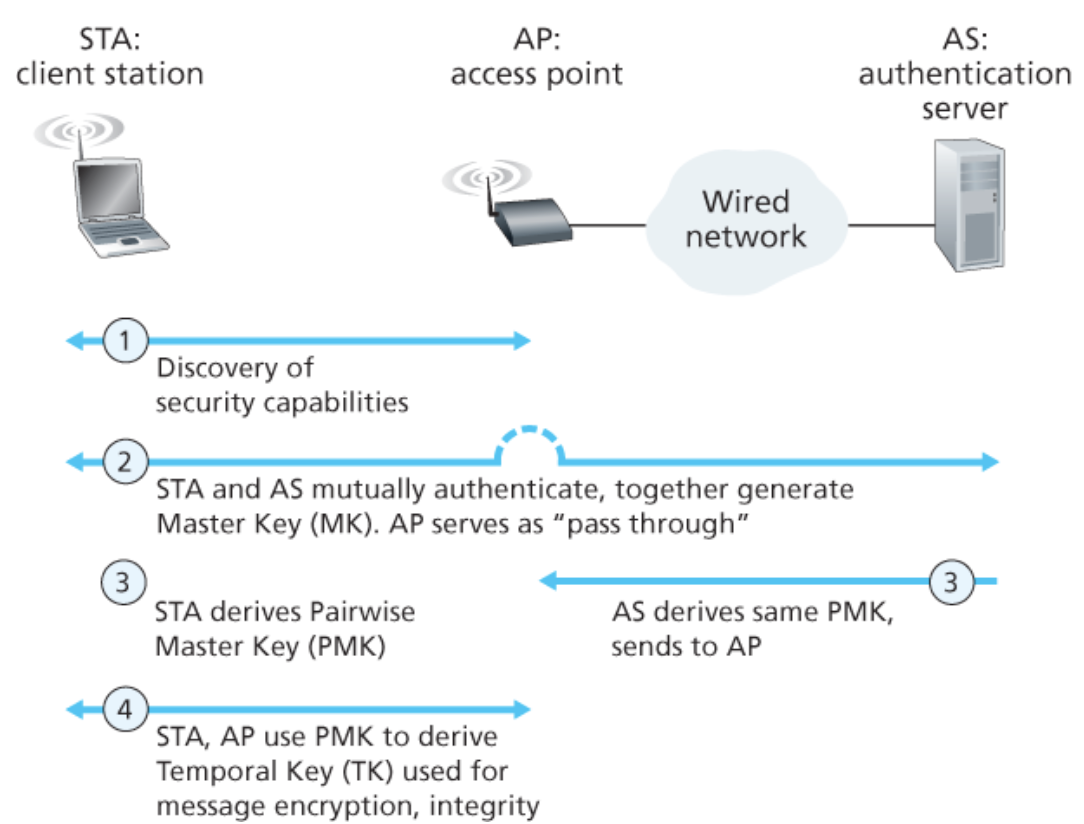
- 발견 : AP는 자신의 존재와 함께 이동 장치에게 제공될 수 있는 인증과 암호화 형식을 알린다. 이동 장치는 원하는 인증과 암호화 형식을 요청한다.
- 상호 인증과 공유 대칭키 생성 : 인증 서버와 이동 장치 간에 이미 공유된 공통의 비밀을 갖고 있다고 가정한다. 이동 장치와 인증 서버는 서로 간의 인증에 넌스와 암호화 해싱 등과 함께 공유 비밀을 이용하게 된다. 이동 장치와 AP 간의 무선 링크를 통해 전송될 프레임의 암호화에 사용될 공유 세션키를 생성한다.
- 공유 대칭 세션키 분배 : 대칭 비밀키는 이동 장치와 인증 서버에서 생성되기에, 인증 서버가 AP에게 공유 대칭 세션키를 알려주기 위한 프로토콜이 필요하다.
- AP를 통한 이동 장치와 원격 호스트 간의 암호 통신 : 2단계와 3단계에서 생성되고 분배된 세션키를 사용하여 암호화된 링크 계층 프레임을 가지고 통신이 이루어진다. 프레임 데이터를 암호화 복호화하기 위해 AES 대칭키 알고리즘을 사용한다.
상호 인증과 공유 대칭키 생성
초기 802.11 보안 규정 WEP은 심각한 보안 오류가 있었고, 이를 극복하기 위해 WPA1이 개발되었다.
WPA1은 메시지 동질성 검사와 사용자가 일정 기간 암호화된 메시지 스트림을 관찰하여 암호화 키를 추측하게 하는 공격을 피하는 것을 도입하였다.
WPA2는 AES 대칭키 암호화를 의무화하여 WPA1을 개선했다.
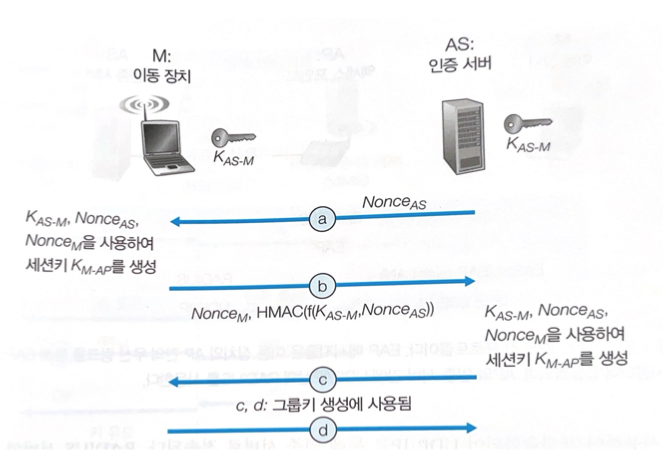
위 그림은 간략한 네 방향 핸드셰이크 프로토콜을 보여준다.
공유 비밀키(ex 비밀번호)를 서로 알고 시작한다.
- 인증 서버는 넌스를 생성하여 이동 장치로 전송한다.
- 이동 장치는 넌스를 AS로부터 전송받고 자신의 넌스를 생성한다. 이동 장치는 자신의 넌스, 받은 넌스, 최초 공유 비밀 키, 이동 장치의 MAC 주소, AS의 MAC 주소를 사용하여 대칭형 공유 세션키를 생성해낸다. 그런 후 자신의 넌스 그리고 받은 넌스와 원래의 공유 비밀을 암호화한 HMAC-signed 값을 전송한다.
- 인증 서버는 최근에 전송한 넌스의 HMAC-signed 버전을 보아 이동 장치가 공유 비밀키로 암호화를 할 수 있었고, 인증 서버 또한 이동 장치가 주장하는 본인이라는 것을 알게 되어 이동 장치를 인증하게 된다. 자신의 넌스, 받은 넌스, 최초 공유 비밀 키, 이동 장치의 MAC 주소, AS의 MAC 주소를 사용하여 똑같은 대칭형 공유 세션키를 만들 수 있다.
만든 대칭형 공유 세션키를 AP에 공유하여 이동 장치와 AP는 서로 데이터를 주고 받을 수 있다.
802.11 보안 메시징 프로토콜
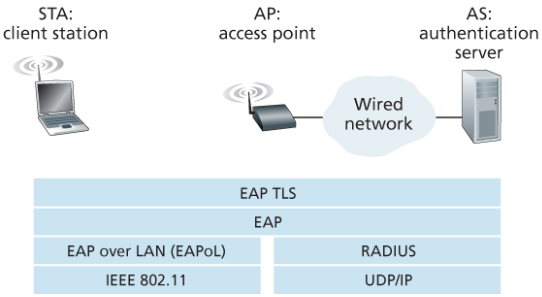
위 그림은 802.11 보안 프레임워크를 구현하기 위해 사용된 확장 인증 프로토콜(Extensible Authentication Protocol, EAP)를 보여준다.
이 프로토콜은 종단 간의 메시지 포맷을 정의한다.
EAP 메시지들은 EAPoL을 사용하여 캡슐화되어 무선 링크로 전송된다.
이러한 EAP 메시지들은 AP에서 역캡슐화되며, RADIUS 프로토콜을 사용하여 재캡슐화되어 UDP/IP를 통해 인증 서버로 전송된다.
8.8.2 4G/5G 셀룰러 네트워크에서의 인증과 키 동의
4G/5G 환경에서의 상호 인증과 키 생성의 목적들은 802.11 환경에서와 동일하다.
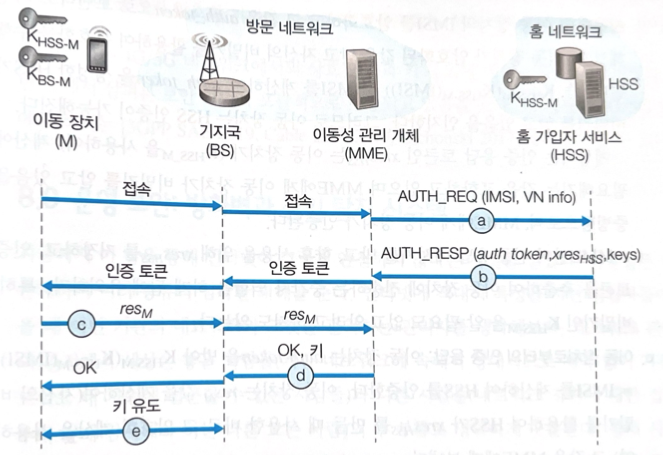
4G 인증과 키 동의 프로토콜
- HSS에 인증 요청 : 이동 장치가 기지국을 경유하여 네트워크에 처음으로 접속 요청을 할 때, 이동성 관리 개체로 전달되는 기기의 국제 이동 가입자 식별자(IMSI)를 포함하는 접속 메시지를 보낸다. MME는 IMSI와 방문지 네트워크 관련 정보를 HSS로 보낸다.
- HSS로부터의 인증 응답 : HSS는 사전 공유 비밀키를 사용하여 인증토큰인 auth_token과 예상되는 인증 응답인 xres를 유도하기 위해 암호화 동작을 수행한다. auth_token은 이동 장치로 하여금 auth_token을 계산한 누구든지 비밀키를 알고 있다는 사실을 인지하게 하는 사전 공유 비밀키를 사용하여 HSS가 암호화한 정보를 포함한다. 즉, auth_token은 사전공유키 K(IMSI)이고, 같은 사전 공유키를 가지고 있으면 IMSI를 알 수 있어 HSS가 비밀키를 알고 있음을 인지하고, 이동장치는 인증된다. xres는 이동 장치가 계산에 필요해지는 값을 포함하고 있으며 MME에게 이동 장치가 비밀키를 알고 있음을 증빙하여 MME에게 이동 장치가 인증된다. MME만이 인증 응답 메시지를 받고, 향후 사용을 위해 xres를 저장하고, 인증 토큰을 추출하여 이동 장치에 전송하는 중간자 역할을 한다.
- 이동 장치로부터의 인증 응답 : 이동 장치는 auth_token을 사전 공유키로 복호화하여 IMSI를 얻어 HSS를 인증한다. 이동 장치는 res값을 계산하여(자신의 비밀키를 활용하여) 그 값을 MME에게 보낸다.
- 이동장치 인증 : MME는 이동 장치가 계산한 res와 HSS가 계산한 xres를 비교하여 일치하면 모두 공통 비밀키를 갖고 있음을 증빙한 것이므로 이동 장치가 인증된다. MME는 기지국과 이동 장치에게 상호 인증이 완료되었음을 알리고, e단계에서 사용할 기지국 키를 보낸다.
- 데이터 평면과 제어 평면 키 도출 : 이동 장치와 기지국은 무선 채널을 통해 프레임 전송에 사용될 암/복호화 키들을 각자 결정한다.
8.9 운영 보안: 방화벽과 침입 탐지 시스템
8.9.1 방화벽
방화벽(firewall)은 전체 인터넷으로부터 기관의 내부 네트워크를 분리시킨 하드웨어와 소프트웨어의 조합으로, 어떤 패킷은 통과가 허용되나 어떤 패킷은 차단된다.
네트워크 관리자가 해당 네트워크에 대한 트래픽 출입을 관리하여 접속을 제어한다.
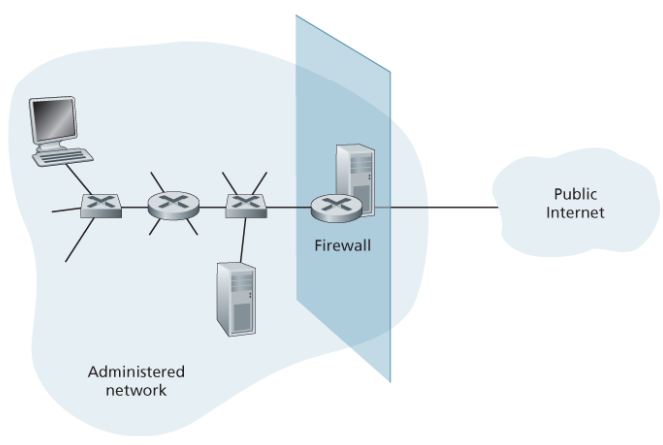
방화벽의 목표
- 외부와 내부를 오가는 모든 트래픽은 방화벽을 거친다.
- 로컬 보안 정책에 정의된 대로 승인된 트래픽만이 통과가 허용된다.
- 방화벽 자체가 침입 시도에 안전해야 한다.
전통적인 패킷 필터
기관은 일반적으로 내부의 네트워크를 ISP에 연결하는 게이트웨이 라우터를 갖는다.
외부와 내부를 오가는 모든 트래픽은 이 라우터를 지나야만 하고, 이 라우터에서 패킷 필터링이 일어난다.
필터링 결정의 근거
- IP 출발지 또는 목적지 주소 : 불행히 출발지 주소를 위장한 데이터그램을 막을 수 없다.
- IP 데이터그램 내의 프로토콜 타입 : TCP, UDP, OSPF 등
- TCP 또는 UDP 출발지와 목적지 포트
- TCP 플래그 비트 : SYN, ACK. ACK 비트가 0인 입력 세그먼트를 거른다면 외부에서 오는 모든 TCP 연결은 거부하고, 내부에서 나가는 건 허락한다.
- ICMP 메시지 타입
- 네트워크에서 나가는 데이터그램과 들어오는 데이터그램에 대한 서로 다른 규칙들
- 서로 다른 라우터 인터페이스에 대한 서로 다른 규칙들
네트워크 관리자는 기관의 정책에 기초해서 방화벽을 설정한다.
예를 들어, 공개 웹 서버 접속 목적을 제외한 어떠한 TCP 연결도 받고 싶지 않다면, 목적지 포트 80번과 웹 서버에 해당하는 목적지 주소를 가진 TCP SYN 세그먼트를 제외한 모든 TCP SYN 세그먼트를 막을 수 있다.
방화벽의 규칙은 접속 제어 목록과 함께 라우터에 구현된다.
상황 고려 패킷 필터
상황 고려 필터는 TCP 연결을 추적하여 이 정보를 패킷 차단 결정을 하는 데 이용한다.
상황 고려 필터는 연결 고려 테이블에 있는 진행 중인 모든 TCP 연결을 추적함으로써 전통적인 패킷 필터에서 통과되던 패킷도 관리한다. (관리하지 않는다면 DoS 공격 등을 막을 수 없다.)
예를 들어, SYN, SYNACK, ACK, FIN을 관찰하여 연결이 60초 동안 사용되지 않는다면 그 연결은 이미 종료되었다고 가정할 수 있다.
상황 고려 필터는 접속 제어 목록에 연결 검사라는 새로운 열을 포함한다.
예를 들어, 외부에서 조작된 패킷을 TCP 출발지 포트 80번, ACK 플래그를 1로 설정하여 내부로 보내려고 한다고 해보자.
전통적인 패킷 필터는 이를 막을 수 없지만 상황 고려 필터는 연결 검사 열을 통해 외부에서 들어오는 패킷을 연결 검사 테이블에서 연결된 상태인지 확인하고 조작된 패킷은 연결 검사 테이블에 없으므로 필터링된다.
애플리케이션 게이트웨이
좀 더 세밀한 수준의 보안을 위해 방화벽은 패킷 필터를 애플리케이션 게이트웨이와 결합해야 한다.
애플리케이션 게이트웨이는 모든 애플리케이션 데이터가 반드시 통과해야 하는 애플리케이션 맞춤 서버다.
다수의 애플리케이션 게이트웨이가 같은 호스트에서 실행될 수 있으나 각 게이트웨이는 자신만의 프로세스들을 가진 분리된 서버다.
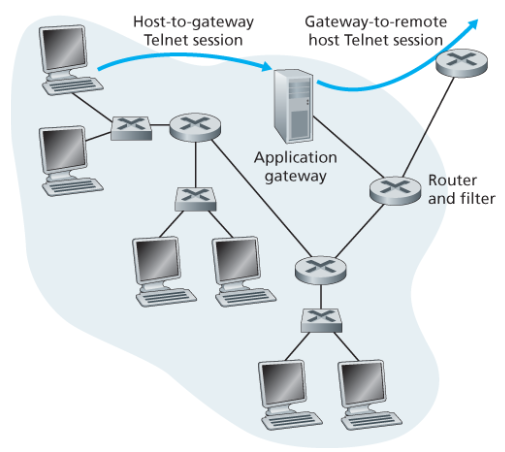
제한된 내부 사용자만 외부로의 텔넷이 가능하게 하고 모든 외부 클라이언트는 내부로 텔넷을 수행하지 못하게 하는 방화벽을 설계해보자.
- 애플리케이션 게이트웨이의 IP주소로부터 시작된 텔넷 연결을 제외하고 모든 텔넷 연결 시도를 막도록 라우터의 필터를 설정한다. 이는 외부로의 모든 텔넷 연결이 애플리케이션 게이트웨이를 통과하게 한다.
- 사용자는 먼저 애플리케이션 게이트웨이와 텔넷 세션을 설정한다.
- 게이트웨이에는 입력되는 텔넷 세션 요청을 듣고 있는 애플리케이션이 있어서 사용자에게 ID와 비밀번호를 요구한다.
- 사용자가 입력하면, 애플리케이션 게이트웨이는 그 사용자가 외부로의 텔넷 연결이 허용되어 있는지 검사한다.
- 허가되지 않았다면, 게이트웨이에 의해 종료된다.
- 허가되었다면, 사용자가 원하는 외부 호스트의 이름을 묻고, 게이트웨이와 외부 호스트 간의 텔넷 연결을 설정한 후 내부 사용자에게서 오는 데이터를 외부 호스트에게 전달한다.
- 즉, 애플리케이션 게이트웨이는 인증 뿐만 아니라 데이터 전달도 수행한다.
단점
- 각 애플리케이션마다 서로 다른 애플리케이션 게이트웨이를 필요로 한다.
- 모든 데이터가 게이트웨이를 경유하여 중계되므로 성능상의 손실이 있다.
- 클라이언트 소프트웨어는 사용자가 요구할 때 어떻게 게이트웨이와 통신할 수 있는지 알아야 하며, 어떤 외부 서버에 연결할지 애플리케이션 게이트웨이에게 알려줄 수 있어야 한다.
익명성과 사생활 보호
자신의 IP 주소를 웹사이트에 남기고 싶지 않고 지역 ISP에 그 웹사이트에 방문한 사실을 남기고 싶지 않은 익명성을 원한다면 어떻게 해야 할까?
신뢰할 수 있는 프록시 서버와 SSL의 조합을 사용할 수 있다.
- 프록시와 SSL 연결을 설립한 후 이 연결을 통해 희망하는 사이트에 대한 HTTP 요청을 전송한다.
- 프록시가 SSL로 암호화된 HTTP 요청을 복호화해서 평문 형식의 HTTP 요청을 웹사이트로 전송한다.
- 웹사이트는 프록시로 응답을 보내고, 프록시는 SSL을 통해 응답을 호스트에게 보낸다.
그러나 프록시는 결국 모든 것을 알고 있으므로 신뢰할 수 있는 프록시 서버를 사용하는 것이 중요하다.
8.9.2 침입 탐지 시스템
통과하려는 패킷 헤더를 살펴볼 뿐만 아니라 자세한 패킷 관찰을 수행하는 새로운 틈새 장치에 대한 요구가 있다.
악의적일 수 있는 트래픽을 발견했을 때 경고를 발생시키는 장치를 침입 탐지 시스템(IDS, Intrusion Detection System)이라고 한다.
의심스러운 트래픽을 걸러내는 장치는 침입 방지 시스템(IPS, Intrusion Prevention System)이라고 한다.
이 둘의 중요한 점은 어떻게 의심스러운 트래픽을 발견하느냐이므로 두 시스템을 통틀어 IDS 시스템으로 호칭한다.
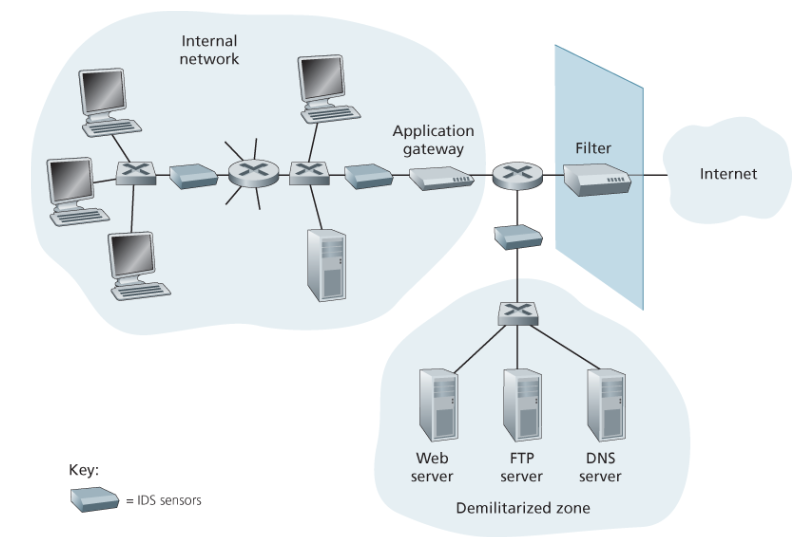
한 기관에서 IDS는 여러 개일 수 있는데, 서로 협조하며 의심스러운 트래픽이 있을 땐 중앙 IDS 프로세서에 전달되어 네트워크 관리자에게 전달된다.
위 그림은 패킷 필터와 애플리케이션 게이트웨이에 의해 보호되고 IDS에 의해 감시되는 높은 보호 구역과 패킷 필터와 IDS만을 사용하는 낮은 구역으로 나눌 수 있다.
IDS는 지나가는 각각의 패킷을 수만 개의 시그니처와 비교해야 하기 때문에 많은 연산이 필요하고 IDS를 안쪽에 위치시켜 전체 트래픽 중 일부만 관찰하면 되도록 한다.
시그니처 기반 시스템
시그니처 기반 IDS는 공격 시그니처에 대한 방대한 데이터베이스를 유지한다.
각 시그니처는 침입 행위에 관련된 규칙들의 집합이다.
시그니처는 단순히 단일 패킷에 대한 특징의 목록일 수도 있고, 연속된 일련의 패킷들에 관련한 것일 수도 있다.
네트워크 관리자는 시그니처를 자신에 맞게 수정하고 그것을 데이터베이스에 추가할 수 있다.
시그니처 기반 IDS는 지나가는 모든 패킷을 읽어 데이터베이스 내의 시그니처들과 비교한다.
만일 어떤 패킷이 데이터베이스 내의 시그니처와 일치하면 경고를 발생시킨다.
그러나 이 방법은 새로운 공격에 대해 대비할 수 없고, 모든 패킷이 데이터베이스와 비교되어야 하므로 성능이 좋지 않다.
이상 기반 IDS
트래픽을 관찰할 때 트래픽 분석표를 만든다.
그 후 ICMP 패킷의 빈도가 지나치게 높다든지 포트 정보 수집과 ping 메시지가 갑자기 증가하는 등 통계학적으로 비정상적인 패킷의 스트림을 찾는다.
참고: Computer Networking: A Top-Down Approach - IT-Book-Organization