Overview
전송 계층(Transport Layer)은 네트워크 통신에서 핵심적인 역할을 담당한다. 이 글에서는 다음 주제를 다룬다.
- 다중화(Multiplexing)와 역다중화(Demultiplexing)
- 신뢰적 데이터 전송(Reliable Data Transfer)
- 흐름 제어(Flow Control): 수신 버퍼 오버플로 방지
- 혼잡 제어(Congestion Control): 네트워크 처리 용량 초과 트래픽 제어
인터넷의 대표적인 전송 계층 프로토콜은 다음과 같다.
- UDP: 비연결형(Connectionless) 전송
- TCP: 연결 지향(Connection-oriented) 신뢰적 전송, 혼잡 제어 포함
- QUIC: 전송 계층 기능의 진화
3.1 Transport-layer Services
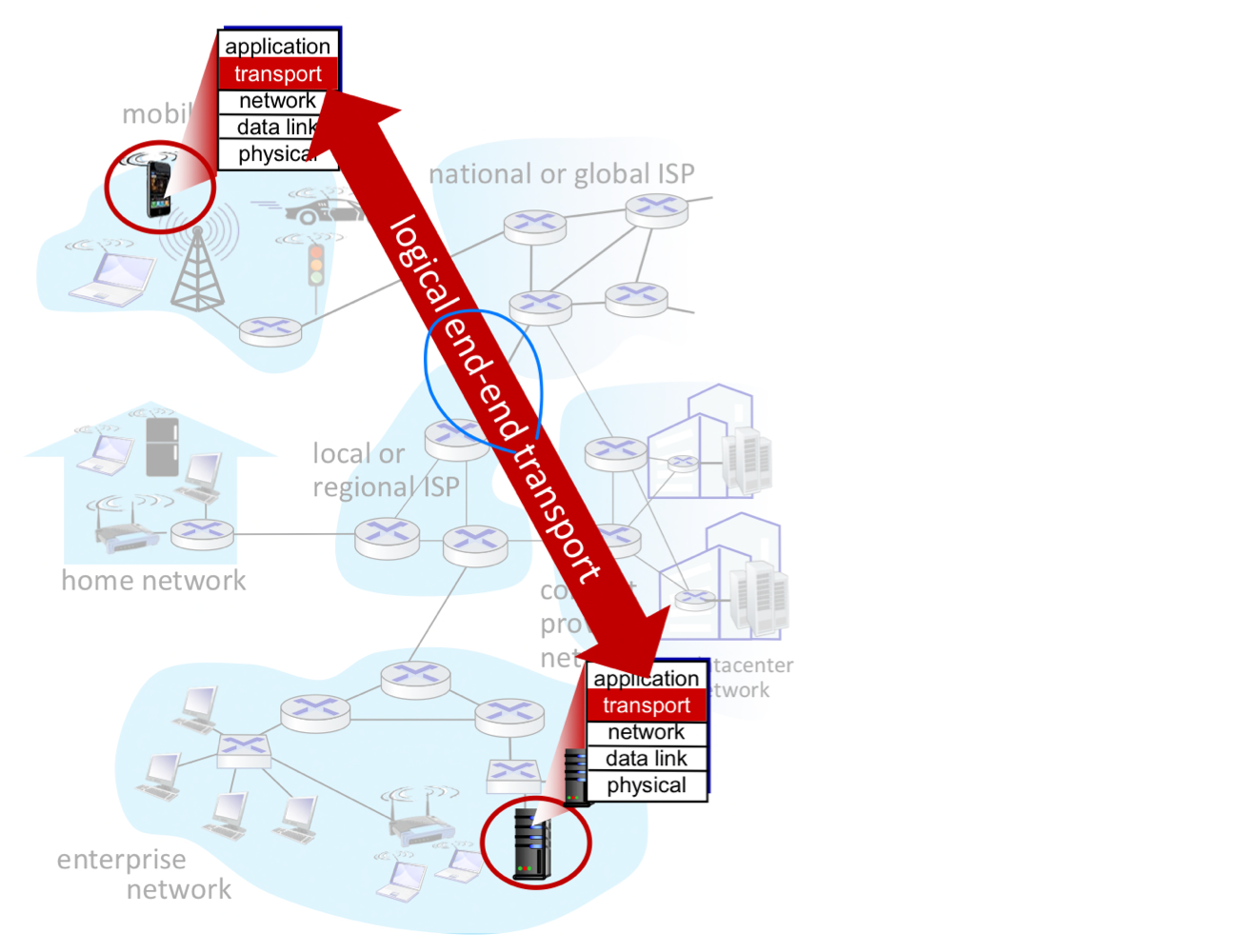
전송 계층은 서로 다른 호스트에서 실행 중인 애플리케이션 프로세스 간의 논리적 통신(Logical Communication)을 제공한다.
전송 프로토콜은 종단 시스템(End System)에서 동작하며, 송신 측과 수신 측에서 각각 다른 역할을 수행한다.
- 송신 측(Sender): 애플리케이션 메시지를 세그먼트(Segment)로 분할하여 네트워크 계층으로 전달한다.
- 수신 측(Receiver): 세그먼트를 재조립하여 메시지로 복원한 뒤 애플리케이션 계층으로 전달한다.
인터넷 애플리케이션에서 사용 가능한 전송 프로토콜은 TCP와 UDP 두 가지이다.
Transport 계층 vs. Network 계층
두 계층의 차이를 명확히 구분해야 한다.
- 네트워크 계층(Network Layer): 호스트(Host) 간의 논리적 통신
- 전송 계층(Transport Layer): 프로세스(Process) 간의 논리적 통신
하나의 호스트에서 여러 프로세스가 동시에 실행될 수 있으므로, 전송 계층은 네트워크 계층 서비스에 의존하면서도 이를 확장(enhance)하는 역할을 한다.
한편, 하위의 IP(Internet Protocol) 계층은 best-effort delivery service를 제공한다. 즉, 다음과 같은 문제가 발생할 수 있다.
- 패킷 손실(Loss)
- 순서 뒤바뀜(Out-of-order)
- 패킷 중복(Duplicate)
- 임의의 지연(Arbitrary Delay)
Transport Layer Actions
송신 측에서는 캡슐화(Encapsulation), 수신 측에서는 역캡슐화(Decapsulation)를 수행한다.


두 가지 주요 전송 프로토콜
TCP(Transmission Control Protocol):
- 연결 지향(Connection-oriented)
- 신뢰적, 순서 보장 전달(Reliable, in-order delivery)
- 혼잡 제어(Congestion control)
- 흐름 제어(Flow control)
- 다중화 / 역다중화
UDP(User Datagram Protocol):
- 비연결형(Connectionless)
- 비신뢰적, 순서 미보장 전달(Unreliable, unordered delivery)
- 오류 검사(Error check): IPv4에서는 선택 사항, IPv6에서는 필수
- 다중화 / 역다중화
- best-effort IP에 최소한의 기능만 추가한 No-frills 프로토콜
전송 계층이 제공하지 않는 서비스도 있다.
- 지연 보장(Delay guarantees)
- 대역폭 보장(Bandwidth guarantees)
3.2 Multiplexing and Demultiplexing
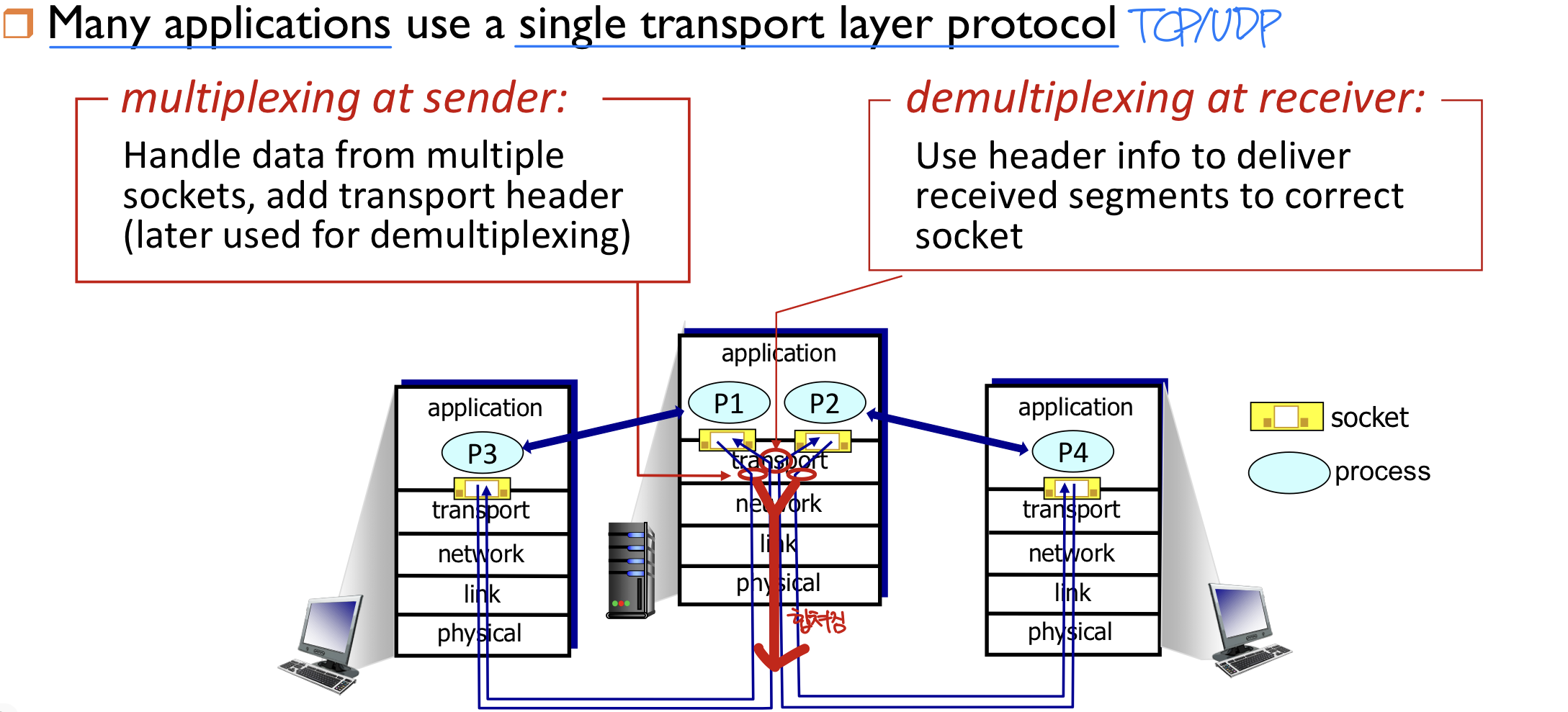
역다중화의 동작 원리
호스트가 IP 데이터그램을 수신하면, 다음 정보를 활용하여 세그먼트를 올바른 소켓으로 전달한다.
- 각 데이터그램(Datagram)에는 출발지 IP 주소, 목적지 IP 주소, 프로토콜 번호(TCP인지 UDP인지 구분)가 포함된다.
- 각 데이터그램은 하나의 전송 계층 세그먼트를 운반한다.
- 각 세그먼트에는 출발지 포트 번호와 목적지 포트 번호가 포함된다.
- 호스트는 IP 주소, 프로토콜 번호, 포트 번호를 조합하여 세그먼트를 적절한 소켓(Socket)으로 전달한다.
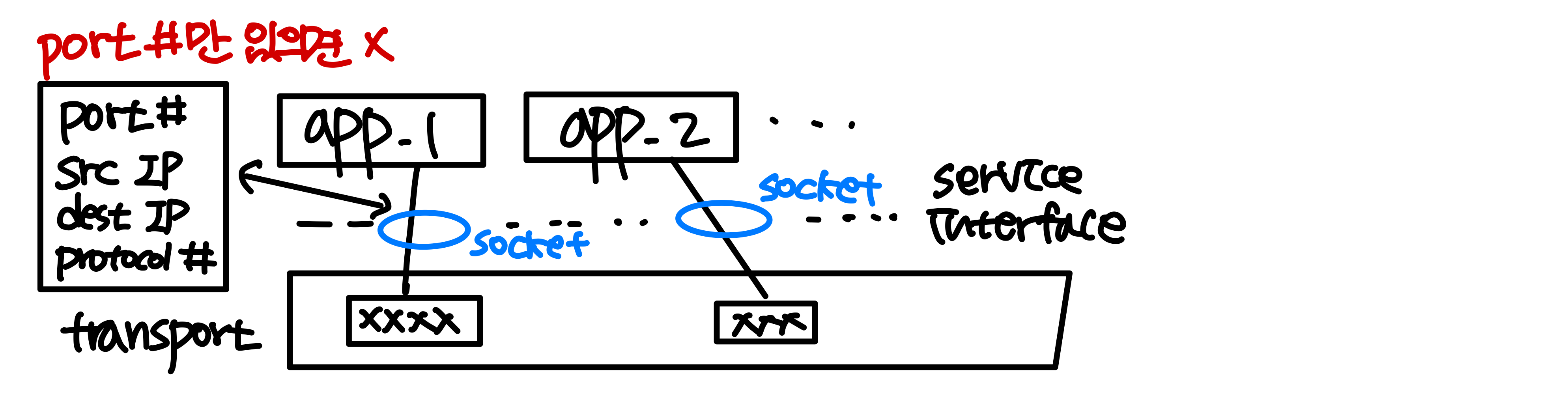
포트 번호(Port Number)
포트 번호는 프로세스를 식별하기 위해 사용된다.
- 16비트 정수: 0 ~ 65,535 ()
- 각 애플리케이션 프로세스는 통신을 위해 포트와 연결된다.
클라이언트 프로세스는 포트 번호를 직접 지정할 필요가 없다. OS가 사용되지 않는 포트 번호를 임의로 할당하며, 이를 임시 포트(Ephemeral Port)라 부른다.
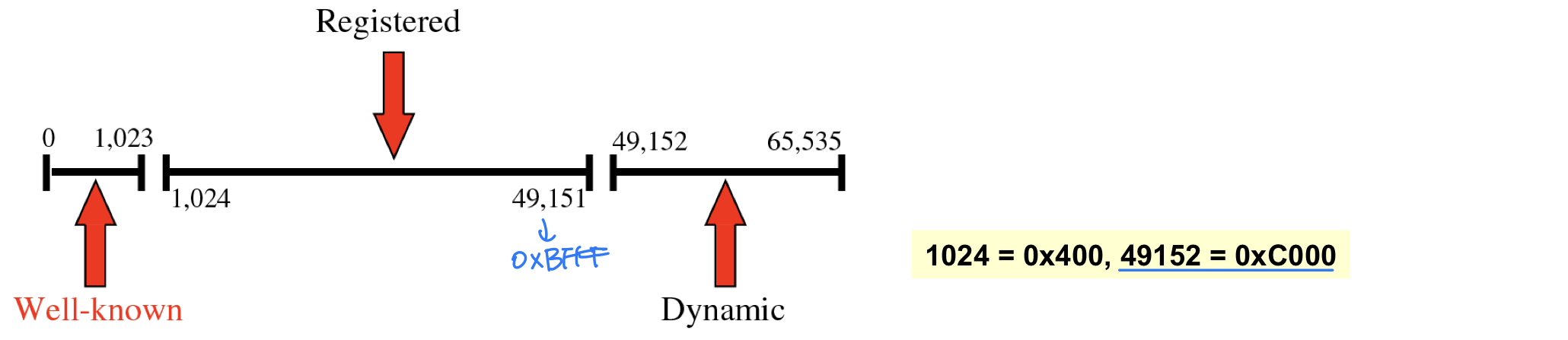
반면 서버 프로세스는 잘 알려진 포트 번호(Well-known Port)를 사용한다. 포트 번호의 범위는 다음과 같이 나뉜다 (RFC 3232 참조).
| 구분 | 범위 | 설명 |
|---|---|---|
| Well-known ports | 0 ~ 1,023 | 표준 서비스용 |
| Registered ports | 1,024 ~ 49,151 | IANA에 등록 가능하나 통제되지는 않음. RFC에 명시되지 않은 TCP/IP 애플리케이션에 사용 |
| Dynamic (Private) ports | 49,152 ~ 65,535 () | 통제도 등록도 되지 않으며, 어떤 프로세스든 사용 가능. 임시 포트로도 활용. 충돌 가능성 있음 |
Connectionless Demultiplexing (UDP)
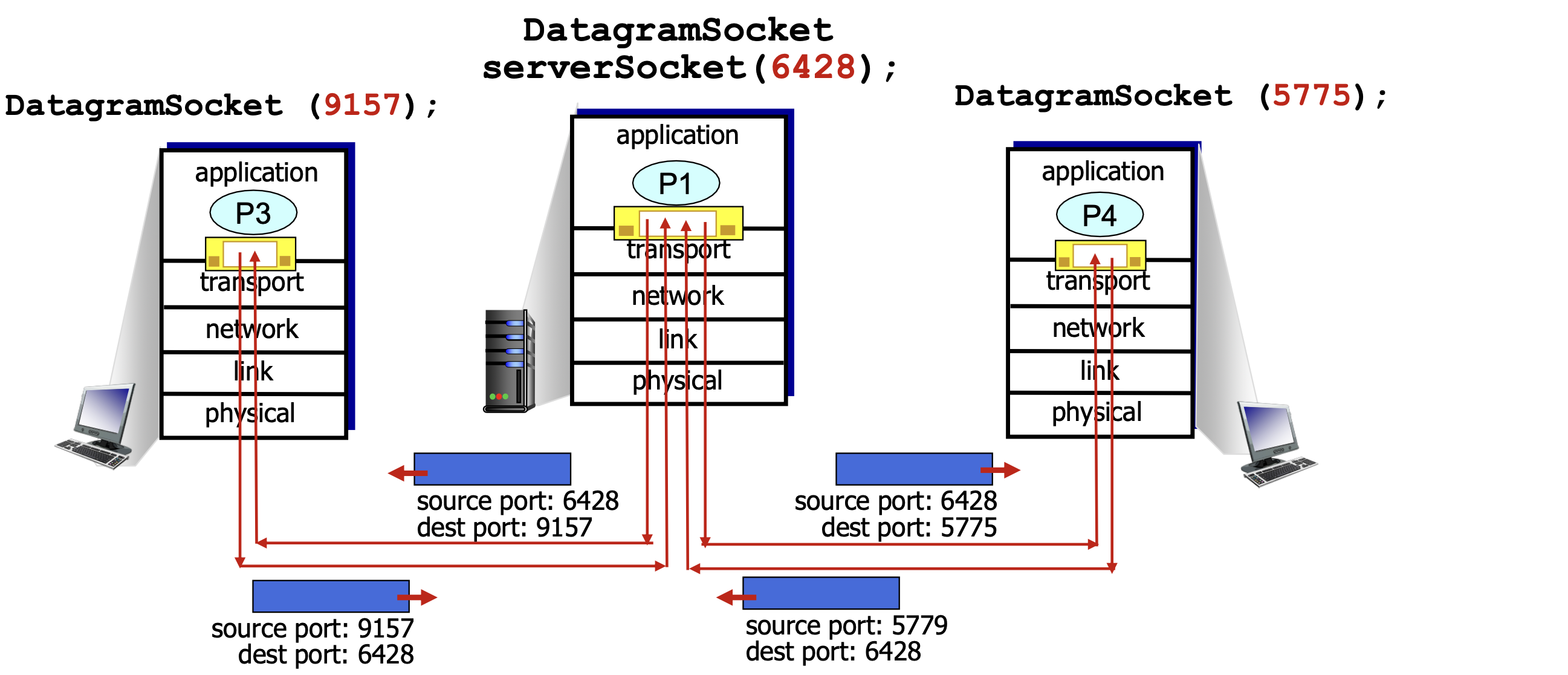
호스트가 UDP 세그먼트를 수신하면 다음과 같이 처리한다.
- 세그먼트의 목적지 포트 번호를 확인한다.
- 해당 포트 번호에 연결된 소켓으로 세그먼트를 전달한다.
핵심은, 목적지 포트 번호가 같으면 출발지 IP 주소나 출발지 포트 번호가 달라도 동일한 소켓으로 전달된다는 점이다. UDP는 목적지에 도착한 뒤 목적지 IP 주소를 별도로 확인하지 않는다. (TCP와 대비되는 특징이다.)
Connection-oriented Demultiplexing (TCP)
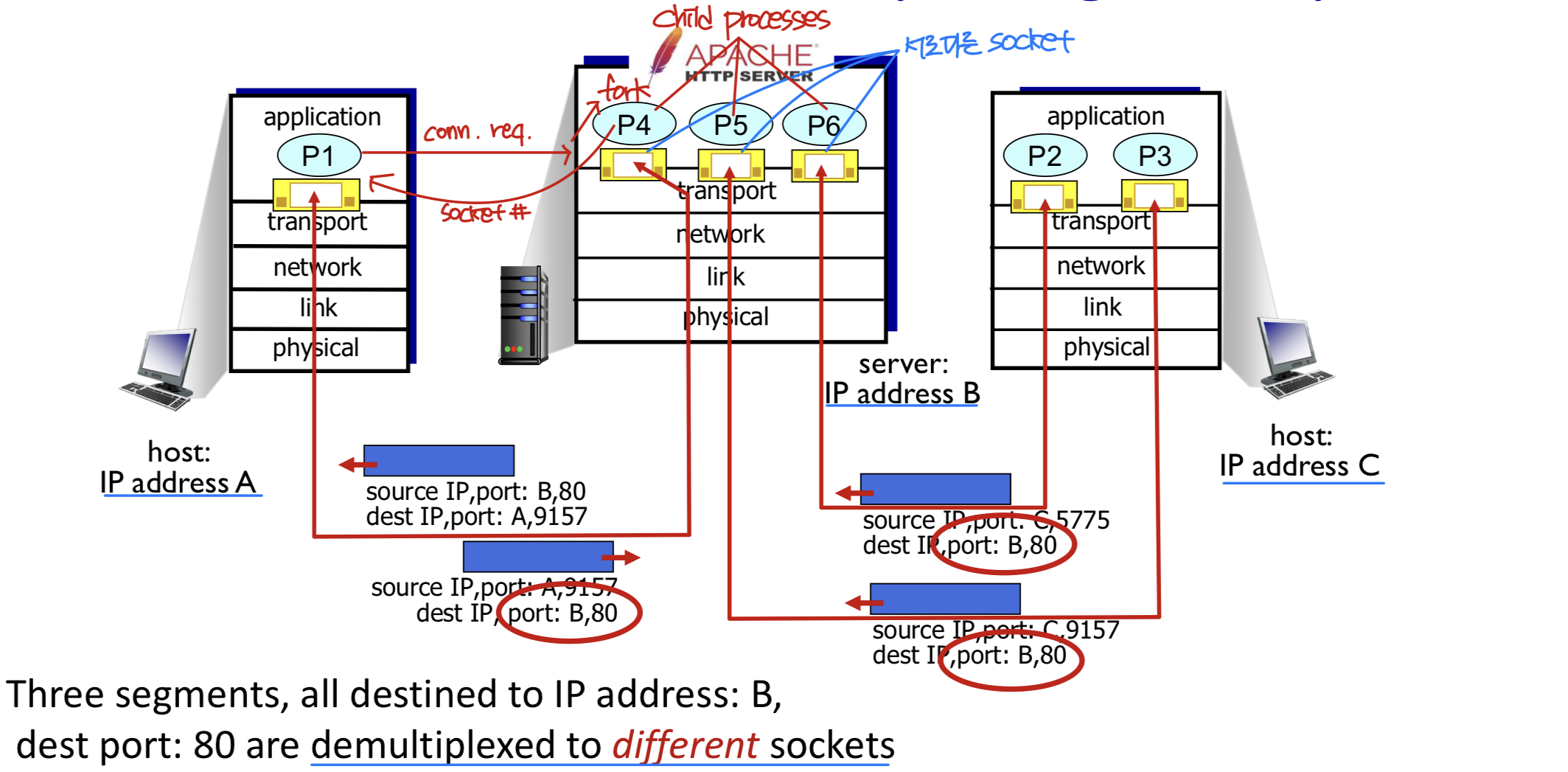
TCP는 reliable, byte stream service를 제공하는 프로토콜이다. TCP 소켓은 4-tuple로 식별된다.
- 출발지 IP 주소 + 출발지 포트 번호
- 목적지 IP 주소 + 목적지 포트 번호
호스트가 TCP 세그먼트를 수신하면, 이 네 가지 값을 모두 사용하여 적절한 소켓으로 세그먼트를 전달한다.
따라서 목적지 포트 번호가 같더라도, 출발지 IP 주소나 포트 번호가 다르면 서로 다른 프로세스로 전달된다. UDP와 결정적으로 다른 점이다.
다중화/역다중화 정리
- 다중화와 역다중화는 세그먼트와 데이터그램의 헤더 필드 값을 기반으로 동작한다.
- UDP: 목적지 포트 번호만으로 역다중화
- TCP: 4-tuple (출발지/목적지 IP + 포트)로 역다중화
- 다중화/역다중화는 모든 계층에서 발생한다.
3.3 Connectionless Transport: UDP
UDP는 "no frills", "bare bones" 인터넷 전송 프로토콜이다. 최소한의 기능만 제공하며, 다음과 같은 특징을 가진다.
신뢰성 없음(No Reliability):
- 세그먼트가 손실되거나 순서가 뒤바뀌어 애플리케이션에 전달될 수 있다.
- 흐름 제어, 혼잡 제어가 없다.
- 체크섬(Checksum)에 의한 오류 검출을 제외하면 오류 복구 메커니즘이 없다.
비연결형(Connectionless):
- 송신자와 수신자 간에 핸드셰이킹(Handshaking)이 없다.
왜 UDP를 사용하는가?
- 연결 설정이 없다: 연결 설정에 따른 RTT 지연이 발생하지 않는다.
- 단순하다: 송수신 측에 연결 상태를 유지할 필요가 없다.
- 헤더 크기가 작다: UDP는 8바이트, TCP는 20바이트이다.
- 혼잡 제어가 없다: 원하는 속도로 데이터를 전송할 수 있으며, 네트워크 혼잡 상황에서도 동작 가능하다. (RFC 4340의 DCCP는 혼잡 제어를 추가한 프로토콜이다.)
- 1:1 통신에 제한되지 않는다: 멀티캐스트를 통한 회의(conference) 서비스 등 1:다 통신이 가능하다.
- TCP 대비 오버헤드가 적어 애플리케이션 수준에서 더 세밀한 제어가 가능하다.
UDP 사용 사례
- 스트리밍 멀티미디어: 손실에 민감하지 않지만 전송 속도에 민감한 애플리케이션
- DNS: 연결 설정/해제 오버헤드 없이 빠르게 질의/응답
- SNMP: 네트워크 관리 프로토콜로, 네트워크 상태가 좋지 않을 때 TCP를 사용하면 오히려 부담이 커지므로 낮은 오버헤드의 UDP를 사용
- RIP(Routing Information Protocol): 30초마다 주기적으로 업데이트하며, 인접 라우터와 통신하므로 오류율이 낮고, 오류가 있더라도 곧 다시 업데이트된다.
- HTTP/3(QUIC + UDP): UDP 위에서 신뢰적 전송이 필요한 경우, 애플리케이션 계층에서 신뢰성과 혼잡 제어를 구현한다. QUIC이 전송 계층의 기능을 애플리케이션 레벨에서 수행하는 방식이다.
UDP의 Transport Layer Actions
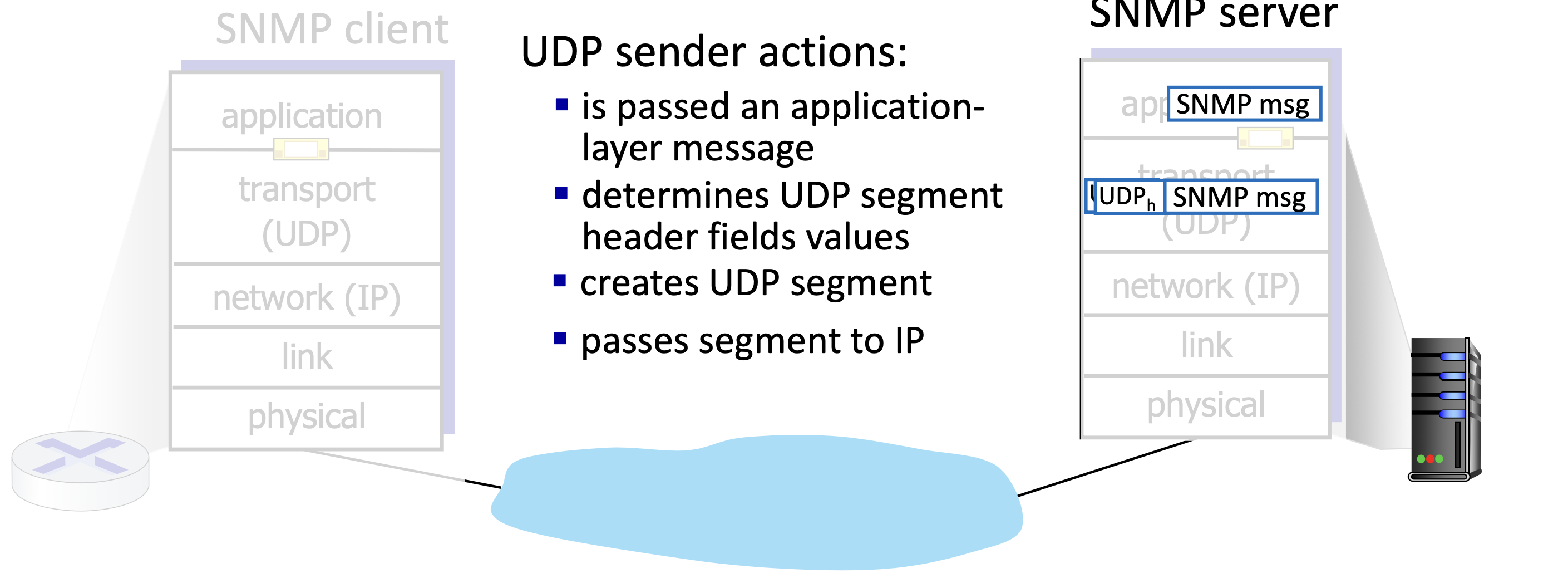
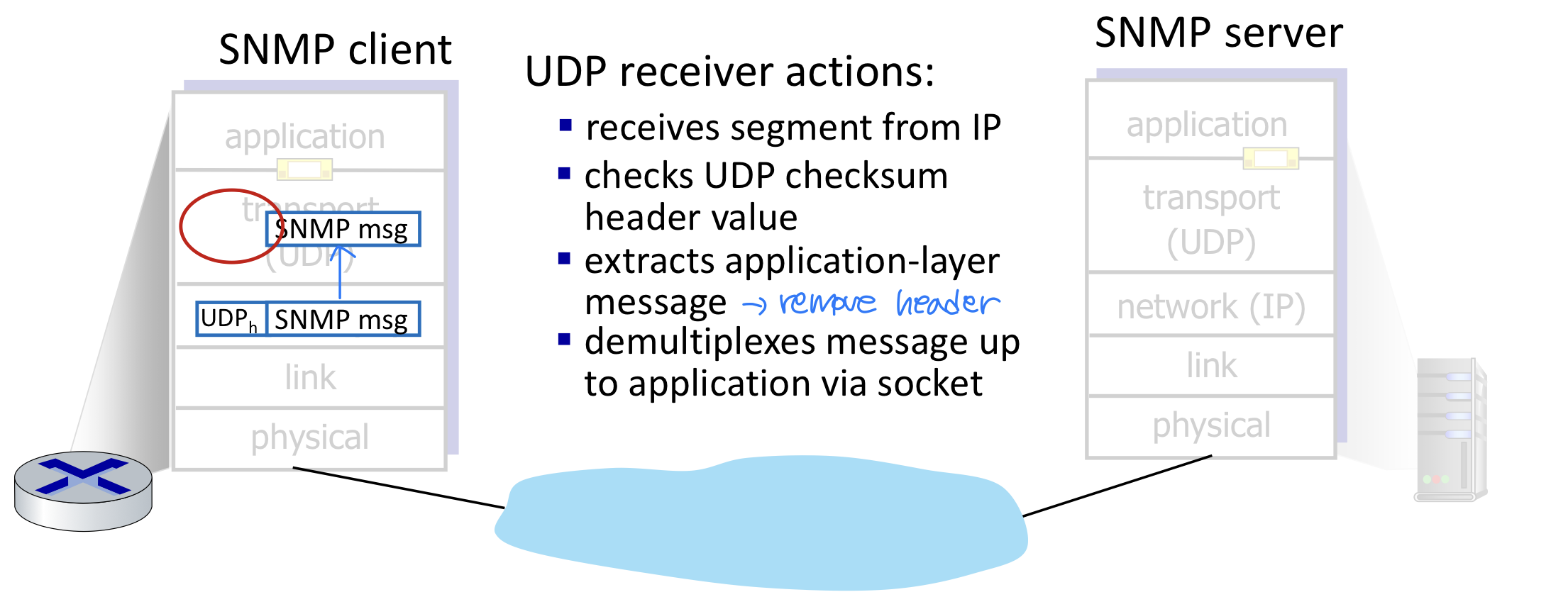
UDP Segment Format
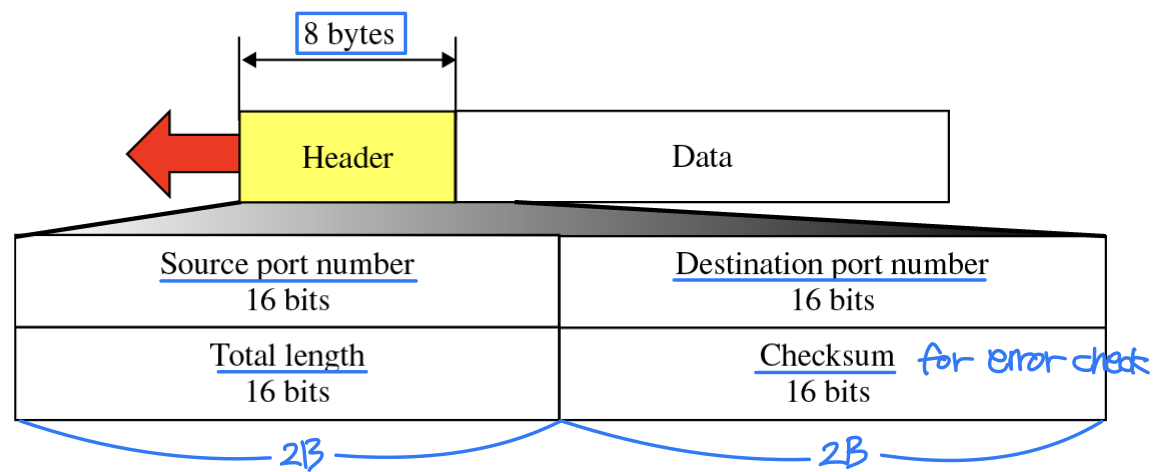
UDP 세그먼트의 주요 필드는 다음과 같다.
- Total Length: 헤더 + 데이터의 전체 길이
- Data(Payload): 애플리케이션 계층으로부터 받은/보낼 데이터
- Checksum: 헤더, 데이터, Pseudo-header를 포함한 전체 사용자 데이터그램에 대한 오류 검출 용도
- IPv4에서는 선택 사항이다 (IPv4 자체에서 오류 검사를 수행하기 때문).
- IPv6에서는 필수이다 (IPv6 헤더에 체크섬 필드가 없기 때문).
- 사용하지 않을 경우 해당 필드를 0으로 채운다.
- 오류가 검출되면 해당 세그먼트는 보통 폐기(discard)된다.
Pseudo-header
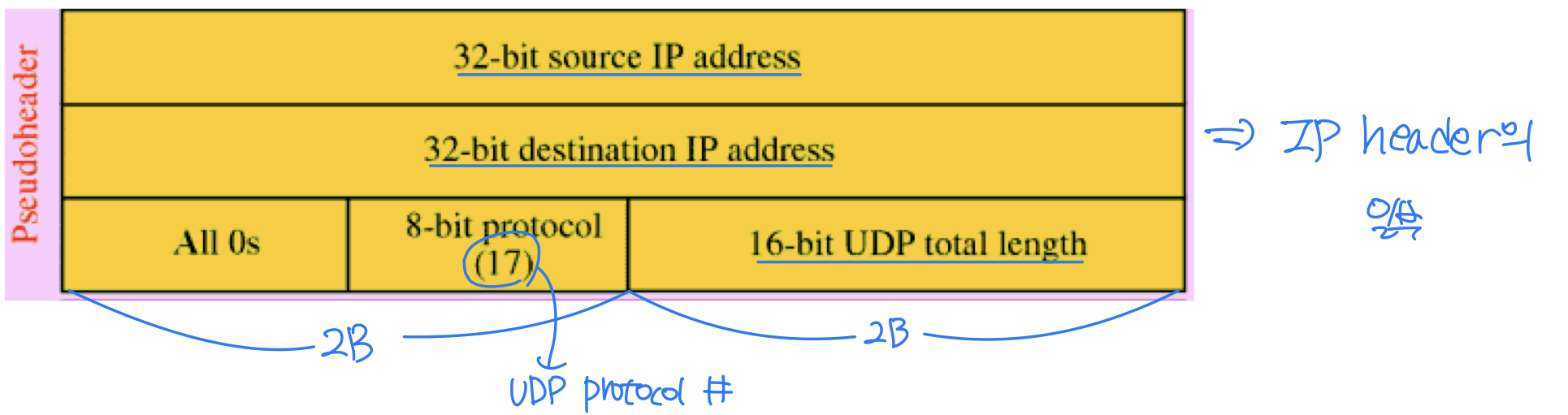
Checksum은 헤더, 데이터, Pseudo-header에 대한 1의 보수 합(one's complement sum)의 1의 보수(one's complement)로 계산되는 16비트 값이다.
Pseudo-header는 체크섬 계산에만 사용되며 실제로 전송되지는 않는다. IP 헤더의 일부 정보를 참조하므로 프로토콜 계층 위반(Layering Violation)에 해당한다. L4(전송 계층)에서 L3(네트워크 계층)의 정보를 참조하기 때문이다.
Checksum 계산 방식
Internet Checksum은 L2의 CRC에 비해 오류 검출 성능은 떨어지지만, 계산량을 단순화하기 위해 사용된다. L2에서 이미 성능이 좋은 CRC로 오류 검사를 하므로 전송 계층에서는 간단한 검사만 수행하는 것이다.
체크섬 생성 규칙:
- 데이터를 16비트 정수의 시퀀스로 간주한다.
- 모든 데이터를 16비트 1의 보수 덧셈으로 합산한다.
- 그 결과의 1의 보수를 취한다.
오류 검사 규칙:
- 체크섬을 포함한 모든 데이터를 16비트 1의 보수 덧셈으로 합산한다.
- 결과가 모두 1(즉, 1의 보수 산술에서 -0)이면 오류 없음. 그렇지 않으면 오류가 발생한 것으로 판단한다.


3.4 신뢰적인 데이터 전송의 원리
신뢰적인 데이터 전송을 구현하는 문제는 트랜스포트 계층뿐만 아니라 링크 계층과 애플리케이션 계층에서도 발생할 수 있는 문제이다.
따라서 이 절에서는 일반적인 상황에서의 신뢰적인 데이터 전송 문제를 다룬다.
신뢰적인 데이터 전송 연구의 프레임워크는 다음과 같다.
a. 서비스 모델
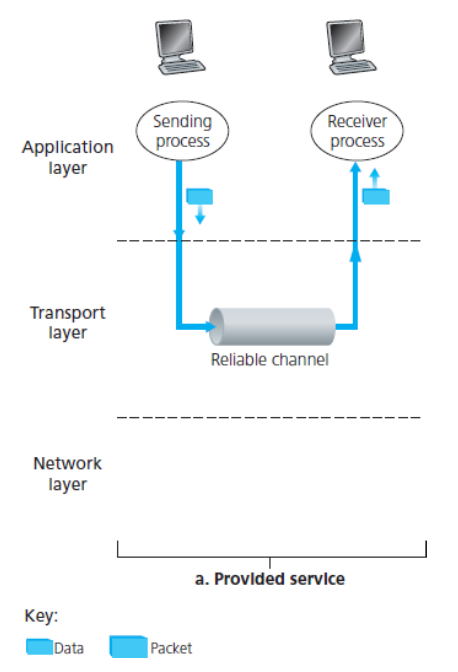
b. 서비스 구현
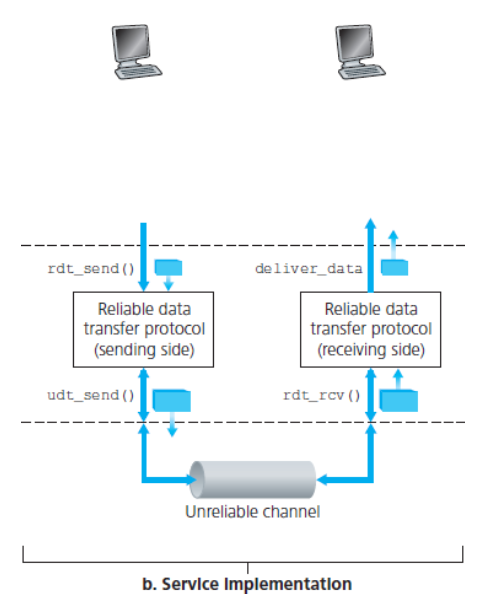
상위 계층 객체에게 제공되는 서비스 추상화는 / 데이터가 전송될 수 있는 신뢰적인 채널의 서비스 추상화다.
- 신뢰적인 채널에서는 전송된 데이터가 손상되거나 손실되지 않으며,
- 모든 데이터는 전송된 순서 그대로 전달된다.
= TCP가 인터넷 애플리케이션에게 제공하는 서비스 모델
신뢰적인 데이터 전송 프로토콜(reliable data transfer protocol)의 의무는 신뢰적인 채널의 서비스 추상화를 구현하는 것이다.
이 절에서는 점점 복잡해지는 하위 채널 모델을 고려하여 신뢰적인 데이터 전송 프로토콜의 송신자 측면과 수신자 측면을 점진적으로 개발해나간다.
논의 과정 중 채택할 한 가지 가정 : 패킷은 순서대로 전달된다.(하부 채널은 패킷의 순서를 바꾸지 않음)
위 두 가지 그림 중 b는 데이터 전송 프로토콜의 인터페이스를 나타낸다.
-
데이터 전송 프로토콜의 송신 측은
rdt_send()호출로 위쪽으로부터 호출될 것이며, 수신 측에서는 상위 계층으로 전달될 데이터를 넘길 것이다.rdt: 신뢰적인 데이터 전송(reliable data transfer) 프로토콜을 나타낸다._send: rdt의 송신 측이 호출되고 있음을 나타낸다.
-
수신 측에서
rdt_rcv()는 패킷이 채널의 수신 측으로부터 도착했을 때 호출된다. -
rdt 프로토콜이 상위 계층에 데이터를 전달하려고 할 때
deliver_data()를 호출한다.
이 절에서는
단방향 데이터 전송(unidirectional data tranfer)의 경우인 송신 측으로부터 수신 측까지의 데이터 전송만을 고려한다.
양방향(전이중) 데이터 전송(bidirectional data transfer)의 설명은 상당히 복잡하다.
단방향 데이터 전송만 생각하더라도 프로토콜의 송신 측과 수신 측이 양방향으로 패킷을 전달할 필요가 있다.
즉, rdt의 송신 측과 수신 측은 전송 데이터를 포함하는 패킷을 교환하는 것 외에 제어 패킷을 양쪽으로 전송해야 한다.
- rdt의 송신 측과 수신 측 모두
udt_send()를 호출함으로써 다른 쪽에 패킷을 전송한다.- udt : 비신뢰적인 데이터 전송(unreliable data transfer)을 나타냄
3.4.1 신뢰적인 데이터 전송 프로토콜의 구축
유한상태 머신(finite-state machine, FSM)에 대한 정의
-
화살표는 한 상태로부터 다른 상태로의 전이를 나타낸다. -
FSM의 초기 상태는
점선 화살표로 표시된다. -
전이를 일으키는 이벤트(event)는 변화를 표기하는
가로선 위에 나타낸다. -
이벤트가 발생했을 때 취해지는 행동, 액션(action)은
가로선 아래에 나타낸다. -
이벤트 발생 시 어떠한 행동도 취해지지 않거나, 어떠한 이벤트 발생 없이 행동이 취해질 때
동작이나 이벤트가 없음을 표시하기 위해 각각 가로선 아래나 위에기호 𝚲를 사용한다.
완벽하게 신뢰적인 채널상에서의 신뢰적인 데이터 전송: rdt1.0
하위 채널이 완전히 신뢰적인 가장 간단한 경우를 고려해보자.
rdt1.0에 대한 FSM
rdt1.0 송신자와 수신자에 대한 유한상태 머신(FSM) 정리는 아래 그림과 같다.
💡 송신자에 대해 그리고 수신자에 대해 분리된 FSM이 있다
- a는 송신자(sender)의 동작에 대한 정의
- b는 수신자(receiver)의 동작에 대한 정의
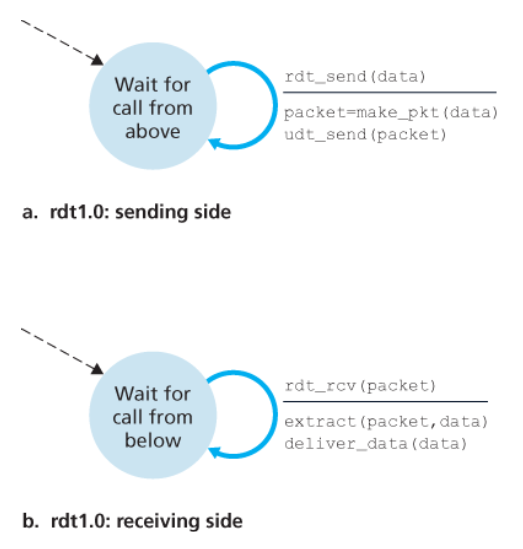
rdt1.0에서 각각의 FSM은 하나의 상태만을 가지므로, 전이는 필연적으로 그 상태로부터 자신으로 되돌아온다.
송신자
-
rdt_send(data)이벤트에 의해
(이 이벤트는 상위 계층 애플리케이션의 프로시저 호출(e.g.,rdt_send())에 의해 발생)- 상위 계층으로부터 데이터를 받아들이고
- 데이터를 포함한 패킷을 생성한다. (
make_pkt(data))
-
그러고 난 후 패킷을 채널로 송신한다.
수신자
-
rdt는
rdt_rcv(packet)이벤트에 의해 하위의 채널로부터 패킷을 수신한다. : 이 이벤트는 하위 계층 프로토콜로부터의 프로시저 호출(e.g.,rdt_rcv())에 의해 발생한다. -
패킷으로부터 데이터를 추출하고 (
extract(packet, data)) -
데이터를 상위 계층으로 전달한다. (
deliver_data(data))
여기서는 데이터 단위와 패킷의 차이점이 없으며, 모든 패킷 흐름은 송신자로부터 수신자까지다.
💡 완전히 신뢰적인 채널에서는 오류가 생길 수 없으므로 수신 측이 송신 측에게 어떤 피드백(feedback)도 제공할 필요가 없다.
또한, 수신자는 송신자가 데이터를 송신하자마자 데이터를 수신할 수 있다고 가정하였다.
따라서 수신자가 송신자에게 천천히 보내라는 것을 요청할 필요가 없다.
비트 오류가 있는 채널상에서의 신뢰적인 데이터 전송: rdt2.0
패킷 안의 비트들이 하위 채널에서 손상되는 모델이다.
일반적으로 이러한 비트 오류는 패킷이 전송 도는 전파되거나 버퍼링될 때 네트워크의 물리적인 구성요소에서 발생한다.
자동 재전송 요구(Automatic Repeat reQuest, ARQ) 프로토콜
긍정 확인응답(positive acknowledgment, “OK”)부정 확인응답(negative acknowledgment, “그것을 반복해주세요”)
이러한 제어 메시지는 정확하게 수신되었는지 또는 잘못 수신되어 반복이 필요한지를 수신자가 송신자에게 알려줄 수 있게 한다.
비트 오류를 처리하기 위해 기본적으로 다음과 같은 세 가지 부가 프로토콜 기능이 ARQ 프로토콜에 요구된다.
오류 검출
비트 오류가 발생했을 때 수신자가 검출할 수 있는 기능이 필요하다. → checksum
이러한 기술은 수신자가 패킷 비트 오류를 검출하고 복구할 수 있게 해준다.
수신자 피드백
송신자가 수신자의 상태를 알기 위한 유일한 방법은 수신자가 송신자에게 피드백을 제공하는 것이다.
수신자의 상태 : 패킷이 정확하게 수신되었는지 아닌지 등
e.g., rdt2.0 프로토콜에서는 수신자로부터 송신자 쪽으로 ACK와 NAK 패킷들을 전송할 것이다.
긍정 확인 응답(ACK)부정 확인 응답(NAK)
→ 이러한 패킷은 단지 한 비트 길이면 된다. (0 또는 1)
재전송
수신자에서 오류를 가지고 수신된 패킷은 송신자에 의해 재전송(retransmit)된다.
rdt2.0에 대한 FSM
송신자
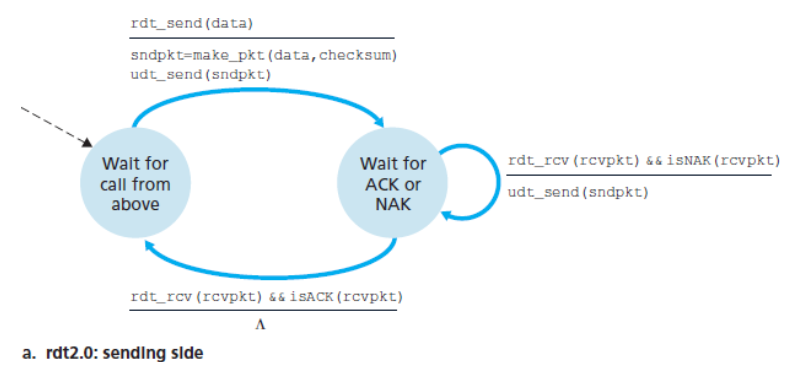
2개의 상태가 존재한다.
-
왼쪽 상태에서 송신 측 프로토콜은 상위 계층으로부터 데이터가 전달되기를 기다린다.
rdt_sent(data)이벤트가 발생하면,- 송신자는 패킷 체크섬과 함께 전송될 데이터를 포함하는 패킷(
sndpkt)을 생성하고, - 그 패킷을
udt_send(sndpkt)동작을 통해 전송한다.
- 송신자는 패킷 체크섬과 함께 전송될 데이터를 포함하는 패킷(
-
오른쪽 상태에서 송신자 프로토콜은 수신자로부터의 ACK 또는 NAK 패킷을 기다린다.
- 만약
ACK패킷이 수신된다면 (rdt_rcv(rcvpkt) && isACK(rcvpkt))- 가장 최근에 전송된 패킷이 정확하게 수신되었음을 의미한다.
- 따라서 프로토콜은 상위 계층으로부터 데이터를 기다리는 상태로 돌아간다.
- 만약
NAK가 수신된다면- 프로토콜은 마지막 패킷을 재전송한다.
- 재전송된 데이터 패킷에 대한 응답으로 수신자에 의해 응답하는 ACK 또는 NAK를 기다린다.
- 만약
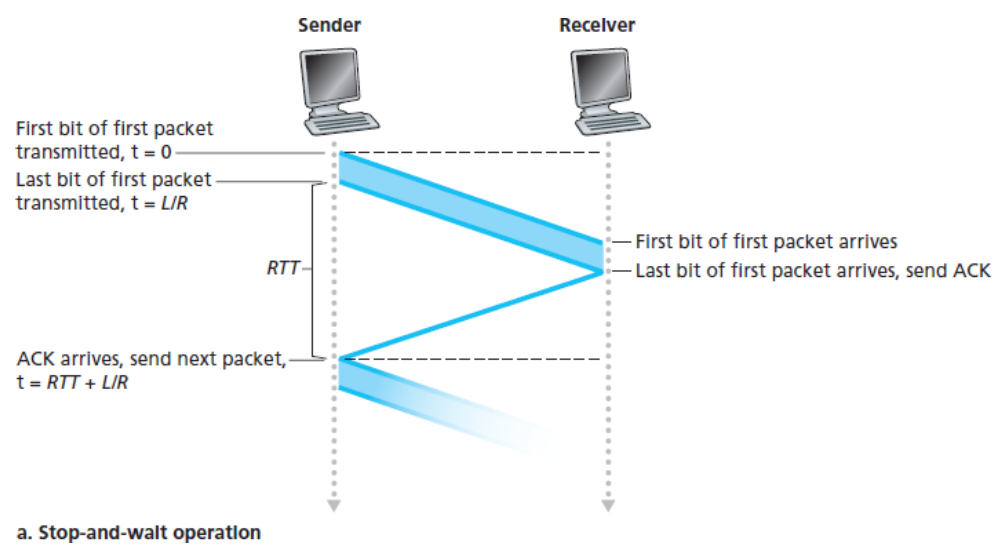
rdt2.0과 같은 프로토콜은 전송 후 대기(stop-and-wait) 프로토콜이다.
💡 송신자가 ACK 또는 NAK를 기다리는 상태에 있을 때, 상위 계층으로부터 더 이상의 데이터를 전달받을 수 없다.
즉, rdt_send() 이벤트는 발생할 수 없으며, 이는 오직 송신자가 ACK를 수신하고 이 상태를 떠난 후에 발생할 것이다.
따라서 송신자는 수신자가 현재의 패킷을 정확하게 수신했음을 확신하기 전까지 새로운 데이터를 전달하지 않는다.
수신자
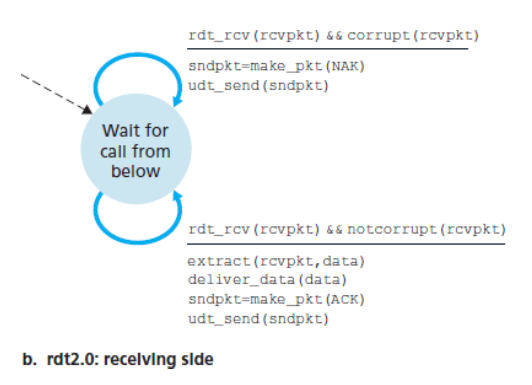
단일 상태를 갖는다.
패킷이 도착했을 때, 수신자는 수신된 패킷이 손상되었는지 아닌지에 따라 ACK 또는 NAK로 응답한다.
rdt2.0의 결함
여기서는 ACK 또는 NAK 패킷이 손상될 수 있다는 가능성을 고려하지 않았다.
만약 ACK 또는 NAK가 손상되었다면, 송신자는 수신자가 전송된 데이터의 마지막 부분을 올바르게 수신했는지를 알 방법이 없다.
대안 1 : 송신자가 검출뿐만 아니라 비트 오류로부터 회복할 수 있도록 충분한 체크섬 비트들을 추가한다.
이 방식은 패킷이 손상될 수 있으나 손실되지는 않는 채널의 경우에는 즉각적으로 문제를 해결할 수 있다.
대안 2 : 송신자가 왜곡된 ACK 또는 NAK 패킷을 수신할 때 현재 데이터 패킷을 단순히 다시 송신한다.
그러나 이 방식은 송신자에게 수신자 간의 채널로 중복 패킷(duplicate packet)을 전송한다.
- 송신자 입장에서는 마지막으로 전송된 ACK 또는 NAK가 송신자에게 정확하게 수신됐는지를 알 수 없다.
- 수신자 입장에서는 도착하는 패킷이 새로운 데이터를 포함하고 있는 것인지 아니면 재전송인지를 사전에 알 수 없다.
해결책
💡 데이터 패킷에 새로운 필드를 추가하고 이 필드 안에
순서 번호(sequence number)를 삽입하는 방식으로 데이터 패킷에 송신자가 번호를 붙인다.
이는 현존하는 데이터 전송 프로토콜에 채택된 방법이다.
수신자는 수신된 패킷이 재전송인지를 결정할 때는 이 순서 번호만 확인하면 된다.
rdt2.0의 수정 버전: rdt2.1
rdt2.1은 rdt2.0보다 두 배 많은 상태를 가지고 있다.
이는 아래의 2가지를 반영해야 하기 때문이다.
- 프로토콜 상태가 현재 (송신자에 의해) 전송되고 있는지에 대한 반영
- (수신자가) 기다리고 있는 패킷이 순서 번호 0 또는 1을 가져야 하는지에 대한 반영
프로토콜 rdt2.1은 수신자로부터 송신자까지의 긍정 확인응답과 부정 확인응답을 모두 포함한다.
- 순서가 바뀐 패킷이 수신되면, 수신자는
이미 전에 수신한 패킷에 대한 긍정 확인응답을 전송한다. - 손상된 패킷이 수신되면, 수신자는
부정 확인응답을 전송한다.
NAK를 송신하는 것 대신에,
가장 최근에 정확하게 수신된 패킷에 대해 ACK를 송신함으로써 NAK를 송신한 것과 같은 효과를 얻을 수 있다.
즉, 같은 패킷에 대해 2개의 ACK를 수신(즉, 중복(duplicate) ACK를 수신)한 송신자는
수신자가 두 번 ACK 한 패킷의 다음 패킷을 정확하게 수신하지 못했다는 것을 알게 된다. (NAK의 의미와 동일)
rdt2.1에 대한 FSM
송신자
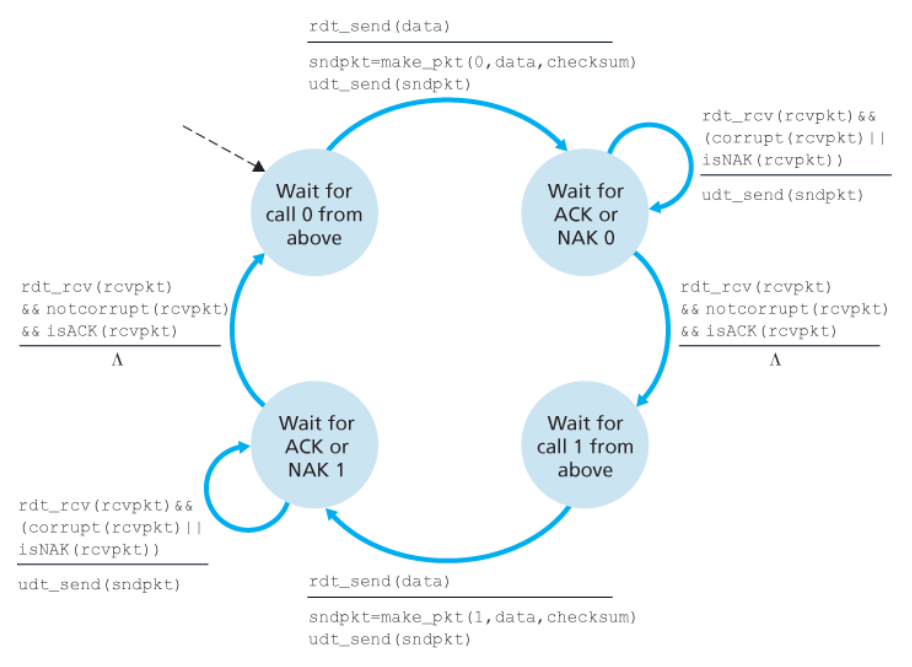
수신자
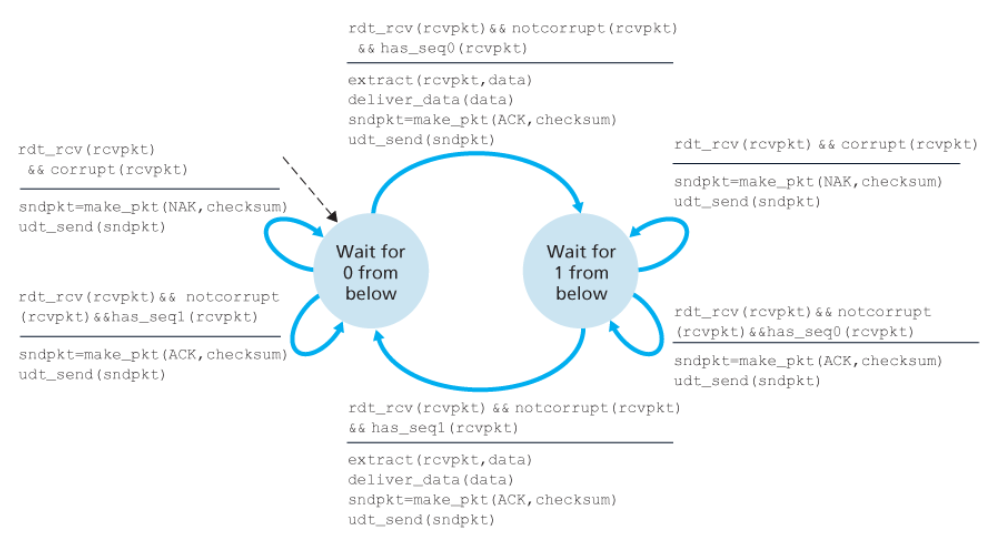
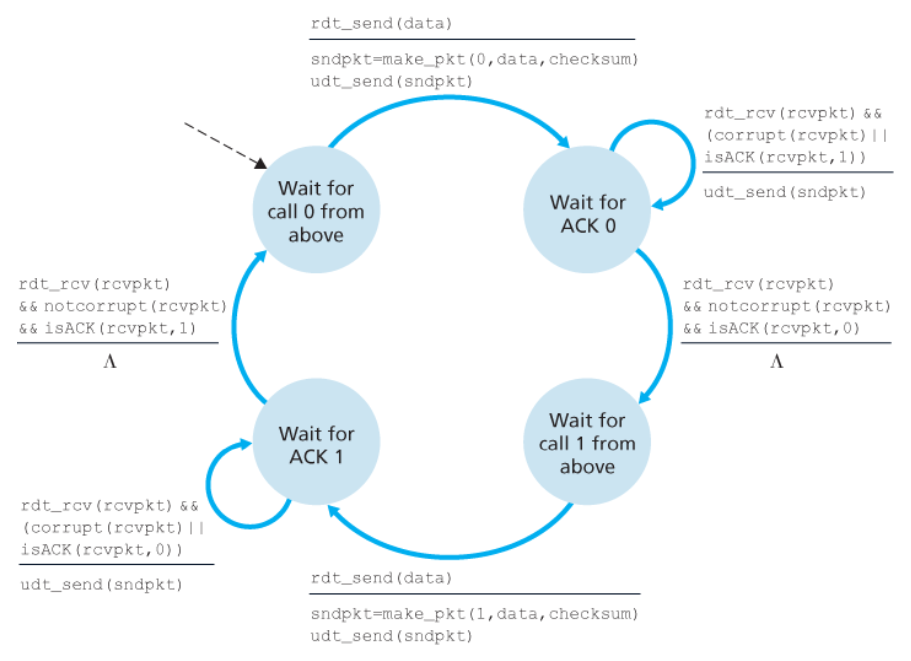
비트 오류를 갖는 채널을 위한 NAK 없는 신뢰적인 데이터 전송 프로토콜 : rdt2.2
rtd2.2는 rdt2.1과 다르게,
- 수신자가 반드시 ACK 메시지에 의해 확인 응답되는 패킷의 순서 번호를 포함해야 한다.
- 이는 수신자 FSM의
make_pkt()에ACK, 0또는ACK, 1인 인수를 넣어서 수행한다.
- 이는 수신자 FSM의
- 송신자는 수신된 ACK 메시지에 의해 확인응답된 패킷의 순서 번호를 반드시 검사해야만 한다.
- 이는송신자 FSM의
isACK()에0또는1인 인수를 넣어서 수행한다.
- 이는송신자 FSM의
rdt2.2에 대한 FSM
송신자
수신자
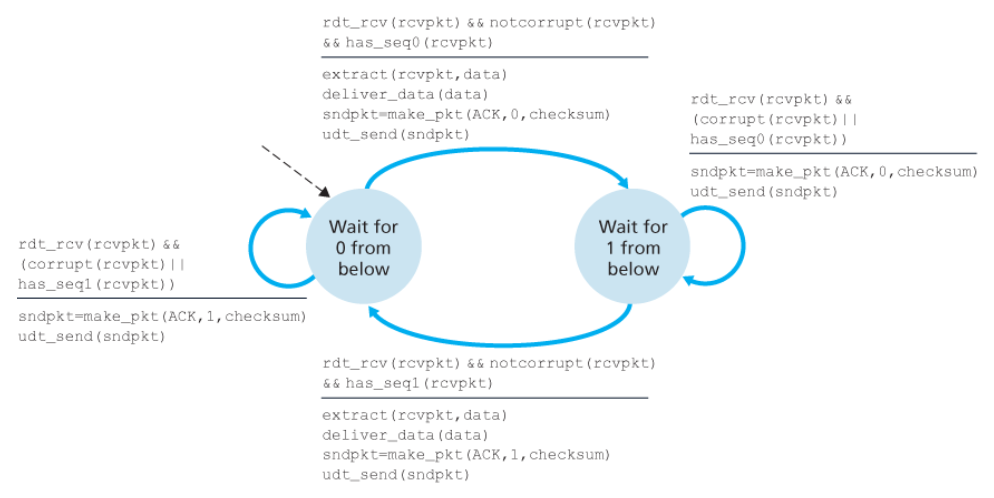
비트 오류와 손실 있는 채널상에서의 신뢰적인 데이터 전송: rdt3.0
하위 채널이 패킷을 손실하는 경우도 생각해보자.
다음과 같은 두 가지 부가 내용을 프로토콜이 다루어야 한다.
- 어떻게 패킷 손실을 검출할 것인가?
- 패킷 손실이 발생했을 때 어떤 행동을 할 것인가?
💡 송신자에게 손실된 패킷의 검출과 회복 책임을 부여한다.
송신자가 데이터 패킷을 전송하고, 패킷 또는 수신자의 패킷에 대한 ACK를 손실했다고 가정하자.
어느 경우에서나 송신자에게는 수신자로부터 어떠한 응답도 없다.
즉, 송신자는 데이터 패킷이 손실되었는지, ACK가 손실되었는지, 패킷 또는 ACK가 단순히 지나치게 지연된 것인지를 알지 못한다.
만약 송신자가 패킷을 잃어버렸다고 확신할 정도로 충분한 시간을 기다릴 수만 있다면, 데이터 패킷은 간단하게 재전송될 수 있다.
그러나 송신자가 어떤 패킷을 손실했다는 것을 확신하기 위해 얼마나 오랫동안 기다려야 할까?
송신자는 적어도 다음의 시간만큼을 기다려야 한다.
송신자와 수신자 사이의
왕복 시간 지연(중간 라우터에서의 버퍼링을 포함) + 수신 측에서패킷을 처리하는 데 필요한 시간
실제 상황에서 채택한 접근 방식은 이와 같다.
💡 패킷 손실이 일어났을 만한 그런 시간을 선택하여, 만일 ACK가 이 시간 안에 수신되지 않는다면 패킷은
재전송된다.
이것은 송신자 대 수신자 채널에서 중복 데이터 패킷(duplicate data packet)의 가능성을 포함하나,
프로토콜 rdt2.2에서처럼 패킷의 순서 번호를 통하여 처리가 가능하다.
시간 기반의 재전송 메커니즘을 구현하기 위해서는
주어진 시간이 지난 후에 송신자를 인터럽트(중단)할 수 있는카운트다운 타이머(countdown timer)가 필요하다.
그러므로 송신자는 다음처럼 동작해야 한다.
- 매 패킷(첫 번째 또는 재전송 패킷)이 송신된 시간에 타이머를 시작한다.
- 타이머 인터럽트에 반응한다. (즉, 적당한 행동을 취함)
- 타이머를 멈춘다.
rdt3.0에 대한 FSM
송신자
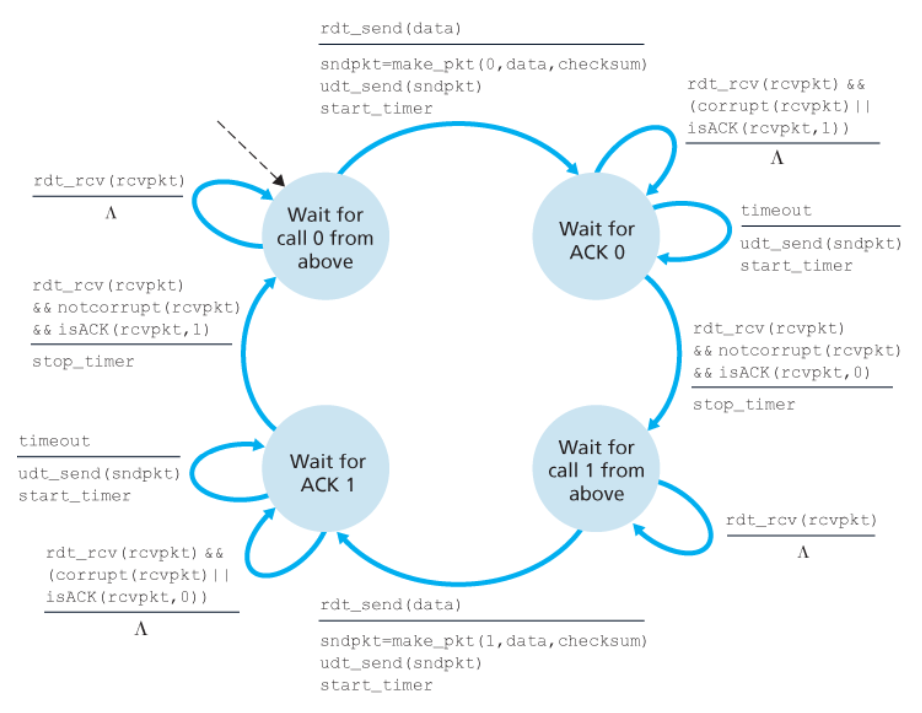
동작과 처리 과정
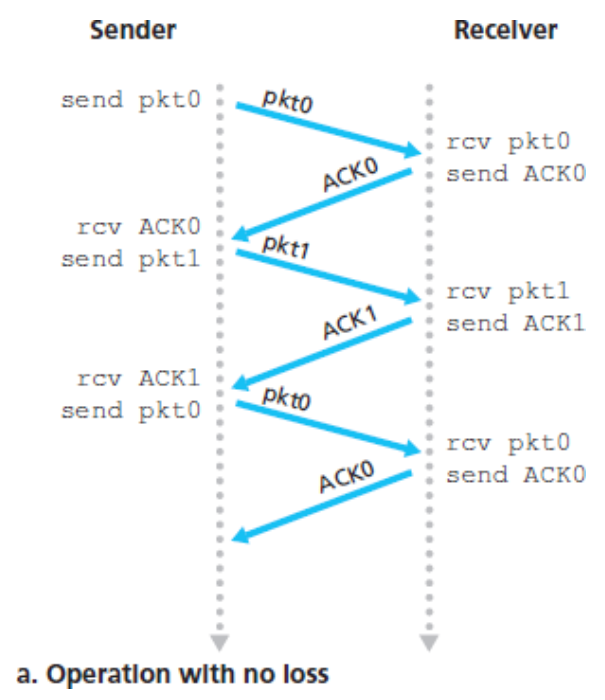
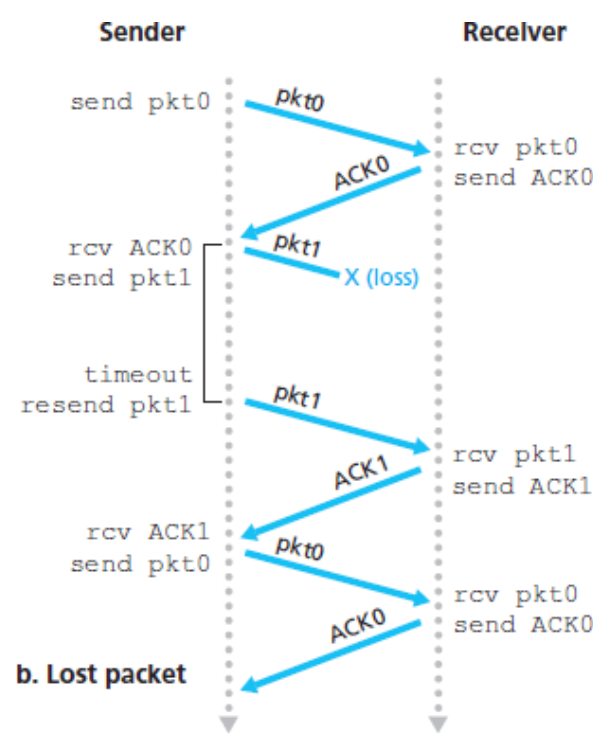
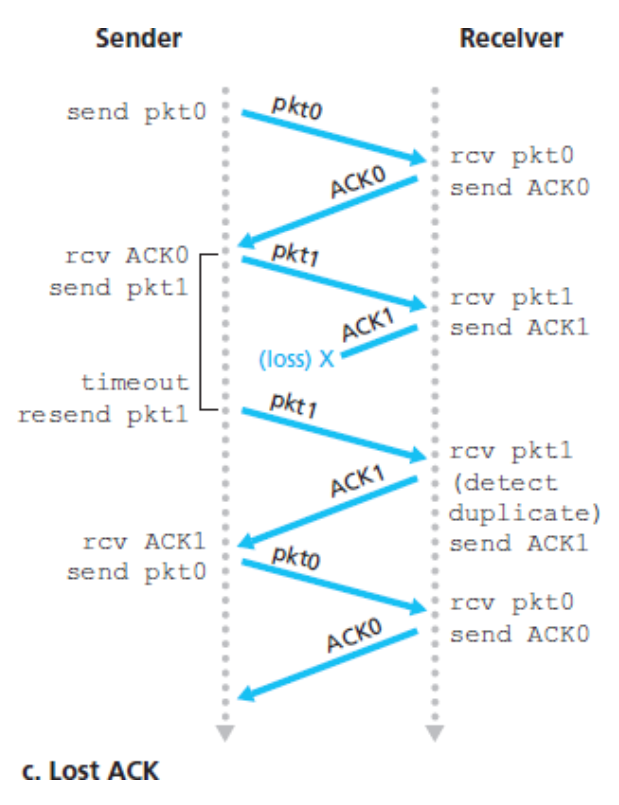
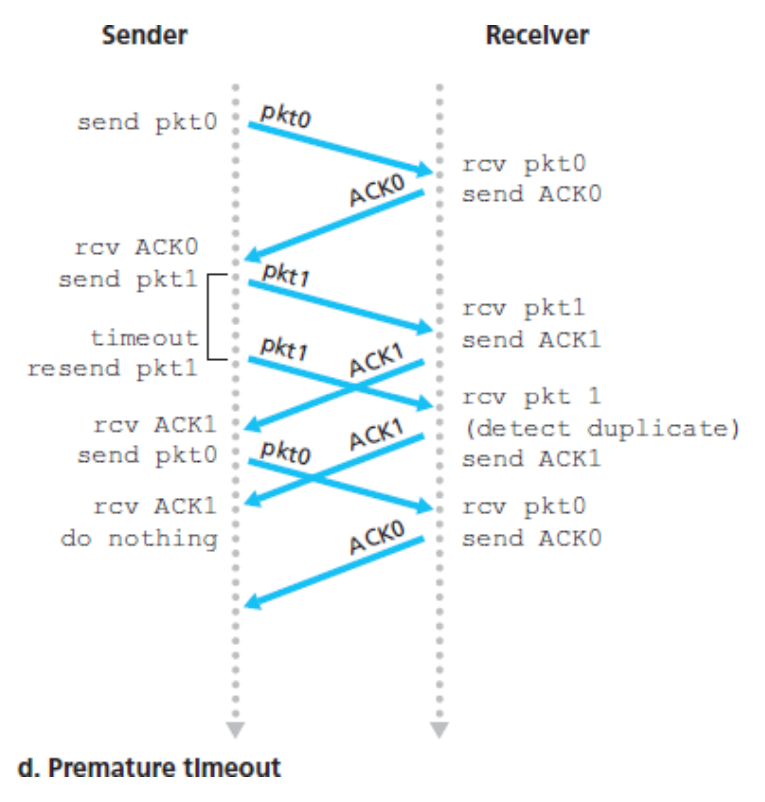
아래의 4가지 다이어그램은 프로토콜이 패킷 손실 또는 지연 없이 어떻게 동작하는지와 손실된 데이터 패킷을 어떻게 처리하는지를 나타낸 것이다.
시간은 다이어그램의 위로부터 아래로 흐른다.
패킷에 대한 수신 시간은 전송 지연과 전파 지연 때문에 패킷 전송 시간보다 더 늦다.
패킷의 순서 번호가 0과 1이 번갈아 일어나기 때문에 프로토콜 rdt3.0은
얼터네이팅 비트 프로토콜(alternating-bit protocol)이라고 부른다.
무손실 동작
패킷 손실
ACK 손실
조급한 타임아웃
3.4.2 파이프라이닝된 신뢰적인 데이터 전송 프로토콜
프로토콜 rdt3.0은 기능적으로는 정확한 프로토콜이나, 오늘날의 고속 네트워크에서 누구나 이것의 성능에 만족하는 것은 아니다.
💡 rdt3.0의 핵심적인 성능 문제는
전송 후 대기(stop-and-wait) 프로토콜이라는 점 때문에 발생한다.
전송 후 대기 프로토콜은 형편없는 송신자 이용률(utilization, 또는 효율)을 갖는다.
이에 대한 해결책은 다음과 같다.
송신자에게 확인응답을 기다리기 전에 송신을 전송하도록 허용하는 것이다. =
파이프라이닝(pipelining)
즉, 많은 전송 중인 송신자-수신자 패킷을 파이프라인에 채워 넣는 것이다.
아래의 그림들을 통해 만약 확인응답들을 기다리기 전에 송신자가 3개의 패킷을 전송하도록 허용한다면
송신자의 이용률은 3배가 되리라는 것을 볼 수 있다.
즉, window size 만큼 효율이 증가한다는 것이다.
전송 후 대기 동작
파이프라이닝된 동작
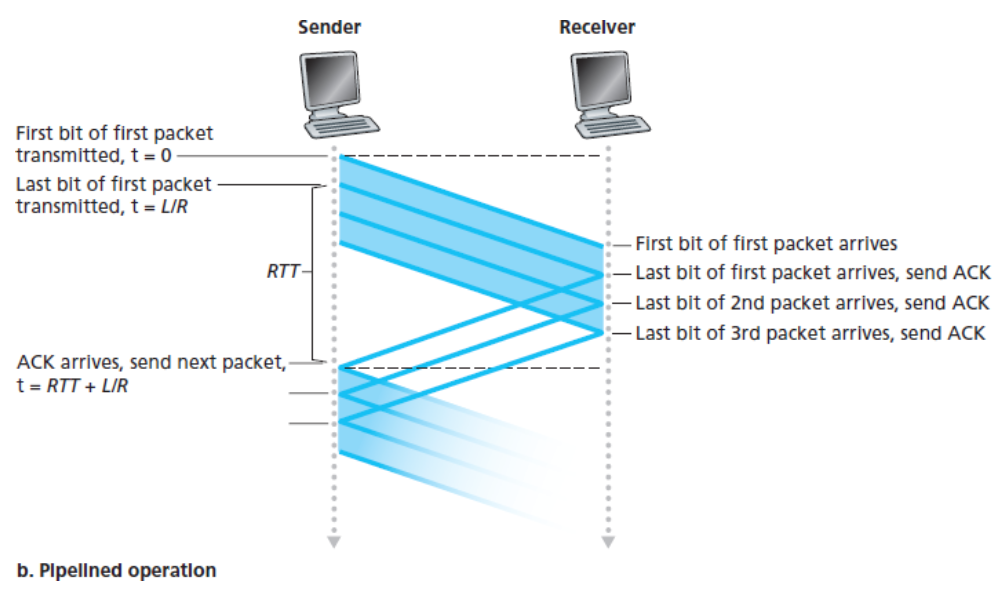
파이프라이닝 방식은 신뢰적인 데이터 전송 프로토콜에서 다음과 같은 중요성을 지니고 있다.
순서 번호의 범위가 커져야 한다.
각각의 전송 중인 패킷은 유일한 순서 번호를 가져야 한다.
전송 중인 확인응답(ACK)이 안 된 패킷이 여럿 있을지도 모르기 때문이다.
프토로콜의 송신 측과 수신 측은 패킷 하나 이상을 버퍼링해야 한다.
최소한 ‘송신자는 전송되었으나 확인응답되지 않은 패킷’을 버퍼링해야 한다.
정확하게 수신된 패킷의 버퍼링은 수신자에게서도 필요하다.
필요한 순서 번호의 범위와 버퍼링 조건은 데이터 전송 프로토콜이 손실 패킷과 손상 패킷 그리고 상당히 지연된 패킷들에 대해 응답하는 방식에 달려 있다.
파이프라인 오류 회복의 두 가지 기본적인 접근 방법
GBN(Go-Back-N): N부터 반복SR(Selective Repeat): 선택적 반복
3.4.3 GBN
💡
GBN(Go-Back-N, N부터 반복) 프로토콜에서 송신자는 확인 응답을 기다리지 않고 여러 패킷을 전송(가능할 때)할 수 있다.
그러나 파이프라인에서
확인응답이 안 된 패킷의 최대 허용 수 N보다 크지 말아야 한다.
아래 그림은 GBN 프로토콜에서 송신자 관점의 순서 번호 범위를 보여준다.
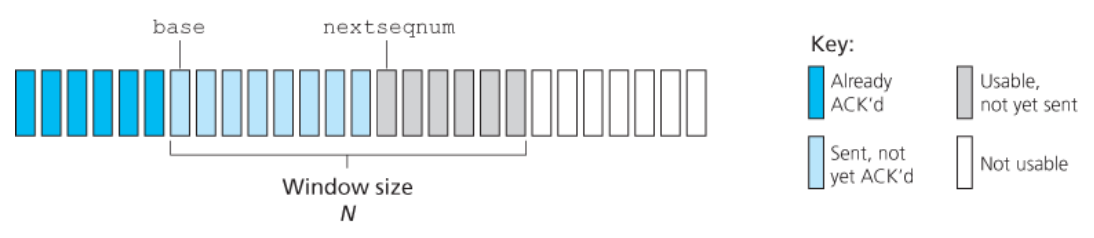
- 확인응답이 안 된 가장 오래된 패킷의 순서 번호를
base로 정의한다. - 가장 작은 순서 번호를
nextseqnum(전송될 다음 패킷의 순서 번호)으로 정의한다.
이를 통해서 순서 번호의 범위에서 4개의 간격을 식별할 수 있다.
-
간격
[0, base-1]: 순서 번호는 이미 전송되고 확인응답이 된 패킷 -
간격
[base, nextseqnum-1]: 송신은 되었지만 아직 확인응답되지 않은 패킷 -
간격
[nextseqnum, base+N-1]: 상위 계층으로부터 데이터가 도착하면 바로 전송될 수 있는 패킷 -
base+N 이상
→ 파이프라인에서 확인응답이 안 된 패킷(특히, 순서 번호base를 가진 패킷)의 확인응답이 도착할 때까지 사용될 수 없다.
슬라이딩 윈도 프로토콜(sliding-window protocol)
전송되었지만 아직 확인응답이 안 된 패킷을 위해,
허용할 수 있는 순서 번호의 범위는 순서 번호의 범위상에서 크기가 N인 ‘윈도(window)’로 나타낸다.
- 프로토콜이 동작할 때, 이 윈도는 순서 번호 공간에서 오른쪽으로 이동(slide)된다.
- N = 윈도 크기(window size)
따라서 GBN 프로토콜은 슬라이딩 윈도 프로토콜(sliding-window protocol)이라고 부른다.
패킷의 순서 번호
실제로 패킷의 순서 번호는 패킷 헤더 안의 고정된 길이 필드에 포함된다.
- 만약
k가 패킷 순서 번호 필드의 비트 수라면, 순서 번호의 범위는[0, 2^k - 1] - 순서 번호의 제한된 범위에서, 순서 번호를 포함하는 모든 계산은
모듈로(modulo) 2^k 연산을 이용한다.
ACK 기반의 NAK 없는 확장된(extended) FSM
base와nextseqnum변수를 추가한다.- 이러한 변수에서의 동작과 이러한 변수를 포함하는 조건부 동작을 추가한다.
송신자
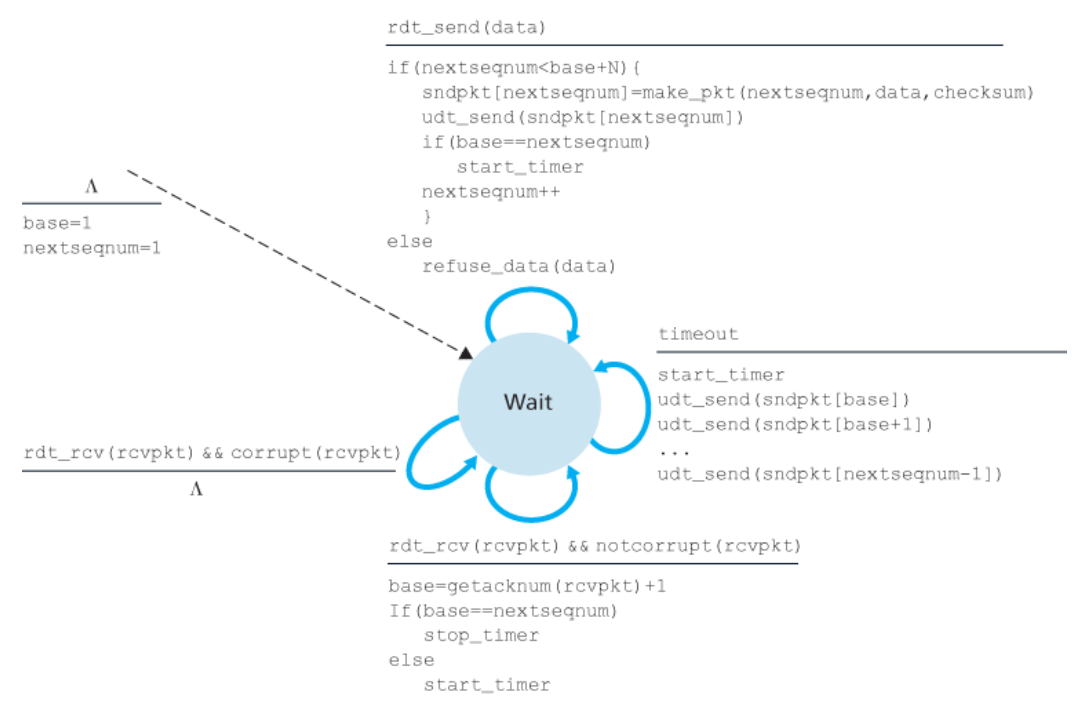
GBN 송신자는 다음과 같은 세 가지 타입의 이벤트에 반응해야 한다.
1️⃣ 상위로부터의 호출
-
rdt_send()가 위로부터 호출되면, 송신자는 우선 윈도가 가득 찼는지 확인한다.
(즉, N개의 아직 확인응답되지 않은 패킷이 있는지를 확인) -
만약 윈도가 가득 차 있지 않다면 패킷이 생성되고 송신되며, 변수들이 적절하게 갱신된다.
-
만약 윈도가 가득 차 있다면, 단지 데이터를 상위 계층으로 반환한다.
- 이는 윈도가 가득 차 있음을 가리키는 함축적인 의미이다.
- 따라서 상위 계층은 나중에
rdt_send()를 다시 시도할 것이다.
실제적인 구현에서 송신자는 아래와 같은 방법을 사용할 것이다.
- 이 데이터를 버퍼링한다. (그러나 즉시 송신하진 않음)
- 오직 윈도가 가득 차 있지 않을 때만
rdt_send()를 호출하는 동기화 메커니즘을 사용한다.
(e.g.,semaphore또는flag)
2️⃣ ACK의 수신
GBN 프로토콜에서
순서 번호 n을 가진 패킷에 대한 확인응답은 누적 확인응답(cumulative acknowledgment)으로 인식된다.
이 누적 확인 응답은 수신 측에서 올바르게 수신된 n을 포함하여, n까지의 순서 번호를 가진 모든 패킷에 대한 확인 응답이다.
3️⃣ 타임아웃 이벤트
타이머는 손실된 데이터 또는 손실된 확인응답 패킷으로부터 회복하는 데 사용된다.
만약 타임아웃이 발생한다면, 송신자는 이전에 전송되었지만 아직 확인응답되지 않은 !!모든!! 패킷을 다시 송신한다.
위의 그림에서 송신자는
**가장 오래된 ‘전송했지만, 아직 확인응답 안 된 패킷’**에 대한 타이머로 생각될 수 있는 단일 타이머를 사용한다.
- 만일 한 ACK가 수신되었지만, 추가로 ‘전송했지만, 아직 확인응답 안 된 패킷’이 아직 존재한다면, 타이머를 다시 시작한다.
- 만약 아직 확인응답 안 된 패킷이 없다면, 타이머를 멈춘다.
수신자
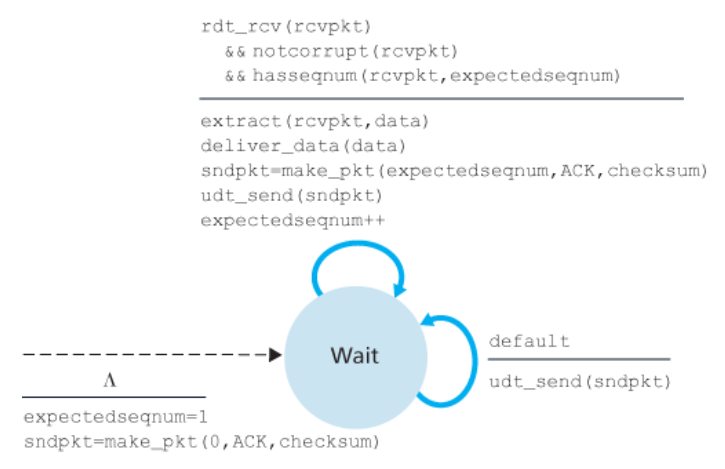
-
만약 순서 번호
n을 가진 패킷이 오류 없이, 그리고 순서대로 수신된다면
(= 상위 계층에 마지막으로 전달된 데이터가 순서 번호n-1을 가진 패킷에서 온 것이라면)
수신자는 패킷 n에 대한 ACK를 송신하고 상위 계층에 패킷의 데이터 부분을 전달한다. -
그 외의 경우에는 수신자는 그 패킷을 버리고 가장 최근에 제대로 수신된 순서의 패킷에 대한
ACK를 재전송한다.
GBM 프로토콜에서 수신자는 순서가 잘못된 패킷들을 버린다.
지금 패킷 n이 수신되어야 하지만, 그 사람 다음의 패킷 n+1이 먼저 도착했다고 가정하자.
수신자는 상위 계층에 데이터를 전달해야 한다.
데이터가 순서대로 전달되어야 하므로, 수신자는 패킷 n+1을 저장하고
나중에 패킷 n이 수신되고 전달된 후에 상위 계층에 이 패킷을 전달한다.
그러나 만일 패킷 n이 손실된다면, GBN 재전송 규칙에 따라 수신자에게는 패킷 n과 n+1이 모두 재전송될 것이다.
💡 이점 : 수신자 버퍼링이 간단하다 (수신자는 어떤 순서가 잘못된 패킷에 대해 버퍼링을 할 필요가 없다!)
- 송신자가 유지해야 하는 것
- 윈도 상위와 하위 경계
- 이 윈도 안에 있는 nextseqnum 위치
- 수신자가 유지해야 하는 것 : 다음 순서 패킷의 순서 번호
물론, 올바르게 수신된 패킷을 버리는 것의 단점은 그 패킷의 재전송이 손실되거나 왜곡될 수 있으므로 많은 재전송이 필요할 수도 있다는 것이다.
아래 그림은 윈도 크기가 4 패킷인 경우에 대한 GBN 프로토콜의 동작을 보여준다.
- 윈도 크기가 4 → 송신자는 패킷 0부터 3까지 송신한다.
- 송신을 계속하기 전에 하나 이상의 패킷이 긍정 확인응답되는 것을 기다려야 한다.
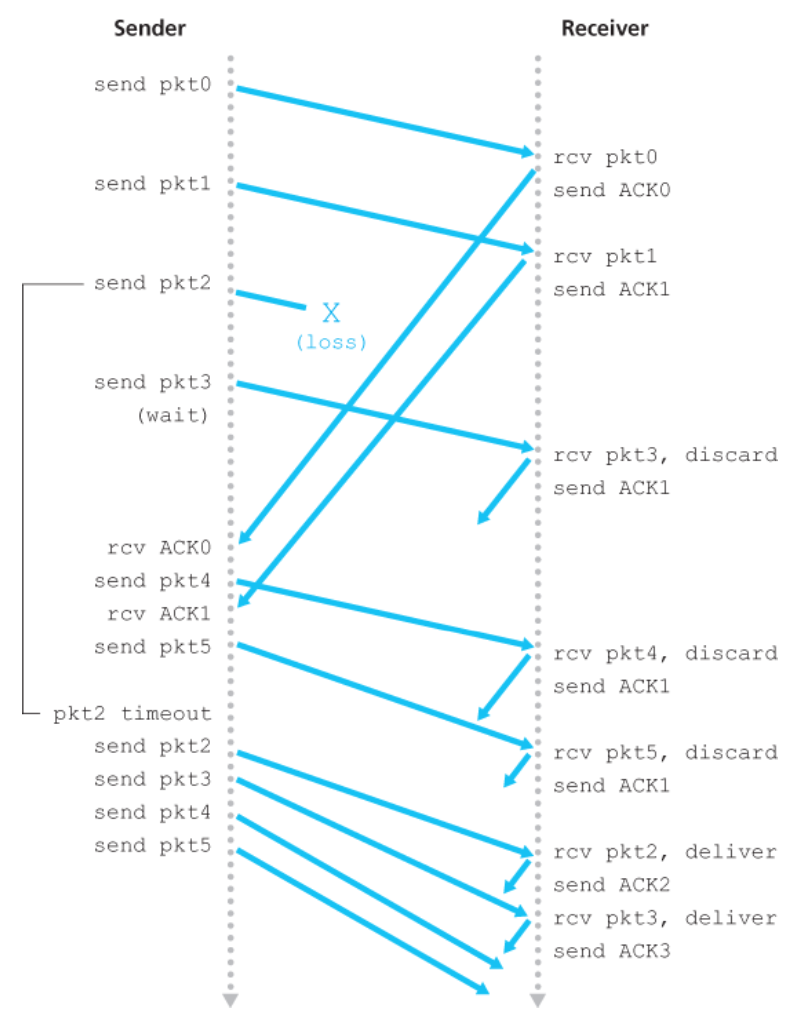
-
ACK0,ACK1처럼 각각의 성공적인 ACK가 수신되었을 때- 윈도는 앞으로 이동한다.
- 송신자는 하나의 새로운 패킷(
pkt4와pkt5, 각각)을 전송한다.
-
수신 측에서는
pkt2가 손실되었으므로pkt3, 4, 5는 순서가 잘못된 패킷으로 발견되어 제거된다.
이벤트 기반 프로그래밍(event-based programming)
앞에서 본, 확장된(extended) FSM을 다시 떠올려보자.
이 구현은 발생할 수 있는 다양한 이벤트에 대한 대응으로 취할 수 있는 동작을 구현하는 다양한 절차들과 유사하다.
이러한
이벤트 기반 프로그래밍(event-based programming)에서의 다양한 프로시저들은
프로토콜 스택에서 다른 프로시저에 의해 야기되거나 인터럽트의 결과로 요청될 것이다.
송신자에서 이러한 이벤트들에 대한 예시로는 다음과 같다.
rdt_send()를 호출하기 위한 상위 계층 개체로부터의 호출- 타이머 인터럽트
- 패킷이 도착했을 때
rdt_rcv()를 호출하기 위한 하위 계층으로부터의 호출
GBN 프로토콜의 성능 문제
GBN 프로토콜은 송신자가 패킷으로 파이프라인을 채우는 것을 통해 전송 후 대기 프로토콜에서의 채널 이용률 문제를 피하도록 하였다.
그러나 GBN 자체에는 성능 문제를 겪는 시나리오들이 존재한다.
윈도 크기와 대역폭 지연(bandwidth-delay) 곱의 결과가 모두 클 때, 많은 패킷이 파이프라인에 있을 수 있다.
GBN은 패킷 하나의 오류 때문에 많은 패킷을 재전송하므로, 많은 패킷을 불필요하게 재전송하는 경우가 발생한다.
채널 오류의 확률이 증가할수록 파이프라인은 불필요한 재전송 데이터로 채워진다.
3.4.4 SR
💡
SR(Selective Repeat, 선택적 반복) 프로토콜은
수신자에서 오류(손실되거나 변조된)가 발생한 패킷을 수신했다고 의심되는 패킷만을 재전송한다.
- 이를 통해서 SR는 불필요한 재전송을 피한다.
- 필요에 따라 각각의 개별적인 재전송은 수신자가 올바르게 수신된 패킷에 대한 개별적인 확인응답을 요구할 것이다.
윈도 크기 N은 파이프라인에서 아직 확인응답이 안 된 패킷 수를 제한하는 데 사용된다.
그러나 GBN과는 달리, 송신자는 윈도에 있는 몇몇 패킷에 대한 ACK를 이미 수신했을 것이다.
순서 번호 공간에 대한 SR 송신자의 관점
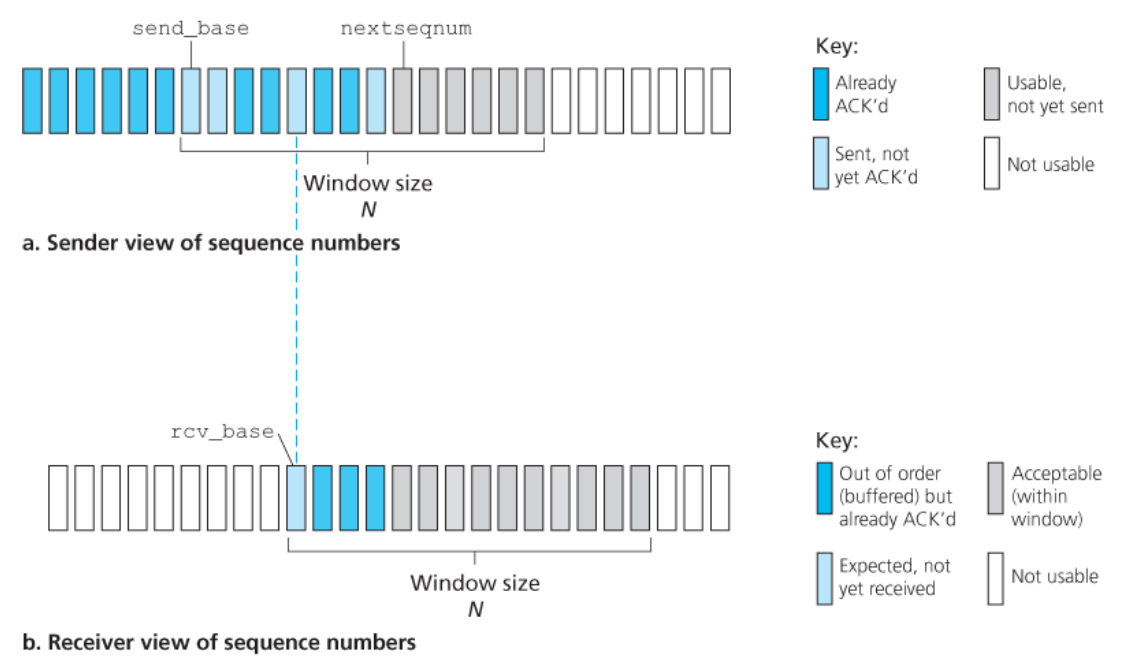
-
SR 수신자는 패킷의 순서와는 무관하게
손상 없이 수신된 패킷에 대한 확인응답을 할 것이다. -
빠진 패킷이 존재하는 경우- 순서가 바뀐 패킷은 빠진 패킷이 수신될 때까지 버퍼에 저장하고,
(빠진 패킷 = 아직 도착하지 않은 더 낮은 순서 번호를 가진 패킷) - 빠진 패킷이 수신된 시점에서 일련의 패킷을 순서대로 상위 계층에 전달할 수 있다.
(re-order & reassemble the packets → in-order delivery to upper layer)
- 순서가 바뀐 패킷은 빠진 패킷이 수신될 때까지 버퍼에 저장하고,
SR 송신자 이벤트와 행동
1️⃣ 상위로부터 데이터 수신
상위에서 데이터가 수신될 때, SR 송신자는 패킷의 다음 순서 번호를 검사한다.
- 순서 번호가 송신자 윈도 내에 있으면 데이터는 패킷으로 송신된다.
- 그렇지 않으면 GBN처럼 버퍼에 나중에 전송하기 위해 되돌려진다.
2️⃣ 타임아웃
타이머는 손실된 패킷을 보호하기 위해 재사용된다.
그러나 타임아웃 시 오직 한 패킷만이 전송되기 때문에, 각 패킷은 자신의 논리 타이머가 있어야 한다.
3️⃣ ACK 수신
ACK가 수신되었을 때, SR 송신자는 그 ACK가 윈도 내에 있다면 그 패킷을 수신된 것으로 표기한다.
- 만약 패킷 순서 번호가
send_base와 같다면, 윈도 베이스는 가장 작은 순서 번호를 가진 아직 확인응답되지 않은 패킷으로 옮겨진다. - 만약 윈도가 이동하고 윈도 내의 순서 번호를 가진 미전송 패킷이 있다면, 이 패킷들은 전송된다.
SR 수신자 이벤트와 행동
1️⃣
[rcv_base, rcv_base+N-1]내의 순서 번호를 가진 패킷이 손상 없이 수신된다.
이 경우는 수신된 패킷이 수신자의 윈도에 속하는 것이며, 선택적인 ACK 패킷이 송신자에게 회신된다.
- 만약 이 패킷이 이전에 수신되지 않았던 것이라면 버퍼에 저장된다.
- 만약 이 패킷이 수신 윈도의
base와 같은 순서 번호를 가졌다면,
이 패킷과 이전에 버퍼에 저장되어 연속적으로 번호를 가진(rcv_base로 시작하는) 패킷들은 상위 계층으로 전달된다.
2️⃣
[rcv_base-N, rcv_base-1]내의 순서 번호를 가진 패킷이 수신된다.
이 경우에는 이 패킷이 수신자가 이전에 확인응답한 것이라도 ACK가 생성되어야 한다.
3️⃣ 그 외의 경우, 패킷을 무시한다.
SR 동작
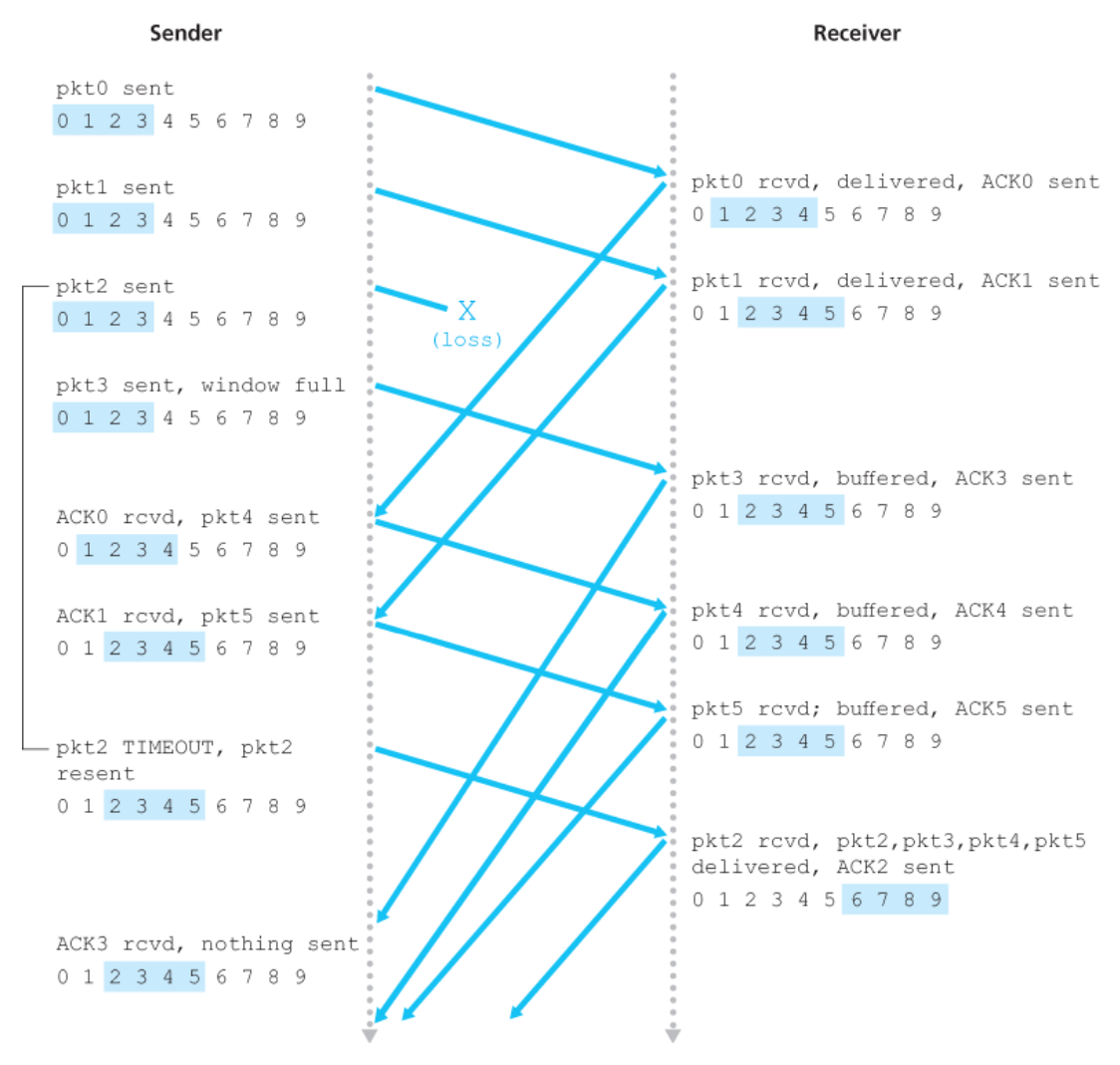
- 처음에
pkt3, 4, 5를 버퍼에 저장한다. - 마지막으로 pkt2가 수신되었을 때
pkt2와 함께 상위 계층에 전달한다.
SR 프로토콜에서 송신자와 수신자의 윈도는 항상 같지 않다
SR 수신자 이벤트와 행동의 2단계 : [rcv_base-N, rcv_base-1] 내의 순서 번호를 가진 패킷이 수신된다.
여기서 수신자가 현재의 윈도
base보다 작은 특정 순서 번호를 가진 ‘이미 수신된 패킷’을무시하지 않고 재확인 응답을 하는 것이 중요하다!
e.g.,
송신자와 수신자의 순서 번호 공간을 줬을 때, 수신자가 송신자에게 보내는 send_base 패킷에 대한 ACK가 없다면
(우리에게는 수신자가 그 패킷을 이미 수신했음이 분명하더라도) 결국 송신자는 send_base 패킷을 재전송할 것이다.
만약 수신자가 이 패킷에 대한 확인응답을 하지 않는다면, 송신자의 윈도는 결코 앞으로 이동하지 않을 것이다.
💡 송신자와 수신자는 올바른 수신과 그렇지 않은 수신에 대해 항상 같은 관점을 갖지는 않을 것이다.
→ 이는 SR 프로토콜에서 송신자와 수신자의 윈도가 항상 같지 않다는 것을 뜻한다.
송신자와 수신자 윈도 사이의 동기화 부족은 순서 번호의 한정된 범위에 직면했을 때 중대한 결과를 가져온다.
e.g.,
- 한정된 범위의 네 패킷 순서 번호
0, 1, 2, 3 - 윈도 크기 :
3
0부터 2까지의 패킷이 전송되어 올바로 수신되고, 수신자에게서 확인이 되었다고 가정하자.
그 순간에 수신자의 윈도는 각각의 순서 번호가 3, 0, 1인 4, 5, 6번째 패킷에 있다.
첫 번째 시나리오
-
처음 3개의 패킷에 대한 ACK가 손실되고, 송신자는 이 패킷을 재전송한다.
-
수신자는 순서 번호가
0인 패킷(처음 보낸 패킷의 복사본)을 수신한다.
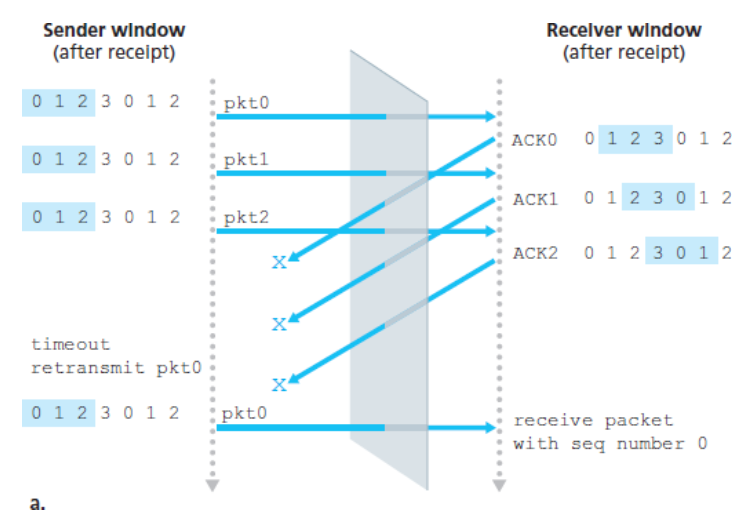
두 번째 시나리오
-
처음 3개의 패킷에 대한 ACK가 모두 올바르게 전달되었다.
-
송신자는 자신의 윈도를 앞으로 이동시켜, 각각의 순서 번호가
3, 0, 1인 4, 5, 6번째 패킷을 보낸다. -
순서 번호
3을 가진 패킷이 손실되고, 순서 번호0을 가진 패킷(새로운 데이터를 포함한 패킷)은 도착한다.
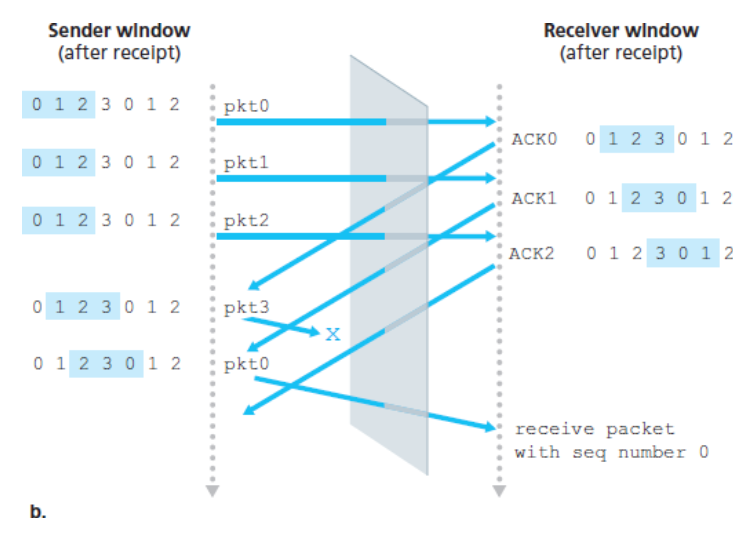
수신자 관점을 고려해보자
수신자는 송신자의 행동을 볼 수 없다.
모든 수신자는 채널을 통해 받고, 채널을 통해 보내는 메시지의 순서를 관찰하는데, 이는 위의 두 가지 시나리오가 똑같다.
즉, 다섯 번째 패킷의 원래 전송과 첫 번째 패킷의 재전송을 구별할 방법은 없다.
최소한의 윈도 크기는 얼마인가?
윈도 크기는 SR 프로토콜에 대한 순서 번호 공간 크기의 절반보다 작거나 같아야 한다.
패킷 순서 바뀜 현상
맨 앞에서 패킷들은 송신자와 수신자 사이의 채널 안에서 순서가 바뀔 수 없다는 가정 하에 신뢰적인 데이터 전송 프로토콜에 대한 설명을 진행하였다.
이는 일반적으로 송신자와 수신자가 단일한 물리적 선으로 연결되어 있을 때 적합한 가정이다.
하지만 **둘을 연결하는 ‘채널’**이 네트워크일 때는패킷 순서 바뀜이 일어날 수 있다.
패킷 순서 바뀜 현상으로, 송신자와 수신자의 윈도가 x를 포함하지 않고 있더라도
순서 번호 또는 확인응답 번호 x를 가진 오래된 패킷의 복사본들이 생길 수 있다.
패킷 순서가 바뀌는 채널이라는 것은 본질적으로 패킷들을 버퍼에 저장하고, 나중에 어느 때나 이 패킷들을 임의로 내보낸다고 간주할 수 있다.
순서 번호가 재사용될 수 있으므로 그런 중복된 패킷들을 막을 수 있는 조치가 필요하다.
실제 방식은 송신자가 이전에 송신된 순서 번호 x를 가진 패킷들이
더는 네트워크 상에 없음을 어느 정도 ‘확신’할 때까지 순서 번호가 재사용되지 않음을 확실히 하는 것이다.
이는 패킷이 어느 일정 시간 이상으로 네트워크에서 존재할 수 없다는 가정에 의해 이루어진다.
신뢰적인 데이터 전송 메커니즘과 그 사용에 대한 요약
체크섬
전송된 패킷 안의 비트 오류를 발견하는 데 사용된다.
타이머
채널 안에서 패킷이 손실되었기 때문에 발생되는 패킷(또는 이것의 ACK)의 타임아웃/재전송에 사용된다.
타임아웃
발생 이유
-
패킷이 지연되었지만 손실되지는 않았을 경우 (
조기 타임 아웃) -
패킷이 수신자에 의해 수신되었으나 수신자에서 송신자로의
ACK가 손실되었을 경우
→ 수신자에 의해 수신되는 패킷은 중복으로 복사(수신)된 패킷일 수 있다.
순서 번호
송신자에서 수신자로 가는 데이터 패킷의 순서 번호를 붙이기 위해 사용된다.
수신자 패킷의 순서 번호의 간격: 수신자가 손실된 패킷을 검사하게 한다.중복된 순서 번호를 갖는 패킷: 수신자가 패킷의 중복 복사를 검사하게 한다.
확인응답
수신자가 한 패킷 또는 패킷 집합이 정확히 수신되었다는 응답을 송신자에게 하기 위해 사용된다.
- 일반적으로 패킷 또는 이미 확인응답된 패킷들의 순서 번호를 전달한다.
- 프로토콜에 따라 개별적이거나 누적된 것일 수 있다.
부정 확인응답
수신자가 패킷이 정확히 수신되지 않았다는 응답을 송신자에게 하기 위해 사용된다.
- 일반적으로 정확히 수신되지 않은 패킷의 순서 번호를 전달한다.
윈도, 파이프라이닝
송신자는 주어진 범위에 있는 순서 번호를 가진 패킷만 전송하도록 제한될 수 있다.
확인응답은 없지만 허가된 패킷이 전송될 수 있으므로, 송신자의 이용률은 전송 후 대기 모드의 동작보다 증가할 수 있다.
윈도 크기는 수신자의 메시지를 수신하고 버퍼링하는 능력, 네트워크의 혼잡 정도, 또는 두 가지 모두에 근거하여 설정된다.
3.5 연결지향형 트랜스포트: TCP
3.5.1 TCP 연결
💡 TCP는 애플리케이션 프로세스가 데이터를 다른 프로세스에게 보내기 전에,
두 프로세스가 서로 ’핸드셰이크’를 먼저 해야 하므로연결지향형(connection-oriented)이다.
즉, 데이터 전송을 보장하는 파라미터들을 각자 설정하기 위한 어떤 사전 세그먼트들을 보내야 한다.
TCP 연결은 두 통신 종단 시스템의 TCP에 존재하는 상태를 공유하는 논리적인 것이다.
TCP 연결은 전이중 서비스(full-duplex service)를 제공한다.
만약 호스트 A의 프로세스와 호스트 B의 프로세스 사이에 TCP 연결이 있다면,
애플리케이션 계층 데이터는 B에서 A로 흐르는 동시에 A에서 B로 흐를 수 있다.
TCP 연결은 항상 단일 송신자와 단일 수신자 사이의 점대점(point-to-point)이다.
따라서 단일 송신 동작으로 한 송신자가 여러 수신자에게 데이터를 전송하는 ‘멀티캐스팅(multicasting)’은 TCP에서는 불가능하다.
TCP 연결 과정
-
클라이언트 프로세스(client process): 연결을 초기화하는 프로세스 -
서버 프로세스(server process)
세 방향 핸드셰이크(three-way handshake)
(3.5.6에서 더 자세히 다룰 예정)
-
클라이언트 애플리케이션 프로세스는 서버의 프로세스와 연결을 설정하기를 원한다고 TCP 클라이언트에게 먼저 알린다.
-
클라이언트의 트랜스포트 계층은 서버의 TCP와의 TCP 연결 설정을 진행한다.
즉, 클라이언트가 먼저 특별한
TCP 세그먼트를 보낸다. -
서버는
두 번째 특별한 TCP 세그먼트로 응답한다. -
마지막으로, 클라이언트가
세 번째 특별한 세그먼트로 다시 응답한다.
-
처음 2개의 세그먼트에는
페이로드(payload, 애플리케이션 계층 데이터)가 없다. -
세 번째 세그먼트는 페이로드를 포함할 수 있다.
TCP 연결이 설정된 이후
일단 TCP 연결이 설정되면, 두 애플리케이션 프로세스는 서로 데이터를 보낼 수 있다.
-
클라이언트 프로세스는
소켓(프로세스의 관문)을 통해 데이터의 스트림을 전달한다. -
데이터가 관문을 통해 전달되면, 이제 데이터는 클라이언트에서 동작하고 있는 TCP에 맡겨진다.
- TCP는 초기 세 방향 핸드셰이크 동안 준비된 버퍼 중의 하나인 연결의
송신 버퍼(send buffer)로 데이터를 보낸다. - 때때로 TCP는 송신 버퍼에서 데이터 묶음을 만들어서 네트워크로 보낸다. (TCP가 언제 버퍼된 데이터를 전송해야 하는지는 정해져 있지 않음)
- TCP는 초기 세 방향 핸드셰이크 동안 준비된 버퍼 중의 하나인 연결의
최대 세그먼트 크기(maximum segment size, MSS)
세그먼트로 모아 담을 수 있는 최대 데이터 양은
최대 세그먼트 크기(maximum segment size, MSS)로 제한된다.
MSS를 결정하는 요소
-
로컬 송신 호스트에 의해 전송될 수 있는 가장 큰 링크 계층 프레임의 길이
(최대 전송 단위(maximum transmission unit, MTU) -
TCP 세그먼트(IP 데이터그램 안에 캡슐화되었을 때)와 TCP/IP 헤더 길이(통상 40바이트)가 단일 링크 계층 프레임에 딱 맞도록 한다.
💡 MSS는 헤더를 포함하는 TCP 세그먼트의 최대 크기가 아니라, 세그먼트에 있는 애플리케이션 계층 데이터에 대한 최대 크기이다.
TCP 세그먼트(TCP segment)
TCP 헤더 + 클라이언트 데이터
-
네트워크 계층에 전달되어
네트워크 계층 IP 데이터그램안에 각각 캡슐화된다. -
세그먼트는 네트워크로 송신된다. -
TCP가 상대에게서 세그먼트를 수신했을 때, 세그먼트의 데이터는 TCP 연결의
수신 버퍼에 위치한다.
→ 애플리케이션은 이 버퍼로부터 데이터의 스트림을 읽는다.
TCP 연결의 양 끝은 각각 자신의
송신 버퍼와수신 버퍼를 갖고 있다.
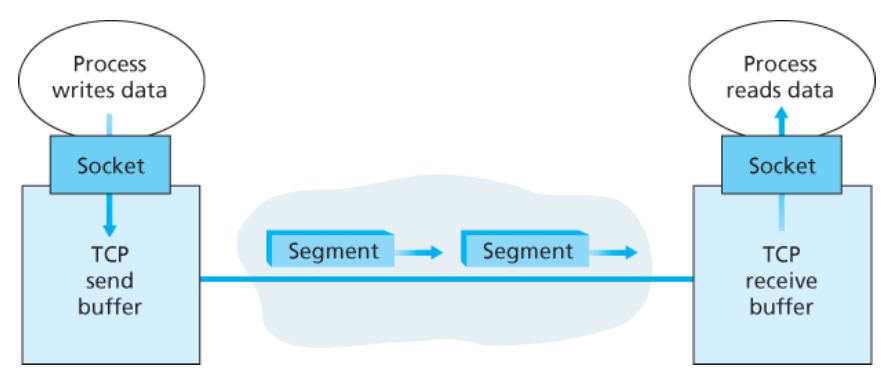
💡 즉, TCP 연결은 한쪽 호스트에서의 버퍼, 변수, 프로세스에 대한 소켓 연결과
다른 쪽 호스트에서의 버퍼, 변수, 프로세스에 대한 소켓 연결의 집합으로 이루어진다.
3.5.2 TCP 세그먼트 구조
구조
헤더 필드
-
출발지와 목적지 포트 번호(source and destination port number) -
체크섬 필드(checksum field) -
32비트
순서 번호 필드(sequence number field) -
32비트
확인응답 번호 필드(acknowledgement number field) -
16비트
수신 윈도(receive window): 흐름 제어에 사용된다.
(수신자가 받아들이려는 바이트의 크기를 나타내는데 사용됨) -
4비트
헤더 길이 필드(header length field): 32비트 워드 단위로 TCP 헤더의 길이를 나타낸다. -
옵션 필드(option field)- 이 필드는 선택적이고 가변적인 길이를 가진다.
- 송신자와 수신자가 최대 세그먼트 크기(MSS)를 협상하거나 고속 네트워크에서 사용하기 위한 윈도 확장 요소로 이용된다.
-
플래그 필드(flag field): 6비트를 포함한다.ACK비트 : 확인응답 필드에 있는 값이 유용함을 가리키는 데 사용된다.RST,SYN,FIN비트 : 연결 설정과 해제에 사용된다.PSH비트 : 이 비트가 설정되었다면 이것은 수신자가 데이터를 상위 계층에 즉시 전달해야 함을 가리킨다.URG비트- 이 세그먼트에서 송신 측 상위 계층 개체가 ‘긴급’으로 표시하는 데이터임을 가리킨다.
- 이 긴급 데이터의 마지막 바이트의 위치는 16비트의
긴급 데이터 포인터 필드(urgent data pointer field)에 의해 가리켜진다.
데이터 필드
애플리케이션 데이터의 일정량을 담는다.
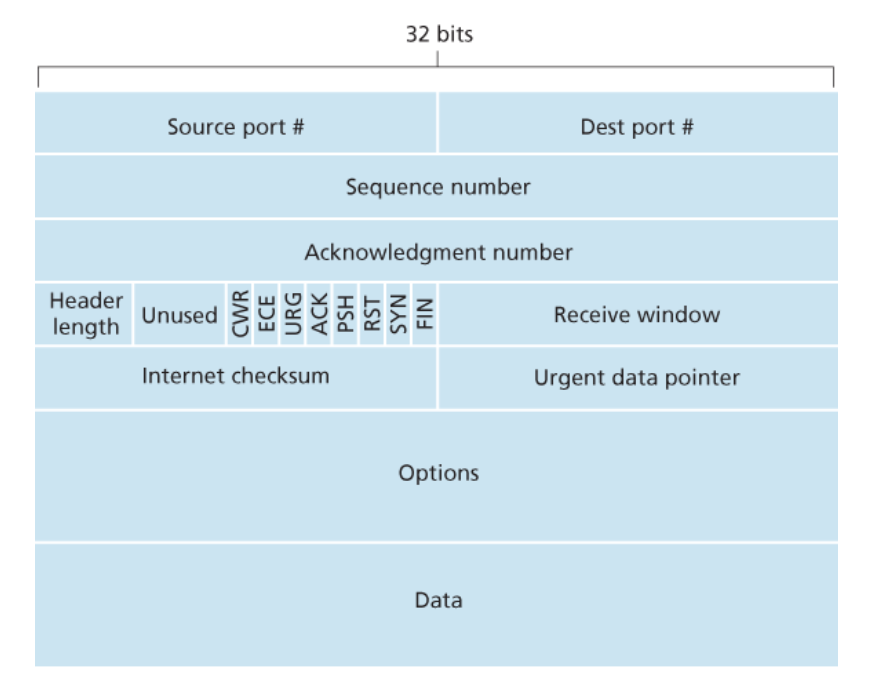
MSS
MSS는 세그먼트 데이터 필드의 크기를 제한한다.
- 큰 파일 전송 시, 일반적으로 MSS 크기로 파일을 분절한다.
- 많은 대화식 애플리케이션은 MSS보다 작은 양의 데이터를 전송한다.
순서 번호와 확인응답 번호
이 두 필드는 TCP의 신뢰적인 데이터 전송 서비스의 중대한 부분이다.
순서 번호
TCP는
데이터를 구조화되어 있지 않고 단지 순서대로 정렬되어 있는 바이트 스트림으로 본다.
세그먼트에 대한 순서 번호는 세그먼트에 있는 첫 번째 바이트의 바이트 스트림 번호다.
e.g.,
- 데이터 스트림은 500,000 바이트로 구성된 파일이라고 가정한다.
- MSS는 1,000 바이트
- 데이터 스트림의 첫 번째 바이트는 0으로 설정한다.
아래 그림처럼 TCP는 데이터 스트림으로부터 500개의 세그먼트들을 구성하며, 각 세그먼트가 할당받는 순서 번호는 다음과 같다.
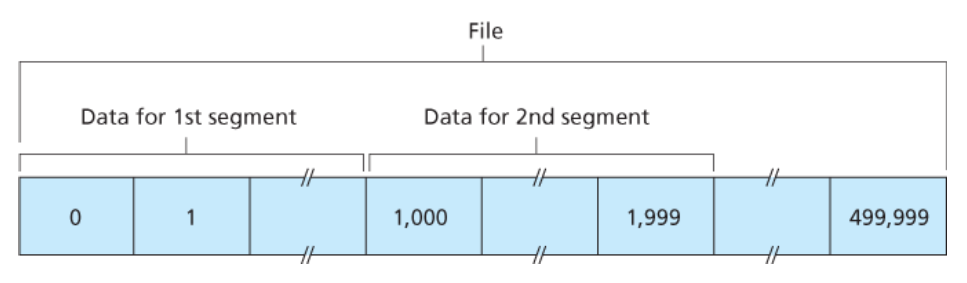
💡 각각의 순서 번호는 적절한 TCP 세그먼트의 헤더 내부의
순서 번호 필드에 삽입된다.
확인응답 번호
TCP는 전이중 방식임을 상기하자.
(호스트 A가 호스트 B로 데이터를 송신하는 동안에 호스트 B로부터 데이터를 수신하게 해줌)
호스트 B로부터 도착한 각 세그먼트는 B로부터 A로 들어온 데이터에 대한 순서 번호를 갖는다.
💡 호스트 A가 자신의 세그먼트에 삽입하는
확인응답 번호는 호스트 A가 호스트 B로부터 기대하는다음 바이트의 순서 번호다.
e.g.,
호스트 A가 호스트 B로부터
0 ~ 535의 바이트를 포함하는 어떤 세그먼트와 900 ~ 1,000의 바이트를 포함하는 또 다른 세그먼트를 수신했다고 가정하자.
(어떤 이유 때문인지 몰라도, 호스트 A는 그 사이 536~899의 바이트를 아직 수신하지 않았음)
호스트 A는 B의 데이터 스트림을 재생성하기 위해 536번째(와 그 다음의) 바이트를 아직 기다리고 있다.
그러므로 B에 대한 A의 다음 세그먼트이 확인응답 번호 필드에 536을 가질 것이다.
TCP는 스트림에서 첫 번째 잃어버린 바이트까지의 바이트들까지만 확인응답하기 때문에,
TCP는누적 확인응답(cumulative acknowledgment)을 제공한다고 한다.
위 예에서 호스트 A는 세 번째 세그먼트(900~1,000 값의 바이트)를 두 번째 세그먼트(536~899 값의 바이트)가 수신되기 전에 수신했다.
즉, 세 번째 세그먼트는 순서가 틀리게 도착했다.
이 상황에서 호스트는 어떻게 행동을 할까?
TCP RFC는 TCP 연결에서 순서가 바뀐 세그먼트를 수신할 때 호스트가 어떤 행동을 취해야 하는지에 대한 어떤 규칙도 부여하지 않았고,
TCP 구현 개발자에게 맡기고 있다.
두 가지 선택지
-
수신자가 순서가 바뀐 세그먼트를 즉시 버린다.
-
수신자는 순서가 바뀐 데이터를 보유하고, 빈 공간에 잃어버린 데이터를 채우기 위해 기다린다.
후자가 네트워크 대역폭 관점에서는 효율적이며, 실제에서도 취하는 방법이다.
텔넷: 순서 번호와 응답확인 번호 사례연구
텔넷(Telnet)
- 원격 로그인을 위해 사용되는 유명한 애플리케이션 계층 프로토콜
- TCP 상에서 실행되며, 한 쌍의 호스트들 사이에서 동작하도록 설계되었다.
호스트 A가 호스트 B로 텔넷 세션을 시작한다고 가정하자.
- 호스트 A가 세션을 시작하므로
클라이언트 - 호스트 B는
서버
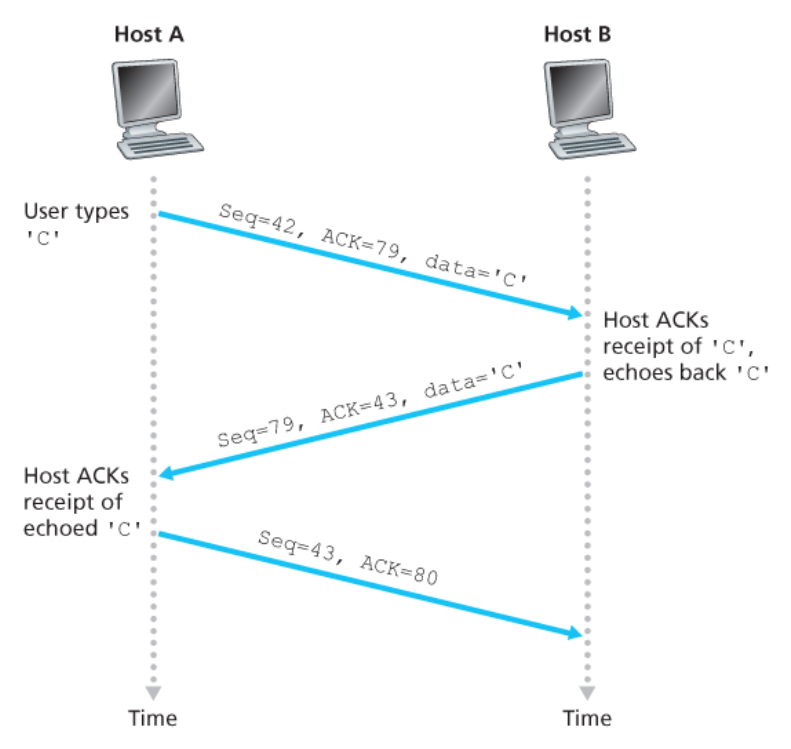
💡 세그먼트의
순서 번호= 데이터 필드 안에 있는 첫 번째 바이트의 순서 번호
- 클라이언트의 초기 순서 번호 :
42→ 클라이언트에서 송신된 첫 번째 세그먼트는 순서 번호 42를 가진다. - 서버의 초기 순서 번호 :
79→ 서버에서 송신된 첫 번째 세그먼트는 순서 번호 79를 가질 것이다.
💡
확인응답 번호= 호스트가 기다리는 데이터의 다음 바이트의 순서 번호
TCP 연결이 설정된 후에 어떤 데이터도 송신되기 전,
- 클라이언트는 바이트
79를 기다리고 있다. - 서버는 바이트
42를 기다리고 있다.
사용자가 하나의 문자 ‘C’를 입력하고, 커피를 마신다고 가정하자.
위 그림처럼 3개의 세그먼트가 송신된다. = 세 방향 핸드셰이크(three-way handshake)
1️⃣ 첫 번째 세그먼트
-
클라이언트에서 서버로 송신된다.
-
순서 번호 필드안에42를 가진다.
2️⃣ 두 번째 세그먼트
-
서버에서 클라이언트로 송신된다.
-
두 가지 목적을 가진다.
-
수신하는 서버에게 데이터에 대한 확인응답을 제공
확인응답 필드안에43을 넣음으로써,
(1) 서버는 클라이언트에게 바이트 42를 성공적으로 수신했고
(2) 앞으로 바이트 43을 기다린다는 것을 말해준다. -
문자 ‘C’를 반대로 반향되도록 하는 것
→ 그의 데이터 필드에 ‘C’의 ASCII 표현을 한다.
두 번째 세그먼트는 TCP 연결의 서버-클라이언트 데이터 흐름의
최초 순서 번호인 순서 79를 갖는다.
(이는 서버가 보내는 데이터의 맨 첫번째 바이트)
-
💡
클라이언트/서버 데이터에 대한 확인응답은 서버와 클라이언트 간에서 데이터를 운반하는 세그먼트 안에서 전달된다.
= 확인응답은 서버-클라이언트 데이터 세그먼트 상에서피기백된다(piggybacked)
3️⃣ 세 번째 세그먼트
-
클라이언트에서 서버로 송신된다.
-
목적 : 서버로부터 수신한 데이터에 대한 확인응답을 하는 것
- 이 세그먼트는 빈 데이터 필드를 갖는다.
- 즉, 확인응답은 어떤 클라이언트-서버 데이터와 함께 피기백되지 않는다.
-
세그먼트는
확인응답 필드안에80을 갖는다.- 클라이언트가
순서 번호 79의 바이트를 통해 바이트의 스트림을 수신했기 때문이다. - 앞으로
80으로 시작하는 바이트를 기다린다.
- 클라이언트가
이 세그먼트가 데이터를 포함하지 않는데도 순서 번호를 갖는다는 것이 이상하지만,
TCP가 순서 번호 필드를 갖고 있으므로 세그먼트 역시 어떤 순서 번호를 가져야 한다.
3.5.3 왕복 시간(RTT) 예측과 타임아웃
💡 TCP는 손실 세그먼트를 발견하기 위해
타임아웃/재전송 매커니즘을 사용한다.
타임아웃은 연결의 왕복 시간(round-trip time, RTT)보다 좀 커야 한다.
왕복 시간 예측
💡
왕복 시간(round-trip time, RTT): 세그먼트가 전송된 시간부터 긍정 확인응답될 때까지의 시간
TCP가 송신자와 수신자 사이에 왕복 시간을 어떻게 예측하는지에 대하여 알아보자.
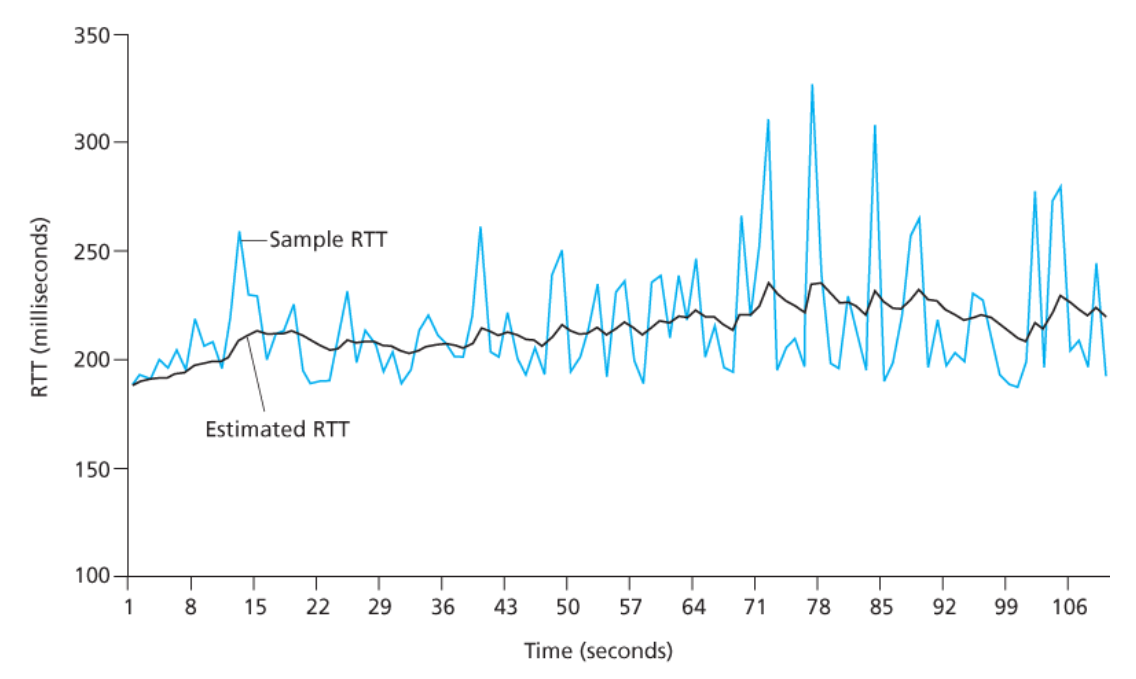
✅ SampleRTT라고 표시되는 세그먼트에 대한 RTT 샘플
: 세그먼트가 송신된 시간(IP에게 넘겨진 시간)으로부터 그 세그먼트에 대한 긍정응답이 도착한 시간까지의 시간 길이
대부분의 TCP는 한 번에 하나의 SampleRTT 측정만을 시행한다.
- 즉, 어떤 시점에서
SampleRTT는 전송되었지만 현재까지 확인응답이 없는 세그먼트 중 하나에 대해서만 측정된다. - 이는 대략 왕복 시간마다
SampleRTT의 새로운 값을 얻게 한다.
✅ SampleRTT 값은 라우터에서의 혼잡과 종단 시스템에서의 부하 변화 때문에 세그먼트마다 다르기 때문에
대체로 RTT를 추정하기 위해 SampleRTT 값의 평균값을 채택한다.
→ TCP는 SampleRTT 값의 평균(EstimatedRTT)을 유지한다.
EstimatedRTT = (1 - α) × EstimatedRTT + α × SampleRTT
(권장되는 α의 값 : 0.125)
💡
EstimatedRTT는SampleRTT의 가중평균(weighted average)이다.
-
이 가중평균은 예전 샘플보다 최근 샘플에 높은 가중치를 준다.
-
최신 샘플들이 네트워크상의 현재 혼잡을 더 잘 반영한다. →
지수적 가중 이동 평균(exponential weighted moving average, EWMA)
아래는 TCP 연결에 대해 α = 1/8의 값에 대한 SampleRTT 값들과 EstimatedRTT를 보여준다.
✅ DevRTT는 RTT 변화율을 의미한다.
이는 SampleRTT가 EstimatedRTT로부터 얼마나 많이 벗어나는지에 대한 측으로 정의한다.
DevRTT = (1 - β) × DevRTT + β × | SampleRTT - EstimatedRTT |
(권장되는 β의 값 : 0.25)
DevRTT는 SampleRTT와 EstimatedRTT 값 차이의 EWMA이다.
재전송 타임아웃 주기의 설정과 관리
주어진 EstimatedRTT 와 DevRTT 값에서, TCP 타임아웃 주기에는 어떤 값이 사용되어야 하는가?
-
주기는
EstimatedRTT보다 크거나 같아야 한다.
(그렇지 않다면 불필요한 재전송이 보내질 것) -
EstimatedRTT보다 너무 크면 안된다.
(너무 크면 세그먼트를 잃었을 때, TCP는 세그먼트의 즉각적인 재전송을 하지 않게 됨)
→ 타임아웃값은 EstimatedRTT에 약간의 여윳값을 더한 값으로 설정하는 것이 바람직하다.
TimeoutInterval = EstimatedRTT + 4 × DevRTT
-
초기
TimeoutInterval의 값으로는 1초를 권고한다. -
타임아웃이 발생할 때,
TimeoutInterval의 값은 두 배로 하여
조만간 확인응답할 후속 세그먼트에게 발생할 수 있는 조기 타임아웃을 피하도록 한다.
3.5.4 신뢰적인 데이터 전송
💡 TCP는 IP의 비신뢰적인 최선형 서비스에서
신뢰적인 데이터 전송 서비스(reliable data transfer service)를 제공한다.
-
프로세스가 자신의 수신 버퍼로부터 읽은 데이터 스트림이 손상되지 않음을 보장한다.
-
중복이 없다는 것과 순서가 유지된다는 것을 보장한다.
즉, 바이트 스트림은 송신자가 전송한 것과 같은 바이트 스트림이다.
타이머 관리는 상당한 오버헤드를 유발할 수 있다.
따라서 전송되었지만 확인응답이 안 된 다수의 세그먼트들이 있다고 하더라도,
권장되는 TCP 타이머 관리 절차에서는 오직 단일 재전송 타이머를 사용한다.
(이 장에서 설명하는 TCP 프로토콜은 단일 타이머를 따름)
TCP 송신자의 데이터 전송/재전송에 관련된 세 가지 주요 이벤트
1️⃣ 상위 애플리케이션으로부터 수신된 데이터
첫 번째 이벤트 발생으로,
- TCP는 애플리케이션으로부터 데이터를 받고,
세그먼트로 이 데이터를 캡슐화하고,- IP에게 이 세그먼트를 넘긴다.
-
각 세그먼트는 세그먼트의 첫 번째 데이터 바이트의 바이트 열 번호인
순서 번호를 포함한다. -
타이머가 이미 다른 세그먼트에 대해 실행 중이 아니면, TCP는 이 세그먼트를 IP로 넘길 때
타이머를 시작한다.
2️⃣ 타이머 타임아웃
- TCP는 타임아웃 이벤트에 대해 타임아웃을 일으킨 세그먼트를 재전송하여 응답한다.
- 그리고 TCP의 타이머를 다시 시작한다.
3️⃣ 수신 확인응답 세그먼트(ACK) 수신
이 이벤트가 발생하면, TCP는 변수 SendBase와 ACK 값 y를 비교한다.
SendBase: 수신 확인응답이 확인되지 않은 / 가장 오래된 바이트의 순서번호SendBase-1: 수신자에게서 정확하게 차례대로 수신되었음을 알리는 마지막 바이트의 순서번호
TCP는 누적 확인응답을 사용하고,
y는 y바이트 이전의 모든 바이트의 수신을 확인한다.
y > SendBase이면, ACK는 이전에 확인응답 안 된 하나 이상의 세그먼트들을 확인해준다.
- 송신자는 자신의
SendBase변수를 갱신한다. - 아직 확인응답 안 된 세그먼트들이 존재한다면 타이머를 다시 시작한다.
몇 가지 흥미로운 시나리오
TCP 프로토콜이 어떻게 작동하는지 몇 가지 간단한 시나리오를 통해 알아보자.
손실된 확인응답에 기인하는 재전송
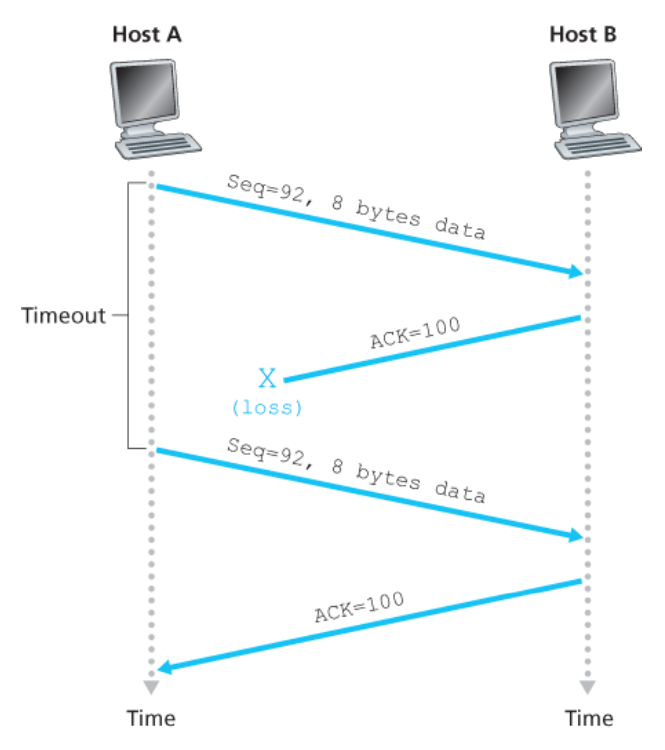
호스트 A로부터 세그먼트가 호스트 B 측에서 수신되었음에도 B로부터 A로의 긍정 확인응답이 손실된다면
- 타임아웃이 발생한다.
- 호스트 A는 같은 세그먼트를 B에게 재전송한다.
- 호스트 B의 TCP는 재송신된 세그먼트의 바이트를 버린다.
세그먼트 100이 재전송되지 않는 경우
호스트 A가 연속해서 두 세그먼트를 전송한다.
호스트 A에서 타임아웃 이전에 어떠한 긍정 확인응답도 수신하지 못한다고 가정하자.
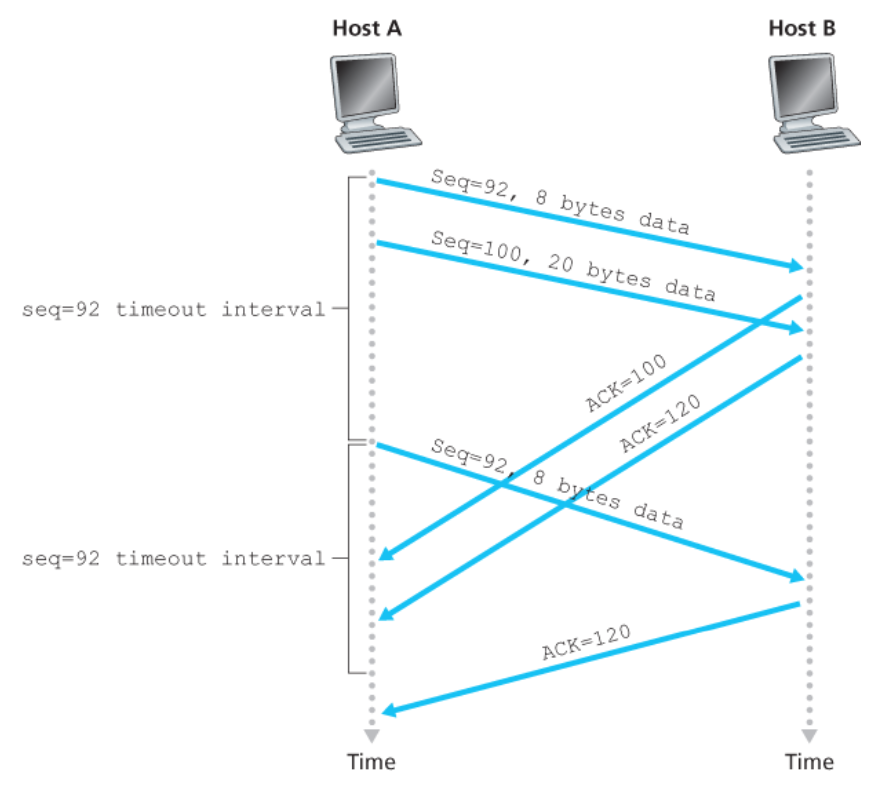
타임아웃 이벤트가 발생하면
- 호스트 A는
순서 번호 92로 첫 번째 세그먼트를 재전송한다. - 타이머를 다시 시작한다.
- 새로운 타임아웃 이전에 두 번째 세그먼트에 대한 ACK가 도착하는 한, 두 번째 세그먼트는 재전송을 하지 않을 것이다.
누적 확인응답은 첫 번째 세그먼트의 재전송을 방지한다
호스트 A가 연속해서 두 세그먼트를 전송한다.
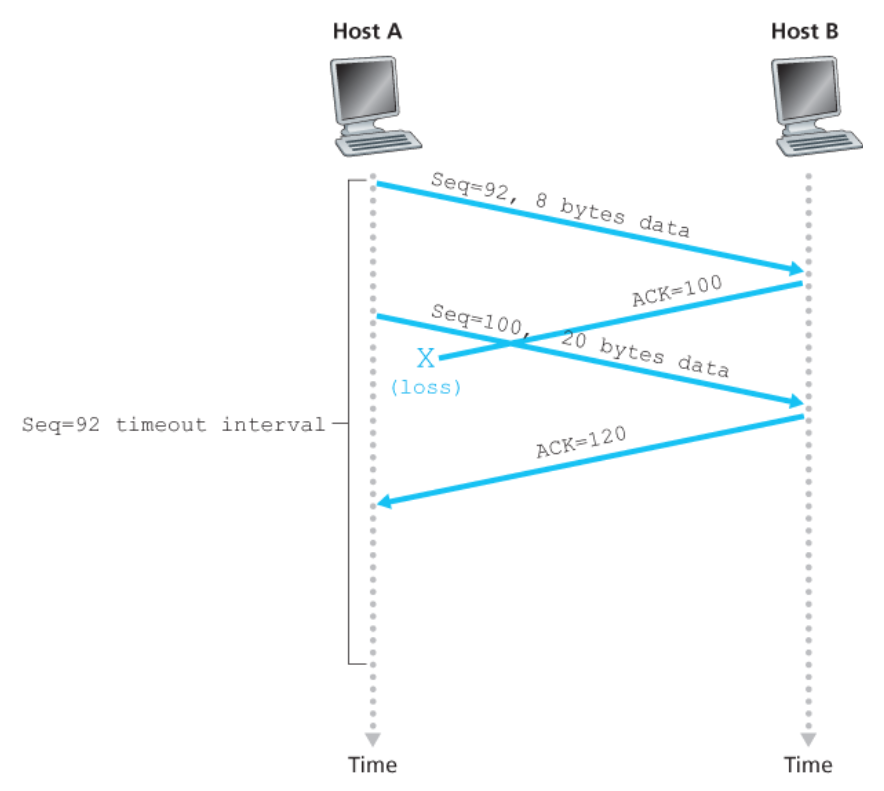
첫 번째 세그먼트의 긍정 확인응답이 네트워크에서 분실되었지만,
첫 번째 세그먼트의 타임아웃 전에 호스트 A가 긍정 응답번호 120의 긍정 확인응답을 수신하면
- 호스트 A는 호스트 B가 119바이트까지 모든 데이터를 수신했음을 알게 된다.
- 그러므로 호스트 A는 두 세그먼트 중 어느 것도 재전송하지 않는다.
TCP는 GBN인가 SR인가?
💡
TCP 확인응답은 누적되고 올바르게 수신되지만, 순서가 잘못된 세그먼트는 수신자가 개별적으로 ACK를 받지 않는다.
TCP 송신자는 전송했지만 확인응답 안 된 바이트의 가장 작은 순서 번호,
SendBase와 전송될 다음 바이트의 순서 번호,NextSeqNum을 유지해야 한다.
이런 관점에서 TCP는 GBN 형태의 프로토콜과 비슷해보이나, ’TCP에서는 올바르게 수신되었지만 순서가 바뀐 세그먼트들을 버퍼링한다’는 차이점이 존재한다.
e.g.,
패킷 n < N에 대한 긍정 확인응답이 손실되었지만,
나머지 N-1개의 긍정 확인 응답들은 타임아웃 전에 송신 측에 도달했다고 가정한다.
-
GBN: 패킷 n뿐만 아니라, 연속적인 패킷 n+1, n+2, … , N 모두를 재전송한다. -
TCP- 세그먼트 n 하나만을 재전송
- 세그먼트 n에 대한 타임아웃 전에 세그먼트 n+1에 대한 긍정 확인 응답이 도착한다면 세그먼트를 재전송하지 않는다.
💡 TCP에서 수정제안된
선택적 확인응답(selective acknowledgment): TCP 수신자가 마지막으로 올바로 수신된 ‘순서가 맞는’ 세그먼트에 대해 누적 확인응답을 하기보다는
‘순서가 틀린’ 세그먼트에 대해 선택적으로 확인응답을 하게 한다.
이를 선택적 재전송과 결합했을 경우, SR 프로토콜과 매우 유사하다.
따라서 TCP의 오류 복구 메커니즘은 GBN과 SR 프로토콜의 혼합으로 분류하는 것이 적당하다.
빠른 재전송
타임아웃이 유발하는 재전송의 문제 : 타임아웃의 주기가 때때로 비교적 길다.
긴 타임아웃 주기는 종단 간의 지연을 증가시키지만,
다행히도 송신자는 종종 중복 ACK에 의한 타임아웃이 일어나기 전에 패킷 손실을 발견한다.
💡
중복 ACK(duplicate ACK): 송신자가 이미 이전에 받은 확인응답에 대한 재확인응답 세그먼트 ACK
수신자가 중복 ACK를 보내는 이유
TCP는 부정 확인응답을 사용하지 않으므로, 수신자는 송신자에게 부정 확인 응답을 보낼 수 없다.
- TCP 수신자가 기다리는 다음 것보다 더 큰 순서 번호를 가진 세그먼트를 받았을 때, TCP 수신자는
손실 세그먼트를 찾아낼 것이다. - 수신자는 마지막으로 수신된 순차적인 바이트를 갖는 데이터를 그냥 다시 확인응답한다.
즉,중복 ACK를 생성한다.
TCP ACK 생성 권고
이벤트 1️⃣
기다리는 순서 번호를 가진 ‘순서가 맞는’ 세그먼트의 도착
기다리는 순서 번호까지의 모든 데이터는 이미 확인응답된다.
TCP 수신자 동작 : 지연된 ACK
- 또 다른 ‘순서가 맞는’ 세그먼트의 도착을 위해 500 ms까지 기다린다.
- 만약 다음 ‘순서에 맞는’ 세그먼트가 이 기간에 도착하지 않으면, 그냥 ACK를 보낸다.
이벤트 2️⃣
기다리는 순서 번호를 가진 ‘순서가 맞는’ 세그먼트의 도착
ACK 전송을 기다리는 다른 하나의 ‘순서에 맞는’ 세그먼트가 있다.
TCP 수신자 동작 : 2개의 ‘순서가 맞는’ 세그먼트들을 ACK하기 위해, 하나의 누적된 ACK를 즉시 보낸다.
이벤트 3️⃣
기다리는 것보다 높은 순서 번호를 가진 ‘순서가 바뀐’ 세그먼트의 도착 격자가 발견된다.
TCP 수신자 동작
: 순서 번호가 다음의 기다리는 바이트(즉, 격차의 최솟값)를 나타내는 중복 ACK를 즉시 보낸다.
이벤트 4️⃣
수신 데이터에서 격차를 부분적으로 또는 모두 채우는 세그먼트의 도착
TCP 수신자 동작 : 그 세그먼트가 격차의 최솟값에서 시작한다고 하면, 즉시 ACK를 보낸다.
빠른 재전송(fast retransmit)
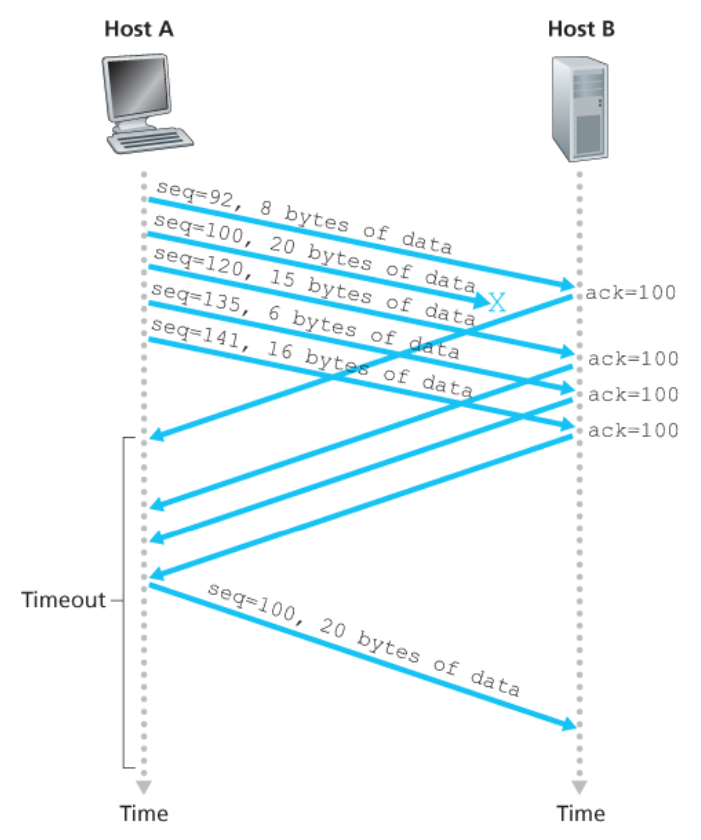
만약 TCP 송신자가 같은 데이터에 대해 3개의 중복 확인응답을 수신한다면,
이것은 ACK된 세그먼트의 다음 3개의 세그먼트가 분실되었음을 의미한다.
💡
3개의 중복 ACK를 수신할 때, TCP는 세그먼트의 타이머가 만료되기 이전에 손실 세그먼트를 재전송한다.
아래 그림을 보면 두 번째 세그먼트를 잃어버린 경우, 타이머가 만료되기 전에 재전송되었다.
3.5.5 흐름 제어
💡 TCP는 송신자가 수신자의 버퍼를 오버플로시키는 것을 방지하기 위해 애플리케이션에게
흐름 제어 서비스(flow-control service)를 제공한다.
→ 수신하는 애플리케이션이 읽는 속도와 송신자가 전송하는 속도를 같게 한다.
TCP 송신자는 IP 네트워크에서 혼잡 때문에 억제될 수도 있다. =
혼잡 제어(congestion control)
흐름 제어와 혼잡 제어는 명백히 각기 다른 목적으로 수행된다. (잘 구별하여야 함)
과정
💡 TCP는
수신 윈도(receive window)라는 변수를 유지하여 흐름 제어를 제공한다.
-
수신 측에서 가용한 버퍼 공간이 얼마나 되는지를 송신자에게 알려주는데 사용된다.
-
TCP는
전이중(full-duplex)이므로 연결의 각 측의 송신자는 별개의 수신 윈도를 유지한다.
e.g., TCP 연결상에서 호스트 A가 호스트 B에게 큰 파일을 전송한다고 가정
-
호스트 B는 이 연결에 수신 버퍼를 할당한다.
(이때 할당된 수신 버퍼의 크기 :RcvBuffer) -
호스트 B의 애플리케이션 프로세스는 버퍼로부터 데이터를 읽으며 다음과 같은 변수들을 정의한다.
LastByteRead: 호스트 B의 애플리케이션 프로세스에 의해 버퍼로부터 읽힌 데이터 스트림의 마지막 바이트 번호LastByteRcvd: 호스트 B에서 네트워크로부터 도착하여 수신 버퍼에 저장된 데이터 스트림의 마지막 바이트 번호rwnd- 수신 윈도 = 버퍼의 여유 공간
- 시간에 따라 여유 공간은 변하므로 이 변수는 동적이다.
LastByteRcvd - LastByteRead ≤ RcvBuffer
rwnd = RcvBuffer - [LastByteRcvd - LastByteRead]
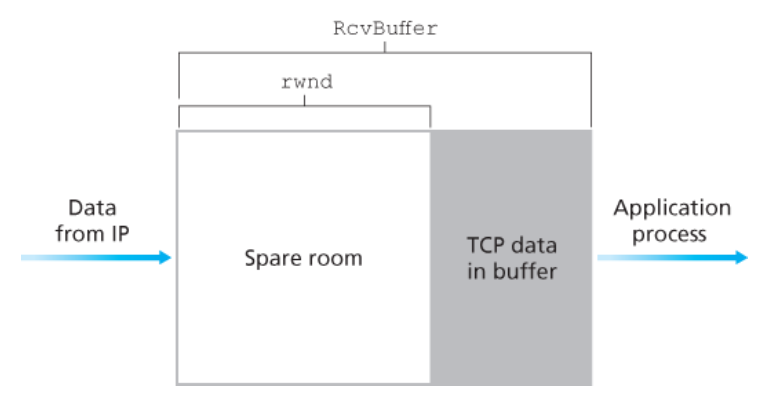
-
호스트 B는 호스트 B가 호스트 A에게 전송하는 모든 세그먼트의 윈도 필드에 현재
rwnd값을 설정한다.이를 통해 호스트 A에게 연결 버퍼에 얼마만큼의 여유 공간이 있는지를 알려준다.
-
호스트 A는 두 변수
LastByteSent와LastByteAcked를 유지한다.LastByteSent - LastByteAcked = 호스트 A가 이 연결에 전송 확인응답이 안 된 데이터의 양
💡
rwnd의 값보다 작은 확인응답 안 된 데이터의 양을 유지함으로써 호스트 A는 호스트 B의 수신 버퍼에 오버플로가 발생하지 않는다는 것을 확신한다.
호스트 A는 연결된 동안 다음의 내용을 보장한다.
LastBySent - LastByteAcked ≤ rwnd
문제점과 해결법
- 호스트 B의 수신 버퍼는
rwnd = 0으로서 가득 찼고 - 호스트 A에게 rwnd = 0이라고 알린 후 호스트 B는 호스트 A에게 전송할 것이 없는 경우
호스트 B에서의 애플리케이션 프로세스가 버퍼를 비우더라도,
TCP는 호스트 A에게 새로운 rwnd로 새로운 세그먼트를 전송하지 않는다.
즉, TCP는 전송할 데이터가 있거나, 전송해야 할 확인응답을 가진 경우에만 호스트 A에게 세그먼트를 전송할 것이다.
→ 호스트 A는 차단되고 더는 데이터를 전송할 수 없다.
따라서 TCP 명세서는 호스트 A가 호스트 B의 수신 윈도가 0일 때, 1바이트 데이터로 세그먼트를 계속해서 전송하도록 요구한다.
3.5.6 TCP 연결 관리
TCP 연결이 어떻게 설정되고 해제되는가?
하나의 호스트(클라이언트)에서 운영되는 프로세스가 다른 호스트(서버) 안의 또 다른 프로세스와 연결을 시작하길 원한다고 가정하자.
- 클라이언트 애플리케이션 프로세스는 서버에 있는 프로세스와 연결 설정하기를 원한다는 것을 클라이언트 TCP에게 알린다.
- 클라이언트 안의 TCP는 다음과 같은 방법으로 TCP를 이용해 서버와 TCP 연결 설정을 시작한다.
연결의 설정 : 세 방향 핸드셰이크(three-way handshake)
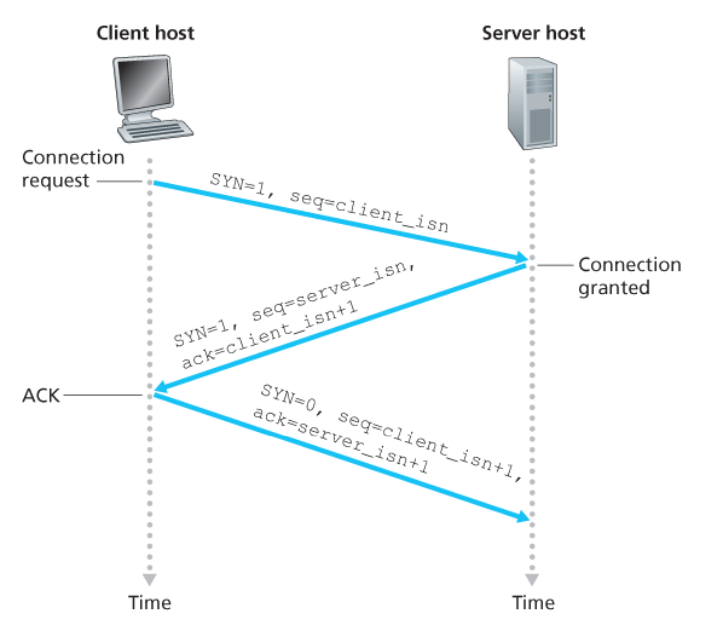
1단계
-
클라이언트 측 TCP는 서버 TCP에게 특별한 TCP 세그먼트,
SYN 세그먼트를 송신한다.- 애플리케이션 계층 데이터를 포함하지 않는다.
- 세그먼트 헤더에
SYN 비트를 1로 설정한다.
-
클라이언트는 최소 순서 번호(
client_isn)를 임의로 선택하고, 최초의 TCP SYN 세그먼트의순서 번호 필드에 이 번호를 넣는다. -
이 세그먼트는 IP 데이터그램 안에서 캡슐화되고 서버로 송신된다.
2단계
TCP SYN 세그먼트를 포함하는 IP 데이터그램이 서버 호스트에 도착하면,
-
서버는 데이터그램으로부터 TCP SYN 세그먼트를 추출한다.
-
연결에 TCP 버퍼와 변수를 할당한다.
-
클라이언트 TCP로 연결 승인 세그먼트,
SYNACK 세그먼트를 송신한다.- 애플리케이션 계층 데이터를 포함하지 않는다.
SYN 비트는 1로 설정된다.- TCP 세그먼트 헤더의
확인응답 필드는client_isn+1로 설정된다. - 서버는 자신의 최초의 순서 번호(
server_isn)를 선택하고, TCP 세그먼트 헤더의순서 번호 필드에 이 값을 넣는다.
3단계
연결 승인 세그먼트를 수신하면,
-
클라이언트는 연결에 버퍼와 변수를 할당한다.
-
클라이언트 호스트는 서버로 또 다른 세그먼트를 송신한다.
- 클라이언트는 TCP 세그먼트 헤더의
확인응답 필드안에server_isn+1값을 넣어, 서버의 연결 승인 세그먼트를 확인한다. - 연결이 설정되었기 때문에
SYN 비트는 0으로 설정된다.
- 클라이언트는 TCP 세그먼트 헤더의
세 번째 단계는 클라이언트에서 서버로의 데이터를
세그먼트 페이로드에서 운반할 수 있다.
위의 세 단계가 완료되면,
- 클라이언트와 서버 호스트들은 각각 서로에게
데이터를 포함하는 세그먼트를 보낼 수 있다. SYN 비트는 0으로 설정된다.
연결의 종료
TCP 연결에 참여하는 두 프로세스 중 하나가 연결을 끊을 수 있다.
연결이 끝날 때, 호스트의 ‘자원’(버퍼와 변수)는 회수된다.
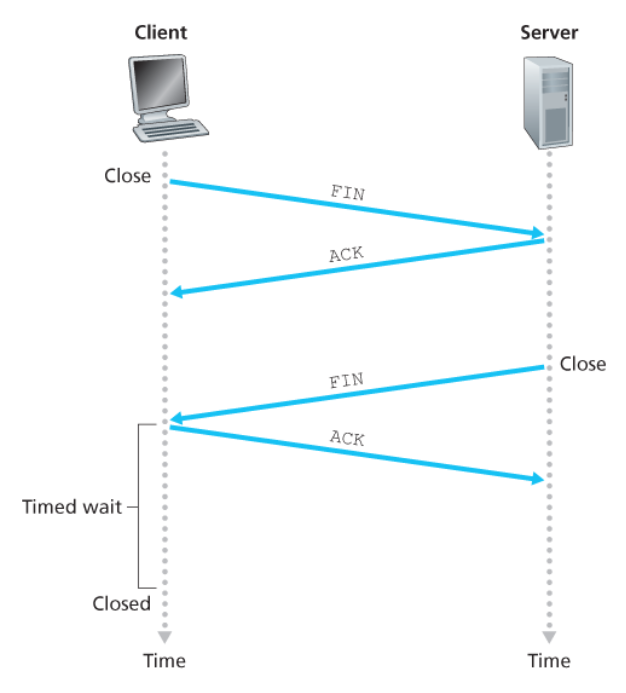
-
클라이언트 애플리케이션 프로세스는 종료 명령을 내린다.
-
이는 클라이언트 TCP가 서버 프로세스에게
특별한 TCP 세그먼트를 보내도록 한다.
(FIN 비트를 1로 설정) -
서버가 이 세그먼트를 수신하면, 서버는 클라이언트에게
확인응답 세그먼트를 보낸다. -
그 다음에
FIN 비트가 1로 설정된 자신의종료 세그먼트를 송신한다. -
마지막으로 클라이언트는 서버의 종료 세그먼트에
확인응답을 한다.이 시점에서 두 호스트의 모든 자원은 할당이 해제된다.
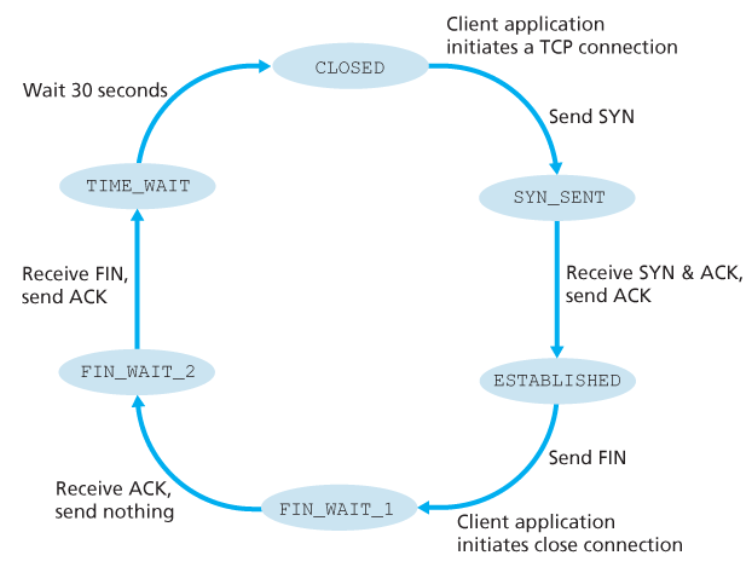
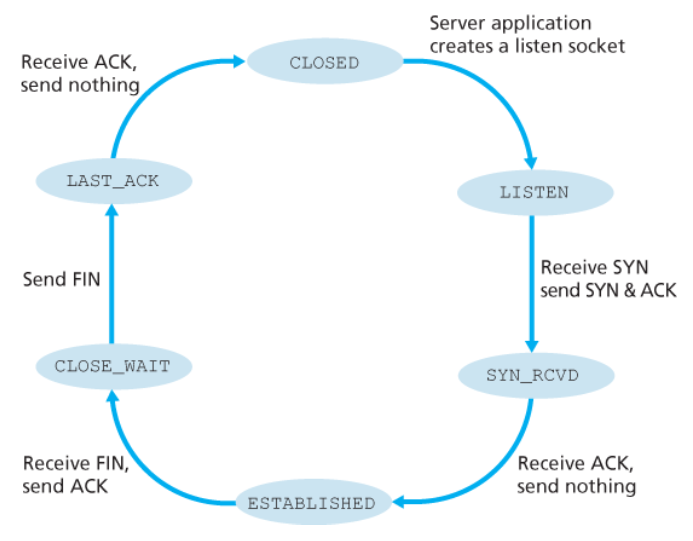
TCP 상태(TCP state)
TCP 연결이 존재하는 동안 각 호스트에서 동작하는 TCP 프로토콜은 다양한 TCP 상태를 두루 전이한다.
아래의 두 그림은 클라이언트가 연결 해제를 시작한다는 것을 가정한다.
클라이언트 TCP에서 TCP 상태 변이의 일반 순서
서버 TCP에서 TCP 상태 변이의 일반 순서
SYN 플러드 공격
TCP의 세 방향 핸드셰이크
-
서버는
수신된 SYN에 대한 응답으로 연결 변수와 버퍼를 할당하고 초기화한다. -
그 다음, 서버는 응답으로
SYNACK을 보내고 클라이언트의ACK 세그먼트를 기다린다.
클라이언트가 이 세 방향 핸드셰이크의 세 번째 단계를 완료하기 위한 ACK를 보내지 않으면
결국(종종 1분 이상 후에) 서버가 절반만 열린 연결을 종료하고 할당된 자원을 회수한다.
→ 이는 SYN 플러드 공격의 무대가 된다.
SYN 플러드 공격(SYN flood attack)
고전적인 서비스 거부(Denial of Service, DoS) 공격
-
공격자는 핸드셰이크의 세 버너째 단계를 완료하지 않은 상태에서 무수한
TCP SYN 세그먼트를 보낸다. -
서버의 연결 자원이 반쪽 연결에 할당된다.
-
결국 서버의 연결 자원이 소진됨에 따라 합법적인 클라이언트들이 서비스 거부가 된다.
SYN 쿠키
이는 SYN 플러드 공격에 대한 방어책으로, 현재 대부분의 운영체제에 존재하고 있다.
동작 방법
-
서버는 SYN에 대해 반만 열린(half-open) TCP 연결을 만들지 않고,
초기 TCP 순서 번호(쿠키, cookie)를 만든다.- 서버가 SYN 세그먼트를 받을 때, 그 세그먼트가 정당한 사용자로부터 또는 공격자로부터 온 것인지 구별할 수 없기 때문이다.
- 해시 함수에 아래의 항목들을 사용하여 쿠키를 생성한다.
- 비밀번호
- SYN 세그먼트의 출발지와 목적지 IP 주소들과 포트번호
-
서버는 이 특별한 초기 순서 번호를 가진
SYNACK패킷을 보낸다.💡 서버는 SYN에 관련된 쿠키나 어떤 다른 상태 정보를 기억하지 않는다.
-
합법적인 클라이언트는
ACK세그먼트를 회신한다. -
이 ACK를 받은 서버는 ACK가 이전에 보낸 일부 SYN에 관한 것인지 확인해야 한다.
- 이는 이전에 보낸 일부 SYN에 관한 것인지는
쿠키를 통해 확인한다. - 서버는 SYNACK에 있는 출발지와 목적지 IP 주소와 포트번호, 비밀번호를 사용해서 동일한 해시 함수를 실행한다.
- 이는 이전에 보낸 일부 SYN에 관한 것인지는
만약 함수의 결과에 1을 더한 것이 클라이언트의 SYNACK에 있는 확인응답 번호(쿠키)와 같다면
서버는 ACK가 초기 SYN 세그먼트에 관련된 것, 즉 올바른 것이라고 결론짓는다.
→ 이후 서버는 소켓을 가지고 완전하게 열린 연결을 만든다.
만약 클라이언트가 ACK 세그먼트를 회신하지 않으면
서버가 처음의 가짜 SYN에 대해 어떤 자원도 할당하지 않았기 때문에 처음의 SYN은 서버에 해를 끼치지 못한다.
3.6 혼잡 제어의 원리
💡 네트워크 혼잡의 원인 : 너무 많은 출발지가 너무 높은 속도로 데이터를 보내려고 시도
→ 이를 처리하기 위해서는 네트워크 혼잡을 일으키는 송신자들을 억제하는 매커니즘이 필요하다.
3.6.1 혼잡의 원인과 비용
시나리오 1 : 2개의 송신자와 무한 버퍼를 갖는 하나의 라우터
- 두 호스트 A와 B가 각각 출발지와 목적지 사이에서
단일 홉을 공유하는 연결을 갖는다. - 호스트 A와 B의 애플리케이션이
λin 바이트/초의 평균 전송률로 데이터를 전송하고 있다. - 라우터 버퍼의 양은 무한하다고 가정한다.
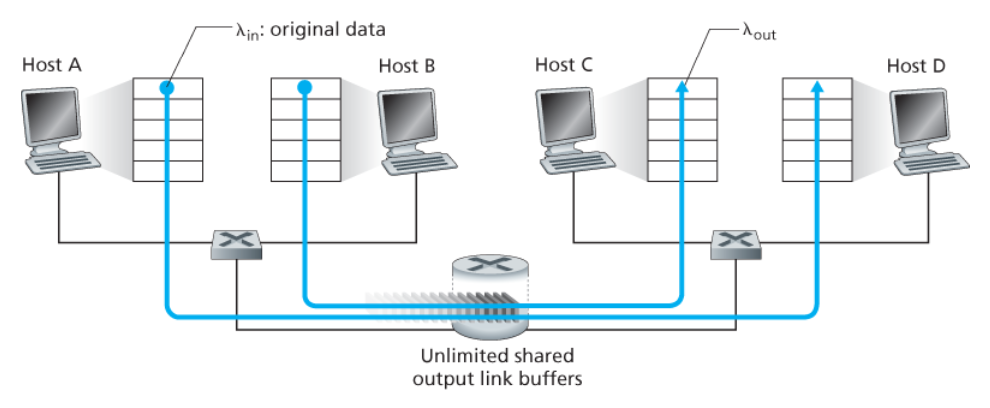
아래 그래프들은 A의 연결 성능을 나타낸다.
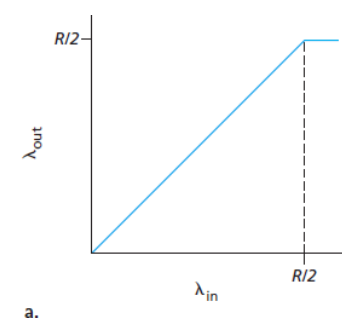
연결당 처리량(per-connection throughput): 수신자 측에서의 초당 바이트 수- 0 ~ R/2 사이의 전송률 : 수신자 측의 처리량은 송신자의 전송률과 같다.
- R/2 이상의 전송률 : 처리량은 R/2
- 즉, 호스트 A와 B가 전송률을 아무리 높게 설정하더라도 각자 R/2보다 높은 처리량을 얻을 수 없다.
평균 지연- 전송률이 R/2에 근접할 경우 : 평균 지연은 점점 커진다.
- 전송률이 R/2를 초과할 경우 : 무제한 (무한한 사용 가능한 버퍼링을 가정)
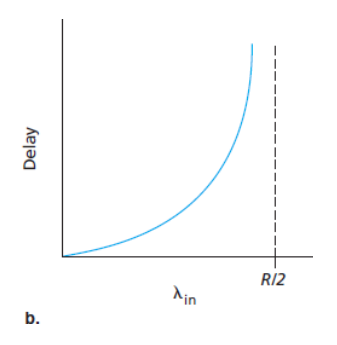
패킷 도착률이 링크 용량에 근접함에 따라 큐잉 지연이 커진다.
시나리오 2 : 2개의 송신자, 유한 버퍼를 가진 하나의 라우터
라우터 버퍼의 양이 유한하다고 가정한다. → 버퍼가 가득 찼을 때 도착하는 패킷들은 버려진다.각 연결은 신뢰적이라고 가정한다. → 패킷이 라우터에 버려지면 송신자에 의해 재전송될 것이다.- 애플리케이션이 원래의 데이터를 소켓으로 보내는 송신율 :
λin 바이트/초 - 네트워크 안으로 세그먼트를 송신하는 트랜스포트 계층에서의 송신율**(제공된 부하, offered load)**
:λ'in 바이트/초= 최초의 데이터 전송과 재전송 합의 속도
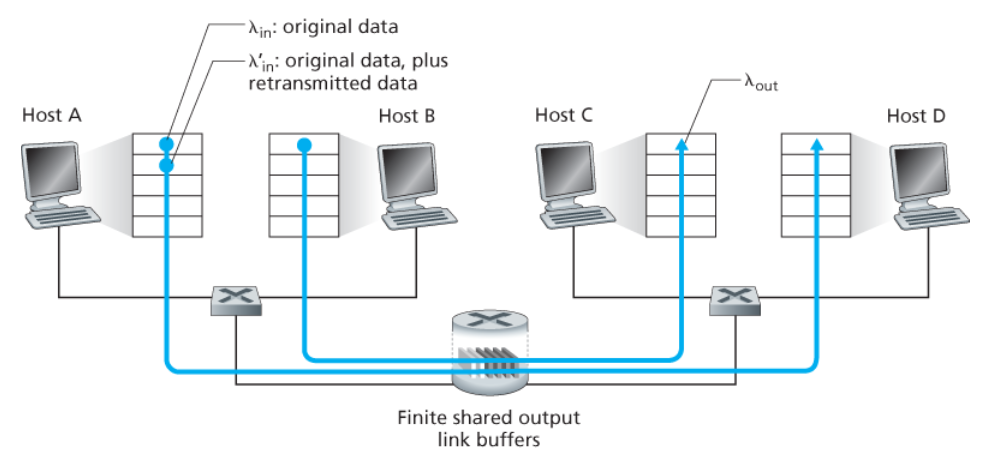
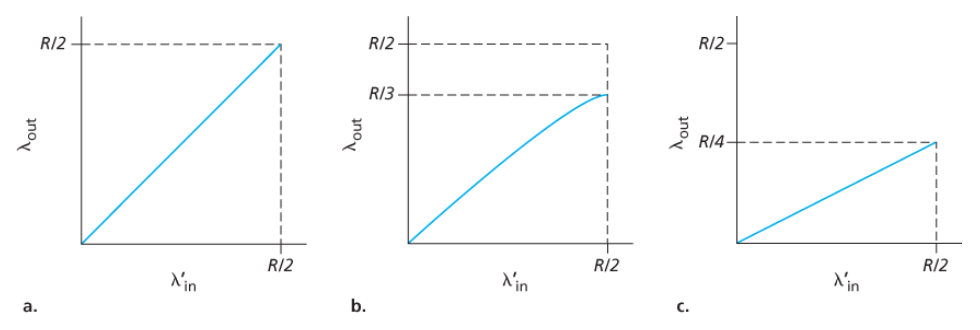
a. 어떠한 손실도 발생하지 않는 경우 (버퍼가 비어 있을 때만 패킷을 송신)
- 연결의 처리량 = λin
- 평균 호스트 송신율은 R/2를 초과할 수 없다.
b. 패킷이 확실히 손실된 것을 알았을 때만 송신자가 재전송하는 경우
제공된 부하 λ'in이 R/2일 경우 : 데이터의 전송률은 R/3- 전송된 데이터의 R/2 중
- 0.333R 바이트/초는 원래의 데이터
- 초당 0.166R 바이트/초(평균)는 재전송 데이터
송신자는 버퍼 오버플로 때문에 버려진 패킷을 보상하기 위해 재전송을 수행해야 한다.
c. 송신자에서 너무 일찍 타임아웃되어 패킷이 손실되지 않았지만, 큐에서 지연되고 있는 패킷을 재전송하는 경우
- 원래의 데이터 패킷과 재전송 패킷 둘 다 수신자에게 도착한다.
- 각 패킷이 라우터에 의해 두 번씩 전달된다고 가정했을 때, 제공된 부하가 R/2일 때의 처리량은 R/4
커다란 지연으로 인한 송신자의 불필요한 재전송은 라우터가 패킷의 불필요한 복사본들을 전송하는 데 링크 대역폭을 사용하는 원인이 된다.
시나리오 3 : 4개의 송신자와 유한 버퍼를 갖는 라우터, 그리고 멀티홉 경로
- 4개의 호스트는 겹쳐지는
2홉 경로를 통해 패킷을 전송한다. - 각각의 호스트가 타임아웃/재전송 매커니즘을 사용한다.
- 모든 호스트는
λin의 동일한 값을 가진다. - 모든 라우터 링크는
R 바이트/초 옹량을 갖는다.
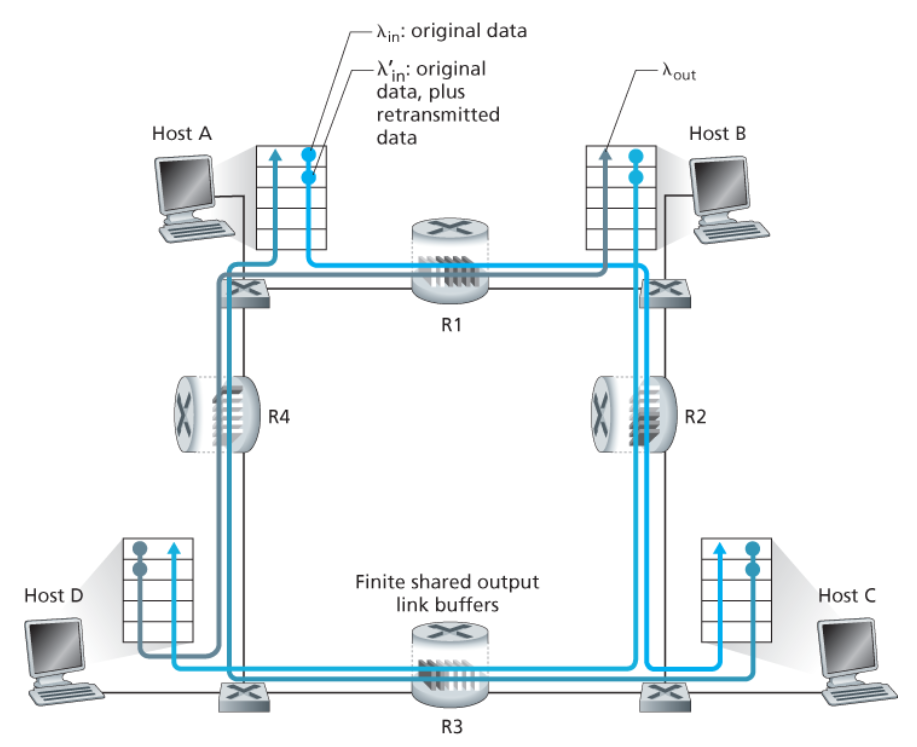
- 라우터 R2는
λin과 관계없이, R1에서 R2까지의 링크 용량, 최대 R인 도착률을 가질 수 있다. - A ~ C와 B ~ D의 트래픽은 버퍼 공간을 라우터 R2에 경쟁해야 한다.
→ R2를 성공적으로 통과하는 A ~ C의 트래픽의 양은 B ~ D에서 제공된 부하가 크면 클수록 더 작아진다.
트래픽이 많은 경우 A~C 종단 간 처리율이 0이 된다.
즉, 아래 그래프처럼 제공된 부하와 처리량 간의 tradeoff가 발생한다.
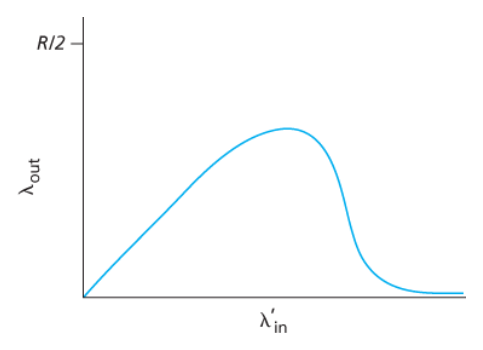 > 패킷이 경로상에서 버려질 때, 버려지는 지점까지 패킷을 전송하는 데 사용된 상위 라우터에서 사용된 전송 용량은 낭비된 것이다.
> 패킷이 경로상에서 버려질 때, 버려지는 지점까지 패킷을 전송하는 데 사용된 상위 라우터에서 사용된 전송 용량은 낭비된 것이다.
3.6.2 혼잡 제어에 대한 접근법
종단 간의 혼잡 제어
네트워크 계층은 혼잡 제어 목적을 위해 트랜스포트 계층에게 어떤 직접적인 지원도 제공하지 않는다.
따라서 네트워크에서 혼잡의 존재는 단지 관찰된 네트워크 동작(패킷 손실 및 지연)에 기초하여 종단 시스템이 추측해야 한다.
이는 TCP가 혼잡 제어를 위해 취하는 방식이다.
- TCP 세그먼트 손실과 증가하는 왕복 지연값을 네트워크 혼잡의 발생 표시로 간주한다.
- TCP는 그에 따라서 윈도 크기를 줄인다.
네트워크 지원 혼잡 제어
라우터들은 네트워크 안에서 혼잡 상태와 관련하여 송신자나 수신자 또는 모두에게 직접적인 피드백을 제공한다.
-
ATM ABR(Available Bite Rate) 혼잡 제어에서
라우터는 자신이 출력 링크(outgoing link)에 제공할 수 있는 전송률을 송신자에게 명확히 알릴 수 있게 해준다. -
최근 IP와 TCP가 이 방식을 선택적으로 구현할 수 있다.
혼잡 정보가 전달되는 두 가지 방법 → 둘 중 하나로 네트워크에서 송신자에게 피드백된다.
-
직접 피드백
- 네트워크 라우터 → 송신자
- 알림의 형태 :
초크 패킷(choke packet)
-
송신자에서 수신자에게로 흐르는 패킷 안에 특정 필드에 표시/수정
- 수신자가 표시된 패킷을 수신했을 때, 혼잡 상태를 송신자에게 알린다.
- 완전한 왕복 시간이 걸린다.
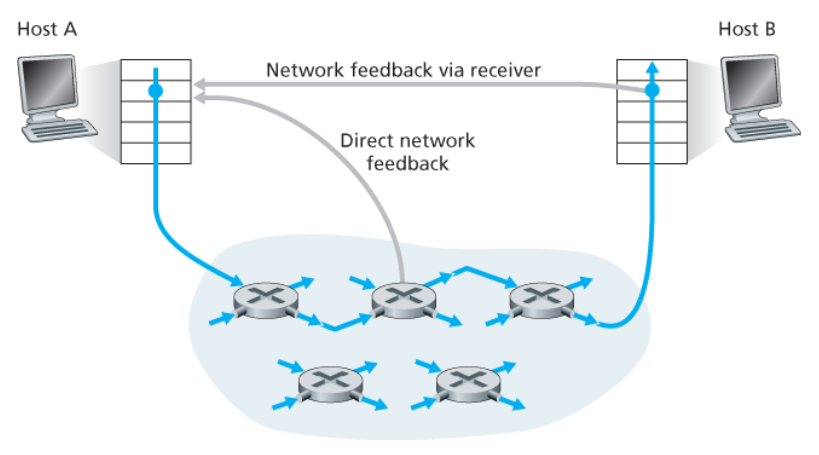 ---
---
3.7 TCP 혼잡 제어
IP 계층은 네트워크 혼잡에 관해 종단 시스템에게 어떠한 직접적인 피드백도 제공하지 않는다.
3.7.1 전통적인 TCP의 혼잡 제어
네트워크의 혼잡에 따라 연결에 트래픽을 보내는 전송률을 각 송신자가 제한하도록 한다.
- TCP 송신자가 자신과 목적지 간의 경로에서 혼잡이 없음을 감지 → 송신율을 높인다.
- TCP 송신자가 경로 사이에 혼잡을 감지 → 송신율을 줄인다.
1. TCP 송신자는 자신의 연결에 송신자 전송 트래픽 전송률을 어떻게 제한하는가?
💡 송신 측에서 동작하는 TCP 혼잡 제어 메커니즘은 추가적인 변수인
혼잡 윈도(congestion window)를 추적한다.
cwnd로 표시- TCP 송신자가 네트워크로 트래픽을 전송할 수 있는 속도에 제약을 가한다.
송신하는 쪽에서 확인응답이 안 된 데이터의 양은
cwnd와 rwnd(수신 윈도 = 버퍼의 여유 공간)의 최소값을 초과하지 않을 것이다.
LastByteSent - LastByteAcked ≤ min(cwnd, rwnd)
→ 따라서 cwnd의 값을 조절하여 송신자는 링크에 데이터를 전송하는 속도를 조절할 수 있다.
2. TCP 송신자는 자신과 목적지 사이 경로의 혼잡을 어떻게 감지하는가?
1️⃣ 손실 이벤트(loss event)가 발생한 경우
과도한 혼잡이 발생하면
-
경로에 있는 하나 이상의 라우터 버퍼들이 오버플로되고
-
그 결과 데이터그램이 버려진다.
-
버려진 데이터그램은 송신 측에서 손실 이벤트를 발생시킨다.
(e.g., 타임아웃 또는 3개의 중복된 ACK의 수신)
이를 통해 송신자는 송신자와 수신자 사이의 경로상의 혼잡이 발생했음을 알게 된다.
2️⃣ 손실 이벤트가 발생하지 않은 경우
💡
자체 클로킹(self-clocking)
TCP는 확인응답을 혼잡 윈도 크기의 증가를 유발하는 트리거(trigger)또는 클록(clock)으로 사용한다.
- 확인응답이 늦은 속도로 도착한다면 → 혼잡 윈도는 상대적으로 낮은 속도로 증가
- 확인응답이 높은 속도로 도착한다면 → 혼잡 윈도는 더 빨리 증가
3. TCP 송신자는 송신율을 변화시키기 위해 어떤 알고리즘을 사용해야 하는가?
전송률을 제어하는 cwnd 값을 조정하는 매커니즘은 무엇인가?
- TCP 송신자들이 너무 빠르게 송신하면 → 혼잡 붕괴가 나타날 것이다.
- TCP 송신자들이 너무 천천히 송신한다면 → 네트워크 내의 대역폭을 충분히 활용하지 못할 것이다.
TCP는 다음과 같은 3가지 처리 원칙에 따라 자신이 송신할 속도를 결정하게 된다.
1️⃣ TCP 전송률은 한 세그먼트를 손실했을 때 줄여야 한다.
손실된 세그먼트 = 혼잡을 의미
손실 세그먼트의 재전송을 야기하는 이벤트는 다음과 같다.
- 타임아웃 이벤트
- 4개의 확인응답 수신 (하나의 원래의 ACK + 3개의 중복된 ACK)
2️⃣ 확인응답되지 않은 세그먼트에 대해 ACK가 도착하면 송신자의 전송률은 증가할 수 있다.
확인응답의 도착 = 네트워크가 송신자의 세그먼트를 수신자에게 성공적으로 전송하였다.
즉, 네트워크는 혼잡하지 않다는 묵시적 표시로 받아들여진다.
3️⃣ 대역폭 탐색
혼잡이 없는 출발지에서 목적지까지의 경로를 표시하는 ACK와 혼잡한 경로를 표시하는 손실 이벤트가 주어지면,
- TCP 송신자로 하여금 손실 이벤트가 발생할 때까지는 ACK가 도착함에 따라 전송률을 증가시킨다.
- 손실 이벤트가 발생한 시점에서 전송률을 줄인다.
그러므로
- TCP 송신자는 혼잡이 발생하는 시점까지 전송률을 증가시키고
- 그 시점 이후로부터는 줄인 후,
- 다시 혼잡 시작이 발생했는지를 보기 위한 탐색을 시작한다.
TCP 혼잡 제어 알고리즘(TCP congestion-control algorithm)
세 가지 구성요소
-
슬로 스타트(slow start) -
혼잡 회피(congestion avoidance) -
빠른 회복(fast recovery)→ 권고, 필수사항은 아니다.
TCP 혼잡 제어의 FSM
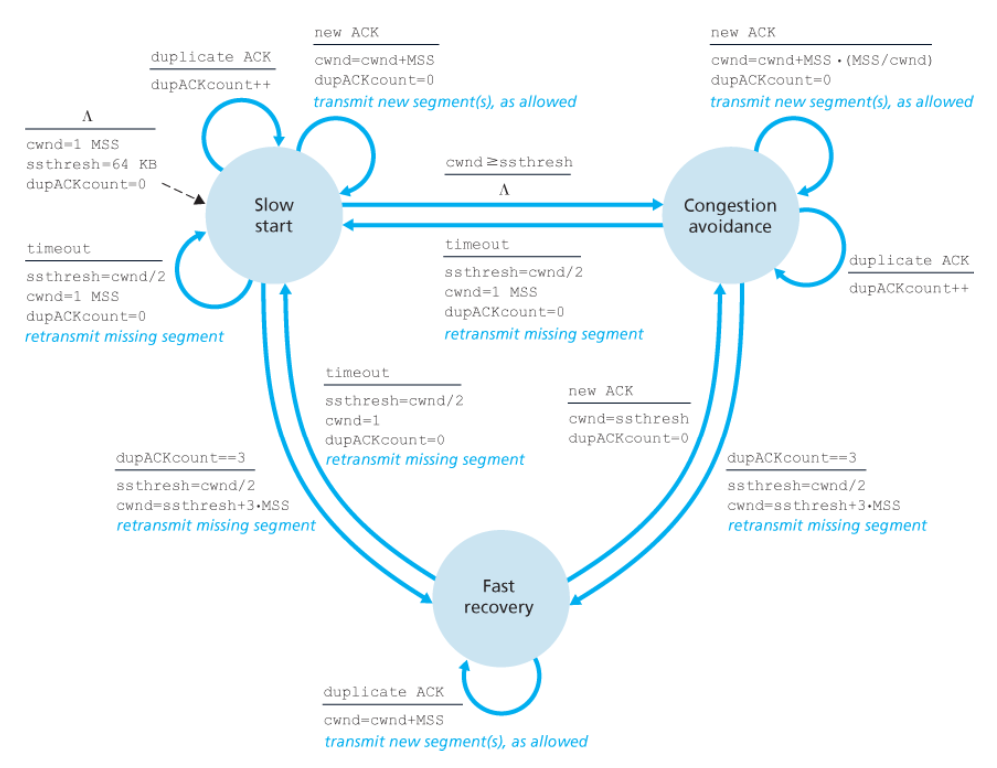
슬로 스타트(slow start)
-
TCP 연결 시작 시,
cwnd의 값은 일반적으로 1 MSS로 초기화된다.
→ 초기 전송률은 대략MSS/RTT -
TCP 송신자에게 가용 대역폭은 MSS/RTT보다 훨씬 크기 때문에 TCP 송신자는 가용 대역폭 양을 조속히 찾고자 한다.
슬로 스타트 상태에서는
cwnd값을 1 MSS에서 시작하여,
한 전송 세그먼트가 첫 번째로 확인응답을 받을 때마다 1 MSS 씩 증가한다.
아래 그림처럼 TCP 전송률은 지수적으로 증가하게 된다.
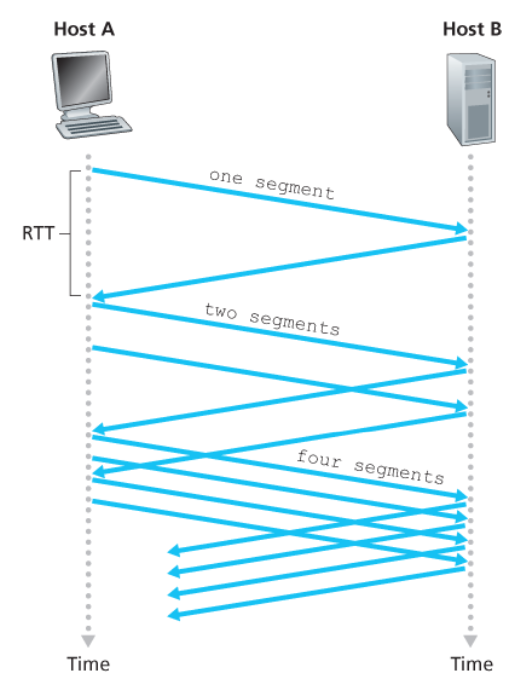
슬로스타트의 종료 조건
이 지수적 증가는 언제 끝나는 것인가?
아래와 같이 3가지 경우가 존재한다.
1️⃣ 타임아웃으로 표시되는 손실 이벤트(혼잡)가 있을 경우
- TCP 송신자는
cwnd값을 1로 설정 - 새로운 슬로 스타트를 시작한다.
2️⃣ cwnd 값이 ssthreah 값과 같을 경우
- 슬로 스타트는 종료되고
- TCP는
혼잡 회피 모드로 전환한다.
-
ssthreah(slow start threshold, 슬로 스타트 임곗값)는 두 번째 상태 변수로,cwnd/2로 정한다.
(= 혼잡이 검출되었을 시점에서의 혼잡 윈도 값의 반) -
TCP는
혼잡 회피 모드에서는cwnd를 좀 더 조심스럽게 증가시킨다.
3️⃣ 중복 ACK가 검출되는 경우
- TCP는 빠른 재전송을 수행하여 빠른 회복 상태로 들어간다.
혼잡 회피
혼잡 회피 상태로 들어가는 시점에서 cwnd의 값은 대략 혼잡이 마지막으로 발견된 시점에서의 값의 반이 된다.
혼잡 회피 상태에서 일반적으로 TCP는 RTT마다 하나의 MSS만큼cwnd를 증가시킨다.
즉, 새로운 승인이 도착할 때마다 cwnd를 MSS 바이트(MSS/cwnd)만큼 증가시킨다.
혼잡 회피 상태의 종료 조건
언제 혼잡 회피의 (RTT당 1 MSS) 선형 증가가 끝날 것인가?
TCP 혼잡 회피 알고리즘은 타임아웃이 발생했을 때 슬로 스타트의 경우와 같이,
cwnd의 값은 1 MSS로 설정하고,ssthreash의 값은 손실 이벤트가 발생할 때의 cwnd 값의 반으로 설정한다.
그러나 손실 이벤트는 3개의 중복된 ACK 이벤트에 의해 야기되며,
이 경우 네트워크는 송신자로부터 세그먼트를 수신자에게 계속 전달하고 있는 중이다.
따라서 이러한 타입의 손실 이벤트에 대해서 TCP는
- 3개의 중복 ACK를 수신한 시점에서
cwnd의 값을 반으로 줄이고 ssthresh값을cwnd 값의 반으로 기록한다.- 이후
빠른 회복 상태로 들어간다.
빠른 회복
빠른 회복 상태에서는cwnd값을 손실된 세그먼트에 대해 수신된 모든 중복된 ACK에 대해1 MSS만큼씩 증가시킨다.
이때 손실된 세그먼트는 TCP를 빠른 회복 상태로 들어가게 했던 세그먼트를 말한다.
-
손실된 세그먼트에 대한 ACK가 도착하면 TCP는
cwnd 혼잡 회피 상태로 들어간다. -
만약 타임아웃 이벤트가 발생한다면 빠른 회복은 슬로 스타트 및 혼잡 회피에서와 같은 동작을 수행한 후 슬로 스타트로 전이한다.
즉,
cwnd값은 1 MSS로 하고,ssthresh값은 손실 이벤트가 발생할 때의 cwnd 값의 반으로 한다.
빠른 회복은 구성요소의 권고사항이며, 필수는 아니다.
-
TCP 타호(TCP Tahoe, 초기 TCP 버전)
: 타임아웃으로 표시되거나 3개의 중복 ACK로 표시되는 손실이 발생하면- 무조건 혼잡 윈도를 1 MSS로 줄이고
- 슬로 스타트 단계로 들어간다.
-
TCP 리노(TCP Reno, 새로운 TCP 버전)는 빠른 회복을 채택했다.
아래는 리노와 타노에 대한 TCP의 혼잡 윈도 변화를 나타낸 그래프이다.
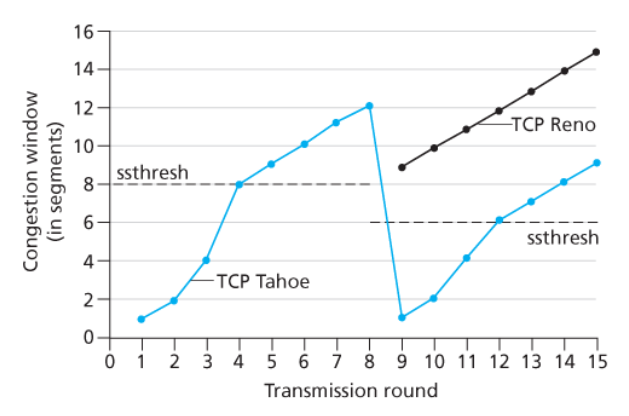
손실 이벤트가 발생했을 때
-
TCP 리노- 혼잡 윈도가 9•MSS로 설정되고
- 선형적으로 증가한다.
-
TCP 타호- 혼잡 윈도는 1 MSS로 설정되고
- ssthreash에 도달할 때까지 지수적으로 증가하며
- 그 이후에는 선형적으로 증가한다.
TCP 혼잡 제어: 복습
- 연결이 시작되고 초기 슬로 스타트 기간을 무시하고,
- 손실이 타임아웃이 아니라 3개의 중복 ACK로 표신된다고 가정한다면,
💡 TCP의 혼잡 제어는
RTT마다 1 MSS씩 cwnd의 선형(가법적인) 증가와
3개의 중복 ACK 이벤트에서 cwnd의 절반화(승법적 감소)로 구성된다.
→ TCP의 혼잡 제어는 가법적 증가, 승법적 감소(additive-increase, multiplicative decrease, AIMD)의 혼잡 제어 형식이라고 불린다.
- TCP는 3개의 중복 ACK 이벤트가 발생할 때까지 선형으로 그 혼잡 윈도 크기(결국 전송률)를 증가시킨다.
- 그러고 나서는 혼잡 윈도 크기를 감소시키지만,
- 다시 추가적인 가용 대역폭이 있는지를
탐색하기 위해 선형으로 증가시키기 시작한다.
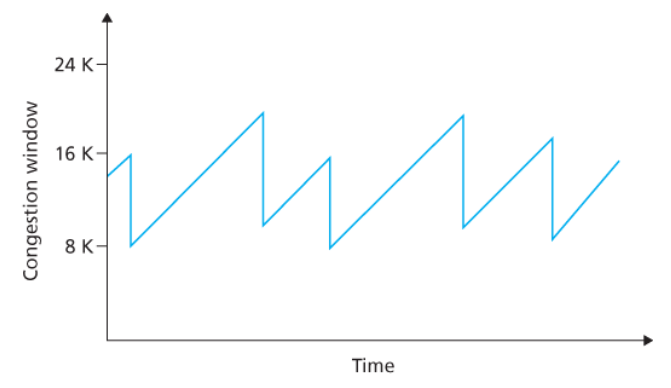
TCP 큐빅(CUBIC)
패킷 손실이 발생한 혼잡한 링크의 상태가 많이 변경되지 않은 경우
전송 속도를 더 빠르게 높여 손실 전 전송 속도에 근접한 다음 대역폭을 신중하게 조사한다.
ACK 수신 시에만 혼잡 윈도를 늘리고 슬로 스타트 단계와 빠른 복구 단계는 TCP 리노와 동일하지만,
아래의 혼잡 회피 단계가 수정되었다.
✅ 몇 가지 조율 가능한 큐빅 매개변수들이 프로토콜의 혼잡 윈도 크기가 얼마나 빨리
Wmax에 도달하는가(K)를 결정한다.
Wmax: 손실이 마지막으로 감지되었을 때 TCP의 혼잡 제어 윈도 크기K시각 : 손실이 없다고 가정할 때 TCP 큐빅의 윈도 크기가 다시 Wmax에 도달하는 미래 시점
✅ 큐빅은 혼잡 윈도를 현재 시각
t와K시각 사이 거리의 세제곱 함수로 증가시킨다.
→ t가 K에 가까울 때보다 멀리 떨어졌을 때 혼잡 윈도 크기 증가가 훨씬 더 커진다.
즉,
- 큐빅은 손실 전 속도인
Wmax에 가까워지도록 TCP의 전송 속도를 빠르게 증가시킨 다음, Wmax에 가까워지면 대역폭을 조심스럽게 탐지한다.
✅ 손실을 유발한 링크의 수준이 크게 변경된 경우 큐빅이 새 작동 지점을 더 빨리 찾을 수 있다.
t가 K에 가까울 때는 큐빅의 혼잡 윈도 증가가 작다.
(이는 손실을 유발하는 링크의 혼잡 수준이 많이 변경되지 않은 경우 좋음)t가 K를 크게 초과함에 따라 혼잡 윈도가 급격히 증가한다.
아래 그래프는 TCP 리노와 TCP 큐빅의 이상적인 성능 비교를 나타낸 것이다.

슬로 스타트 단계는 t0에서 끝나며,
t1, t2, t3에서 혼잡 손실이 발생하면 큐빅은 Wmax에 가깝게 더 빠르게 증가한다.
→ 따라서 TCP 큐빅이 더 많은 전체 처리량을 누린다.
TCP 큐빅은 혼잡 임곗값 바로 아래에서 가능한 한 오랫동안 흐름을 유지하려고 시도한다.
3.7.2 네트워크 지원 명시적 혼잡 알림과 지연 기반 혼잡 제어
1980년대 후반 슬로 스타트와 혼잡 회피의 초기 표준화 이후, TCP는 종단 끝 혼잡 제어 형식을 구현했다.
하지만 최근에는 네트워크가 TCP 송신자와 수신자에게 명시적으로 혼잡 신호를 보낼 수 있도록
IP 및 TCP에 대한 확장이 제안, 구현 및 배포되었다. (네트워크 지원 혼잡 제어 방식)
또한 측정된 패킷 지연을 사용하여 혼잡을 추론하는 TCP 혼잡 제어 프로토콜의 일부 변형이 제안되었다.
명시적 혼잡 알림(Explicit Congestion Notification, ECN)
인터넷 내에서 수행되는 네트워크 지원 혼잡 제어의 한 형태이다.
네트워크 계층에서 IP 데이터그램 헤더의 서비스 유형(Type of Service) 필드에 있는 2비트가 ECN에 사용된다.
💡 손실이 발생하기 전에 혼잡 시작을 송신자에게 알리기 위해 혼잡 알림 비트를 설정한다.
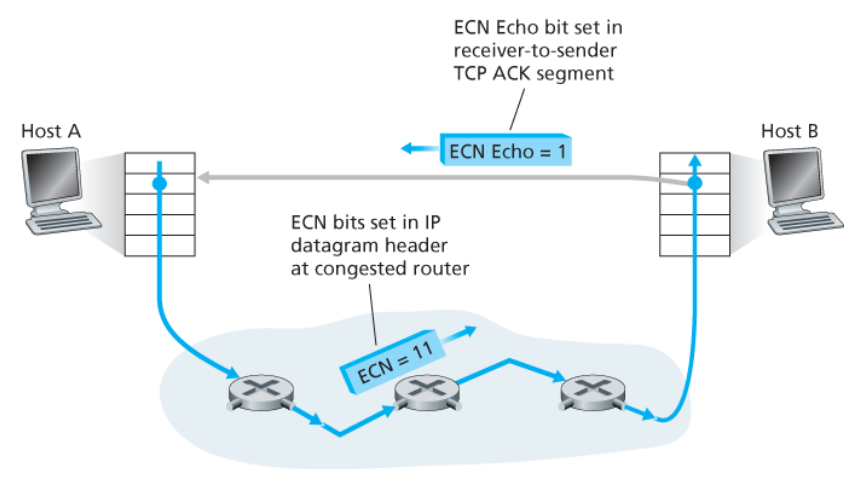
ECN 비트의 설정
ECN 비트의 한 설정은 라우터가 정체를 겪고 있음을 나타내기 위해 라우터에서 사용된다.
→ 이 혼잡 표시는 표시된 IP 데이터그램에서 목적지 호스트로 전달되어 위의 그림처럼 송신 호스트에게 알린다.
ECN 비트의 두 번째 설정은 발신 호스트가 라우터에게 다음의 정보를 알리는 데에 사용된다.
- 송신자와 수신자가 ECN을 사용할 수 있다.
- 이에 따라 ECN으로 표시된 네트워크 혼잡에 대한 응답으로 조취할 수 있다.
과정
💡 혼잡해지는 라우터는 그 라우터에서 버퍼가 가득 차서 패킷들이 삭제되기 전에
송신자에게 혼잡 시작을 알리는혼잡 알림 비트를 설정할 수 있다.
-
수신 호스트의 TCP가 수신 데이터그램을 통해
ECN 혼잡 알림 표시를 수신하면, -
수신 호스트의 TCP는 수신자-송신자 TCP ACK 세그먼트의
ECE(Explicit Congestion Notification Echo, 명시적 혼잡 알림 에코) 비트를 설정하여
송신 호스트의 TCP에 혼잡 표시를 알린다. -
TCP 송신자는 혼잡 윈도를 절반으로 줄여 혼잡 알림 표시가 있는 ACK에 반응하고,
-
다음 전송되는 TCP 수신자 세그먼트 헤더에
CWR(Congestion Window Reduced) 비트를 1로 설정한다.
지연 기반 혼잡 제어
패킷 손실이 발생하기 전에 혼잡 시작을 사전에 감지
TCP 베가스(Vegas)는 TCP 송신자가 파이프를 가득 채우되 그 이상으로 채우지 않도록 해야 한다는 원칙하에 동작한다.
즉, 파이프가 가득 찬 상태에서는 큰 큐가 쌓이도록 허용되는 경우가 좋을 게 없다는 것을 의미한다.
-
TCP 베가스는 모든 확인응답된 패킷에 대한 출발지에서 목적지까지 경로의
RTT를 측정한다. -
RTTmin : 송신자에서 측정한 RTT 값 중 최솟값
-
실제 송신자가 측정한 처리량이
cwnd/RTTmin에 가깝다면- 경로가 아직 정체되지 않았고,
- 따라서 TCP 전송 속도가 증가할 수 있다는 것이다.
-
실제 송신자가 측정한 처리량이 혼잡하지 않을 때의 처리율보다 현저히 낮다면
- 경로가 혼잡하고
- TCP 베가스 송신자는 전송 속도를 낮추게 된다.
3.7.3 공평성
각각 다른 종단 간의 경로를 갖지만, 모두 R bps의 전송률인 병목 링크(bottleneck link)를 지나는 K개의 TCP 연결을 생각해보자.
각 연결은 큰 파일을 전송하고 있고, 병목 링크를 통과하는 UDP 트래픽은 없다고 가정했을 때,
각 연결의 평균 전송률이
R/K에 가깝다면 혼잡 제어는 메커니즘이 공평하다고 한다.
즉, 각 연결은 링크 대역폭을 동등하게 공유한다.
아래 그림처럼 전송률이 R인 링크 하나를 공유하는 2개의 TCP 연결을 살펴보자.
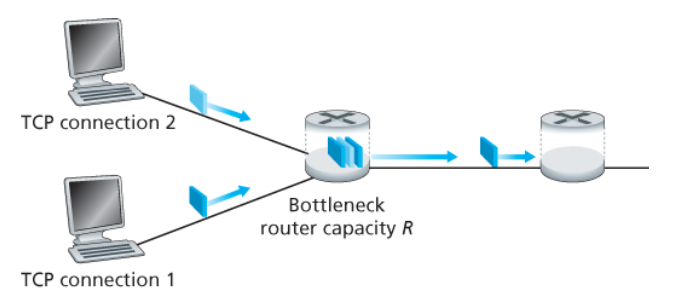
가정
- 두 연결이
같은 MSS와 RTT를 가진다.
→ 그들이 같은 혼잡 윈도우 크기를 갖는다면 같은 처리율을 가질 것이다. - 송신할 많은 양의 데이터가 있다.
- TCP의 슬로 스타트 현상을 무시한다.
- TCP 연결이 언제나
혼잡 회피 방식으로 동작한다.
TCP 연결 1과 2에 의해 실현되는 처리율은 다음과 같이 나타낼 수 있다.
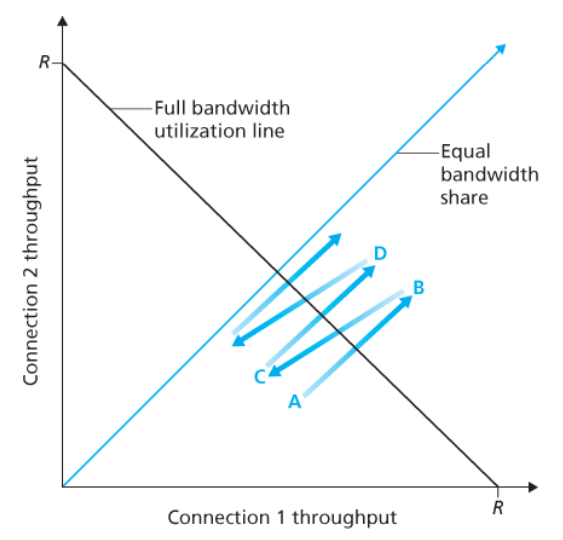
- 만약 TCP가 두 연결 사이에서 링크 대역폭을 똑같이 공유한다면,
실제 처리율은 원점에서부터 발산하면서 45º 각도의 화살표(동등한 대역폭 공유)를 따라야 한다. - 이상적으로는 두 처리율의 합이 R과 같아야 한다.
→ 목적 : 동등한 대역폭 공유 선과 완전한 대역폭 이용선의 교차 지점 가까운 곳의 처리율을 얻는 것
1️⃣ TCP 윈도 크기가 어느 주어진 시점에서 연결 1과 2가 A 지점으로 나타내는 처리율을 실현한다고 하자.
-
두 연결에 의해 공동으로 소비되는 링크 대역폭의 양이 R보다 적기 때문에
어떠한 손실도 발생하지 않을 것이다. -
양 연결은
TCP 혼잡 회피 알고리즘의 결과로서 RTT당 1 MSS씩 이들의 윈도우를 증가시킬 것이다.
따라서 두 연결의 공동 처리율은 A 지점에서 시작하는 45º 각도의 선을 따라서 계속되며,
2️⃣ 결국 두 연결에 의해 공동으로 소비되는 링크 대역폭은 R보다 커질 것이다. → 패킷 손실이 발생
(B 지점에 의해 나타내는 처리율을 실현할 때 패킷 손실을 경험한다고 하자)
그러므로 연결 1과 2는 반으로 그들의 윈도를 감소시킨다.
3️⃣ 결과적으로 실현된 처리율은 C 지점에 있게 되는데, 이는 B와 원점의 중간이다.
공동 대역폭 사용이 C 지점에서 R보다 낮으므로,
두 연결은 다시 C로부터 시작하는 45º 각도의 선을 따라 처리율을 증가시킨다.
4️⃣ 결국 손실은 다시 발생할 것이고(D 지점), 두 연결은 다시 반으로 윈도 크기를 감소시킨다.
즉, 두 연결에 의해 실현되는 대역폭은
동등한 대역폭 공유선을 따라서 결국에는 변동하며
2차원 공간 어디에 있든지 간에 상관없이 수렴한다.
→ 왜 TCP가 연결 사이에서 대역폭을 똑같이 공유하는지에 대한 직관적 느낌
위의 이상적인 시나리오와는 다르게,
현실에서는 클라이언트-서버 애플리케이션들은 링크 대역폭의 각기 다른 양을 얻을 수 있다.
특히 여러 연결이 공통의 병목 링크를 공유할 때,
- 더 작은 RTT를 갖는 세션은 대역폭이 좀 더 빠르게 비워지므로 링크에서 가용한 대역폭을 점유할 수 있고,
- 그래서 큰 RTT를 갖는 연결보다 더 높은 처리율을 갖는다.
공평성과 UDP
UDP는 혼잡 제어를 갖고 있지 않는다.
TCP의 관점에서 보면 UDP 상에서 수행되는 멀티미디어 애플리케이션은 공평하지 못하다.
즉, 다른 연결들과 협력하지도 않으며, 그들의 전송률을 적당하게 조절하지도 않는다.
TCP 혼잡 제어는 혼잡(손실) 증가에 대해 전송률을 감소시키므로,
그럴 필요가 없는 UDP 송신자들이 TCP 트래픽을 밀어낼 가능성이 있다.
→ UDP 트래픽으로 인해 인터넷이 마비되는 것을 방지하는 인터넷을 위한 혼잡 제어 방식의 개발이 필요하다.
공평성과 병렬 TCP 연결
UDP 트래픽이 공평하게 행동하도록 강요하더라도,
TCP 기반 애플리케이션의 다중 병렬 연결의 사용을 막을 방법이 없기 때문에 공평성 문제는 여전히 완전하게 해결되지 않는다.
애플리케이션이 다중 병렬 연결을 사용할 때는 혼잡한 링크 대역폭의 더 많은 부분을 차지한다.
3.8 트랜스포트 계층 기능의 발전
앞서 언급된 TCP들 뿐만 아니라, 더 많은 버전의 TCP가 존재한다.
여러 TCP 변형 프로토콜의 유일한 공통 특징은
- TCP 세그먼트 포맷을 사용하고
- 네트워크 혼잡에 직면하여 서로 ‘공정하게’ 경쟁해야 한다는 점이다.
QUIC: 빠른 UDP 인터넷 연결
애플리케이션에서 필요로 하는 트랜스포트 서비스는
- UDP가 제공하는 것보다 더 많은 서비스가 필요하지만,
- TCP와 함께 제공되는 특정 기능들을 모두 원하지는 않거나 다른 서비스를 원할 수 있다.
💡 애플리케이션 설계자는 애플리케이션 계층에 항상 ‘
자신의 프로토콜을 확장’할 수 있다.
e.g., QUIC(Quic UDP Internet Connections) = 빠른 UDP 인터넷 연결
-
특히 QUIC은 보안 HTTP를 위한 트랜스포트 계층 서비스의 성능을 향상하기 위해
처음부터 새롭게 설계된 애플리케이션 계층 프로토콜이다. -
오늘날 인터넷의 7% 이상이 QUIC이다.
-
신뢰적인 데이터 전송, 혼잡 제어 및 연결 관리를 위한 많은 접근 방식을 사용한다.
아래 그림을 통해 볼 수 있듯, QUIC은 UDP를 하위 트랜스포트 계층 프로토콜로 사용하는 애플리케이션 계층 프로토콜이며,
HTTP/2 버전 위에서 인터페이스되도록 설계되었다.
왼쪽 : 전통적인 보안 HTTP 프로토콜 스택 / 오른쪽 : 보안 QUIC 기반 HTTP/3 프로토콜 스택
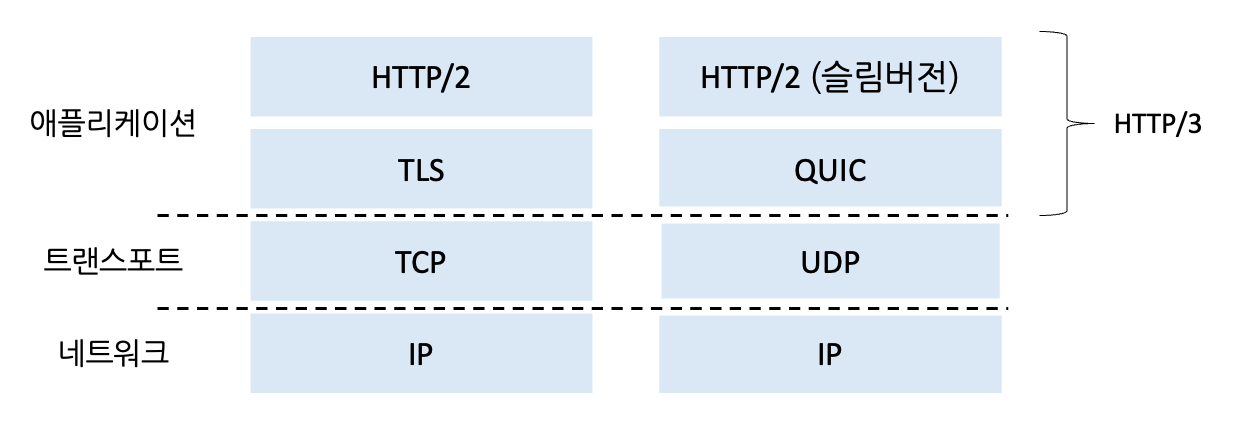
가까운 장래에 HTTP/3은 기본적으로 QUIC을 통합할 것이다.
QUIC의 주요 기능
✅ 연결지향적이고 안전함
QUIC은 두 종단 간의 연결지향 프로토콜이다.
- QUIC 연결 상태를 설정하기 위해 종단 간에
핸드셰이크가 필요 - 연결 상태의 두 부분 : 출발지와 목적지 연결 ID
QUIC은 연결 상태를 설정하는 데 필요한 핸드셰이크와 인증 및 암호화에 필요한 핸드셰이크를 결합하여,
- 먼저 TCP 연결을 설정한 다음
- TCP 연결을 통해 TLS 연결을 설정하여
여러 RTT가 필요한 전통적인 보안 HTTP 프로토콜 스택보다 더 빠른 설정을 제공한다.
✅ 스트림
- 단일 QUIC 연결을 통해 여러 애플리케이션 레벨의 ‘
스트림’들을 다중화할 수 있다. - QUIC 연결이 설정되면 새 스트림을 빠르게 추가할 수 있다.
✅ 신뢰적이고 TCP 친화적인 혼잡 제어 데이터 전송
QUIC은 각 QUIC 스트림에 대해 독립적으로 신뢰적인 데이터 전송을 제공한다.
이는 아래 그림에서 확인할 수 있다.

(a) HTTP/1.1
TCP의 RDT(신뢰적인 데이터 전송) 및 CC(혼잡 제어)상에서
애플리케이션 프로그램 레벨의 TLS 암호화를 사용하는 단일 연결 클라이언트 및 서버
TCP는 신뢰적이고 순서대로 바이트 전달을 제공하므로 여러 HTTP 요청이 목적지 HTTP 서버에서 순서대로 전달되어야 한다.
따라서 한 HTTP 요청의 바이트가 손실되면
나머지 HTTP 요청들은 손실된 바이트가 재전송되어 HTTP 서버에서 TCP가 올바르게 수신할 때까지 전달될 수 없다.
(= HOL 차단 문제)
(b) HTTP/3
UDP의 비신뢰적인 데이터그램 서비스상에서
QUIC의 암호화, 신뢰적인 데이터 전송 및 혼잡 제어를 사용하는 멀티스트림 클라이언트 및 서버
QUIC은 스트림별로 신뢰적이고 순서대로 전달하기 때문에
손실된 UDP 세그먼트는 해당 세그먼트에서 데이터가 전달된 스트림에만 영향을 준다.
즉, 다른 스트림의 HTTP 메시지는 계속 수신되어 애플리케이션에 전달될 수 있다.
QUIC은 TCP와 유사한 확인응답 메커니즘을 사용하여 신뢰적인 데이터 전송을 제공한다.
QUIC의 혼잡 제어는 TCP 리노 프로토콜을 약간 수정한 TCP 뉴리노(NewReno)를 기반으로 한다.
💡 QUIC은 두 종단 사이에 신뢰적이고 혼잡 제어된 데이터 전송을 제공하는
애플리케이션 계층 프로토콜이다.
이는 ‘애플리케이션 프로그램 업데이트 시간 척도’면에서 QUIC으로 변경될 수 있음을 의미하며,
이는 TCP 또는 UDP 업데이트 시간 척도보다 훨씬 빠르다는 뜻이다.
참고: Computer Networking: A Top-Down Approach - IT-Book-Organization