그래프의 기본 개념
그래프는 정점(Vertex) 의 집합과 간선(Edge) 의 집합으로 이루어진 자료구조다. 네트워크 경로, 의존 관계, 소셜 관계 등 현실 세계의 다양한 관계를 모델링할 수 있어 컴퓨터 과학 전반에서 핵심적인 역할을 한다.
그래프의 종류
그래프는 크게 두 가지 기준으로 분류된다.
가중치 여부: 간선에 가중치가 있는 가중 그래프(Weighted Graph) 와 가중치가 없는 비가중 그래프(Unweighted Graph) 로 나뉜다.
방향 여부:
- 방향 그래프(Directed Graph, Digraph): 간선에 방향이 있다. 간선 (u, v)에서 u는 head, v는 tail이다.
- 무방향 그래프(Undirected Graph): 간선에 방향이 없다. 일반적으로 자기 자신으로의 간선(self-loop)은 허용되지 않으며, 동일한 간선이 중복될 수 없다.
대칭 방향 그래프(Symmetric Digraph) 는 모든 간선 vw에 대해 역방향 간선 wv도 함께 존재하는 특수한 방향 그래프다.

완전 그래프(Complete Graph) 는 모든 정점 쌍 사이에 간선이 존재하는 무방향 그래프다.
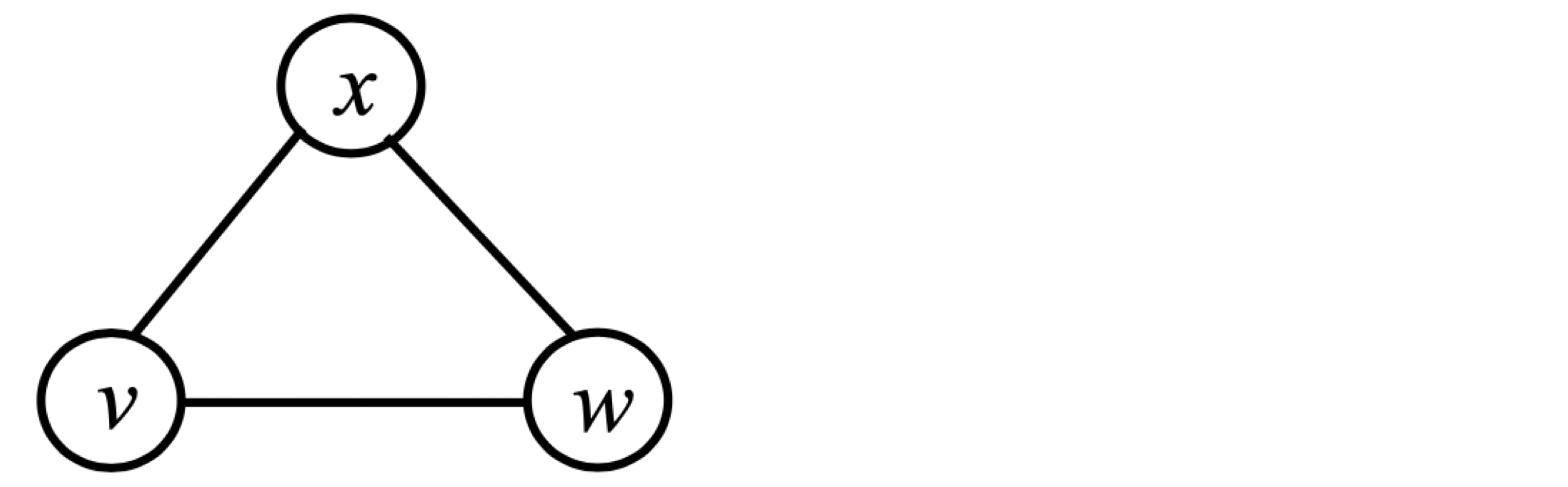
그래프의 크기
그래프의 크기는 두 가지 값으로 표현된다.
- n: 정점(노드)의 수
- m: 간선의 수
밀집 그래프(Dense Graph) 는 간선이 많은 그래프다.
- 무방향: 모든 정점이 서로 연결되면 m = n(n-1)/2 로, 이것이 완전 그래프다.
- 방향: m = n(n-1)
희소 그래프(Sparse Graph) 는 간선이 적은 그래프다. 극단적으로 간선이 0개일 수도 있다.
경로, 사이클, 부분 그래프
경로(Path) 는 정점의 나열 P = (v, v, ..., v)으로, 1 ≤ i ≤ k인 모든 i에 대해 간선 (v, v) ∈ E를 만족한다. 어떤 정점도 두 번 이상 등장하지 않으면 단순 경로(Simple Path) 라 한다.
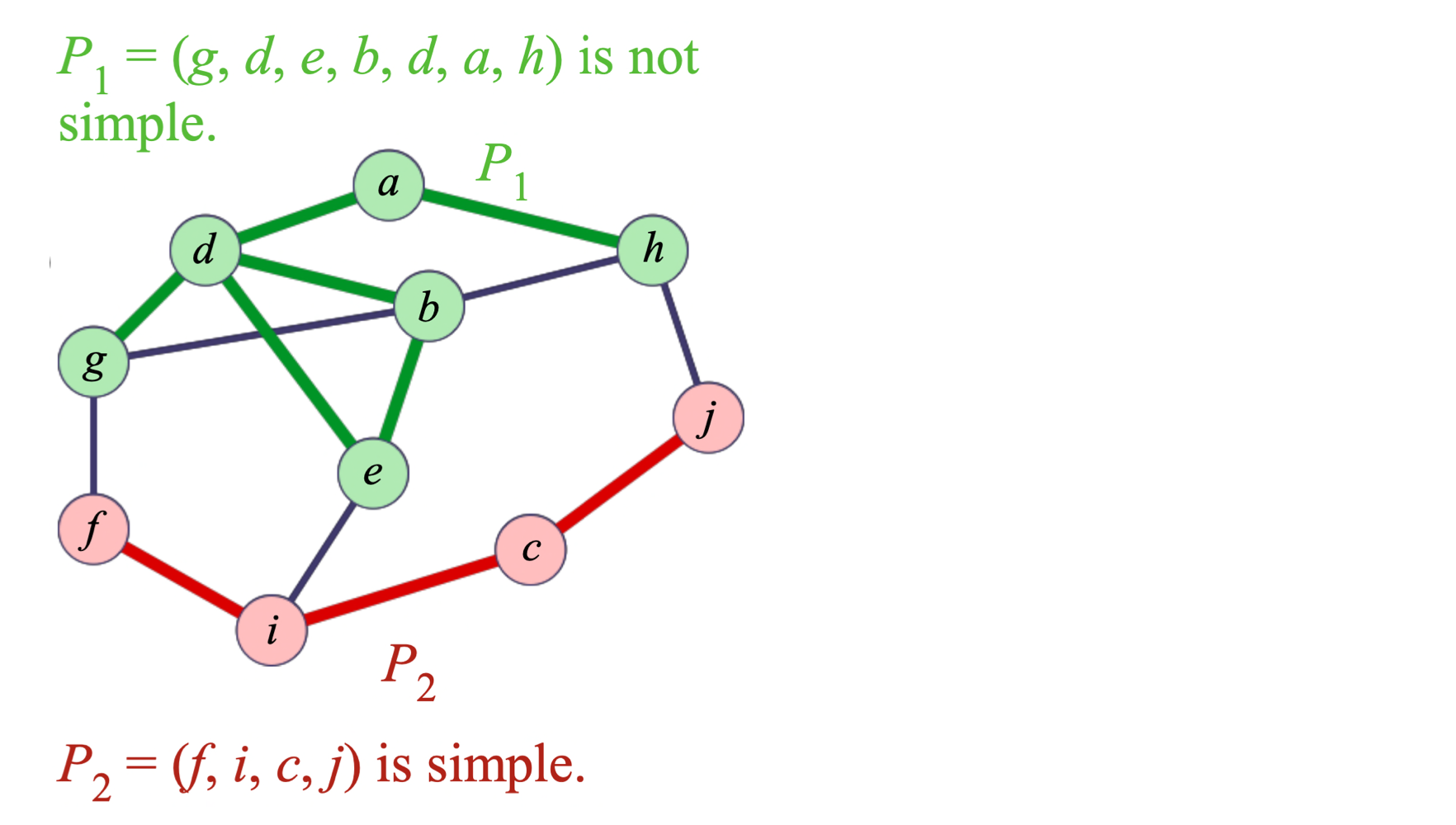
사이클(Cycle) 은 정점의 나열 C = (v, v, ..., v)로, 0 ≤ i < k인 모든 i에 대해 간선 (v, v) ∈ E를 만족한다. 내부 경로 (v, v, ..., v)가 단순 경로이면 단순 사이클이라 한다.
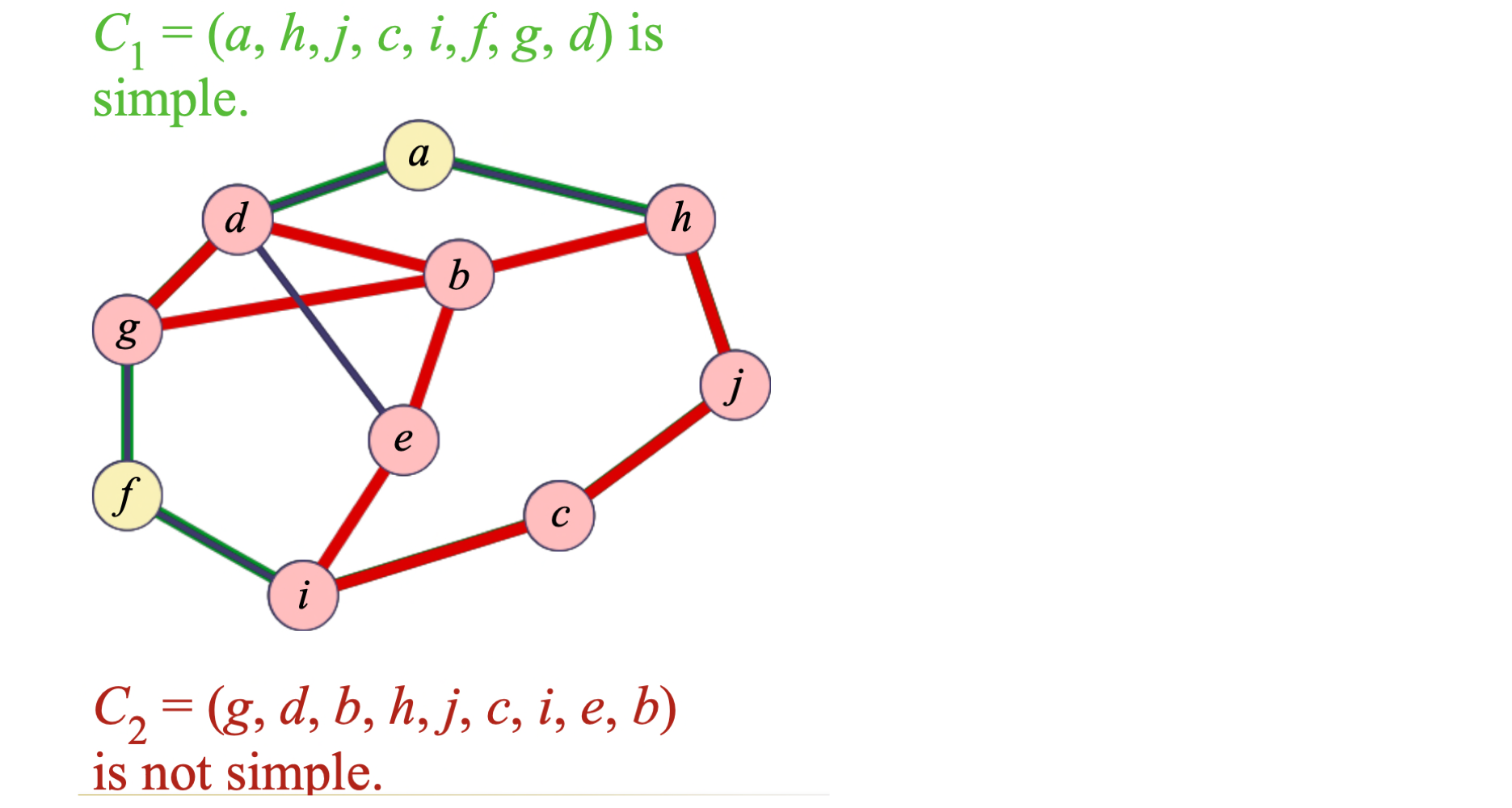
그래프 H = (W, F)가 그래프 G = (V, E)의 부분 그래프(Subgraph) 이려면 W ⊆ V 이고 F ⊆ E여야 한다. 신장 그래프(Spanning Graph) 는 G의 모든 정점을 포함하는 부분 그래프다.
연결성
무방향 그래프의 연결성:
- 연결 그래프(Connected Graph): 임의의 두 정점 사이에 경로가 존재하는 그래프다.
- 연결 요소(Connected Component): 극대(maximal) 연결 부분 그래프다.
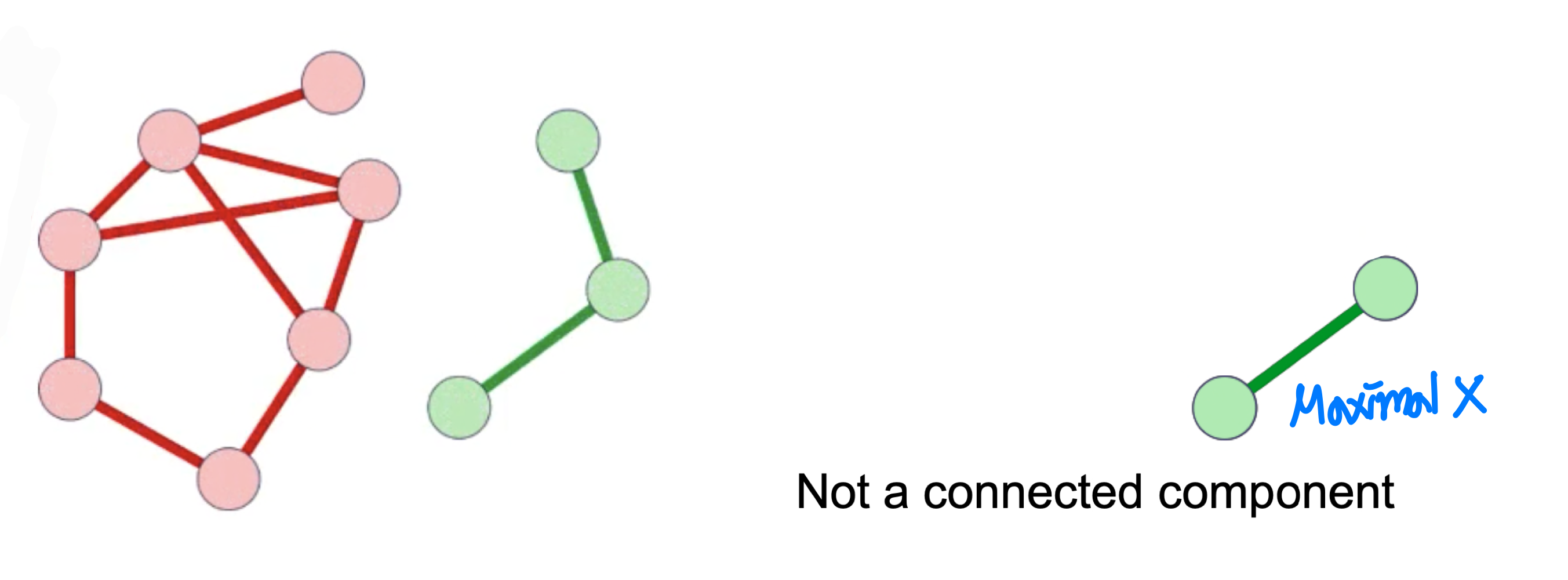
방향 그래프의 강연결(Strongly Connected):
- 방향 그래프에서는 방향이 연결성에 영향을 준다. 정점 u에서 v로 도달 가능하더라도 v에서 u로 도달 가능하지 않을 수 있다.
- 강연결이란 양방향 모두 도달 가능한 상태, 즉 대칭적인 도달 가능성을 의미한다.
특수한 그래프 구조
- 비순환 그래프(Acyclic Graph): 사이클이 없는 그래프
- DAG(Directed Acyclic Graph): 사이클이 없는 방향 그래프. 위상 정렬 등 다양한 응용에 활용된다.
- 트리(Tree): 연결이면서 사이클이 없는 그래프
- 신장 트리(Spanning Tree): 신장 그래프이면서 트리인 그래프
그래프의 표현
그래프를 컴퓨터에 저장하는 대표적인 방법은 두 가지다.
인접 행렬(Adjacency Matrix) -- O(V) 저장 공간
정점이 4개인 무방향 그래프를 인접 행렬로 표현할 때 최소 저장 공간은 6 bits다. 무방향 그래프의 인접 행렬은 대칭이므로 절반만 저장하면 되고, 자기 루프가 없으므로 대각선도 필요 없다.

인접 행렬은 밀집 그래프에 적합하다. 큰 그래프에서는 저장 공간이 과도하지만, 작은 그래프에서는 매우 효율적일 수 있다. 대부분의 대규모 그래프는 희소 그래프이므로, 이런 경우에는 인접 리스트가 더 적절한 표현 방식이다.
인접 리스트(Adjacency List) -- O(V+E) 저장 공간
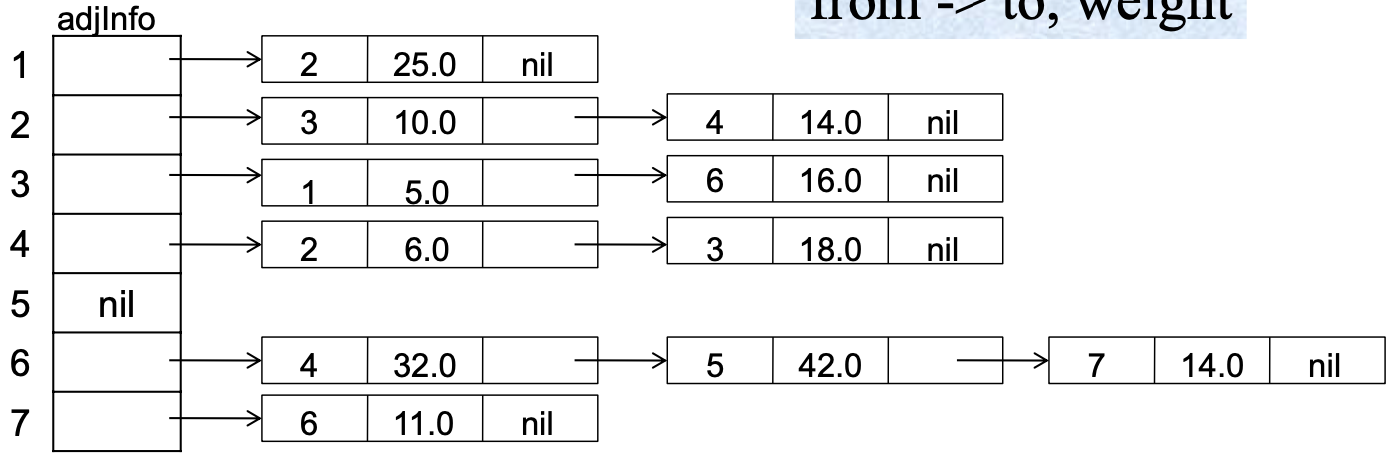
BFS (너비 우선 탐색)
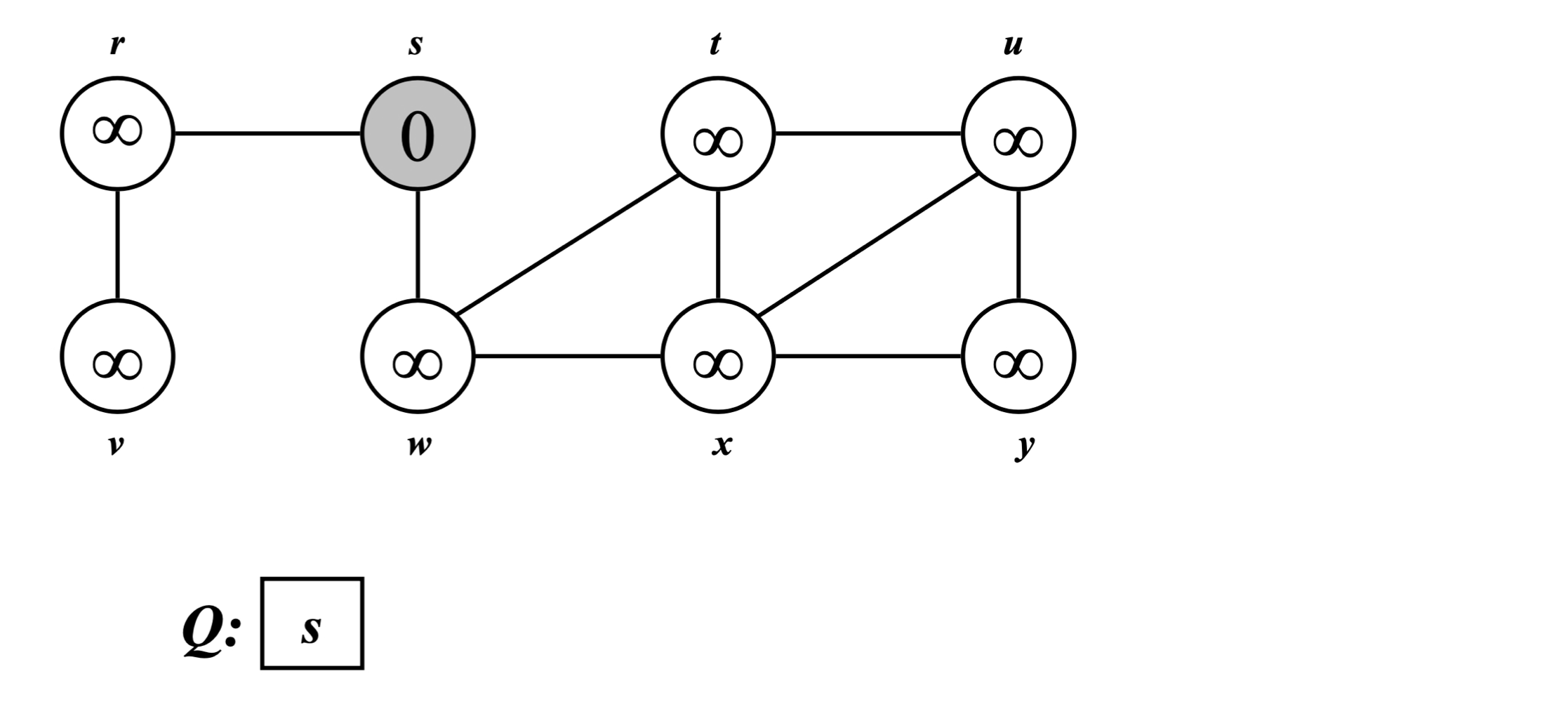
BFS(Breadth-First Search)는 그래프를 스캔하여 너비 우선 신장 트리(Breadth-First Spanning Tree) 를 구축하는 알고리즘이다. 마치 호수에 돌을 던졌을 때 파문이 퍼져 나가는 것처럼, 시작 정점에서 가까운 정점부터 차례로 방문한다.
동작 원리
- 시작 정점 s를 루트로 선택한다.
- s의 인접 정점(자식)을 발견하고, 그 다음에는 그들의 인접 정점을 발견하는 식으로 확장해 나간다.
- s에서 도달 가능한 모든 정점 v에 대해, 트리에서 s에서 v까지의 경로는 G에서의 최단 경로에 해당한다.
여기서 두 가지 핵심 용어를 구분해야 한다.
- Discover(발견): 정점을 처음 만나는 것. 모든 도달 가능한 정점이 발견된다.
- Explore(탐색): 간선을 처음 조사하는 것. 탐색되지 않는 간선이 존재할 수 있다.
색상 기반 상태 관리
BFS는 각 정점을 세 가지 색으로 관리한다.
- White(흰색): 아직 발견되지 않은 상태. 모든 정점은 처음에 흰색이다.
- Gray(회색): 발견되었지만 아직 처리가 끝나지 않은 상태. 흰색 정점과 인접해 있을 수 있으며, 너비 우선 트리에 추가된다.
- Black(검정): 발견되었고 처리가 완료된 상태. 검정 또는 회색 정점하고만 인접한다.
흰색 정점이 발견되면 회색으로 바꾸고, 그 정점의 모든 흰색 이웃을 발견한다. 모든 이웃이 발견되면 검정으로 바꾸어 완료 표시를 한다. 회색 정점의 인접 리스트를 스캔하며 새로운 정점을 발견해 나간다.

시간 복잡도 분석
BFS의 수행 시간은 다음과 같이 분석된다.
- A. 각 노드는 한 번만 큐에 삽입된다 (white → gray): (V)
- B. 각 노드는 한 번만 큐에서 제거된다 (gray → black): (V)
- C. 각 인접 리스트는 한 번만 스캔된다: (E)
따라서 전체 수행 시간은 (V+E) 이다.
비유: 섬과 다리
정점을 섬, 간선을 다리라고 생각해 보자. BFS는 여러 사람이 출발점에서 동시에(또는 거의 동시에) 각 방향으로 퍼져 나가며 탐색하는 것과 같다.
연습 문제
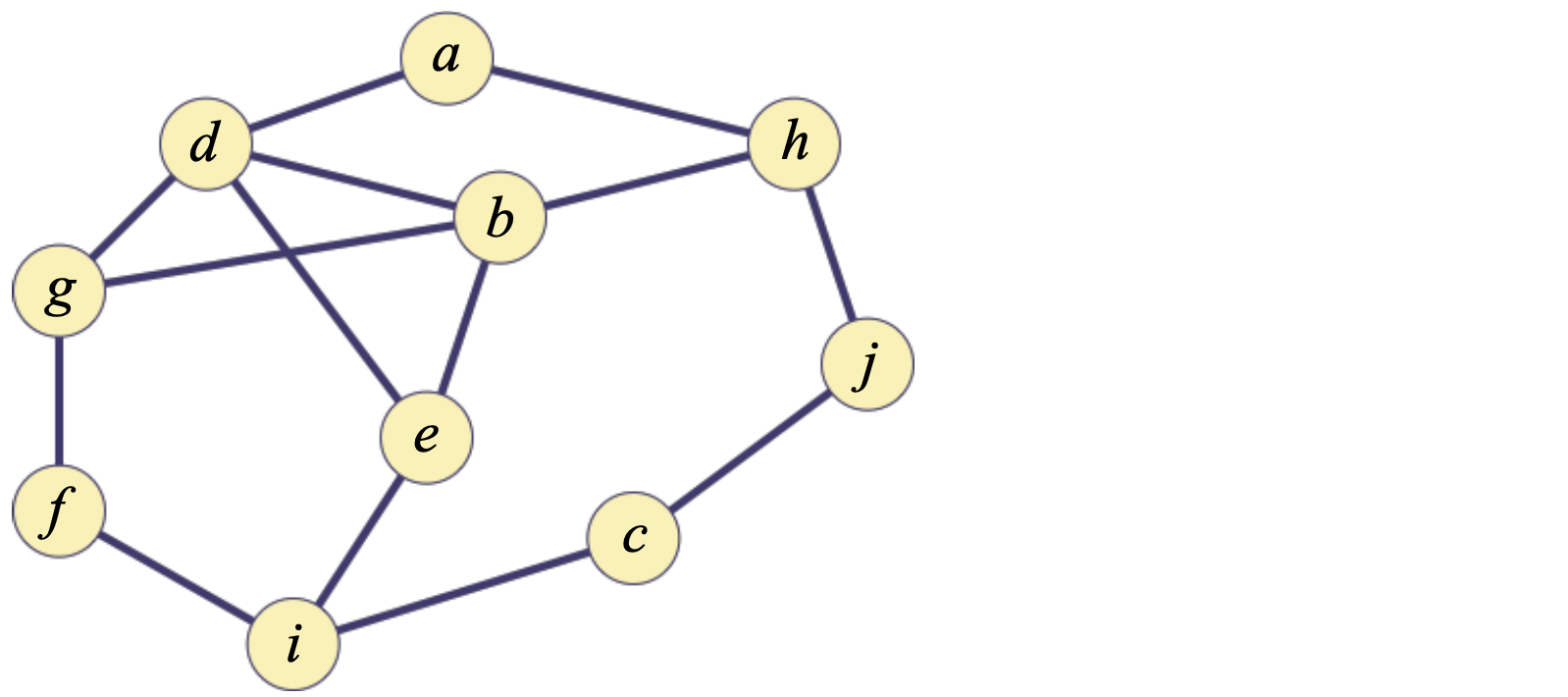
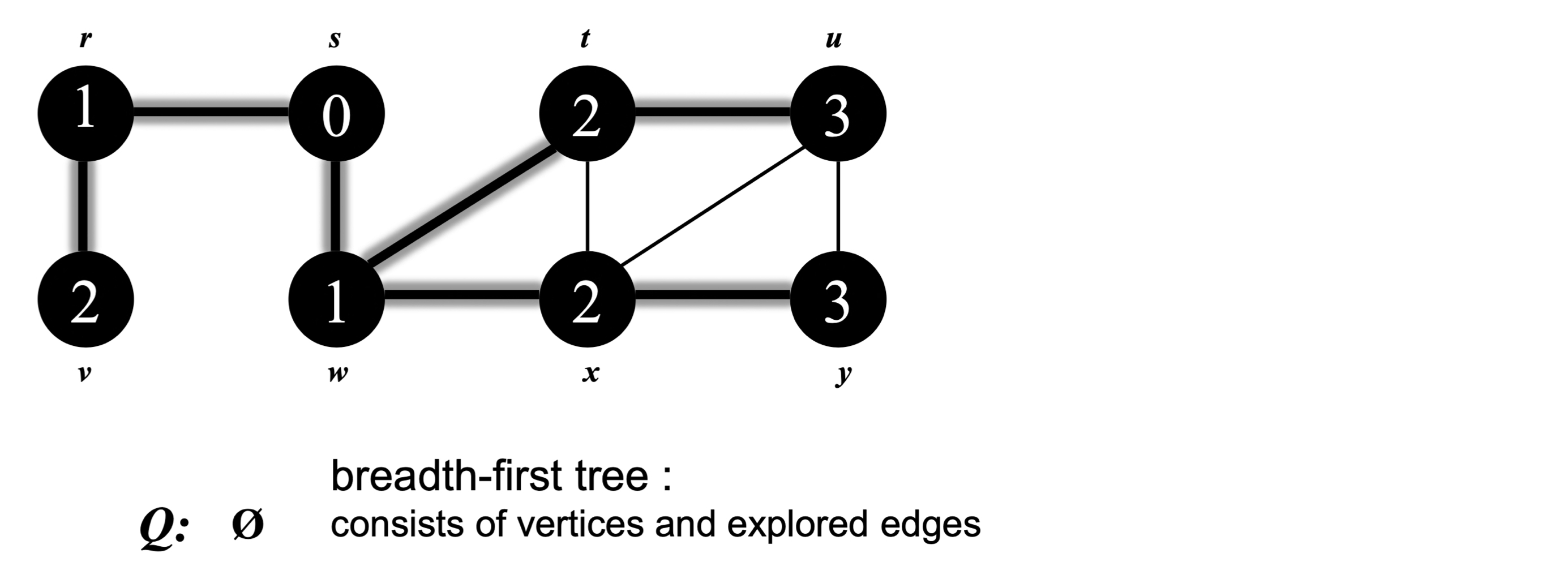
위 그래프에서 정점 'a'를 루트로 하여 너비 우선 신장 트리를 만들어 보자. 정점은 알파벳 순서로, 각 인접 리스트도 알파벳 순서로 정렬되어 있다고 가정한다.
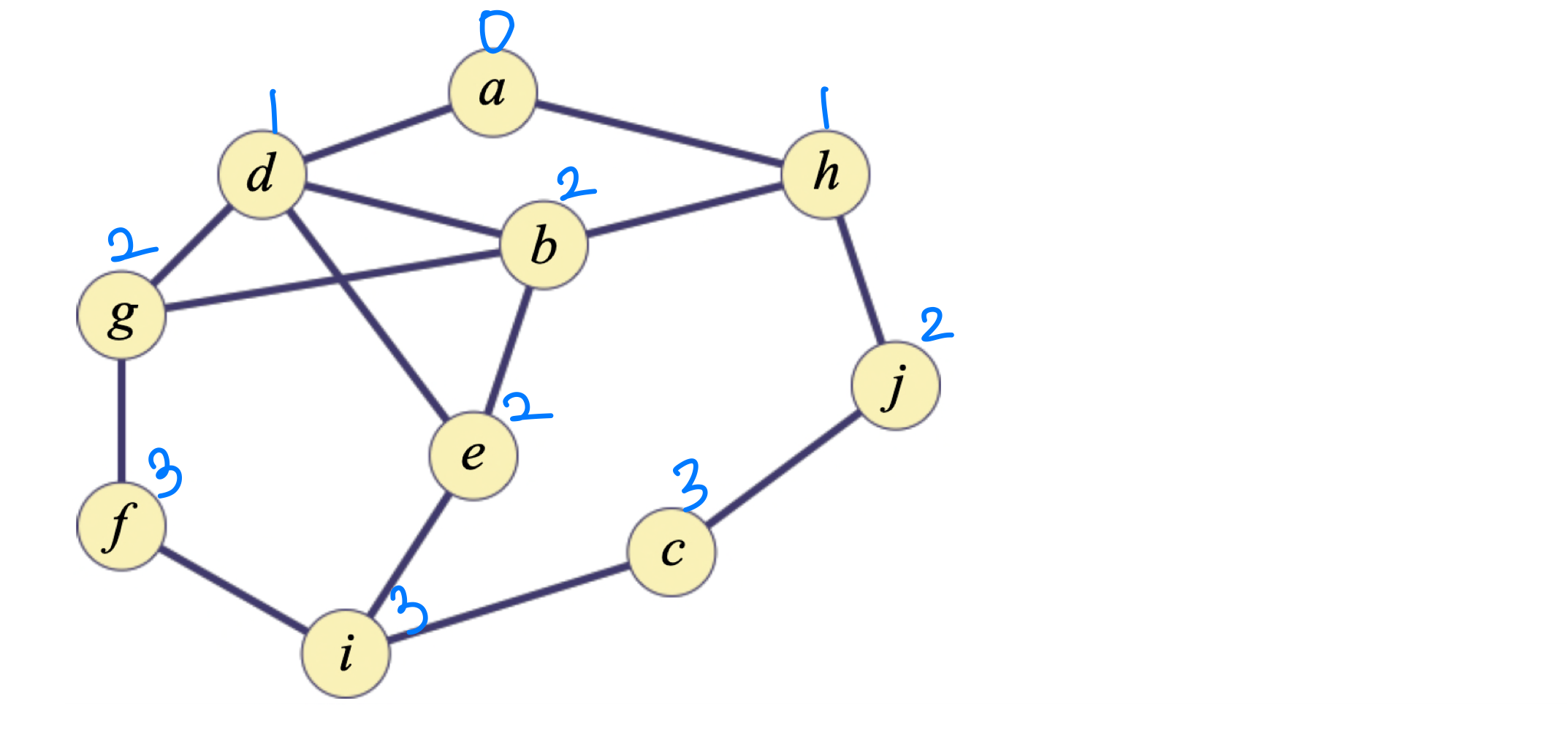
정점 c에서 루트까지의 최소 거리는 3이다.
BFS의 성질
정리 1: BFS는 루트로부터의 거리가 증가하는 순서로 정점을 방문한다. BFS가 만든 너비 우선 트리에서 루트까지의 경로는 원래 그래프 G에서의 최단 경로를 나타낸다.
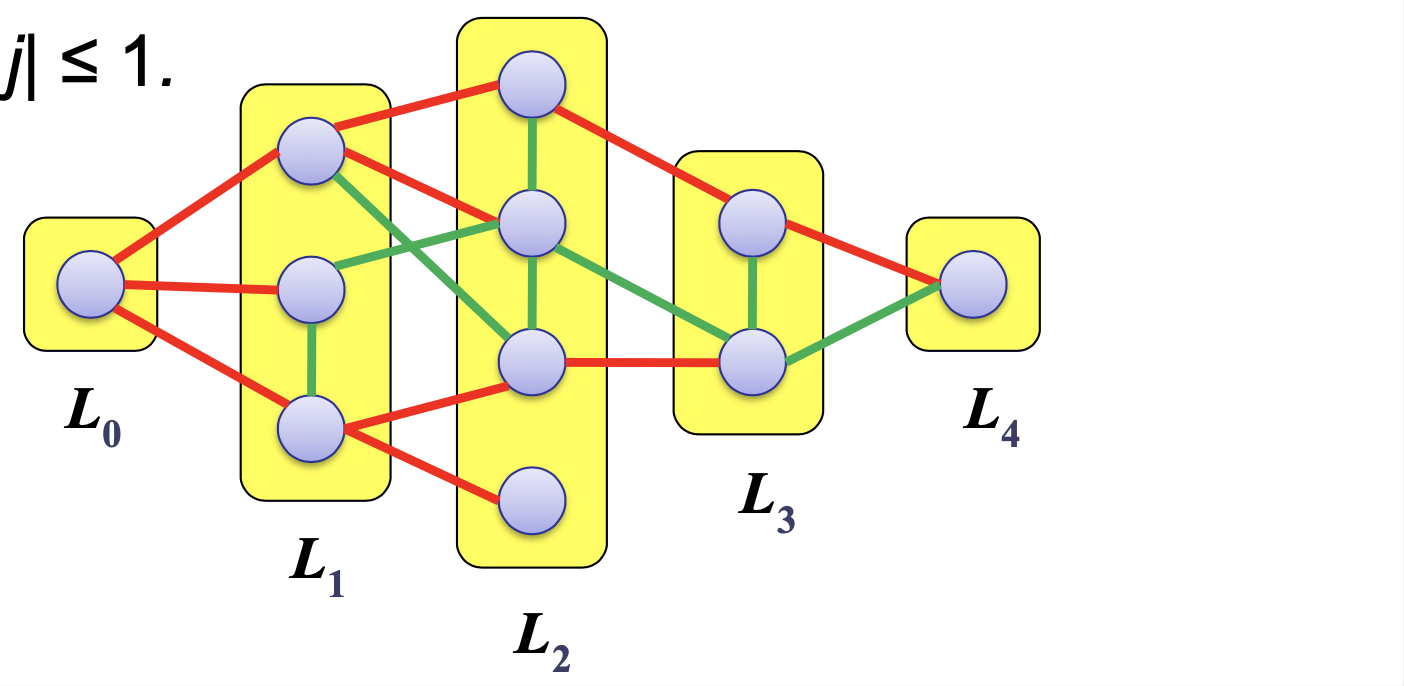
정리 2: 그래프 G의 모든 간선 (v, w)에 대해 v ∈ L이고 w ∈ L이면, |i - j| ≤ 1 이다. 즉, 인접 정점은 같은 레벨이거나 한 레벨 차이가 난다.
DFS (깊이 우선 탐색)
DFS(Depth-First Search)는 그래프를 탐색하는 또 다른 전략으로, 가능한 한 깊이 들어가며 탐색한다. BFS가 파문처럼 넓게 퍼진다면, DFS는 미로에서 한 방향으로 끝까지 가 보고, 막히면 되돌아와서 다른 방향을 시도하는 방식이다.
동작 원리
- 시작 정점 s를 루트로 선택한다.
- 가장 최근에 발견된 정점 v에서 아직 탐색하지 않은 간선이 있으면 그 간선을 따라간다.
- v의 모든 간선이 탐색되면 v를 발견시킨 정점으로 백트래킹(backtrack) 한다.
- 하나의 DFS 트리가 완성되면, 아직 발견되지 않은 정점이 있다면 그 정점에서 새로 시작한다. 이는 그래프가 비연결인 경우에 해당한다.
BFS와의 핵심 차이는 이것이다. BFS는 발견한 정점을 큐에 넣고 나중에 탐색하지만, DFS는 발견 즉시 그 정점에서 탐색을 계속한다. 다만, 인접 정점이 이미 발견된 상태라면 간선은 탐색하지 않고 확인만 하는데, 이 점은 BFS와 동일하다.
색상과 타임스탬프
DFS도 BFS와 마찬가지로 세 가지 색으로 정점 상태를 관리한다.
- WHITE: 미발견
- GRAY: 발견했지만 처리 미완료 (아직 이 정점에서의 탐색이 끝나지 않음)
- BLACK: 완료 (이 정점에서 도달 가능한 모든 것을 찾음)
DFS의 특징적인 출력은 각 정점에 기록되는 두 개의 타임스탬프다.
- d[v]: 발견 시간 (discovery time)
- f[v]: 완료 시간 (finish time)
이 타임스탬프는 1부터 2|V|까지의 고유한 정수값을 가지며, 모든 정점 v에 대해 1 ≤ d[v] < f[v] ≤ 2|V| 을 만족한다.

알고리즘
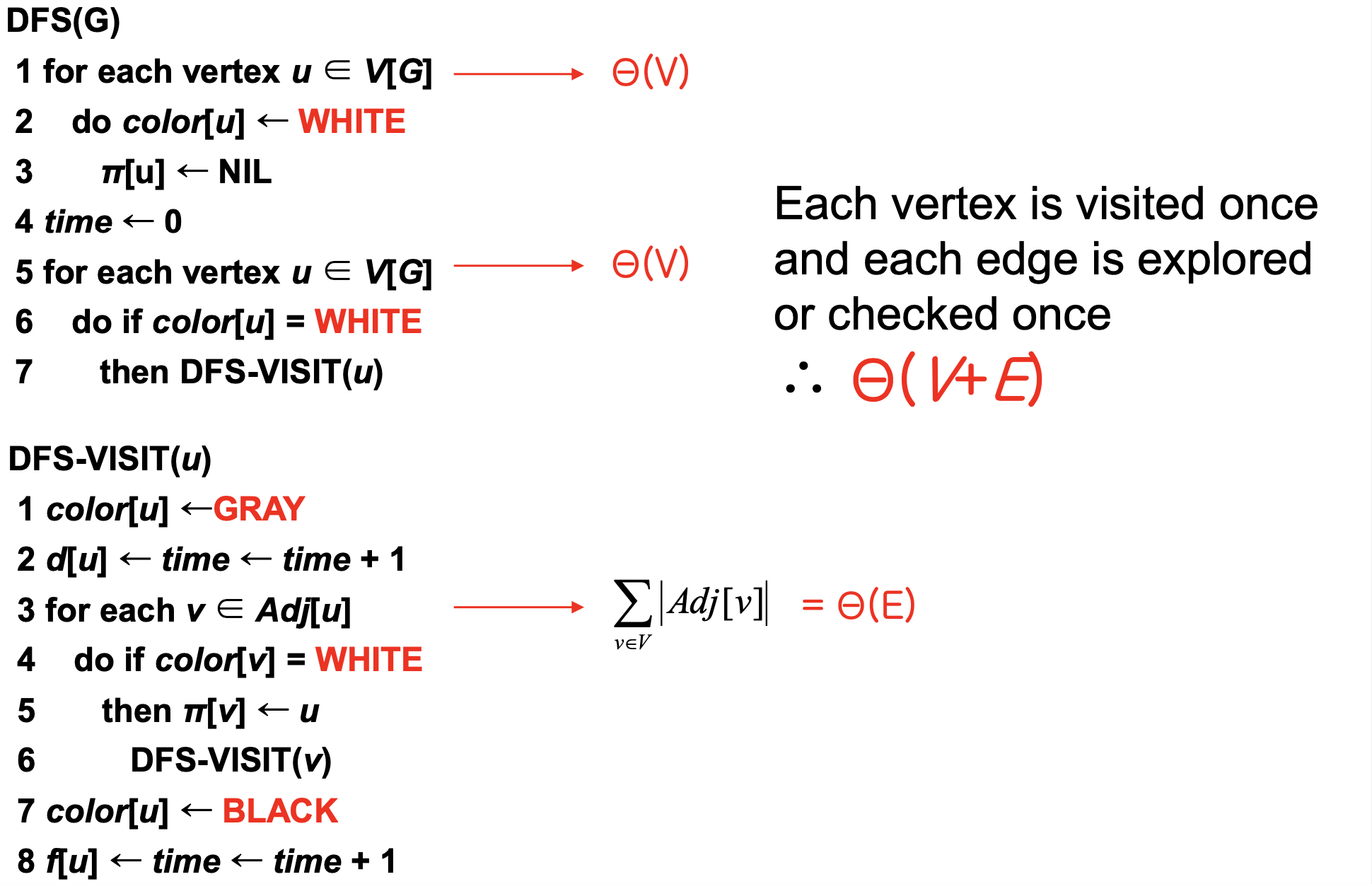
DFS(V, E)
for u : V
color[u] = WHITE
time = 0 // Global timestamp
for u : V
if color[u] == WHITE
DFS-VISIT(u)
DFS-VISIT(u)
// Discovery
color[u] = GRAY
time++
d[u] = time
// Adj
for v : Adj[u]
if color[v] == WHITE
DFS-VISIT
// Finish
color[u] = BLACK
time++
f[u] = time비유: 섬과 다리 (DFS 버전)
DFS에서는 BFS와 달리 한 사람이 섬들을 탐색한다. 아직 발견하지 않은 섬이 있으면 화살표 방향으로 이동하고, 다리를 역방향으로 건너야 하면 뒤로 걸어간다. 이것이 바로 백트래킹이다.
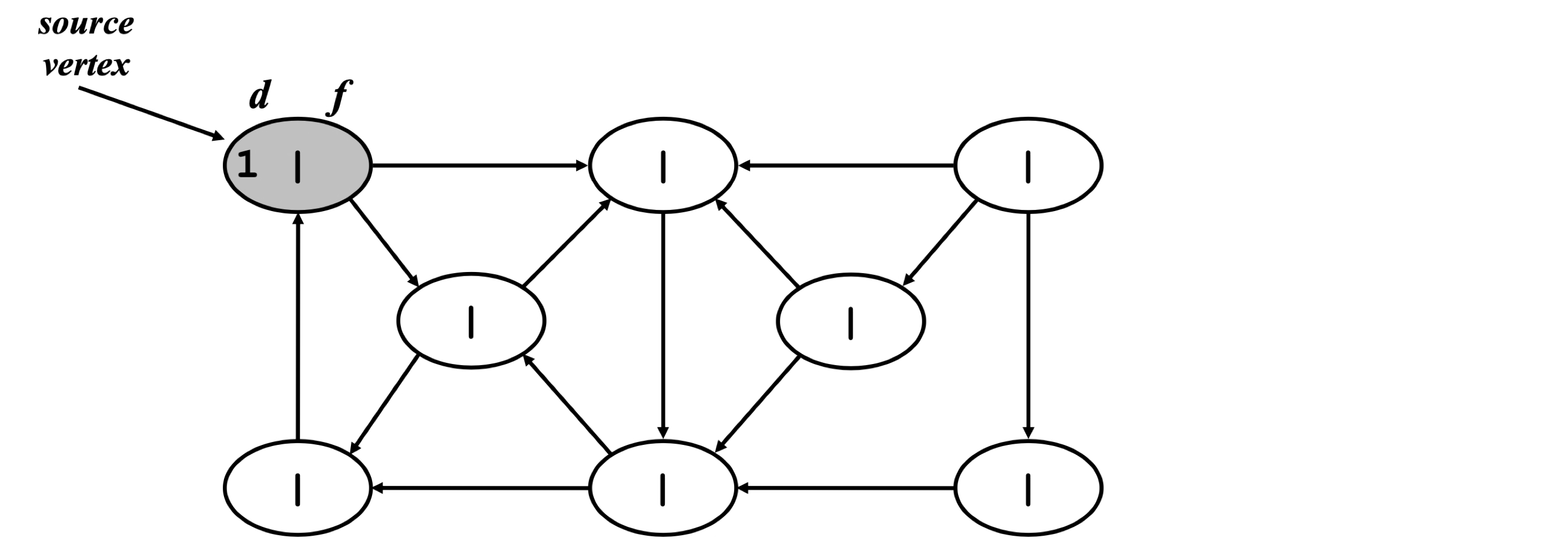
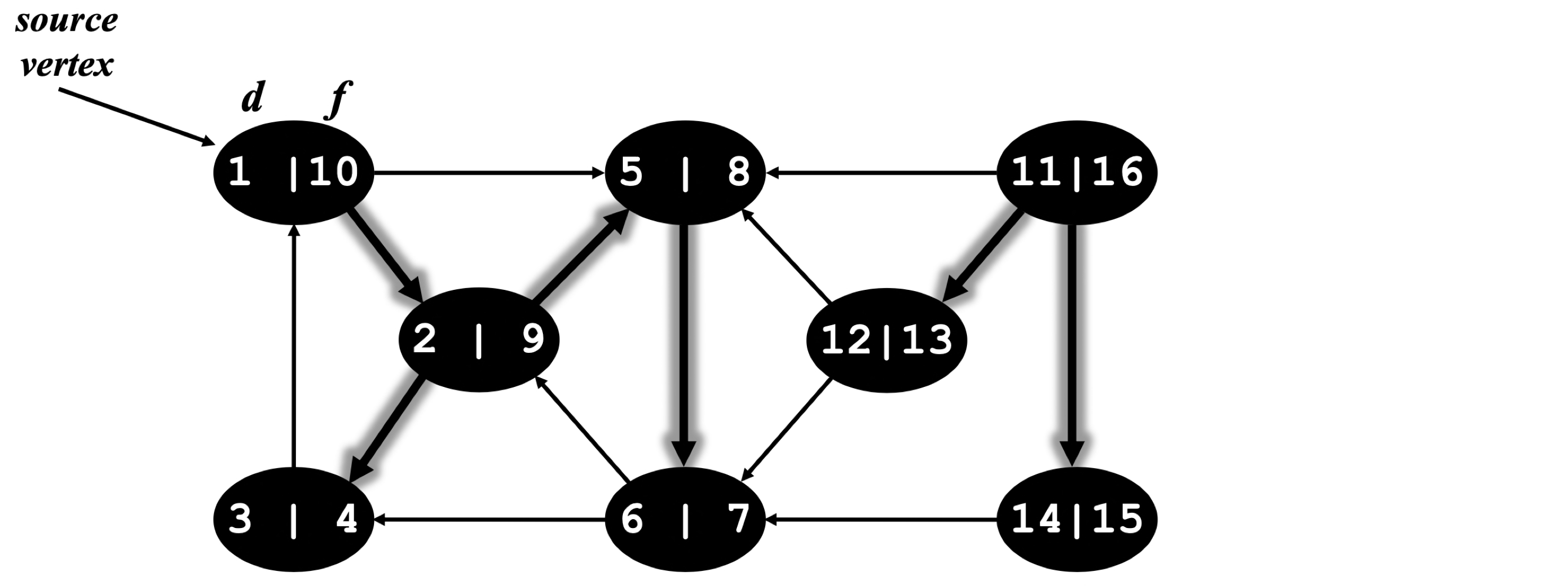
연습 문제
정점은 알파벳 순서로, 각 인접 리스트도 알파벳 순서로 정렬되어 있다고 가정한다.
시간 복잡도 분석
트리 vs. 일반 그래프에서의 DFS
트리에서 DFS를 수행하면 G1, G2, G3처럼 서로소 집합이므로, 이미 방문한 노드를 다시 방문할 가능성을 걱정할 필요가 없다. 트리의 간선은 한 방향이고 사이클이 없으므로 |V| = n, |E| = n-1 이다.


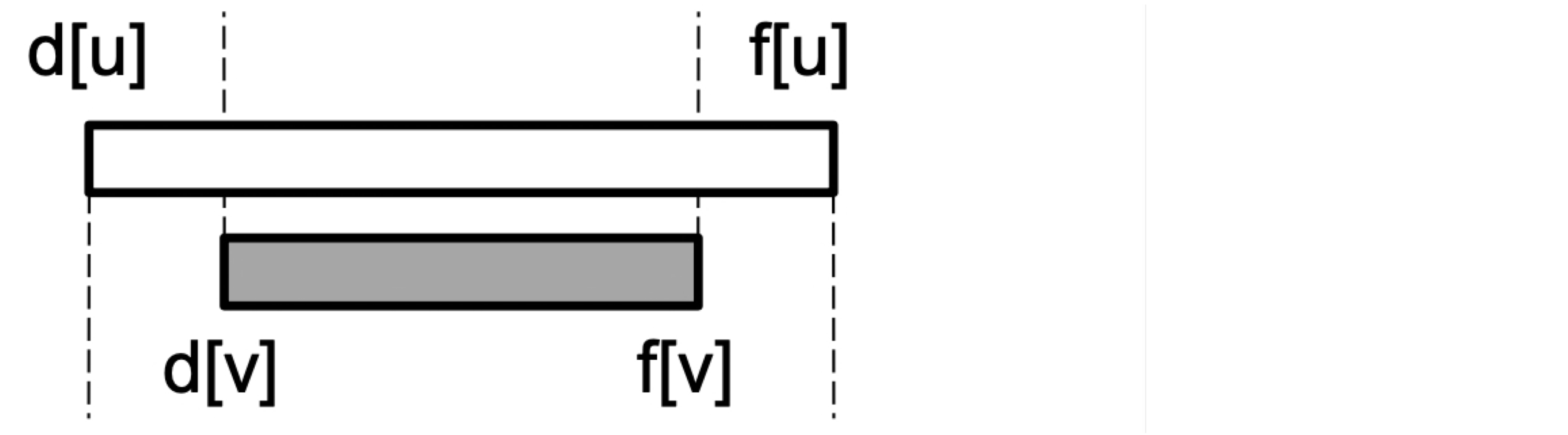
괄호 정리 (Parenthesis Theorem)
DFS에서 발견 시간과 완료 시간은 괄호 구조처럼 동작한다. 모든 정점 u, v에 대해 정확히 하나의 경우만 성립한다.
- d[u] < f[u] < d[v] < f[v] 또는 d[v] < f[v] < d[u] < f[u] -- u와 v는 서로 자손 관계가 아니다
- d[u] < d[v] < f[v] < f[u] -- v는 u의 자손이다
- d[v] < d[u] < f[u] < f[v] -- u는 v의 자손이다
따라서 d[u] < d[v] < f[u] < f[v]는 불가능하다. 이는 마치 괄호와 같다. ()[], ([]), [()]는 올바르지만, ([)]이나 [(])는 올바르지 않다.
Corollary: v가 u의 적절한 자손(descendant) 이면 d[u] < d[v] < f[v] < f[u]이다.
Proof
대칭성을 이용해 d[u] < d[v] 를 가정한다.
경우 1: d[v] < f[u]인 경우
v는 u가 아직 회색인 동안 발견되었으므로 v는 u의 자손이다. v가 u보다 나중에 발견되었으므로 v에서 나가는 모든 간선이 탐색되고 v가 완료된 후에야 u가 완료된다.
따라서 f[v] < f[u]이고, 결과적으로 d[u] < d[v] < f[v] < f[u]이다.
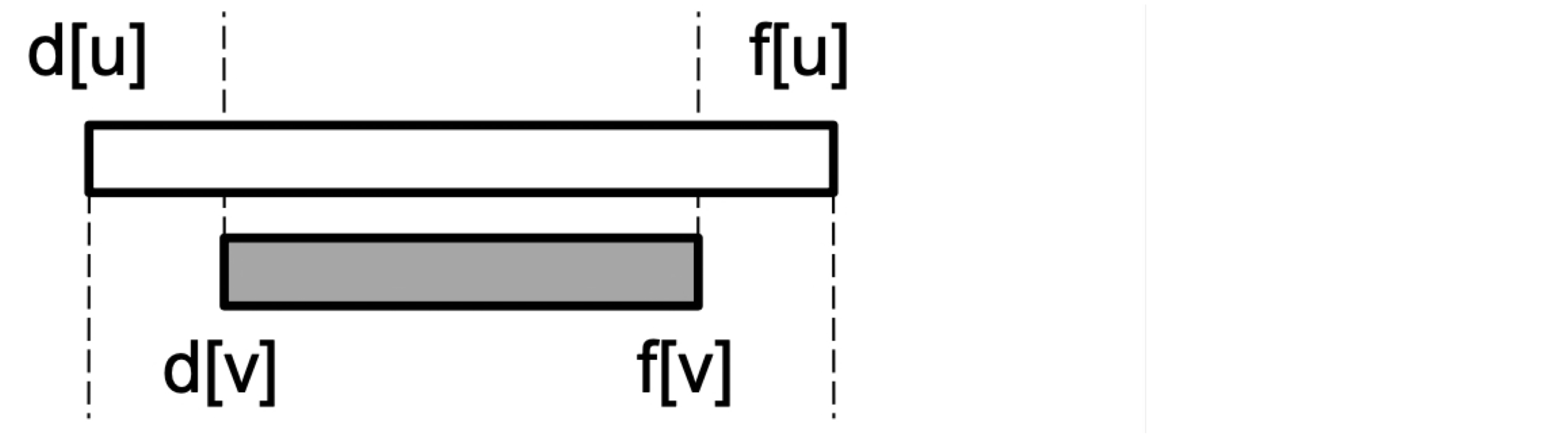
구간 [d[v], f[v]]가 구간 [d[u], f[u]] 안에 완전히 포함된다.
경우 2: d[v] > f[u]인 경우(분리된 구간)
d[u] < f[u] < d[v] < f[v]가 되어 두 구간이 겹치지 않는다.

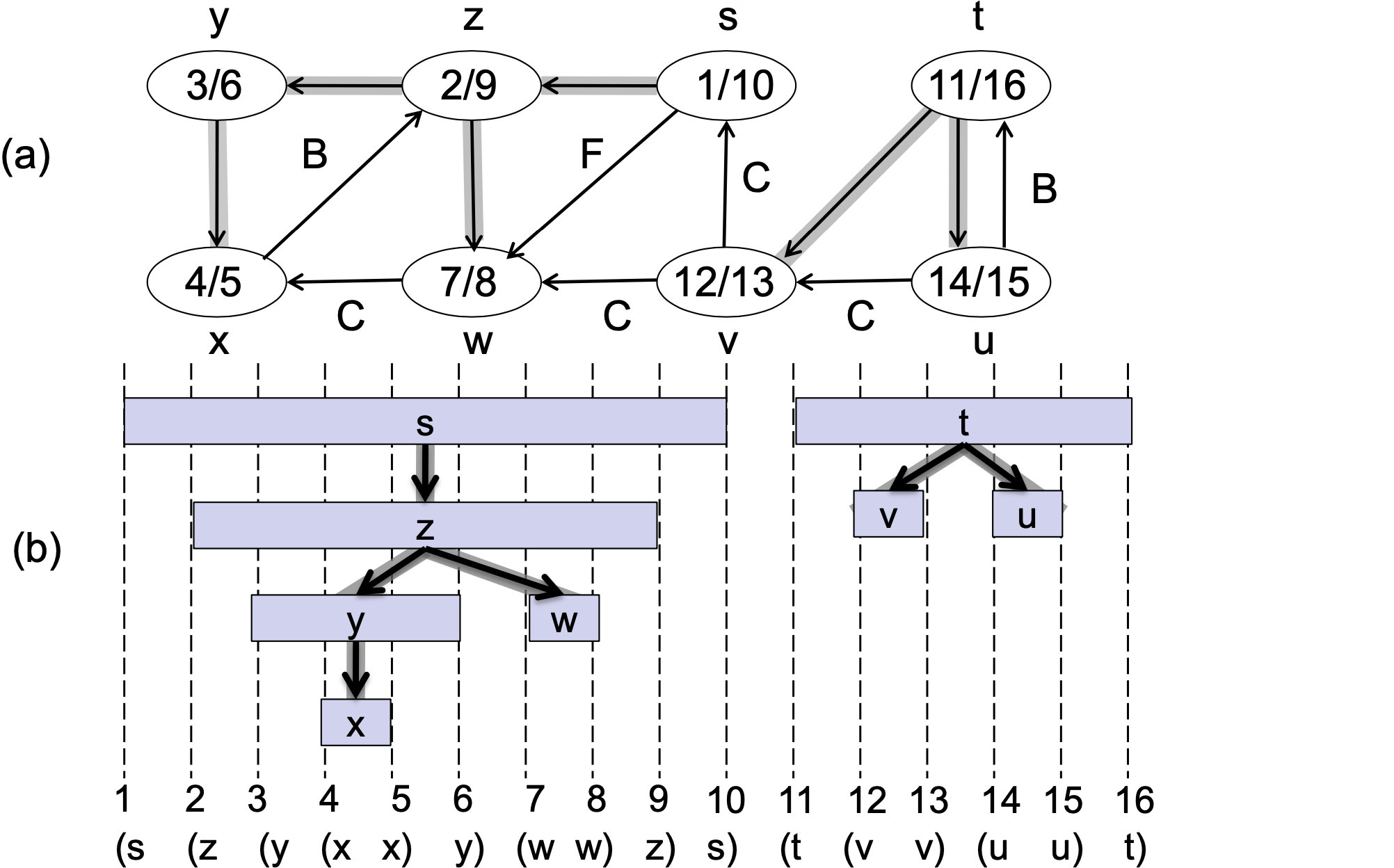
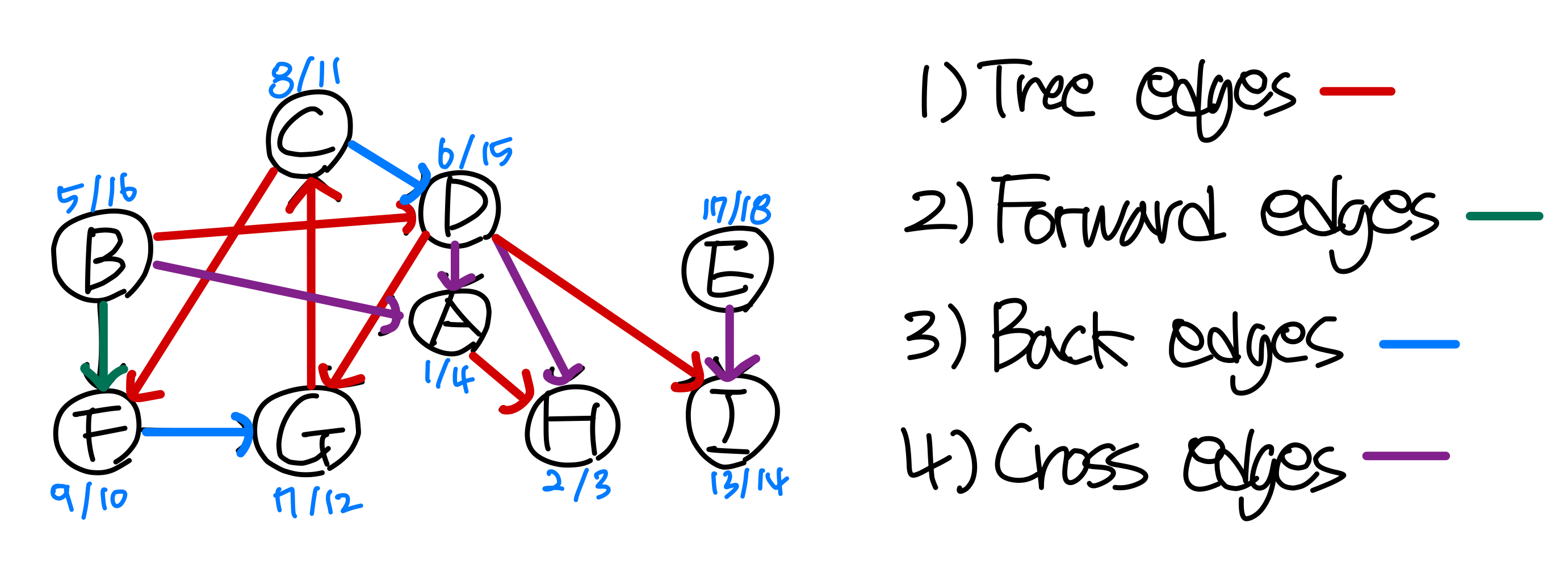
DFS 간선의 분류
DFS를 수행하면 그래프의 간선은 네 가지 유형으로 분류된다.
Tree edge(트리 간선): 새로운(흰색) 정점을 만나는 간선이다. 트리 간선들은 신장 포레스트(Spanning Forest) 를 구성한다. 트리 간선은 사이클을 형성할 수 없다.
Back edge(역방향 간선): 자손에서 조상으로 향하는 간선이다. 회색 정점에서 회색 정점으로 이동하는 경우에 해당한다.

Forward edge(순방향 간선): 조상에서 자손으로 향하는 간선이다. 트리 간선이 아닌 경우다. 회색 노드에서 검정 노드로의 간선이다.
Cross edge(교차 간선): 서로 다른 트리 또는 서브트리 사이의 간선이다. 마찬가지로 회색 노드에서 검정 노드로의 간선이다.
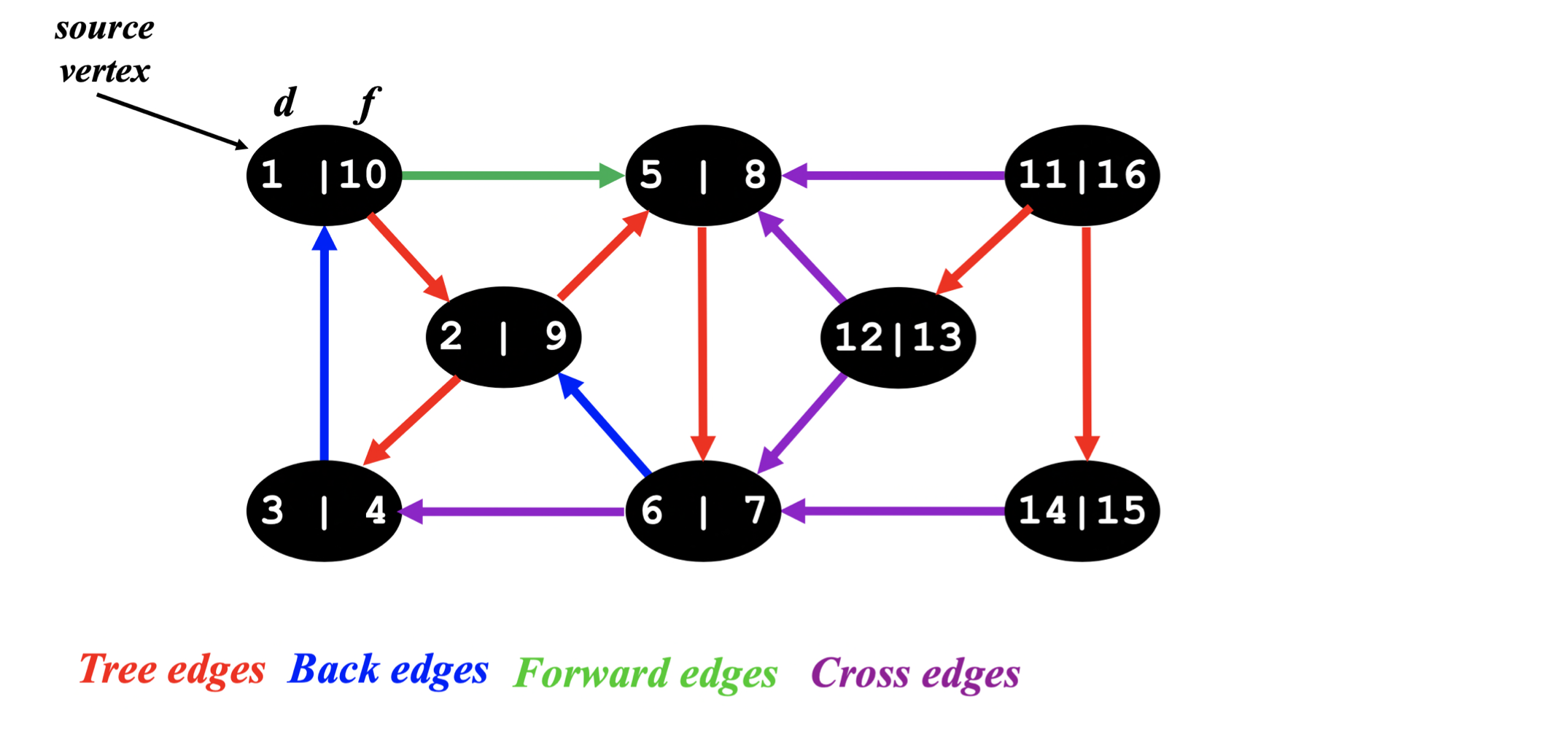
간선 분류 예제
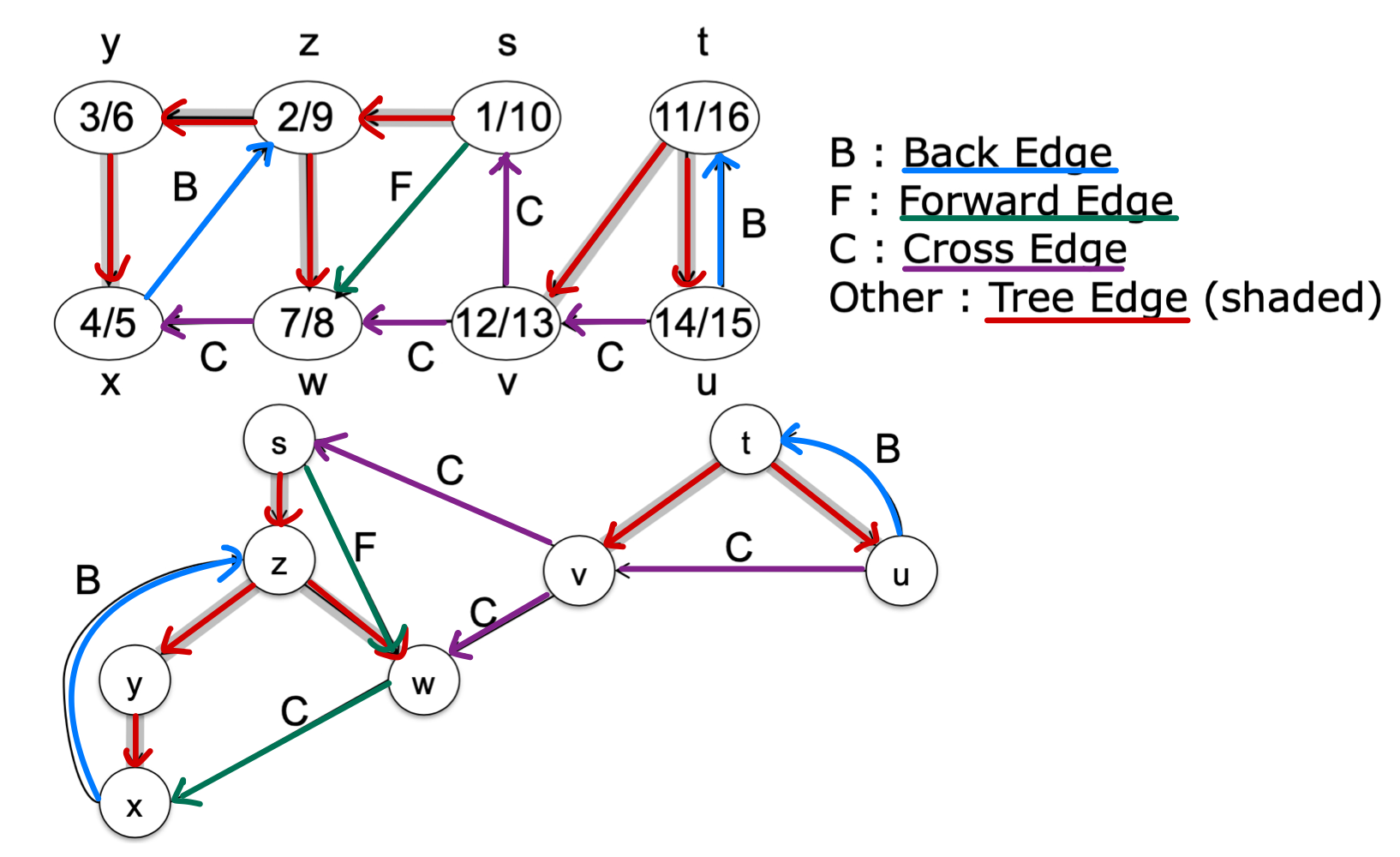
간선 유형을 판별하는 규칙을 정리하면 다음과 같다.
- 회색 노드 → 흰색 노드: Tree edge
- 회색 노드 → 회색 노드: Back edge
- 회색 노드 → 검정 노드: Forward edge 또는 Cross edge
그렇다면 Forward edge와 Cross edge는 어떻게 구분할까? 바로 발견 시간과 완료 시간으로 구분한다.
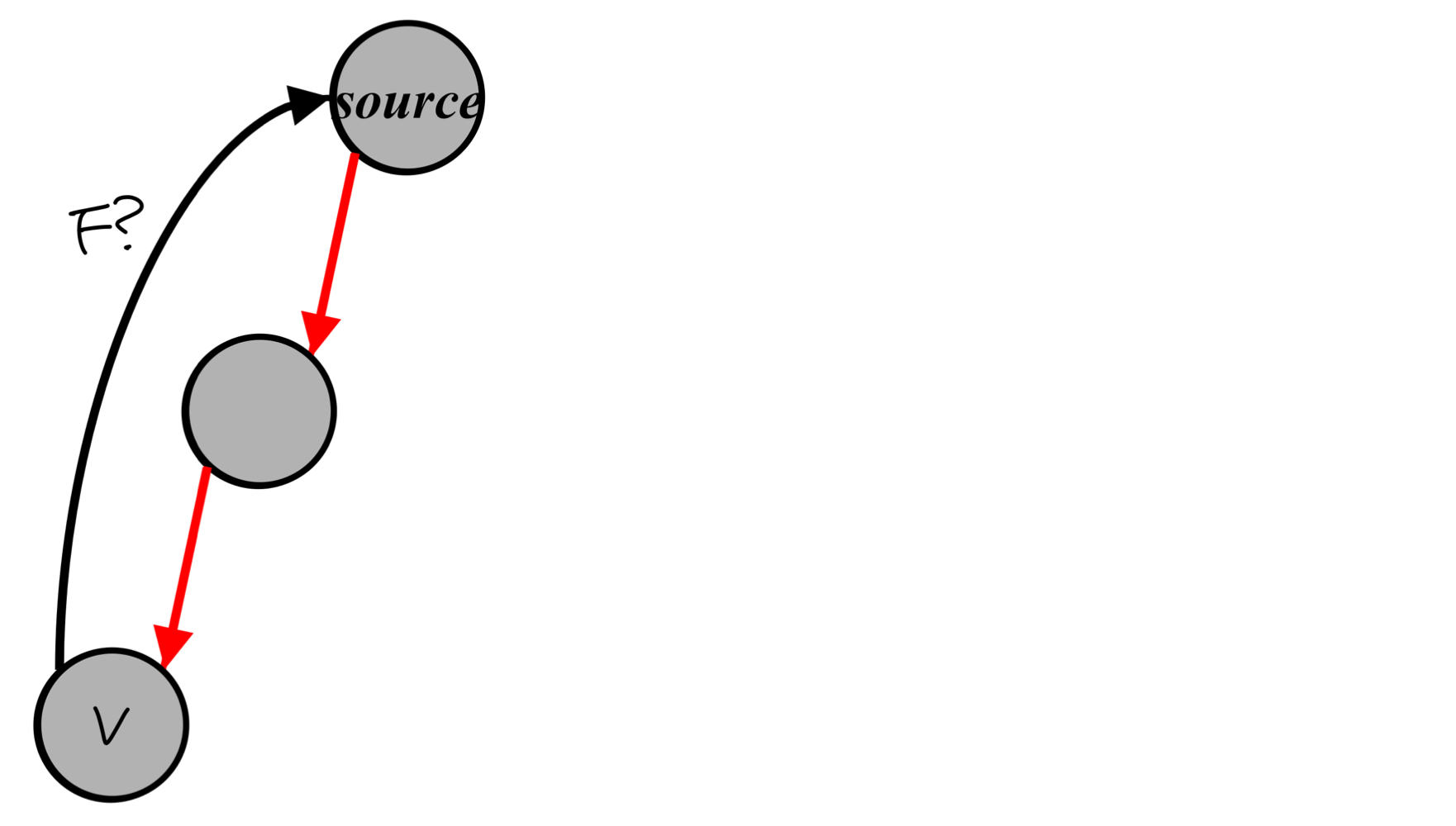
- Forward edge의 경우:
- Cross edge의 경우:

무방향 그래프에서의 DFS
무방향 그래프에서 DFS를 수행하는 방법은 두 가지다.
- 간선이 두 번 처리되어도 상관없다면: 대칭 방향 그래프로 변환하여 간선을 두 번 처리한다.
- 그렇지 않다면: 간선이 처음 만나지는 방향으로만 탐색한다.

무방향 그래프의 간선 유형 (정리 22.10)
무방향 그래프에서 DFS를 수행하면 트리 간선과 역방향 간선만 존재한다. 순방향 간선과 교차 간선은 나타나지 않는다.
귀류법으로 증명:
순방향 간선이 있다고 가정하면, 무방향 그래프에서는 그 간선이 반대 방향에서 보면 사실상 역방향 간선이 된다. 정점 v에서 해당 간선이 확인되지 않았다는 뜻이기 때문이다.
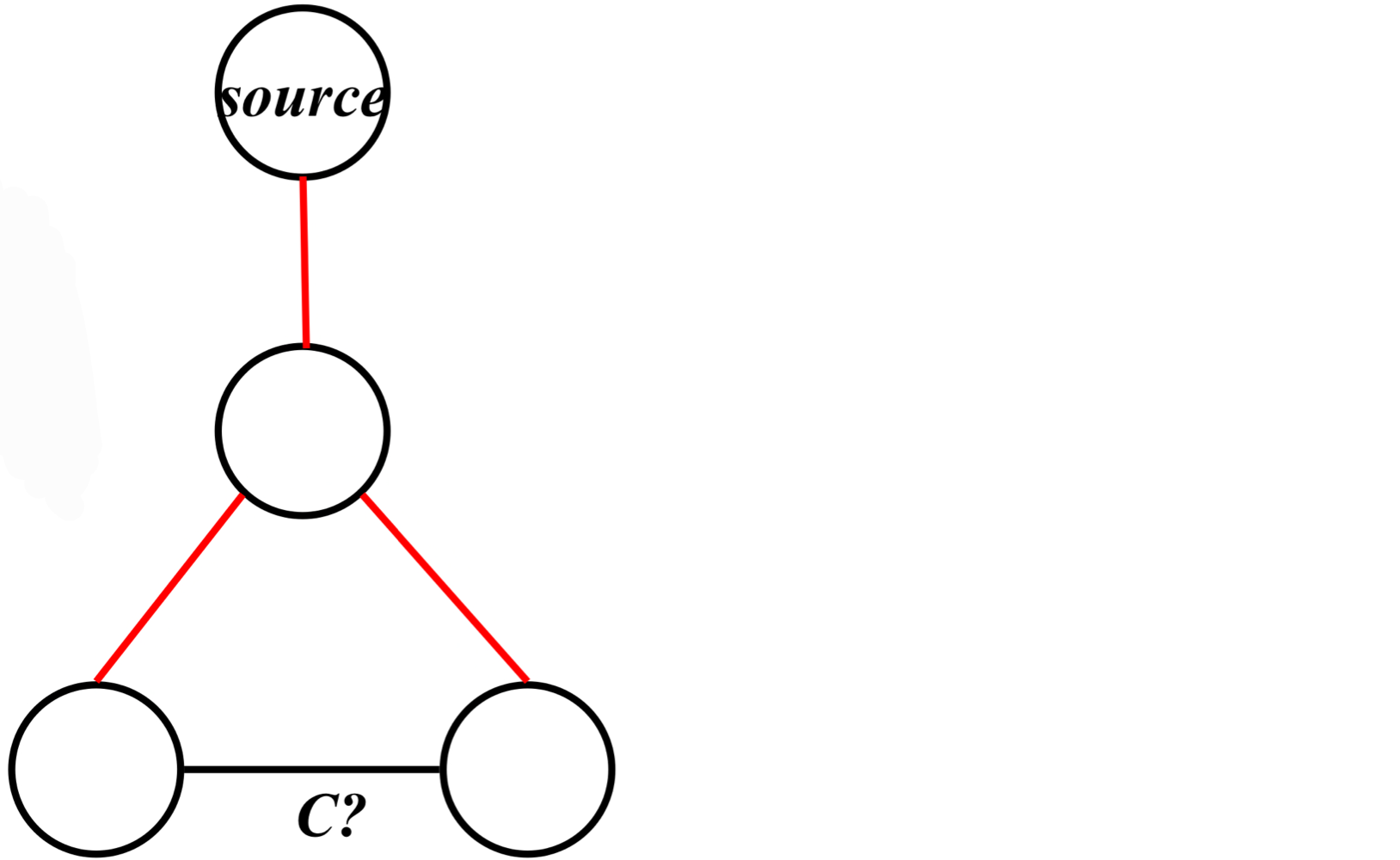
교차 간선이 있다고 가정하면, 해당 간선은 연결하는 두 정점 중 하나에서 먼저 탐색되어야 하므로, 다른 정점이 탐색되기 전에 트리 간선이 된다. 따라서 교차 간선이 될 수 없다.
DFS vs. BFS 비교
| 항목 | DFS | BFS |
|---|---|---|
| 자료구조 | Stack | Queue |
| 처리 기회 | 2번 (Preorder + Postorder) | 1번 |
DFS가 가진 두 번의 처리 기회는 매우 유용하다.
- Preorder: 처음 발견했을 때 처리
- Postorder: 완료 표시할 때 처리. 이 시점에서는 인접 정점에 대한 정보를 모두 갖고 있다.

예를 들어, 이진 트리의 리프 노드 수를 세는 문제는 Postorder 처리의 대표적인 활용 사례다.
DFS의 응용
DFS는 그 자체로도 유용하지만, 다양한 그래프 알고리즘의 기반이 된다. 여기서는 다섯 가지 대표적인 응용을 다룬다.
1) 위상 정렬 (Topological Sort)
위상 정렬은 DAG의 모든 정점을 선형 순서로 나열하되, 간선 (u, v) ∈ G이면 정점 u가 정점 v보다 앞에 오도록 하는 것이다. 사이클이 없기 때문에 이러한 순서가 존재한다.
실생활 예시로는 옷 입는 순서가 있다. 속옷을 입기 전에 바지를 입을 수 없고, 양말을 신기 전에 신발을 신을 수 없다.
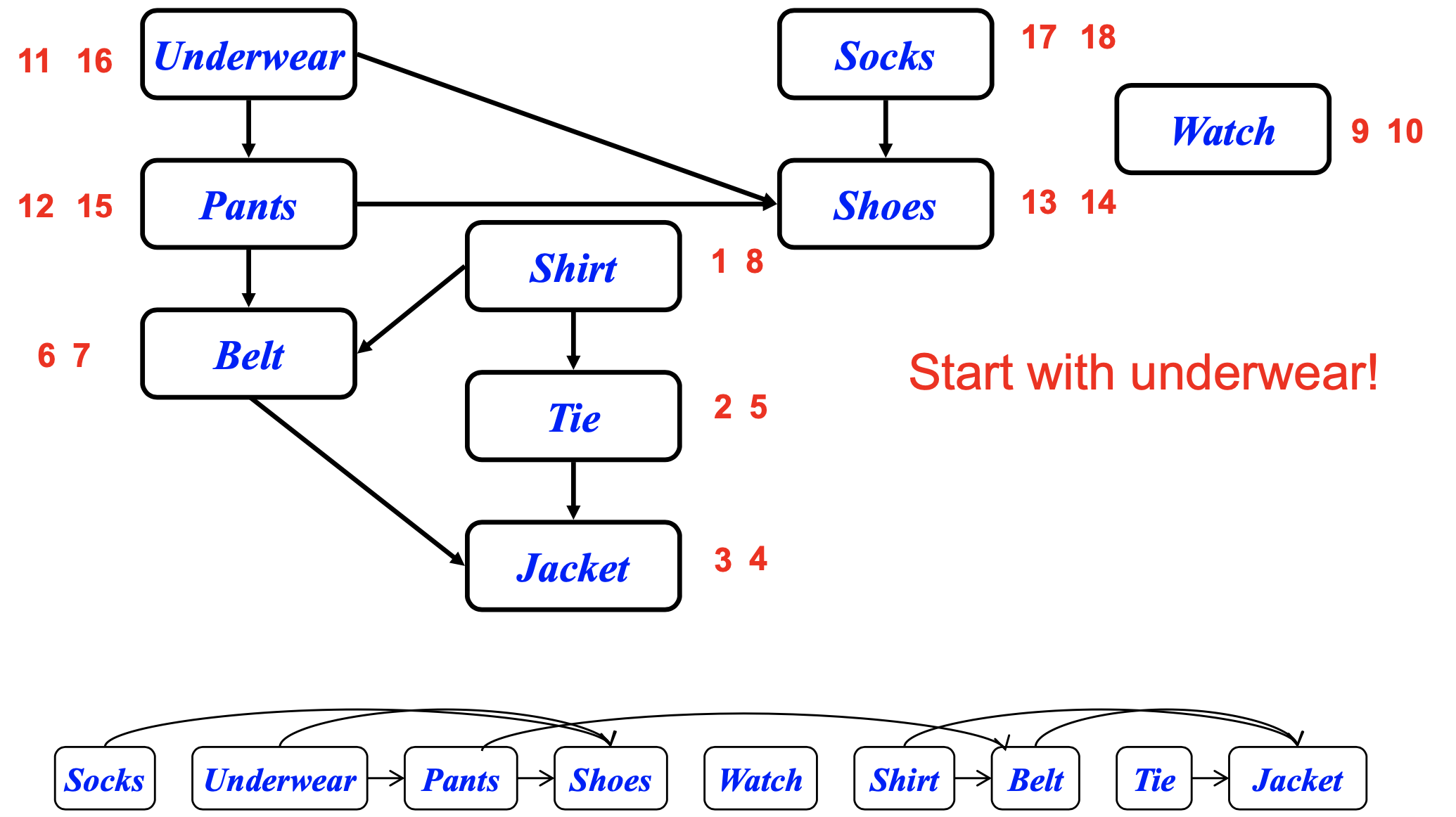
"속옷부터 시작"하여 의존 관계를 따라가면 올바른 순서를 얻을 수 있다.
알고리즘
Topological-Sort():
- DFS를 수행하여 모든 정점 v V에 대해 완료 시간 f[v]를 계산한다 → (V+E)
- 각 정점이 완료될 때마다 연결 리스트의 앞에 삽입한다 (또는 완료 시간의 내림차순으로 출력한다) → (V)
전체 시간 복잡도는 (V+E) 이다.
정확성 증명: 간선 (u, v) ∈ G이면 f[u] > f[v] 임을 보이면 된다.
간선 (u, v)를 탐색할 때 u는 회색이다.
- v가 회색이면 → (u, v)는 역방향 간선이다. 그런데 DAG에는 사이클이 없으므로 모순이다.
- v가 흰색이면 → v는 u의 자손이 된다. v가 완료된 후에야 u가 완료되므로 f[v] < f[u] 이다.
- v가 검정이면 → v는 이미 완료되었으므로 f[v] < f[u] 이다.
2) 연결 요소 (Connected Component) -- 무방향 그래프
무방향 그래프의 연결 요소를 찾으려면 먼저 그래프를 대칭 방향 그래프로 변환한다.
DFS 함수 (BFS로도 가능):
- 미발견 정점을 찾아 해당 정점에서 DFS-VISIT을 시작한다.
- 미발견 정점 v의 레이블 id (label(v)) 를 DFS-VISIT에 전달한다.
DFS-VISIT 함수:
- 현재 정점의 레이블을 label(v) 로 결정하고, 인접한 흰색 정점에 동일한 레이블을 전달한다.
- 각 연결 요소별로 별도의 연결 리스트를 만든다.

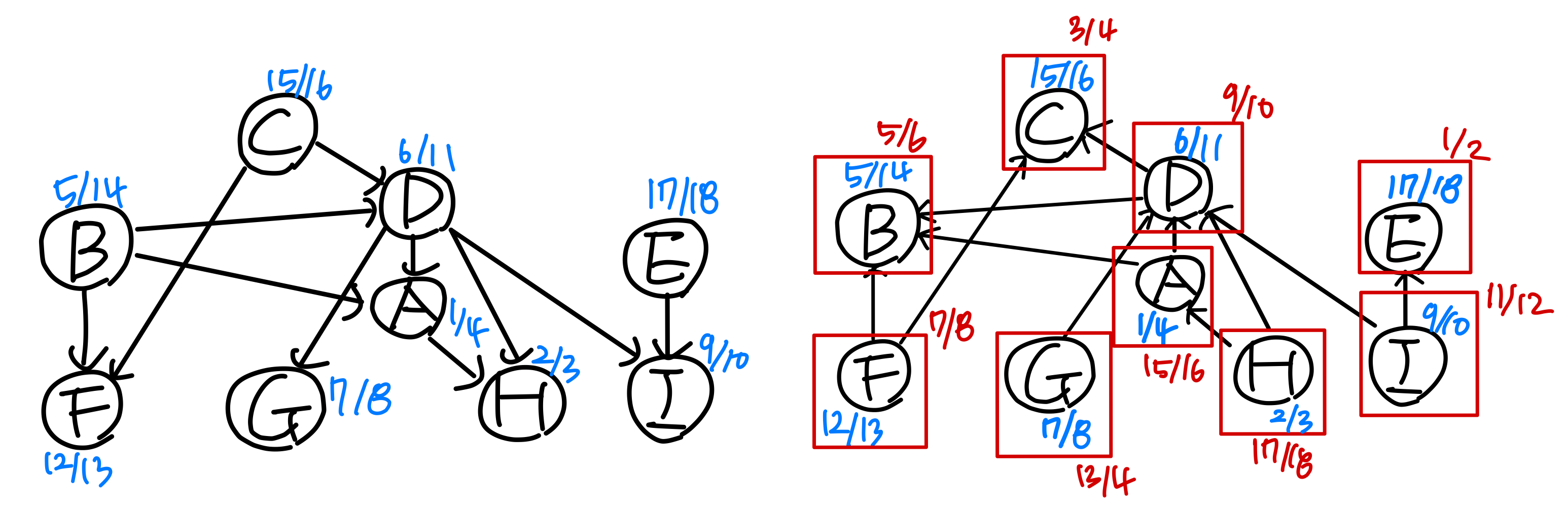
3) 강연결 요소 (Strongly Connected Component) -- 방향 그래프
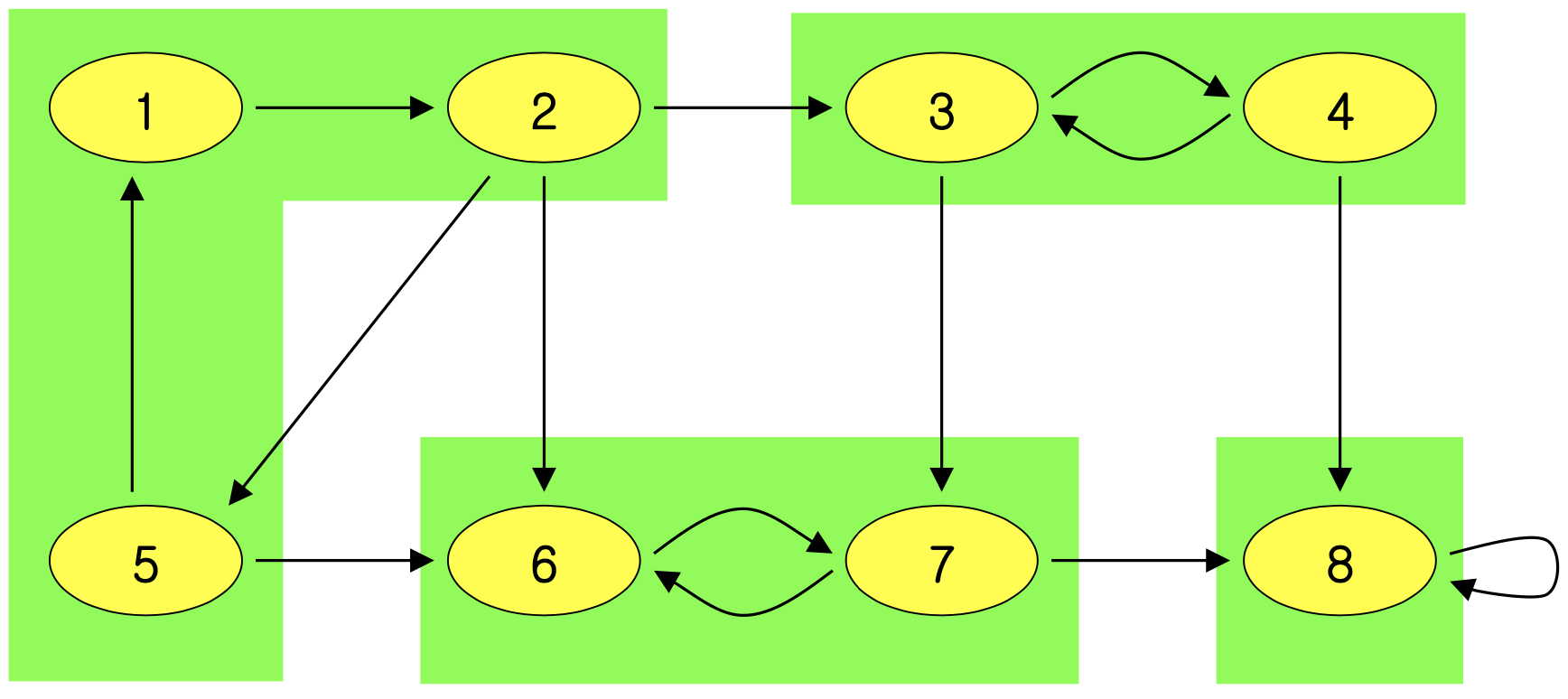
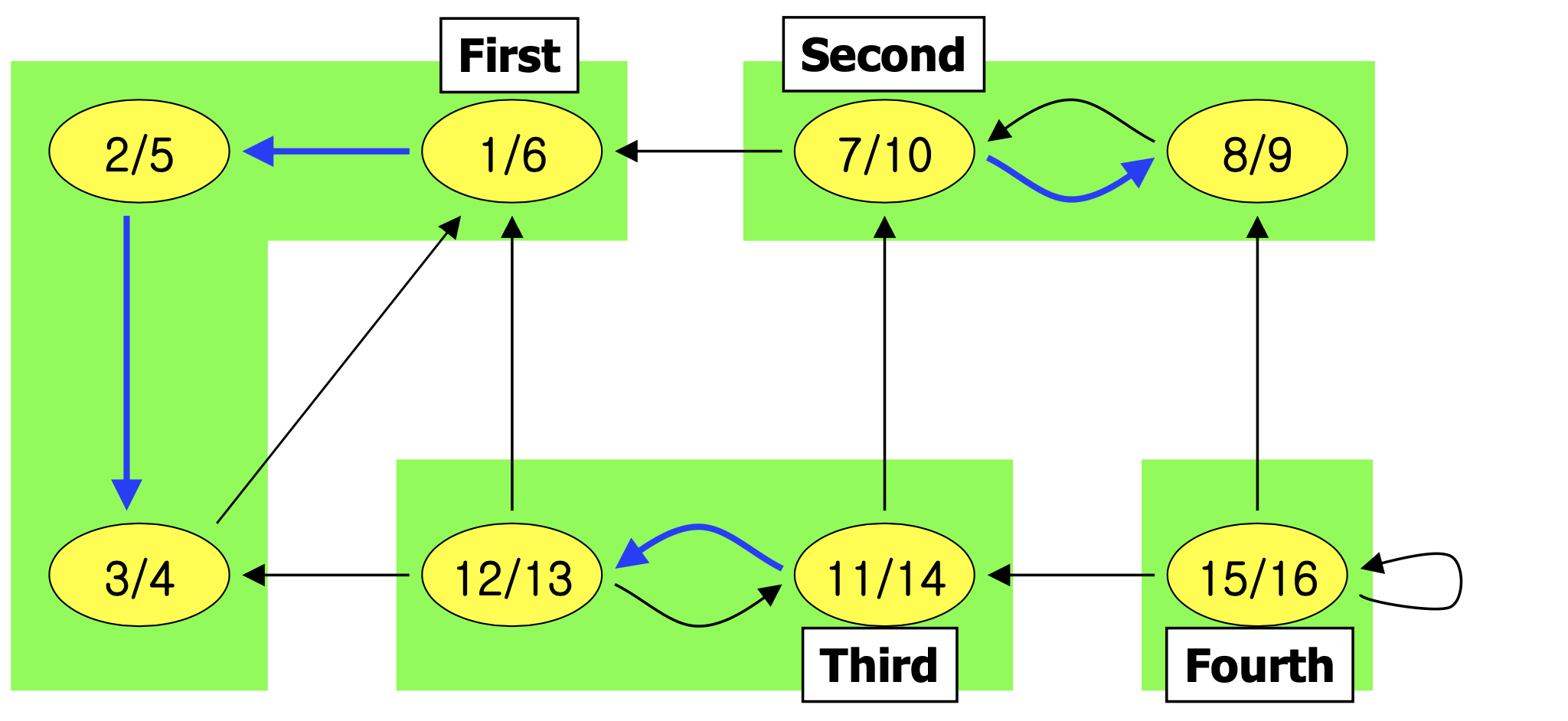
강연결 요소(SCC) 는 방향 그래프에서 극대 정점 집합 C ⊆ V로, C의 모든 정점 쌍 u, v에 대해 u → v이고 v → u인 경로가 존재한다. 쉽게 말해, 모든 정점에서 다른 모든 정점에 도달 가능한 극대 부분 그래프다.
아래 그림에서 초록색 영역이 SCC이며, 총 4개의 SCC가 있다.
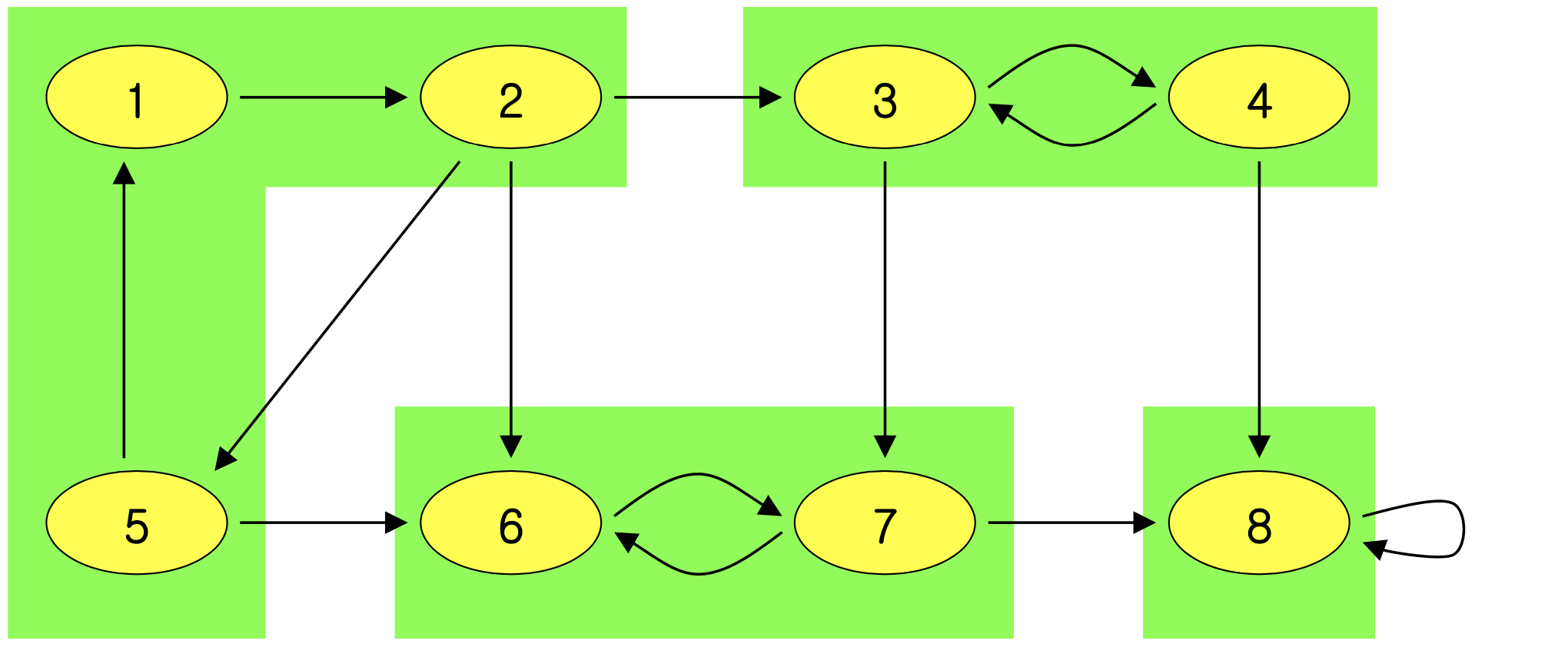
SCC의 성질
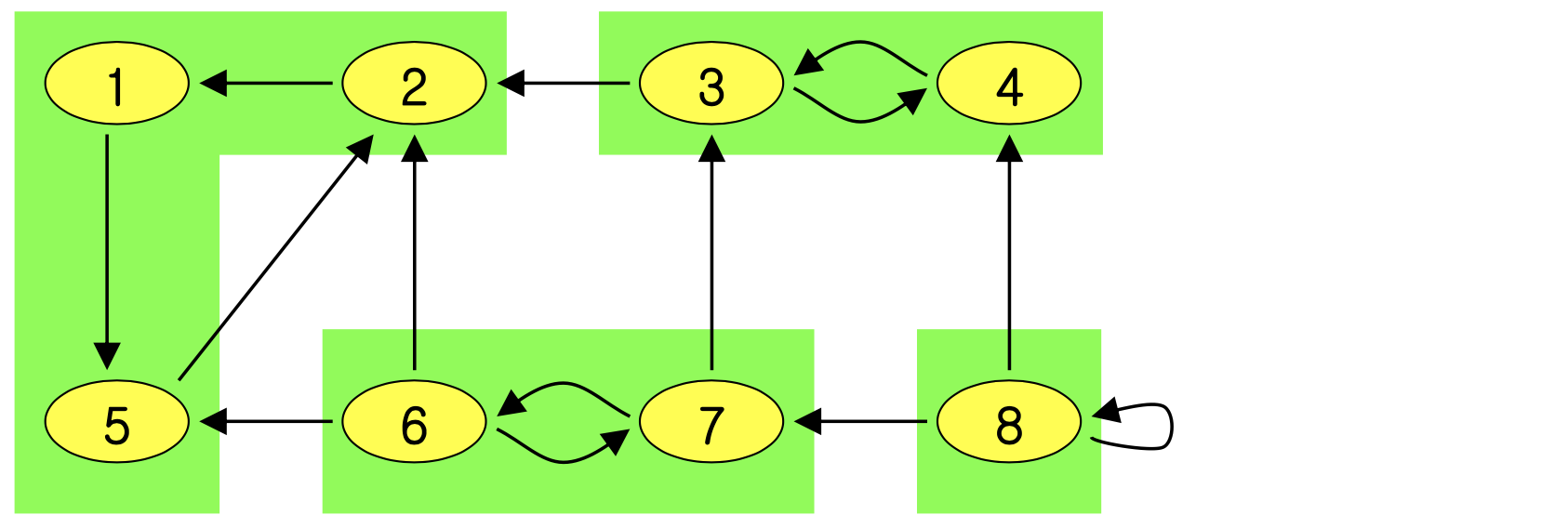
그래프 G와 그 전치 그래프 G는 정확히 같은 강연결 요소를 가진다.
또한 요소 그래프(Component Graph) G는 DAG다. 만약 사이클이 있다면 사이클을 구성하는 모든 요소가 하나의 SCC로 합쳐져야 하기 때문이다.
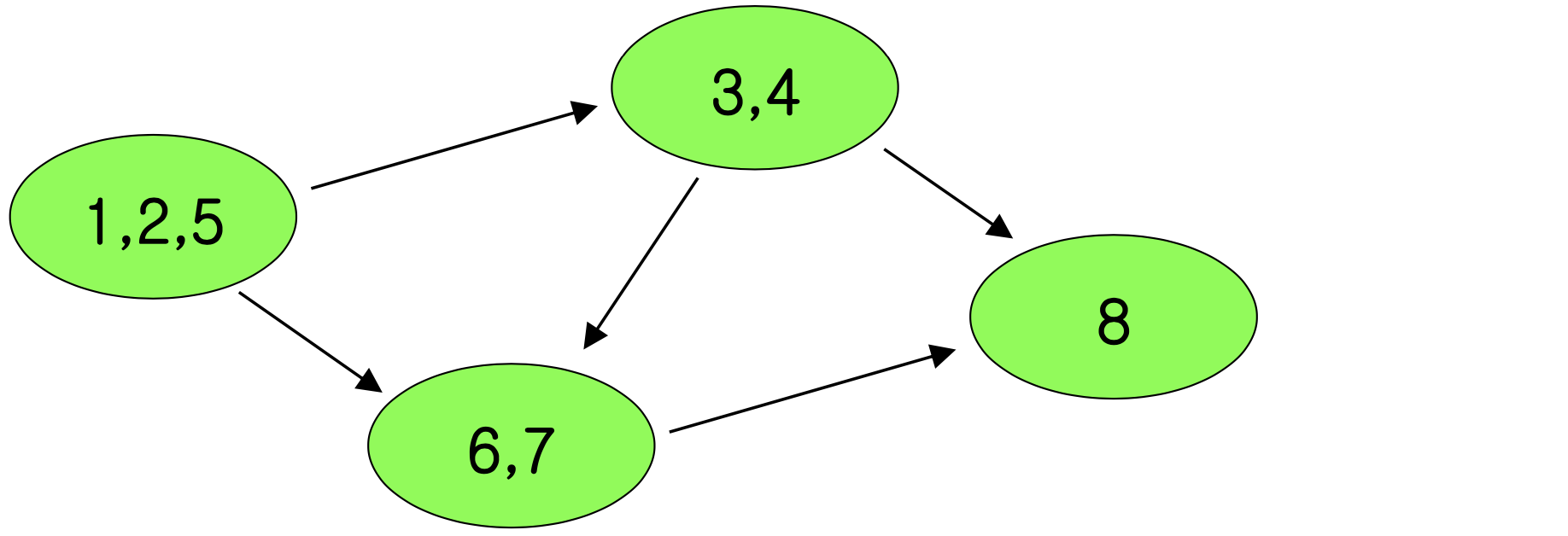
알고리즘
STRONGLY-CONNECTED-COMPONENTS(G):
- DFS(G) 를 수행하여 각 정점 u의 완료 시간 f[u]를 계산한다 → (V+E)
- G (전치 그래프)를 계산한다 → 행렬이면 (V), 리스트면 (V+E)
- DFS(G) 를 수행하되, 메인 루프에서 정점을 f[u]의 내림차순으로 처리한다 (알파벳 순서가 아님) → (V+E)
- 3단계에서 형성된 깊이 우선 포레스트의 각 트리의 정점들을 하나의 강연결 요소로 출력한다 → (1)
전체 수행 시간은 (V+E) 이다.
G의 SCC 그래프 vs. 전치 그래프
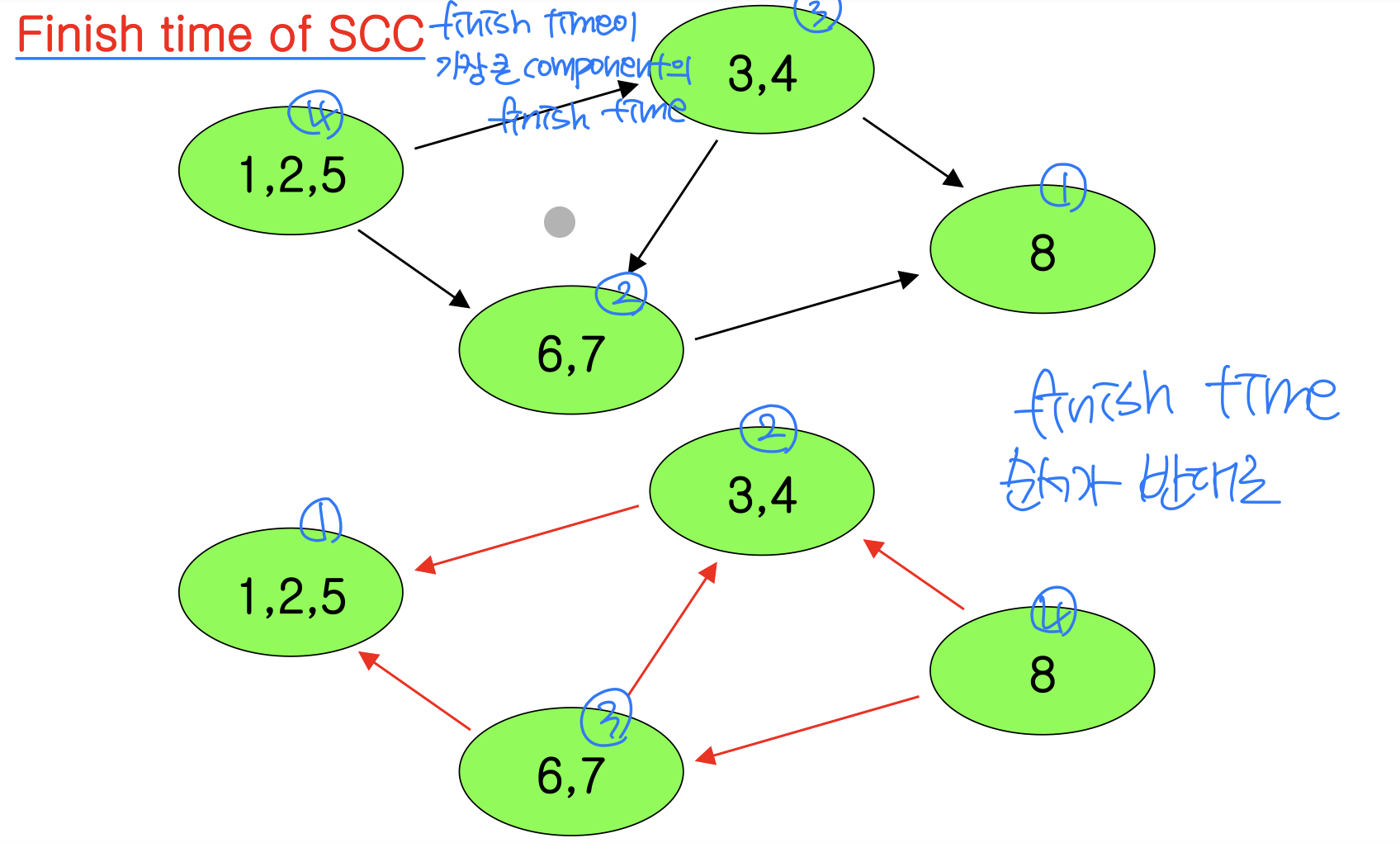
예제
Step 1: DFS(G)를 수행한다.
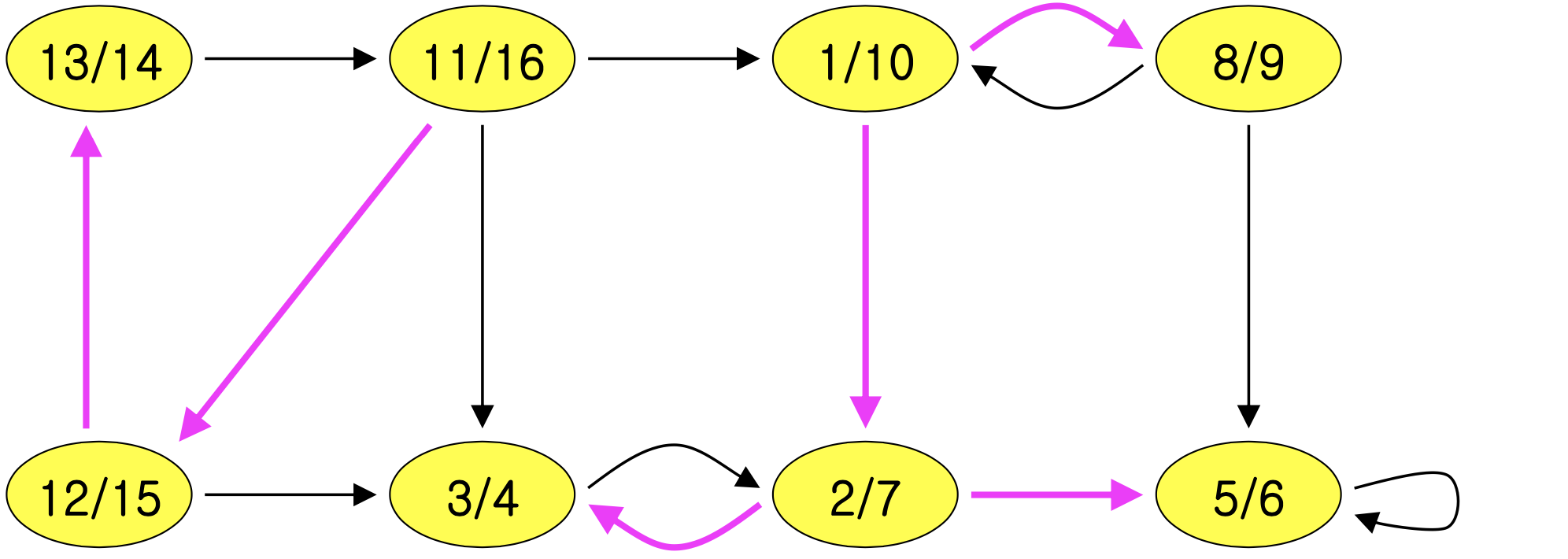
Step 2: G의 전치 그래프를 계산한다.
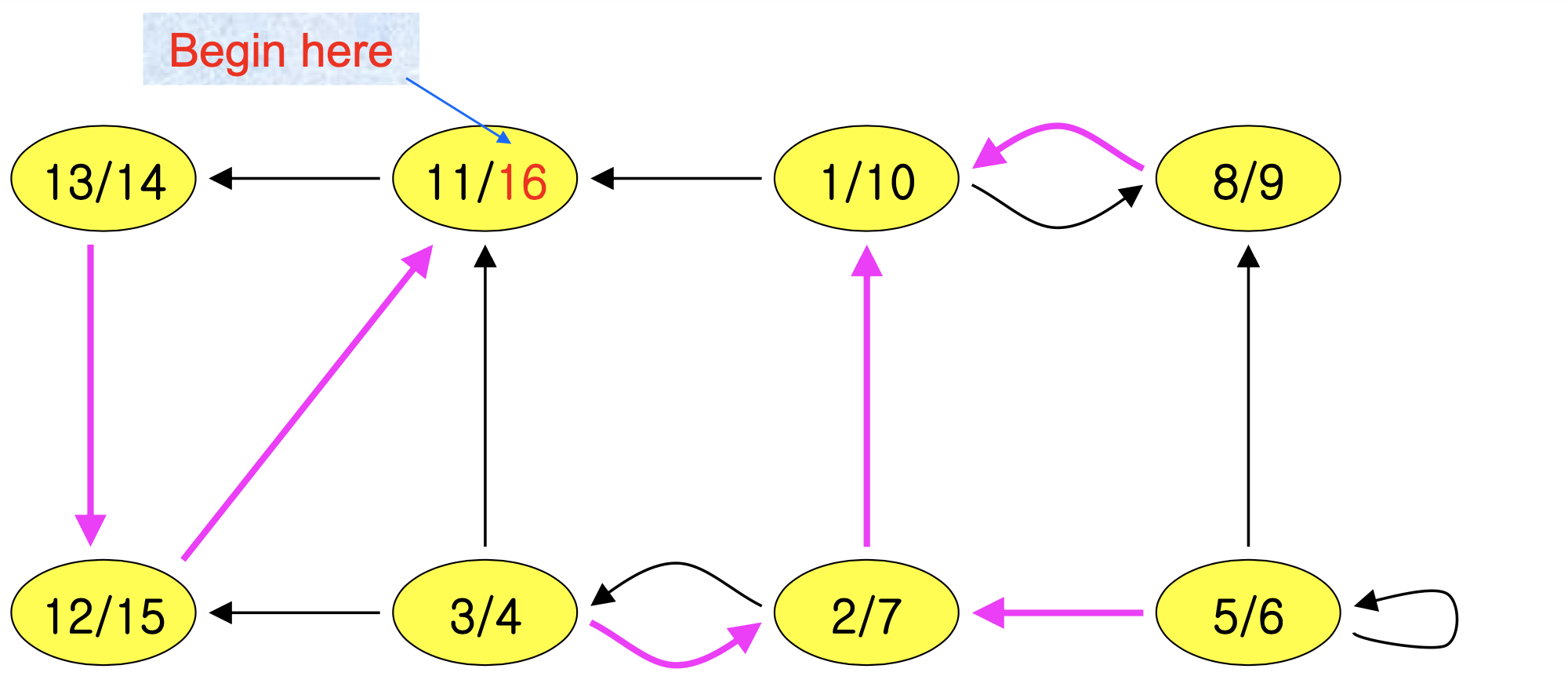
Step 3: DFS(G)를 f[u]의 내림차순으로 수행한다.
보조 정리와 따름 정리
Lemma 22.13: C와 C'가 방향 그래프 G = (V, E)에서 서로 다른 SCC이고, u, v ∈ C, u', v' ∈ C'이며, G에서 u → u' 경로가 존재한다면, G에서 v' → v 경로는 존재할 수 없다.
Lemma 22.14: C와 C'가 서로 다른 SCC이고, 간선 (u, v) ∈ E에서 u ∈ C, v ∈ C'이면, f(C) > f(C') 이다.
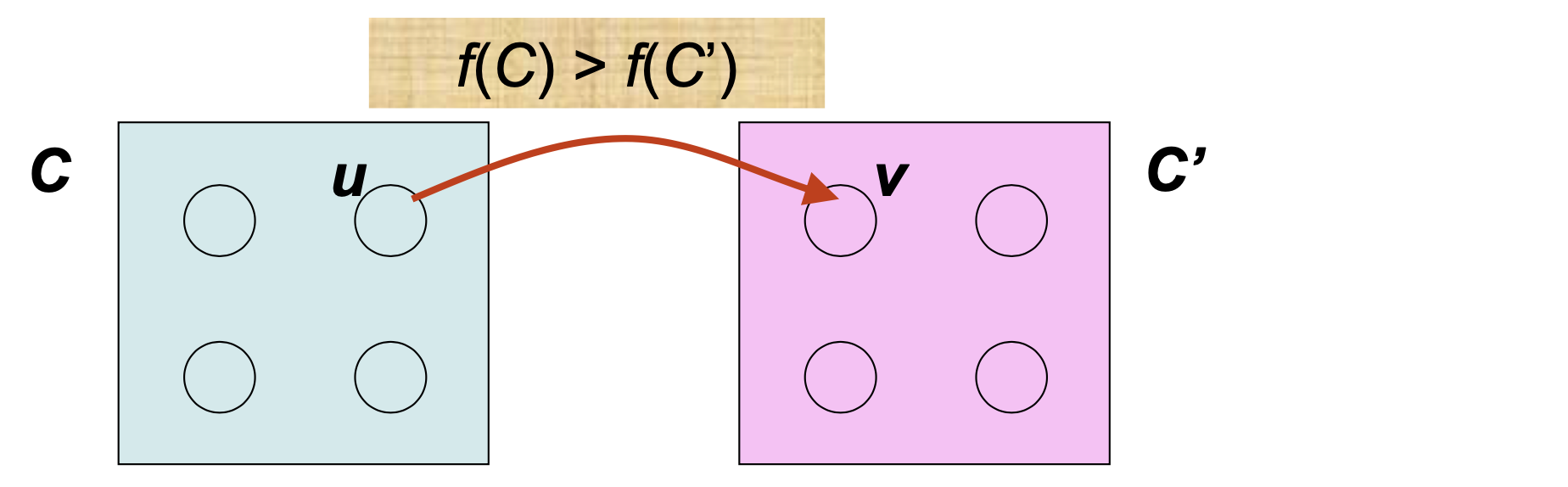
여기서 f(U) = max{f[u]}로, U에 속한 정점 중 가장 큰 완료 시간을 의미한다.
Corollary 22.15: C와 C'가 서로 다른 SCC이고, 간선 (v, u) ∈ E에서 u ∈ C, v ∈ C'이면, f(C) > f(C') 이다.
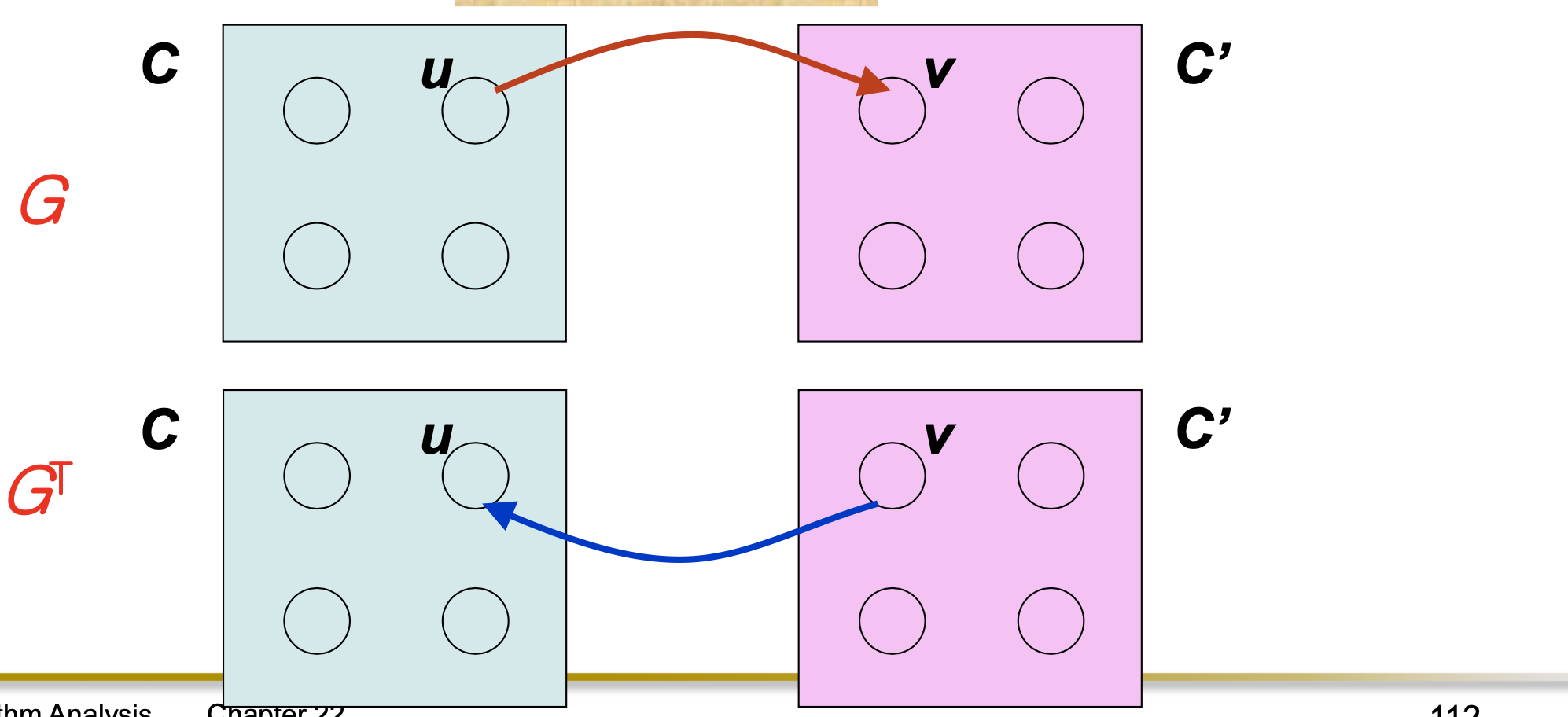
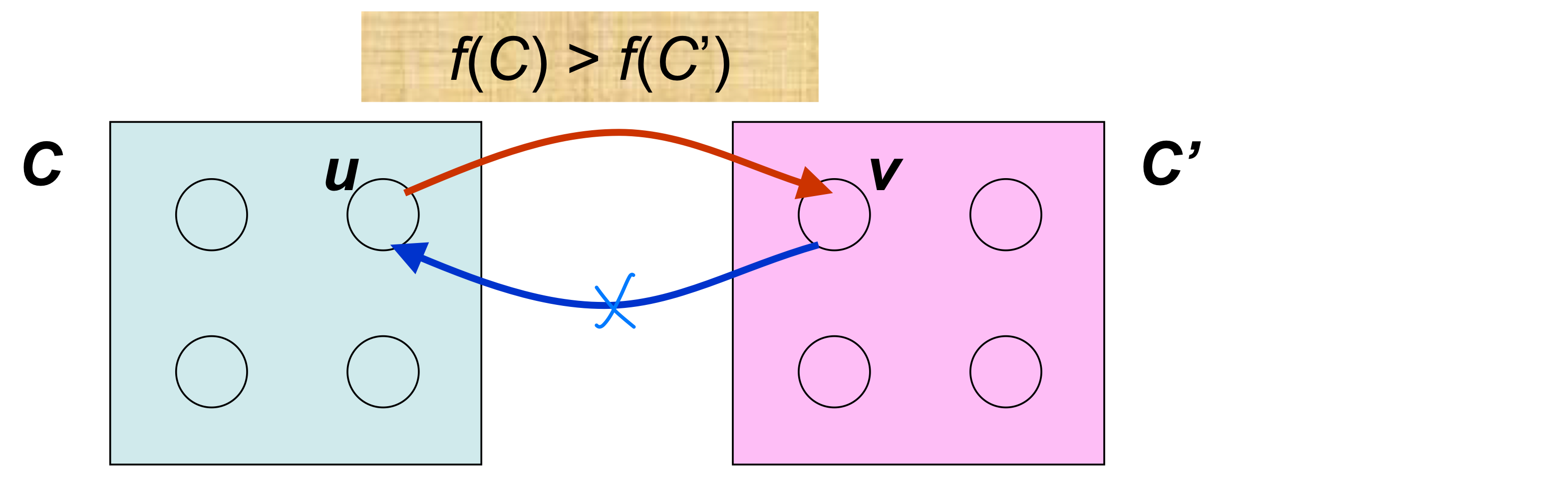
Corollary: C와 C'가 서로 다른 SCC이고 f(C) > f(C')이면, G에서 C에서 C'로의 간선은 존재할 수 없다.
정확성 증명 (Theorem 22.16)
STRONGLY-CONNECTED-COMPONENTS(G)가 올바르게 SCC를 계산함을 증명한다.
두 번째 DFS를 G에서 수행할 때, f(C)가 최대인 SCC C에서 시작한다. C의 어떤 정점 x에서 출발하는 두 번째 DFS는 C의 모든 정점을 방문한다. 따름 정리에 의해 f(C) > f(C')인 모든 C' ≠ C에 대해 G에서 C에서 C'로의 간선이 없으므로, DFS는 C의 정점만 방문하게 된다.
다음 루트로 선택되는 SCC C'는 C를 제외한 나머지 중 f(C')가 최대인 것이다. DFS는 C'의 모든 정점을 방문하지만, C'에서 나가는 간선은 이미 방문한 C로만 향한다.
매번 두 번째 DFS의 루트를 선택할 때, 도달 가능한 것은 다음 두 가지뿐이다.
- 자신의 SCC에 속한 정점 -- 트리 간선으로 연결된다
- 이미 방문한 SCC의 정점 -- 트리 간선이 생기지 않는다
결과적으로 (G)의 정점을 위상 정렬의 역순으로 방문하게 된다.
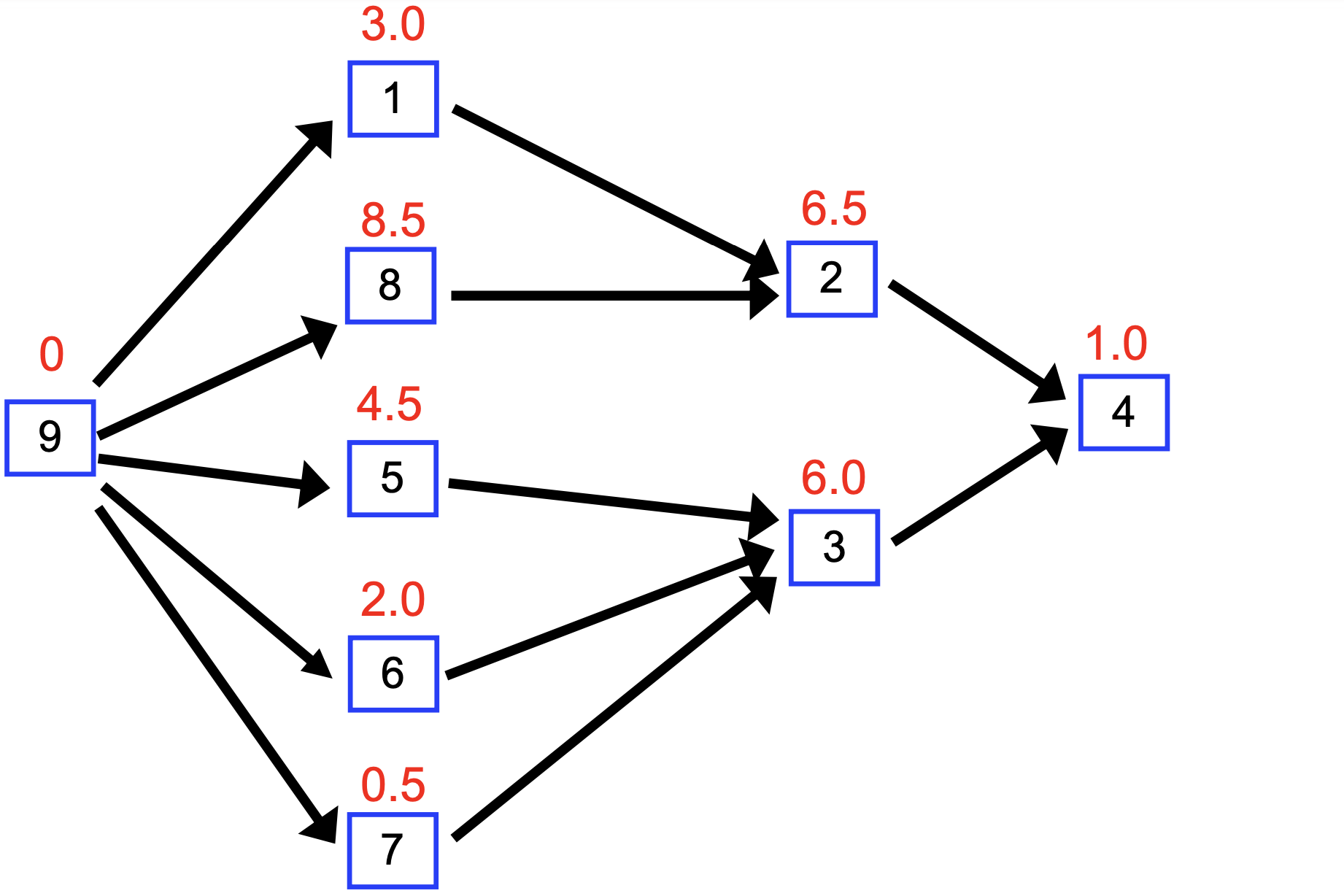
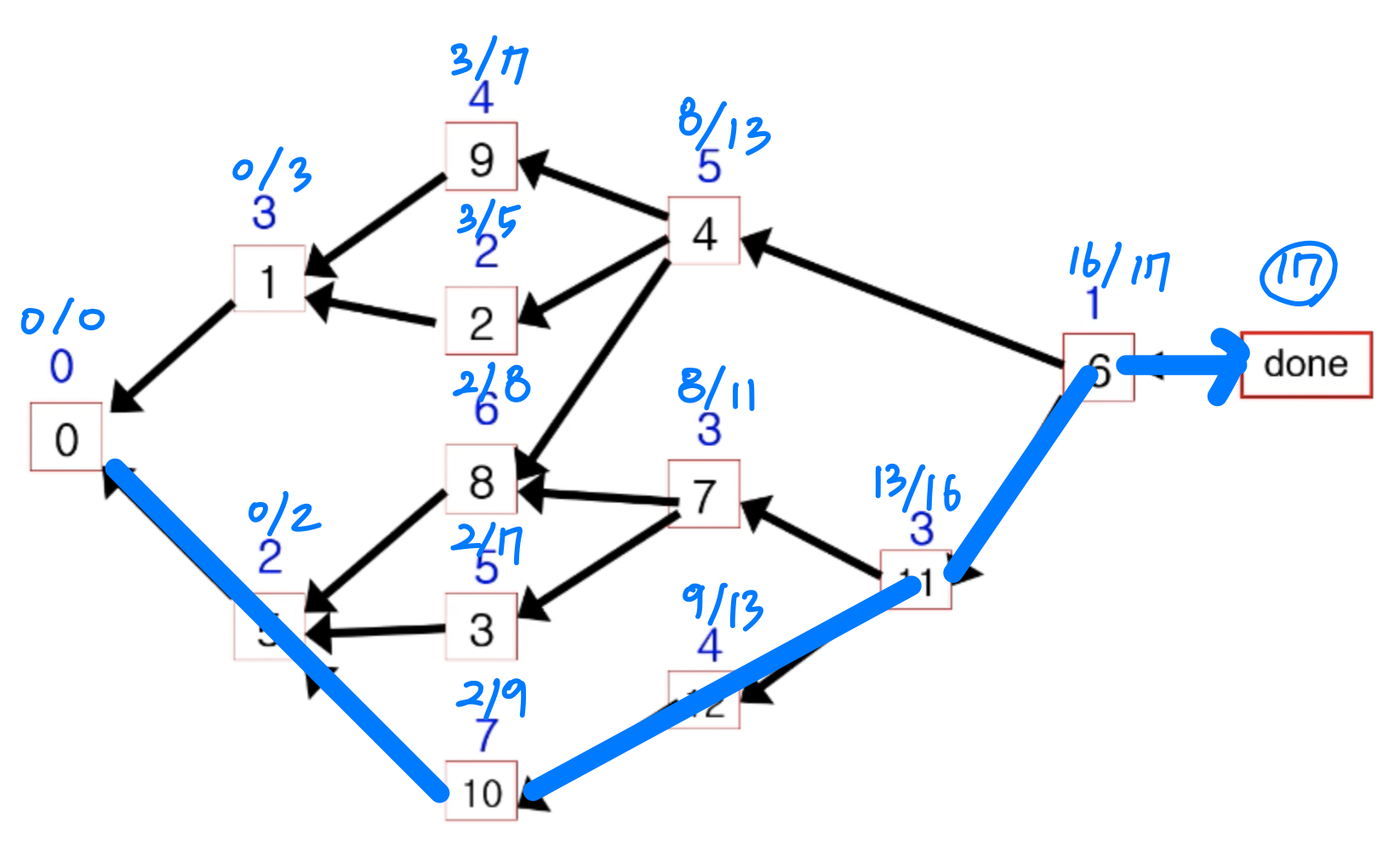
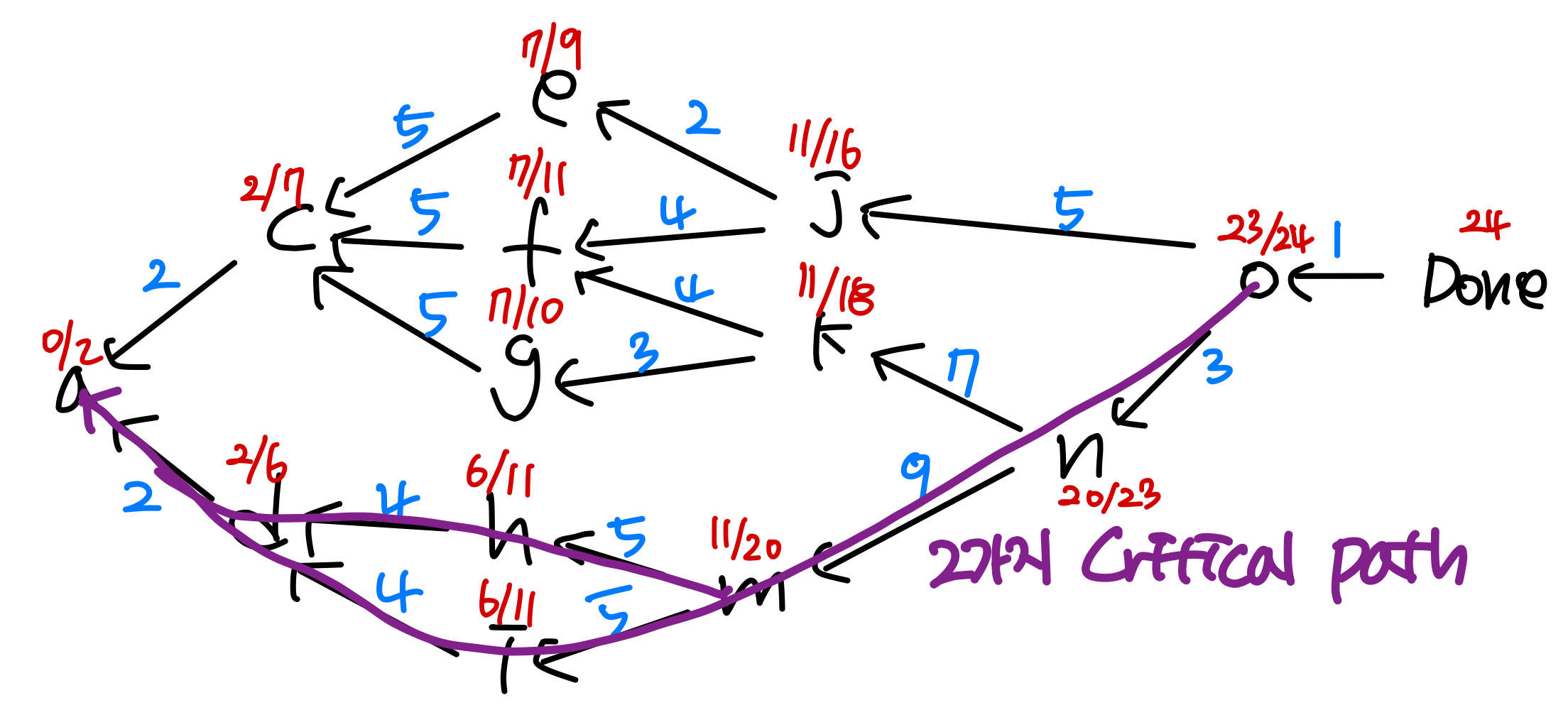
4) 임계 경로 (Critical Path)
DAG가 일련의 작업(task) 간의 의존 관계를 나타낸다고 하자. 각 작업에는 소요 시간이 있고, 여러 작업을 동시에 수행할 수 있다.
시작 노드에서 끝 노드까지 여러 경로가 존재할 수 있으며, 각 경로는 일정한 총 소요 시간을 요구한다. 이 중 가장 긴 경로가 임계 경로(Critical Path) 다. 프로젝트 전체 소요 시간은 임계 경로의 길이에 의해 결정된다.
임계 경로도 DFS를 변형하여 (V+E) 에 구할 수 있다.
각 노드에 대해 다음 두 값을 기록한다.
- est: 가장 이른 시작 시간 (earliest start time)
- eft: 가장 이른 완료 시간 (earliest finish time), eft = est + duration
est의 계산 방법은 의존 관계에 따라 달라진다.
- 의존성이 없으면: 바로 시작할 수 있다. est = 0
- 하나의 작업에 의존하면: est = 그 작업의 eft
- 여러 작업에 의존하면: est = max(의존 작업들의 eft)
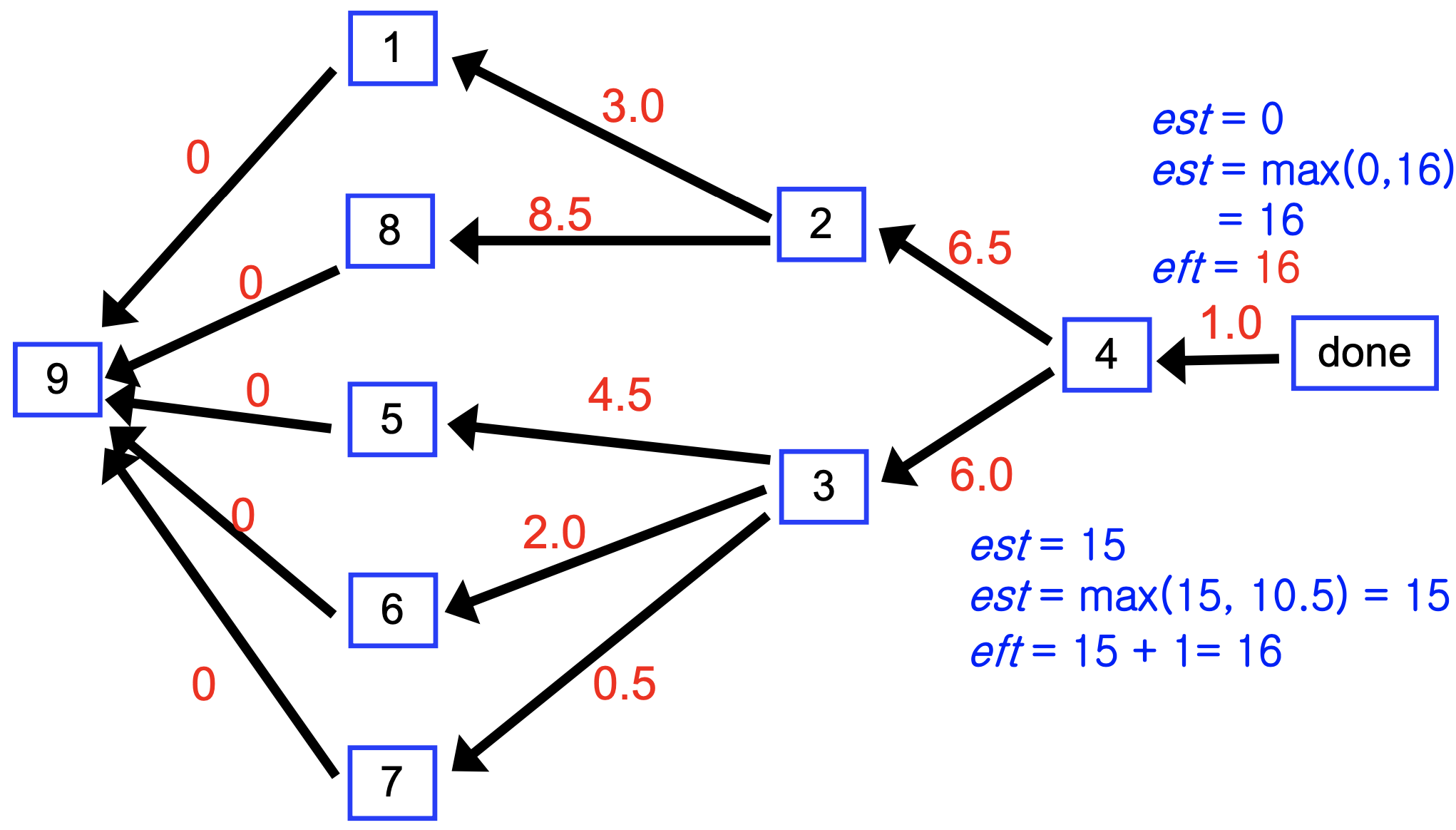
Modified DAG
프로젝트에 done이라는 특수 작업을 추가한다. duration은 0이고, 작업 번호는 n+1이다. 다른 작업의 의존성이 되지 않는 모든 작업(잠재적 최종 작업)은 done의 의존성으로 설정된다.
프로젝트 DAG에서 v가 w에 의존할 때 가중 간선 vw를 추가하되, 방향을 역전시킨다. 간선의 가중치는 w의 소요 시간이다.
알고리즘
프로젝트 DAG에서 DFS를 수행한다. 간선 vw에서 백트래킹할 때:
if eft[w] > est[v]
est[v] = eft[w]
Crit_Dep[v] = w // w에서 오는 경로가 critical pathPostorder 처리 시점에 eft[v] = est[v] + duration[v] 를 계산한다.
예제
연습 문제
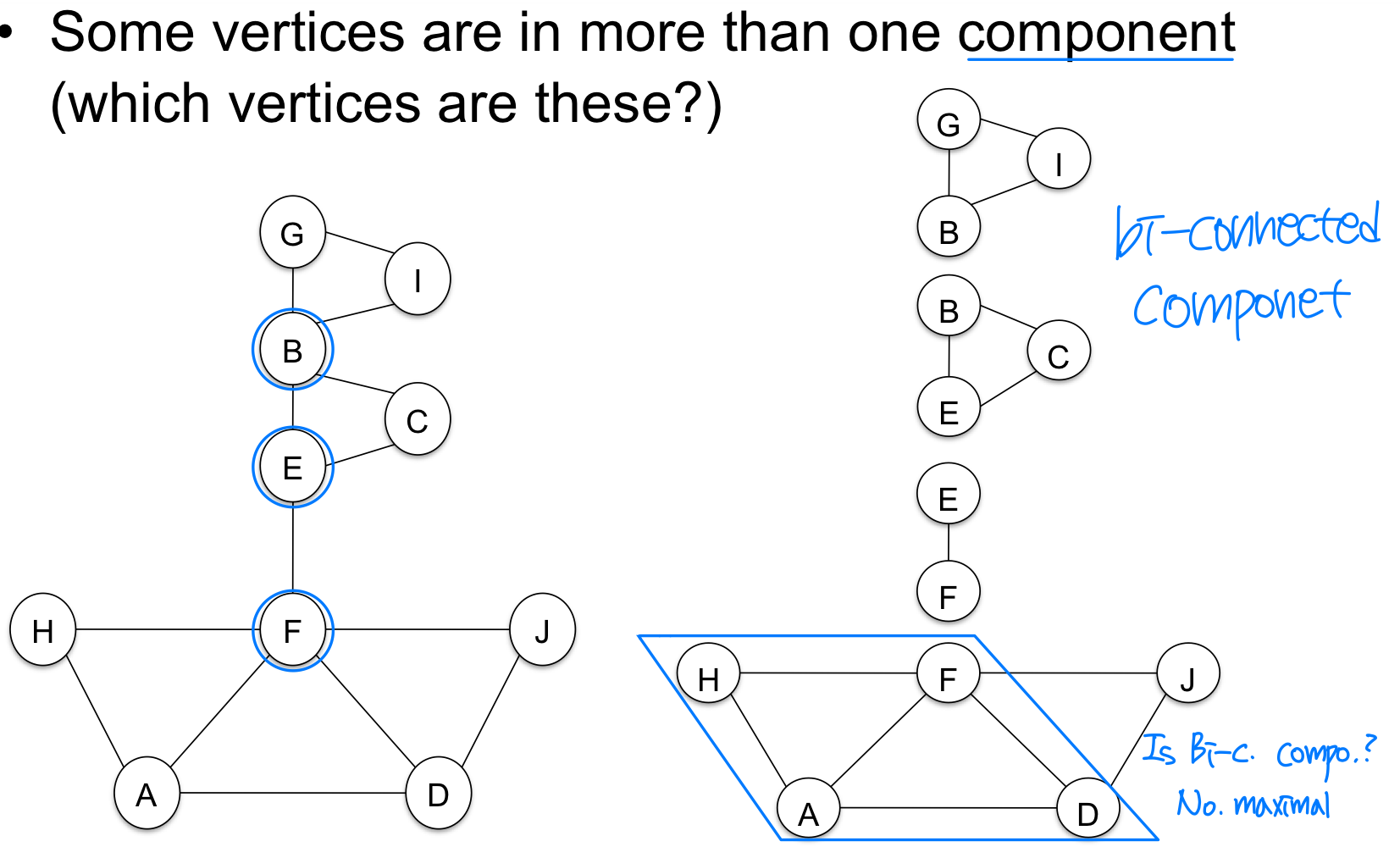
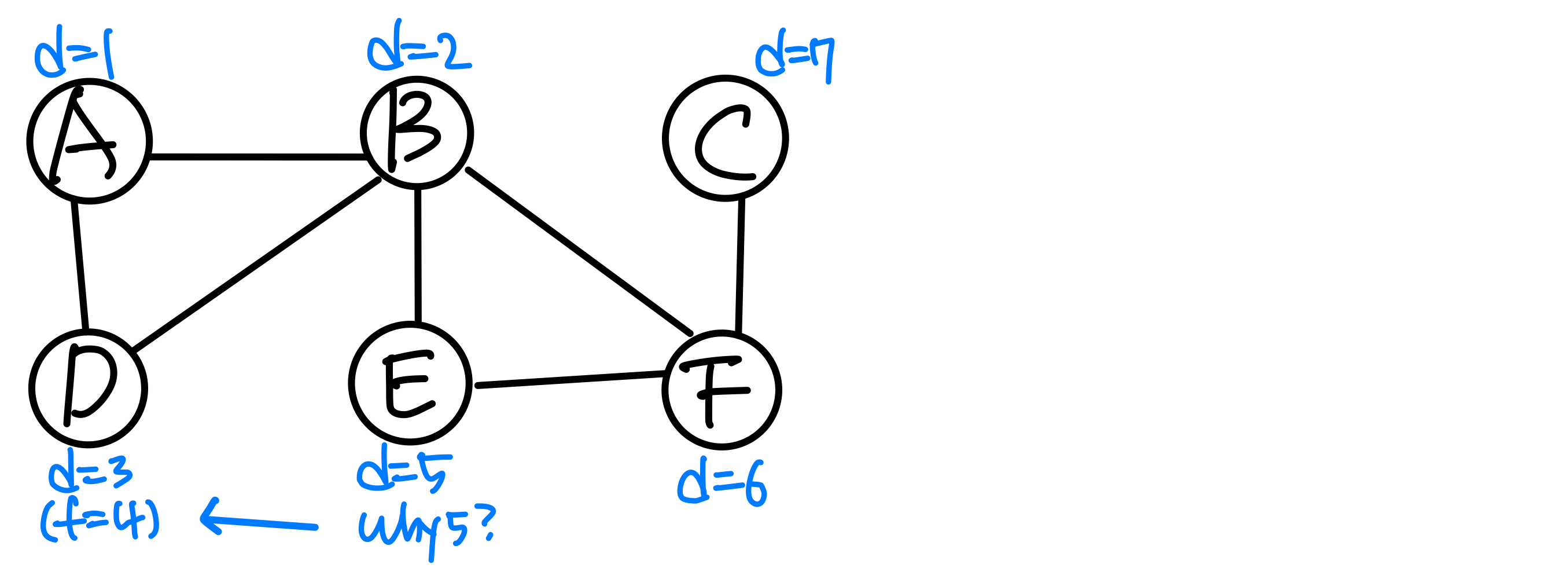
5) 이중 연결 요소와 단절점 (Bi-connected Components & Articulation Point)
문제: 연결 그래프에서 어떤 하나의 정점(과 그에 연결된 간선)을 제거했을 때, 나머지 부분 그래프가 여전히 연결 상태를 유지하는가?
이중 연결 그래프(Biconnected Graph): 어떤 정점 하나를 제거하더라도 여전히 연결된 그래프다.
이중 연결 요소(Biconnected Component): 무방향 그래프의 극대 이중 연결 부분 그래프다. 더 큰 이중 연결 부분 그래프에 포함되지 않는다.
단절점(Articulation Point): 정점 v가 단절점이란, v와 구별되는 두 정점 w, x 사이의 모든 경로에 v가 포함된다는 의미다. v를 제거하면 w와 x가 단절된다.
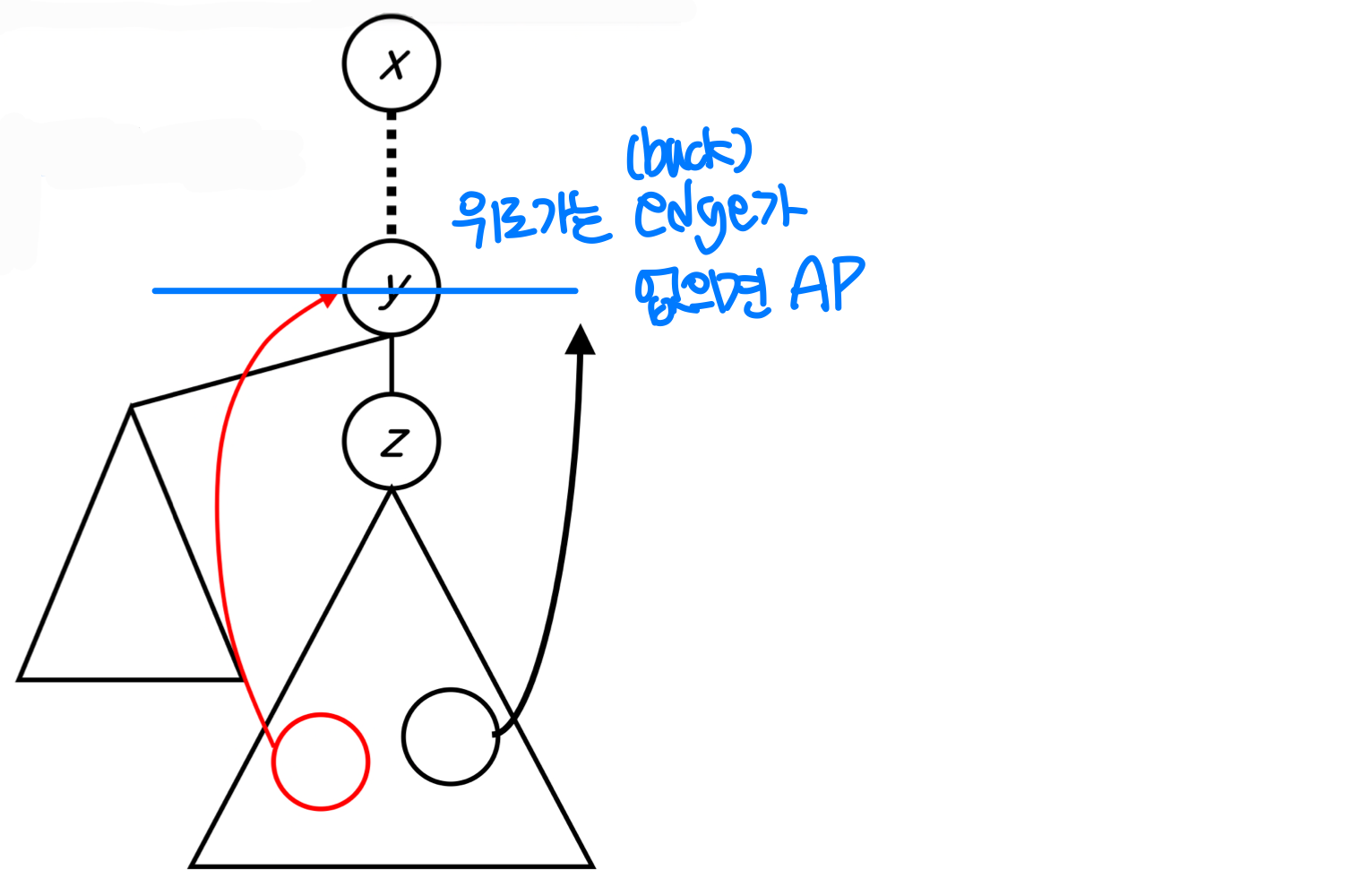
단절점 찾기
무방향 그래프에서의 DFS에서 중요한 사실 세 가지가 있다.
- 모든 간선은 트리 간선 또는 역방향 간선이다.
- 리프 노드는 단절점이 될 수 없다.
- z에서 y로 백트래킹할 때, z를 루트로 하는 서브트리의 어떤 정점에서도 y의 조상으로의 역방향 간선이 없다면, y는 단절점이다.
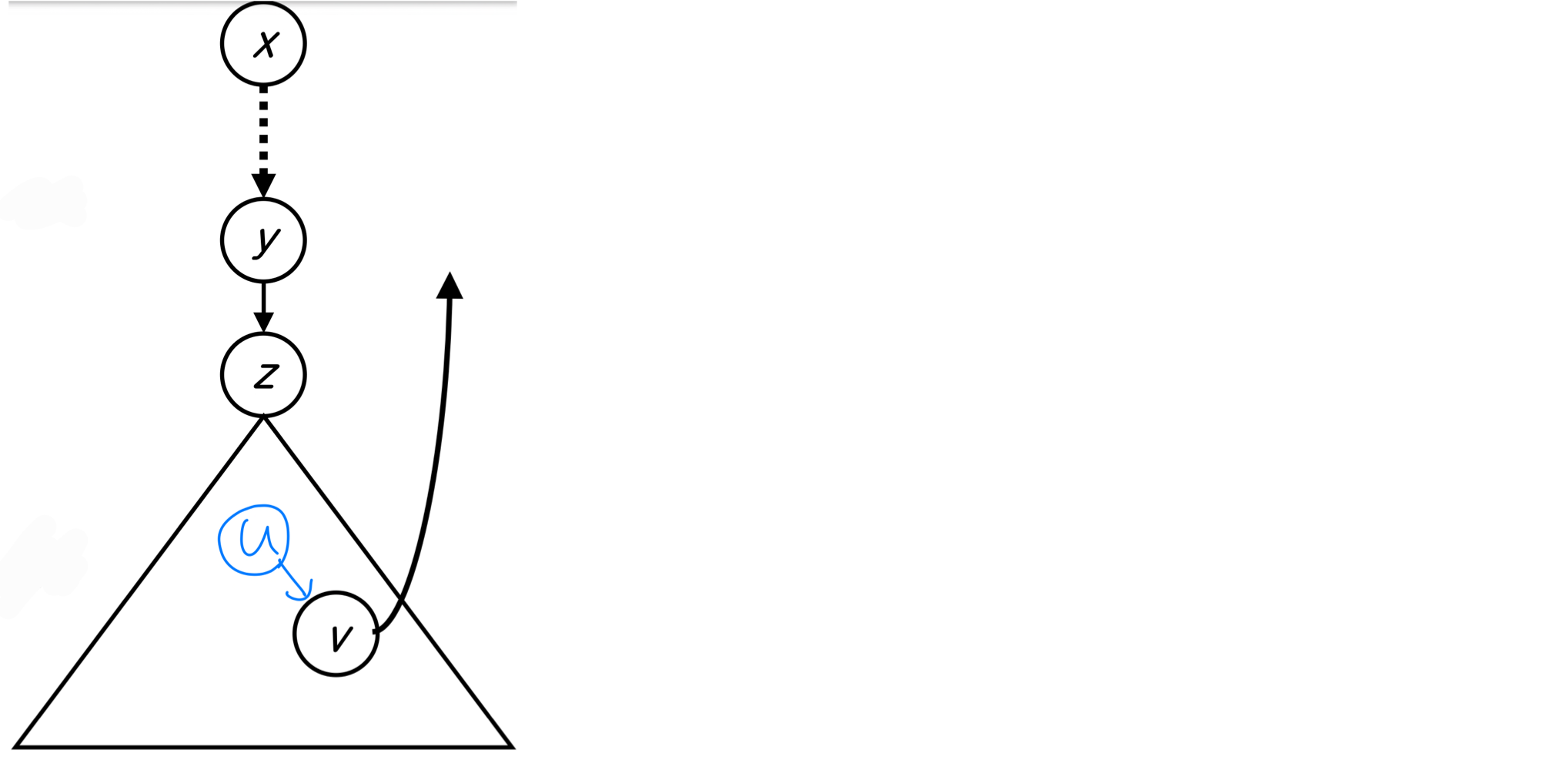
그래프에 DFS를 수행하면서 back 값을 저장한다.
모든 정점 v에 대해 역방향 간선 vw를 확인한다.
- a. back은 d[v] 로 초기화한다.
- b. 역방향 간선 vw를 만나면: back = min(back, d(w))
- c. v에서 u로 백트래킹할 때: back = min(back, back)
z에서 y로 백트래킹할 때, z 이하의 모든 정점에 대해 back ≥ d(y)이면 y는 단절점이다. back < d(y)이면 y는 단절점이 아니다.
예제
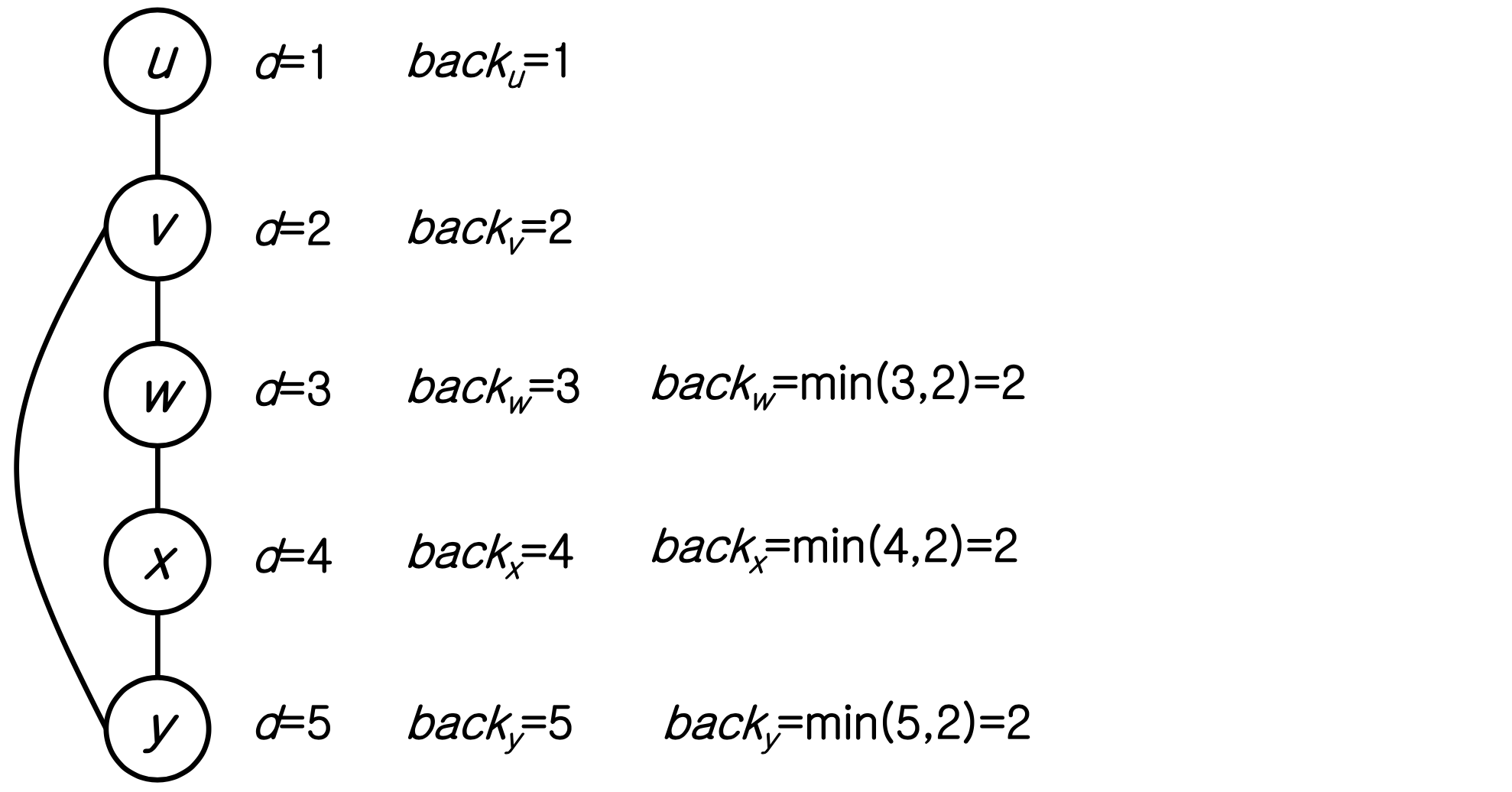
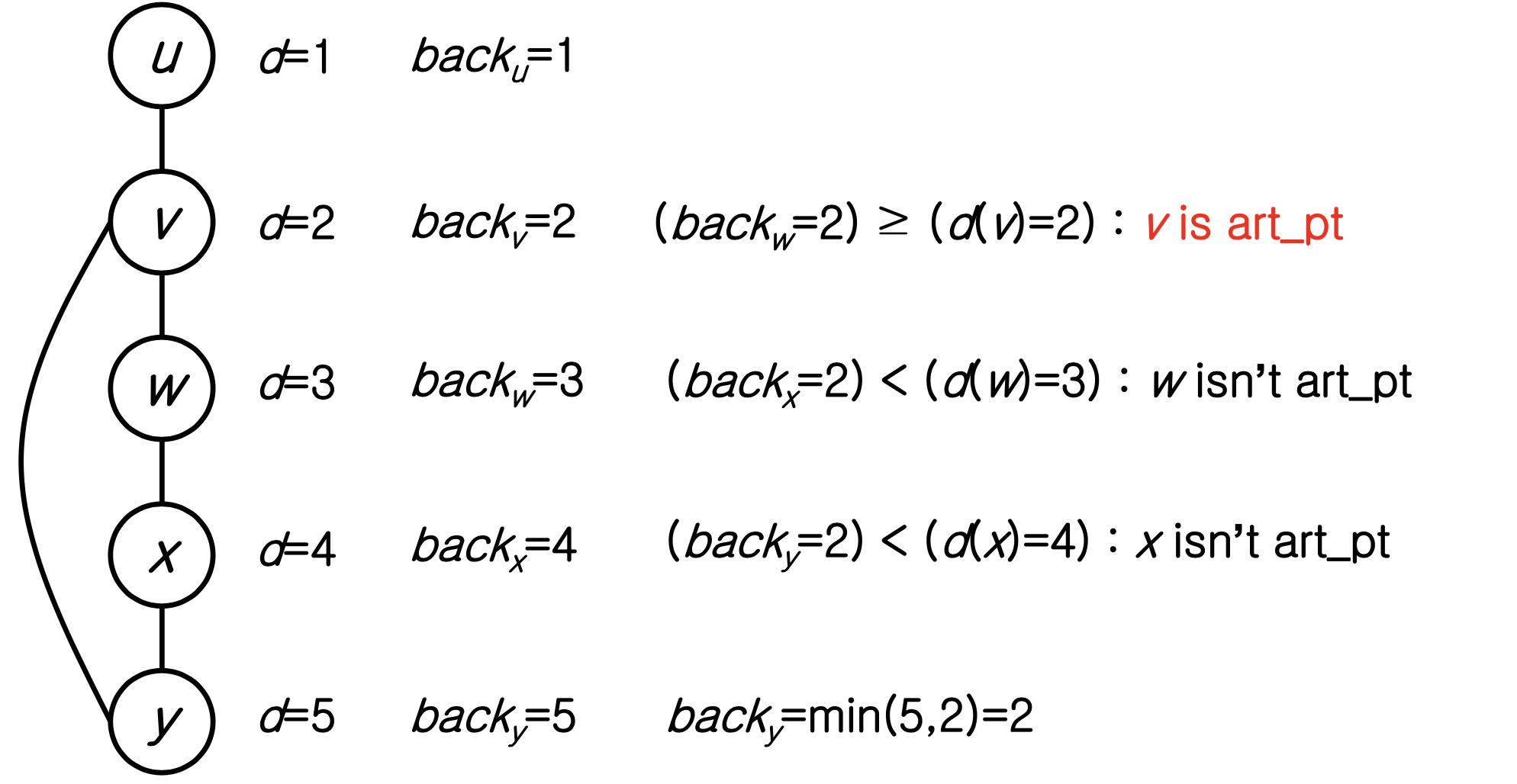
이중 연결 요소와 단절점의 관계:
- DFS 트리의 루트가 단절점이려면 자식이 2개 이상이어야 한다. 자식이 하나뿐이면 루트는 단절점이 아니다.
- 루트가 아닌 정점 u가 단절점이려면 자식이 최소 1개 있어야 한다.
연습 문제
아래 그래프에서 단절점을 찾아보자. 정점은 알파벳 순서로, 각 인접 리스트도 알파벳 순서로 정렬되어 있다고 가정한다.
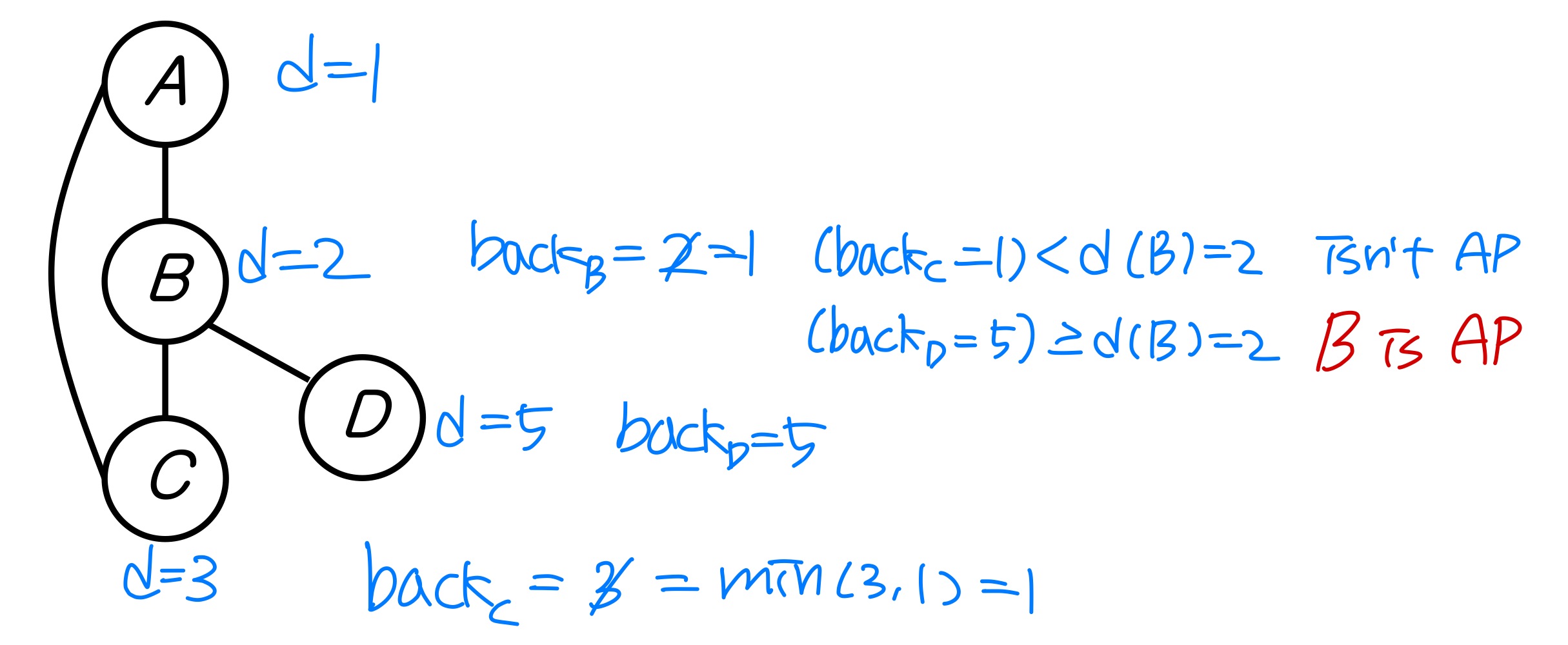
수업 연습 문제
1. 인접 행렬과 인접 리스트
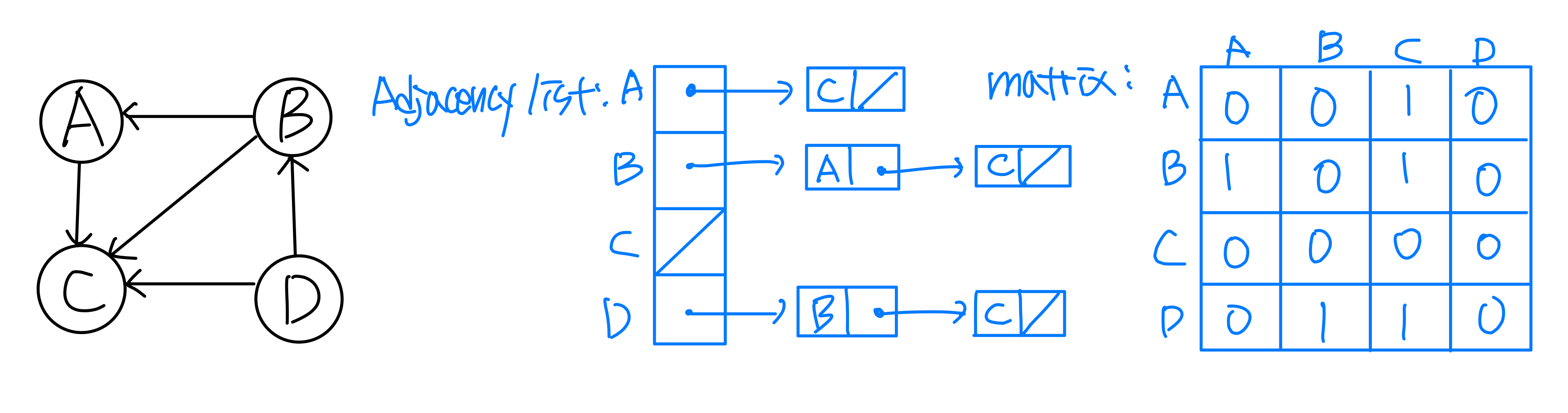
공간 복잡도: 인접 행렬 (V), 인접 리스트 (V+E)
2. BFS
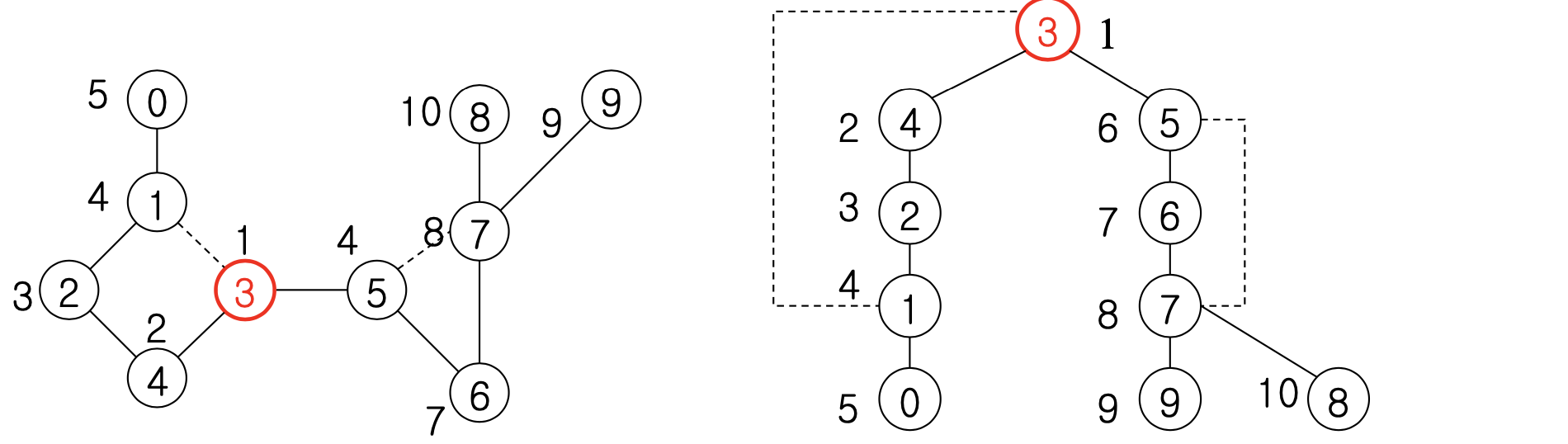
정점 3을 시작점으로 BFS를 수행했을 때의 d와 값을 구하라.
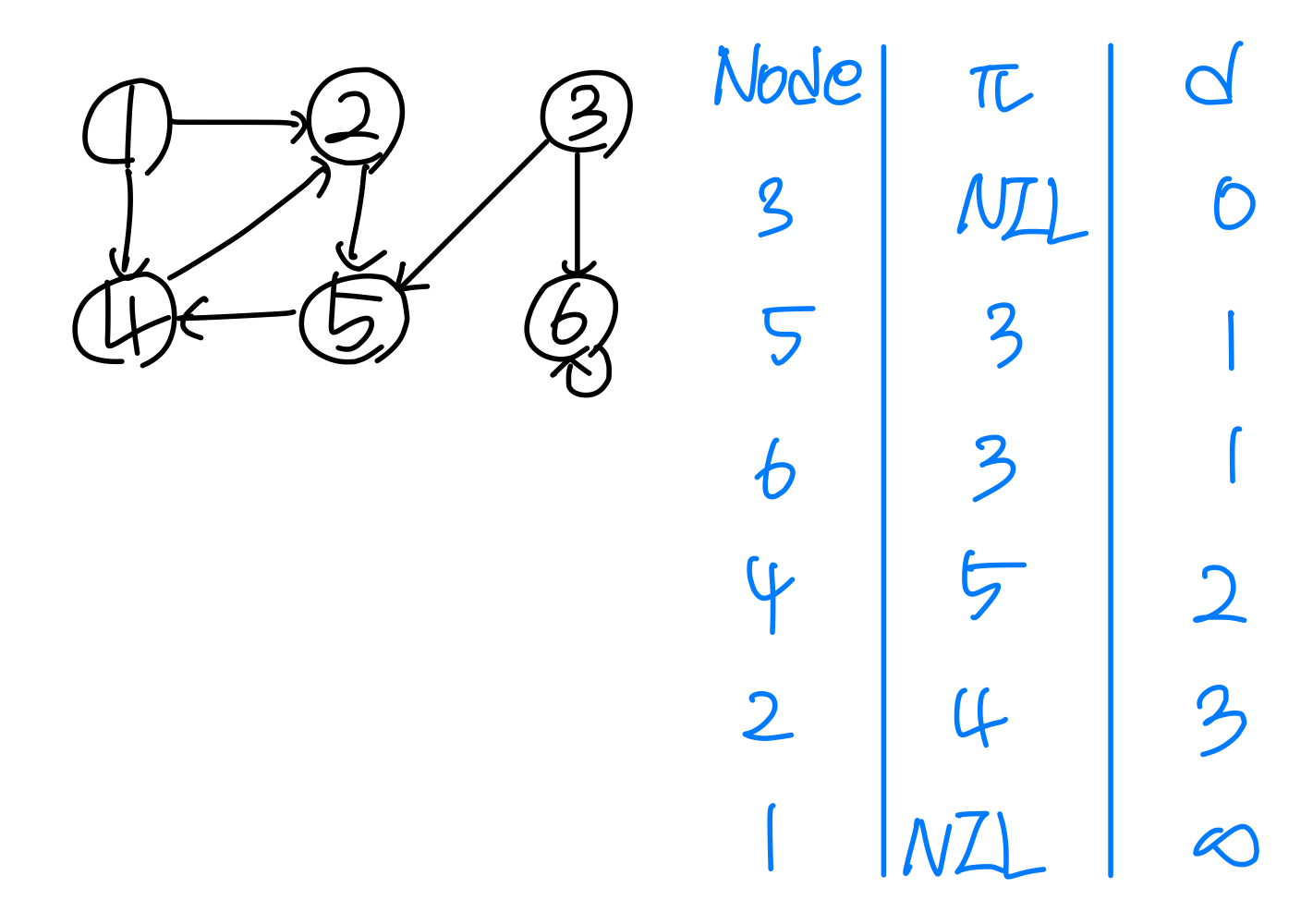
3. BFS 수행 시간
- 인접 리스트: (V+E)
- 인접 행렬로 수정할 경우: (V)
DFS도 마찬가지로 (V+E)이다. 이보다 점근적으로 빠른 알고리즘이 존재할까? 존재하지 않는다.
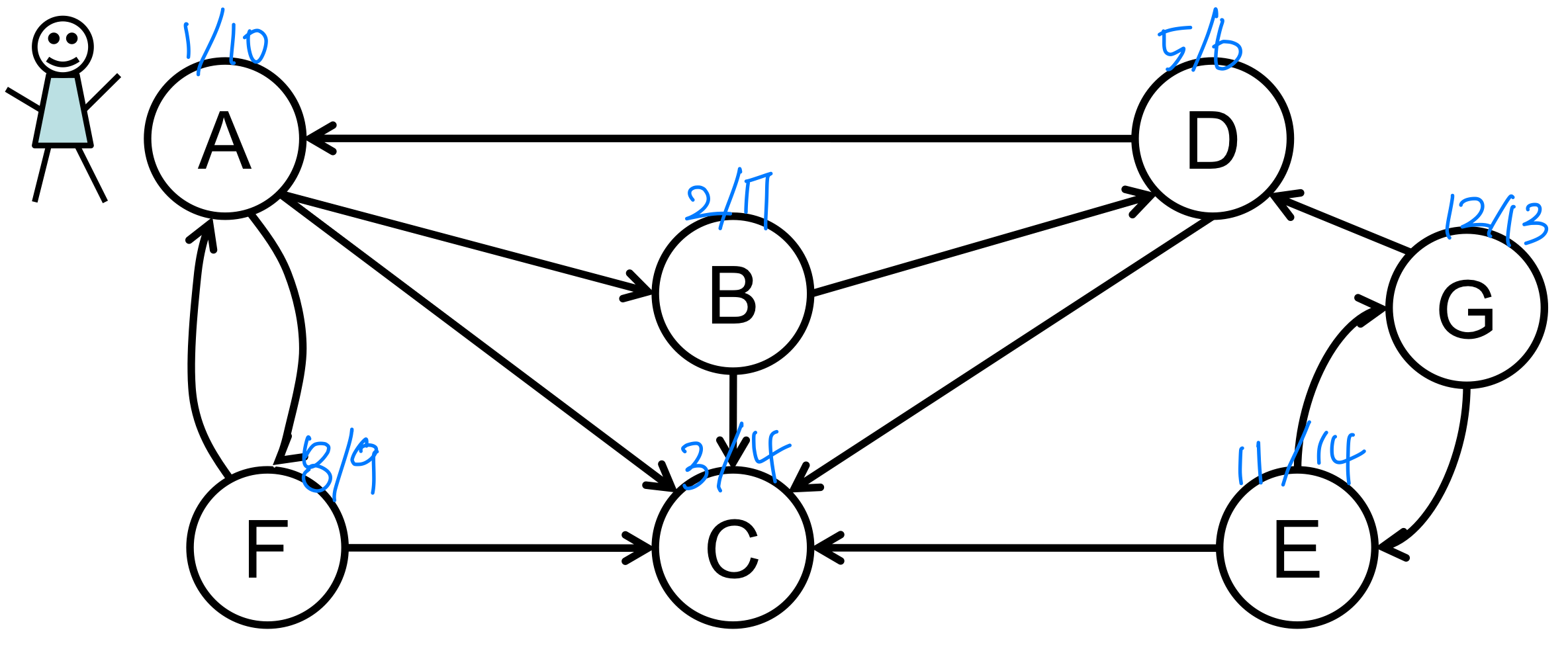
DFS: 간선의 유형
정점은 알파벳 순서로, 각 인접 리스트도 알파벳 순서로 정렬되어 있다고 가정한다.
4. 완료 시간과 정점의 연결

구조체 또는 별도의 배열을 사용한다.
5. SCC
6. 임계 경로
각 노드의 est와 eft를 구하라.
7. 단절점 (AP)
노드 B가 단절점이 되는 경우:

HGU 전산전자공학부 용환기 교수님의 23-1 알고리듬 분석 수업을 듣고 작성한 포스트이며, 첨부한 모든 사진은 교수님 수업 PPT의 사진 원본에 필기를 한 수정본입니다.