Quicksort란?
Quicksort는 1962년 C. A. R. Hoare가 제안한 정렬 알고리즘이다. 핵심 특징은 세 가지다.
- 분할 정복(Divide-and-Conquer) 기반 알고리즘이다
- 제자리 정렬(In-place Sort) 로, 추가 메모리를 거의 사용하지 않는다
- 피벗 선택만 잘 하면 매우 실용적(practical) 이다
이름처럼 "빠른" 정렬인데, 평균 시간 복잡도가 이면서도 상수 계수가 작아 실무에서 가장 널리 쓰이는 정렬 중 하나다.
분할 정복 전략
Quicksort는 n개의 원소를 가진 배열을 다음 세 단계로 정렬한다.
1. Divide(분할): 배열에서 피벗(pivot) x를 선택하고, 피벗을 기준으로 두 부분 배열로 나눈다. 왼쪽 부분 배열의 모든 원소는 x 이하, 오른쪽 부분 배열의 모든 원소는 x 이상이 되도록 한다. 이 분할 과정이 Quicksort에서 가장 핵심적인 단계다.

2. Conquer(정복): 두 부분 배열을 재귀적으로 정렬한다.
3. Combine(결합): 별도의 결합 과정이 필요 없다(Trivial). 분할 과정에서 이미 원소들이 올바른 위치로 이동했기 때문이다.
여기서 핵심은 선형 시간(Linear-time)에 동작하는 분할 서브루틴이다. 분할이 효율적이어야 전체 알고리즘도 효율적이다.
Partition 서브루틴
분할 서브루틴은 배열의 마지막 원소를 피벗으로 선택하고, 나머지 원소를 피벗 기준으로 좌우로 재배치한다.

실행 예시
배열 A = {2, 8, 7, 1, 3, 5, 6, 4}에 대해 PARTITION()이 어떻게 동작하는지 살펴보자. 마지막 원소인 4가 피벗이 된다.
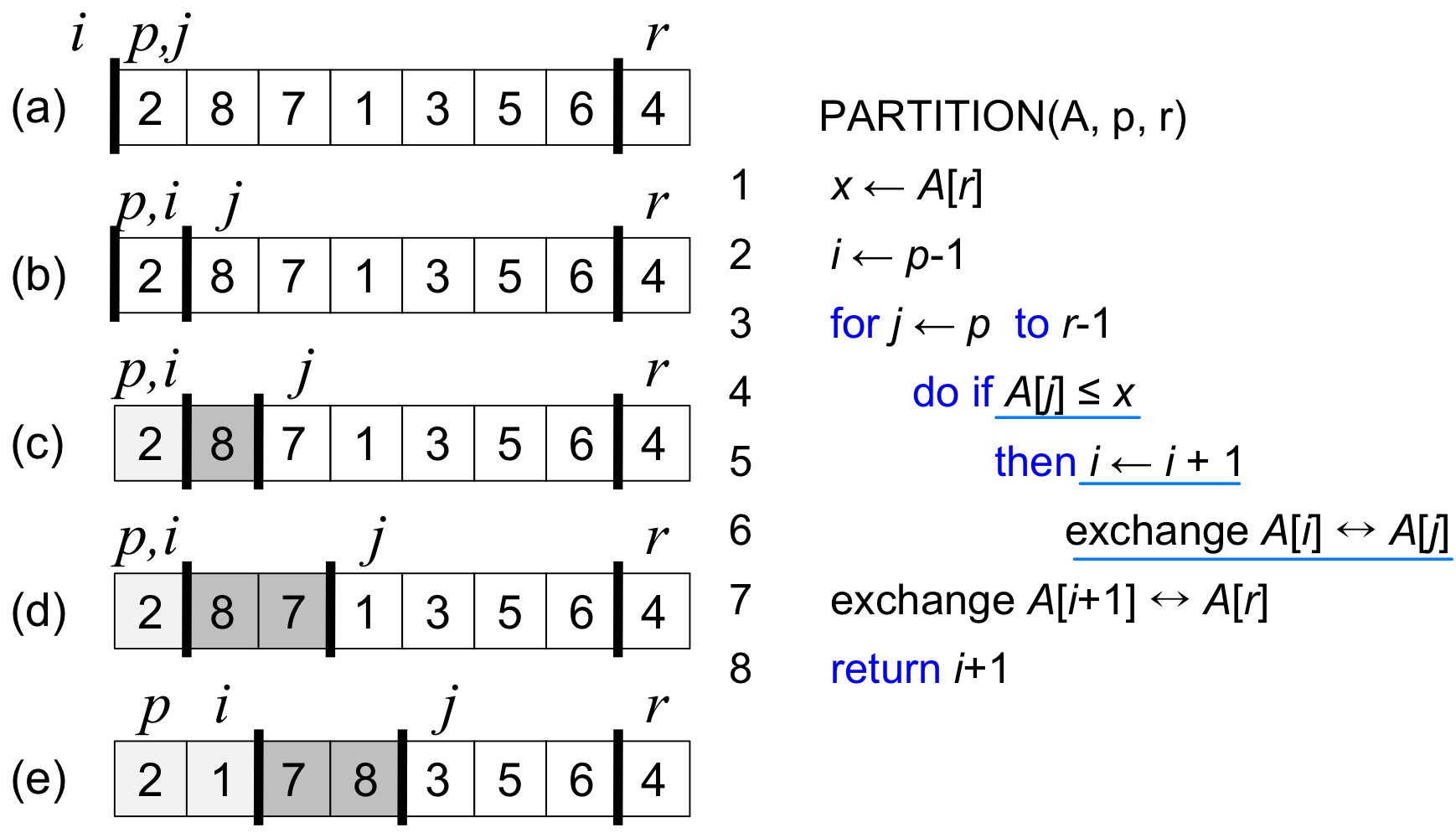

전체 알고리즘
Quicksort의 전체 알고리즘은 Partition을 호출한 뒤 양쪽 부분 배열에 대해 재귀 호출하는 구조다.

정확성 증명 (Loop Invariant)
Partition의 정확성은 루프 불변식(Loop Invariant) 으로 증명할 수 있다. 루프가 반복되는 동안 아래 세 조건이 항상 유지된다.
- A[p..i] 의 모든 원소는 피벗 이하
- A[i+1..j-1] 의 모든 원소는 피벗 초과
- A[r] = pivot (피벗은 배열 끝에 위치)
초기화(Initialization): 루프 시작 전 i = p-1, j = p이므로 A[p..i]와 A[i+1..j-1]은 빈 배열이다. 빈 배열에 대해 불변식은 자명하게 참이다.
유지(Maintenance): 루프가 실행되는 동안, A[j] ≤ pivot이면 A[j]와 A[i+1]을 교환(swap)한 뒤 i와 j를 증가시킨다. A[j] > pivot이면 j만 증가시킨다. 어느 경우든 불변식이 유지된다.
종료(Termination): 루프가 종료되면 j = r이 되어, 배열의 모든 원소가 "피벗 이하", "피벗 초과", "피벗" 세 영역 중 하나에 속하게 된다.
Partition의 수행 시간은 배열을 한 번 순회하므로 이다.
시간 복잡도 분석
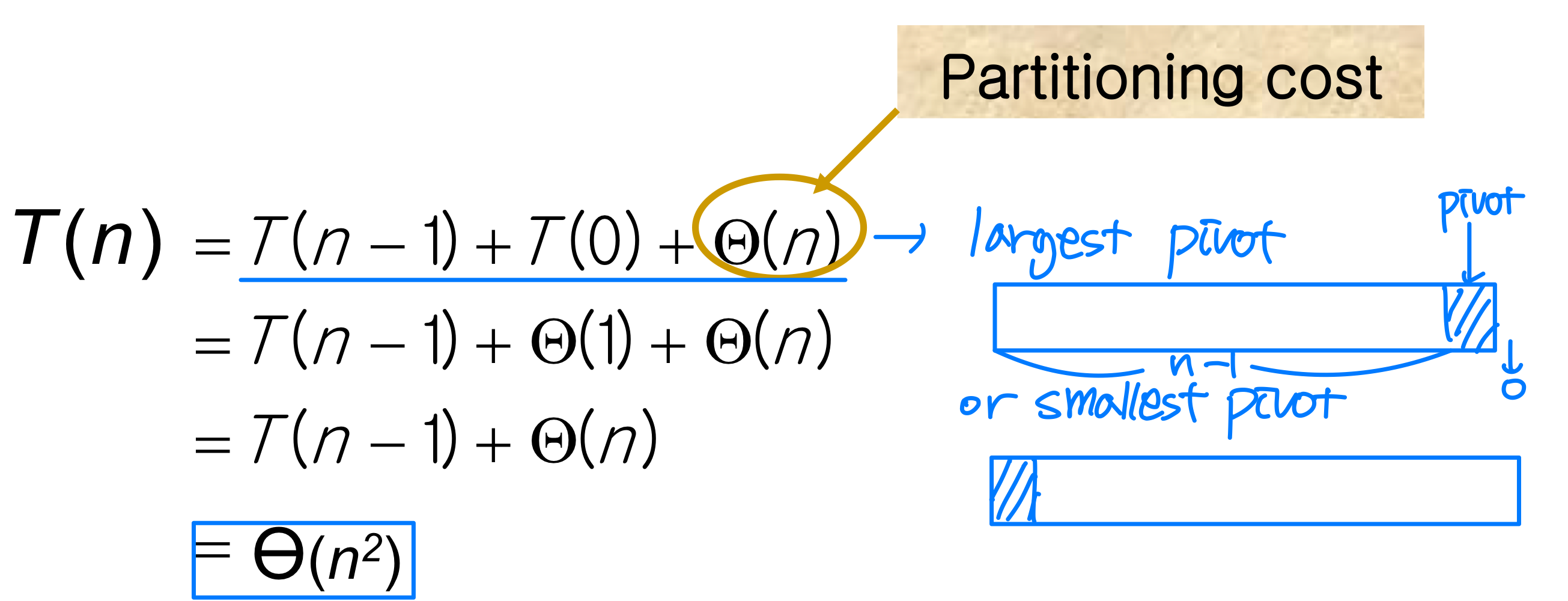
최악의 경우: Θ(n²)
분할이 극단적으로 불균형할 때 최악의 경우가 발생한다. 한쪽 부분 배열에 n-1개, 다른 쪽에 0개의 원소가 배치되는 경우다.
이런 상황은 입력이 이미 오름차순 또는 내림차순으로 정렬되어 있을 때 발생한다. 마지막 원소를 피벗으로 선택하면 항상 가장 크거나 가장 작은 값이 피벗이 되기 때문이다.
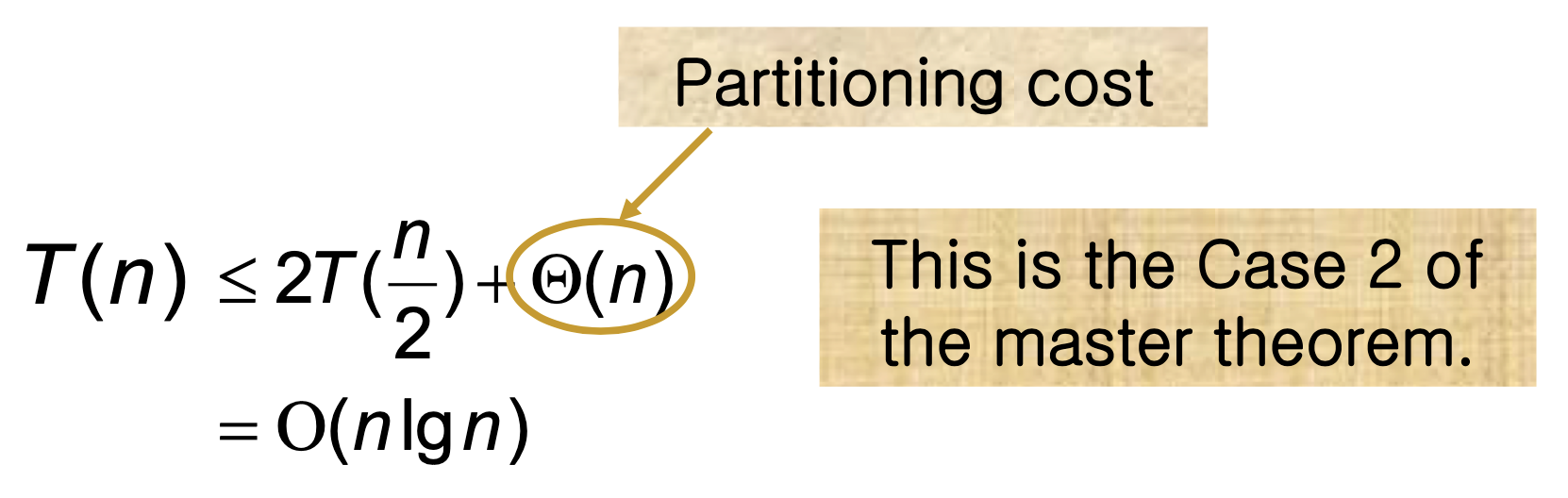
최선의 경우: Θ(n lg n)
분할이 균등하게 이루어질 때 최선의 경우가 된다. 두 부분 배열의 크기가 모두 n/2 이하가 되는 경우다.
평균적인 경우
Quicksort의 평균 수행 시간은 최악보다 최선에 훨씬 가깝다. 평균적인 경우를 분석하는 접근법은 두 가지가 있다.
- 입력 배열을 랜덤하게 섞는 방법: 직관적(Intuitive) 분석
- 랜덤 피벗을 선택하는 Randomized Quicksort: 형식적(Formal) 분석
직관적 이해: 불균형 분할도 괜찮다
Partition이 항상 9:1 비율로 분할한다고 가정해보자. 꽤 불균형해 보이지만, 점화식을 세우면 다음과 같다.
재귀 트리의 깊이는 어떻게 될까?
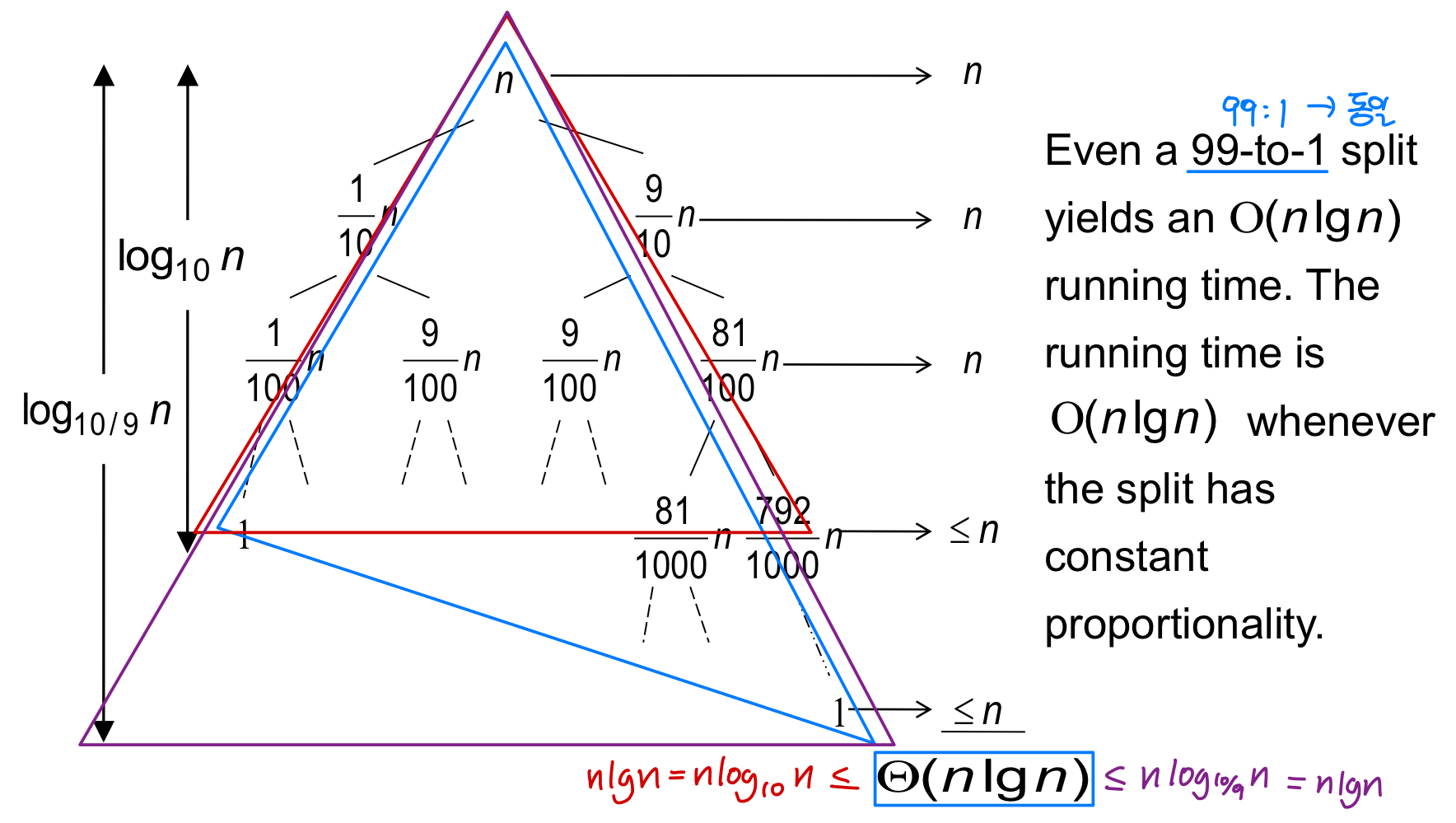
긴 쪽 경로의 깊이가 이므로, 결과적으로 이 된다. 9:1처럼 보기에 불균형한 분할도 전체 수행 시간에는 큰 영향을 주지 않는다는 점이 핵심이다.
직관적 이해: 좋은 분할과 나쁜 분할의 혼합
실제로 Quicksort를 실행하면 좋은 분할과 나쁜 분할이 섞여서 발생한다. 이 분할들은 재귀 트리 전체에 무작위로 분포한다.
직관적으로, 최선의 분할 [(n-1)/2 : (n-1)/2]과 최악의 분할 [n-1 : 0]이 번갈아 나온다고 가정해보자.
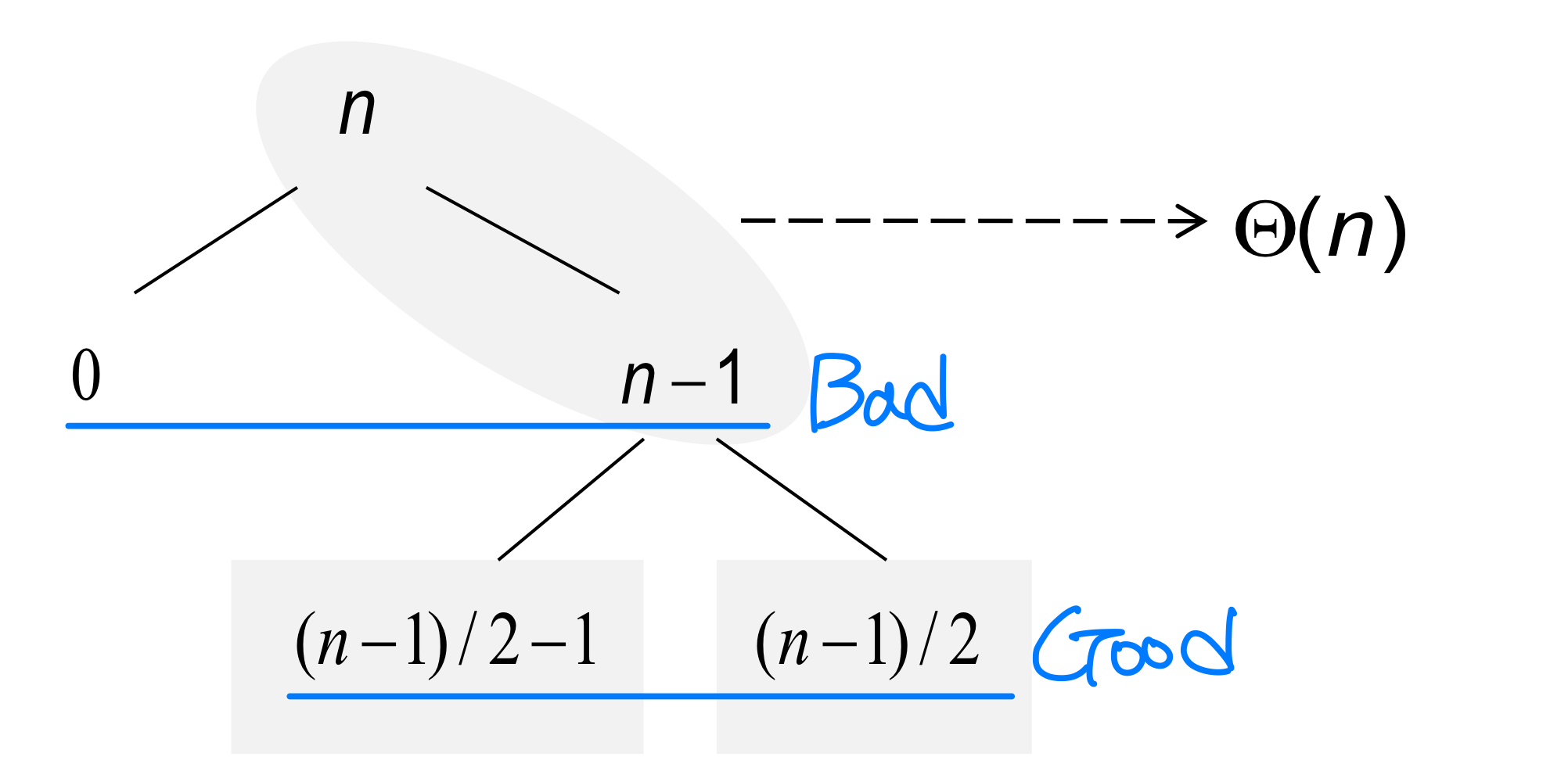
루트 노드에서 나쁜 분할이 일어나고, 그 결과인 크기 (n-1) 노드에서 좋은 분할이 일어나면 어떻게 될까?
- 세 개의 부분 배열이 생기는데, 크기는 각각 0, (n-1)/2 - 1, (n-1)/2이다
- 두 번의 분할에 드는 총 비용은
- 이는 처음부터 좋은 분할만 한 것과 다를 바 없다
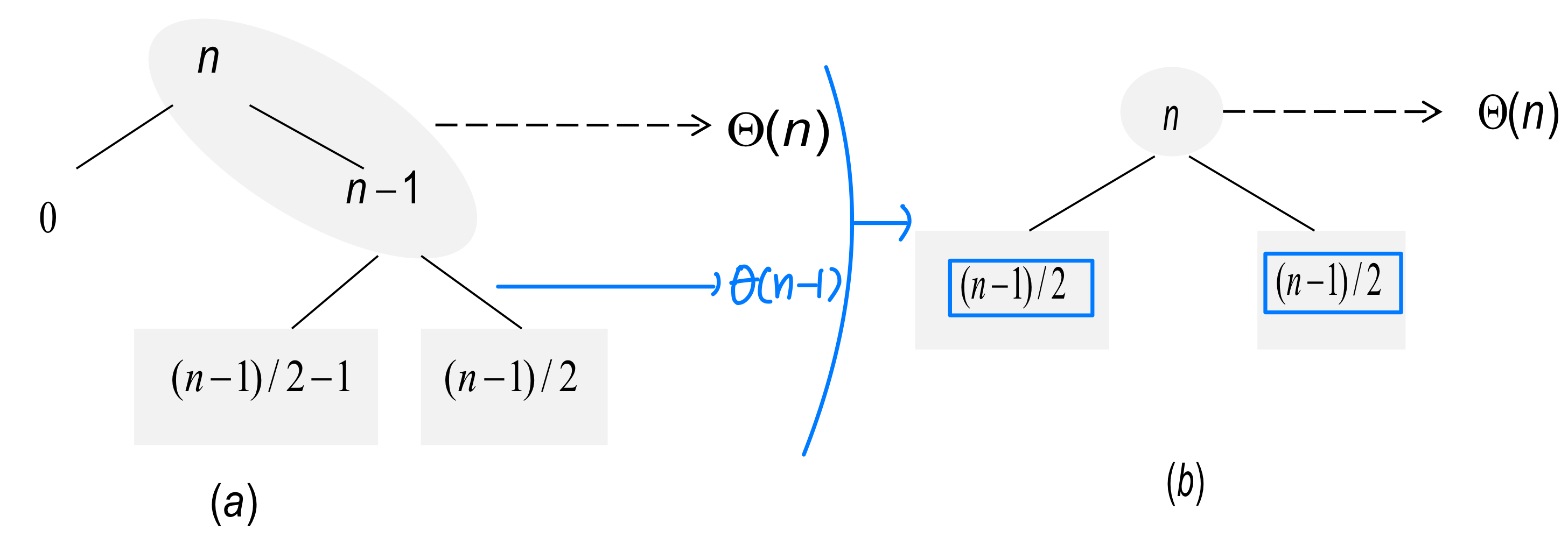

결국 나쁜 분할의 비용은 바로 다음에 오는 좋은 분할에 의해 "흡수"된다. 이것이 Quicksort의 평균 성능이 최선에 가까운 직관적 이유다.
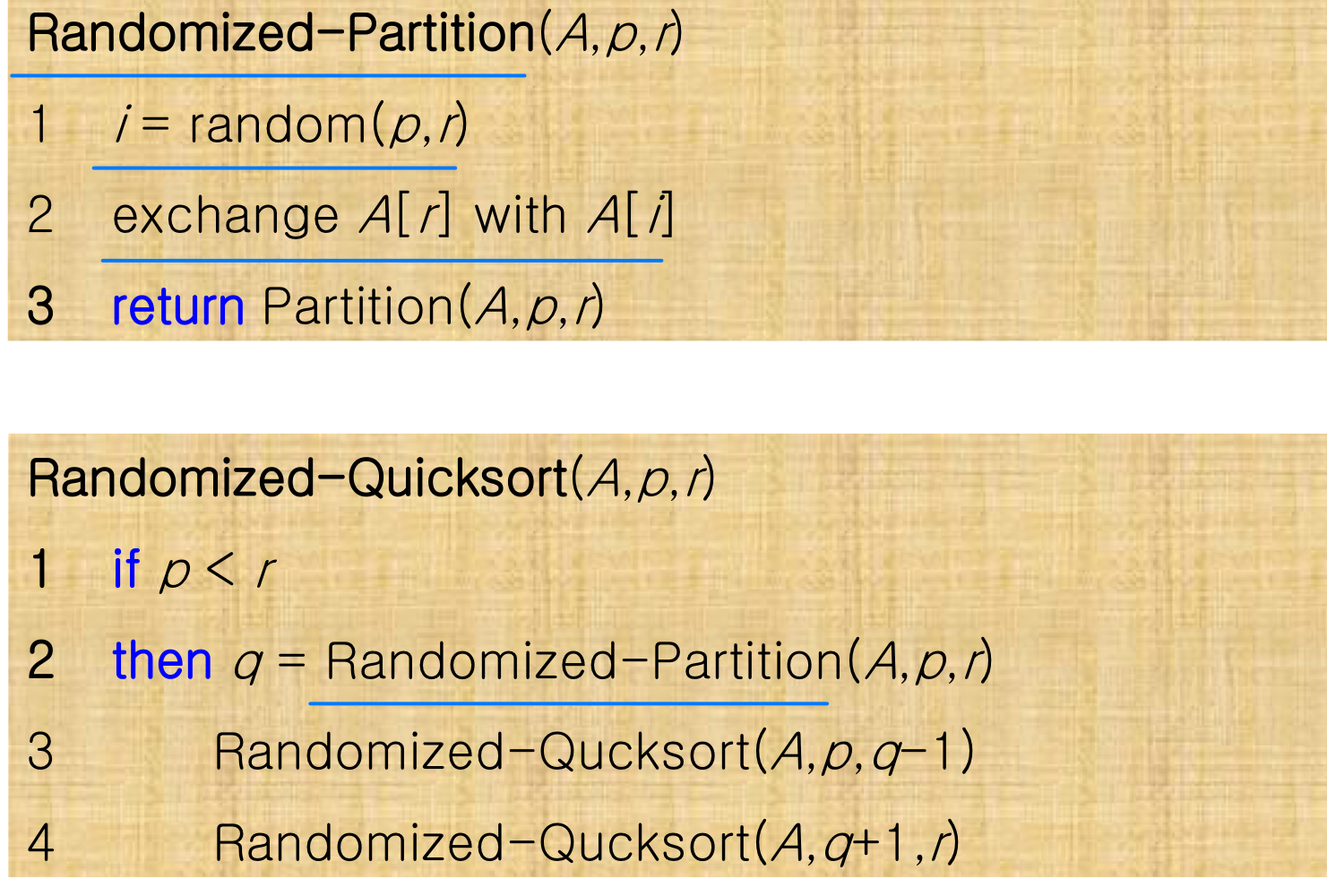
형식적 분석: Randomized Quicksort
입력 배열이 거의 정렬되어 있거나 이미 정렬된 상태라면, 마지막 원소를 피벗으로 선택하는 방식은 최악의 성능을 낸다. 해결책은 간단하다. 피벗을 무작위로 선택하면 된다.
Randomized Quicksort는 특정 입력 패턴에 의해 최악의 경우가 발생하는 것을 방지한다.
평균 수행 시간 분석
분석을 위해 두 가지를 가정한다.
- 모든 입력 원소가 서로 다르다 (중복 없음)
- Randomized-Partition() 을 사용한다. 부분 배열에서 무작위로 원소를 골라 피벗으로 삼는다.
이 경우 모든 분할 (0:n-1, 1:n-2, 2:n-3, ..., n-1:0)이 동일한 확률 1/n으로 발생한다.
T(n)을 기대 수행 시간이라 하면, 점화식은 다음과 같다.
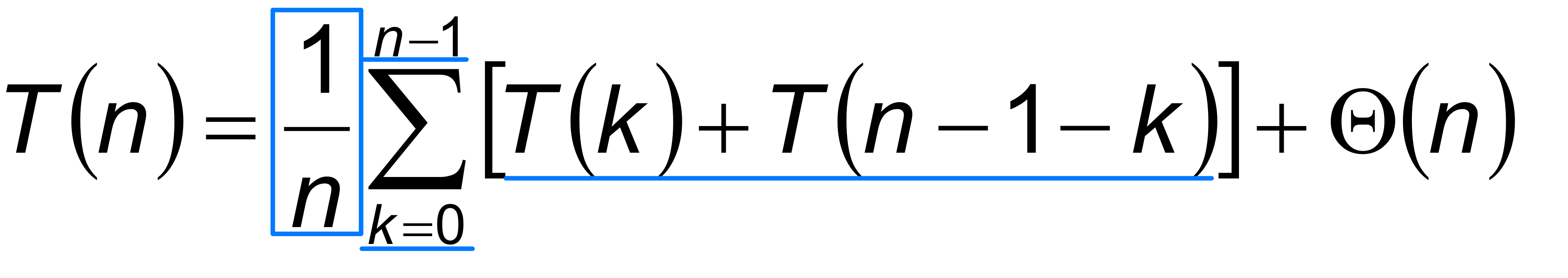
합산 아래의 각 항은 k=0일 때 (0:n-1) 분할, k=1일 때 (1:n-2) 분할, ..., k=n-1일 때 (n-1:0) 분할에 해당한다. 항은 Partition의 비용이다.
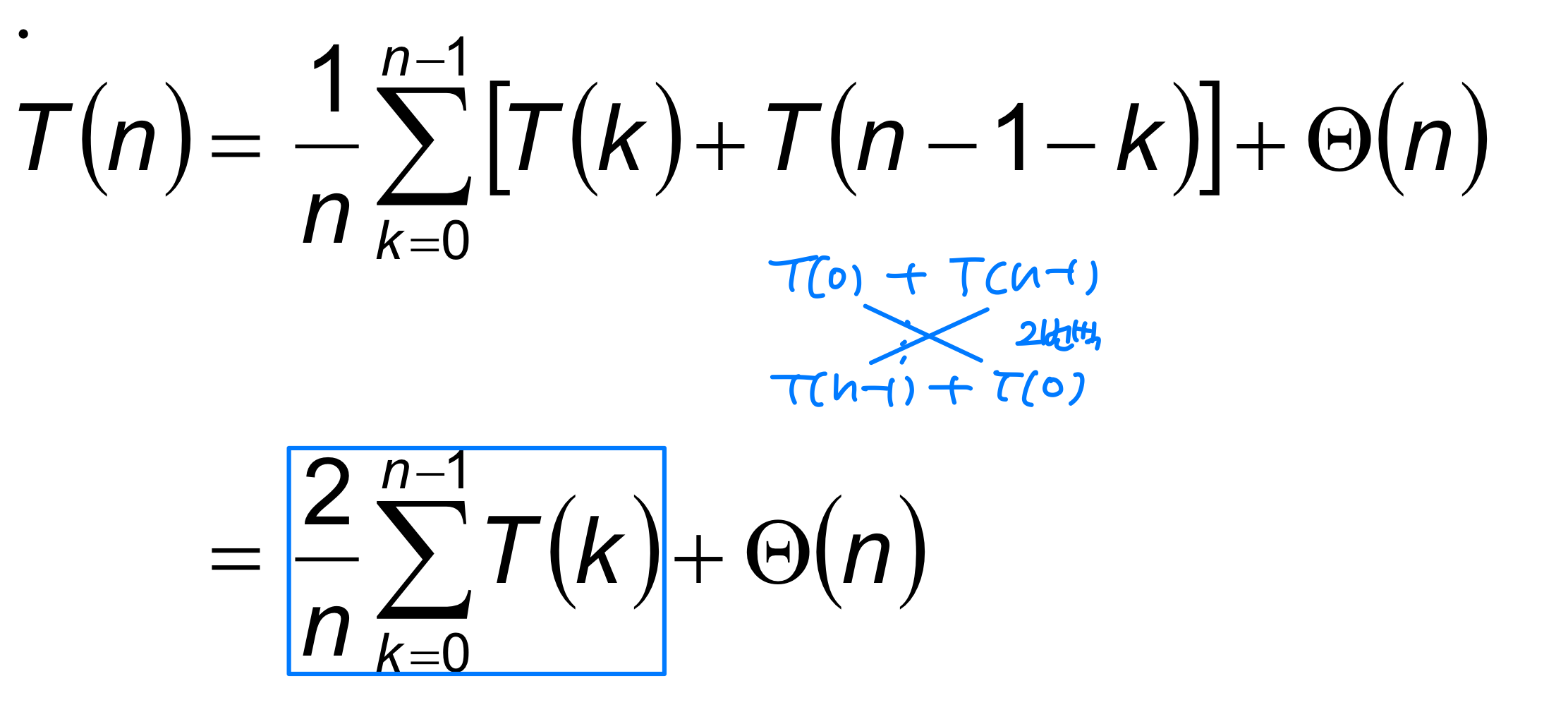
이 점화식을 치환법(Substitution Method) 으로 풀 수 있다. 절차는 다음과 같다.
- 추측:
- 귀납 가설 설정: 어떤 상수 a, b에 대해
- 대입: 점화식에서 n보다 작은 값 k에 대해 가설을 대입
- 증명: n에 대해서도 부등식이 성립함을 보인다



결론적으로, 적절한 상수 a와 b가 존재하여 가 성립한다. 귀납법이 성립하므로 이다.
따라서 Quicksort의 평균 수행 시간은 이다.
핵심 합산식 (Key Summation)
위 증명에서 사용한 핵심 합산식의 유도 과정은 다음과 같다.
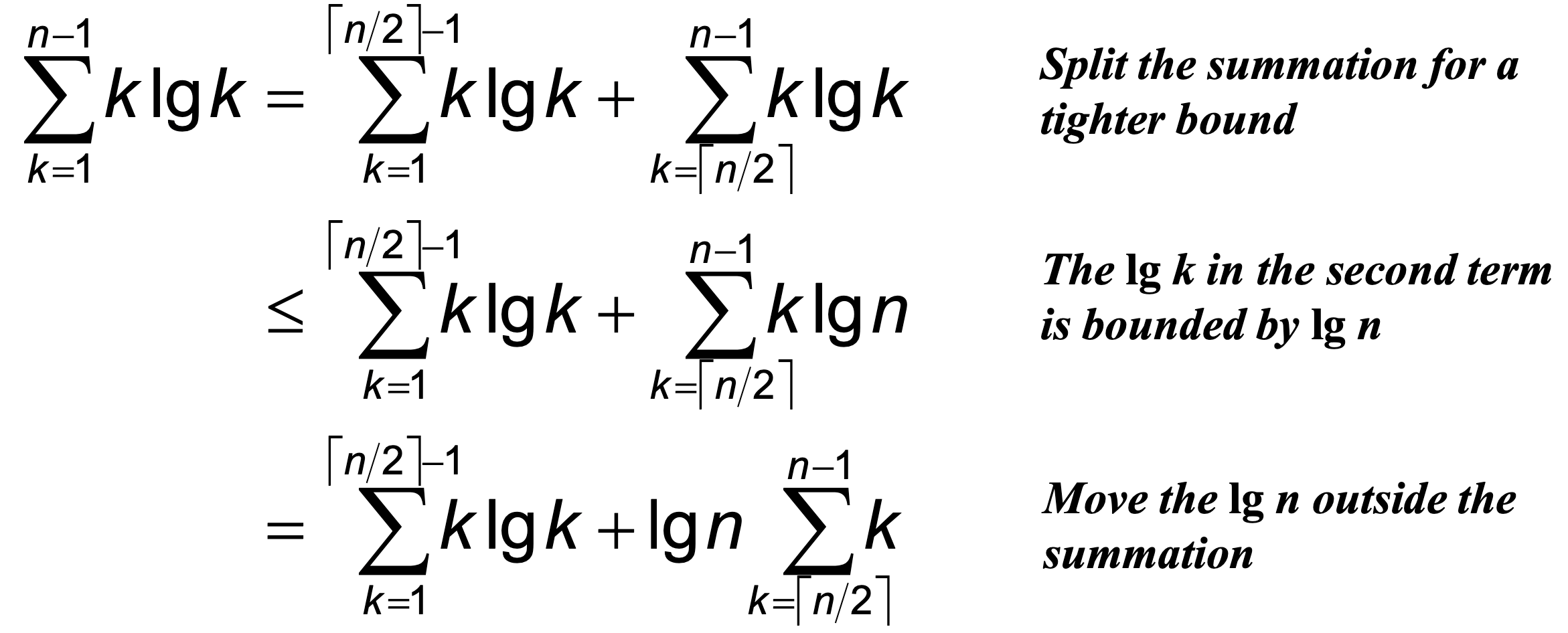


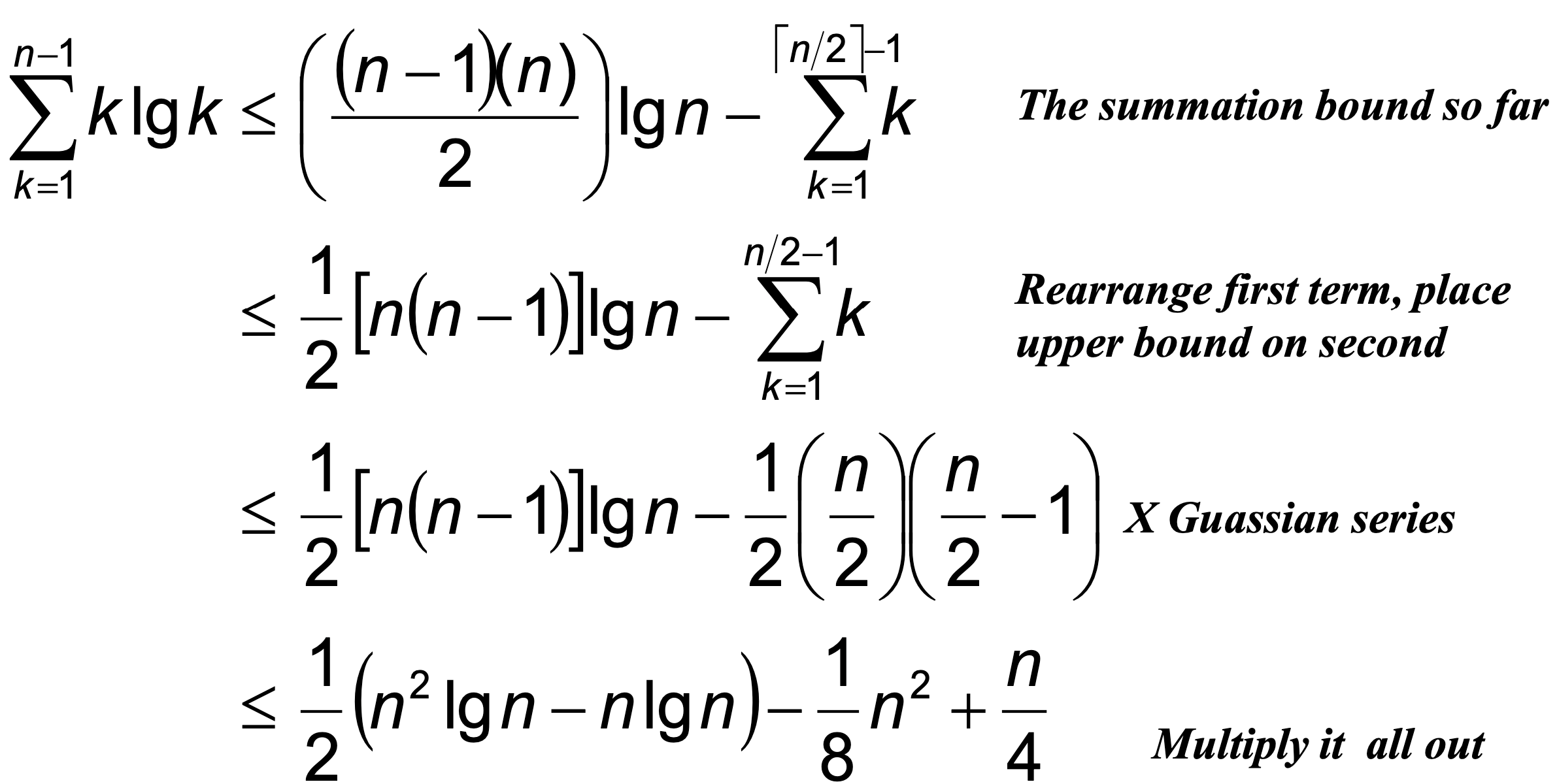
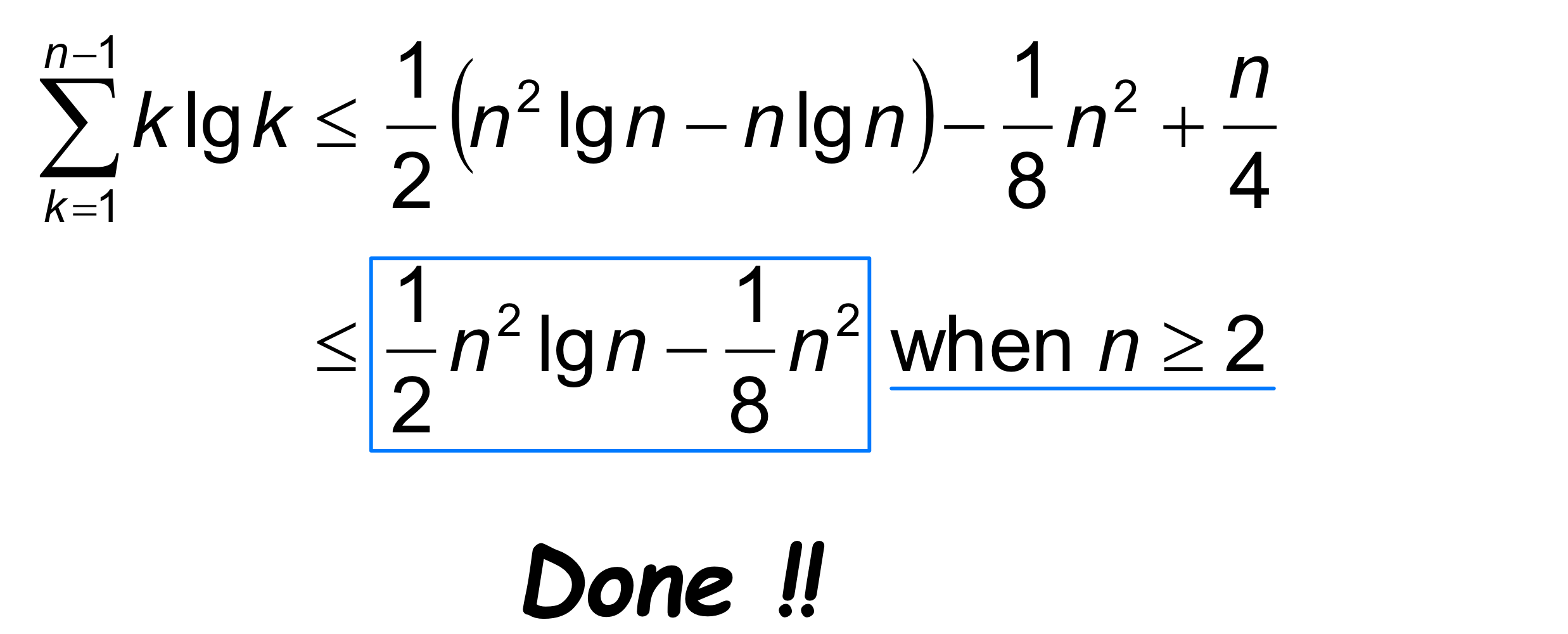
정리
수행 시간 요약
| 경우 | 시간 복잡도 |
|---|---|
| 최악 (Worst) | |
| 최선 (Best) | |
| 평균 (Average) |
점화식 표현
| 경우 | 점화식 |
|---|---|
| 최악 | |
| 최선 | |
| 평균 | 본문의 세 가지 분석 방법 참고 |
HGU 전산전자공학부 용환기 교수님의 23-1 알고리듬 분석 수업을 듣고 작성한 포스트이며, 첨부한 모든 사진은 교수님 수업 PPT의 사진 원본에 필기를 한 수정본입니다.