지금까지의 정렬 알고리즘
선형 시간 정렬을 다루기 전에, 지금까지 배운 정렬 알고리즘을 간략히 정리한다.
Insertion Sort --
코드가 단순하고, 원소가 약 50개 이하인 작은 입력에서 빠르다. 또한 거의 정렬된 입력에서도 효율적이다. 다만 최악/평균 모두 이다. Selection Sort, Bubble Sort도 같은 에 속한다.
Merge Sort -- , Stable
분할 정복(Divide-and-Conquer) 방식으로, 배열을 반으로 나누고 재귀적으로 정렬한 뒤 선형 시간에 병합한다. 안정 정렬이지만 제자리 정렬(in-place)이 아니다.
Heap Sort -- , Not Stable
완전 이진 트리(Complete Binary Tree) 기반의 힙 자료구조를 사용한다. 부모 키가 자식 키보다 큰 힙 성질을 이용하며, 최악에도 을 보장한다. 제자리 정렬이다.
Quick Sort -- 평균 , 최악
역시 분할 정복 방식이다. 배열을 두 부분 배열로 분할하고 재귀적으로 정렬하는데, 병합 단계가 필요 없다는 것이 특징이다. 실무에서 가장 빠른 정렬 중 하나지만, 최악의 경우 이 될 수 있다. 안정 정렬이 아니다.
정렬은 얼마나 빠를 수 있을까?
위의 모든 알고리즘에는 공통점이 하나 있다. 원소 간의 쌍별 비교(Pairwise Comparison) 를 통해 순서를 결정한다는 것이다. 이런 정렬을 비교 정렬(Comparison Sort) 이라 한다.
비교 정렬에는 이론적 한계가 존재한다.
정리: 모든 비교 정렬 알고리즘은 의 시간 복잡도를 가진다.
그렇다면 이것이 정렬의 궁극적인 한계일까? 이 한계를 깨뜨리는 방법은 없을까?
결정 트리(Decision Tree)
비교 정렬의 하한을 증명하기 위해 결정 트리(Decision Tree) 모델을 사용한다.
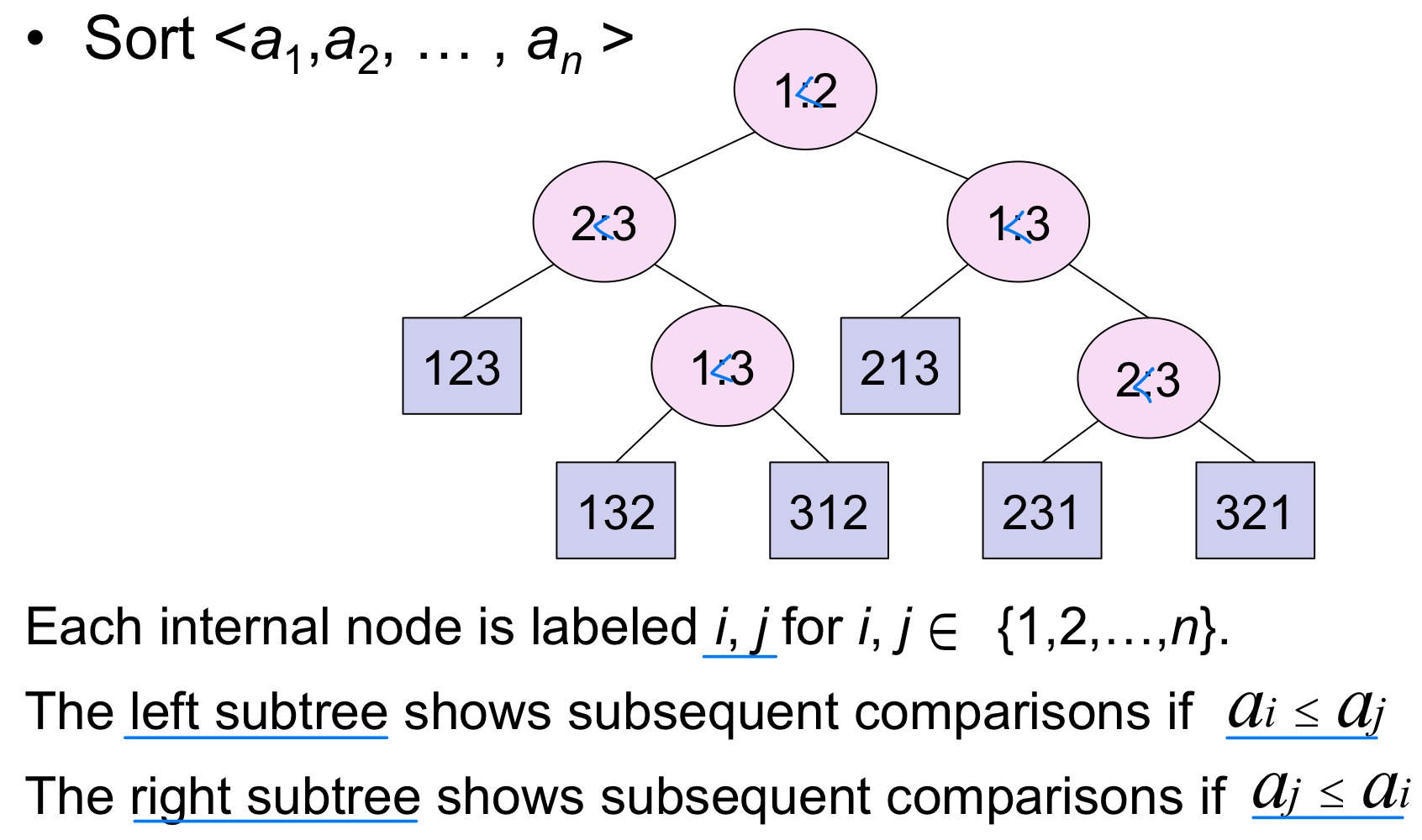
결정 트리는 비교 정렬의 실행 과정을 트리 구조로 모델링한 것이다. 각 내부 노드는 두 원소 간의 비교를, 각 리프(leaf)는 하나의 정렬 결과(순열)를 나타낸다.
결정 트리 예시
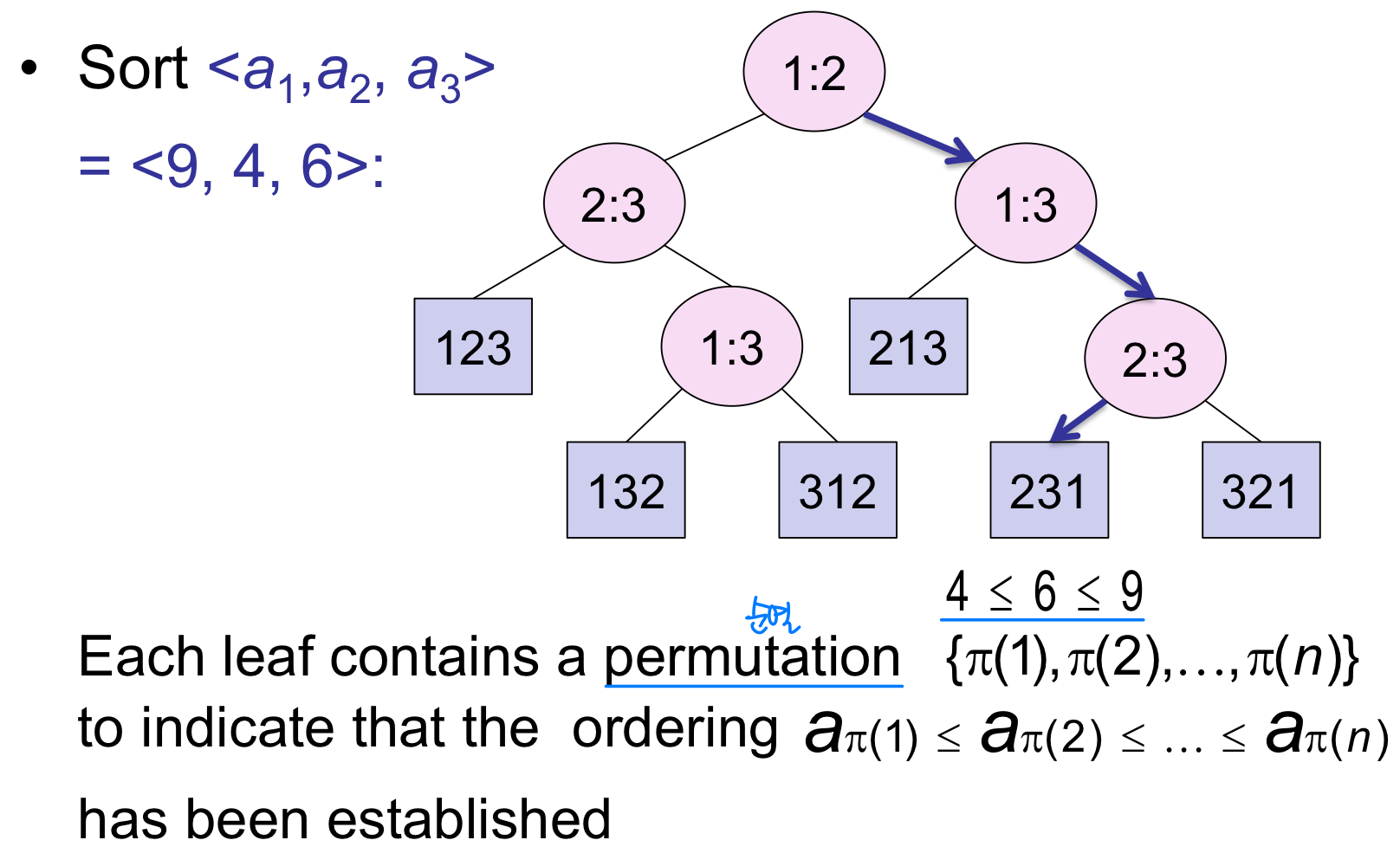
결정 트리 모델의 핵심
결정 트리는 모든 비교 정렬의 실행을 모델링할 수 있다.
- 입력 크기 n마다 하나의 트리가 존재한다
- 알고리즘이 두 원소를 비교할 때마다 분기가 발생한다
- 트리에는 가능한 모든 실행 경로의 비교가 포함된다
- 알고리즘의 실행 시간 = 경로의 길이
- 최악의 경우 실행 시간 = 트리의 높이(height)
결정 트리 정렬의 하한
정리: n개의 원소를 정렬할 수 있는 결정 트리의 높이는 이다.
증명: n개의 원소에 대해 가능한 순열은 n! 가지이므로, 트리는 최소 n!개의 리프를 가져야 한다. 높이가 h인 이진 트리의 리프 수는 최대 개이다. 따라서 가 성립한다.
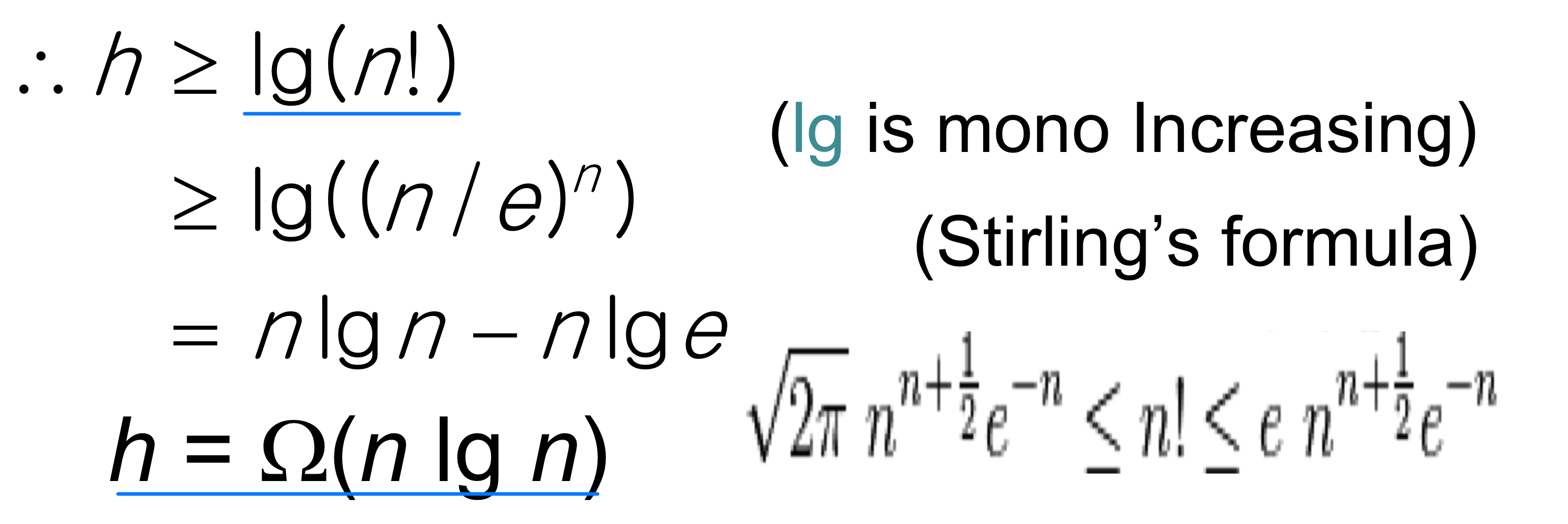
비교 정렬의 하한 정리
이로부터 n개의 원소를 비교 정렬로 정렬하는 데 시간이 필요하다는 결론이 나온다.
따름정리(Corollary): Heap Sort와 Merge Sort는 점근적으로 최적인 비교 정렬이다.
그런데 이 글의 제목은 "선형 시간 정렬"이다. 어떻게 보다 더 빠르게 정렬할 수 있을까? 답은 간단하다. 비교를 하지 않으면 된다.
Counting Sort
Counting Sort는 원소 간의 비교를 전혀 사용하지 않는다. 대신 세기(counting) 를 통해 정렬한다. 입력 조건만 맞으면 시간에 정렬이 가능하다.
단, 다음과 같은 제약 조건이 있다.
- 입력 원소가 모두 정수(Integer) 여야 한다
- 각 원소가 0부터 k까지의 범위에 있어야 한다
- k = O(n) 으로 표현 가능해야 한다
입출력과 핵심 아이디어
입출력:
- 입력: A[1..n], 각 원소 A[j]
- 출력: B[1..n], 정렬된 배열 (제자리 정렬이 아님)
- 보조 배열: C[0..k]
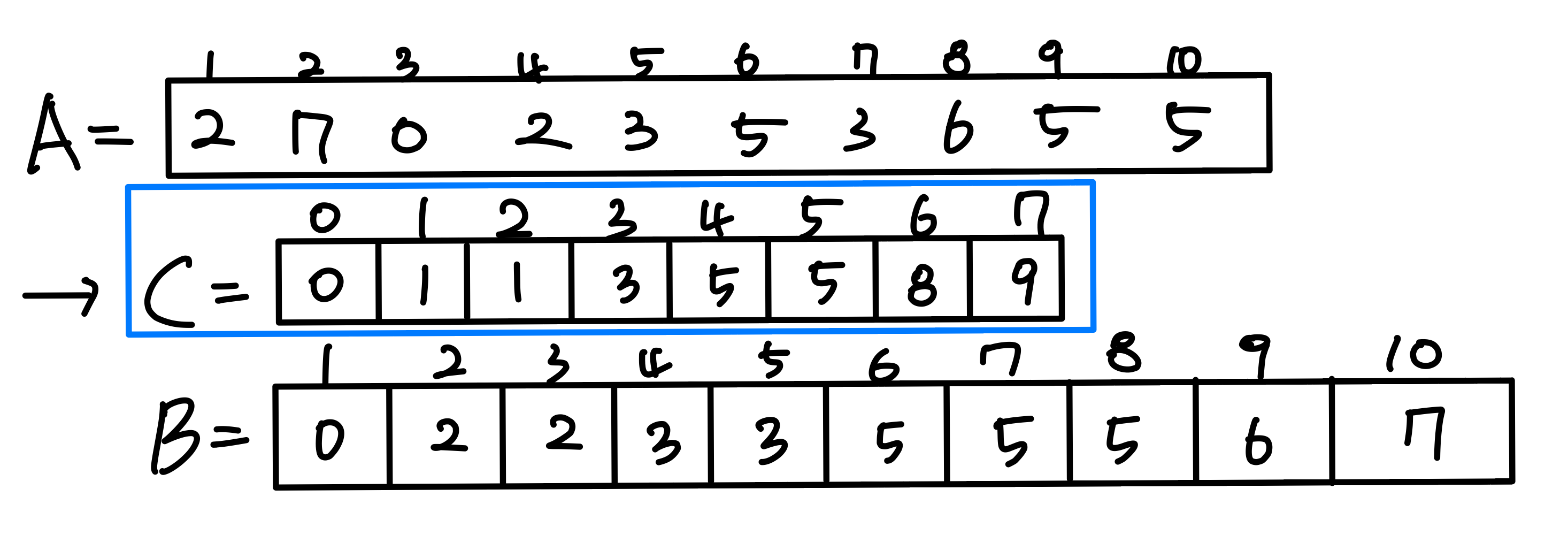
핵심 아이디어: 각 입력 원소 x에 대해 x보다 작은 원소의 개수를 센다. 이 정보를 이용하면 x를 출력 배열의 정확한 위치에 직접 배치할 수 있다.
택배 분류 시스템에 비유하면, 우편번호별로 박스 개수를 먼저 세고, 각 우편번호의 시작 위치를 계산한 뒤, 택배를 해당 위치에 바로 넣는 것과 같다.
의사 코드(Pseudo-code)

단계별로 살펴보면 다음과 같다.
Line 1-2: C 배열을 0으로 초기화한다.
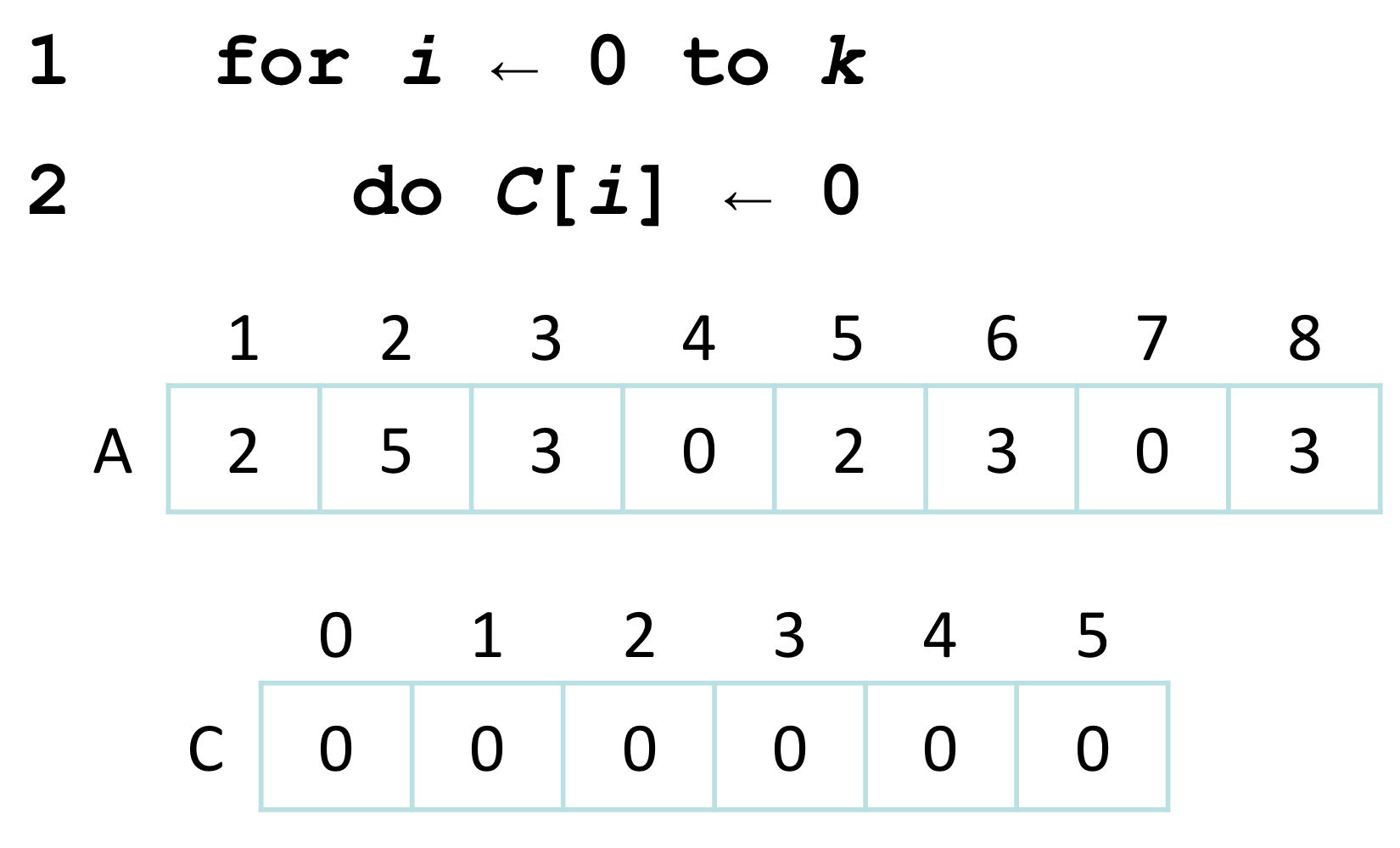
Line 3-4: A 배열을 순회하며 각 값의 등장 횟수를 C에 기록한다.
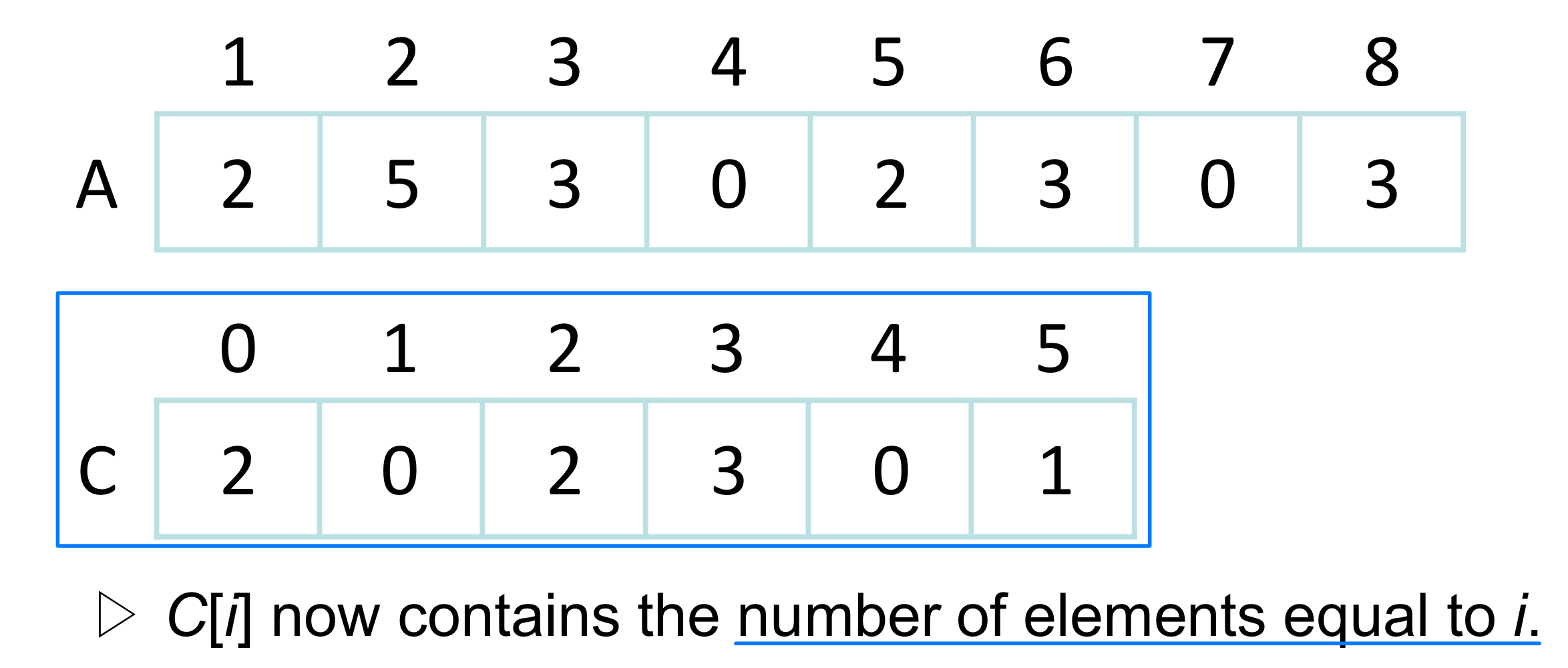
Line 5-6: C 배열의 누적합을 구한다. C[i]는 i 이하인 원소의 개수가 된다.

Line 7-9: A 배열을 뒤에서 앞으로 순회하면서 B 배열의 올바른 위치에 배치한다. 뒤에서부터 순회하는 이유는 안정 정렬(Stable Sort) 을 보장하기 위해서다.
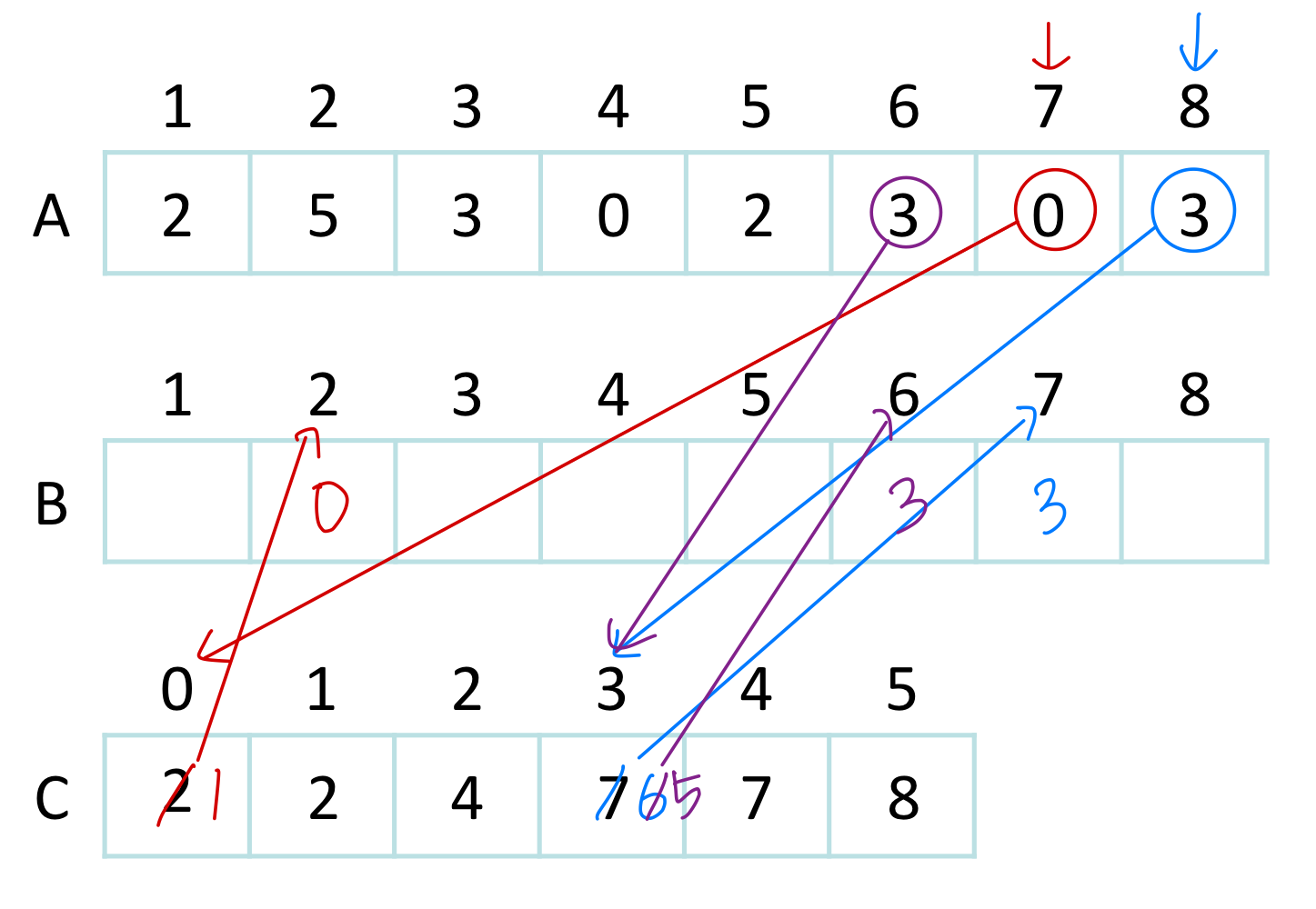
시간 복잡도 분석

k = O(n)이면 Counting Sort의 시간 복잡도는 이다.
여기서 의문이 생길 수 있다. "정렬은 이 하한이라고 했는데?" 이것은 비교 정렬의 하한이다. Counting Sort는 비교 정렬이 아니다. 실제로 원소 간의 비교가 단 한 번도 일어나지 않는다.
왜 항상 Counting Sort를 쓰지 않을까?
Counting Sort는 원소의 범위 k에 의존하기 때문이다. 예를 들어 32비트 정수를 Counting Sort로 정렬하려면 = 4,294,967,296 크기의 보조 배열이 필요하다. k가 너무 커서 k = O(n)이라 할 수 없으므로, 이 경우에는 사용할 수 없다.
안정 정렬(Stable Sort)
Counting Sort는 안정 정렬이다. 즉, 동일한 값을 가진 원소들이 입력에서의 순서를 그대로 유지한다.
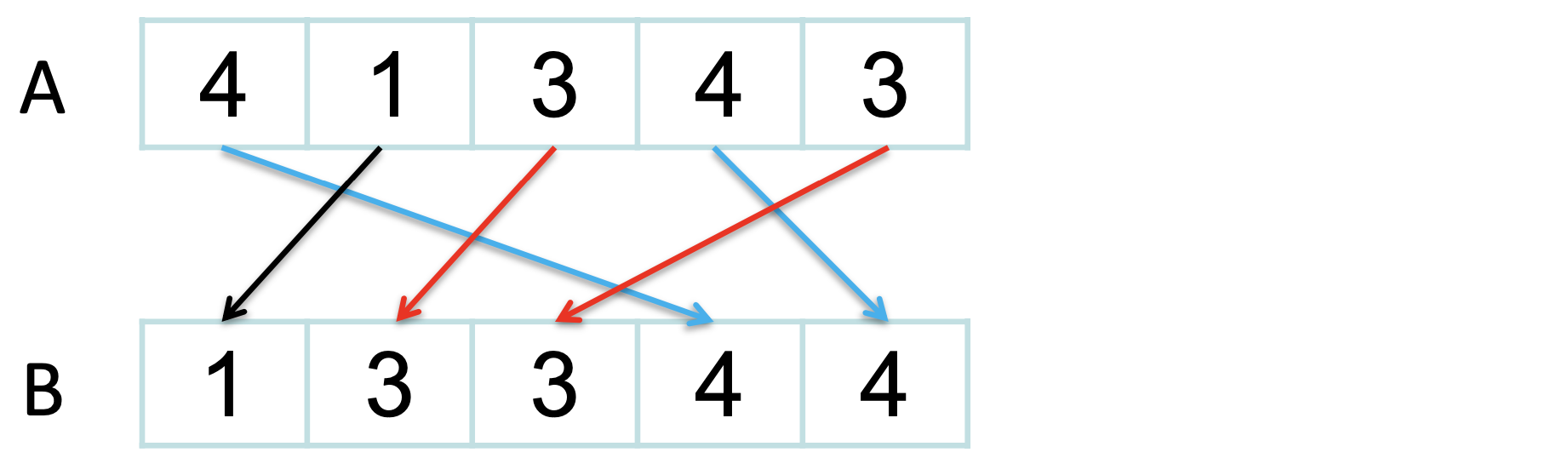
안정성은 원소에 부수 데이터(satellite data)가 있을 때 특히 중요하다. 그리고 Counting Sort의 안정성은 다음에 다룰 Radix Sort의 핵심 전제 조건이기도 하다.
Radix Sort
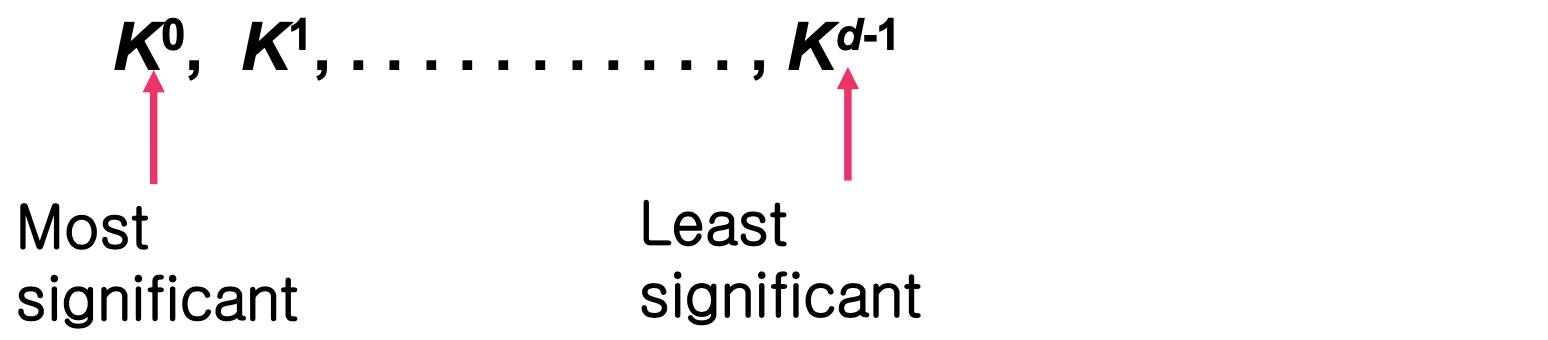
지금까지의 정렬은 하나의 키로 비교했다. 하지만 키가 여러 개라면 어떨까? 예를 들어 d자리 숫자는 각 자릿수가 하나의 키가 된다.
카드 정렬을 예로 들어보자. 카드에는 두 가지 키가 있다.
- 무늬(suit): 클로버 < 다이아 < 하트 < 스페이드
- 숫자(face value): 2 < 3 < ... < J < Q < K < A
최종 정렬 결과는 2C, 3C, ..., KC, AC, 2D, 3D, ..., KS, AS 순이어야 한다.
정렬 방법은 두 가지다.
MSD(Most Significant Digit): 가장 중요한 자릿수부터 정렬
- 무늬로 정렬
- 각 무늬 그룹 안에서 숫자로 정렬
LSD(Least Significant Digit): 가장 덜 중요한 자릿수부터 정렬
- 숫자로 정렬
- 무늬로 정렬
직관적으로는 MSD가 자연스러워 보인다. 하지만 MSD 방식은 중간 결과를 별도로 관리해야 하는 많은 중간 그룹이 생긴다. Radix Sort의 핵심 아이디어는 가장 덜 중요한 자릿수부터 정렬(LSD) 하는 것이다.

예시
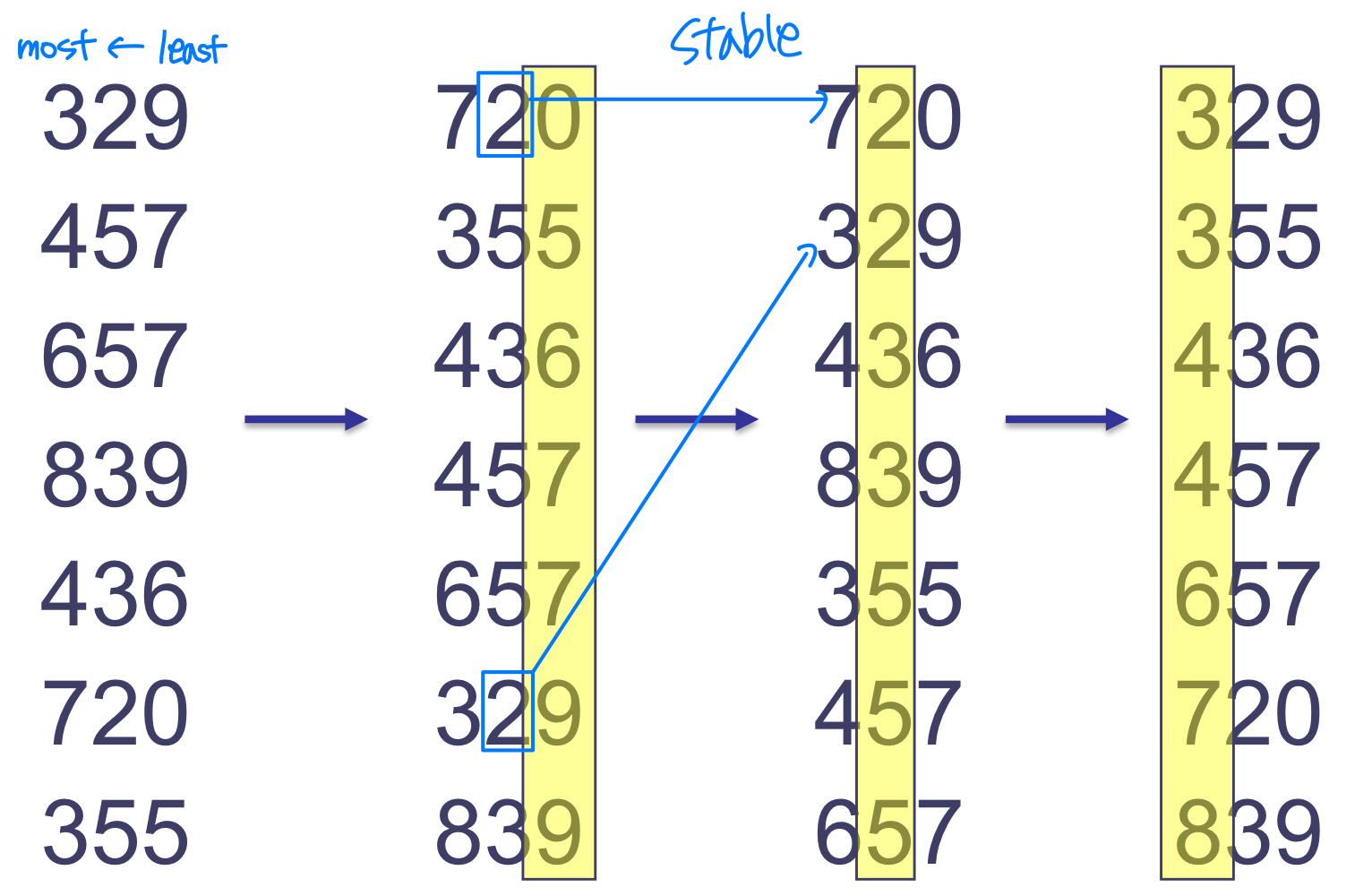
Radix Sort의 정당성
LSD 방식이 올바르게 동작하는 이유를 귀납법으로 증명할 수 있다. 통과 횟수(pass)에 대한 귀납이다.
- 가정: 하위 자릿수 \{ j : j < i \}가 이미 정렬되어 있다
- 증명: i번째 자릿수를 정렬하면 배열이 올바르게 정렬된다
- i번째 자릿수가 다른 두 수는, 그 자릿수 기준으로 정렬하면 올바른 순서가 된다 (하위 자릿수는 무관)
- i번째 자릿수가 같은 두 수는, 이미 하위 자릿수 기준으로 정렬되어 있다. 안정 정렬을 사용하므로 그 순서가 유지된다
여기서 안정 정렬이 왜 중요한지 명확해진다. 같은 자릿수를 가진 원소의 기존 순서를 깨뜨리면 하위 자릿수의 정렬이 무의미해지기 때문이다.
시간 복잡도
각 자릿수의 정렬에 어떤 알고리즘을 쓸까? Counting Sort가 자연스러운 선택이다.
- n개의 수를 1..k 범위의 자릿수 기준으로 정렬:
- d자리 수에 대해 d번의 패스를 수행하므로, 총 시간은
- d가 상수이고 k = O(n)이면 시간에 정렬된다
Counting Sort 기반의 Radix Sort는 빠르고, 점근적으로 선형이며, 구현도 단순한 좋은 선택지다.
Bucket Sort
Bucket Sort는 입력이 [0, 1) 구간의 실수(Real Number) 일 때 사용하는 정렬이다.
기본 아이디어는 다음과 같다.
- [0, 1) 구간을 크기 1/n인 n개의 버킷(Bucket) 으로 나눈다
- 각 입력 원소를 해당 버킷에 넣는다
- 각 버킷을 Insertion Sort로 정렬한다
- 버킷을 순서대로 연결한다
입력이 균등 분포(Uniform Distribution) 를 따르면, 각 버킷에 들어가는 원소 수는 평균적으로 이다. 따라서 기대 총 시간은 이 된다. 이 아이디어는 해시 테이블(Hash Table) 과 유사하다.
최악의 경우
모든 원소가 하나의 버킷에 몰리는 경우, 그 버킷 안에서 정렬해야 한다.
최악의 경우 Bucket Sort는 시간이 걸린다. Merge Sort를 사용하면 으로 줄일 수 있지만, 일반적으로 Insertion Sort가 더 단순하여 선호된다.
평균의 경우
입력이 [0, 1)에서 균등하게 무작위로 추출될 때, 각 버킷의 기대 크기는 이다. 이때 Bucket Sort의 평균 시간 복잡도는 이다.
정리
| 알고리즘 | 시간 복잡도 | 조건 |
|---|---|---|
| 비교 기반 정렬 | 이론적 하한 | |
| Merge Sort, Heap Sort, Quick Sort | 비교 기반 최적 | |
| Counting Sort | 정수, k = O(n) | |
| Radix Sort | 정수, 유한 범위 | |
| Bucket Sort | 평균 | 균등 분포 실수 |
- 모든 비교 기반 정렬은 시간이 필요하다
- Merge Sort, Heap Sort, Quick Sort는 비교 기반이며 이므로 최적이다
- 입력에 대한 가정을 활용하면 더 빠른 정렬이 가능하다
- Counting Sort와 Radix Sort는 유한 범위의 정수에 대해 선형 시간을 달성한다
- Bucket Sort는 균등 분포의 실수에 대해 평균 선형 시간을 달성한다
수업 연습 문제
1. In-place 정렬과 Stable 정렬
In-place 정렬: 입력 배열 외부에 저장되는 원소가 상수 개 이하인 정렬이다.
- 예시: Insertion Sort, Heap Sort, Quick Sort
Stable 정렬: 같은 키를 가진 원소가 입력과 동일한 순서로 출력되는 정렬이다.
- 예시: Insertion Sort, Merge Sort, Counting Sort
2. Counting Sort 연습
HGU 전산전자공학부 용환기 교수님의 23-1 알고리듬 분석 수업을 듣고 작성한 포스트이며, 첨부한 모든 사진은 교수님 수업 PPT의 사진 원본에 필기를 한 수정본입니다.