"Ctrl + F"를 눌러 문서에서 단어를 찾아본 적이 있을 것이다. 이 간단한 동작 뒤에는 문자열 매칭(String Matching) 알고리즘이 동작하고 있다. 긴 텍스트 안에서 특정 패턴을 찾는 문제는 텍스트 편집기, 검색 엔진, DNA 서열 분석 등 다양한 분야에서 핵심적인 역할을 한다.
이 글에서는 Naive 알고리즘부터 시작하여 Rabin-Karp, 유한 오토마타(FA), 그리고 KMP 알고리즘까지, 문자열 매칭 문제를 해결하는 네 가지 접근법을 비교 분석한다.
기본 용어 정리
문자열 매칭 알고리즘을 다루기 전에 기본 표기법을 정리한다.
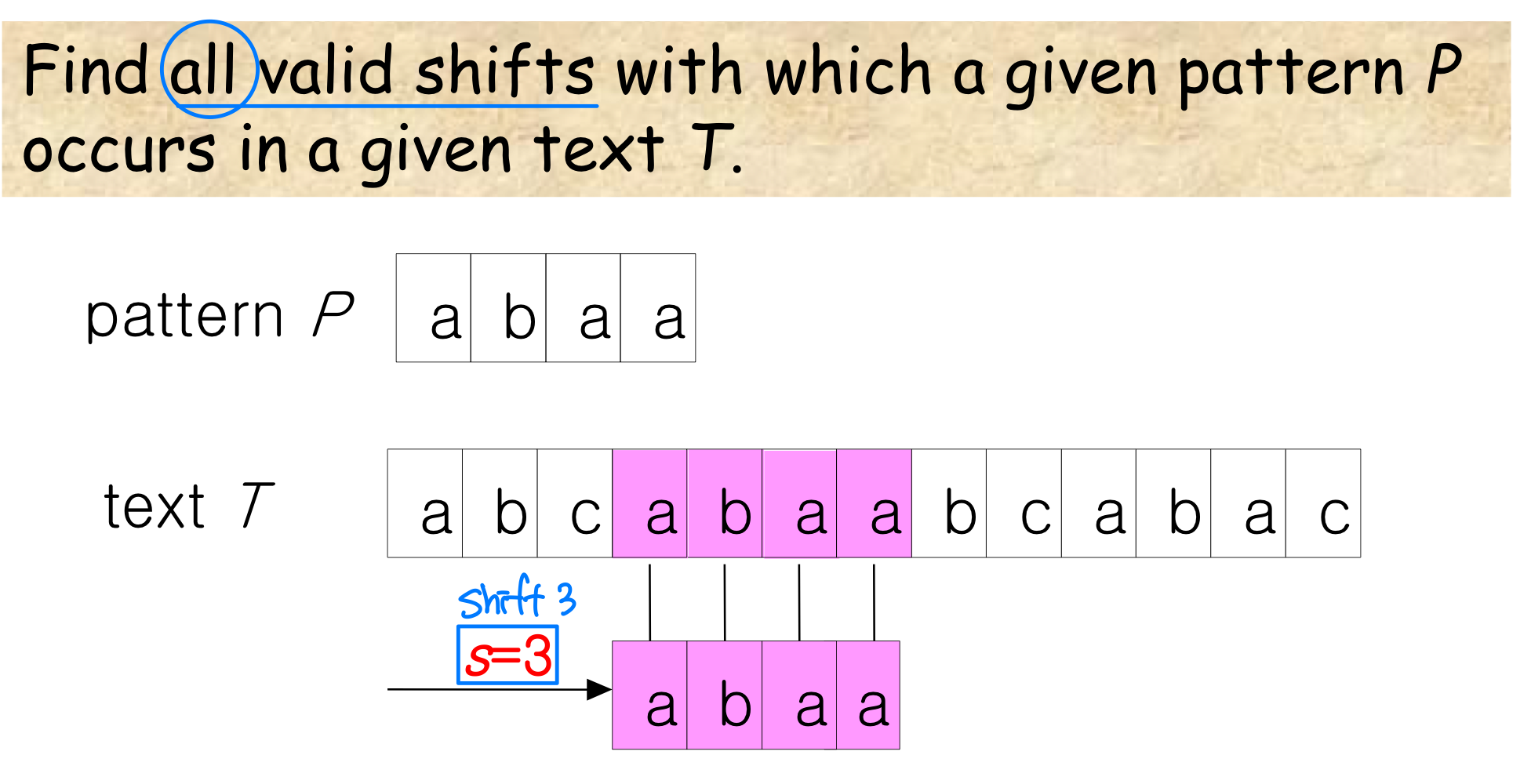
- T[1..n]: 검색 대상인 텍스트 (길이 n)
- P[1..m]: 찾고자 하는 패턴 (길이 m)
- P가 텍스트 T에서 시프트(shift) s만큼 이동한 위치에 존재한다는 것은, T[s+j] = P[j] (1 ≤ j ≤ m)를 만족한다는 뜻이다.
- 이때 s를 유효한 시프트(valid shift) 라 하고, 그렇지 않으면 무효한 시프트(invalid shift) 라 한다.
핵심은 간단하다. 텍스트 위에 패턴을 놓고 한 칸씩 밀어가면서 일치하는 위치를 찾는 것이다. 문제는 얼마나 효율적으로 찾느냐에 있다.
Naive 알고리즘
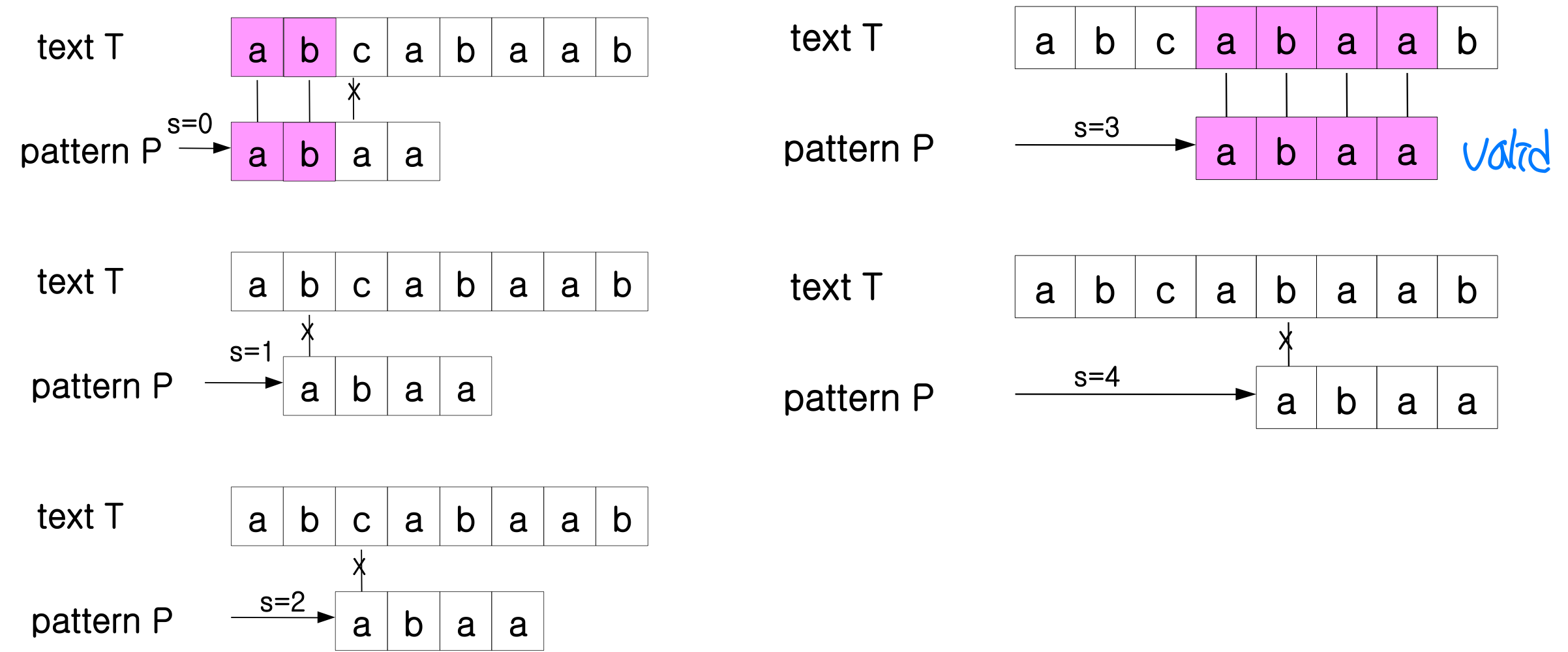
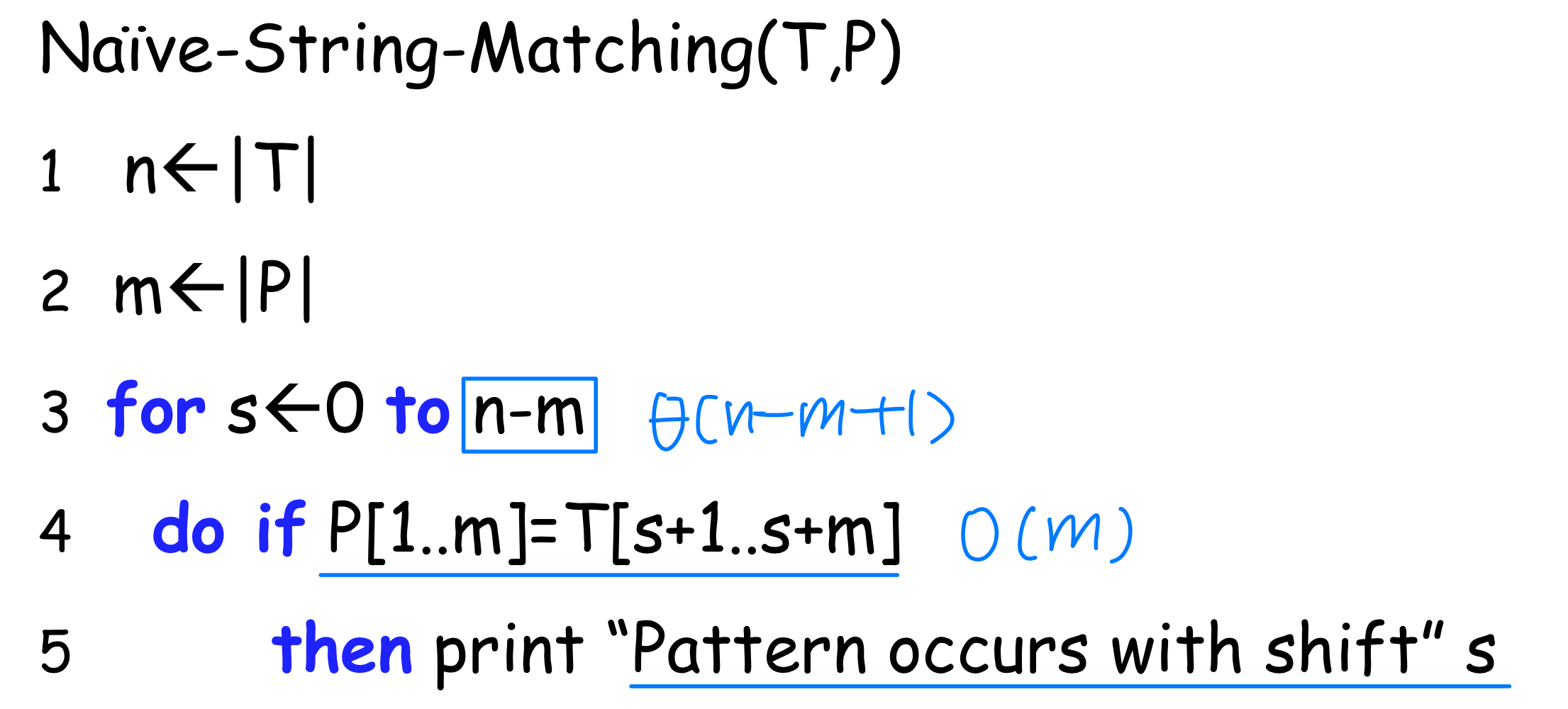
가장 직관적인 방법은 텍스트의 모든 가능한 위치에서 패턴을 하나씩 비교하는 것이다.
Naive 알고리즘의 문제점
시간 복잡도는 O((n-m+1)m) 이다. m이 n/2 수준이면 O(n) 까지 치솟는다.
이 알고리즘이 비효율적인 근본적 이유는, 어떤 시프트 s에서 텍스트와 비교하며 얻은 정보를 다음 시프트에서 전혀 활용하지 않기 때문이다.
예를 들어 P = "aaab"이고 s = 0에서 매칭에 실패했다면, 이미 비교 과정에서 T의 처음 몇 글자가 'a'라는 것을 알고 있다. 따라서 s = 1, 2, 3은 유효하지 않다는 것을 추가 비교 없이 알 수 있다. 하지만 Naive 알고리즘은 이 정보를 버리고 처음부터 다시 비교한다.
이 문제를 해결하기 위해 등장한 것이 아래의 알고리즘들이다.
Rabin-Karp 알고리즘
핵심 아이디어: 문자열을 숫자로 바꾸자
Rabin-Karp 알고리즘의 핵심 아이디어는 문자열 비교를 숫자 비교로 변환하는 것이다.
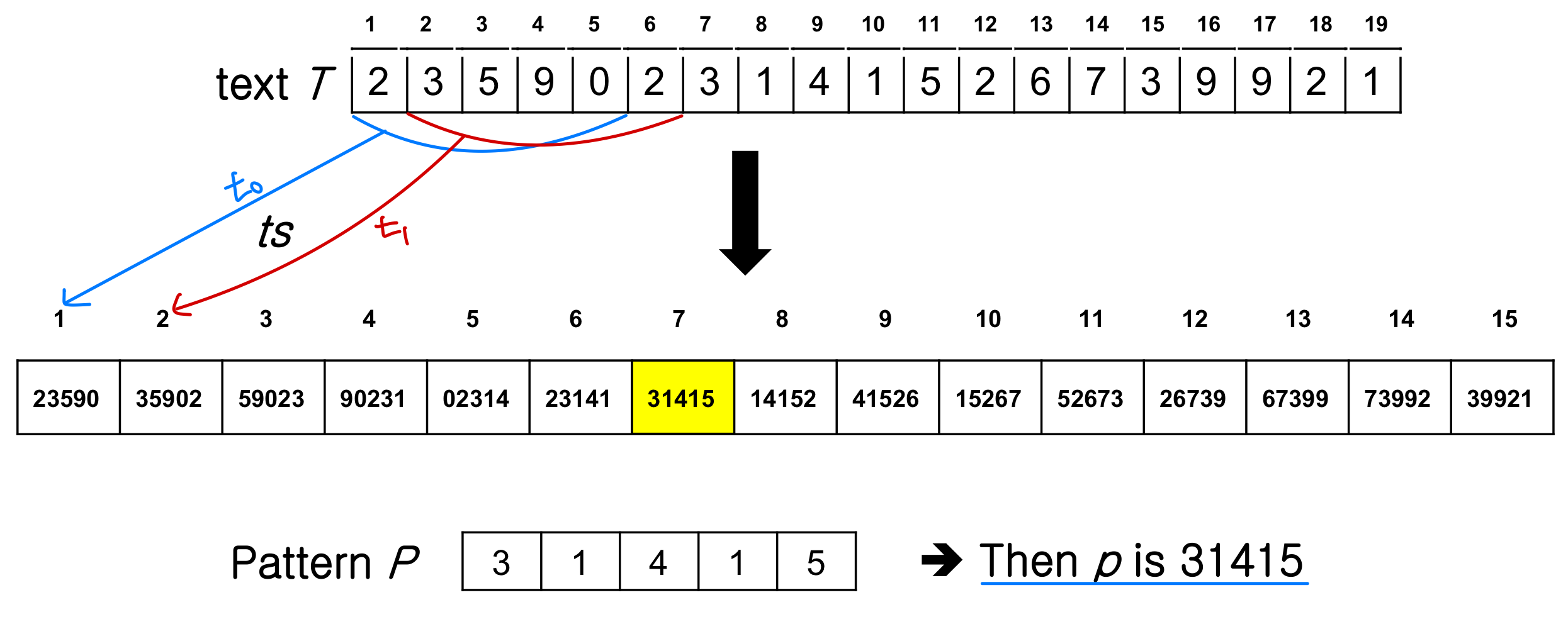
길이 m인 문자열을 m자리 d진법 숫자로 간주한다. 알파벳 = {0, 1, 2, ..., 9}인 경우, 패턴 P[1..m] = "31425"는 단순히 숫자 31,425가 된다.
마찬가지로 텍스트의 부분 문자열 T[s+1..s+m]도 숫자 로 변환한다. 이제 p = 이면 매칭이 성공한 것이다. 즉, 문자열 매칭 문제가 숫자 비교 문제로 바뀐다.
예제
문자열을 숫자로 변환하기
패턴 P를 숫자 p로 변환할 때는 Horner's Rule을 사용한다.
예를 들어 P[1..m] = "31425"이면, p = 5 + 10 * (2 + 10 * (4 + 10 * (1 + 10 * 3))) = 31,425 이다. 이 계산은 (m) 시간이 걸린다.
알파벳이 = {a, b, ..., z}인 경우에는 10 대신 26을 곱하면 된다.
슬라이딩 윈도우: 다음 해시값 빠르게 구하기
는 Horner's Rule로 계산하면 된다. 핵심은 을 로부터 (1)에 계산할 수 있다는 점이다.
이것은 숫자의 맨 앞 자릿수(최상위 자릿수)를 제거하고, 새로운 자릿수를 맨 뒤에 추가하는 것과 같다. 마치 슬라이딩 윈도우처럼 한 칸씩 밀어가며 숫자를 갱신하는 방식이다.
예를 들어 = 31415이고 T[s+5+1] = 2이면, = 10(31415 - 10000 * 3) + 2 = 14152 로, (1) 시간에 계산된다.
정리하면 다음과 같다.
- p와 계산: (m)
- , , ..., 계산: 각각 (1)이므로 총 (n-m), 즉 (n)
p와 t 비교: 모듈로 연산
한 가지 문제가 있다. m이 크면 p와 가 매우 큰 숫자가 되어 상수 시간에 비교할 수 없다.
해결책은 모듈로(modulo) 연산을 사용하는 것이다. p와 를 직접 비교하지 않고, 적당한 소수 q로 나눈 나머지를 비교한다.
하지만 이 방법은 완벽하지 않다. 라고 해서 반드시 인 것은 아니기 때문이다.
- 유효한 매칭(Valid): 이고
- 가짜 히트(Spurious hit): 이지만
- 반대로 이면 일 가능성은 전혀 없다
예를 들어, 67399 31415이지만 67399 31415 (mod 13)이다. 이처럼 나머지가 같더라도 실제 값이 다를 수 있으므로, 나머지가 일치하면 원래 문자열을 직접 비교하여 진짜 매칭인지 확인해야 한다.
알고리즘
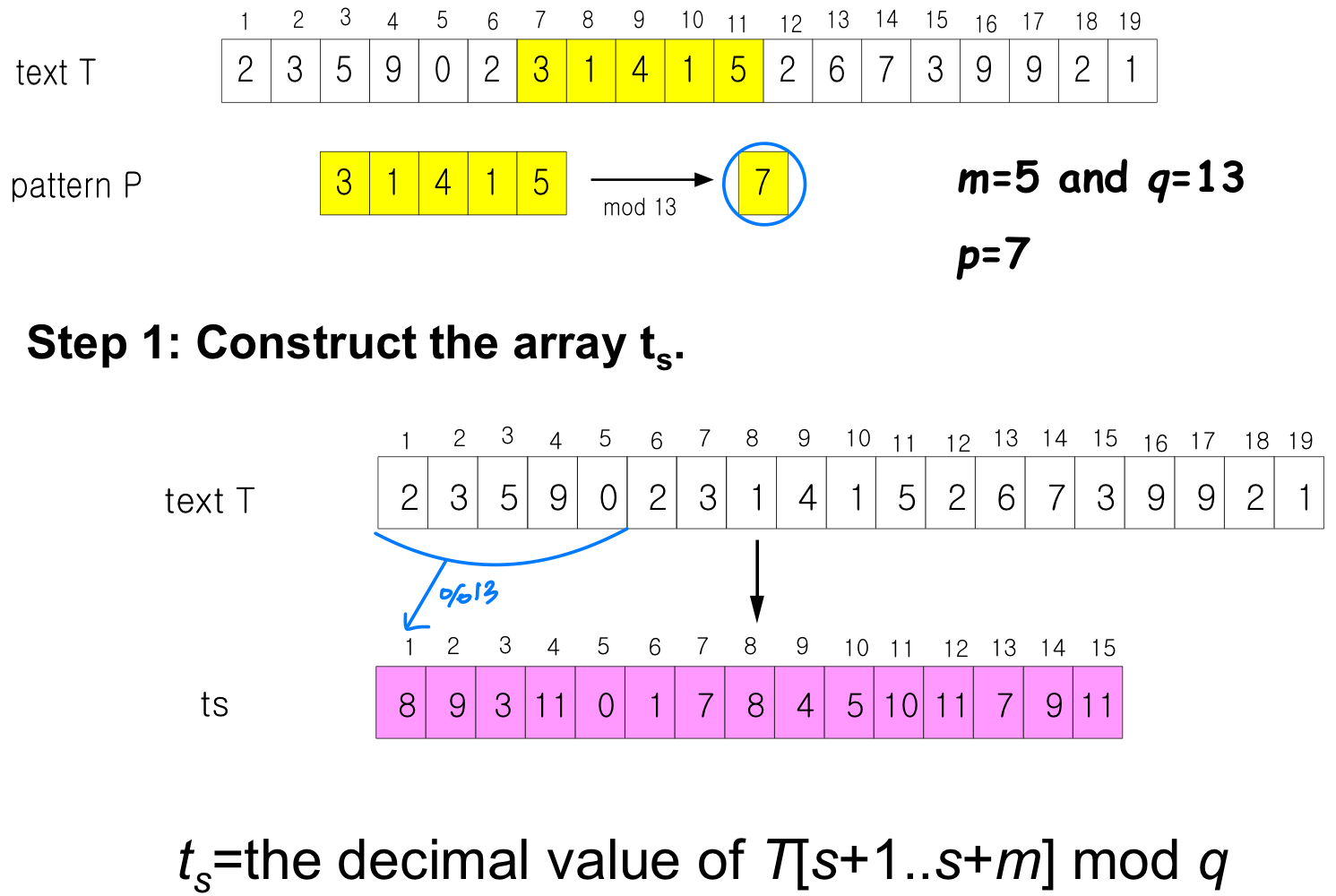
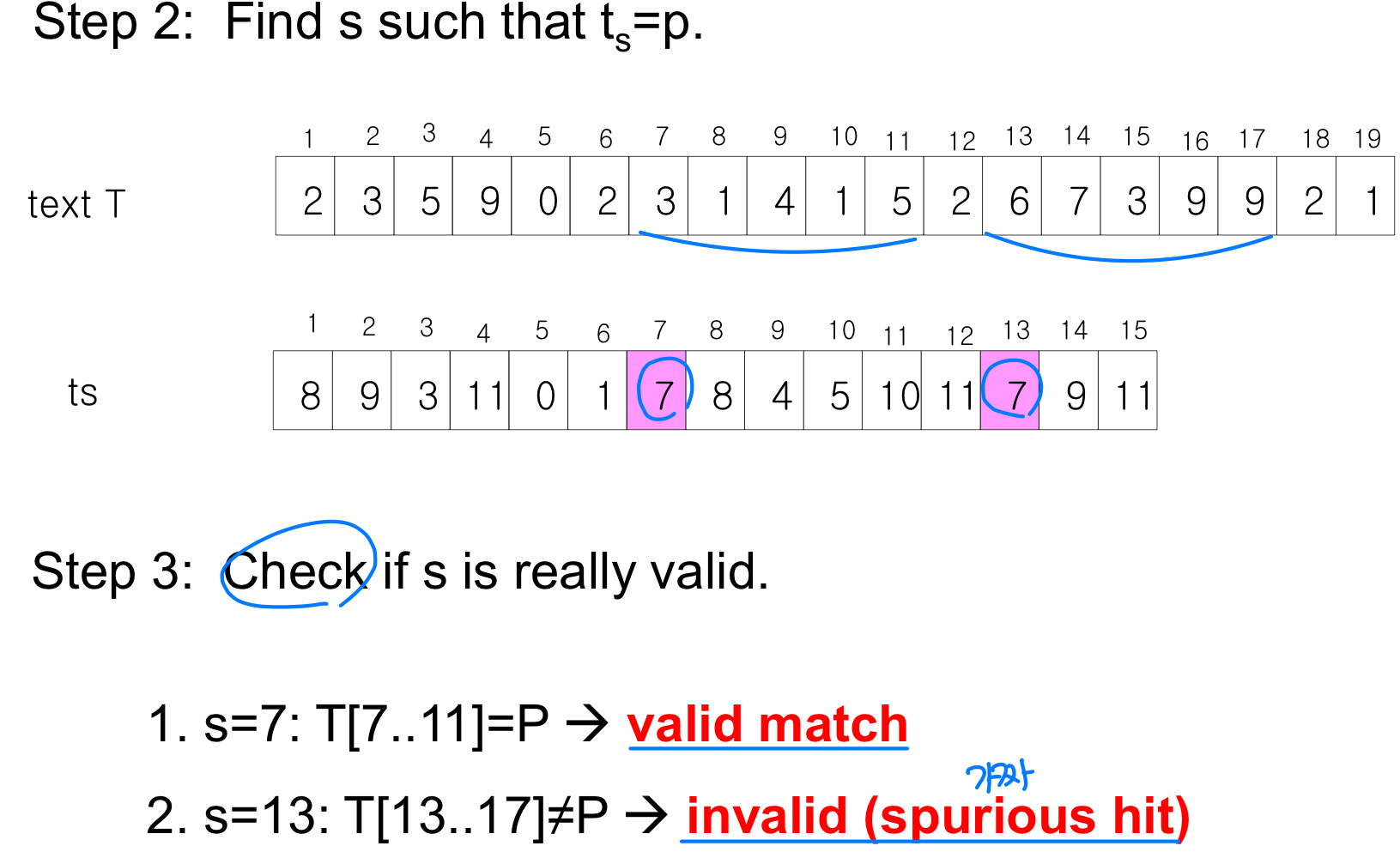
모듈로 연산 상세
q는 보통 소수(prime number) 로 선택하며, d진법 알파벳에서 d * q가 한 컴퓨터 워드에 딱 맞는 크기로 고른다.
모듈로를 적용한 재계산 공식은 다음과 같다.
여기서 h = mod q 이다. 이 계산은 (1) 시간에 수행된다.
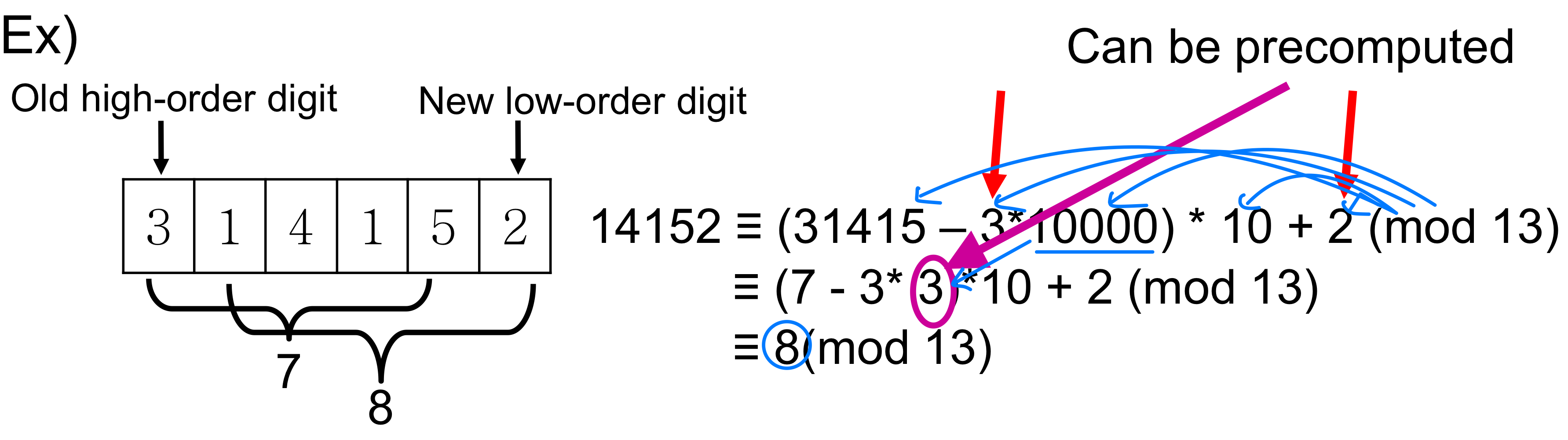
위 과정은 모두 상수 시간에 처리된다.
시간 복잡도 분석
- 전처리 시간: p와 계산에 (m)
- 최악의 경우(Worst case): 모든 위치에서 mod q 값이 동일하면 ((n-m+1)m)
- 유효한 시프트 s를 찾기 위해 (n-m+1) 번 비교
- 각 비교마다 실제 문자열 확인에 (m) 시간
하지만 실제로는 가짜 히트(spurious hit)가 거의 발생하지 않으므로, 평균적으로는 최악보다 훨씬 빠르게 동작한다.
유한 오토마타를 이용한 문자열 매칭
문자열 매칭 문제는 유한 오토마타(Finite Automaton) 로도 풀 수 있다. 패턴에 대응하는 오토마타를 구성하면, 텍스트를 한 글자씩 읽으며 상태를 전이하는 것만으로 매칭 여부를 판단할 수 있다.
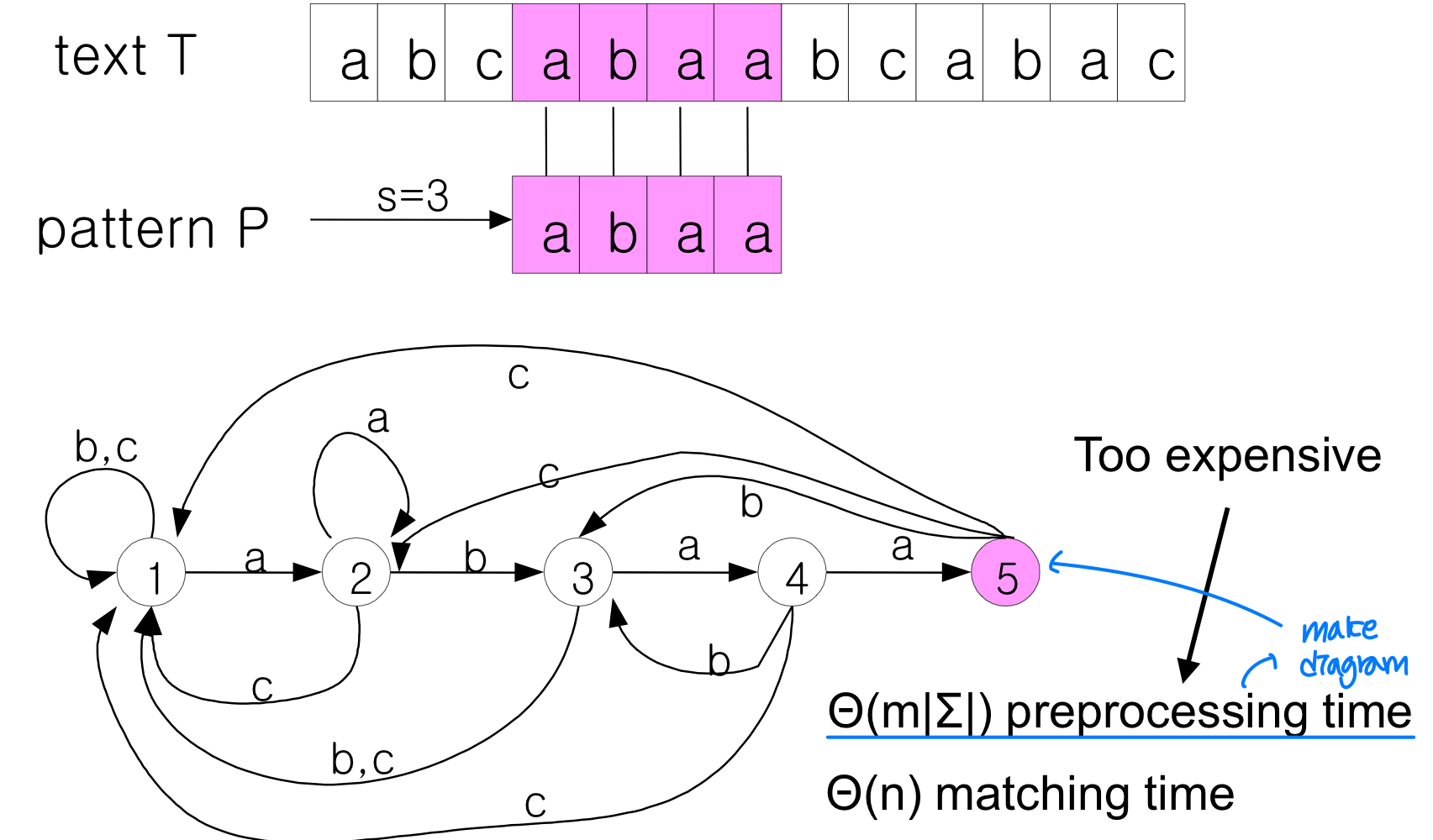
KMP (Knuth-Morris-Pratt) 알고리즘
KMP 알고리즘은 Naive 알고리즘의 핵심 약점인 "이미 알고 있는 정보를 버리는 문제" 를 정면으로 해결한다.
Naive 알고리즘의 재검토
Naive 알고리즘의 동작을 다시 살펴보자.
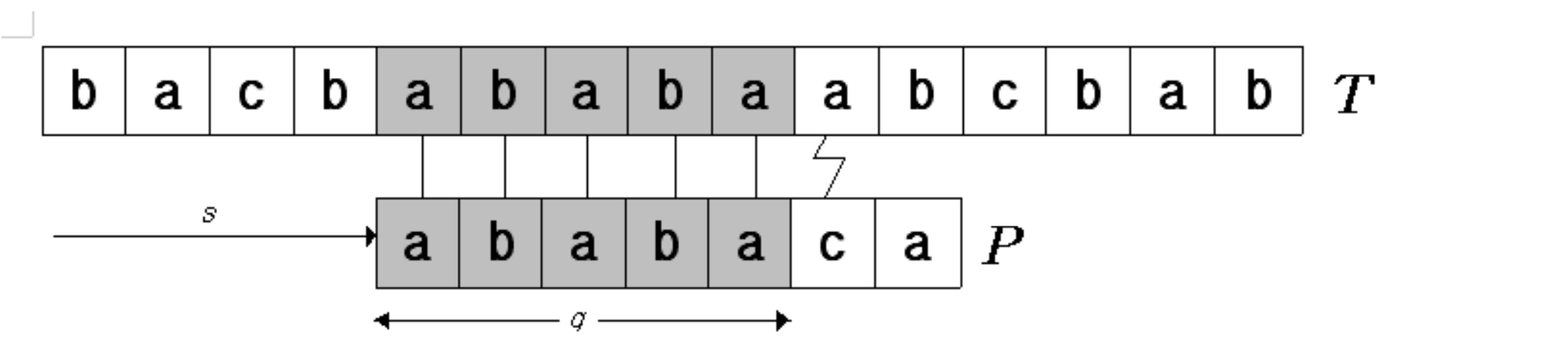
6번째 패턴 문자에서 매칭이 실패했다고 하자. 이때 어디서부터 매칭을 다시 시작해야 할까?
Naive 알고리즘은 바로 다음 문자부터 처음부터 다시 비교한다. 하지만 실제로는 그럴 필요가 없다.
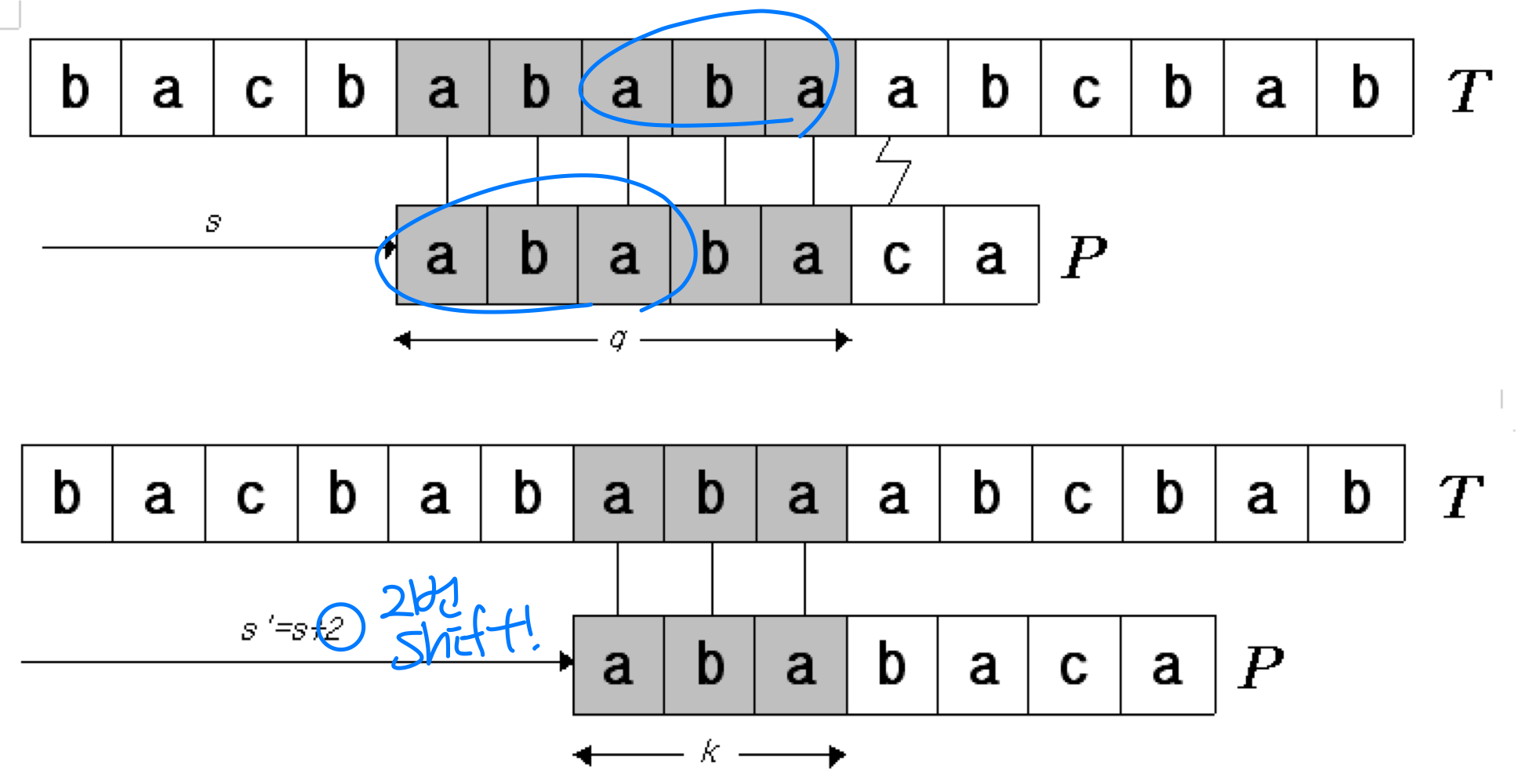
이미 일치한 부분 중에서, 패턴의 접두사(prefix)와 일치하는 접미사(suffix) 가 있다면 그 부분은 다시 비교할 필요가 없기 때문이다.
핵심 질문
일반적으로 다음 질문에 대한 답을 알면 된다.
패턴 문자 P[1..q] 가 텍스트 문자 T[s+1..s+q] 와 일치할 때, P[1..k] = T[s'+1..s'+k] 를 만족하는 최소 시프트 s' > s 는 무엇인가? (단, s' + k = s + q)
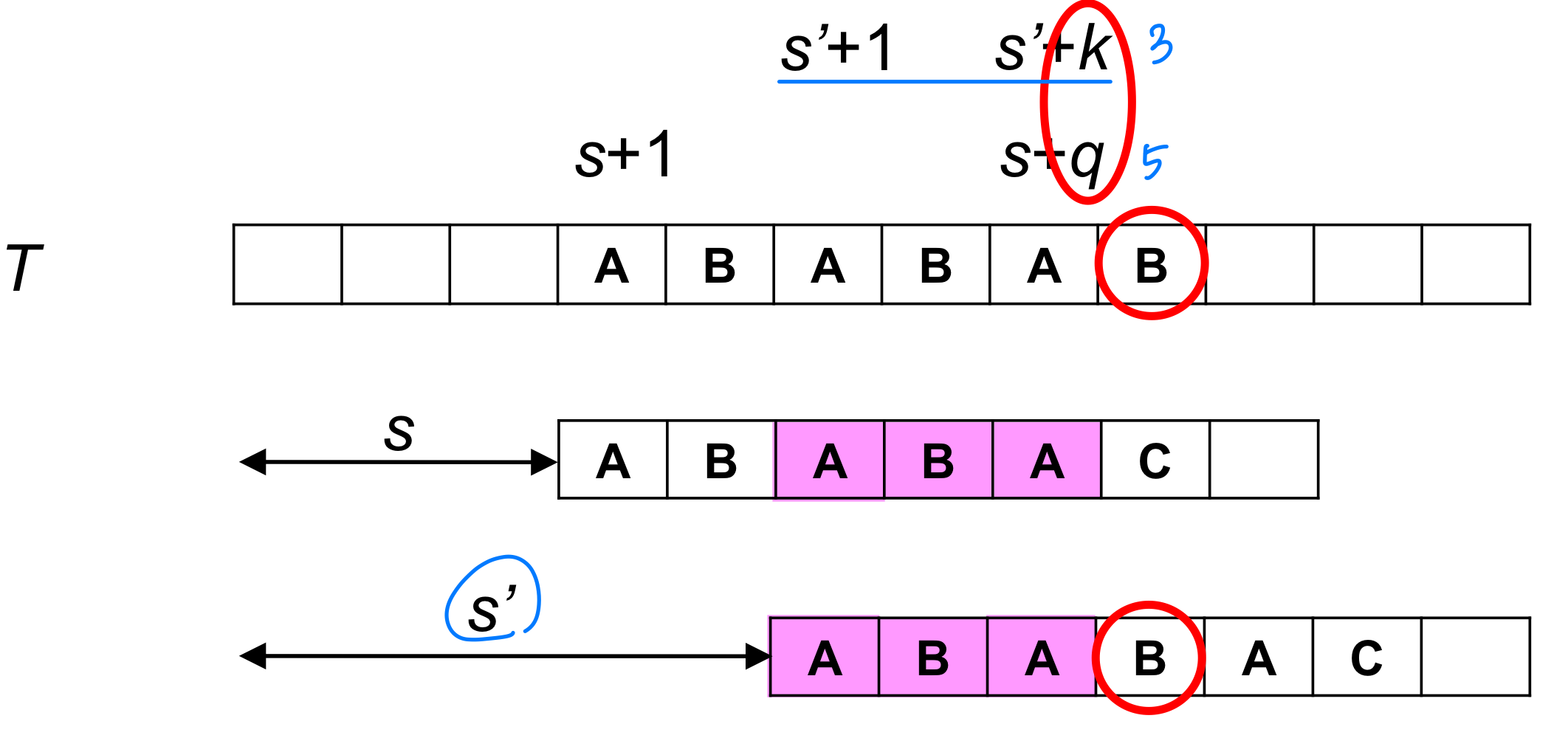
핵심적인 사실은, 이 필요한 정보를 텍스트 없이 패턴만으로 미리 계산할 수 있다는 점이다. 패턴을 자기 자신과 비교하여 접두사-접미사 관계를 파악하면 된다.
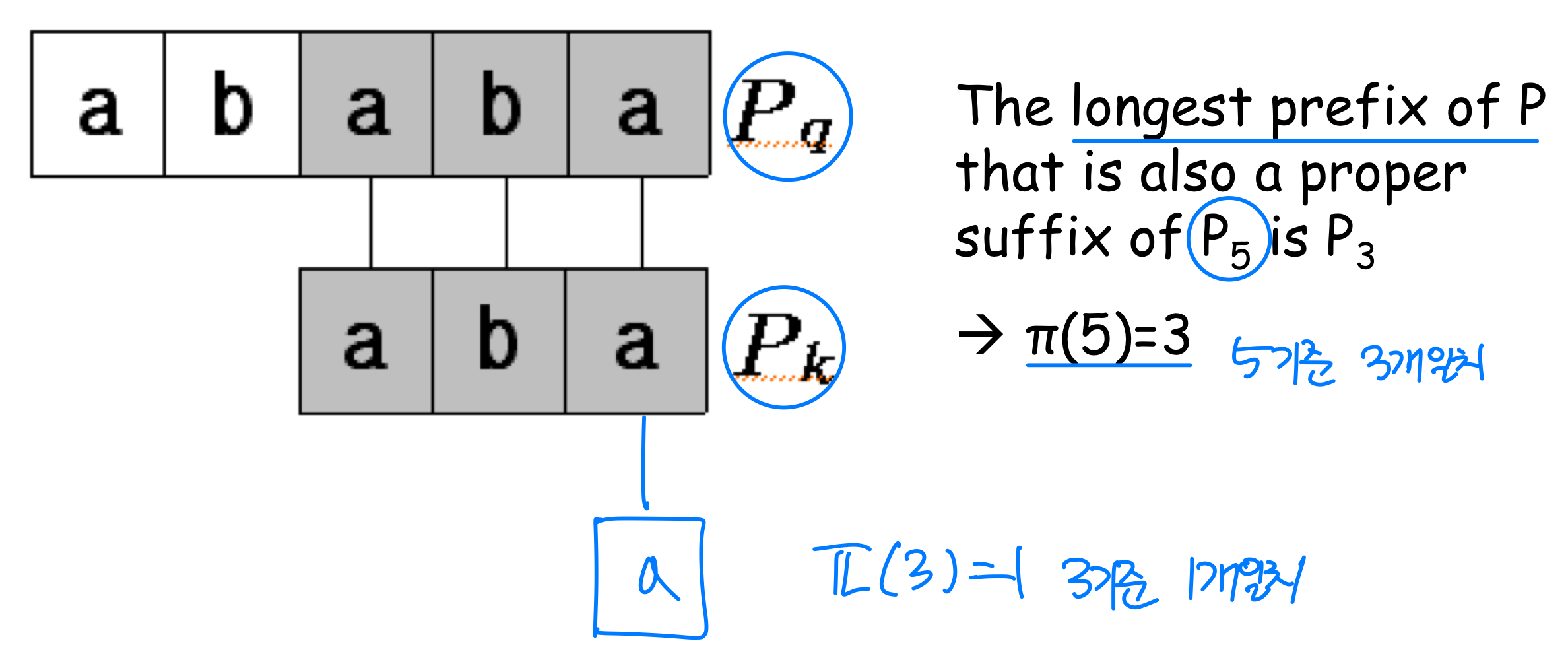
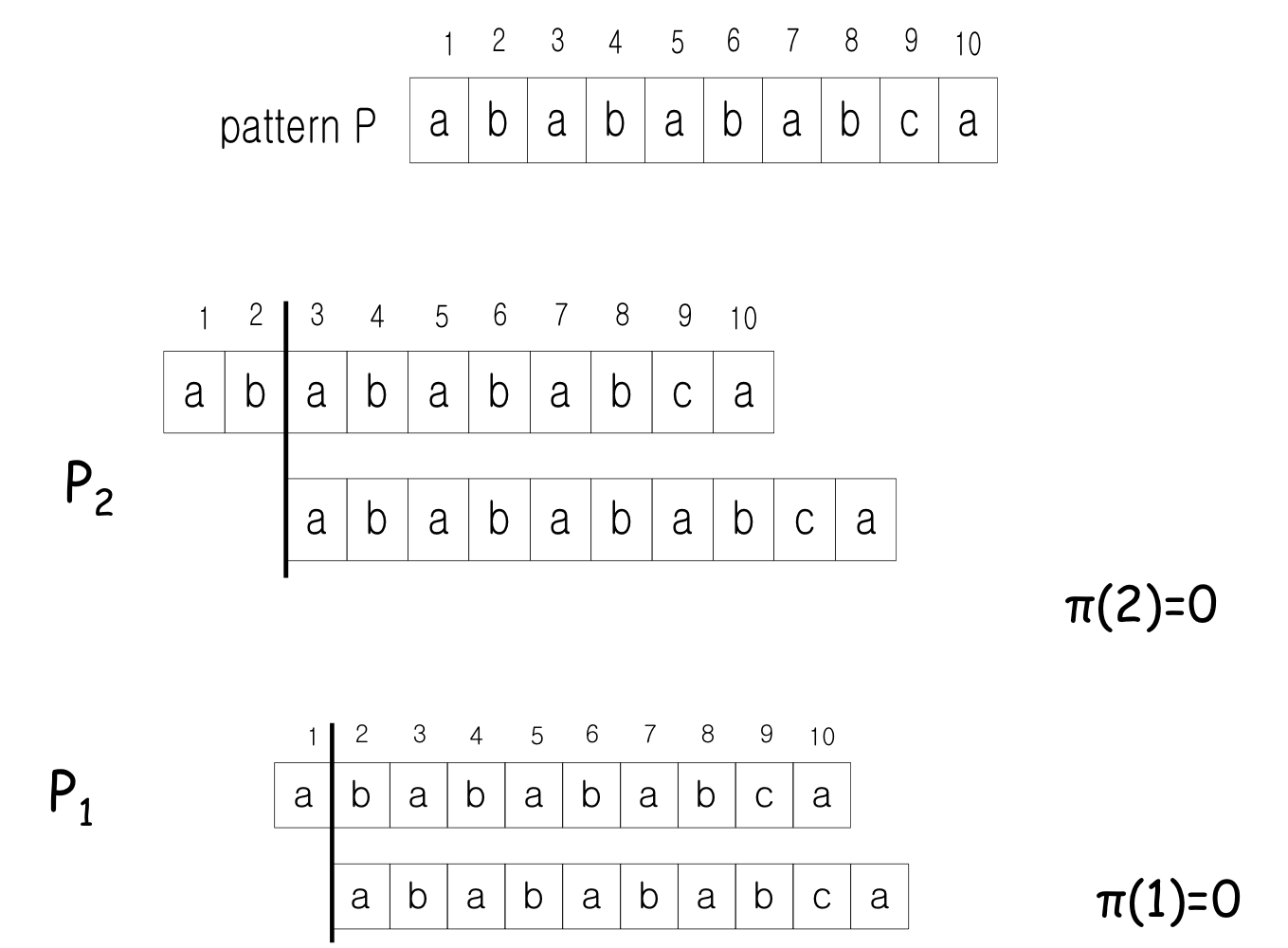
접두사 함수 (Prefix Function)
접두사 함수 는 KMP 알고리즘의 핵심이다. [q]는 P[1..q]의 진접두사(proper prefix)이면서 동시에 접미사(suffix)인 가장 긴 문자열의 길이를 나타낸다.
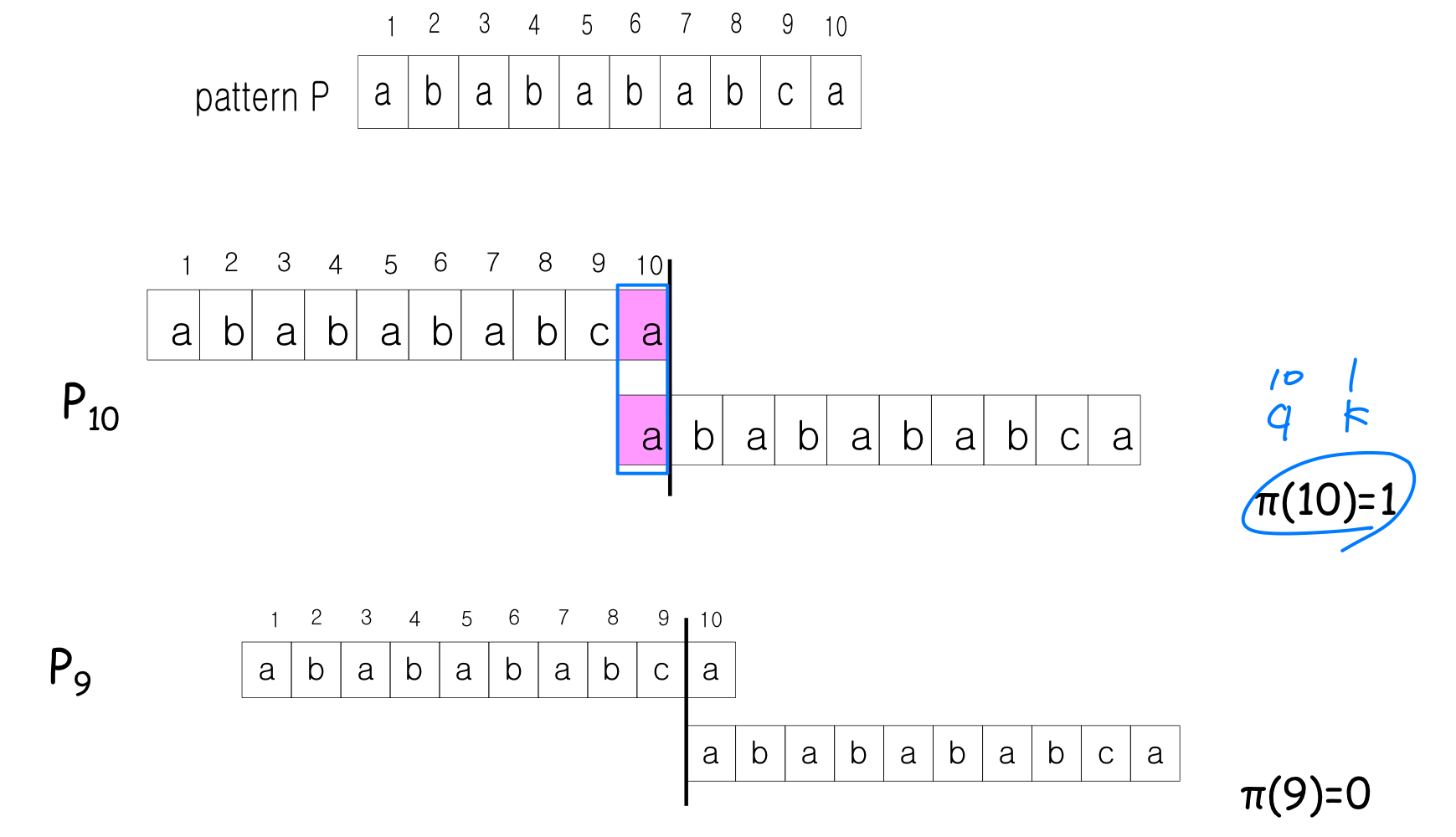
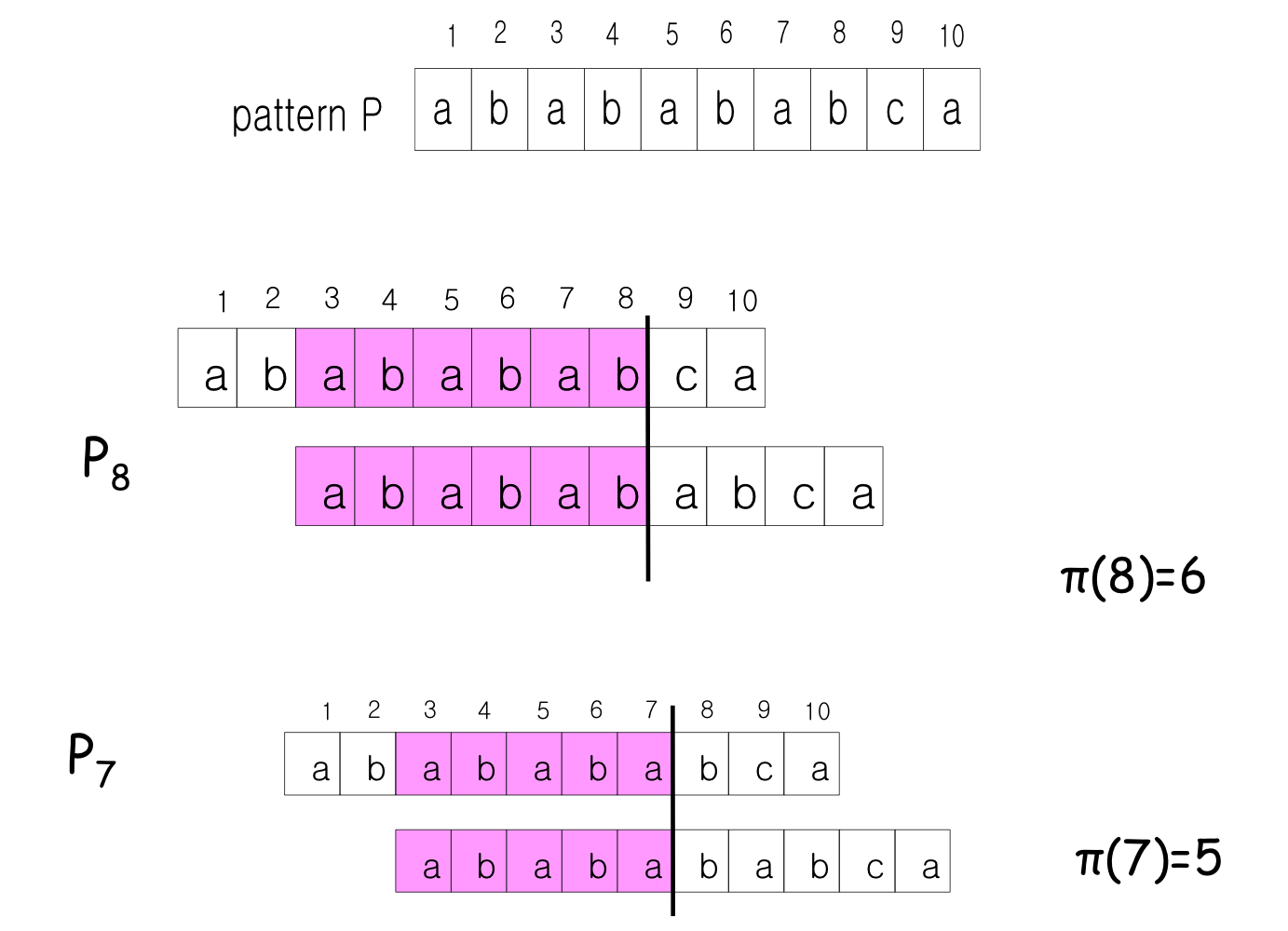
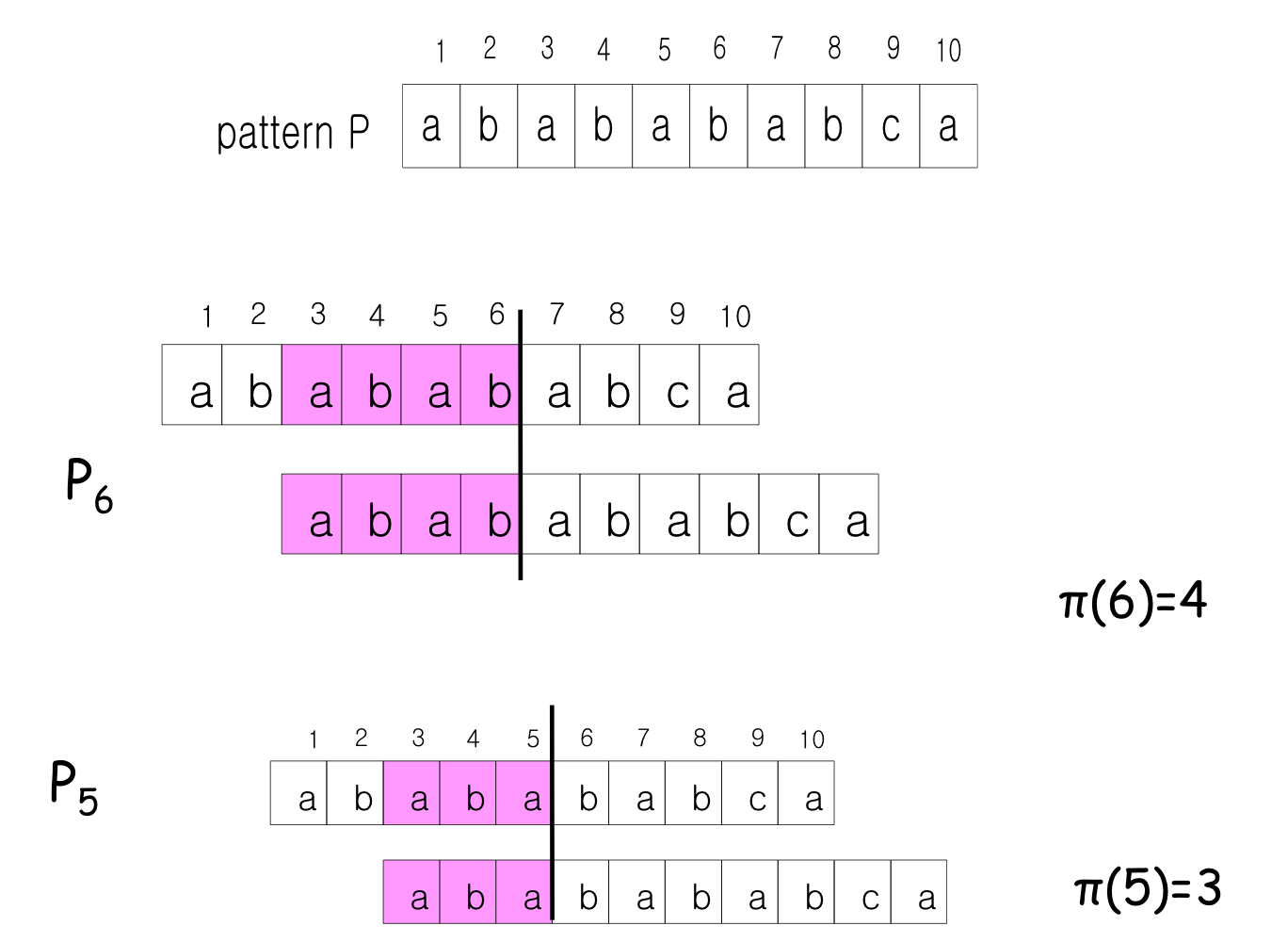
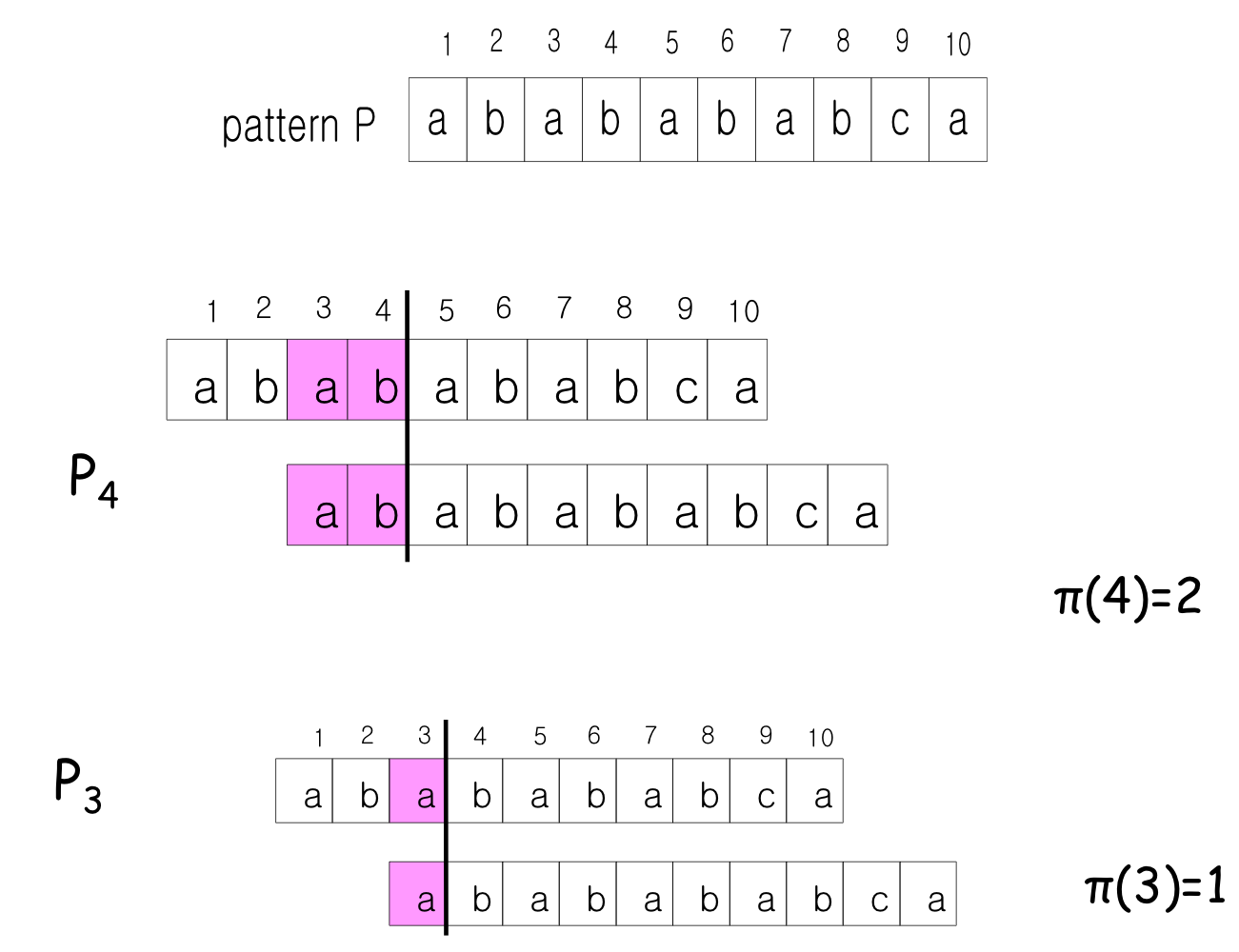
KMP 동작 예시
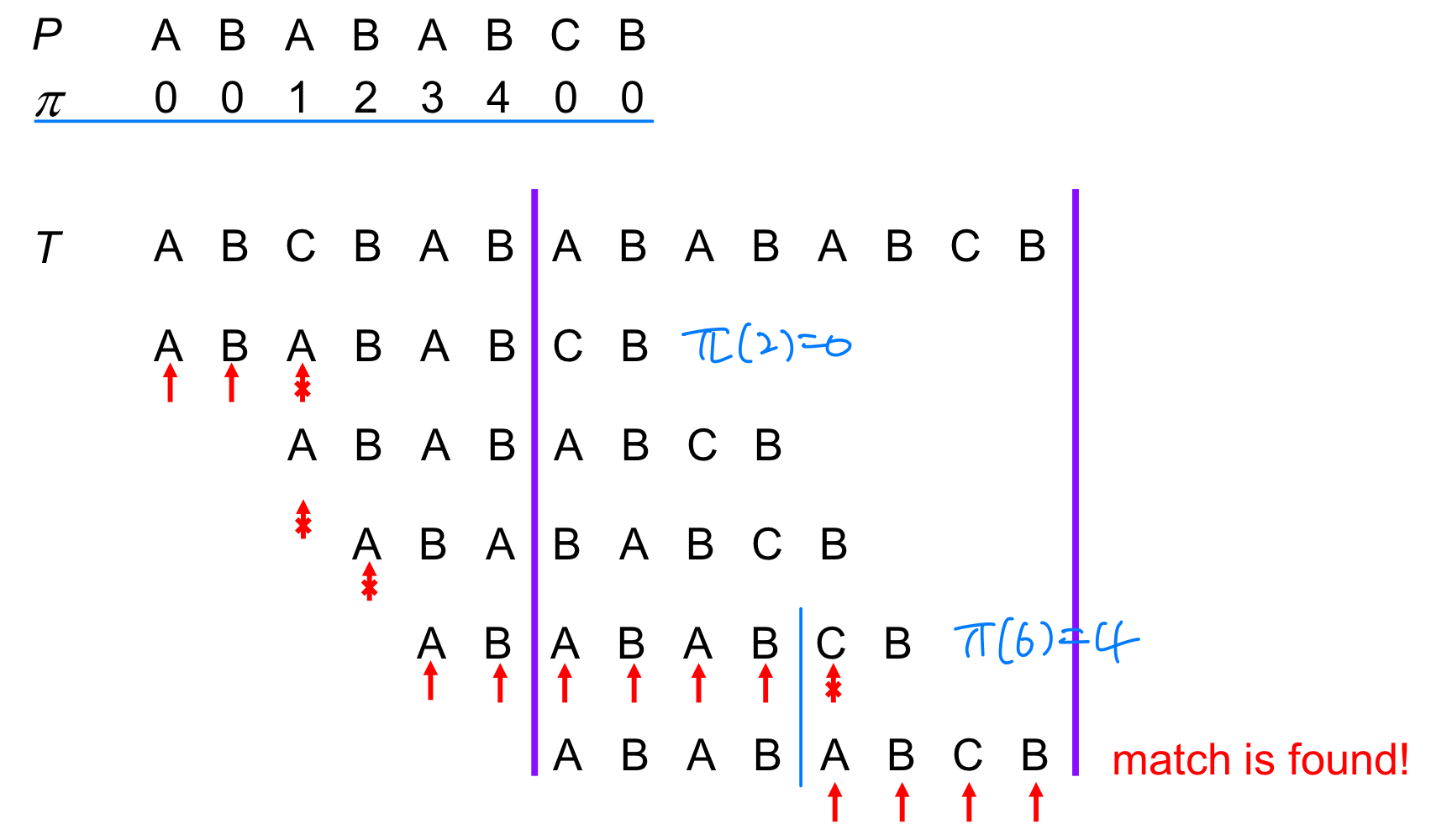
KMP 알고리즘은 매칭 과정에서 세 가지 경우를 처리한다.
Case 1: 패턴의 첫 번째 문자가 불일치
패턴의 첫 번째 문자가 텍스트 문자와 일치하지 않는 경우, 즉 P[1] T[i] 일 때, 패턴을 1칸 이동한다. 이는 텍스트 인덱스를 1 증가시키는 것과 같으며, 패턴 인덱스는 변하지 않는다.

Case 2: 첫 번째 이후 문자에서 불일치
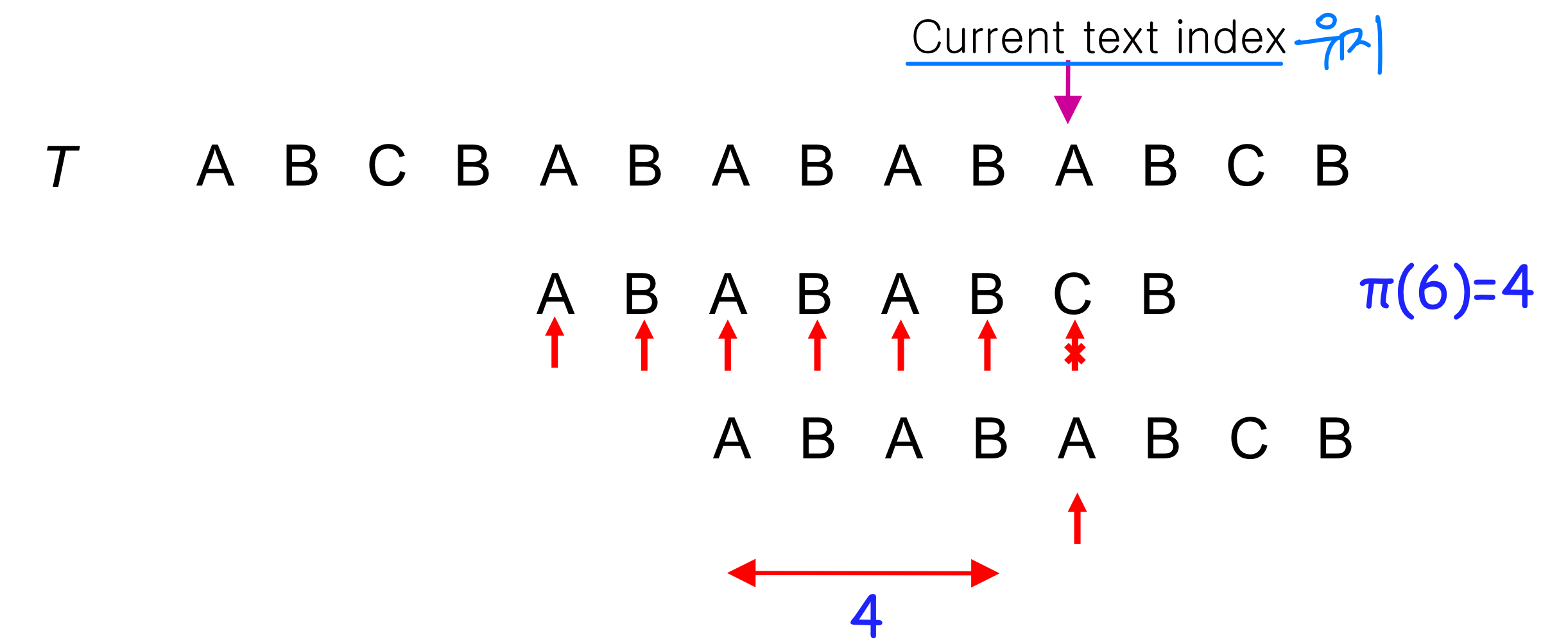
패턴의 첫 번째가 아닌 문자에서 불일치가 발생한 경우, 즉 P[q+1] T[i] 일 때, 접두사 함수 값만큼 패턴을 이동한다. 이미 비교된 접두사 부분은 다시 비교하지 않아도 된다.
Case 3: 문자가 일치
패턴 문자와 텍스트 문자가 일치하는 경우, 즉 P[q+1] = T[i] 일 때, 텍스트 인덱스와 패턴 인덱스를 모두 1 증가시킨다.

모든 패턴 문자가 일치하면 매칭 성공이다.
알고리즘

전체 실행 예시
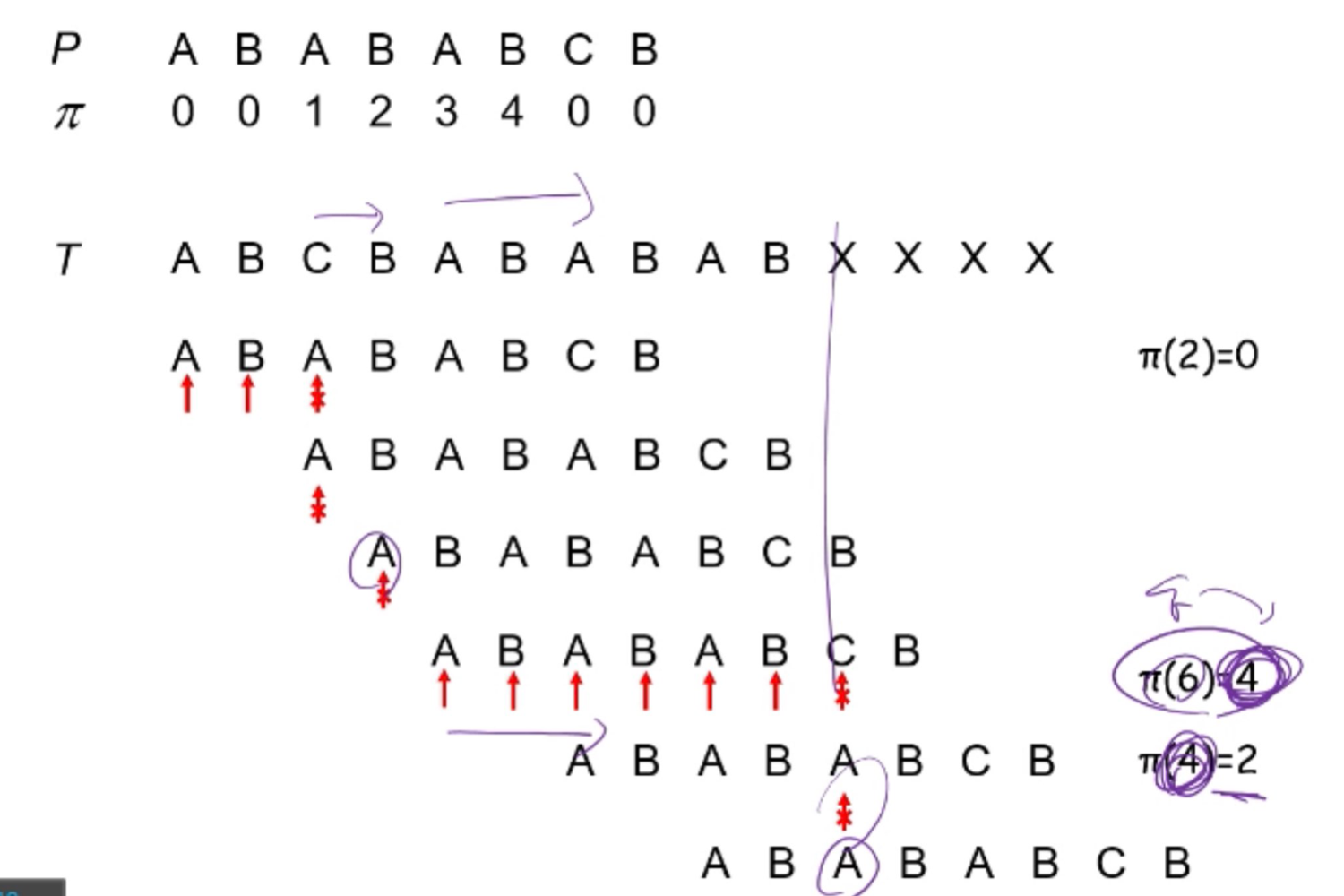
시간 복잡도
분할 상환 분석(Amortized Analysis)을 적용하면 다음과 같다.
- COMPUTE-PREFIX-FUNCTION: (m)
- KMP-MATCHER: (n)
Naive 알고리즘의 O(nm)과 비교하면 상당한 성능 향상이다. 텍스트를 한 번만 스캔하면서 패턴을 찾을 수 있다.
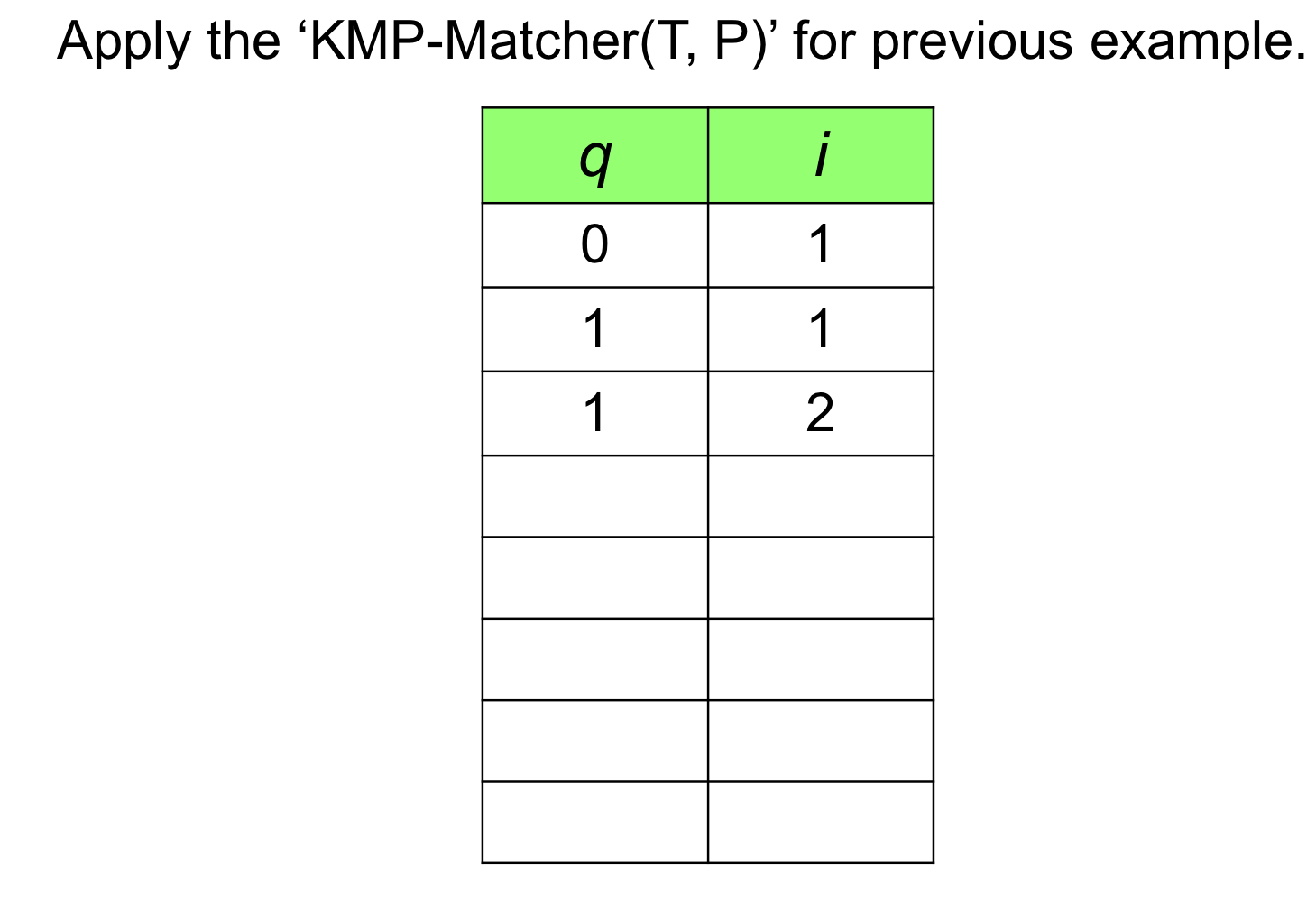
연습 문제
수업 연습 문제
1. Rabin-Karp에서의 spurious hit 개수
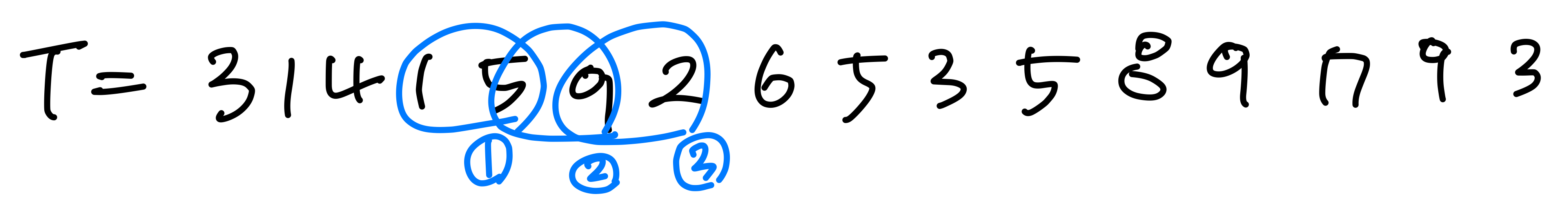
패턴 p = 26을 찾을 때, q = 11로 모듈로 연산을 수행한다. 26 % 11 = 4이므로, 나머지가 4인 위치를 모두 찾으면 4개이다. 이 중 실제로 26과 일치하는 것은 1개뿐이므로, spurious hit은 3개이다.
2. 접두사 함수 계산
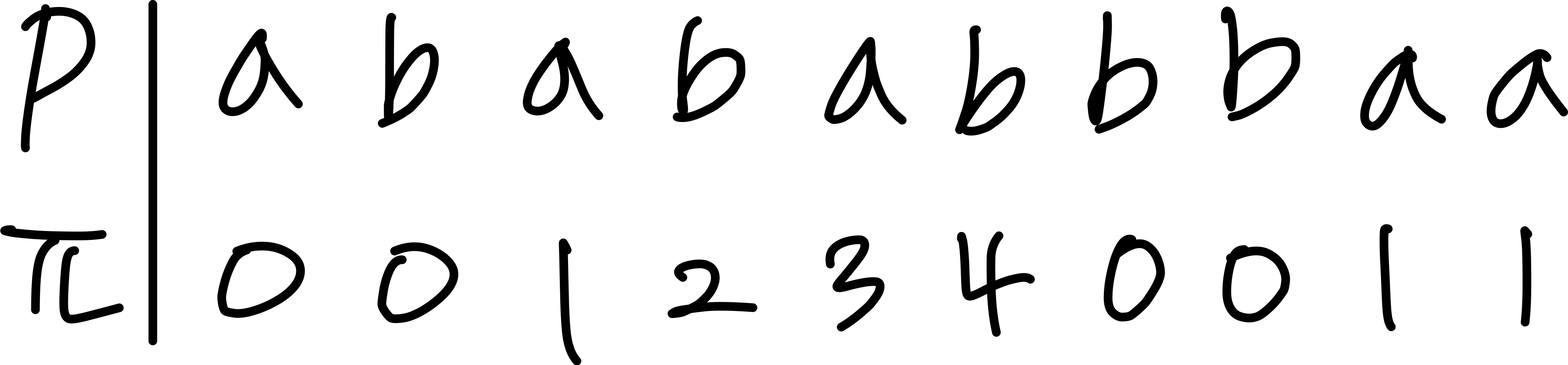
3. KMP 알고리즘 실행

HGU 전산전자공학부 용환기 교수님의 23-1 알고리듬 분석 수업을 듣고 작성한 포스트이며, 첨부한 모든 사진은 교수님 수업 PPT의 사진 원본에 필기를 한 수정본입니다.