순서 통계량(Order Statistics)이란?
n개의 원소로 이루어진 집합에서 i번째 순서 통계량(ith order statistic) 은 i번째로 작은 원소를 뜻한다. 단순하게 말하면, 원소를 오름차순으로 정렬했을 때 i번째에 위치하는 값이다.
- 최솟값(Minimum) 은 1번째 순서 통계량이다.
- 최댓값(Maximum) 은 n번째 순서 통계량이다.
- 중앙값(Median) 은 "가운데" 순서 통계량이다.
- n이 홀수이면**(n+1)/2** 번째 순서 통계량
- n이 짝수이면 하위 중앙값(lower median)은 n/2, 상위 중앙값(upper median)은**(n/2)+1** 번째 순서 통계량
정렬을 하면 모든 순서 통계량을 에 구할 수 있지만, 특정 하나의 순서 통계량만 필요하다면 정렬 없이도 더 빠르게 구할 수 있다. 이 글에서는 그 방법을 살펴본다.
최솟값과 최댓값을 동시에 구하기
입력으로 n개의 수가 주어졌을 때, 최솟값과 최댓값을 한 번에 구하려면 비교를 몇 번 해야 할까?
가장 단순한 방법은 각각 독립적으로 구하는 것이다. 최솟값을 구하는 데 n-1번, 최댓값을 구하는 데 n-1번, 총 2n-2번의 비교가 필요하다.
더 효율적인 방법이 있다. 핵심 아이디어는 원소를 min, max와 각각 따로 비교하지 말고, 쌍(pair)으로 묶어서 처리하는 것이다.
- 먼저 쌍의 두 원소를 서로 비교한다.
- 큰 쪽을 현재 max와 비교한다.
- 작은 쪽을 현재 min과 비교한다.
이렇게 하면 2개의 원소를 처리하는 데 3번의 비교만 필요하다.
n이 짝수인 경우: 처음 두 원소를 비교하여 큰 값을 max, 작은 값을 min으로 초기화한다. 이후 나머지 원소를 쌍으로 처리하면, 1 + 3(n-2)/2 = 3n/2 - 2번 비교로 충분하다.
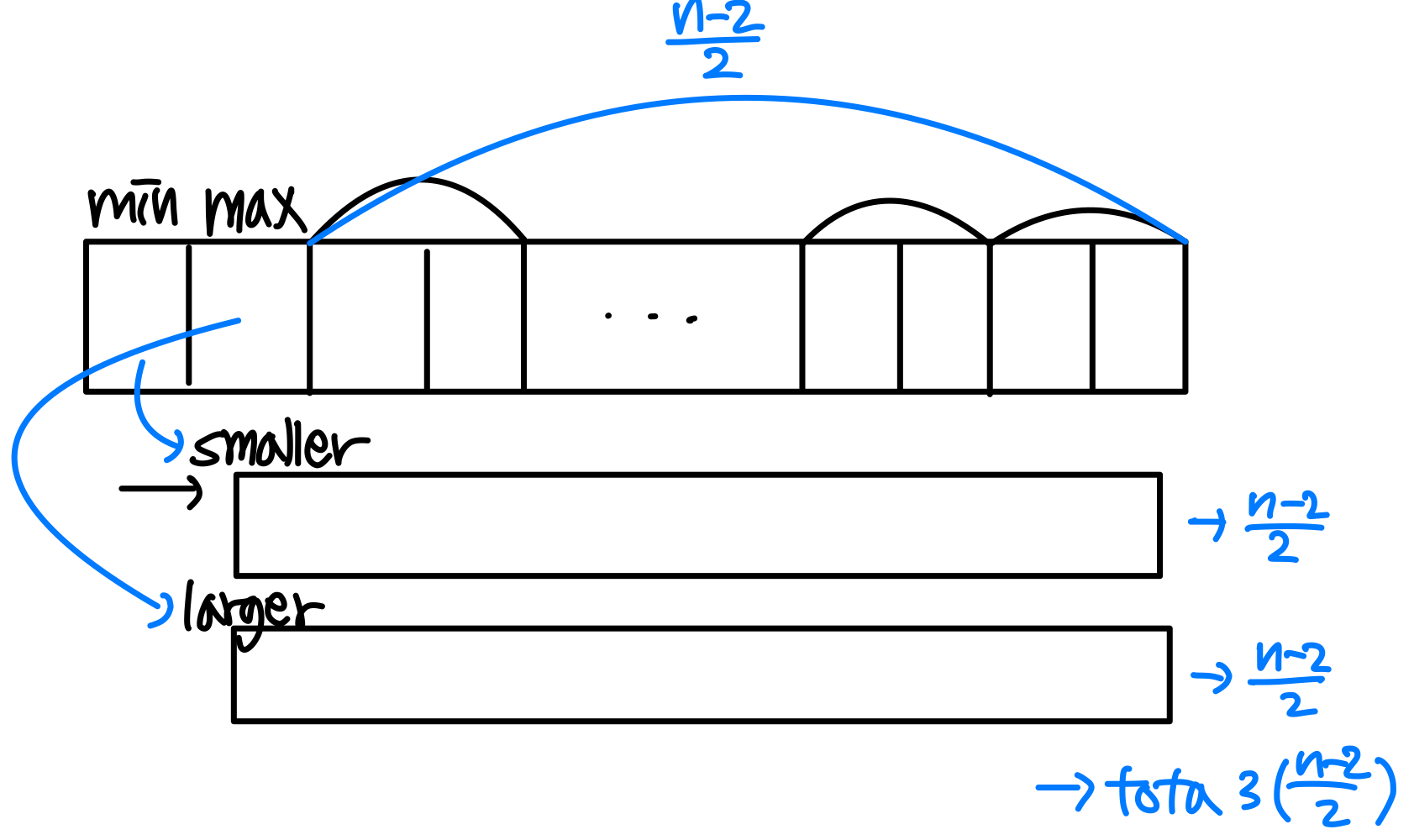
n이 홀수인 경우: 첫 번째 원소를 min과 max 모두로 초기화한 뒤, 나머지를 쌍으로 처리한다. 총 3(n-1)/2번 비교가 필요하다.
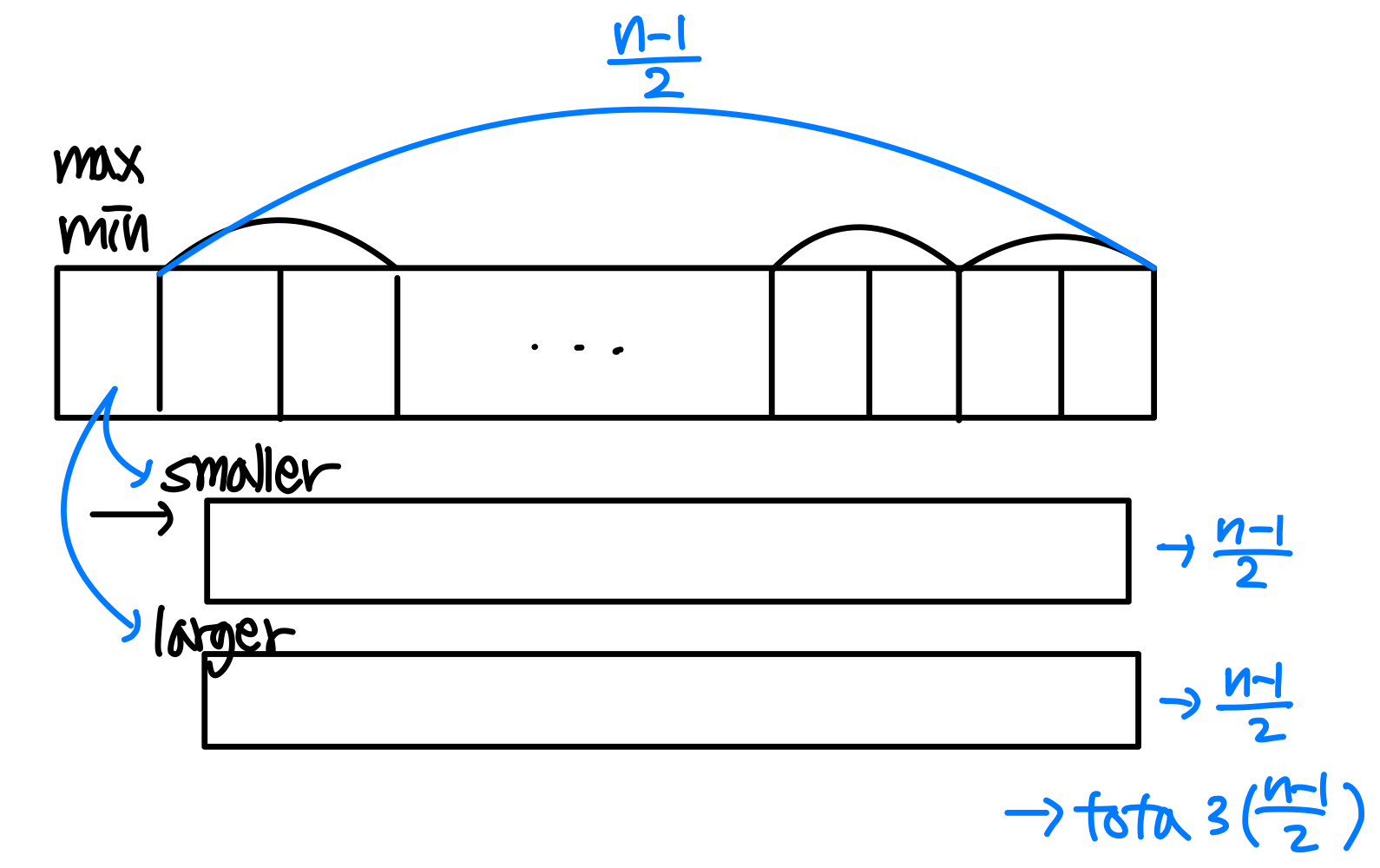
단순 접근의 2n-2번과 비교하면, 약 25% 정도 비교 횟수가 줄어든다.
선택 문제(Selection Problem)
min이나 max를 찾는 것은 특수한 경우일 뿐이다. 더 일반적인 문제는 i번째로 작은 원소를 찾는 선택(Selection) 문제다.
- 입력: n개의 (서로 다른) 원소로 이루어진 집합 A와, 1 ≤ i ≤ n인 정수 i
- 출력: A에서 정확히 i-1개의 원소보다 큰 원소 x, 즉 i번째로 작은 원소

이 문제를 해결하는 두 가지 알고리즘을 살펴본다.
- Randomized Select: 실용적인 랜덤 알고리즘. 기대 시간 복잡도
- Worst-case Linear-Time Select: 이론적으로 흥미로운 알고리즘. 최악의 경우에도
Randomized Select
핵심 아이디어
Quicksort에서 사용하는 partition() 을 그대로 활용한다. 다만 Quicksort와 달리 한쪽 부분 배열만 재귀적으로 탐색하면 되므로, 양쪽을 모두 처리할 필요가 없다. 이 절약이 시간 복잡도를 으로 끌어내린다.
동작 과정
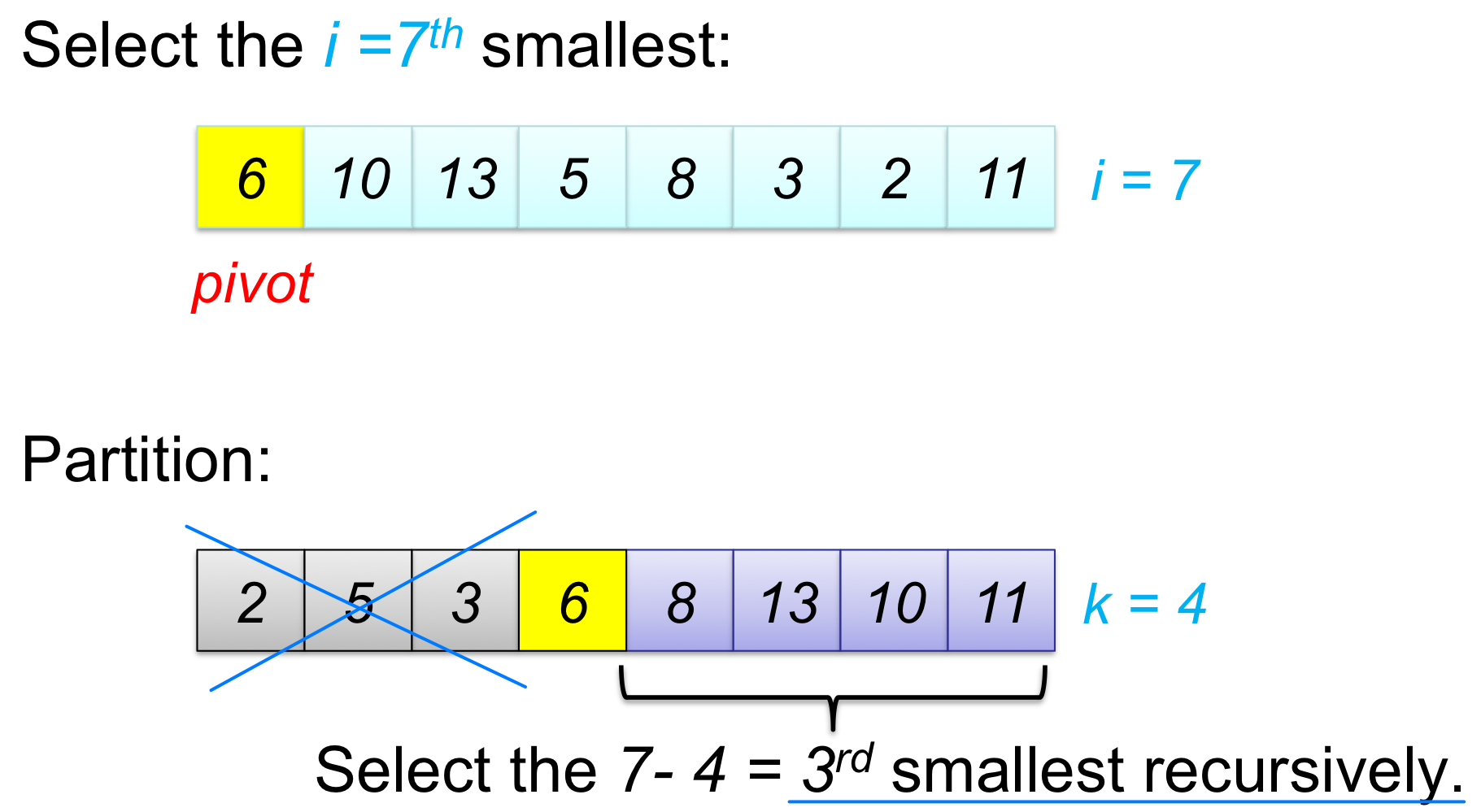
배열 A[p..r]을 partition하면 피벗 A[q]를 기준으로 두 부분 배열 A[p..q-1]과 A[q+1..r]이 만들어진다. 피벗이 p번째부터 세었을 때 k번째라 하면:
- i = k 이면: A[q]가 바로 답이다. 반환한다.
- i < k 이면: 답은 왼쪽 부분 배열 A[p..q-1] 에 있다. 이쪽에서 i번째를 찾는다.
- i > k 이면: 답은 오른쪽 부분 배열 A[q+1..r] 에 있다. 이쪽에서**(i-k)번째**를 찾는다.

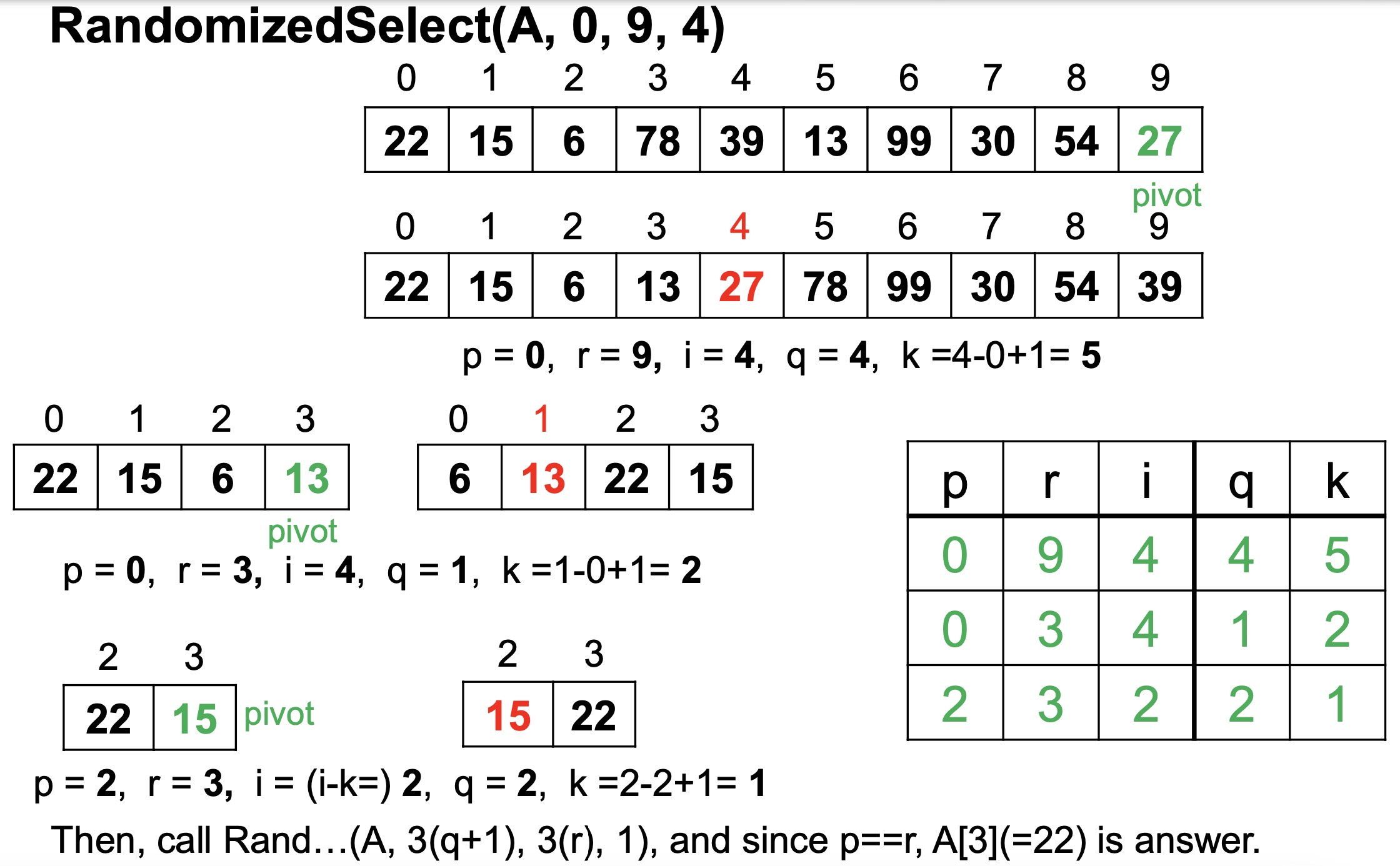
예시
코드

시간 복잡도 분석
아래 분석은 모든 원소가 서로 다르다는 가정 하에 진행한다.




Randomized Select는 기대 시간 복잡도가 이다. 실무에서 매우 잘 동작하는 알고리즘이지만, 최악의 경우(매번 가장 불균형한 partition이 발생하면)에는 까지 떨어질 수 있다.
최악의 경우에도 선형 시간: Worst-case Linear-Time Selection
Randomized Select는 실무에서 잘 동작하지만, 최악의 경우 시간 복잡도가 라는 한계가 있다. 이를 보완한 것이 Worst-case Linear-Time Selection 알고리즘이다. 최악의 경우에도 을 보장하지만, 상수 계수가 크기 때문에 실제로는 이론적 관심에 그친다.
핵심 아이디어는 partition의 피벗으로 항상 좋은 분할을 보장하는 원소를 선택하는 것이다.
알고리즘 단계

Step 1. n개의 원소를 5개씩 그룹으로 나눈다 (마지막 그룹은 5개 미만일 수 있다).
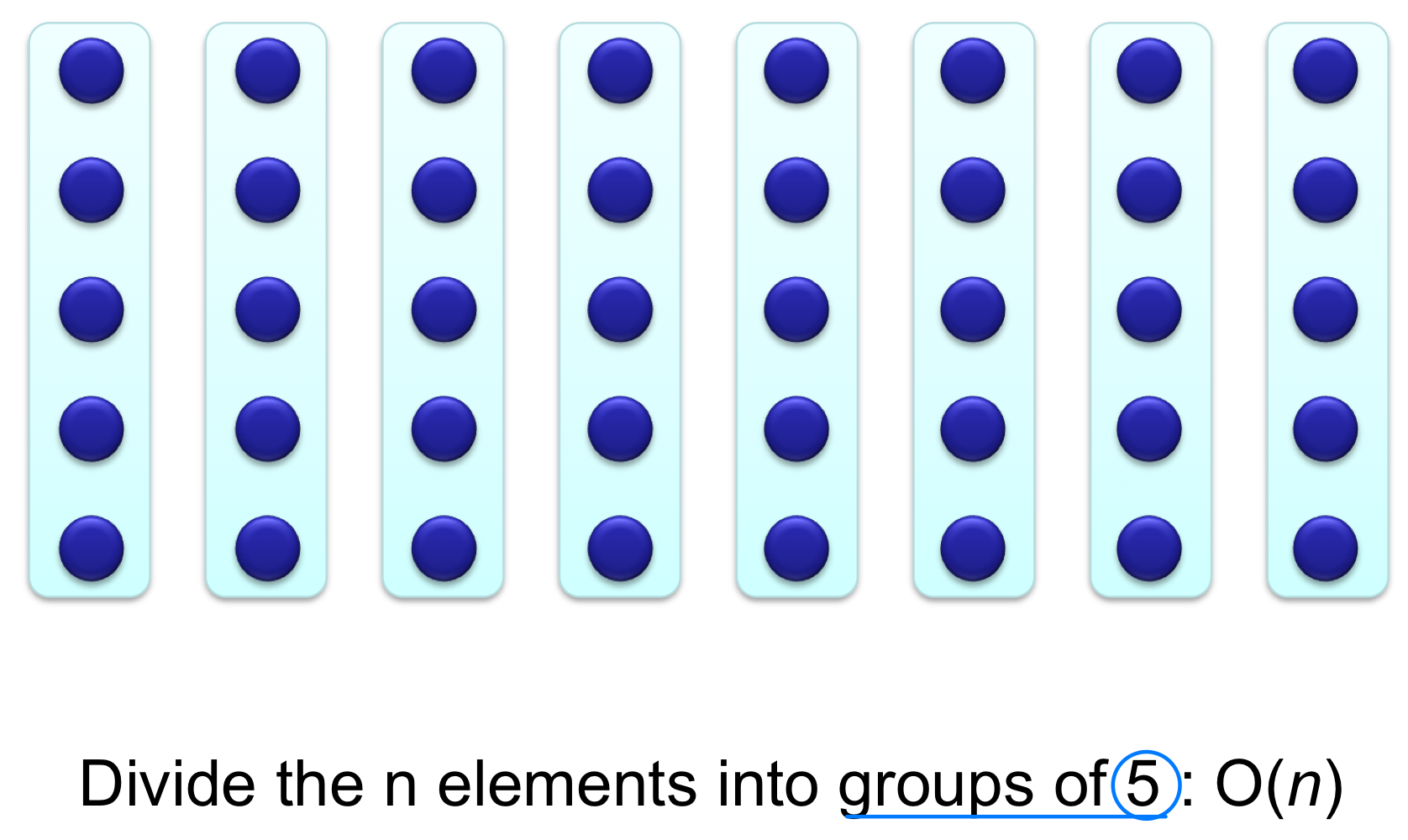
Step 2. 각 그룹을 정렬하여 중앙값(Median) 을 구한다. 5개 원소의 정렬은 상수 시간이므로, 전체적으로 시간이 걸린다.
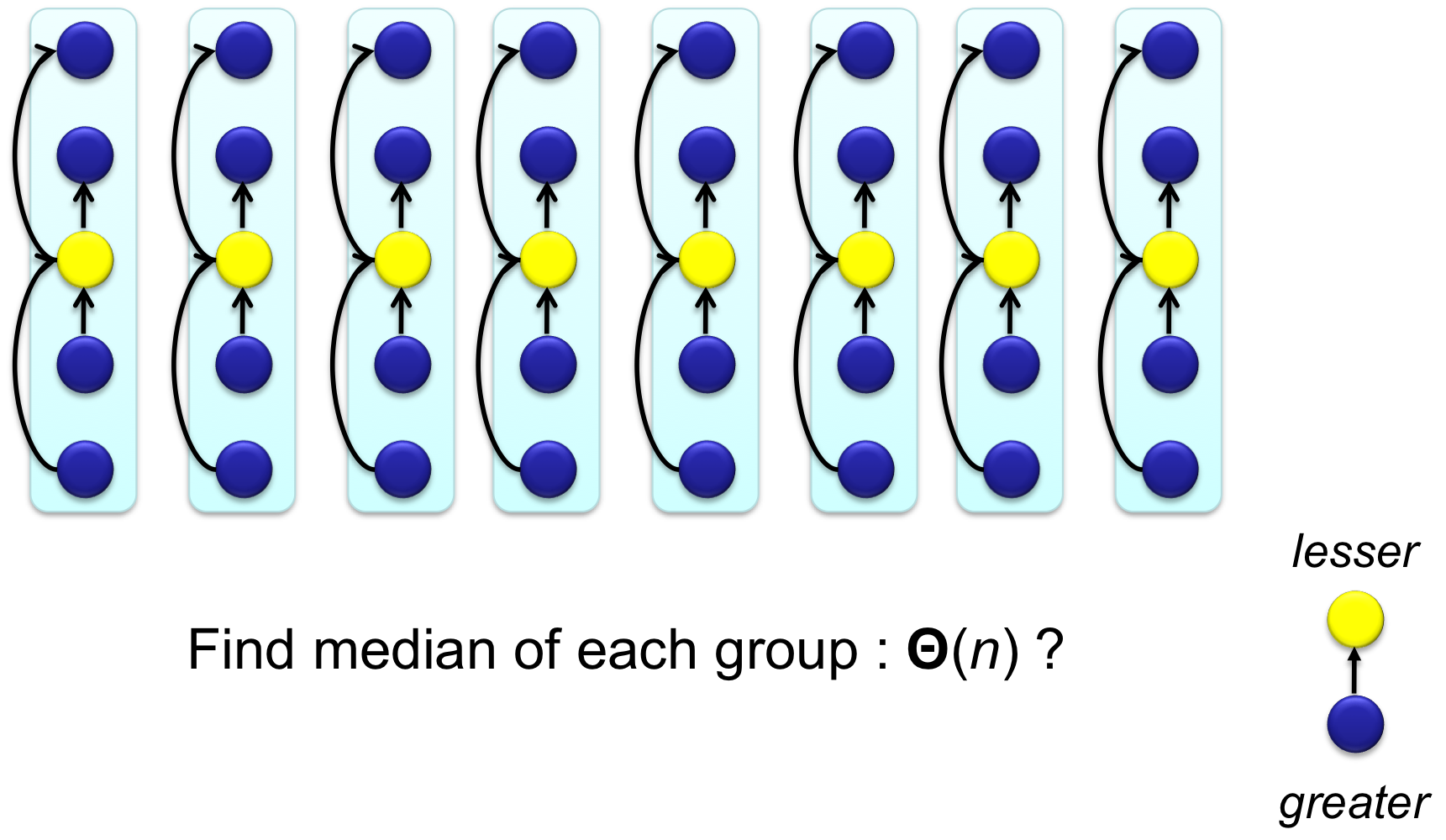
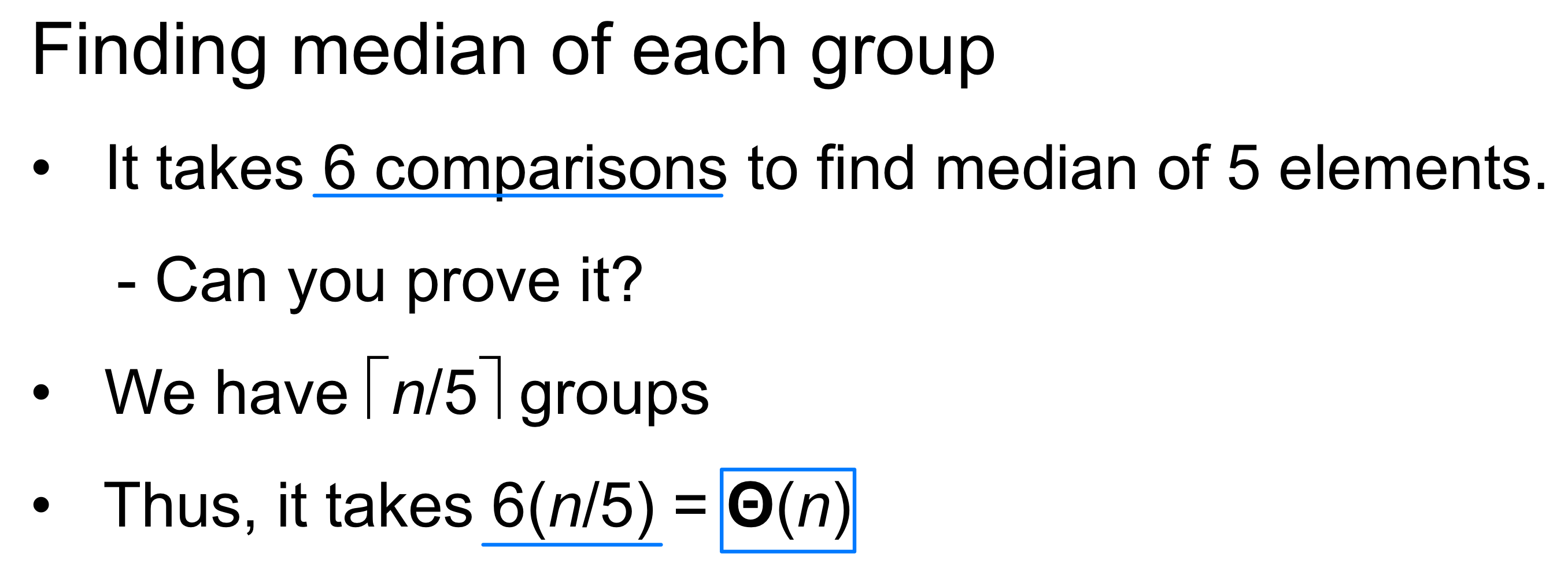
Step 3. 이 중앙값들의 중앙값(Median of Medians) 을 재귀적으로 구한다. 이것이 피벗 x가 된다.
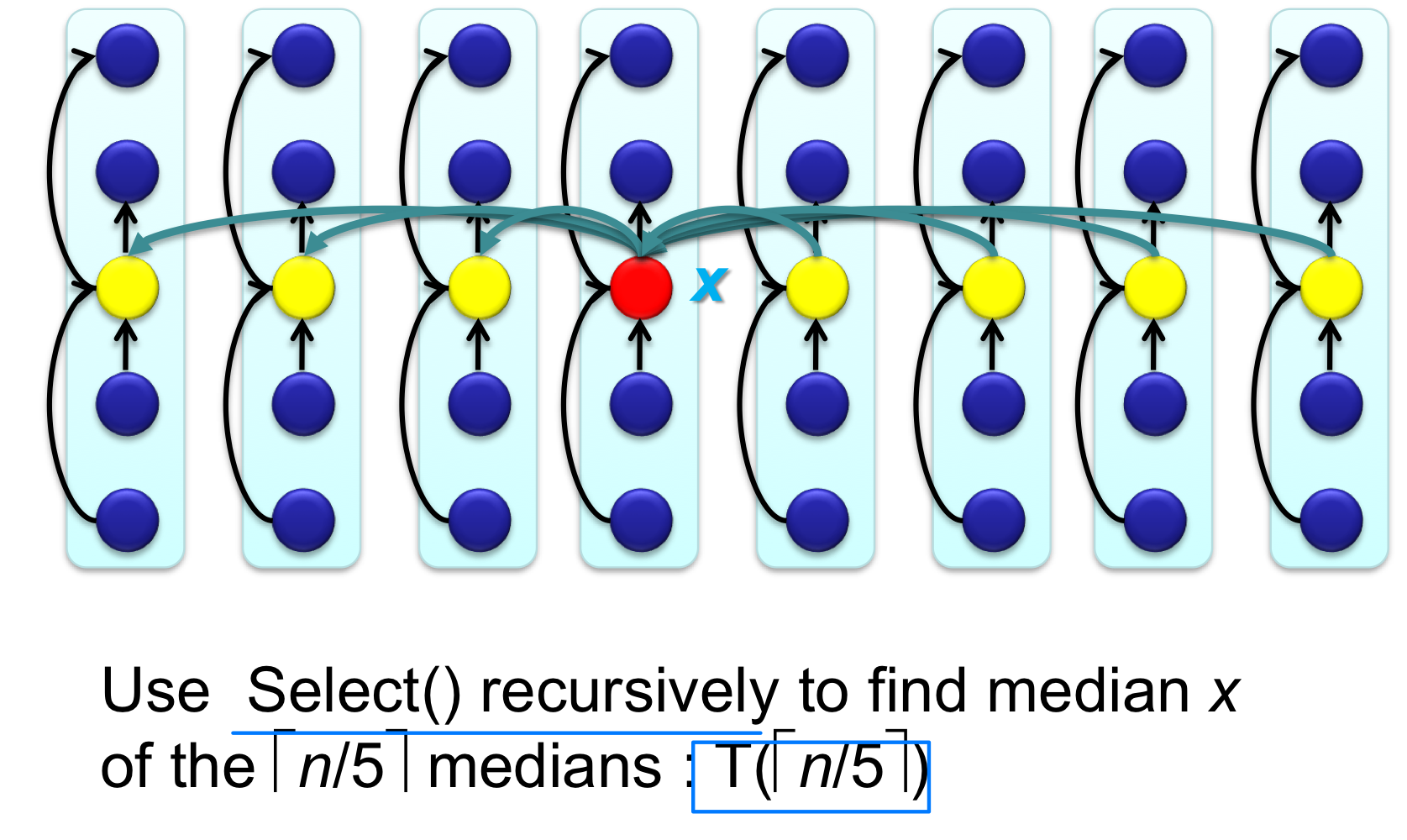
Step 4. x를 피벗으로 partition한 뒤, Randomized Select와 동일한 방식으로 재귀한다.
피벗의 품질
이렇게 구한 피벗 x가 왜 좋은 분할을 보장하는지 살펴보자.
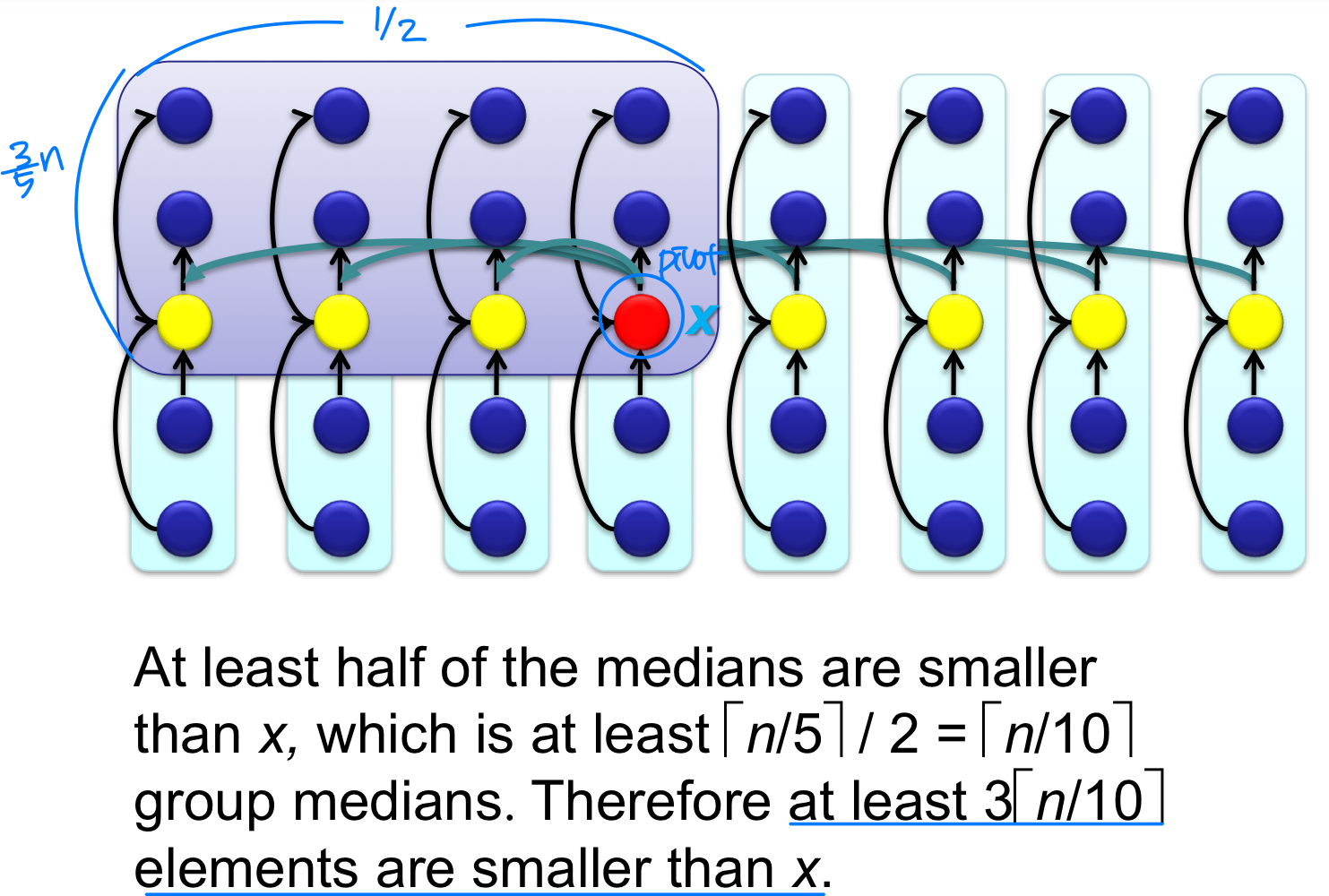
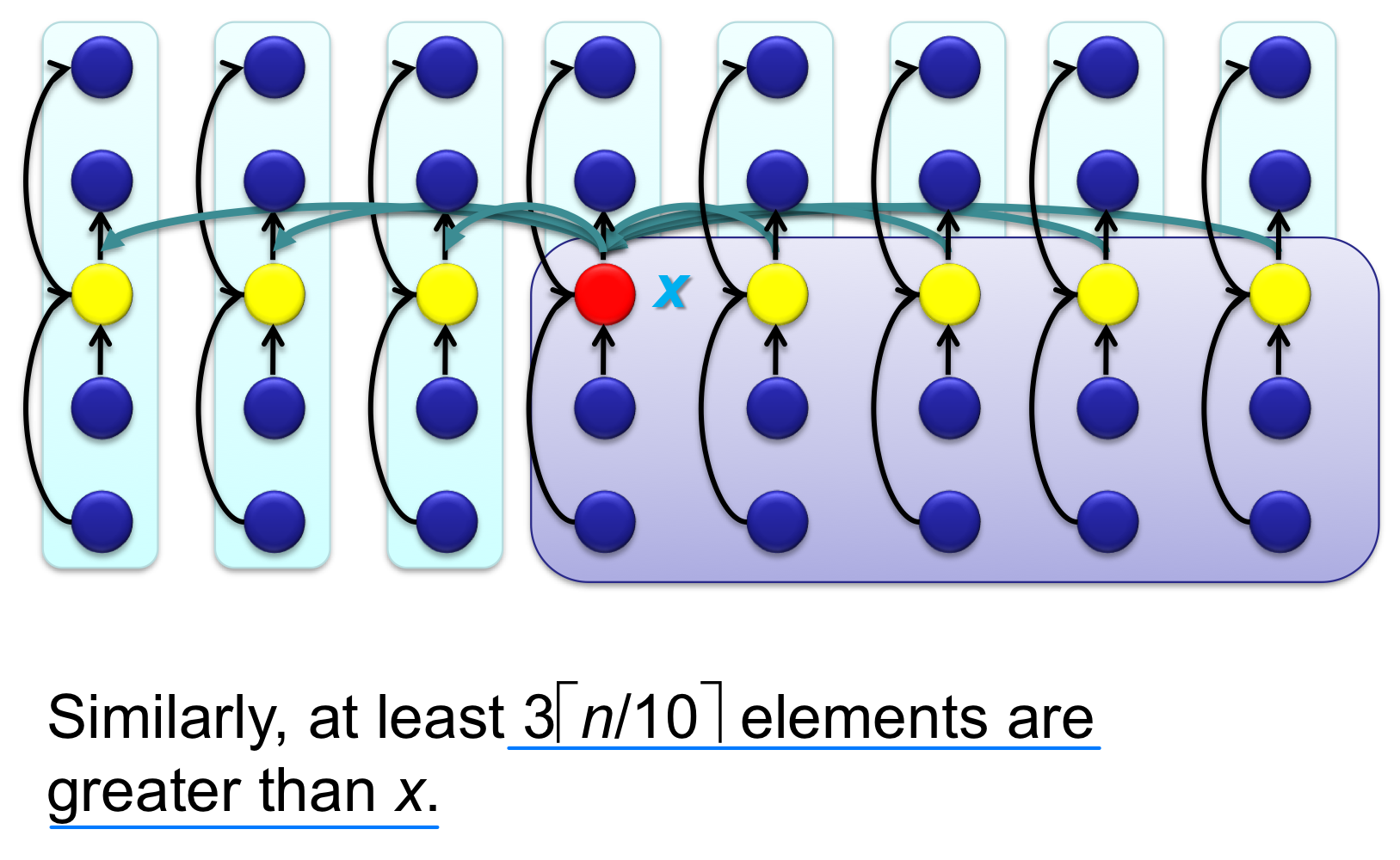

Median of medians를 피벗으로 사용하면, 전체 원소의 최소 30% 이상이 피벗보다 작거나 같고, 최소 30% 이상이 피벗보다 크거나 같다. 따라서 재귀 호출 시 최악의 경우에도 부분 배열의 크기가 전체의 약 70% 이하로 줄어든다.
시간 복잡도 분석


점화식을 풀면 이 된다. 최악의 경우에도 선형 시간을 보장하지만, 숨겨진 상수 계수가 커서 Randomized Select보다 실제 성능은 떨어진다. 그래서 실무에서는 Randomized Select를, 이론적 보장이 필요할 때만 이 알고리즘을 사용한다.
Exercise in Class
문제 1


문제 2: 5개 원소의 중앙값을 구하는 데 필요한 최소 비교 횟수
정답: 6번

HGU 전산전자공학부 용환기 교수님의 23-1 알고리듬 분석 수업을 듣고 작성한 포스트이며, 첨부한 모든 사진은 교수님 수업 PPT의 사진 원본에 필기를 한 수정본입니다.