Greedy Algorithm이란?
그리디 알고리즘(Greedy Algorithm) 은 일부 최적화 문제에 사용되는 설계 전략이다. 모든 최적화 문제에 적용되는 것은 아니다.
핵심 아이디어는 단순하다. 매 순간 가장 좋아 보이는 선택을 한다. 즉 지역 최적(Local Optimum) 을 선택하는 것이다.
이 전략이 항상 전역 최적(Global Optimum) 을 보장하지는 않는다. 하지만 많은 경우에 전역 최적 해를 찾아낸다. 놀이공원에서 최대한 많은 놀이기구를 타려면, 지금 당장 가장 빨리 끝나는 것부터 타는 식이다. 단순하지만 꽤 효과적인 접근법이다.
Activity Selection Problem
놀이공원에서 본전을 뽑으려면? 최대한 많은 놀이기구를 타는 것이 목표다.
이를 일반화하면 활동 선택 문제(Activity Selection Problem) 가 된다. 하나의 공유 자원을 독점적으로 사용하는 여러 활동을 스케줄링할 때, 서로 겹치지 않는(Mutually Compatible) 활동의 최대 집합을 선택하는 것이 목표다.
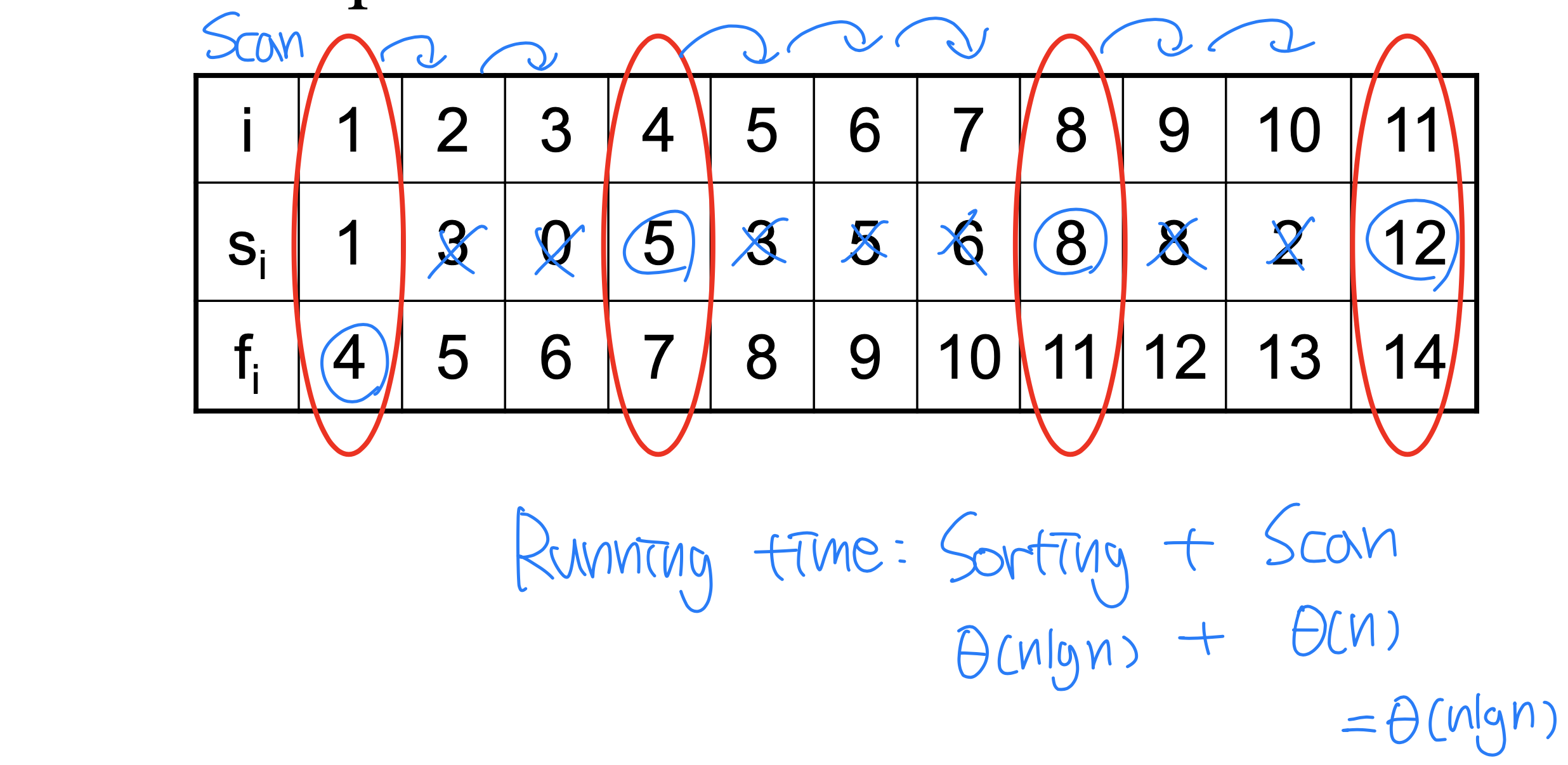
각 활동 는 시작 시각 와 종료 시각 를 가지며, 구간 로 표현된다. 두 활동 와 가 양립 가능(Compatible) 하려면 와 가 겹치지 않아야 한다.
활동들은 종료 시각의 오름차순으로 정렬되어 있다고 가정한다. 즉 이다.
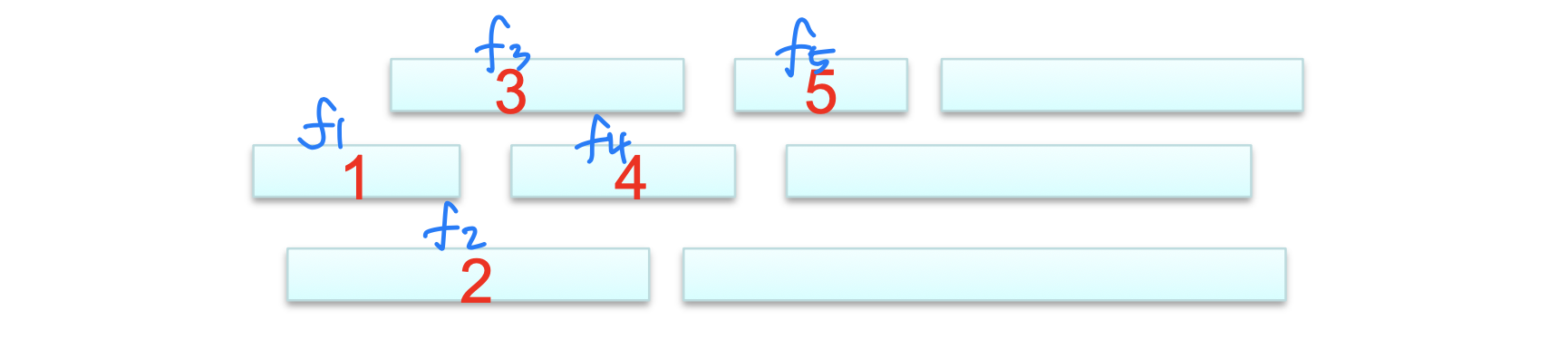
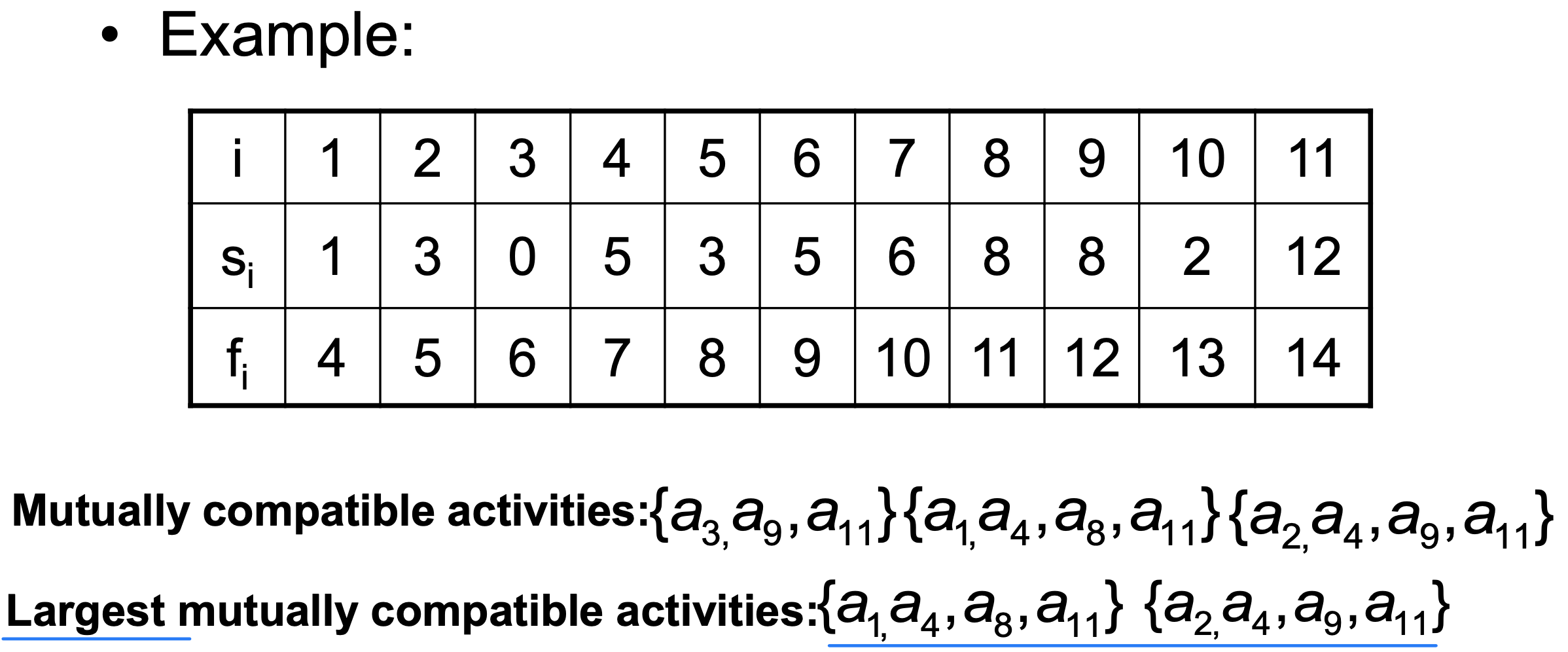
최적 스케줄의 구조
부분 집합 는 활동 가 끝난 후에 시작하고, 활동 가 시작하기 전에 끝나는 활동들의 집합이다.
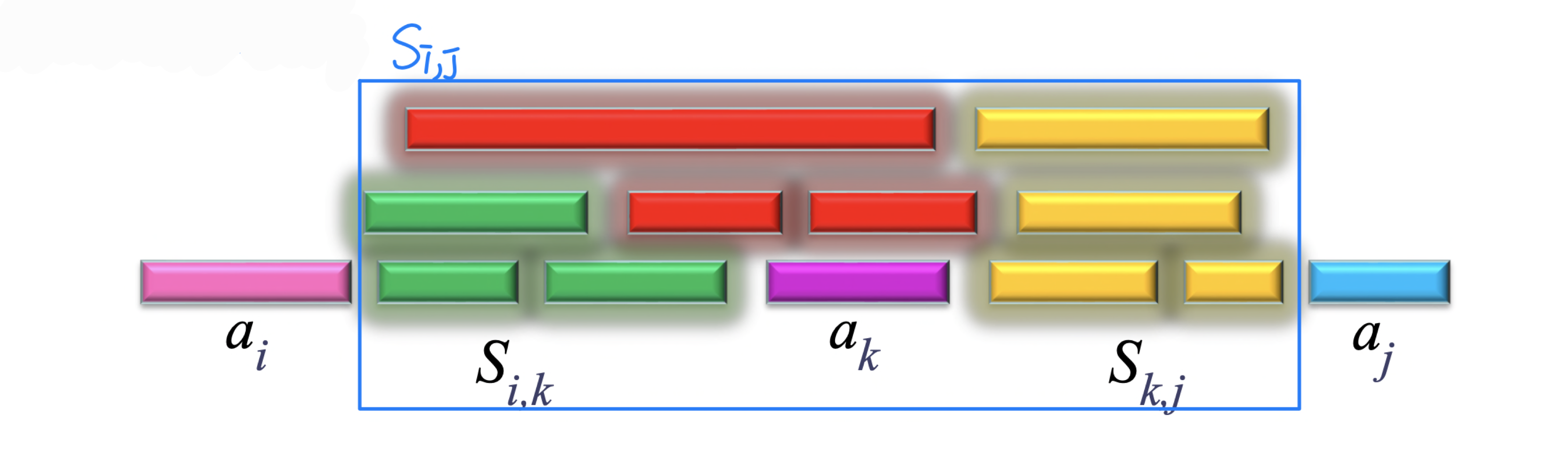
활동 가 의 최적 스케줄에 포함된다고 가정하면, 이며 최적 스케줄은 다음 세 부분으로 구성된다.
- 의 최대 부분 집합
- 의 최대 부분 집합
이 구조는 최적 부분 구조(Optimal Substructure) 를 만족한다.
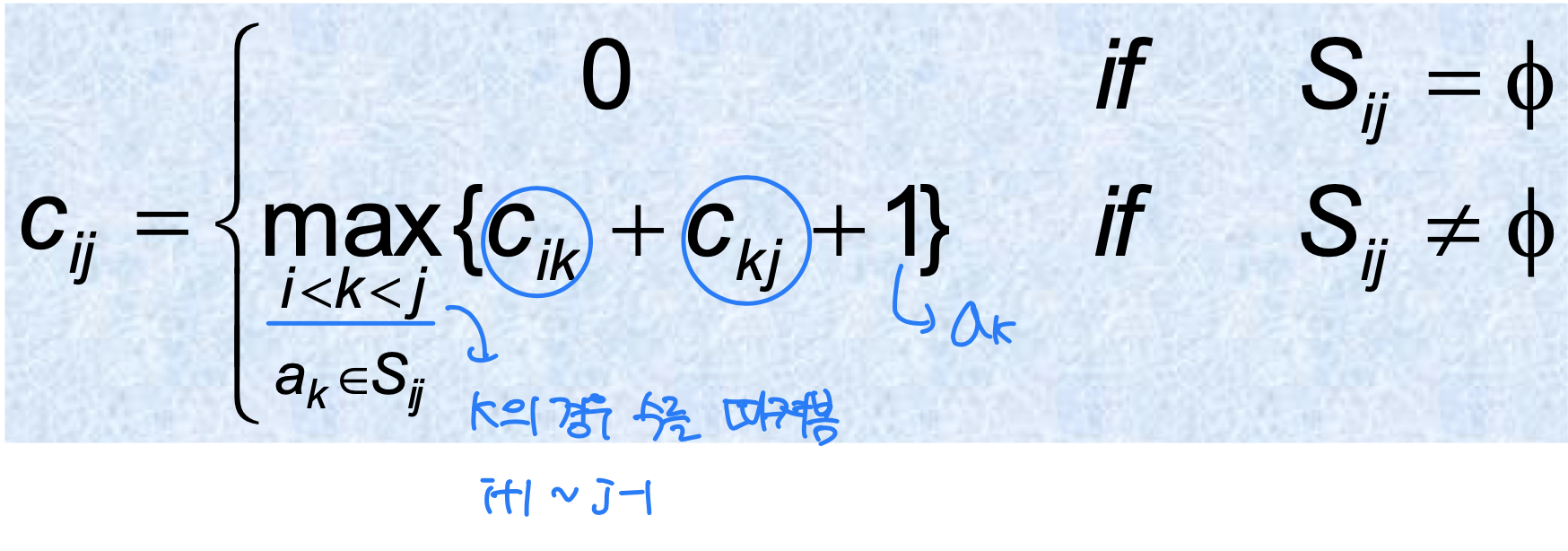
정리(Theorem)
을 에서 가장 빨리 끝나는 활동이라 하자. 그러면 다음 두 가지가 성립한다.
- 은 의 서로 양립 가능한 활동의 최대 크기 부분 집합 중 하나에 포함된다.
- 이므로, 을 선택하면 만이 유일한 비어있지 않은 부분 문제로 남는다.

가장 빨리 끝나는 활동을 선택하면, 남은 문제가 하나뿐이라는 점이 핵심이다. 이것이 그리디 접근을 가능하게 한다.
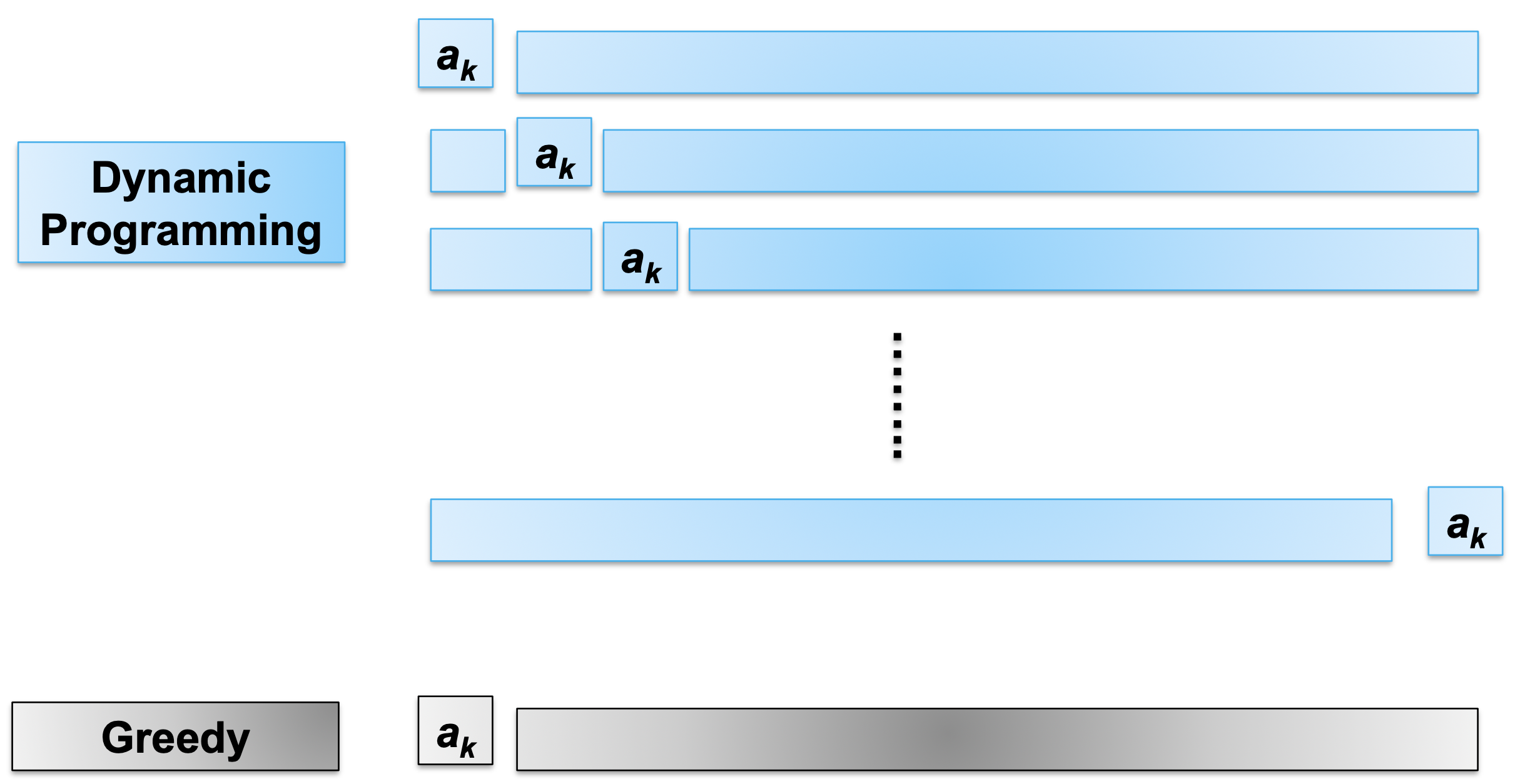
Dynamic Programming vs. Greedy
두 방법의 차이는 부분 문제의 수에 있다.
- DP: 하나의 최적 해에 두 개의 부분 문제가 사용된다. 부분 문제 를 풀 때 개의 선택지를 고려해야 한다.
- Greedy: 하나의 최적 해에 하나의 부분 문제만 사용된다. 를 풀 때 단 하나의 선택만 고려하면 된다.
그리디 알고리즘 구현
문제의 변형
위 문제에서는 수업 개수를 최대화하는 것이 목표였다. 만약 목표를 강의실 사용 총 시간을 최대화하는 것으로 바꾸면 어떻게 될까?
DP 접근은 여전히 유효하다. 하지만 다음과 같은 그리디 선택으로는 해결할 수 없다.
- 가장 일찍/늦게 시작하는 수업 선택
- 가장 일찍/늦게 끝나는 수업 선택
- 가장 긴 수업 선택
어떤 그리디 기준을 적용하더라도 최적 해를 보장하지 못한다. 이처럼 그리디가 모든 최적화 문제에 통하지는 않는다.
Greedy Choice Property
그리디 알고리즘이 올바르게 동작하려면 Greedy Choice Property가 성립해야 한다.
부분 문제에 대한 해를 고려하지 않고, 그 순간 최선으로 보이는 선택만으로 전역 최적 해를 구할 수 있다.
Huffman Codes: 텍스트 인코딩
Huffman Code는 데이터 압축에서 널리 사용되는 매우 효과적인 기법이다. 최적 접두사 코드(Optimal Prefix Code) 를 생성하며, 주어진 텍스트를 가능한 한 간결하게 표현하는 것이 목표다.
인코딩 방식 비교
고정 길이 인코딩(ASCII)
표준 ASCII 인코딩은 모든 문자를 7비트로 표현한다.

이 방식으로는 133비트 = 17바이트가 필요하다.
고정 길이 인코딩(최적화)
하지만 실제로 사용되는 문자가 12개뿐이라면, 이므로 4비트만으로 각 문자를 인코딩할 수 있다.
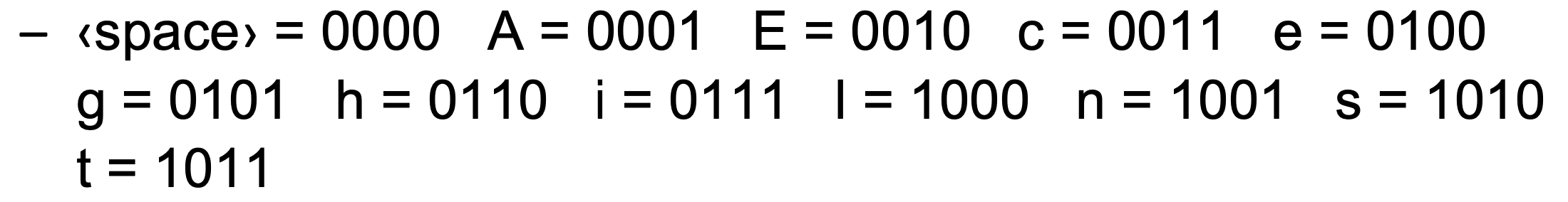
이 경우 76비트 = 10바이트로 줄어든다.
가변 길이 인코딩
자주 등장하는 문자에는 짧은 코드를, 드물게 등장하는 문자에는 긴 코드를 할당하면 더 효율적이다.
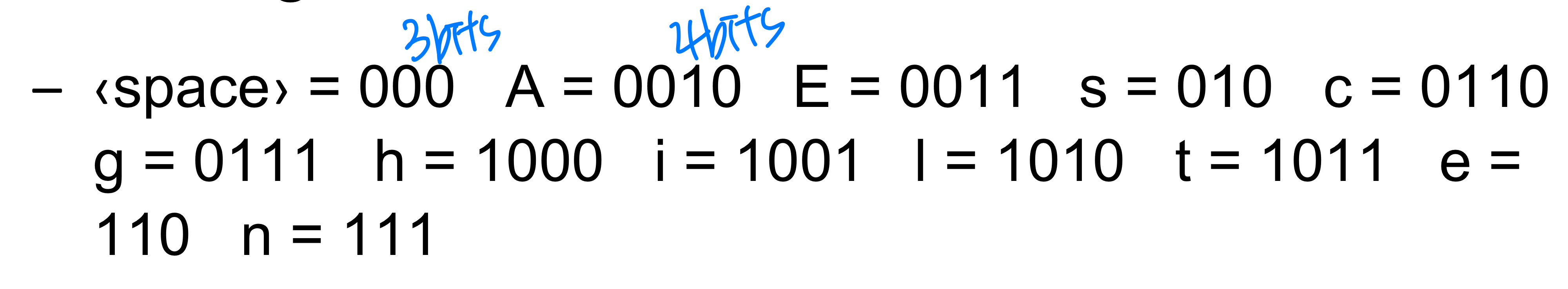
이 방식으로는 65비트 = 9바이트만 필요하다.
Prefix Code
접두사 코드(Prefix Code) 란, 어떤 코드워드도 다른 코드워드의 접두사(Prefix) 가 되지 않는 코드를 말한다. 예를 들어 10110이라는 비트열에서 1011은 4번째 접두사에 해당한다.
접두사 코드의 특징은 다음과 같다.
- 접두사 코드를 통해 최적 데이터 압축이 가능하다
- 디코딩이 쉽다: 비트열을 왼쪽부터 읽으며 코드워드를 즉시 구분할 수 있다
- 접두사 코드가 아닌 코드는 모호(Ambiguous) 하다. 즉, 2가지 이상으로 해석이 가능하다
- 대우 관계로, 접두사 코드이면 모호하지 않다(Unambiguous)
디코딩/인코딩 트리
고정 길이 코드의 트리
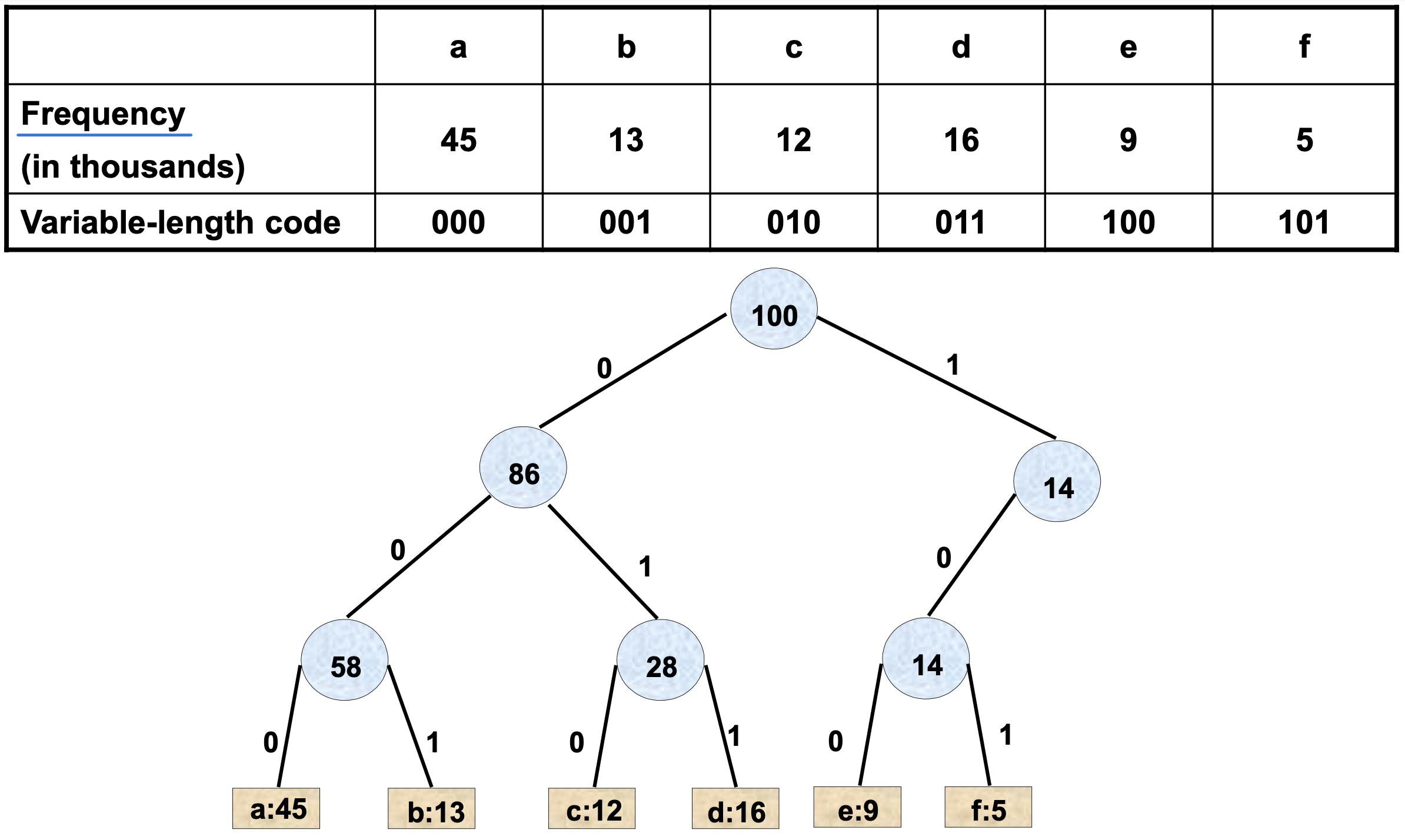
가변 길이 코드의 트리
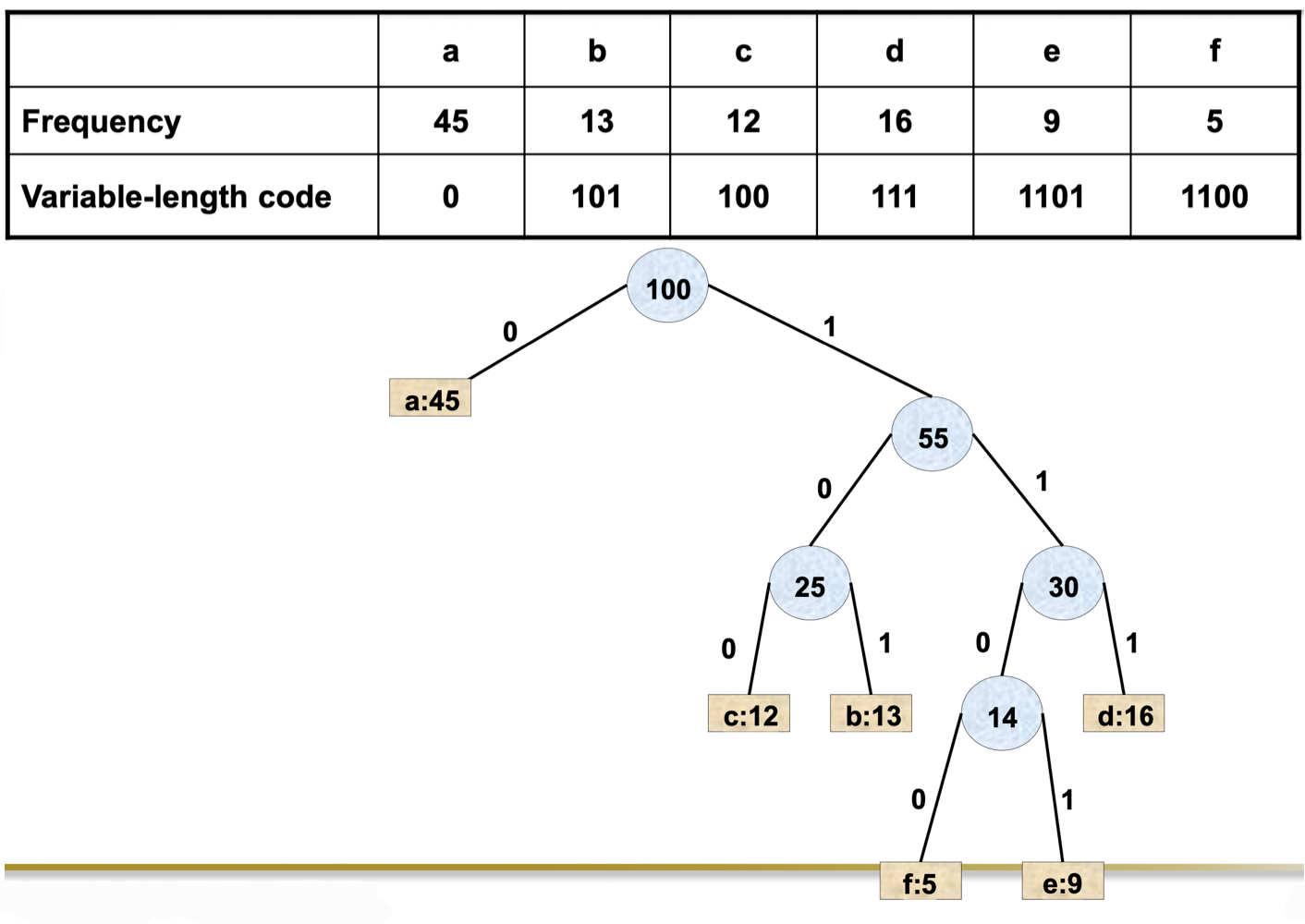
고정 길이 코드에서는 모든 리프가 같은 깊이에 있지만, 가변 길이 코드에서는 자주 등장하는 문자가 더 얕은 깊이에 위치한다.
파일 인코딩 비용
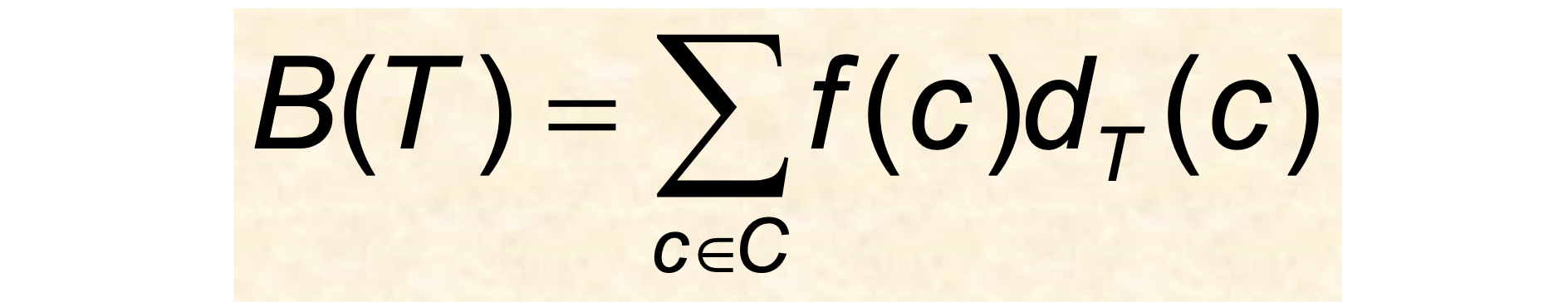
인코딩 비용을 수식으로 표현하면 다음과 같다.
- T: 알파벳 C에 대한 코딩 방식 c에 대응하는 트리
- f(c): 파일에서 문자 c의 빈도(Frequency)
- : 트리에서 문자 c의 리프 깊이(Depth)
- B(T): 파일을 인코딩하는 데 필요한 전체 비트 수
빈도가 높은 문자일수록 트리에서 얕은 위치에 놓아야 전체 비트 수가 줄어든다. Huffman 알고리즘은 이 B(T)를 최소화하는 트리를 만든다.
Huffman 알고리즘
Huffman-Code(C) {
n = len(C)
Q = C
for i = 1 to n-1
do allocate a new node z
left[z] = Extract-Min(Q) // O(lg n)
right[z] = Extract-Min(Q) // O(lg n)
f[z] = f[left[z]] + f[right[z]]
Insert(Q, z) // O(lg n)
return Extract-Min(Q)
}알고리즘의 동작 과정은 다음과 같다.
- 모든 문자를 빈도와 함께 우선순위 큐(Min-Heap) Q에 넣는다.
- 큐에서 빈도가 가장 작은 두 노드를 꺼내 새 노드의 왼쪽, 오른쪽 자식으로 연결한다.
- 새 노드의 빈도는 두 자식 빈도의 합이다.
- 새 노드를 큐에 다시 삽입한다.
- 큐에 노드가 하나 남을 때까지 반복한다.
Extract-Min과 Insert 연산이 각각 이고, 이를 번 반복하므로 전체 시간 복잡도는 이다.
실행 예시
아래 그림들은 Huffman 알고리즘이 단계별로 트리를 구성하는 과정을 보여준다.
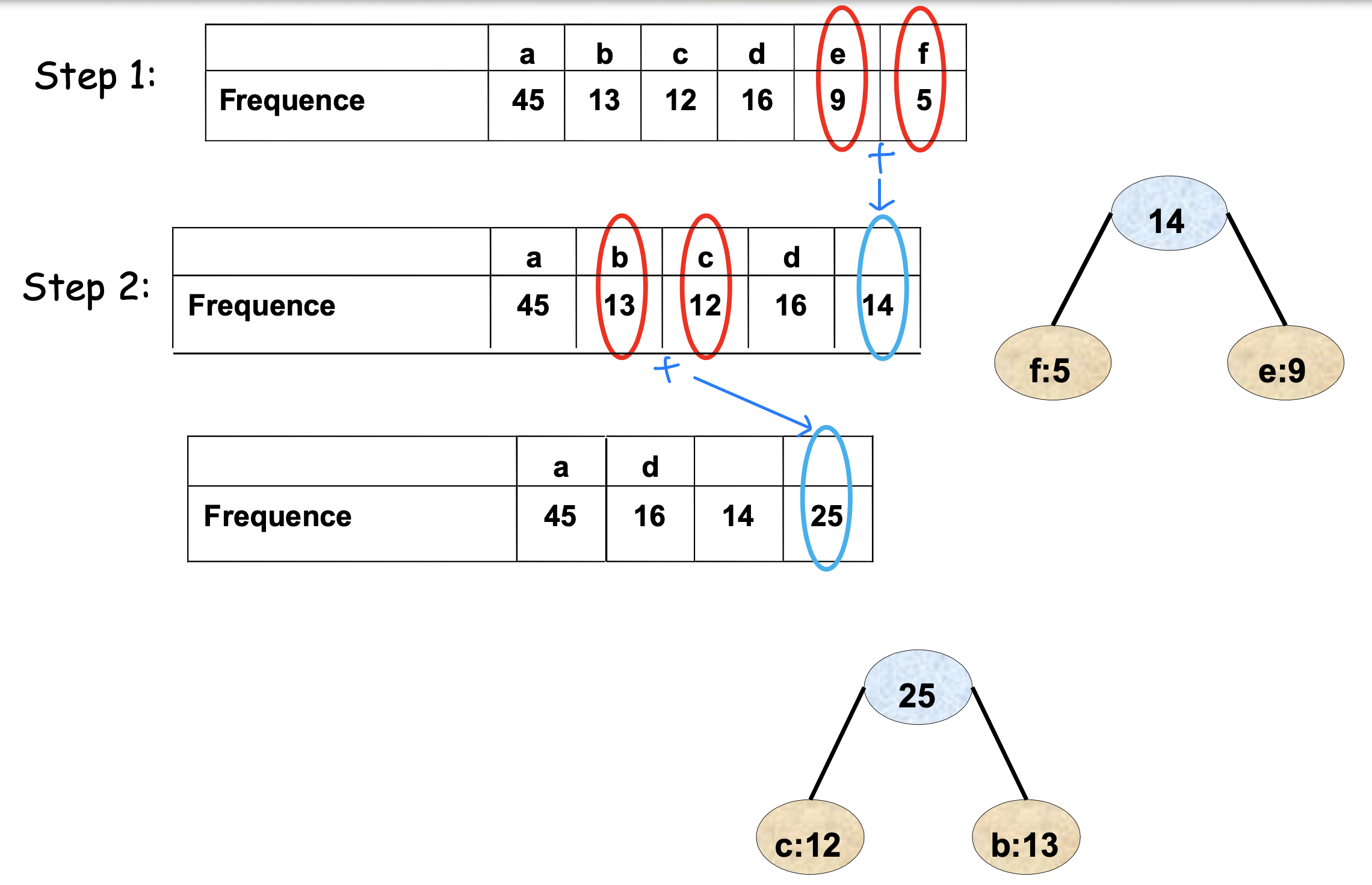
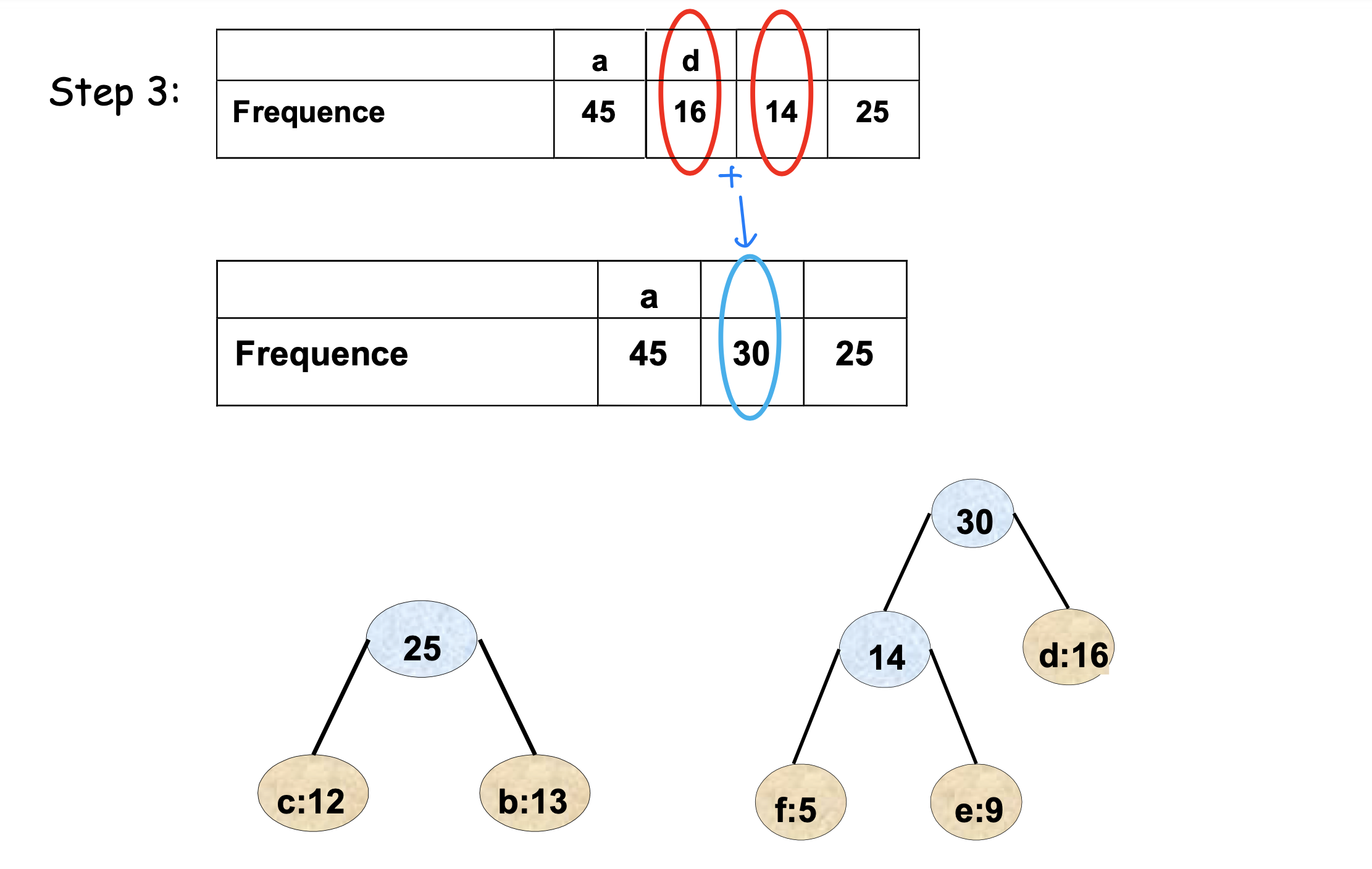
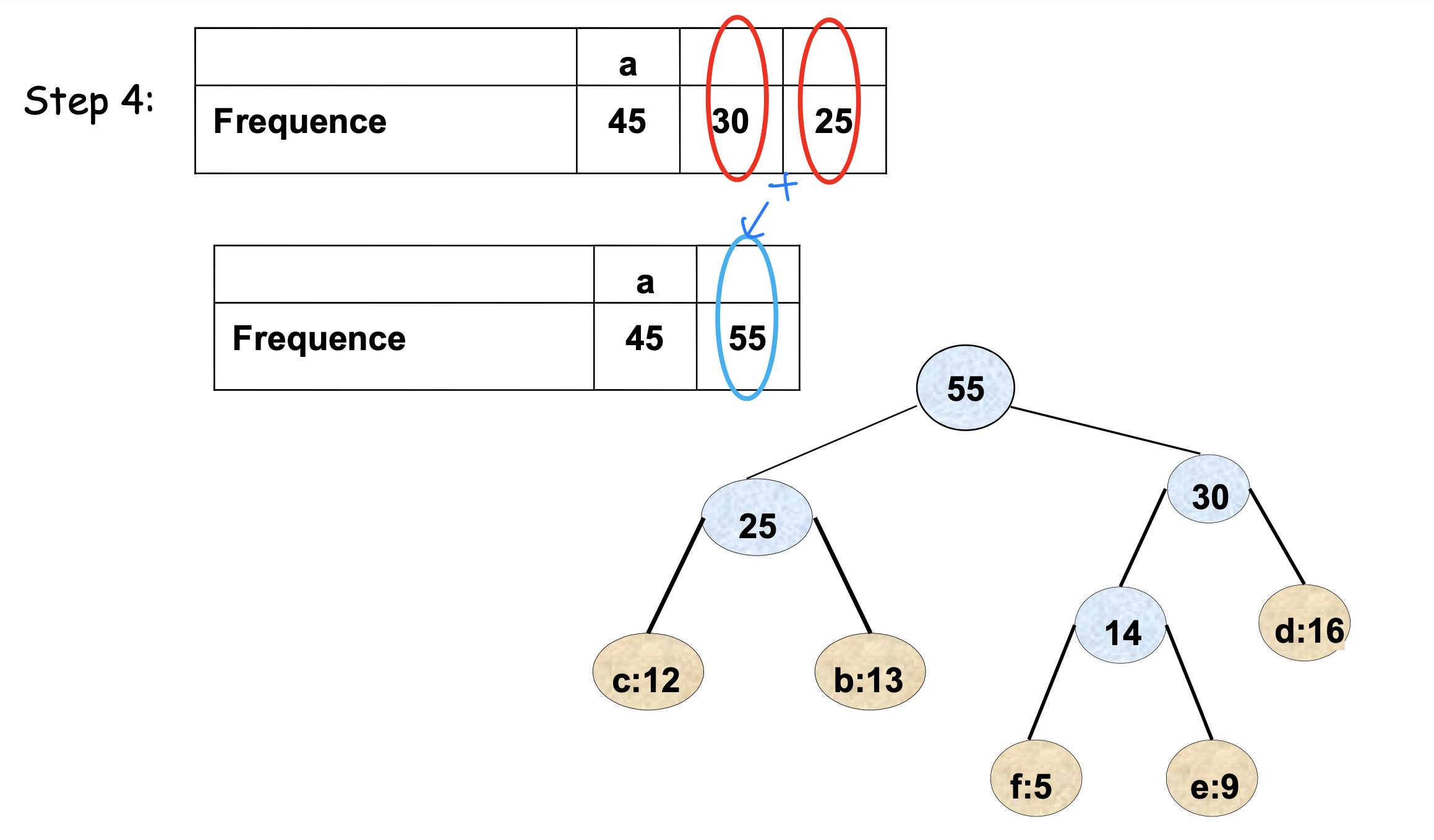
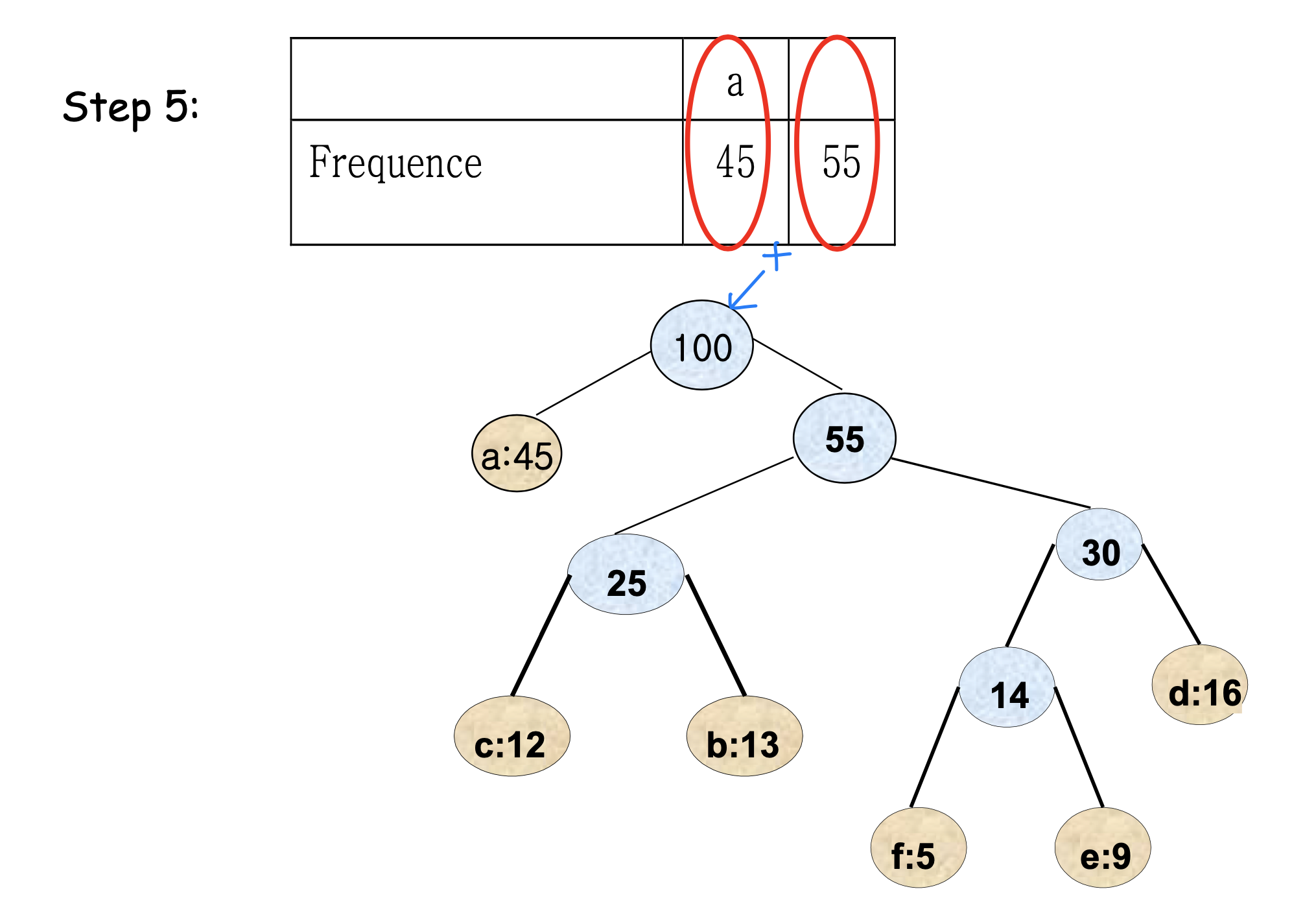
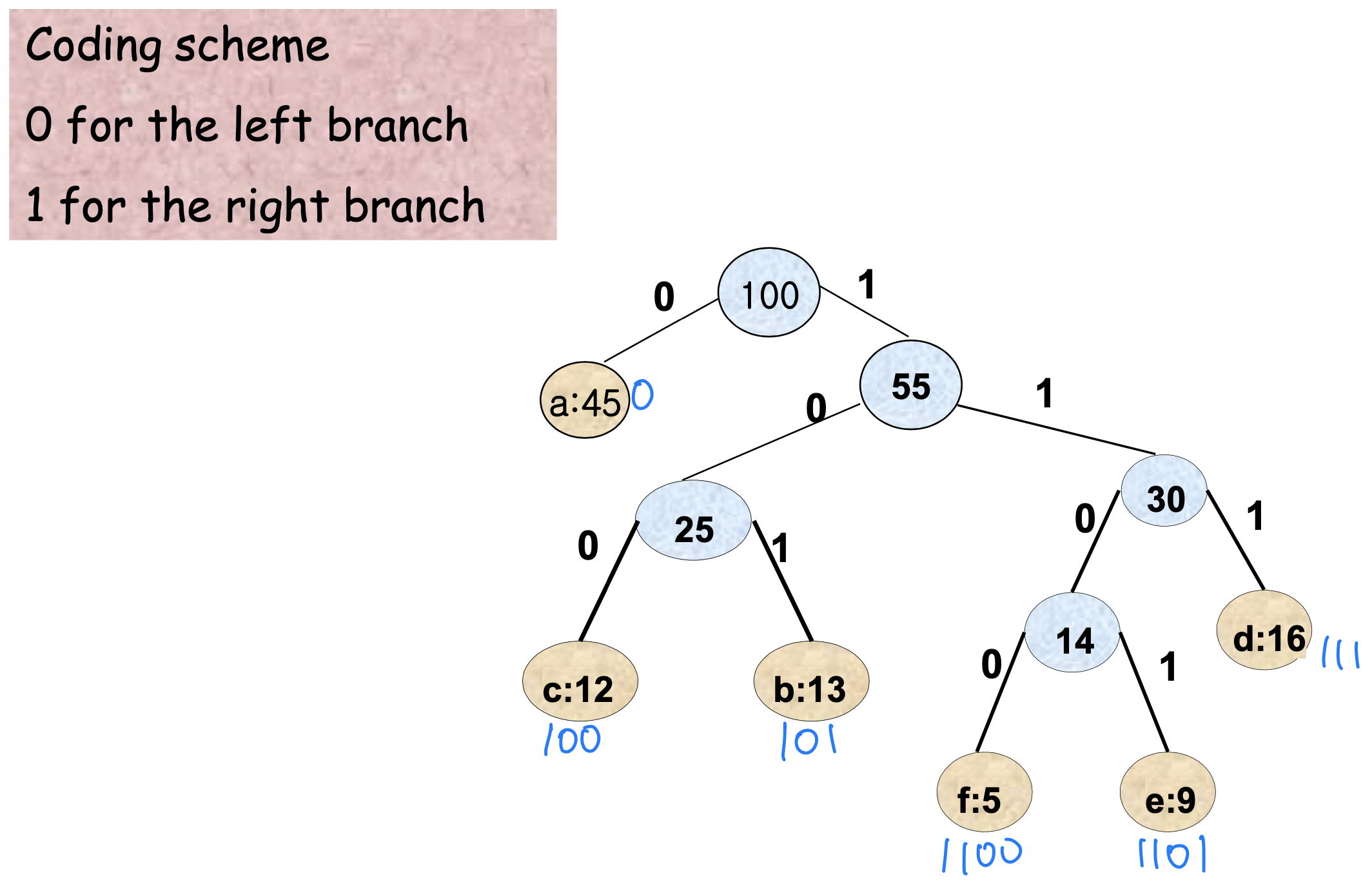
최종 트리에서 각 리프까지의 경로가 해당 문자의 코드가 된다. 왼쪽으로 가면 0, 오른쪽으로 가면 1을 부여하는 방식이다.
연습 문제
1. 거스름돈 문제: Greedy와 반례
동전의 종류가 이고 거스름돈이 30일 때를 생각해 보자.
그리디 방식은 가장 큰 동전부터 선택하므로 25 + 1 + 1 + 1 + 1 + 1 = 6개의 동전을 사용한다. 하지만 최적 해는 10 + 10 + 10 = 3개다. 그리디가 항상 최적이 아닌 대표적인 반례다.
2. 거스름돈 문제: DP 풀이
DP로 풀기 위한 점화식은 다음과 같다.
- V: 거스름돈 금액
- num[V]: 금액 V를 만드는 최소 동전 개수
- coins[1...m]: 1번부터 m번까지 각 동전의 단위

시간 복잡도는 이다. 금액 V의 각 값에 대해 m개의 동전을 모두 확인하기 때문이다.
3. Activity Selection: 반례
"호환되는 활동 중 지속 시간이 가장 짧은 활동을 선택하는" 그리디 접근이 최적이 아님을 보이는 반례다.
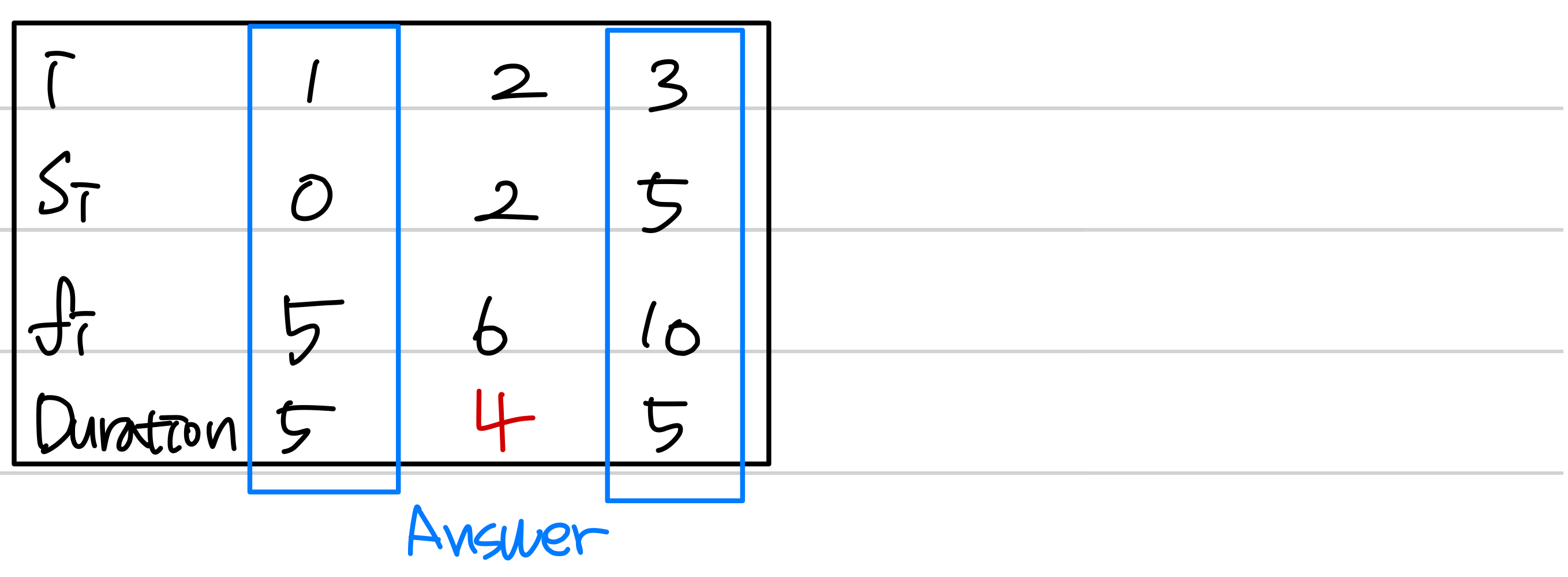
이 그리디 방식은 를 선택하지만, 최적 해는 과 를 선택하는 것이다. "가장 빨리 끝나는 활동"이 아닌 "가장 짧은 활동"을 기준으로 하면 최적 해를 보장하지 못한다.
4. Huffman 코딩 연습
다음과 같은 빈도 테이블이 주어졌을 때 Huffman 트리를 구성한다.
| a | b | c | d | e | f | g | h |
|---|---|---|---|---|---|---|---|
| 1 | 1 | 2 | 3 | 5 | 8 | 13 | 21 |
왼쪽 가지는 0, 오른쪽 가지는 1로 부여한다.
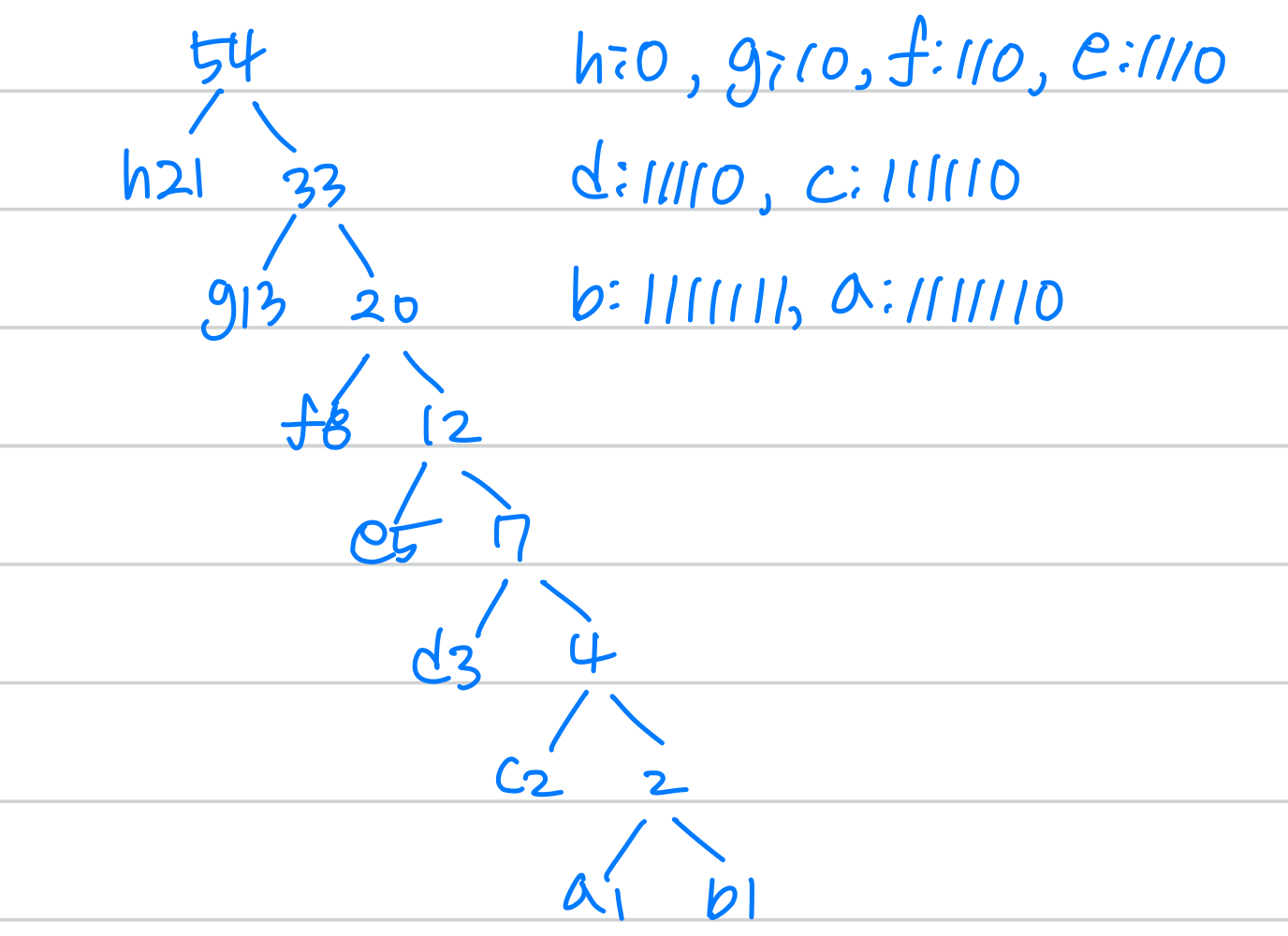
참고로 'c'가 큐에서 추출된 직후 생성되는 새 노드의 빈도는 2이다. (a와 b를 합친 노드의 빈도가 2이고, 이것이 c의 빈도와 같다.)
5. Greedy로 풀려면 꼭 증명해야 하는가?
그렇다. Greedy Choice Property가 성립함을 증명해야 한다. 그리디 전략이 "그럴듯하게 보이는 것"과 "실제로 최적 해를 보장하는 것"은 다르다. 앞서 본 반례들이 이를 잘 보여준다.
HGU 전산전자공학부 용환기 교수님의 23-1 알고리듬 분석 수업을 듣고 작성한 포스트이며, 첨부한 모든 사진은 교수님 수업 PPT의 사진 원본에 필기를 한 수정본입니다.