정렬 알고리즘을 선택할 때 흔히 속도와 메모리 효율 사이에서 고민하게 된다. Merge Sort는 빠르지만 추가 메모리가 필요하고, Insertion Sort는 제자리(in-place) 정렬이지만 느리다. Heap Sort는 이 두 가지 장점을 모두 갖춘 알고리즘이다. 빠르면서도 입력 배열 외에 상수 개의 추가 공간만 사용한다.
이 글에서는 Heap Sort의 기반이 되는 힙(Heap) 자료구조, 힙을 유지하는 연산, 정렬 과정, 그리고 힙을 활용한 우선순위 큐(Priority Queue) 까지 차례로 살펴본다.
힙(Heap)이란?
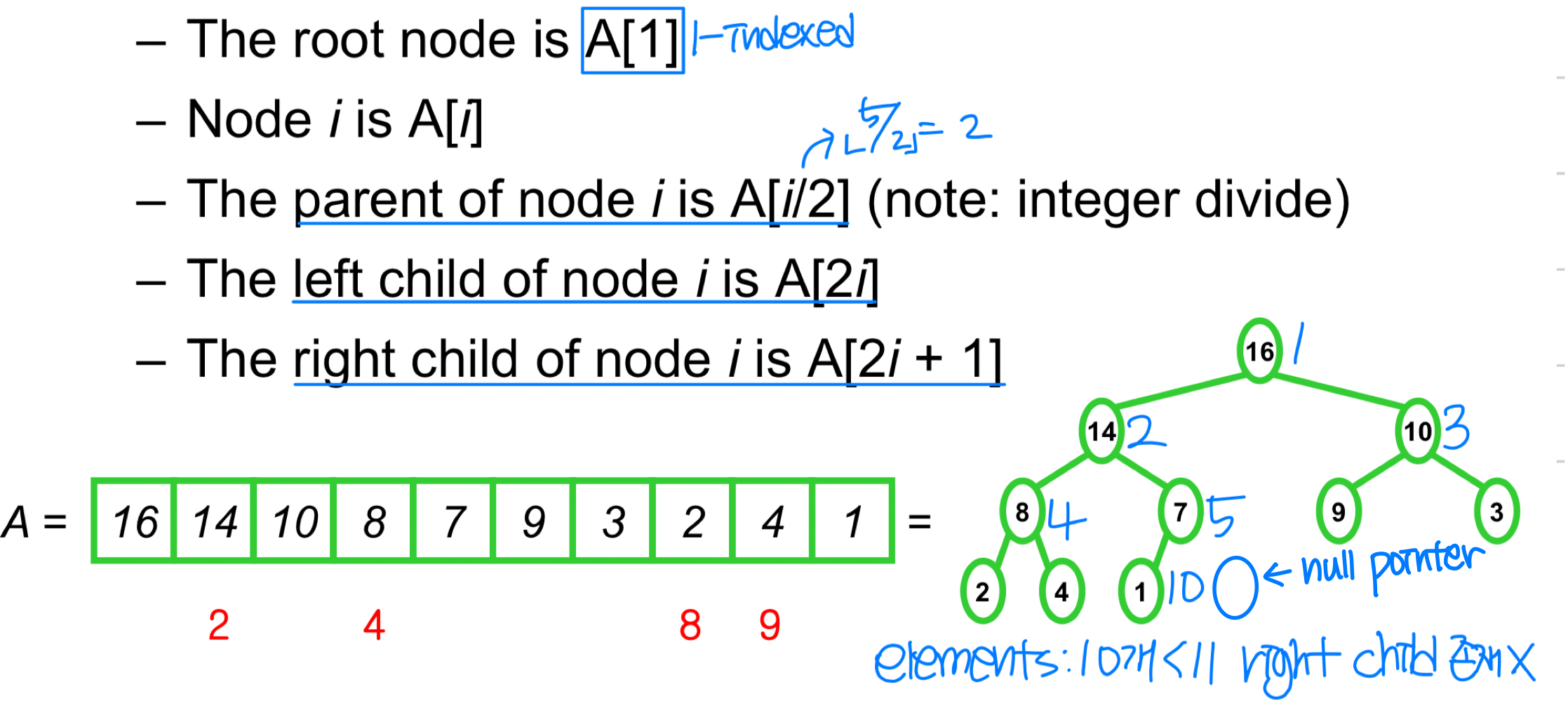
힙은 거의 완전 이진 트리(Nearly Complete Binary Tree) 를 배열로 구현한 자료구조다. "거의 완전"이라 함은 마지막 레벨을 제외한 모든 레벨이 꽉 차 있고, 마지막 레벨은 왼쪽부터 순서대로 채워져 있다는 뜻이다.
힙에는 두 종류가 있다.
- Max-Heap: 부모 노드의 값이 자식 노드의 값보다 항상 크거나 같다 (거의 완전 이진 트리 + Max Tree)
- Min-Heap: 부모 노드의 값이 자식 노드의 값보다 항상 작거나 같다 (거의 완전 이진 트리 + Min Tree)
힙 속성(Heap Property)
Max-Heap의 핵심 속성은 다음과 같다.
A[Parent(i)] >= A[i](모든 노드 i > 1에 대해)
즉, 어떤 노드의 값이든 그 부모 노드의 값을 넘을 수 없다. 이 속성이 루트까지 연쇄적으로 적용되므로, 힙에서 가장 큰 원소는 항상 루트에 위치한다.
트리에서 노드의 높이(height) 란 해당 노드에서 리프까지 가장 긴 하향 경로의 간선 수를 뜻하며, 트리의 높이는 루트의 높이와 같다. 원소가 n개인 힙의 높이는 이다.
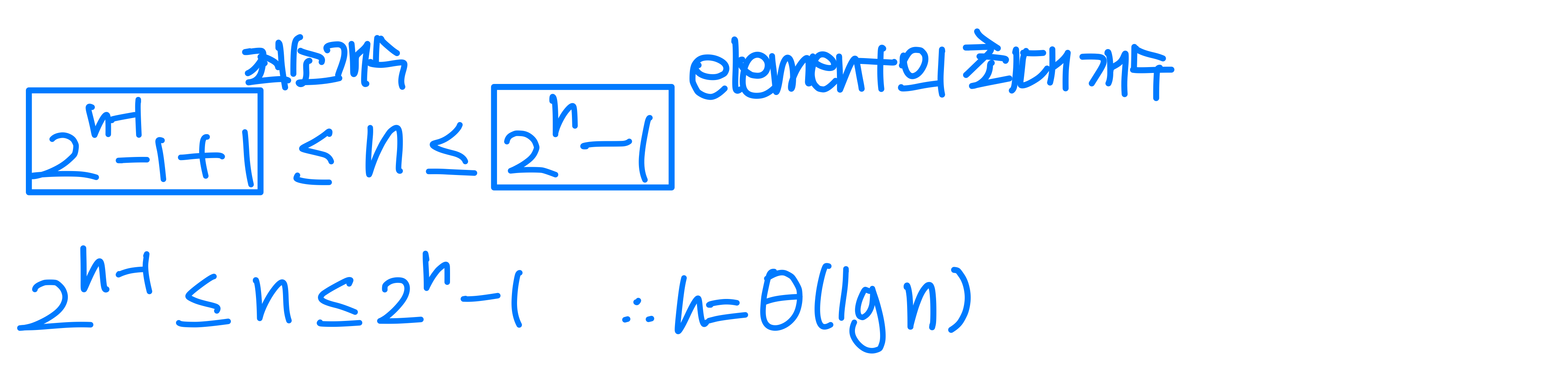
Max-Heapify
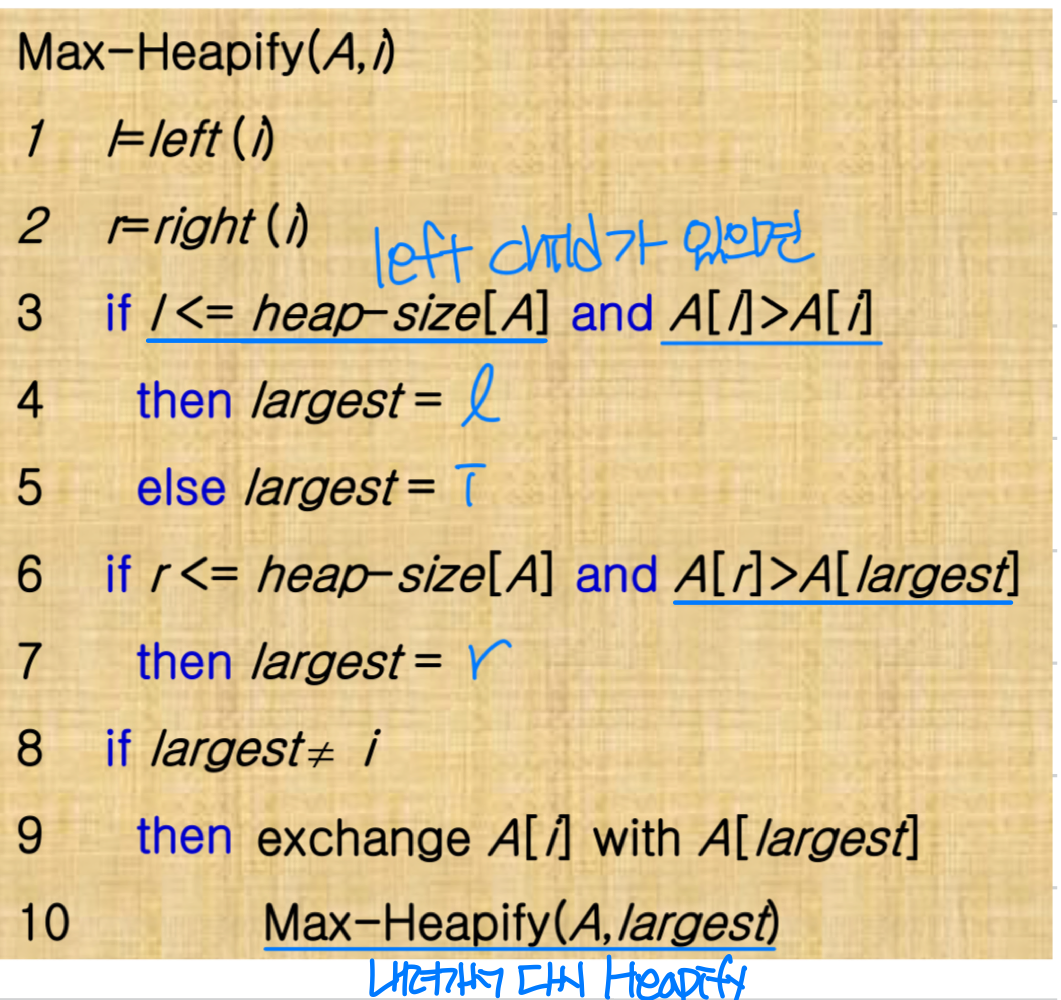
Max-Heapify는 Max-Heap 속성을 유지시키는 핵심 연산이다.
동작 조건과 과정은 다음과 같다.
- 호출 전에 A[i]가 자식보다 작을 수 있다 (힙 속성 위반 가능)
- 단, i의 왼쪽과 오른쪽 서브트리는 이미 Max-Heap이라고 가정한다
- Max-Heapify를 실행하면 A[i]가 아래로 "떠내려가면서(float down)" 올바른 위치를 찾고, i를 루트로 하는 서브트리가 Max-Heap이 된다
Max-Heapify의 시간 복잡도
i, left(i), right(i) 사이의 관계를 비교하고 교환하는 작업은 에 끝난다. 문제는 교환 후 재귀적으로 서브트리를 타고 내려가야 한다는 점이다.
최악의 경우는 트리가 가장 불균형할 때, 즉 왼쪽 서브트리만 가득 찬 경우다. 이때 왼쪽 서브트리의 크기가 최대 2n/3이 되고(마지막 행이 절반만 차 있는 상태), 오른쪽은 n/3이다.
따라서 점화식은 다음과 같다.
Master Theorem의 Case 2를 적용하면, 이다.
Build-Max-Heap
Build-Max-Heap은 정렬되지 않은 배열을 Max-Heap으로 변환하는 연산이다. 핵심 아이디어는 상향식(Bottom-Up) 접근이다.
배열 A의 길이가 n일 때, A[n/2 + 1] ~ A[n] 에 해당하는 노드들은 리프 노드다. 리프 노드는 자식이 없으므로 이미 그 자체로 힙이다. 따라서 n/2번째 노드부터 1번째 노드까지 역순으로 Max-Heapify를 호출하면 된다.

Build-Max-Heap의 시간 복잡도
단순 분석으로는 Max-Heapify 호출이 O(lg n) 이고 총 n/2 번 호출하므로 O(n lg n) 이 된다. 하지만 더 정밀한 분석을 하면, 낮은 높이의 노드가 압도적으로 많고 각 노드에서의 작업량이 높이에 비례하기 때문에, 실제 수행 시간은 O(n) 으로 더 타이트한 상한을 갖는다.

Heap Sort
Heap Sort는 두 단계로 동작한다.
- Phase 1 - 힙 구성: 임의의 배열을 Max-Heap으로 만든다 (Build-Max-Heap)
- Phase 2 - 정렬: 루트(최댓값)를 배열 끝으로 보내고, 힙 크기를 줄인 뒤 Max-Heapify를 반복한다
루트에 항상 최댓값이 있다는 힙의 특성을 이용하여, 최댓값을 하나씩 뽑아 배열 뒤쪽에 배치하는 방식이다.

우선순위 큐(Priority Queue)
우선순위 큐는 동적 집합(Dynamic Set) 을 관리하는 자료구조다. 동적 집합이란 원소가 추가되거나 삭제되는 등 시간에 따라 변하는 집합을 뜻한다. 각 원소는 우선순위를 나타내는 키(key) 를 가진다.
대표적인 활용 예시는 다음과 같다.
- Max-Priority Queue: 공유 컴퓨터에서 작업 스케줄링에 활용된다. 우선순위가 높은 작업부터 처리한다.
- Min-Priority Queue: 서비스 대기 시간을 최소화하기 위해, 가장 작은 키를 가진 작업을 먼저 선택한다.
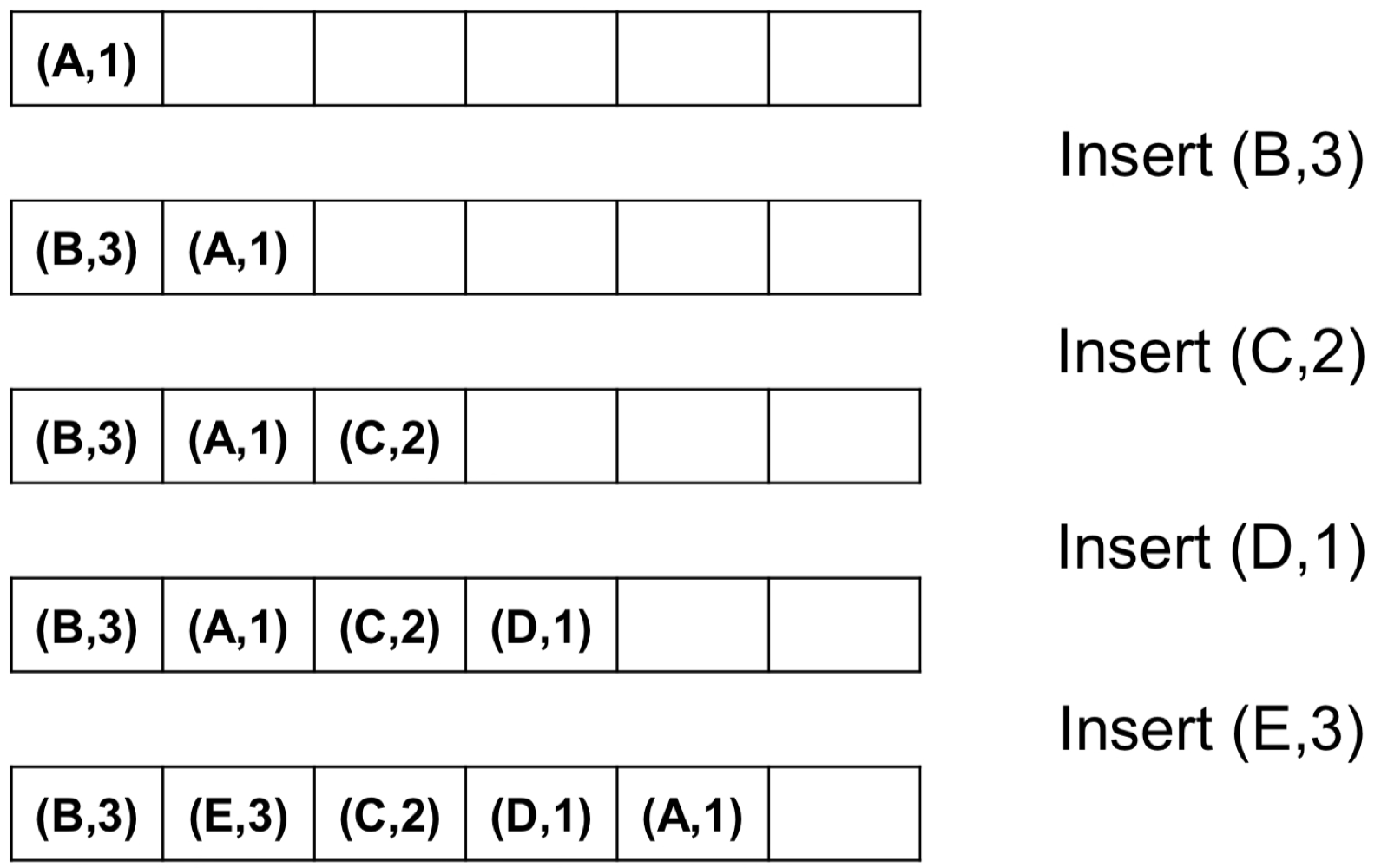
예시
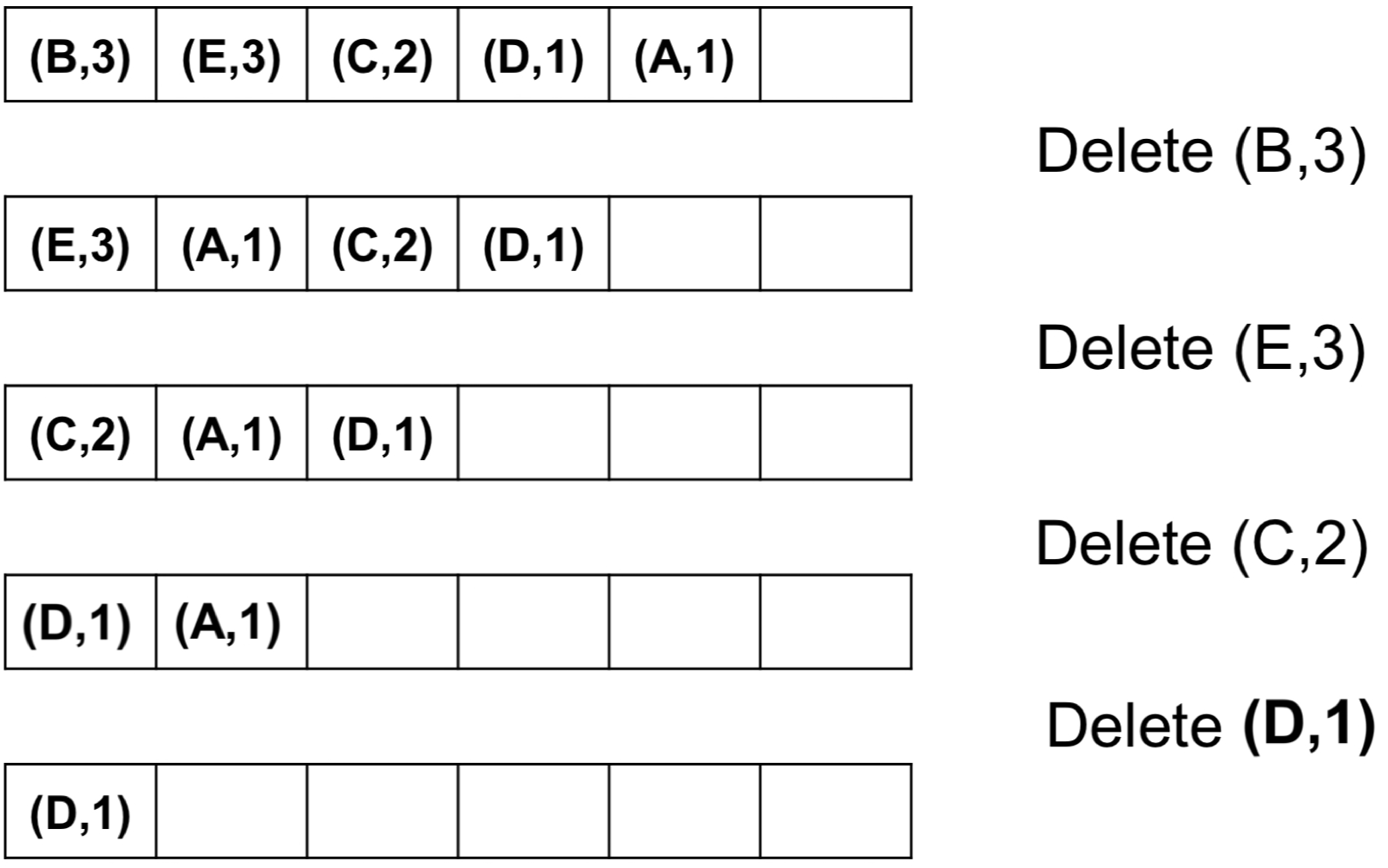
주요 연산
INSERT(S, x) - 원소 삽입
집합 S에 원소 x를 삽입한다. 새 원소를 힙의 마지막에 추가한 뒤, 키 값에 맞는 위치까지 위로 올린다.

MAXIMUM(S) - 최댓값 조회
집합 S에서 가장 큰 키를 가진 원소를 반환한다. Max-Heap에서는 루트가 항상 최댓값이므로 에 수행된다.

EXTRACT-MAX(S) - 최댓값 추출
집합 S에서 가장 큰 키를 가진 원소를 제거하고 반환한다. 루트를 꺼낸 뒤, 마지막 원소를 루트로 올리고 Max-Heapify를 수행하여 힙 속성을 복원한다.

INCREASE-KEY(S, x, k) - 키 값 증가
원소 x의 키 값을 k로 증가시킨다. 키가 커졌으므로 부모와 비교하며 위로 올려 힙 속성을 유지한다.

연습 문제
1. 우선순위 큐에서 삽입 순서는 중요한가?
힙 기반 우선순위 큐는 우선순위만 따지는 것이 아니다. 삽입 순서에 따라 힙의 구조가 달라지기 때문에, 순서도 결과에 영향을 준다.
2. Max-Heap 여부 판별
| 배열 | Max-Heap? |
|---|---|
| 100, -, 89, 67, 25, 80, -, - | No |
| 100, 90, 52, 89, 67, 25, 55, 80 | No |
| 100, 40, 82, 35, 25, 1, -, - | Yes |
첫 번째와 두 번째 배열은 부모보다 큰 자식이 존재하여 Max-Heap 속성을 위반한다. 세 번째 배열은 모든 부모-자식 관계가 속성을 만족한다.
3. 참/거짓
(1) 오름차순으로 정렬된 배열은 Min-Heap이다 → 참(T)
오름차순이면 A[Parent(i)] ≤ A[i]가 항상 성립하므로 Min-Heap 조건을 만족한다.
(2) Max-Heap에서 가장 작은 원소는 배열의 마지막 원소이다 → 거짓(F)
가장 작은 원소는 반드시 리프 노드에 있지만, 마지막 리프라는 보장은 없다. 어떤 리프 노드에든 위치할 수 있다.
4. Build-Max-Heap 수행
초기 배열:
| 20 | 1 | 16 | 9 | 10 | 6 | 8 | 9 | 3 | 2 |
Build-Max-Heap 결과:
| 20 | 10 | 16 | 9 | 2 | 6 | 8 | 9 | 3 | 1 |
여기서 주의할 점은 Tie Breaking이다. 값이 같을 때 교환 여부는 비교 연산에 등호(=)를 포함하느냐에 따라 달라진다.
5. Max-Priority Queue 시뮬레이션
다음 연산을 순서대로 수행한다.
- Insert(A, 4)
- Insert(B, 3)
- Insert(C, 5)
- Insert(D, 4)
- Delete (C, 5 제거)
- Delete (A, 4 또는 D, 4 제거)
- Insert(E, 4)
- Insert(F, 5)
- Delete (F, 5 제거)
최종 결과:
| A, 4 | B, 3 | E, 4 |
HGU 전산전자공학부 용환기 교수님의 23-1 알고리듬 분석 수업을 듣고 작성한 포스트이며, 첨부한 모든 사진은 교수님 수업 PPT의 사진 원본에 필기를 한 수정본입니다.